文章目录
- 前言
- 一、IMDB-WIKI人脸数据集
- 二、WiderFace人脸检测数据集
- 三、GENKI 人脸图像数据集
- 四、哥伦比亚大学公众人物脸部数据库
- 五、CelebA人脸数据集
- 六、美国国防部人脸库
- 七、MTFL人脸识别数据集
- 八、BioID人脸数据集
- 九、PersonID人脸识别数据集
- 十、CMU PIE人脸库
- 十一、Youtube视频人脸数据集
- 十二、CASIA 人脸图像数据集
- 十三、Caltech人脸数据库
前言
数据集对应应用场景,不同的应用场景有不同的检测难点以及对应改进方法,本系列整理汇总领域内的数据集,方便大家下载数据集。关注免费领取整理好的数据集资料!
一、IMDB-WIKI人脸数据集
IMDB-WIKI 500k+ 是一个包含名人人脸图像、年龄、性别的数据集,图像和年龄、性别信息从 IMDB 和 WiKi 网站抓取,总计 524230 张名人人脸图像及对应的年龄和性别。其中,获取自 IMDB 的 460723 张,获取自 WiKi 的 62328 张。
转换好格式数据集:关注后私信领取
下载链接【点此处即可下载
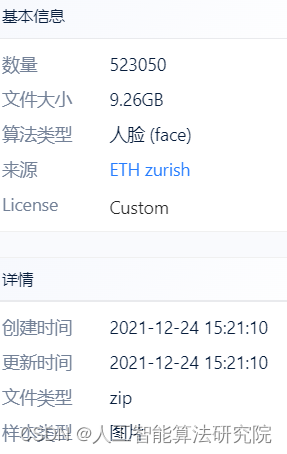
样图如下:

二、WiderFace人脸检测数据集
WIDER FACE数据集是人脸检测的一个benchmark数据集,包含32203图像,以及393,703个标注人脸,其中,158,989个标注人脸位于训练集,39,496个位于验证集。每一个子集都包含3个级别的检测难度:Easy,Medium,Hard。这些人脸在尺度,姿态,光照、表情、遮挡方面都有很大的变化范围。WIDER FACE选择的图像主要来源于公开数据集WIDER。制作者来自于香港中文大学,他们选择了WIDER的61个事件类别,对于每个类别,随机选择40%10%50%作为训练、验证、测试集。检测算法在测试集上的评估方式与PASCAL VOC DATADASET 相同,并且测试集的真值包围框(boundingbox)未发布。
转换好格式数据集:关注后私信领取
下载链接【点此处即可下载】

三、GENKI 人脸图像数据集
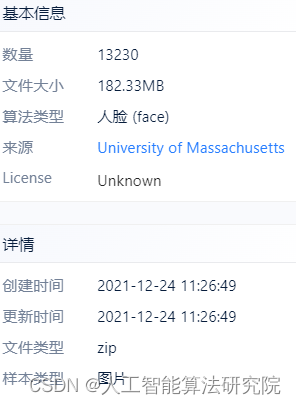
GENKI数据集是由加利福尼亚大学的机器概念实验室收集。该数据集包含GENKI-R2009a,GENKI-4K,GENKI-SZSL三个部分。GENKI-R2009a包含11159个图像,GENKI-4K包含4000个图像,分为“笑”和“不笑”两种,每个图片的人脸的尺度大小,姿势,光照变化,头的转动等都不一样,专门用于做笑脸识别。GENKI-SZSL包含3500个图像,这些图像包括广泛的背景,光照条件,地理位置,个人身份和种族等。
下载链接【点此处即可下载】
转换好格式数据集:关注后私信领取
四、哥伦比亚大学公众人物脸部数据库
PubFig数据库是一个大型的真实世界人脸数据集,由从互联网上收集的58797张200人的图像组成。与大多数其他现有的人脸数据集不同,这些图像是在完全不受控制的情况下与非合作对象拍摄的。因此,在姿势、照明、表情、场景、相机、成像条件和参数等方面存在很大差异。PubFig数据集与麻省大学阿默斯特分校(UMass Amherst)创建的野外标记人脸(LFW)数据集在本质上相似,尽管两者之间存在一些显著差异:
LFW包含12333张5749人的图像,因此比PubFig要宽得多。然而,它也更小、更浅(平均每人的图像更少)。
LFW来源于T.Berg等人的《新闻工作》中的名字和面孔。这些图像最初是通过在线新闻来源收集的。对于许多人来说,在同一个活动中,经常会有几张照片,照片中的人穿着相似的衣服,在相同的环境中。我们在ICCV 2009上的论文表明,算法经常可以利用这一点来提高表演的真实性。
下载链接【点此处即可下载】

