本篇文章梳理Java常用类--String类.
String类是非常重要的,也是面试的重灾区,一起加油啊~~
主要讲解String类 :
- String类的基础知识
- String类的特性
- String类的方法
- String,StringBuilder,StringBuffer之间的比较
- 字符串常量池
- String应用 : 到底创建了多少个对象
希望给您带来帮助~~~
目录
本篇文章梳理Java常用类--String类.
String类基础
介绍一下String类
String类的底层原理
String类底层
String类构造
String类能被继承吗,为什么。
Java 9 为何要将 String 的底层实现由 char[] 改成了 byte[] ?
HashMap使用String做key有什么好处
String a = "b" 底层原理是什么 ?
String 类型的变量和变量做“+”运算时发生了什么?/String 类型的变量和常量做“+”运算时发生了什么?
String 类型的常量和常量做“+”运算时发生了什么?
String s与 new String与有什么区别 ?
String s1 = new String("abc");这句话创建了几个字符串对象?
字符型常量和字符串常量的区别
在自己的代码中,如果创建一个java.lang.String类,这个类是否可以被类加载器加载?为什么?
字符串拼接的几种方式和区别
为什么不建议在循环体中使用+进行字符串拼接呢?/ '+' 拼接的实现原理是什么?
五种拼接字符串的方式效率比较
一个Java字符串中到底能有多少个字符?/String有没有长度限制 ?
String的equals() 和 Object的equals() 有何区别?
被final修饰的String会发生什么 ?
switch 是否能作用在 byte 上,是否能作用在 long 上,是否能作用在 String 上? 如果是那是怎么实现的呢 ?
String.valueOf和Integer.toString的区别
String的特性
不可变性
什么是不可变性 ?
String 为什么是不可变的?
String为什么设计成不可变的?
String设计成不可变的有什么好处?
如何设计成一个不可变类呢 ?
String s = "Hello";s = s + " world!";这两行代码执行后,原始的 String 对象中的内容是否会改变?
线程安全
String 是线程安全的么 ? String为什么是线程安全的 ?
String类的方法
String 类的常用方法都有那些呢?
intern方法
关于intern方法的面试题
substring方法
JDK6的substring会出现的问题
replace方法
如何比较两个字符串?
String,StringBuffer,StringBuilder比较
String,StringBuffer,StringBuilder比较
String,StringBuffer,StringBuilder 到底用哪个 ?
StringBuilder为什么线程不安全?
怎么让StringBuilder线程安全?
字符串拼接用“+” 还是 StringBuilder?
字符串常量池
字符串常量池的作用了解吗?
String类基础
介绍一下String类
- String是字符串类型, 是JDK内置的一个类 (Java.lang.String),提供了构造和管理字符串的各种基本逻辑, 在Java中,每个使用用双引号括起来的字符串都是String类的一个实例.
- String是引用类型,不是基本数据类型
- 字符串在实际的开发中使用太频繁,为了执行效率,所以把字符串放到了方法区的字符串常量池当中.-->凡是带双引号的都在字符串常量池当中有一份.
- String的特性 : String类是不可变类 , 也由于它的不可变性,类似拼接、裁剪字符串等动作,都会产生新的 String 对象. String是线程安全的
String类的底层原理
String类底层
根据JDK8
public final class String implements java.io.Serializable, Comparable<String>, CharSequence { /** String的底层数据结构是char value[] */ private final char value[]; /** Cache the hash code for the string */ private int hash; // Default to 0 ..... }
- String类被final修饰,不能有被子类继承.
- String类实现了Serilizable接口,可以序列化.
- String类实现Comparable接口,对字符串比较可以使用compareTo
- JDK8 String的底层是使用被private final修饰的char[]数组 value , JDK9以后就把char[]数组替换为了byte[]数组.
- 还会有一个hash值用于缓存字符串的hashcode(当我们首次调用
hashCode()方法时,会计算哈希值并将其存储在hash字段中。之后,每次调用hashCode()时,都会直接返回缓存的哈希值,而不是重新计算)
String类构造

String类有很多构造方法.
常用的有3种 :
public static void main(String[] args) { //1.使用常量串构造 String s1 = "hello"; //2.直接new String对象 String s2 = new String("hello"); //3.使用字符数组进行构造 char[] array = {'h','e','l','l','o'}; String s3 = new String(array); }public String(String original) { this.value = original.value; this.hash = original.hash; } public String(char value[]) { this.value = Arrays.copyOf(value, value.length); }
String类能被继承吗,为什么。
 因为String类被final修饰,代表该类不能被子类继承.
