Pytorch入门系列大致会更5篇文章不到,以后有机会的话再细细更新吧,主要复习一下Pytorch基本知识,复习一下在大二入门Pytorch的学习笔记!原教程位于B站,讲的个人感觉蛮好的。
超级传送门,这个系列教程会很快速的让我们入门Pytorch,虽不能明白整个过程的原理,但可以明白深度学习训练的大致过程。
文章目录
- 一、数据对应关系
- 二、数据集的读取
- 三、两大法宝函数
- 四、编辑器对比
- 五、Tensorboard的使用
- 六、Transforms数据预处理
- 七、Torchvision官方数据集的使用
- 八、DataLoader的使用
一、数据对应关系
- ①标签标记在数据集所在的文件夹名
- ②标签以一定的格式掺杂在该类数据集的文件名中或者标记在图片内
- ③将数据与标签分开存放,设定一个数据文件夹,一个标签文件夹,同样的文件名(去除后缀)一个存数据,一个存标签
二、数据集的读取
- ①dataset
提供一种方式,获取数据集的label以及数据
如何获取每一个数据及其label
告诉我们一共有多少的数据 - ②dataloader
为后面的网络提供不同的数据形式
可以自己实现一个读取数据的类。(自定义的魔法函数与C++中的泛型编程运算符重载很相似)
# torch是pytorch框架的工具箱,utils是工具箱的一个常用的工具包,dataset就是那个工具
from torch.utils.data import Dataset
from PIL import Image
import os
#
class MyData(Dataset):
# 将数据集所在的文件夹上一级传进去,作为root_dir,数据集所在的文件夹名称作为label_dir
def __init__(self,root_dir,label_dir):
self.root_dir=root_dir
self.label_dir=label_dir
# 将数据集所在的路径进行完整的拼接存储到path属性中
self.path=os.path.join(self.root_dir,self.label_dir)
# 将数据集所在的文件路径传进去,读取出来所有的文件名称
self.img_path=os.listdir(self.path)
# 将文件名所处的位置传进去,idx为int型作为数组的下标
def __getitem__(self, idx):
# 获取数据的名称
img_name=self.img_path[idx]
