什么是Flink CDC,以及如何使用
- CDC介绍
- Flink CDC
- 适用于场景?
- Flink CDC 的简单用例
- 数据库配置
- 创建数据库和相应的表
- 开启mysql数据库bin-log日志
- 1.如果是服务器
- 2.如果在Windows使用小皮
- 搭建Flink CDC java环境
- 添加maven相关pom
- 构建Sink
- main配置运行
- 操作数据库查看结果
- 操作数据JSON讲解
CDC介绍
数据库中的CDC(Change Data Capture,变更数据捕获)是一种用于实时跟踪数据库中数据变化的技术。CDC的主要目的是在数据库中捕获增量数据,以便在需要时可以轻松地将这些数据合并到其他系统或应用程序中。CDC在数据库管理、数据同步、数据集成和数据备份等方面具有广泛的应用。
CDC通常通过以下几种方式实现:
-
基于触发器的CDC:在表上创建触发器,当数据发生更改时,触发器会将更改的数据记录到其他系统或表中。
-
基于事务日志的CDC:通过读取数据库事务日志,将日志中的更改记录解析为可操作的数据。这种方法通常用于增量备份和恢复。
-
基于游标的CDC:在数据库中使用游标,逐行处理数据更改,并将这些更改应用于其他系统或表。
-
基于时间戳的CDC:为表中的每个数据行分配一个时间戳,当数据发生更改时,更新相应的时间戳。然后,可以使用时间戳来识别和处理数据更改。
-
基于消息队列的CDC:将数据更改作为事件发送到消息队列,以便其他系统或应用程序可以订阅和处理这些事件。
Flink CDC
Flink CDC(Change Data Capture,即数据变更抓取)是一个开源的数据库变更日志捕获和处理框架,它可以实时地从各种数据库(如MySQL、PostgreSQL、Oracle、MongoDB等)中捕获数据变更并将其转换为流式数据。Flink CDC 可以帮助实时应用程序实时地处理和分析这些流数据,从而实现数据同步、数据管道、实时分析和实时应用等功能。
Flink CDC 的主要特点包括:
-
支持多种数据库类型:Flink CDC 支持多种数据库,如 MySQL、PostgreSQL、Oracle、MongoDB 等。
-
实时数据捕获:Flink CDC 能够实时捕获数据库中的数据变更,并将其转换为流式数据。
-
高性能:Flink CDC 基于 Flink 引擎,具有高性能的数据处理能力。
-
低延迟:Flink CDC 可以在毫秒级的延迟下处理大量的数据变更。
-
易集成:Flink CDC 与 Flink 生态系统紧密集成,可以方便地与其他 Flink 应用程序一起使用。
-
高可用性:Flink CDC 支持实时备份和恢复,确保数据的高可用性。
适用于场景?
Flink CDC 可以用于各种场景,如:
-
实时数据同步:将数据从一个数据库实时同步到另一个数据库。
-
实时数据管道:构建实时数据处理管道,处理和分析数据库中的数据。
-
实时数据分析:实时分析数据库中的数据,提供实时的业务洞察。
-
实时应用:将数据库中的数据实时应用于实时应用程序,如实时报表、实时推荐等。
-
实时监控:实时监控数据库中的数据,检测异常和错误。
Flink CDC 的简单用例
数据库配置
创建数据库和相应的表
创建mydb数据库,并创建user表
create database mydb;
create table user(
id bigint primary key auto_increment,
name varchar(255)
);
INSERT INTO mydb.user (name) VALUES ('小明');
INSERT INTO mydb.user (name) VALUES ('小红');
创建了一个名为 mydb 的数据库,并在其中创建了一个名为 user 的表。表中包含一个主键 id 和一个字符串类型的 name 字段。还向 user 表中插入了两条记录,分别是 '小明' 和 '小红'。
开启mysql数据库bin-log日志
1.如果是服务器
在my.cnf中添加binlog配置,并重启mysql数据库
server-id = 123
log_bin = mysql-bin
binlog_format = row
binlog_row_image = full
expire_logs_days = 10
gtid_mode = on
enforce_gtid_consistency = on
已经为 MySQL 设置了一些配置参数。下面是对这些参数的解释:
-
server-id = 123:指定服务器的唯一标识符,通常用于区分不同的数据库服务器。
-
log_bin = mysql-bin:启用二进制日志记录,以便在数据库出现故障时可以恢复数据。
-
binlog_format = row:指定二进制日志的记录格式。row 格式会记录每个更改行的详细信息,这对于需要事务完整性的应用程序非常有用。
-
binlog_row_image = full:设置 row 格式的二进制日志记录行的完整信息,包括列值、注释等。这有助于提高应用程序的可恢复性。
-
expire_logs_days = 10:设置自动清理过期二进制日志文件的天数。在这个例子中,设置为 10 天。
-
gtid_mode = on:启用全局事务 ID 模式,这使得基于 GTID 的复制成为可能。
-
enforce_gtid_consistency = on:强制执行 GTID 一致性,确保事务在不同的 MySQL 实例之间保持一致。
2.如果在Windows使用小皮