因为String类被final修饰,代表该类不能被子类继承.
Java 9 为何要将 String 的底层实现由 char[] 改成了 byte[] ?
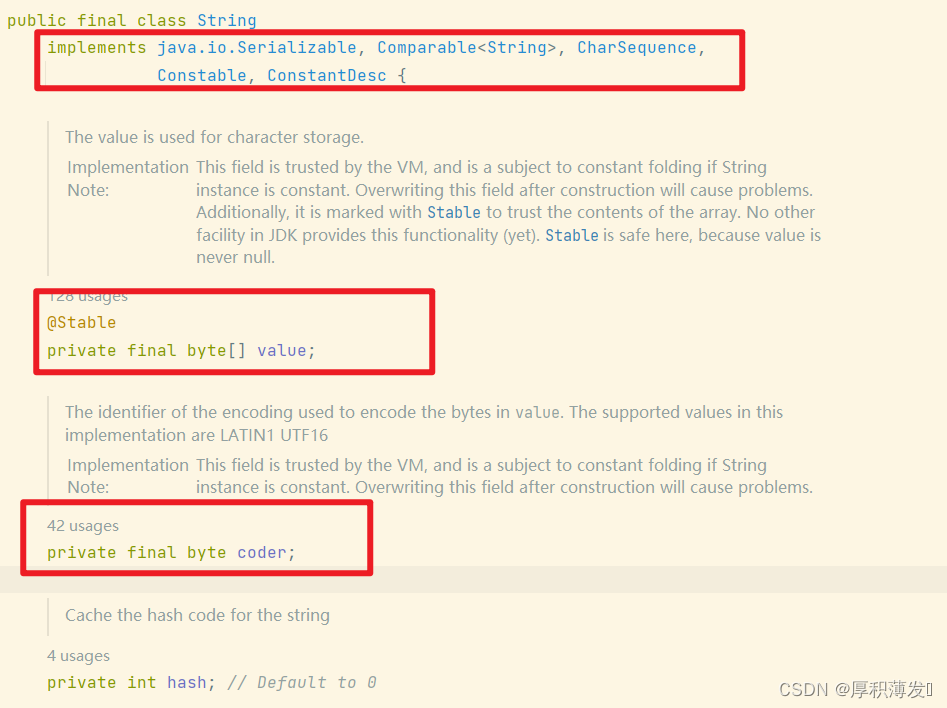
从char[] 到 byte[] 最主要的目的就是节省字符串所占用的内存空间.
因为 在Java中 char占用两个字节 , 所以 使用char[]来表示String就会导致,即使String中的字符只用一个字节就能表示,也得占用两个字节
除了转成byte[]数组以外,JDK9以后的String还增加了一个coder字段来设置编码,Java会根据字符串的内容自动设置相应的编码,要么Latin-1 要么UTF-16
如果字符串中包含的汉字没有超过Latin-1可表示的范围内的字符,那么就会使用Latin-1作为编码方案,byte占一个字节,cha占用2个字节, byte相较于char节省一半的内存空间, JDK官方也说了绝大部分字符串只包含Latin-1可表示的字符
如果超过了Latin-1可表示的范围内的字符,byte和char所占用的空间是一样的.
HashMap使用String做key有什么好处
HashMap 内部实现是通过 key 的 hashcode 来确定 value 的存储位置,因为字符串是不可变的,所以当创建字符串时, 它的 hashcode 被缓存下来(有一个hash字段来存储),不需要再次计算,所以相比于其他对象更快.
String a = "b" 底层原理是什么 ?