# 将数据集所在的路径与数据文件名进行拼接
img_item_path=os.path.join(self.root_dir,self.label_dir,img_name)
# 从文件夹内读取文件
img=Image.open(img_item_path)
# 读取数据的标签
label=self.label_dir
# 返回出所读的数据
return img,label
def __len__(self):
return len(self.img_path)
# print(os.getcwd()+"../../数据集/练手数据集/train")
# print(os.path.split(os.getcwd())[0])
# C:\Users\123\Desktop\近期作业\机器学习\9.PyTorch框架(入门)
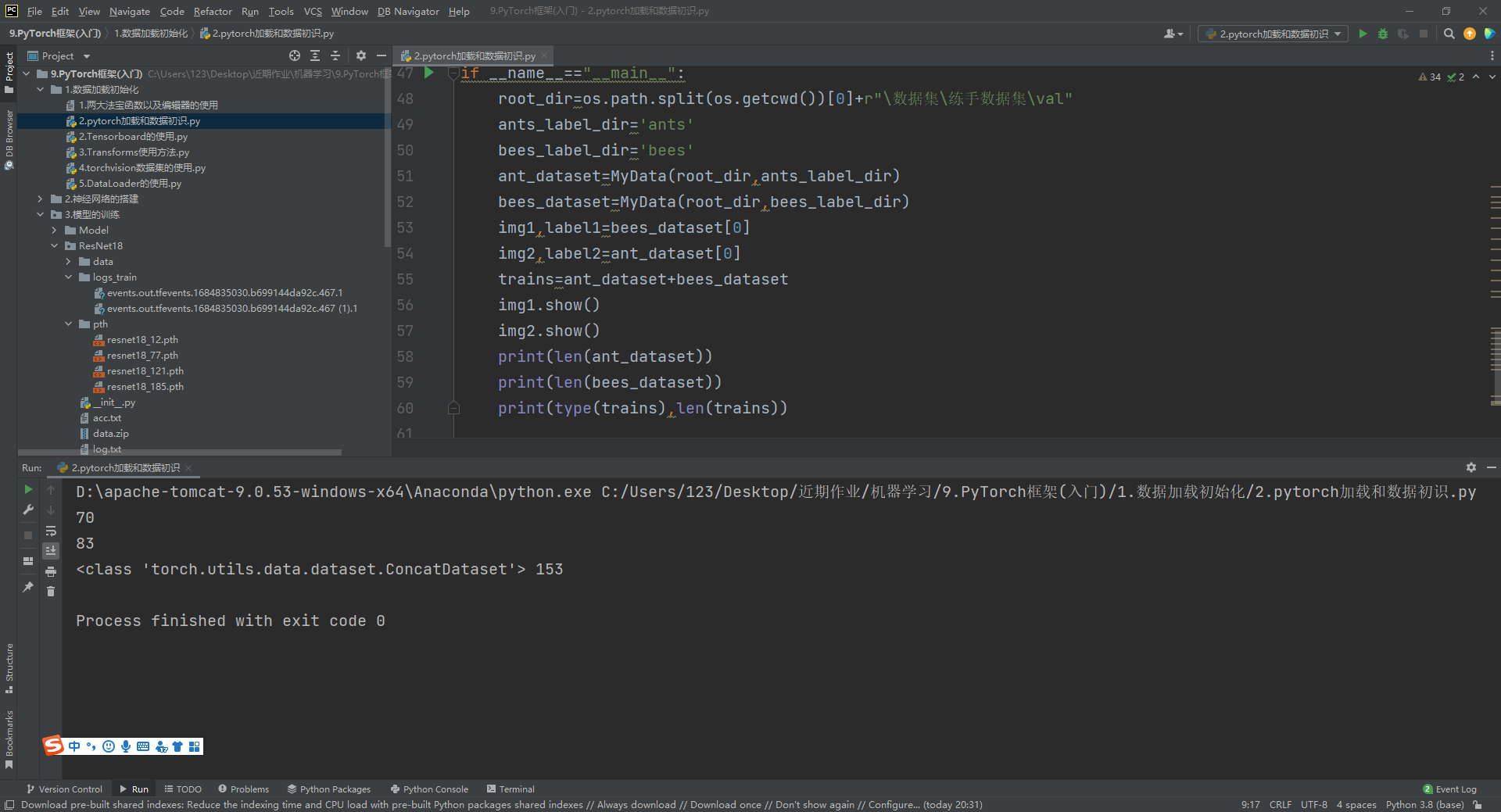
if __name__=="__main__":
root_dir=os.path.split(os.getcwd())[0]+r"\数据集\练手数据集\val"
ants_label_dir='ants'
bees_label_dir='bees'
ant_dataset=MyData(root_dir,ants_label_dir)
bees_dataset=MyData(root_dir,bees_label_dir)
img1,label1=bees_dataset[0]
img2,label2=ant_dataset[0]
trains=ant_dataset+bees_dataset
img1.show()
img2.show()
print(len(ant_dataset))
print(len(bees_dataset))
print(type(trains),len(trains))
三、两大法宝函数
pytorch是一个工具包,里面有别人写好的工具,工具太多自己不好调用怎么办呢?
- dir() :列出函数都有哪些,或者类下都有哪些函数与属性
- help() : 查看函数或者属性的使用方法
四、编辑器对比
- 1.pycharm: 集成开发python的环境,在其内部运行py文件时,会从文件头开始,依次向下执行(报错本次执行直接终止)
- 2.python自带的命令行: 可以分模块运行,但是运行起来之后出错较难修正(shift+回车进入多行编辑模式)
