利用pytorch构建LSTM预测股票收益率详细教程
- 1. 整体实现思路
- 2.代码编写
- 2.1 step1:导入所需的库
- 2.2 step2: 读取数据、构建训练样本
- 2.3 step3: 定义部分辅助函数
- 2.4 step4:LSTM模型构建
- 2.5 step5:模型训练
- 2.6 step6:模型预测和评估
- 3. 小结
1. 整体实现思路
step1:导入所需的库
- torch:用于构建神经网络和进行模型训练
- torch.nn:包含用于构建神经网络的类和函数
- numpy:用于数据处理和数组操作
- pandas:用于数据读取和处理
- matplotlib.pyplot:用于数据可视化
- sklearn:用于数据预处理和评估模型性能
- torchviz:用于绘制动态计算图
step2:读取数据、构建训练样本
- 从文件中读取股票收益率数据
- 进行必要的数据预处理,如时间序列排序和数据划分
- 定义一个函数,将收益率序列转换为训练样本
- 使用滑动窗口方法,将收益率序列划分为输入特征和目标值
- 将输入特征和目标值转换为PyTorch张量
step3:定义部分辅助函数
- 定义模型动态计算图绘制函数
- 定义时序数据序列化处理函数
step4:LSTM模型构建
- 定义一个LSTM类,继承自torch.nn.Module
- 在构造函数中定义LSTM层和全连接层
- 实现forward方法,定义前向传播过程
step5:模型训练
- 设置超参数,包括隐藏层大小、学习率、迭代次数等
- 创建LSTM模型实例、损失函数和优化器
- 迭代训练模型,计算损失并进行反向传播更新模型参数
- 记录训练过程中的损失值,并绘制损失变化的折线图
- 绘制模型动态计算图并保存为png
step6:模型预测和评估
- 使用训练好的模型对测试数据进行预测
- 计算预测结果与实际值之间的均方误差(MSE)
- 保存预测结果与真实值到指定文件中
- 可视化预测结果和实际值的对比
下面对各个步骤进行详细的code编写和实现。
2.代码编写
2.1 step1:导入所需的库
import torch
import torch.nn as nn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from torchviz import make_dot
# 设置随机种子
seed = 1234
torch.manual_seed(seed)
np.random.seed(seed)
2.2 step2: 读取数据、构建训练样本
601318.csv数据下载
# 导入数据
df = pd.read_csv('./data/601318.csv')
df['trade_date'] = pd.to_datetime(df['trade_date'], format='%Y%m%d')
df.set_index('trade_date', inplace=True)
df.sort_index(inplace=True)
pct_chg = df['pct_chg'].values.astype(float)
# 定义训练集和测试集的比例
train_ratio = 0.8
train_size = int(len(pct_chg) * train_ratio)
# 划分数据集
train_data = pct_chg[:train_size]
test_data = pct_chg[train_size:]
#查看数据基本特征
print(df[['pct_chg']].describe())
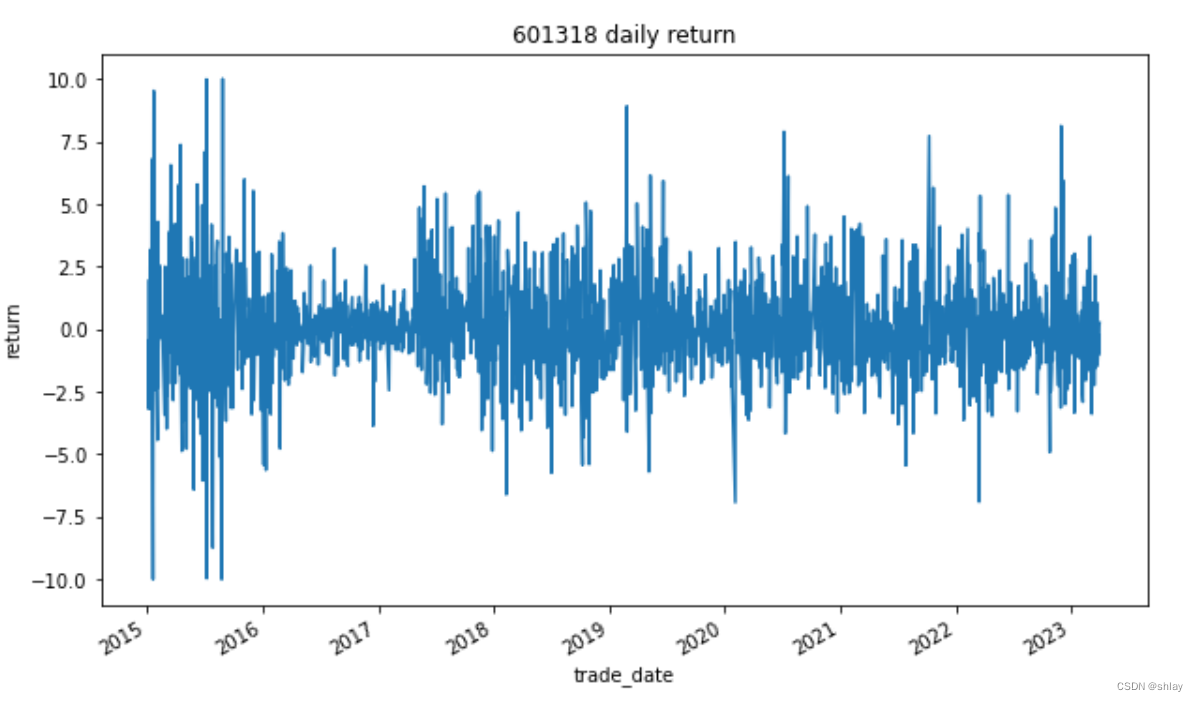