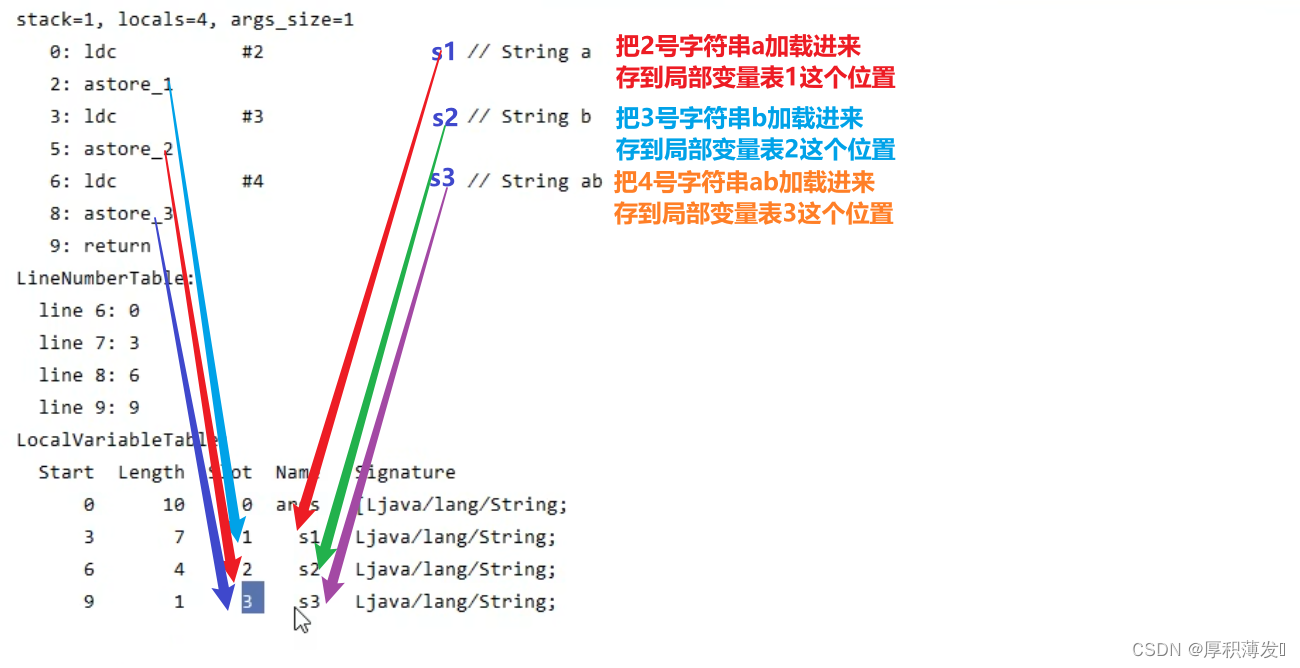
- 常量池中的符号会在程序运行的时候去加载到运行时常量池中.
- 字符串对象都是懒惰创建的,遇到的时候才去创建
- 创建完字符串对象后,先去串池中找,如果没有就放入串池,如果有就使用串池中的对象,相同的对象只会有一份
String 类型的变量和变量做“+”运算时发生了什么?/String 类型的变量和常量做“+”运算时发生了什么?
这个题问的就是String变量拼接会发生什么 ?
String字符串变量的拼接会被转化为StringBuilder的拼接然后在调用toString()方法,所以返回的是一个新的对象.
class Test{ public static void main(String[] args) { String s1 = "a";//字符串对象遇到时才会创建--->延迟加载 String s2 = "b"; String s3 = "ab"; String s4 = s1 + s2;//变量的拼接会被转化为new StringBuilder().append("a").append("b").toString(); } }

原因是 : 变量的值在编译期间不是确定的, 在运行的时候,引用也有可能被修改,是不能确定的,所以必须在运行期间,动态的用StringBuilder的方法来拼接.
String 类型的常量和常量做“+”运算时发生了什么?

常量与常量, 这时Javac在编译器期间的优化,因为,常量是确定的,在编译期间就已经确定了,所以直接会去串池中找,发现有,就不用在创建了,直接引用串池中的字符串对象.
String s与 new String与有什么区别 ?
对于 : String s = "" 如果这个字符串在字符串常量池中出现,则不创建对象,直接引用字符串常量池中的对象,否则再字符串常量池中创建一个对象
对于new String("")会在堆中创建一个字符串对象.
String s1 = new String("abc");这句话创建了几个字符串对象?
创建了1个或者2个对象.
首先先看看双引号引起来的字符串在字符串常量池中有没有,如果没有则创建一个对象放到字符串常量池中,如果有则不创建.
其次new String会创建在堆中创建一个字符串对象.
综上 :
如果字符串常量池中有该字符串,就只会在堆中创建一个对象.否则的话会在堆中和字符串常量池中都要创建字符串对象.
字符型常量和字符串常量的区别
- 字符通常是由单引号引起的单个字符,字符串则是双引号引起的若干字符。
- 字符常量只占2个字节;字符串常量占若干个字节(至少一个字符结束标志) (注意: char 在Java中占两个字节)
- 字符常量相当于一个整型值( ASCII 值),可以参加表达式运算; 而字符串常量则不可以
在自己的代码中,如果创建一个java.lang.String类,这个类是否可以被类加载器加载?为什么?
字符串拼接的几种方式和区别
- concat
- StringBuffer,StringBuilder
- StringUtils.join
- "+" 拼接
concat
public String concat(String str) {
int otherLen = str.length();
if (otherLen == 0) {
return this;
}
int len = value.length;
char buf[] = Arrays.copyOf(value, len + otherLen);
str.getChars(buf, len);
return new String(buf, true);
}
concat方法原理就是 :先创建一个新的字符数组,这个新的字符数组长度是新拼接字符串的长度 + 原先字符串的长度. 然后把两个字符串的值拷贝到新的字符数组中,new一个新的String对象返回 .
