导读:火山引擎正在打造完善的虚拟数字人技术和应用体系,那么火山引擎是如何定义虚拟数字人的呢?火山引擎 2D 虚拟数字人和 3D 数字人采用了怎样先进的技术?火山引擎数字人有哪些应用和前景展望?今天我们就来一起探秘火山引擎虚拟数字人技术与应用。
今天的介绍会围绕下面五点展开:
-
火山引擎虚拟数字人简介
-
2D 数字人技术体系
-
3D 数字人技术体系
-
火山引擎虚拟数字人应用
-
火山引擎虚拟数字人展望
分享嘉宾|樊博 字节跳动AI-Lab智能语音 算法研究员
编辑整理|张续然 中睿信
出品社区|DataFun
01/火山引擎虚拟数字人简介
首先介绍一下火山引擎虚拟数字人的基本情况。
1. 火山引擎虚拟数字人定义
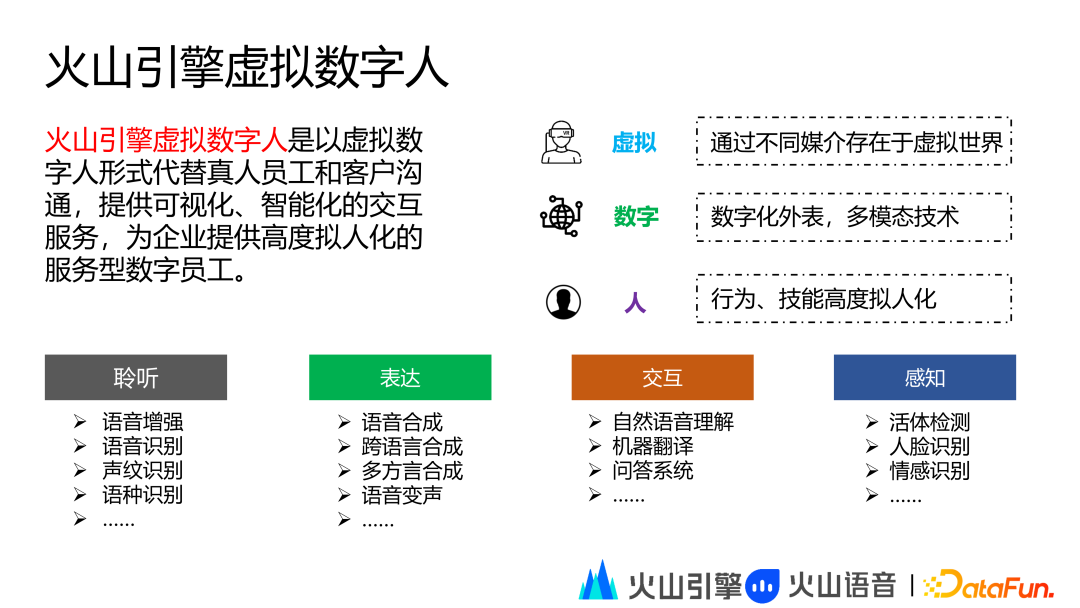
火山引擎虚拟数字人是以虚拟数字人形式代替真人员工和客户沟通,提供可视化、智能化的交互服务,为企业提供高度拟人化的服务型数字员工。
虚拟数字人中的“虚拟”指数字人能够通过不同媒介存在于虚拟世界,包括移动端、PC 端和 VR 设备等。虚拟数字人中的“数字”指数字人具有数字化的外表,通过多模态技术赋予其智能,这里的智能包括聆听、表达、交互和感知四大类:
-
聆听:语音增强、语音识别、声纹识别、语种识别等
-
表达:语音合成、跨语言合成、多方言合成、语音变声等
-
交互:自然语言理解、机器翻译、问答系统等
-
感知:活体检测、人脸识别、情感识别等
