目录
1 Adam及优化器optimizer(Adam、SGD等)是如何选用的?
1)Momentum
2)RMSProp
3)Adam
2 Pytorch的使用以及Pytorch在以后学习工作中的应用场景。
1)Pytorch的使用
2)应用场景
3 不同的数据、数据集加载方式以及加载后各部分的调用处理方式。如DataLoder的使用、datasets内置数据集的使用。
4 如何加快训练速度以及减少GPU显存占用
技巧1:inplace=True
技巧2:with torch.no_grad():
技巧3:forward中的变量命名
技巧4:Dataloader数据读取
技巧5:gradient accumulation
1 Adam及优化器optimizer(Adam、SGD等)是如何选用的?
深度学习的优化算法主要有GD,SGD,Momentum,RMSProp和Adam算法。Adam是一种计算每个参数的自适应学习率的方法。相当于 RMSprop + Momentum。
在讲这个算法之前说一下移动指数加权平均。移动指数加权平均法加权就是根据同一个移动段内不同时间的数据对预测值的影响程度,分别给予不同的权数,然后再进行平均移动以预测未来值。假定给定一系列数据值 那么,我们根据这些数据来拟合一条曲线,所得的值
那么,我们根据这些数据来拟合一条曲线,所得的值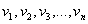 就是如下的公式:
就是如下的公式:
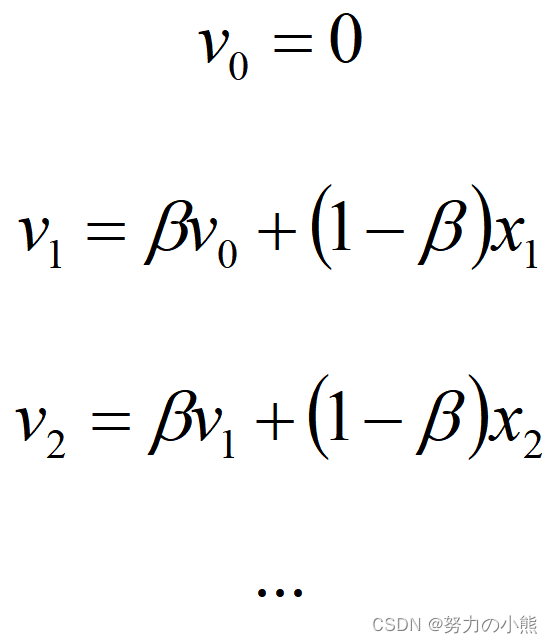
其中,在上面的公式中,β等于历史值的加权率。根据这个公式我们可以根据给定的数据,拟合出下图类似的一条比较平滑的曲线。

1)Momentum
通常情况我们在训练深度神经网络的时候把数据拆解成一小批地进行训练,这就是我们常用的mini-batch SGD训练算法,然而虽然这种算法能够带来很好的训练速度,但是在到达最优点的时候并不能够总是真正到达最优点,而是在最优点附近徘徊。另一个缺点就是这种算法需要我们挑选一个合适的学习率,当我们采用小的学习率的时候,会导致网络在训练的时候收敛太慢;当我们采用大的学习率的时候,会导致在训练过程中优化的幅度跳过函数的范围,也就是可能跳过最优点。我们所希望的仅仅是网络在优化的时候网络的损失函数有一个很好的收敛速度同时又不至于摆动幅度太大。
所以 Momentum 优化器刚好可以解决我们所面临的问题,它主要是基于梯度的移动指数加权平均。假设在当前的迭代步骤第 t 步中,那么基于 Momentum 优化算法可以写成下面的公式:
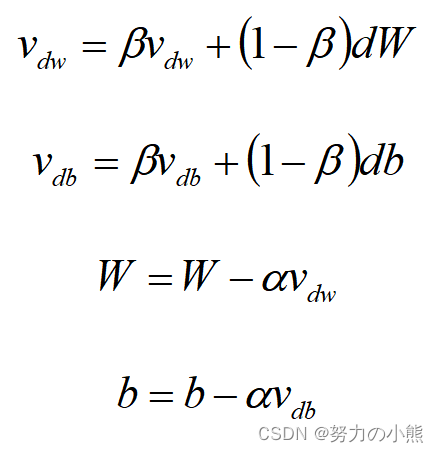
其中,在上面的公式中vdw和vdb分别是损失函数在前 t-1 轮迭代过程中累积的梯度动量,β是梯度累积的一个指数,这里我们一般设置值为0.9。所以Momentum优化器的主要思想就是利用了类似于移动指数加权平均的方法来对网络的参数进行平滑处理的,让梯度的摆动幅度变得更小。
dW和db分别是损失函数反向传播时候所求得的梯度,下面两个公式是网络权重向量和偏置向量的更新公式,α是网络的学习率。当我们使用Momentum优化算法的时候,可以解决mini-batch SGD优化算法更新幅度摆动大的问题,同时可以使得网络的收敛速度更快。
2)RMSProp
RMSProp算法的全称叫 Root Mean Square Prop,是Geoffrey E. Hinton在Coursera课程中提出的一种优化算法,在上面的Momentum优化算法中,虽然初步解决了优化中摆动幅度大的问题。所谓的摆动幅度就是在优化中经过更新之后参数的变化范围,如下图所示,蓝色的为Momentum优化算法所走的路线,绿色的为RMSProp优化算法所走的路线。