五、CelebA人脸数据集
CelebFaces Attributes Dataset (CelebA) 是一个大规模的人脸属性数据集,包含超过 20 万张名人图像,每张都有 40 个属性注释。 该数据集中的图像涵盖了较大的姿势变化和杂乱的背景。 CelebA 种类多、数量多、注释丰富,包括10,177 个身份,202,599 张人脸图像,以及5 个地标位置,每张图像 40 个二进制属性注释。
该数据集可用作以下计算机视觉任务的训练和测试集:人脸属性识别、人脸识别、人脸检测、地标(或人脸部分)定位以及人脸编辑与合成。
下载链接【点此处即可下载】

六、美国国防部人脸库
为促进人脸识别算法的研究和实用化,美国国防部的Counterdrug Technology Transfer Program(CTTP)发起了一个人脸识别技术(Face Recognition Technology 简称FERET)工程,它包括了一个通用人脸库以及通用测试标准。到1997年,它已经包含了1000多人的10000多张照片,每个人包括了不同表情,光照,姿态和年龄的照片。
下载链接【点此处即可下载】
转换好格式数据集:关注后私信领取
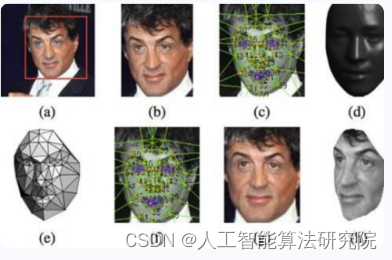
七、MTFL人脸识别数据集
该数据集包含 12,995 张人脸图像,这些图像用 (1) 五个面部标志,(2) 性别、微笑、戴眼镜和头部姿势的属性进行了注释。
下载链接【点此处即可下载】
转换好格式数据集:关注后私信领取

八、BioID人脸数据集
这个数据集包含了1521幅分辨率为384x286像素的灰度图像。 每一幅图像来自于23个不同的测试人员的正面角度的人脸。为了便于做比较,这个数据集也包含了对人脸图像对应的手工标注的人眼位置文件。 图像以 "BioID_xxxx.pgm"的格式命名,其中xxxx代表当前图像的索引(从0开始)。类似的,形如"BioID_xxxx.eye"的文件包含了对应图像中眼睛的位置。
下载链接【点此处即可下载】
转换好格式数据集:关注后私信领取

九、PersonID人脸识别数据集
该数据集所选用的人脸照片均来自于两部比较知名的电视剧,《吸血鬼猎人巴菲》和《生活大爆炸》。
下载链接【点此处即可下载】

十、CMU PIE人脸库
CMU PIE人脸库建立于2000年11月,它包括来自68个人的40000张照片,其中包括了每个人的13种姿态条件,43种光照条件和4种表情下的照片,现有的多姿态人脸识别的文献基本上都是在CMU PIE人脸库上测试的。
下载链接【点此处即可下载】

十一、Youtube视频人脸数据集
数据集介绍:
该数据集包含 1,595 个不同人的 3,425 个视频。 所有视频都是从 YouTube 下载的。 每个主题平均有 2.15 个视频可用。 最短剪辑时长为 48 帧,最长剪辑为 6070 帧,视频剪辑的平均长度为 181.3 帧。在这个数据集下,算法需要判断两段视频里面是不是同一个人。有不少在照片上有效的方法,在视频上未必有效/高效。
下载链接【点此处即可下载】

十二、CASIA 人脸图像数据集
该数据集包含1595个不同的人的3425个视频。所有视频都是从YouTube上下载的。每个主题平均有2.15个视频可用。最短的剪辑持续时间为48帧,最长的剪辑为6070帧,视频剪辑的平均长度为181.3帧。
下载链接【点此处即可下载】

十三、Caltech人脸数据库
该数据集包含通过在谷歌图像搜索中键入常见的名字从网络上收集的人物图像。每个正面的眼睛、鼻子和嘴巴中心的坐标都在地面真相文件中提供。该信息可用于对齐和裁剪人脸,或作为人脸检测算法的基本事实。该数据集具有10524张不同分辨率和不同设置的人脸,例如肖像图像、人群等。轮廓人脸或非常低分辨率的人脸没有标记。
下载链接【点此处即可下载】

未完待续。。。





![[附源码]计算机毕业设计学生宿舍维修管理系统Springboot程序](https://img-blog.csdnimg.cn/8bfb91b8347549a9800c15f93e85b049.png)



![[附源码]计算机毕业设计springboot疫情背景下社区互助服务系统](https://img-blog.csdnimg.cn/5d0b986ea7dc4d9c96730b6c4cf86597.png)