虚拟数字人中的“人”指通过多模态技术赋能的数字人的行为、技能高度拟人化。
2. 火山引擎虚拟数字人分类
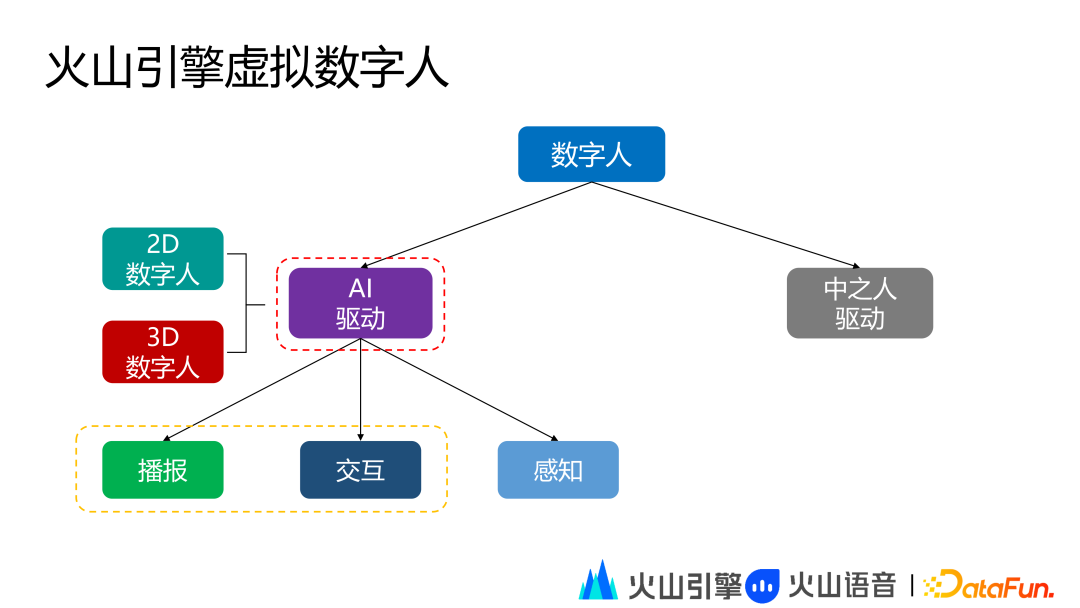
火山引擎虚拟数字人目前可以分为 AI 智能驱动型数字人和中之人驱动型数字人。AI 智能驱动型数字人是基于各种 AI 多模态技术打造的数字人。中之人驱动型数字人是基于真人驱动技术打造的数字人。当前火山引擎虚拟数字人的研究重点方向是 AI 智能驱动型数字人。
AI 智能驱动型数字人按能力划分可以分为播报型数字人、交互型数字人和感知型数字人,按形象类别划分可以分为 2D 数字人和 3D 数字人。
在能力方面,播报型数字人仅具备表达能力,交互型数字人具备聆听、表达和交互的能力,感知型数字人在交互型数字人的基础上增加感知能力。

在形象类别方面,火山引擎支持 2D 真人、3D 卡通和 3D 超写实形象。旨在通过丰富的形象覆盖更多样的落地场景。
02/2D 数字人技术体系
1. 2D 数字人技术全景
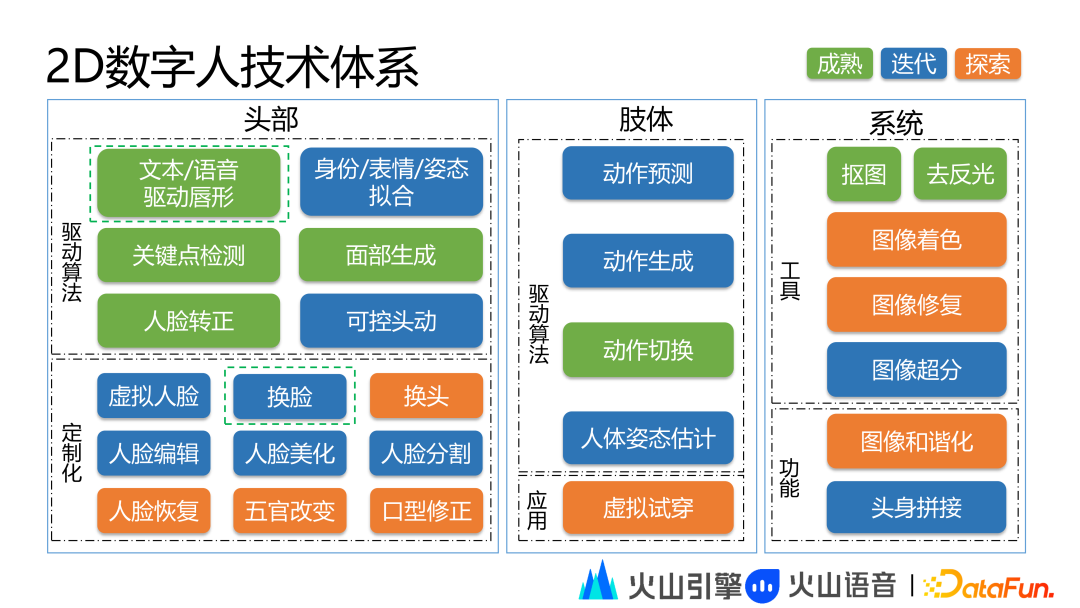
2D 数字人技术体系分为头部、肢体和系统三大部分。头部层面主要包括驱动算法和定制化。头动驱动算法的主要功能是驱动头动、唇形运动和表情等。驱动算法包括文本、语音驱动唇形、身份/表情/姿态拟合、人脸关键点检测、面部生成、人脸转正、可控头动等技术。定制化主要用于增强人头的定制能力。定制化能力包括虚拟人脸、换脸、换头、人脸编辑、人脸美化、人脸分割、人脸回复、五官改变、口型修正等技术。