StringBuilder,StringBuffer
由于String是不可变的类,所以对字符串的修改都需要创建新的对象,所以会有一定的成本,我们可以使用StringBuilder,StringBuffer两个类对字符串进行多次修改,不会产生新的对象,在原来字符串对象的基础上进行修改.
StringBuilder与StringBuffer的区别是 : StringBuilder不是线程安全的,而StringBuffer是线程安全的.
Stringbuffer,StringBuilder内部也是维护一个char数组,也会维护一个count变量,因为char数组中并不是所有的位置都有字符.
其中有一个append方法就是用于拼接字符串的,内部其实会把拼接的字符串直接复制到内部的char[]数组中,如果长度不够,就会扩容.
和
String类类似,StringBuilder类也封装了一个字符数组,定义如下:char[] value;与
String不同的是,它并不是final的,所以他是可以修改的。另外,与String不同,字符数组中不一定所有位置都已经被使用,它有一个实例变量,表示数组中已经使用的字符个数,定义如下:int count;其append源码如下:
public StringBuilder append(String str) { super.append(str); return this; }该类继承了
AbstractStringBuilder类,看下其append方法:public AbstractStringBuilder append(String str) { if (str == null) return appendNull(); int len = str.length(); ensureCapacityInternal(count + len); str.getChars(0, len, value, count); count += len; return this; }append会直接拷贝字符到内部的字符数组中,如果字符数组长度不够,会进行扩展。
StringBuffer和StringBuilder类似,最大的区别就是StringBuffer是线程安全的,看一下StringBuffer的append方法。public synchronized StringBuffer append(String str) { toStringCache = null; super.append(str); return this; }该方法使用
synchronized进行声明,说明是一个线程安全的方法。而StringBuilder则不是线程安全的。
StringUtils.join
StringUtils中提供的join方法,最主要的功能是:将数组或集合以某拼接符拼接到一起形成新的字符串
String[] str = {"how","are","you"};
System.out.println(StringUtils.join(str));public static String join(final Object[] array, String separator, final int startIndex, final int endIndex) {
if (array == null) {
return null;
}
if (separator == null) {
separator = EMPTY;
}
// endIndex - startIndex > 0: Len = NofStrings *(len(firstString) + len(separator))
// (Assuming that all Strings are roughly equally long)
final int noOfItems = endIndex - startIndex;
if (noOfItems <= 0) {
return EMPTY;
}
final StringBuilder buf = new StringBuilder(noOfItems * 16);
for (int i = startIndex; i < endIndex; i++) {
if (i > startIndex) {
buf.append(separator);
}
if (array[i] != null) {
buf.append(array[i]);
}
}
return buf.toString();
}
Java8中的String类中也提供了一个静态的join方法
public static String join(CharSequence delimiter, CharSequence... elements) {
Objects.requireNonNull(delimiter);
Objects.requireNonNull(elements);
// Number of elements not likely worth Arrays.stream overhead.
StringJoiner joiner = new StringJoiner(delimiter);
for (CharSequence cs: elements) {
joiner.add(cs);
}
return joiner.toString();
}"+" 拼接
为什么不建议在循环体中使用+进行字符串拼接呢?/ '+' 拼接的实现原理是什么?

阿里巴巴Java手册里面建议我们在循环体内使用StringBuilder,因为使用 '+' 在循环体内拼接会产生大量的对象,造成内存资源的浪费.
因为 使用 '+' 进行拼接,通过反编译可以看出每次循环都会new出一个StringBuilder对象,然后进行append操作,最后在通过toString()方法返回String对象,造成内存资源的浪费.
五种拼接字符串的方式效率比较
虽然字符串是不可变的,但是还是可以通过新建字符串的方式来进行字符串的拼接。
直接使用StringBuilder的方式是效率最高的。因为StringBuilder天生就是设计来定义可变字符串和字符串的变化操作的。
StringBuilder > StringBuffer > concat > '+' > StringUtils.join
但是,还要强调的是:
1、如果不是在循环体中进行字符串拼接的话,直接使用+就好了。
2、如果在并发场景中进行字符串拼接的话,要使用StringBuffer来代替StringBuilder。
一个Java字符串中到底能有多少个字符?/String有没有长度限制 ?