- 3.jupyter: 一个多功能的函数解释器,有自己的虚拟环境,支持文件的模块运行(报错之后也支持模块运行,除非程序崩溃)
缺点:各个模块有依赖性,必须一块一块的运行
五、Tensorboard的使用
TensorBoard是TensorFlow自带的一个强大的可视化工具,也是一个Web应用程序套件。TensorBoard目前支持7种可视化,Scalars,Images,Audio,Graphs,Distributions,Histograms和Embeddings。其中可视化的主要功能如下。
- (1)Scalars:展示训练过程中的准确率、损失值、权重/偏置的变化情况。
- (2)Images:展示训练过程中记录的图像。
- (3)Audio:展示训练过程中记录的音频。
- (4)Graphs:展示模型的数据流图,以及训练在各个设备上消耗的内存和时间。
- (5)Distributions:展示训练过程中记录的数据的分部图。
- (6)Histograms:展示训练过程中记录的数据的柱状图。
- (7)Embeddings:展示词向量后的投影分部。
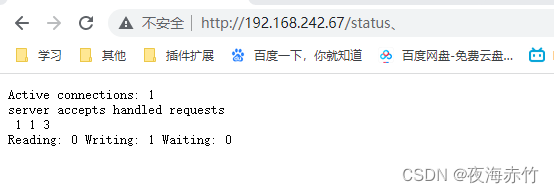
TensorBoard通过运行一个本地服务器,来监听6006端口。在浏览器发出请求时,分析训练时记录的数据,绘制训练过程中的图像。TensorBoard的可视化界面如下图所示
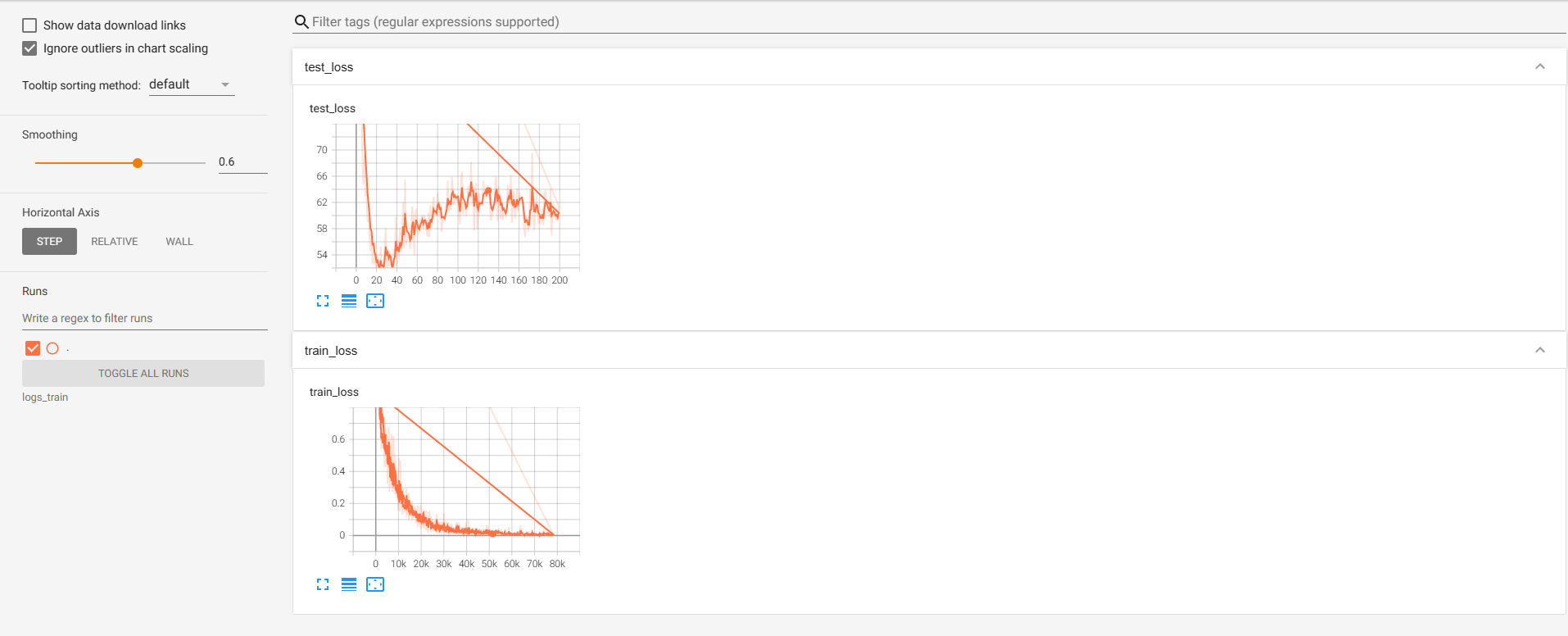
使用方法如下:
import os
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
# 指定检测日志存储的位置(可以指定如果不指定的话存进默认的路径)
# Default is runs/**CURRENT_DATETIME_HOSTNAME**,
# 项目基础路径
basepath=os.path.split(os.getcwd())[0]
# 将训练数据记录在项目基础路径下的\logss\logs文件夹内
writer = SummaryWriter(basepath+r'\logss\logs')
# add_scalar() 将数据加入到summary中
# 第一个参数是图表的标题
# 第二个参数是训练的数值(也就是y轴)
# 第三个参数是训练的多少步(也就是x轴)
for i in range(100):
writer.add_scalar('y=x',i,i)
print("成功将数据导入!")