# 绘制收益率曲线
df['pct_chg'].plot(figsize=(10,6))
plt.title('601318 daily return')
plt.xlabel('trade_date')
plt.ylabel('return')
plt.show()
输出:
pct_chg
count 2006.000000
mean 0.038926
std 1.907410
min -10.000000
25% -0.974750
50% -0.030000
75% 0.913225
max 10.020000
2.3 step3: 定义部分辅助函数
记得在自己代码的同级目录下创建一个名为result的文件夹用于保存相关的结果和可视化图
# 生成训练样本
def generate_samples(data, sequence_length):
X = []
y = []
for i in range(len(data) - sequence_length):
X.append(data[i:i+sequence_length])
y.append(data[i+sequence_length])
return torch.tensor(X).unsqueeze(2), torch.tensor(y).unsqueeze(1)
# 使用torchviz生成动态计算图
def save_model_graph(model, input_size, hidden_size, output_size):
# 创建一个随机输入张量
example_input = torch.randn(1, input_size)
dot = make_dot(model(example_input), params=dict(model.named_parameters()))
# 保存计算图为图片
dot.render('./result/lstm_model_graph', format='png')
print("模型的动态计算图已保存为LSTM_Model_graph.png")
2.4 step4:LSTM模型构建
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(LSTM, self).__init__()
self.hidden_size = hidden_size
self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.lstm(x)
out = self.fc(out[:, -1, :])
return out
2.5 step5:模型训练
# 设置超参数和其他参数
input_size = 1
hidden_size = 32
output_size = 1
sequence_length = 10
num_epochs = 5000
learning_rate = 0.0003
batch_size = 100
patience = 20
best_loss = float('inf')
early_stop_counter = 0
# 创建模型实例
model = LSTM(input_size, hidden_size, output_size)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 将训练数据转换为样本
train_input, train_target = generate_samples(train_data, sequence_length)
train_input = train_input.float()
train_target = train_target.float()