Java字符串中的字符数量取决于字符串的编码方式和所使用的Unicode字符集。在UTF-16编码中,一个字符占用2个字节,因此一个字符串最多可以有65536个字符(即2^16-1)。但是,在某些情况下,由于字符串中包含不可见的字符或控制字符,实际可用的字符数量可能会少于65536个。
String的equals() 和 Object的equals() 有何区别?
String中的equals方法是被重写过的,比较的是 String 字符串的值是否相等. Object的equals方法是比较的对象的内存地址。
被final修饰的String会发生什么 ?
被 final 关键字修改之后的 String 会被编译器当做常量来处理,编译器在程序编译期就可以确定它的值,其效果就相当于访问常量。
如果 ,编译器在运行时才能知道其确切值的话,就无法对其优化。
switch 是否能作用在 byte 上,是否能作用在 long 上,是否能作用在 String 上? 如果是那是怎么实现的呢 ?
switch对整形的支持实现
- switch对int的判断是直接比较整数的值。
switch对字符类型的支持实现
- 对char类型进行比较的时候,实际上比较的是ascii码,编译器会把char型变量转换成对应的int型变量
switch对字符串类型的支持实现
public class switchDemoString {
public static void main(String[] args) {
String str = "world";
switch (str) {
case "hello":
System.out.println("hello");
break;
case "world":
System.out.println("world");
break;
default:
break;
}
}
}
public class switchDemoString
{
public switchDemoString()
{
}
public static void main(String args[])
{
String str = "world";
String s;
switch((s = str).hashCode())
{
default:
break;
case 99162322:
if(s.equals("hello"))
System.out.println("hello");
break;
case 113318802:
if(s.equals("world"))
System.out.println("world");
break;
}
}
}
字符串的switch是通过equals()和hashCode()方法来实现的
进行switch的实际是哈希值,然后通过使用equals方法比较进行安全检查,为什么要用equals比较.因为可能会发生哈希冲突
其实switch只支持一种数据类型,那就是整型,其他数据类型都是转换成整型之后再使用switch的。
public static void main(String[] args) {
String s = "hello";
byte a = 1;
short e = 4;
int b = 2;
char d = '1';
long c = 3;//不可以
double f = 10.0;//不可以
float g = 1.9f;//不可以
boolean h = false;//不可以
}String.valueOf和Integer.toString的区别
String.valueOf() :
public static String valueOf(int i) {
return Integer.toString(i);
}Integer.toString :
public static String toString(int i) {
if (i == Integer.MIN_VALUE)
return "-2147483648";
int size = (i < 0) ? stringSize(-i) + 1 : stringSize(i);
char[] buf = new char[size];
getChars(i, size, buf);
return new String(buf, true);
}String.valueOf底层就是通过Integer.toString来实现的.
String的特性
不可变性
什么是不可变性 ?
不可变对象是在完全创建后其内部状态保持不变的对象, 一旦对象被赋值给变量,我们既不能更新引用,也不能通过任何方式改变其内部状态.
当要修改的时候而是创建一个原来对象的副本,在副本上进行修改,修改完成之后,再让原内存地址引用这个新的对象
如果一个对象,在它创建完成之后,不能再改变它的状态,那么这个对象就是不可变的。不能改变状态的意思是,不能改变对象内的成员变量,包括基本数据类型的值不能改变,引用类型的变量不能指向其他的对象,引用类型指向的对象的状态也不能改变。
一旦一个String对象在内存中被创建出来,它就无法被修改,并且String类的方法都没有改变字符串本身的值,而是返回一个新的对象.

String 为什么是不可变的?
- String的底层数据结构是使用char数组(Java9改为了byte数组),这个char[]数组被final修饰,所有属性都被final所修饰 并且是私有的,String类中并没与提供/暴露修改字符串的这个方法
- String类是被final修饰的,表示这个类不能被继承,进而避免了子类破坏String不可变.
String为什么设计成不可变的?
这个主要从 缓存,安全性,线程安全和性能等方面进行考虑的.
- 缓存
因为字符串是平常非常广泛使用的数据结构,由于创建大量的字符串是非常耗费资源的,Java提供了字符串常量池来大量的节省堆空间.
让相同内容的字符串变量指向池子中的同一个字符串对象.
之所以这么做是因为,字符串是不可变的,如果字符串可变,那么修改一个字符串变量,另外的字符串变量也会跟着改变.
- hashcode缓存
由于String类的不可变性,字符串的值就不会改变,hashcode方法在String类中被重写,以方便缓存String类会有一个属性hash来专门记录缓存的hashcode,这样hashcode只会在第一次调用期间进行计算并且缓存,以后就直接返回缓存相同的值.