为了进一步优化损失函数在更新中存在摆动幅度过大的问题,并且进一步加快函数的收敛速度,RMSProp算法对权重 W 和偏置 b 的梯度使用了微分平方加权平均数。 其中,假设在第 t 轮迭代过程中,各个公式如下所示:
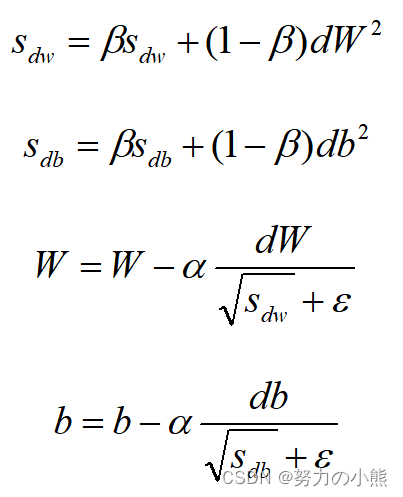
算法的主要思想就用上面的公式表达完毕了。在上面的公式中sdw和sdb分别是损失函数在前 t−1 轮迭代过程中累积的梯度动量,β是梯度累积的一个指数。所不同的是,RMSProp算法对梯度计算了微分平方加权平均数。这种做法有利于消除了摆动幅度大的方向,用来修正摆动幅度,使得各个维度的摆动幅度都较小。另一方面也使得网络函数收敛更快。(比如当 dW或者 db中有一个值比较大的时候,那么我们在更新权重或者偏置的时候除以它之前累积的梯度的平方根,这样就可以使得更新幅度变小)。为了防止分母为零,使用了一个很小的数值 来进行平滑,一般取值为10的负八次方。
来进行平滑,一般取值为10的负八次方。
3)Adam
有了上面两种优化算法,一种可以使用类似于物理中的动量来累积梯度,另一种可以使得收敛速度更快同时使得波动的幅度更小。那么将两种算法结合起来所取得的表现一定会更好。Adam(Adaptive Moment Estimation)算法是将Momentum算法和RMSProp算法结合起来使用的一种算法。
很多论文里都会用 SGD,没有 Momentum 等。SGD 虽然能达到极小值,但是比其他算法用的时间长,而且可能会被困在鞍点。
如果需要更快的收敛,或者是训练更深更复杂的神经网络,需要用一种自适应的算法。
整体来讲,Adam 是最好的选择。
2 Pytorch的使用以及Pytorch在以后学习工作中的应用场景。
1)Pytorch的使用
①安装pytorch
②使用Spyder 创建一个project,点击Projects--->New Project
创建一个project,点击Projects--->New Project
③在其中输入project名称,选择项目地址就ok了,比如我们创建Handwritten_numeral_recognition(手写数字识别)