肢体主要包括驱动算法和应用。驱动算法包括动作预测、动作生成、动作切换和人体姿态估计。应用包括模拟试穿等。
系统层面主要包括数字人建模前处理和后处理相关的算法集合。本次分享的重点是驱动算法和定制化中的换脸算法。
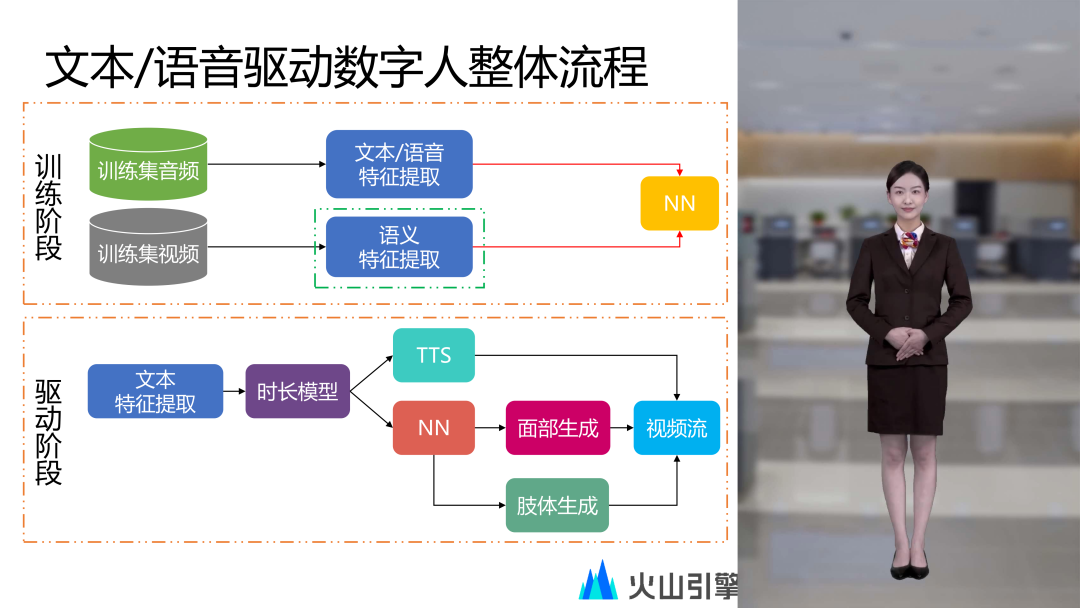
2. 2D 数字人语义提取和驱动技术原理
当前火山数字人的输入是文本或语音。定制一个 2D 数字人首先需要录制主播的音视频数据,这里的录制工作需要专业的主播按照指定的文本朗读录制形成训练集,在训练阶段从训练集的音频中提取文本或语音特征,同时从视频中提取头部相关的语义特征,最后通过 NN 模型学习两者之间的映射关系。
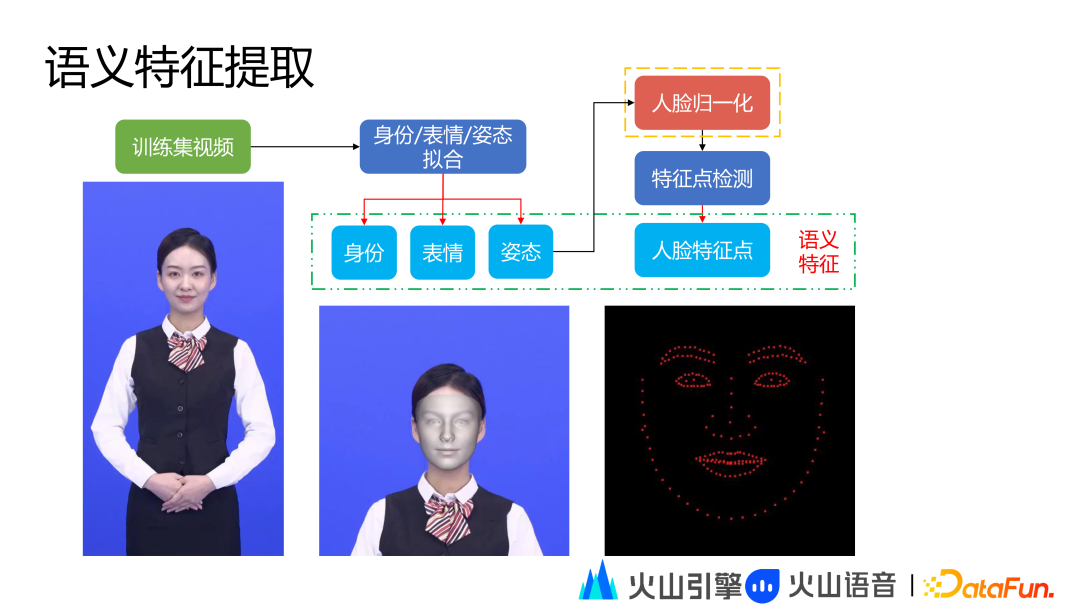
这里重点介绍语义特征提取,语义特征包括身份、表情、姿态和人脸特征点信息,对于训练集每一个视频的每一帧,都会通过身份、表情和姿态拟合模块提取主播的身份、表情和三维姿态特征信息。为更好的实现数字人生成效果,三维姿态信息需要既准又稳。在拿到三维姿态信息之后,需要对人脸做归一化处理,这一步非常关键,在人脸归一化之后需要做人脸特征点提取,提取的特征点可以消除姿态的影响,以便在最终 NN 模型训练阶段更容易收敛,同时也会使最终合成的唇形效果更好。