缓存hashcode有什么用处呢 ?
因为在使用集合类比如HashMap,HashSet...这些存储key-value的容器的时候,经常会使用String类型作为key,进而也要用String类型的hashcode来计算映射的下标. 这样我们只需要在第一次调用的时候进行计算并且缓存,以后直接返回缓存中的值就可以了.
- 安全性
由于字符串在应用程序中可以存储敏感信息(用户名,密码,URL等),因此让String类不被修改,就可以提升整个应用程序的安全性.
如果这个字符串不可变,那么就不会被修改,我们就可以相信这个字符串的内容.相反如果字符串可变,随时都有可能被修改,那么就没有安全性可言了.
- 线程安全
不可变性会使得字符串自动的称为线程安全的. 当多个线程访问字符串的时候,字符串被多个线程所共享,字符串的内容不会被修改,如果修改了,修改的也是新的字符串对象.,因此String是线程安全的.
- 性能
字符串常量池,hashcode缓存都是提升性能的体现.
因为字符串不可变,所以使用字符串常量池进行缓存可以大大减少堆内存,而且提前对hashcode做缓存,更加的高效.
又因为字符串对象在开发中广泛的使用到,所以字符串的性能对整个应用程序的总体性能有相当大的影响.
String设计成不可变的有什么好处?
这个主要从 缓存,安全性,线程安全和性能等方面进行考虑的.
对于引入缓存,引入了字符串常量池,可以大大减少堆内存的占用
对于引入hashcode缓存, String会有一个hash字段来记录字符串的hashcode,第一次调用hashcode的时候缓存并且记录起来. 当下一次再有调用hashcode的时候直接返回,省去了再次计算hashcode的时间
提高安全性 : 因为字符串不可变,也就是不可以修改字符串中的值,可以保证存储到字符串里面的内容是安全的.
保证线程安全,String的不可变性使得字符串线程安全. 多个线程共享这个字符串,但是字符串的内容不会被修改,如果修改了,修改的也是新的字符串对象.,因此String是线程安全的.
提升性能 :
字符串常量池,hashcode缓存都是提升性能的体现.
因为字符串不可变,所以使用字符串常量池进行缓存可以大大减少堆内存,而且提前对hashcode做缓存,更加的高效.
如何设计成一个不可变类呢 ?
- 将class自身声明为final,这个类就不能被继承(别人就不能扩展来绕过限制)
- 将所有成员变量定义为 private 和final,并且不要实现setter方法
- 通常构造对象的时候,成员变量使用深拷贝来初始化,而不是直接赋值,(无法确定输入对象不被其他人修改)
- 如果确实需要实现getter方法,或者其他可能返回内部状态的方法,使用 copy-on-write原则,创建私有的copy.
- 对于getter方法,和setter方法,建议确定有需要的时候再去实现