train_data_size = len(train_input)
loss_history = []
# 开始训练
for epoch in range(num_epochs):
model.train()
total_loss = 0
for batch_start in range(0, train_data_size, batch_size):
batch_end = batch_start + batch_size
if batch_end > train_data_size:
batch_end = train_data_size
batch_input = train_input[batch_start:batch_end]
batch_target = train_target[batch_start:batch_end]
outputs = model(batch_input)
loss = criterion(outputs, batch_target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / (train_data_size // batch_size)
loss_history.append(avg_loss)
# 更新最佳损失值并进行early-stop判断
if avg_loss < best_loss:
best_loss = avg_loss
early_stop_counter = 0
else:
early_stop_counter += 1
if early_stop_counter >= patience:
print(f'Early stopping at epoch {epoch+1}')
break
# 每隔100个epoch 打印一次当前的loss
if (epoch + 1) % 100 == 0:
print(f'Epoch: {epoch + 1}/{num_epochs}, Loss: {avg_loss}')
# 保存模型
torch.save(model.state_dict(), f'./result/lstm_model_{num_epochs}.pth')
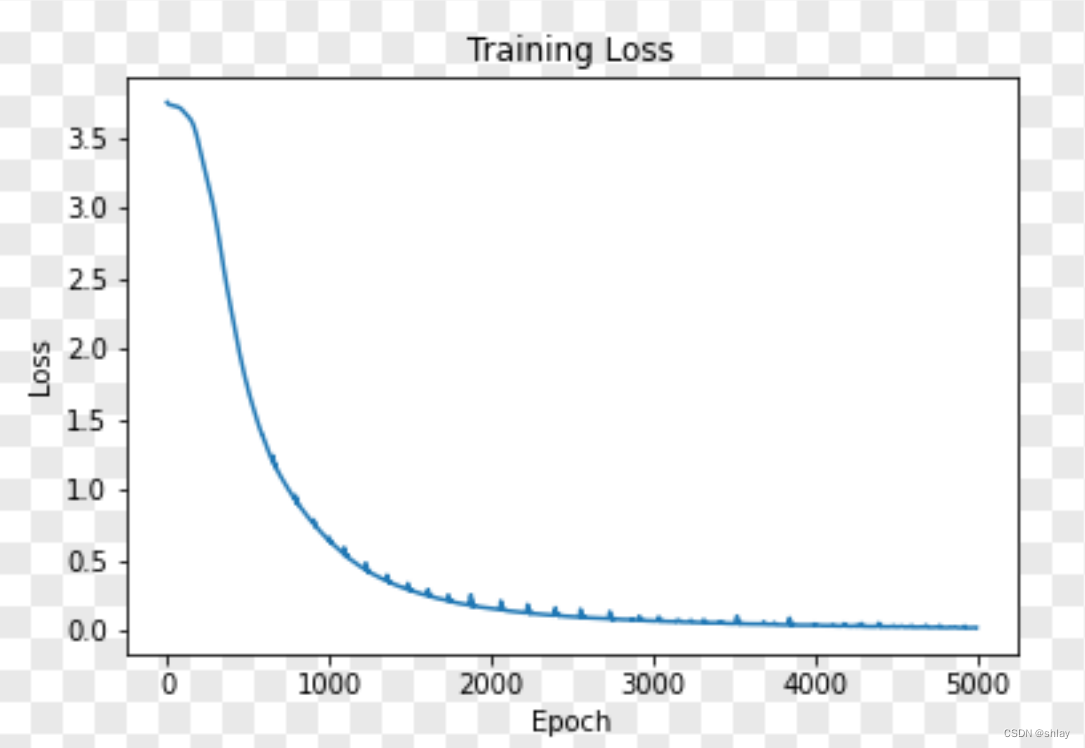
# 绘制损失值变化的折线图
plt.plot(figsize=(12,6))
plt.plot(loss_history)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title(f'Training Loss (epochs={num_epochs})')
plt.savefig('./result/loss_plot.png')
plt.show()
# 绘制动态计算图并保存为图片
inputs = torch.tensor(train_input, dtype=torch.float32)
dot = make_dot(model(inputs), params=dict(model.named_parameters()))
dot.render('./result/LSTM_dynamic_graph', format='png')
2.6 step6:模型预测和评估
# 加载模型
model.load_state_dict(torch.load(f'./result/lstm_model_{num_epochs}.pth'))
# 测试集数据转换为张量
test_input, test_target = generate_samples(test_data, sequence_length)