在驱动阶段,提取文本特征后通过时长模型对音素级的特征进行帧级延展,然后分别将延展后的特征送到 TTS 模块和训练好的 NN 模块,TTS 模块生成文本对应的语音。NN 模块生成头部相关的语义信息,语义信息用于面部生成和肢体生成,面部生成和肢体生成的图像与 TTS 生成的语音共同封装成视频流最终形成数字人播报的效果。如果改为语音输入,则 TTS 模块可以忽略,即语音输入直接走 NN 模块,用真人语音替代之前 TTS 合成的语音,同样可以生成数字人播报的效果。
3. 多语种数字人技术方案
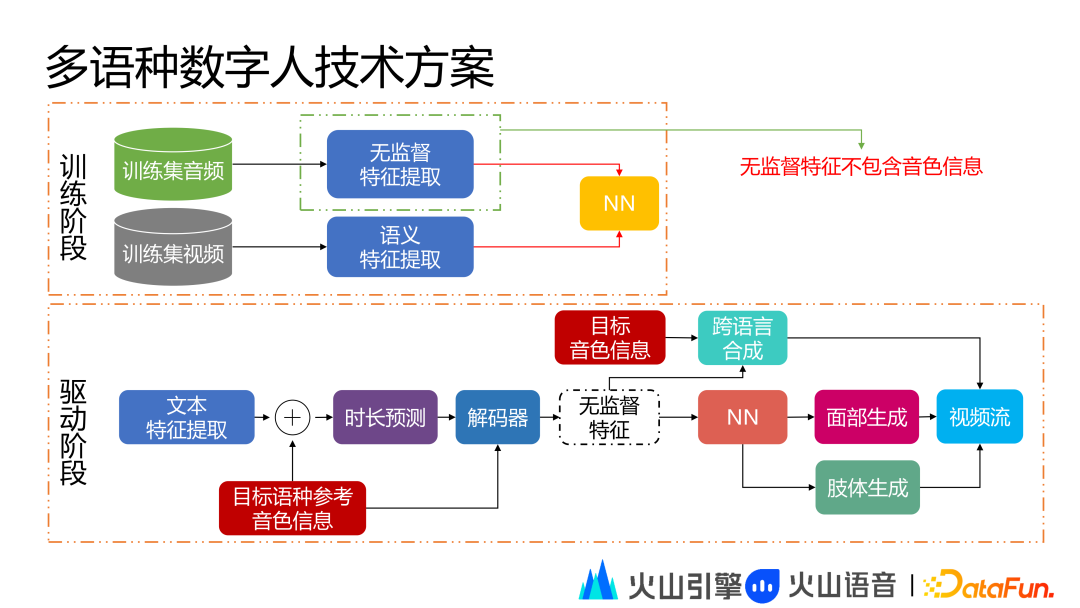
前述技术方案主要支持单语种播报,当训练集是中文时,数字人无法播报英文或者其他语种,如果需要播报其他语种,则需要录制多语种的训练集。在实际操作中,以上方案不能满足一些场景的需求,因此我们提出多语种数字人方案,主播仅需录制单语种音视频即可实现多语种数字人的多语种表达。
当前多语种数字人的技术方案在训练阶段和前述流程差不多,不同的点在于我们将从训练集的音频中提取一个无监督特征,这里的无监督特征不包含音色信息,在训练阶段相当于训练无监督特征和提取的语义特征之间的映射关系。在驱动阶段,对于指定语种的输入文本附加上目标语种的参考音色信息,此时在解码器中解出的就是无监督特征,这个特征就包括目标语种的韵律和风格信息。因为无监督特征不包含音色信息,所以当我们再把无监督特征送到跨语言合成模型的时候,需要附带目标音色信息。