前言
在Redis中,hashtable 被称为字典(dictionary),它是一个数组+链表到结构。每个键值对都会有一个dictEntry
OBJ_ENCODING_HT
这种编码夯实内部才是真正的哈希表结构,或称为字典结构,其可以实现O(1)复杂度的读写操作,因此效率很高。
在Redis内部。从OBJ_ENCODING_HT:

编码格式
redis6
ziplist
hashtable
ziplist
ziplist 压缩列表是一种紧凑编码格式,总体思想是花时间来(压缩,解压)获取节约空间,即以部分读写性能为代价,来换取极高的内存空间利用率,因此只会用于字段个素少,且字段值也比较小的场景。压缩类标内存利用率极高的原因与其连续内存的特性是分不开的。
ziplist为了节约内存开发的,他是由连续内存卡组成的顺序型数据结构,优点类似于数组。
zi plist是一个特殊编码的双向链表,他不存储指向前一个链表节点prev和执行下一个链表节点的指针next.
而是存储上一个节点长度和当前节点长度。通过牺牲部分读写性能,来换取高效的内存空间利用率,节约内存,是一种时间换空间的思想。
zplist 中 的zlentry
对比java hashMap中 Map.entry<K,V>
static class Node<K,v> implements Map.entry<K,V>{
final K key;
V value;
Node<K,V> next;
}
而 zap中是zlEntry

zipList 的存取
zlentry 属性解析
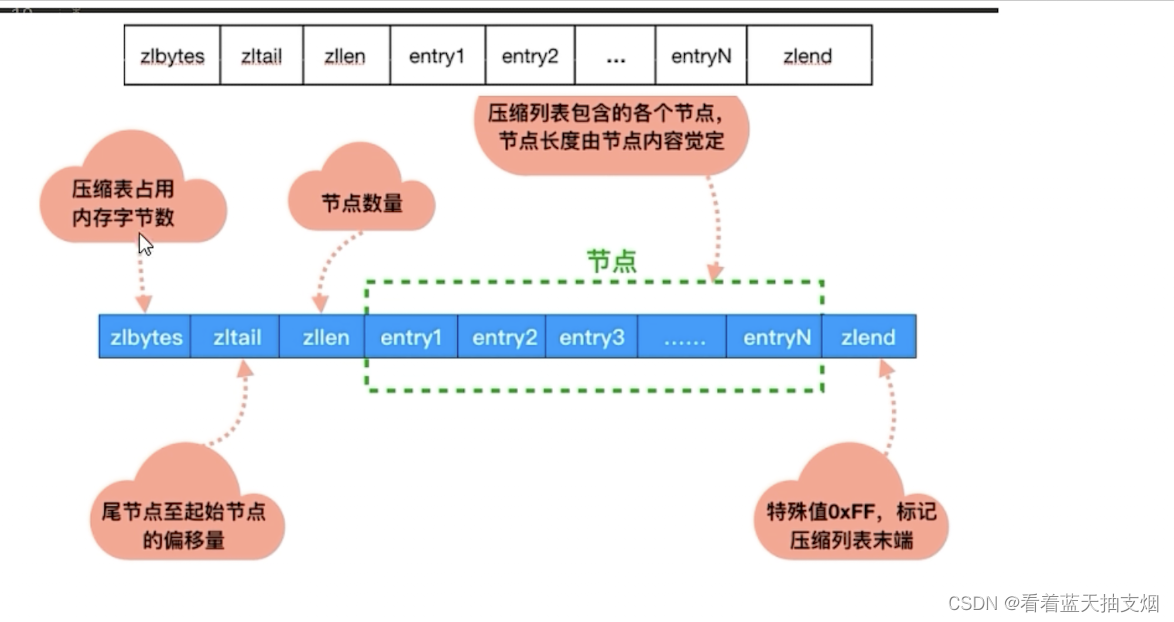
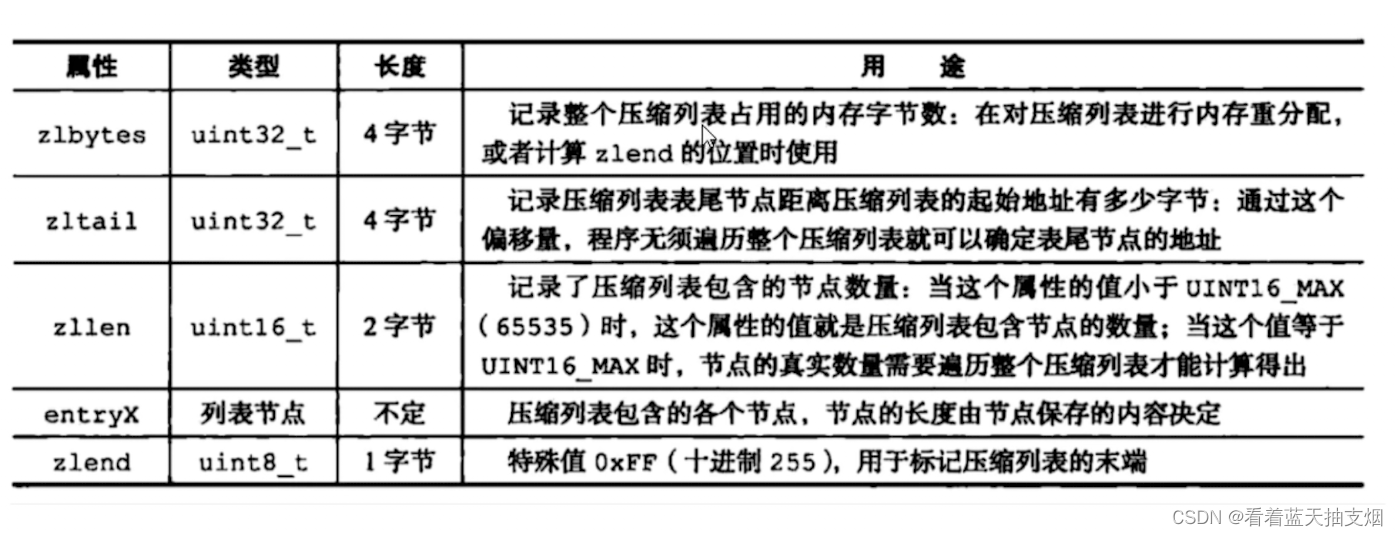
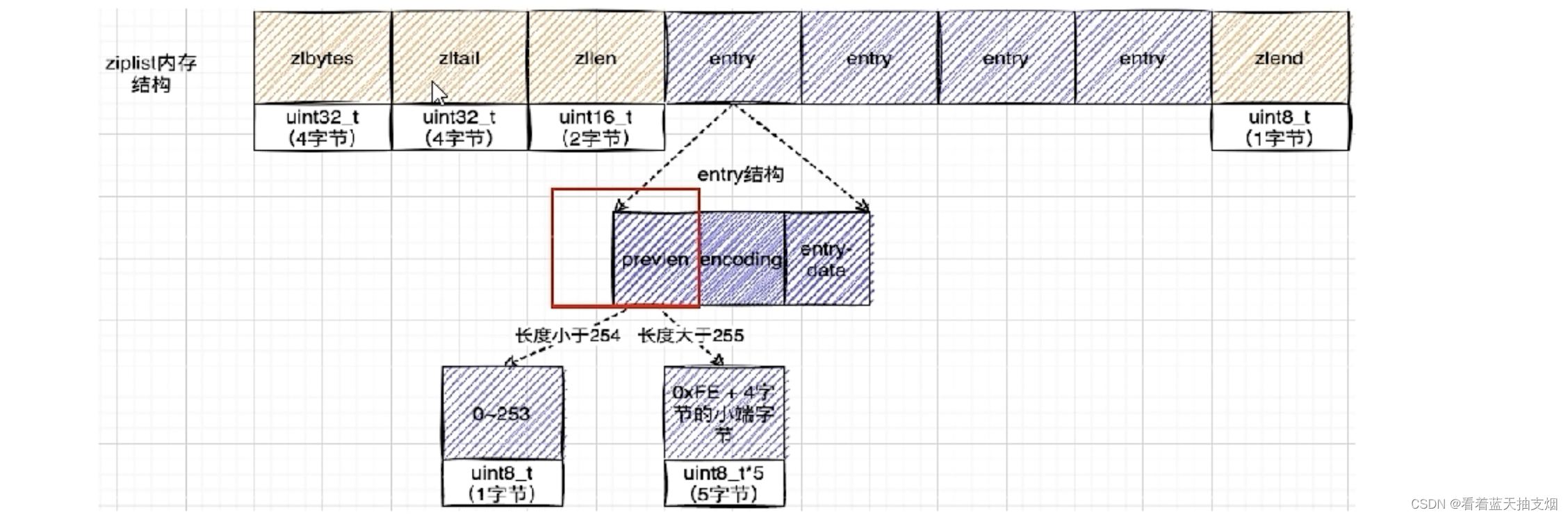
压缩列表zlentry 节点结构: 每个zlenrty由前一个节点的长度,encoding和entry-data三部分组成
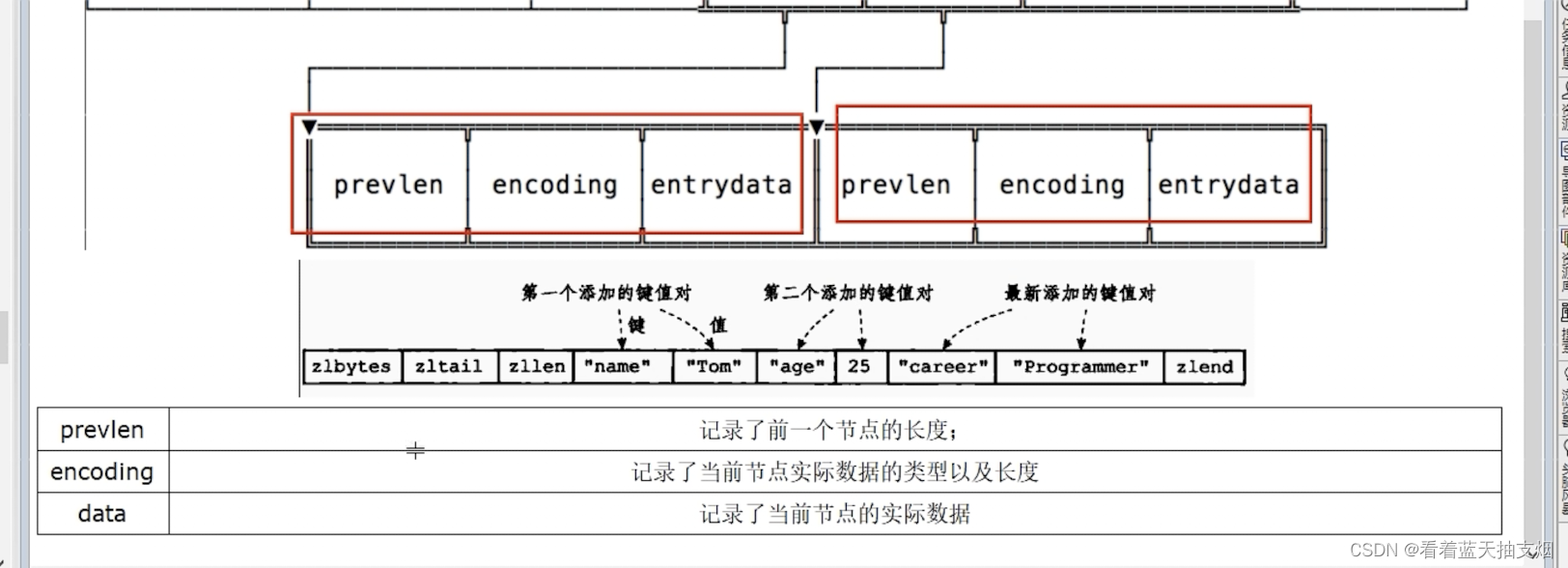