# add_image()
# 第一个参数是标题,第二个是图片数据(可以是torch.tensor numpy.array string blobname)
# 将图片加入到观测到数据曲线中,用于检测每一步的数据变化,一旦数据有异常
# 可以找出异常数据的准确位置
img=Image.open(os.path.split(os.getcwd())[0]+r"\数据集\hymenoptera_data\train\ants\0013035.jpg")
# print(img)
img.show()
img=np.array(img)
writer.add_image("test",img,1,dataformats="HWC")
print("成功将图片导入!")
writer.close()
训练过程中产生的信息会存进指定的文件夹,命名格式如下:

我们可以通过下面命令查看训练过程是否符合现在的预期
tensorboard --logdir=logs_train

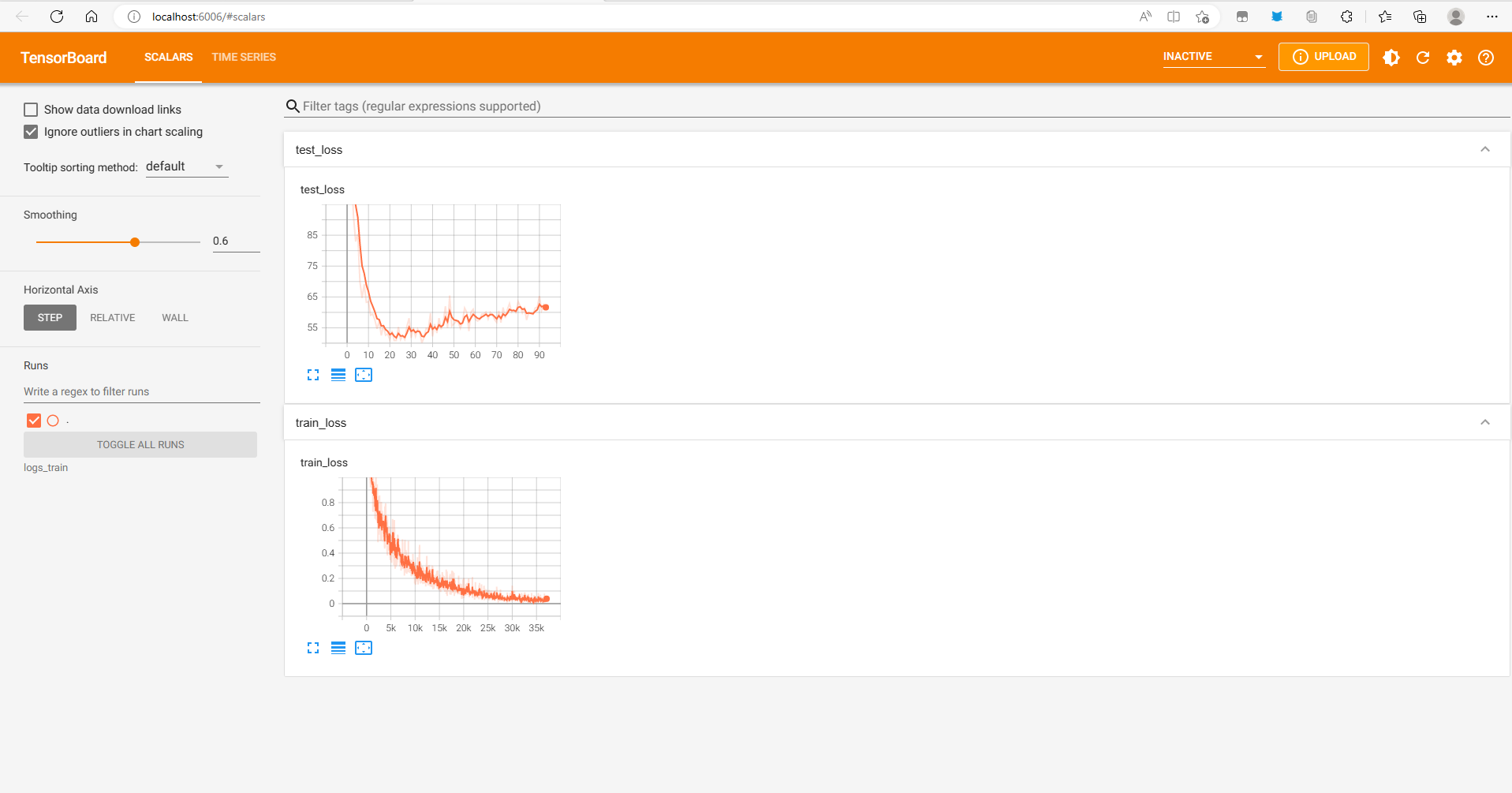
通常我们会记录以下信息:
writer.add_scalar("train_loss", loss.item(), total_train_step)
writer.add_scalar("train_acc", train_acc, total_train_step)
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_acc", test_acc, total_test_step)
六、Transforms数据预处理
transforms主要的作用就是对数据进行预处理,使数据的特征更加明显,totrnsor是将数据化成可以传入神经网络中的数据会在内部加入一些属性或者函数便于图片在神经网络中进行传播,而图片也作为totensor属性存在该类的对象中。
常用的数据转换方法:
- totensor //-------------将图像加入到tensor对象中
以下三种转换器必须是tensor数据类型的参数,得到的结果也是tensor数据类型,生成转换器时不需要将图像传进去,只需将转换所用的参数传进去即可,进行图像转换时将图像传到转换器的call函数,进行转换。
- transforms.Normalize() //-------------归一化
- transforms.resize() //-------------修改图像到指定的大小
- transforms.randomcrop() //-------------随机裁剪
# 读取一个图像
basepath=os.path.split(os.getcwd())[0]
img_path=basepath+r"\数据集\hymenoptera_data\train\ants\0013035.jpg"
img=Image.open(img_path)