④创建一个module,创建一个test.py。


⑤输入import torch,就可以开始pytorch的使用了。

2)应用场景
①医疗

基于U-net的医学影像分割
通过Pytorch深度学习框架,编写分割脑部解剖结构程序。
②工业
比如通过Pytorch深度学习框架,编写设备的剩余寿命预测、故障诊断程序。
3 不同的数据、数据集加载方式以及加载后各部分的调用处理方式。如DataLoder的使用、datasets内置数据集的使用。
- dataloader本质是一个可迭代对象,使用iter()访问,不能使用next()访问;
- 使用iter(dataloader)返回的是一个迭代器,然后可以使用next访问;
- 也可以使用`for inputs, labels in dataloaders`进行可迭代对象的访问;
- 一般我们实现一个datasets对象,传入到dataloader中;然后内部使用yeild返回每一次batch的数据;
pytorch 的数据加载到模型的操作顺序是这样的:
① 创建一个 Dataset 对象
② 创建一个 DataLoader 对象
③ 循环这个 DataLoader 对象,将img, label加载到模型中进行训练
dataset = MyDataset()
dataloader = DataLoader(dataset)
num_epoches = 100
for epoch in range(num_epoches):
for img, label in dataloader:
....所以,作为直接对数据进入模型中的关键一步, DataLoader非常重要。
4 如何加快训练速度以及减少GPU显存占用
到底什么在占用显存?
输入的数据占用空间其实并不大,比如一个(256, 3, 100, 100)的Tensor(相当于batchsize=256的100*100的三通道图片。)只占用31M显存。
实际上,占用显存的大头在于:1. 动辄上千万的模型参数;2. 模型中间变量;3. 优化器中间参数。
第一点模型参数不必介绍;第二点,中间变量指每个语句的输出。而在backward时,这部分中间变量会翻倍(因为需要保留原中间值)。第三点,优化器在梯度下降时,模型参数在更新时会产生保存中间变量,也就是模型的params在这时翻倍。
技巧1:inplace=True
一些激活函数与Dropout有一个参数"inplace",默认设置为False,当设置为True时,我们在通过ReLU()计算时得到的新值不会占用新的空间而是直接覆盖原来的值,这也就是为什么当inplace参数设置为True时可以节省一部分内存的缘故。但在某些需要原先的值的情况下,就不可设置inplace。
此操作相当于针对显存占用第二点(模型中间变量)的优化。
技巧2:with torch.no_grad():
对于只需要forward而不需要backward的过程(validation和test),使用torch.no_grad做上下文管理器(注意要在model.eval()之后),可以让测试时batchsize扩大近十倍,而且也可以加速测试过程。此操作相当于针对显存占用第二点(因为直接没有backward了)和第三点进行优化。
model.eval()
with torch.no_grad():
pass技巧3:forward中的变量命名
在研究pytorch官方架构和大神的代码后可发现大部分的forward都是以x=self.conv(x)的形式,很少引入新的变量,所以启发两点以减少显存占用(1)把不需要的变量都用x代替,(2)变量用完之后马上用del删除(此操作慎用,清除显存的同时使得backProp速度变慢)。此操作相当于针对第二点(模型中间变量)进行优化。
技巧4:Dataloader数据读取
一定要使用pytorch的Dataloader来读取数据。按照以下方式来设置:
loader = data.Dataloader(PYTORCH_DATASET, num_works=CPU_COUNT,
pin_memory=True, drop_last=True)第一个参数是用pytorch制作的TensorDataset,第二个参数是CPU的数量(默认为0,在真正训练时建议调整),第三个参数默认为False,用来控制是否把数据先加载到缓存再加载到GPU,建议设置为True,第四个参数用于扔掉最后一个batch,使得训练更为稳定。
将pin_memory开启后,在通过dataloader读取数据后将数据to进GPU时把non_blocking设置为True,可以大幅度加快数据计算的速度。
for input_tensor in loader:
input_tensor.to(gpu, non_blocking=True)
model.forward(input_tensor)技巧5:gradient accumulation
梯度积累通过累计梯度来解决本地显存不足的问题,即不在每个batch都更新模型参数,而是每经过accumulation steps步后,更新一次模型参数。相当于针对第三点(n步才更新一次参数)来进行优化。且由于参数更新的梯度计算是算力消耗的一部分,故梯度累计还可以一定程度上加快训练速度。
loss = model(input_tensor)
loss.backward()
if batch_idx % accumulate_steps == 0:
optim.step()
optim.zero_grad()相当于一个epoch的步数(step)变少了(一个step相当于参数更新一次),但单个step的计算时间变长了(略小于n倍的原来时间)。