在小皮面板里设置,如图:
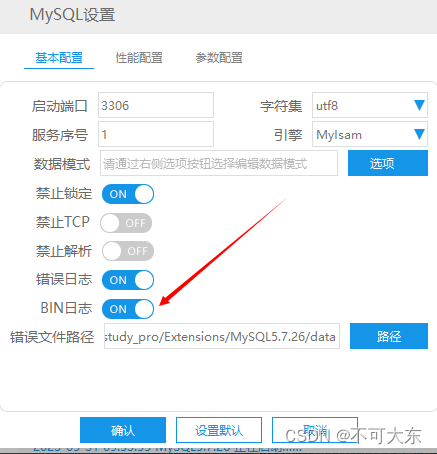
打开bin日志开关
搭建Flink CDC java环境
添加maven相关pom
在pom里添加相关Flink CDC依赖
<!-- flink connector 基础包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>1.14.4</version>
</dependency>
<!-- CDC mysql 源-->
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-sql-connector-mysql-cdc</artifactId>
<version>2.3.0</version>
</dependency>
<!-- Flink Steam流处理-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>1.14.4</version>
</dependency>
<!-- flink java客户端-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.14.4</version>
</dependency>
<!-- 开启webui支持,默认是8081,默认没有开启-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_2.12</artifactId>
<version>1.14.4</version>
</dependency>
<!-- Flink Table API和SQL API使得在Flink中进行数据处理变得更加简单和高效
通过使用Table API和SQL API,可以像使用传统的关系型数据库一样,通过编写SQL语句或者使用类似于
Java的API进行数据处理和分析-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime_2.11</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.11</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>2.0.6</version>
</dependency>
这是一段 Maven 依赖配置,它引入了 Flink Connector Base、CDC MySQL Source、Flink Streaming Java、Flink Java Client、Flink Runtime Web、Flink Table Runtime 和 Logback Classic。
这些依赖库提供了以下功能:
-
Flink Connector Base:Flink 的连接器基础包,用于将 Flink 与其他系统进行集成。
-
CDC MySQL Source:Flink 的 MySQL CDC 源,用于从 MySQL 数据库中读取数据流。
-
Flink Streaming Java:Flink 的 Java 流处理 API,用于编写并发程序以处理数据流。
-
Flink Java Client:Flink 的 Java API,用于在 Java 应用程序中使用 Flink。
-
Flink Runtime Web:Flink 的 Web UI,用于监控和管理 Flink 集群。
-
Flink Table Runtime:Flink 的 Table API,使在 Flink 中进行数据处理变得更加简单和高效。
-
Logback Classic:日志记录库,用于记录应用程序的日志信息。
构建Sink
Flink CDC(Change Data Capture)中的Sink用于将CDC接收到的数据写入外部系统(如数据库或文件系统),以实现数据同步和数据备份等功能,并将其转换为DataStream流。然后,Sink将这个DataStream流写入到外部系统中,以便进行后续的数据处理和分析。
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
public class CustomSink extends RichSinkFunction<String> {
@Override
public void invoke(String value, Context context) throws Exception {
System.out.println("json->: "+value);
}
}
这段代码定义了一个名为CustomSink的类,它继承自RichSinkFunction类。RichSinkFunction是Flink CDC中用于将数据写入外部系统(如数据库或文件系统)的函数接口。CustomSink的作用是将CDC接收到的数据写入外部系统中。具体实现方式由子类CustomSink来定义。由于这个类继承了RichSinkFunction,因此可以使用Flink中的其他RichSink函数特性,例如设置日志级别、配置连接等,invoke则是处理函数。
main配置运行
如下面的代码,构建Flink CDC连接
public static void main(String[] args) throws Exception {
MySqlSourceBuilder<String> builder = MySqlSource.builder();