# 转换为Tensor类型
trans_toten=transforms.ToTensor()
tensorimg=trans_toten(img)
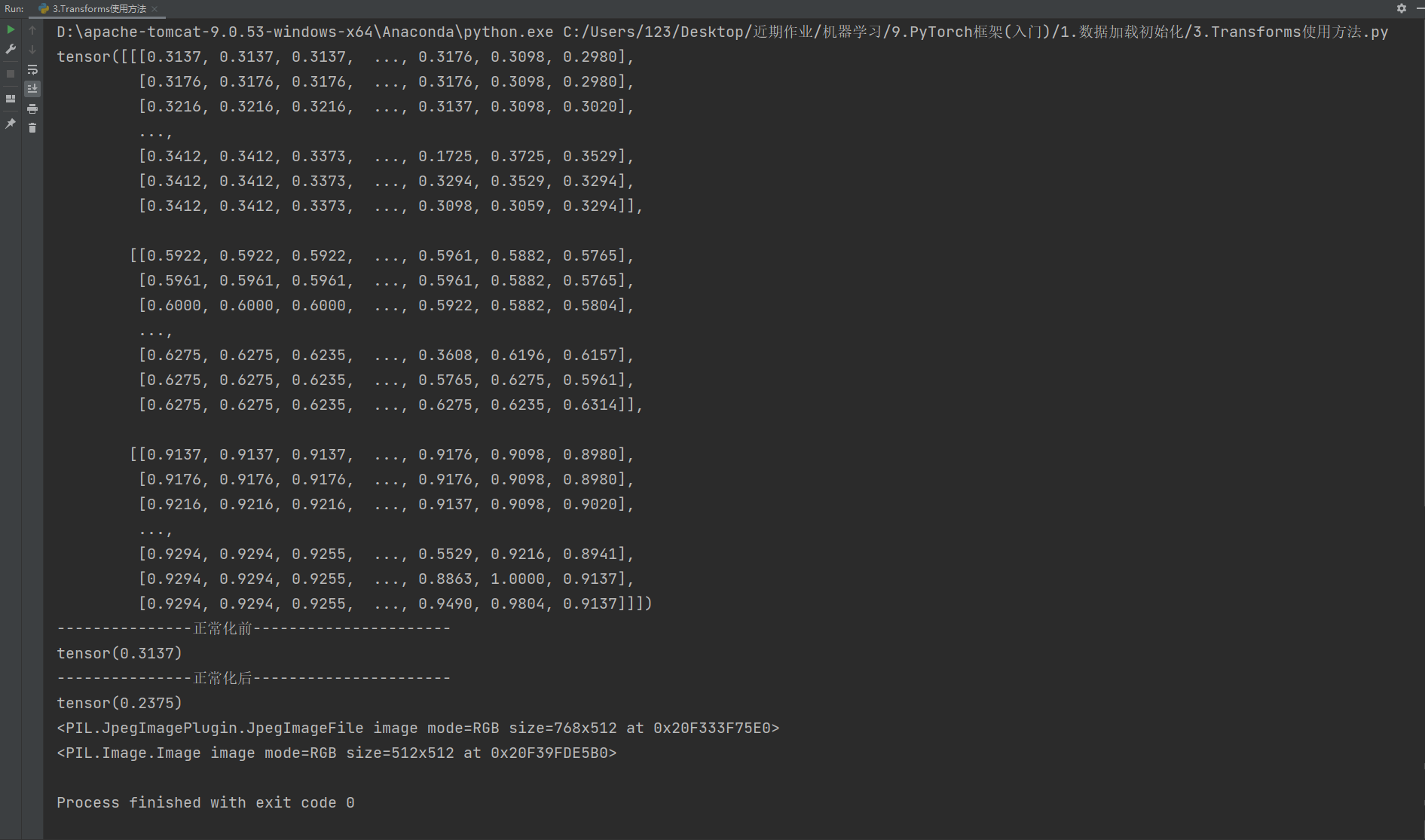
print(tensorimg)
print("---------------正常化前----------------------")
print(tensorimg[0][0][0])
trans_norm=transforms.Normalize([0.1,0.9,0.1],[0.9,0.1,0.9])
trans_img=trans_norm(tensorimg)
print("---------------正常化后----------------------")
print(trans_img[0][0][0])
# 修改大小
# 进去resize之前是PIL图像,出来之后依旧是PIL图像
trans_resize=transforms.Resize((512,512))
resize_img=trans_resize(img)
# 打印可知这两个图像的大小有所差异
print(img)
# img.show()
print(resize_img)
下面转换器可以执行多次图像的转换,构造转换器的时候,将需要进行转换的转换器列表传进去,工作原理是前一个转换器输出将作为后一个转换器的输入,是一种批处理方式类似于我们平时用的Docker Compose。
transforms.Compose()分步执行图像的转化
- 参数是一个列表,传进去的参数是transforms工具包生成的对象
- 前一个参数输出结果作为后一个参数的输入
生成转换器之后可以直接将PIL或者numpy数组传进去。使用方法如下:
# 定义一系列转换器
trans_toten=transforms.ToTensor()
trans_resize=transforms.Resize((512,512))
# 编排
trans_compose=transforms.Compose([trans_resize,trans_toten])
# 转换
compose_img=trans_compose(img)
这里可能会有疑问:
Tensor数据类型是什么
向神经网络中输送数据时不仅仅要进行数据的传入,还要有参数的传递,而Tensor数据类型中综合存储了常用的属性,使数据更适合神经网络。
Transform怎么使用
transform就是将numpy类型的数据或者PIL图像转换称为tensor数据类型
使用的原理是,通过transform.ToTensor()类模板生成一个tensor对象。
七、Torchvision官方数据集的使用
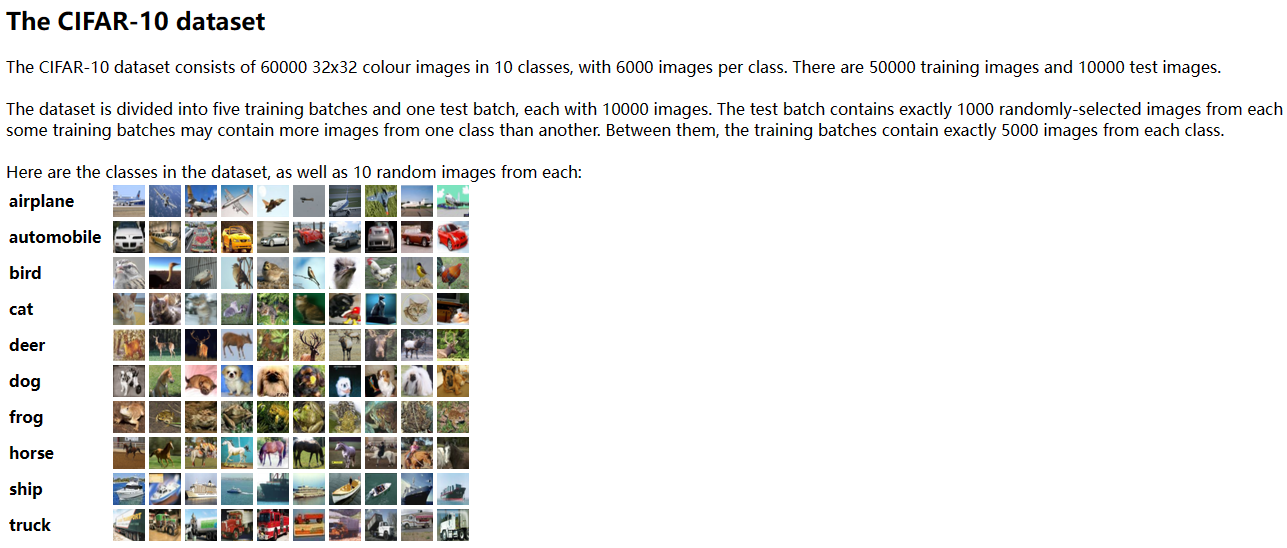
可以从下图看出Torchvision有许多自带的已经处理好的数据集,我们可以测试模型的时候使用。下面会以CIFAR10数据集来展开介绍应该如何使用。