String s = "Hello";s = s + " world!";这两行代码执行后,原始的 String 对象中的内容是否会改变?
原始的String对象不会改变,因为String类是不可变的,当对原字符串进行修改的时候,是创建一个新的对象.
线程安全
String 是线程安全的么 ? String为什么是线程安全的 ?
String是线程安全的, 因为String类的不可变性使得它线程安全. 因为当有多个线程访问的时候,它不会被修改.也就是说字符串对象被多个线程共享,如果线程更改了值,将会在字符串常量池中创建新的对象,原来的字符串对象不会被修改. 所以线程安全
String类的方法
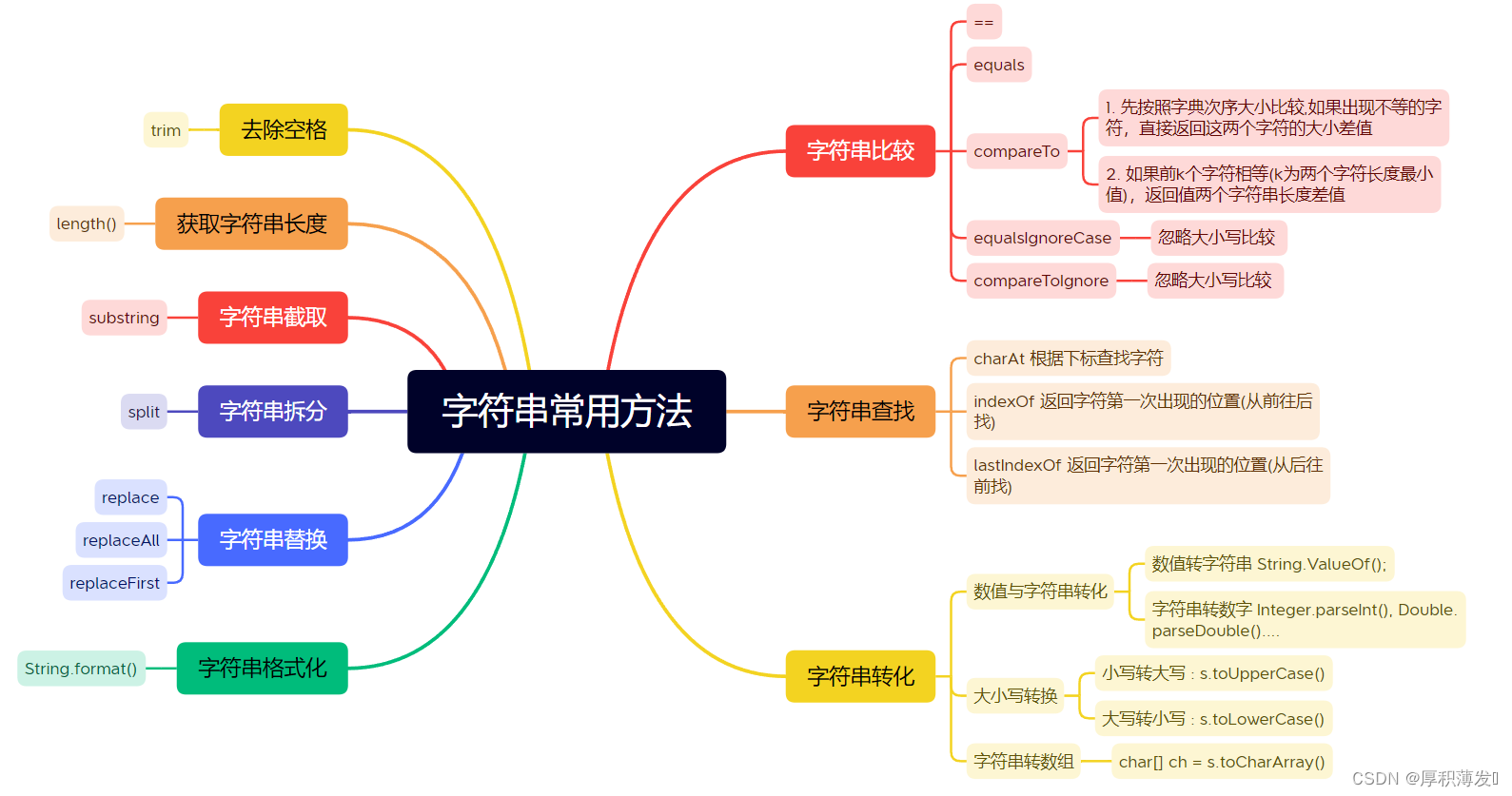
String 类的常用方法都有那些呢?
intern方法
String的intern 方法有什么作用? JDK1.7与1.8有什么区别?
intern方法可以将串池中还没有的字符串对象放进字符串常量池中.
- JDK1.8调用intern方法 会尝试将字符串对象尝试放入到串池, 如果串池中有则不会放入到串池,如果串池中没有 ,则放入到串池中. 调用intern方法最终返回的是串池中的对象.(调用intern方法返回的字符串对象和真正放入到串池中的对象都是串池中的对象是相同的对象)
- JDK1.6调用intern方法 会尝试将字符串对象尝试放入到串池,如果有,则不会放入到串池,如果串池中没有,会把对象复制一份放入到串池. 调用intern方法最终返回的是串池中的对象.(调用intern方法的字符串对象和真正放入到串池中的对象是两个不同的对象)
- 总结一点就是JDK1.8调用intern如果串池中没有会直接放入到串池中,而对于JDK1.6来说它是复制一份放到串池中(所以调用intern方法的字符串对象和返回的对象不是同一个对象)
关于intern方法的面试题
请你说一说对象是否相等 ?
JDK1.8后举例
public static void main(String[] args) {
String s1 = new String("a") + new String("b");
String s2 = s1.intern();
String x = "ab";
System.out.println(s1 == x);
System.out.println(s2 == x);
}我们来分析一下 :
首先看到 "a" , "b" -->双引号引起来的 就会在字符串常量池中创建对象,因为是new,堆中也会有a,b
然后a+b 将a和b拼接起来,--->就会在堆中创建"ab"对象
现在为止 :
字符串常量池 : ["a","b"]
堆 : [new String("a"),new String("b"),new String("ab")]
然后调用s1.intern()方法尝试把"ab"对象放入到串池中,发现串池中没有,就会放入到串池,并返回串池中的引用.