test_input = test_input.float()
test_target = test_target.float()
# 关闭梯度追踪
with torch.no_grad():
model.eval()
# 进行预测
predicted = model(test_input)
# 计算均方误差
mse = criterion(predicted, test_target[-1].view(-1, 1, 1))
print(f'Test MSE: {mse.item():.4f}')
# 可视化预测结果
predicted = predicted.view(-1).numpy()
# 保存测试集的真实值和预测值到csv
test_result = pd.DataFrame({'actual':pct_chg[train_size+ sequence_length:], 'predicted': predicted})
test_result.to_csv(f'./result/test_result{num_epochs}.csv', index=False)
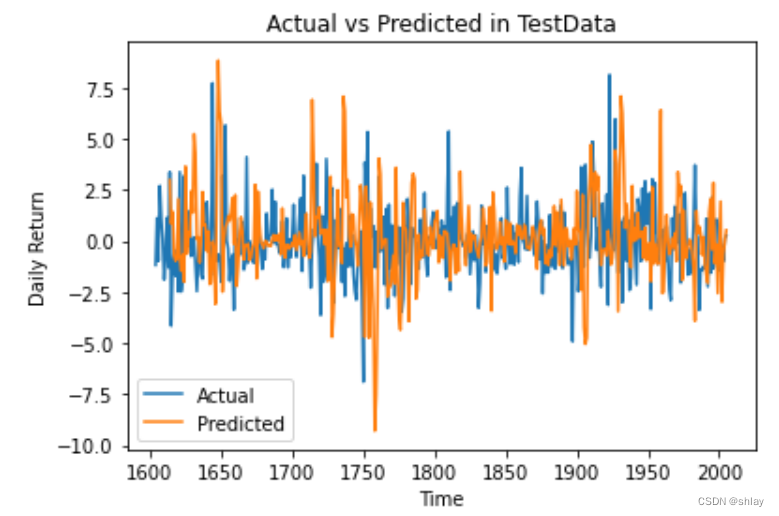
# 绘制预测结果
plt.plot(figsize=(12,6))
plt.plot(range(train_size, len(pct_chg)), pct_chg[train_size:], label='Actual')
plt.plot(range(train_size + sequence_length, len(pct_chg)), predicted, label='Predicted')
plt.xlabel('Time')
plt.ylabel('Daily Return')
plt.title('Actual vs Predicted in TestData')
plt.legend()
plt.savefig(f'./result/test_prediction_plot{num_epochs}.png')
plt.show()
3. 小结
完整代码LSTM_ReturnPrediction.py下载
思考如何将完整代码模块化,并在命令行窗口运行含参数设置的py文件
1. 总结模型的性能和训练过程中的变化:
- 1.可在不设置early_stop条件时,设置不同的训练次数num_epochs,分析训练过程中损失函数的变化情况,观察是否存在收敛和过拟合的现象。
- 2.可设置不同的学习率,观察模型的训练速度以及最优的迭代次数。
- 3.可比较预测结果与实际值之间的均方误差(MSE),评估模型在测试集上的预测性能。
- 4.可以绘制预测结果与实际值之间的对比图,以直观了解模型的预测效果。
2. 探讨可能的改进方法:
- 1.调整模型结构:
- 增加/减少LSTM层的数量,改变隐藏层的大小。
- 尝试不同的激活函数,如ReLU、Tanh等。
- 添加正则化技术,如Dropout层,以防止过拟合。
- 2.超参数调优:
- 对学习率、迭代次数、滑动窗口大小等超参数进行调优,以提高模型性能。
- 可以使用网格搜索或随机搜索等方法来搜索最佳超参数组合。
- 3.数据预处理和特征工程:
- 考虑对输入数据进行更复杂的特征工程,如技术指标的计算或时间序列的平滑处理。
- 尝试不同的数据标准化或归一化方法,以改善模型的训练效果。
- 4.模型集成:
- 考虑使用模型集成方法,如投票、堆叠等,结合多个不同的LSTM模型,以提高预测性能和鲁棒性。
通过以上改进方法的尝试和实验,可以进一步提升模型的性能和泛化能力。在实践中,可以进行多次迭代和实验,根据实际情况进行调整和优化,以获得更好的预测结果。尝试优化模型以提高预测精度~~~