train_set=torchvision.datasets.CIFAR10(root=basepath+r"\数据集",train=True,download=True,transform=trans_compose)
test_set=torchvision.datasets.CIFAR10(root=basepath+r"\数据集",train=False,download=True,transform=trans_compose)
torchvision.datasets.CIFAR10参数解释
- root指定存放数据集的目录
- train True代表训练集,False代表测试机,在CIFAR10数据集中大概有5000张训练集,1000张测试集
- download指的是如果指定的路径中没有需要的数据集就在网上下载,有的话就什么也不干
- transform可以指定图像的一系列变化可以是compose
整体加载torchvision.datasets.CIFAR10的代码:
import os
import torchvision
# 全局取消证书验证
# import ssl
# ssl._create_default_https_context = ssl._create_unverified_context
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
basepath=os.path.split(os.getcwd())[0]
# 编排好的数据集处理方式,一会加载数据集的时候使用。
trans_compose=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5])
])
train_set=torchvision.datasets.CIFAR10(root=basepath+r"\数据集",train=True,download=True,transform=trans_compose)
test_set=torchvision.datasets.CIFAR10(root=basepath+r"\数据集",train=False,download=True,transform=trans_compose)
# # 打印测试集中的第一个数据(获取到的时一个元组)
# print(test_set[0])
# # 打印测试集中有的数据类型
# print(test_set.classes)
# # 获取测试集第一个数据的数据与标签
# img,target=test_set[0]
# # 打印数据
# print(img)
# # 打印标签
# print(target)
# # 在类别中找到数据对应的类别
# print(test_set.classes[target])
# img.show()
writer=SummaryWriter(basepath+r'\logss\log1')