MySqlSource<String> source = builder.hostname("192.168.2.6")
.port(3306)
.databaseList("mydb")
.tableList("mydb.user")
.username("root")
.password("root")
.deserializer(new JsonDebeziumDeserializationSchema())
.includeSchemaChanges(true)
.build();
// 启动webui,绑定本地web-ui端口号
Configuration configuration=new Configuration();
configuration.setInteger(RestOptions.PORT,8081);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
env.enableCheckpointing(5000);
env.fromSource(source, WatermarkStrategy.noWatermarks(),"MYSQL Source")
.addSink(new CustomSink());
env.execute();
}
这段代码是使用Flink构建一个数据流处理任务,从MySQL数据库中读取数据并进行处理。
首先,使用MySqlSourceBuilder创建一个MySqlSource对象,并设置连接参数(hostname、port、databaseList、tableList、username和password)以及反序列化器(JsonDebeziumDeserializationSchema)。然后,创建Configuration对象并设置WebUI端口号(RestOptions.PORT),接着使用StreamExecutionEnvironment创建一个执行环境,启用检查点(checkpointing)并将MySqlSource和自定义的Sink添加到执行环境中。最后,执行整个任务。
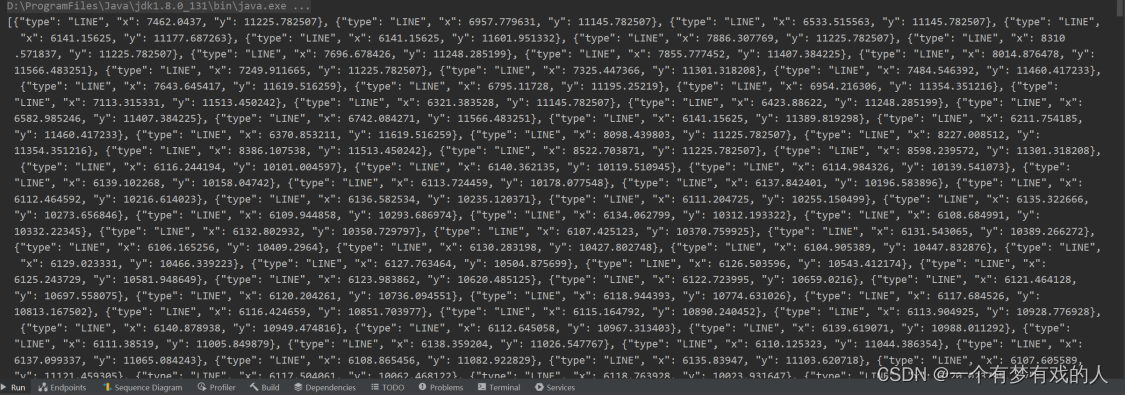
操作数据库查看结果
如图所示:
{
"before": null,
"after": {
"id": "1661935564737286146",
"qu_type": 4,
"level": 1,
"image": "",
"content": "dos查看日期、时间",
"create_time": 1685100091000,
"update_time": 1685100091000,
"remark": "",
"analysis": ""
},
"source": {
"version": "1.6.4.Final",
"connector": "mysql",
"name": "mysql_binlog_source",
"ts_ms": 0,
"snapshot": "false",
"db": "mydb",
"sequence": null,
"table": "t_user",
"server_id": 0,
"gtid": null,
"file": "",
"pos": 0,
"row": 0,
"thread": null,
"query": null
},
"op": "r",
"ts_ms": 1685521801276,
"transaction": null
}
这段代码是Flink CDC监听到的MySQL数据库binlog中的一条变更数据记录,表示在MySQL的t_user表中发生了一次读取操作,读取的数据记录的内容为:
-
“id”: “1661935564737286146”
-
“qu_type”: 4
-
“level”: 1
-
“image”: “”
-
“content”: “dos查看日期、时间”
-
“create_time”: 1685100091000
-
“update_time”: 1685100091000
-
“remark”: “”
-
“analysis”: “” 其中,before字段为null,表示这是一条insert操作;after字段为变更后的数据内容;source字段表示数据的来源信息,包括MySQL的版本、连接器类型、数据库名称、表名称等;op字段表示操作类型,"r"表示读取操作;ts_ms字段表示变更发生的时间戳;transaction字段表示事务信息,这里为null,表示这是一条非事务性的操作记录。
操作数据JSON讲解
在Flink CDC中,op字段表示MySQL数据库binlog中的操作类型,通常情况下分为以下几种类型:
-
“c”:表示create,表示对数据库进行了创建操作。
-
“u”:表示update,表示对数据库进行了更新操作。
-
“d”:表示delete,表示对数据库进行了删除操作。
-
“r”:表示read,表示对数据库进行了读取操作。 其中,前三种操作类型都是数据的变更操作,read操作则是指对数据库进行的查询操作。在Flink CDC中,一般只会监听到前三种操作类型,因为只有这三种操作类型才会导致数据库中的数据发生变化,而read操作则只是查询数据,并不会导致数据的变化。







![深度学习进阶篇[7]:Transformer模型长输入序列、广义注意力、FAVOR+快速注意力、蛋白质序列建模实操。](https://img-blog.csdnimg.cn/img_convert/15d0de3275239031b89367901bf89247.jpeg)