目录
HashMap概述:
数据结构的组成:
一个键值对是如何存入该结构中:
HashMap中链表和红黑树的用途和转换方式 :
HashMap概述:

HashMap是基于哈希表的Map接口实现的,它存储的内容是键值对<key,value>映射。
该类无序。
数据结构的组成:
在JDK1.7及以前,HashMap的数据结构是有数组+单向链表组成的。(在链表中插入元素采用头插法)
在JDK1.8之后,HashMap的数据结构是有数组+单向链表+红黑树组成的。(在链表中插入元素采用尾插法)
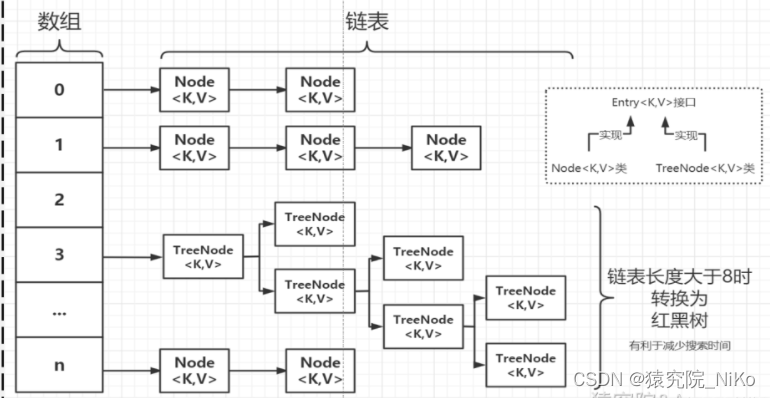
HashMap内部数据结构使用数组+链表+红黑树进行存储的。数组的类型为Node[ ],每个Node都保存了某个KV键值对元素的key、value、hash、next等值。如图:

每个Node对象都是单向链表的组成节点。
在HashMap中存在加载因子(填充因子)默认为0.75。
代表HashMap对数组容量的使用率为75%,超过该使用率则数组就会扩容。
加载因子决定了HashMap对数组的使用率,加载因子越高,表示填满的元素就越多,集合的空间利用率就越高,但是冲突的机会就会增加。反之,越小则冲突越少,但是空间利用率就越低,浪费了很多空间。

当
一个键值对是如何存入该结构中:
当添加一个KV键值对元素时,通过该元素的key的hash值,计算出该元素在数组中的下标。如果该下标位置已经有其他Node对象,则采用链地址法处理,即将新添加的KV键值对元素以链表的形式存储。将新元素封装成一个新的Node对象,插入到该下标位置的链表尾部。当链表的长度超过8并且数组的长度超过64时,为了避免查找搜索的性能下降,该链表会转成一个红黑树。
当添加第一个KV键值对时,如果数组为空,则默认扩容为16。
加入元素时,如果链表长度大于阈值(默认为8)并且数组长度小于64时,会产生数组扩容。
添加元素后,当HashMap中的元素个数超过【数组大小×加载因子】时,原数组扩容2倍。
在JDK1.7及之前计算下标时,采用hash%数组长度
在JDK1.8之后,采用(数组长度-1)& hash。(提高了性能,数组的长度必须为2的N次幂)
HashMap中链表和红黑树的用途和转换方式 :
HashMap采用数组+单向链表+红黑树组成。
数组的特点:查询快,插入删除慢。
链表的特点:查询慢,插入删除快。
看一个实例:
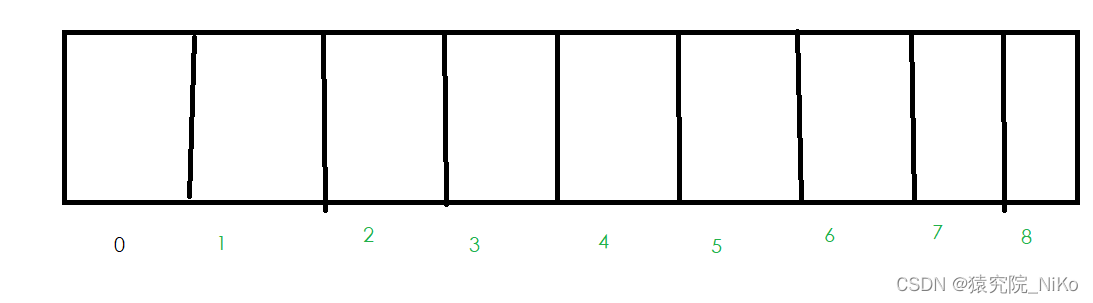
有以上长度为9的数组,现在要存储key="张三"这样一个数据,假设他的hash值为423。用(数组长度-1)& hash计算下标 得0,将key存放在下标为0处。
通过这样的方法也随之会产生一个问题——哈希冲突。因为数组的大小有限,我们计算的下标始终在一定范围内。这样我们难免会产生一样的索引,但是同一个位置又不能存放2个不同的key,所以就产生了哈希冲突。这样的话,链表的用处就来了,当发现数组上的位置被占用了,我们可以将key链接在该位置后。
我们都知道链表的查询速度很慢,所以当链表上的数据过多时就会导致查询速度变慢。当链表的长度大于等于8并且数组长度大于64时,会将链表转换为红黑树,加快查询速度。当长度小于8时又会变成链表结构。




![[架构之路-202]- 常见的需求获取技术=》输出=》用户需求、客户需求(As...., I want.....)、用例图](https://img-blog.csdnimg.cn/23fcc0dfdc42409d88f1a84aaad49d32.png)