所以 :
字符串常量池 : ["a","b","ab"]
堆 : [new String("a"),new String("b"),new String("ab")]
又 String x = "ab" 串池中有"ab",所以x直接指向串池中的对象.
至此 s1 ,s2 ,x 都指向串池中的对象. 答案也就出来了

public static void main(String[] args) {
String s1 = new String("a") + new String("b");//1
String x = "ab";//2
String s2 = s1.intern();//3
System.out.println(s1 == x);//4
System.out.println(s2 == x);//5
}1,2行代码执行完成后 :
字符串常量池 : ["a","b","ab"]
堆 : [new String("a"),new String("b"),new String("ab")]
然后在执行第三行代码,尝试把"ab"字符串放入到串池,但是串池中已经有"ab"字符串对象了,所以不会放入,s1依然指向的是堆中的"ab"字符串, 又因为调用intern方法后返回串池中的引用.
所以s2指向串池中的对象.

substring方法
substring的作用
- substring的作用就是用于截取字符串并返回范围(左闭右开)内的内容.
调用substring时发生了什么?
当对其字符串截取之后,截取之后的结果赋值给的变量,指向一个全新的字符串对象.
JDK6中的substring
//JDK 6
String(int offset, int count, char value[]) {
this.value = value;
this.offset = offset;
this.count = count;
}
public String substring(int beginIndex, int endIndex) {
//check boundary
return new String(offset + beginIndex, endIndex - beginIndex, value);
}
String是通过字符数组实现的。在jdk 6 中,String类包含三个成员变量:
char value[],int offset,int count。他们分别用来存储真正的字符数组,数组的第一个位置索引以及字符串中包含的字符个数。当调用substring方法的时候,会创建一个新的string对象,但是这个string的值仍然指向堆中的同一个字符数组。这两个对象中只有count和offset 的值是不同的。

也就是说在JDK6的substring方法,原来的对象和截取后的对象不是同一个对象,但是他们共同指向的是堆中的同一个对象.
JDK6的substring会出现的问题
即使比如你有一个超长的字符串,但是你使用substring的时候只需要截取一小段,你却引用了整个超长的字符串, 因为这个超长的字符数组一直被引用,就会无法被回收,就可能导致内存泄漏问题.
在JDK 6中,一般用以下方式来解决该问题,原理其实就是生成一个新的字符串并引用他。
JDK7中的substring
//JDK 7
public String(char value[], int offset, int count) {
//check boundary
this.value = Arrays.copyOfRange(value, offset, offset + count);
}
public String substring(int beginIndex, int endIndex) {
//check boundary
int subLen = endIndex - beginIndex;
return new String(value, beginIndex, subLen);
}
在jdk 7 中,substring方法会在堆内存中创建一个新的数组。原来的对象和substring截取的对象不是同一个对象.

JDK 7中的subString方法, 使用new String创建了一个新字符串,避免对老字符串的引用。从而解决了内存泄露问题。
replace方法
replace,replaceAll和replaceFirst之间的区别
replace、replaceAll和replaceFirst是Java中常用的替换字符的方法,它们的方法定义是:
- replace(CharSequence target, CharSequence replacement) ,用replacement替换所有的target,两个参数都是字符串。
- replaceAll(String regex, String replacement) ,用replacement替换所有的regex匹配项,regex很明显是个正则表达式,replacement是字符串。
- replaceFirst(String regex, String replacement) ,基本和replaceAll相同,区别是只替换第一个匹配项。
可以看到,其中
- replaceAll以及replaceFirst是和正则表达式有关的,而replace和正则表达式无关。
- replaceAll和replaceFirst的区别主要是替换的内容不同,replaceAll是替换所有匹配的字符,而replaceFirst()仅替换第一次出现的字符
从字符串中删除空格有几种方式
- trim() : 删除字符串开头和结尾的空格。
- strip() : 删除字符串开头和结尾的空格。
- stripLeading() : 只删除字符串开头的空格
- stripTrailing() : 只删除字符串的结尾的空格
- replace() : 用新字符替换所有目标字符
- replaceAll() : 将所有匹配的字符替换为新字符。此方法将正则表达式作为输入,以标识需要替换的目标子字符串
- replaceFirst() : 仅将目标子字符串的第一次出现的字符替换为新的字符串

如何比较两个字符串?
分别有 == ,equals, equalsIgnoreCase,compareTo,compareToIgnoreCase(忽略大小写比较)方法
compareTo方法的源码
public int compareTo(String anotherString) {
int len1 = value.length;
int len2 = anotherString.value.length;
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
return len1 - len2;
}