前节点: (前节点占用的内存字节数)表示前1个zlentry的长度,privious_entry_lengthy有两种取值情况: 1字节和5字节。取值1字节时,表示上一个entry的长度小于254字节。虽然1字节的值能表示0到255,但是压缩列表中zlend到的取值默认时255,因此就默认使用255表示整个压缩列表的结束,其他表示疮毒的地方就不能使用255这个值了。所以上一个长度小于等于254字节时,pre_len取值为1字节,否则为5字节。记录长度的好处:暂用内存小,1或者5个字节
encoding:记录节点的context保存的类型和context的长度
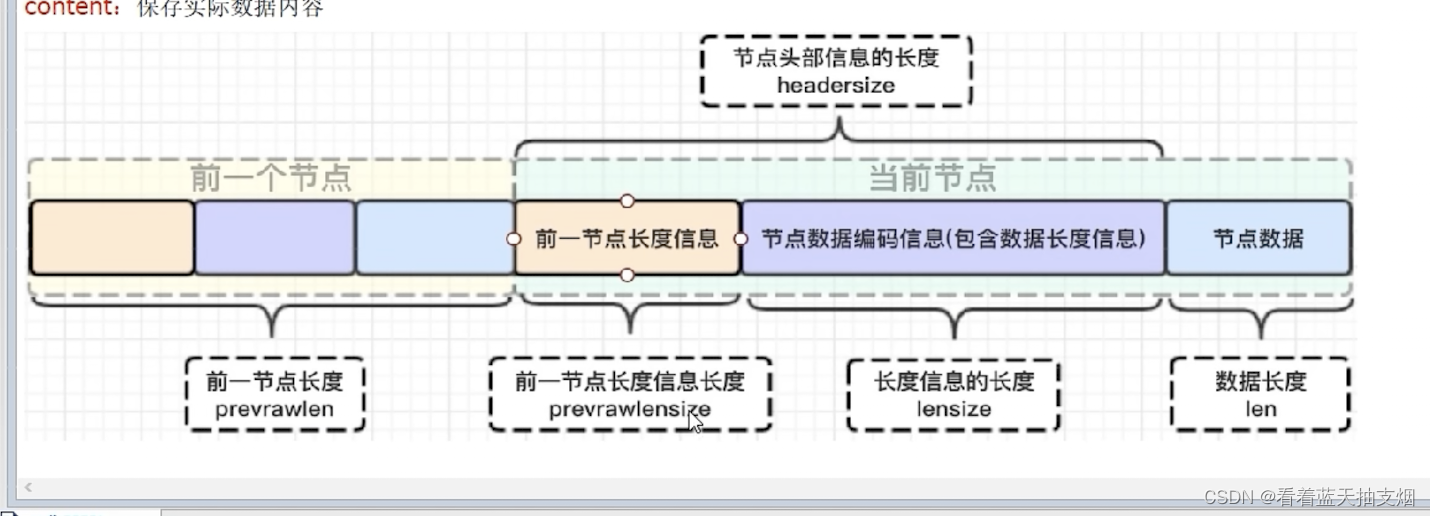
zlentry 为什么要这么设计?
privious_entry_length,encoding长度都可以根据编码方式推算,正在变化的是context,而context长度记录在encoding里,因此entry的长度就知道了
entry的总长度= privious_entry_length字节数+encoding字节数+context字节数。
链表在内存中,一般是不连续的,遍历相对比较慢,而zipList可以很好的解决这个问题。如果知道当前的起始地址,因为entry是连续的,entry后一定是另一个entry,想知道下一个entry的地址,只要将当前的起始地址加上当前entry的总长度。如果还想知道下一个enrty,则继续上一步的操作。


结构
hash-max-ziplist-entries: 使用压缩列表保存时哈希集合中的最大元素个数
hash-max-ziplist-value: 使用压缩列表保存时哈希集合中单个元素的最大长度。
结论
1.哈希对象保存的键值对数量小于512个;
2.所有的键值对的键和值的字符串长度都小于等于64byte(一个英文字符一个字节,一个数字一个字节)
3. ziplist 升级到hash table 可以,hashtable变为ziplist不可用,在节省内存空间方面hashtable没有zi plist高效

![深度学习进阶篇[7]:Transformer模型长输入序列、广义注意力、FAVOR+快速注意力、蛋白质序列建模实操。](https://img-blog.csdnimg.cn/img_convert/15d0de3275239031b89367901bf89247.jpeg)