for i in range(10):
# 因为test_set存放的是所有图片信息以及数据集中每一张图片对应的类别还有一些其他配置
# 使用下标获取到的数据是一个元组,有图片数组有对应的类别
# 所以对图片操作时先将图片与类别获取出来,然后再将图片传进tensorboard中进行检测
img,target=test_set[i]
#使用Tensorboard查看数据集。
writer.add_image("test",img,i)
writer.close()
八、DataLoader的使用
DataLoader作用
DataSet作用是将数据以标签+图像的形式读取出来
DataLoader是对DataSet中的数据以一定的形式进行抽取输送到神经网络中
DataLoader主要参数
- dataset 数据与标签映射关系存放的对象
- batch_size 每次读取到的大小,也就是将多少图片进行打包一次性读取
- shuffle 读取完后下次读取是否重新排列顺序,True进行重新排列
- num_workers 多线程,0表示主线程
- drop_last 最后数据不够打包是否舍去(True进行舍去)
以下是一段使用DataLoader加载数据集的代码:
import os
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
basepath=os.path.split(os.getcwd())[0]
test_data=torchvision.datasets.CIFAR10(root=basepath+r"\数据集",train=False,transform=torchvision.transforms.ToTensor())
# 读取test_data每次读64张图片,读完重新打乱顺序,只使用主线程,删除不够打包的数据
test_loader=DataLoader(dataset=test_data,batch_size=64,shuffle=True,num_workers=0,drop_last=True)
# 探索一下test_loader中都有什么
print(test_loader)
writer=SummaryWriter(basepath+r"\logss\log2")
for test in range(2):
step=0
for data in test_loader:
imgs,targets=data
writer.add_images(f"test:{test}",imgs,step)
step=step+1
if test==0:
print(data)
print(imgs)
print(targets)
'''
会将打包好的图片以及他们对应的标签一块打印出来
'''
writer.close()