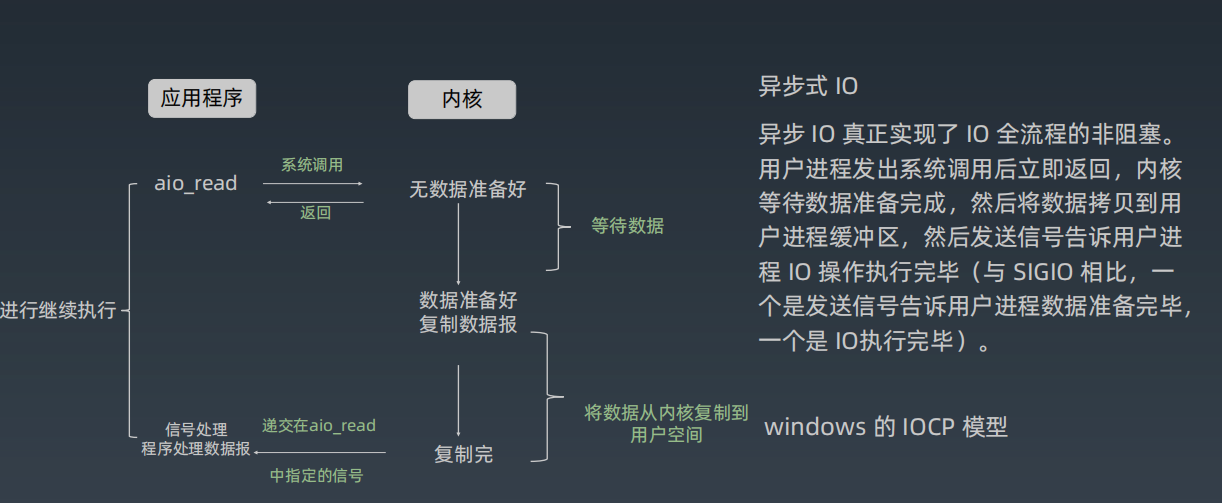
EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention

论文:https://arxiv.org/abs/2305.07027
代码:Cream/EfficientViT at main · microsoft/Cream · GitHub

🏆🏆🏆🏆🏆🏆Yolo轻量化模型🏆🏆🏆🏆🏆🏆
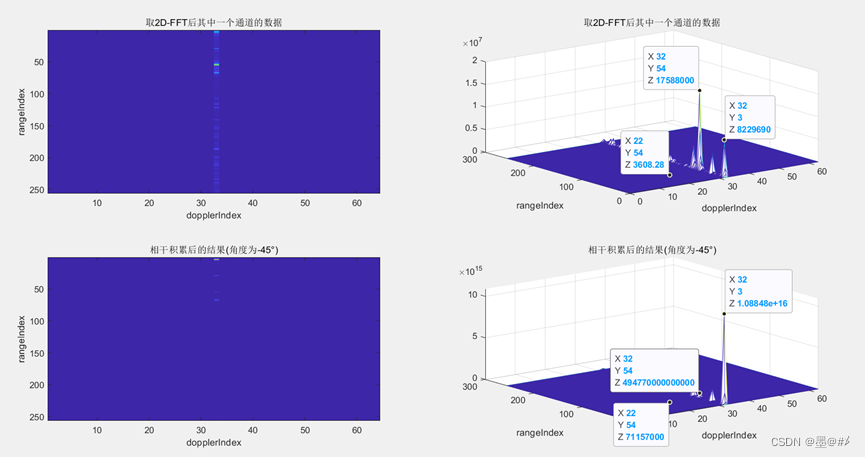
近些年对视觉Transformer模型(ViT)的深入研究,ViT的表达能力不断提升,并已经在大部分视觉基础任务 (分类,检测,分割等) 上实现了大幅度的性能突破。
然而,很多实际应用场景对模型实时推理的能力要求较高,但大部分轻量化ViT仍无法在多个部署场景