这里的目标音色信息指主播在做训练集朗读时仅录制中文,并将中文音色信息作为输入,然后跨语言合成模型就会生成指定语种输入文本对应的语音。在无监督特征方面,通过刚才训练好的 NN 模型,生成头部相关的语音信息,最后通过面部生成和肢体生成得到图像,然后和语音打包成视频流形成数字人播报。基于多语种数字人方案也可以实现多方言数字人播报的效果。


4. 数字人交互系统

为拓展数字人的应用场景,需要给数字人增加交互能力。因此我们需要整合多模态 AI 技术实现数字人从播报到交互的升级。
火山引擎虚拟数字人交互系统在交互过程中能够在不同状态之间进行切换,常见的三个状态为表达、聆听和休闲,在实际交互过程中数字人的状态变化会更加复杂。
表达指数字人在说话,聆听指数字人在听用户讲话,休闲指没有交互的状态下数字人所处的状态。状态之间的切换通过状态机控制,状态切换的信号来源于理解决策层的输出。用户的语音通过语音识别系统和语义理解之后会形成是否打断、对话内容、动作标签和状态类型等信号。比如对话内容是需要数字人播报出来的文本,假如数字人处于聆听或者休闲状态时收到对话内容,它需要立刻切换到表达状态。当数字人收到打断请求时,它需要立刻从表达状态切换到聆听状态,听取客户输入的语音内容。如果数字人处于表达状态中收到动作标签,则它需要在表达的同时插入动作,这也要求数字人具备动作插入能力。
5. 数字人交互系统
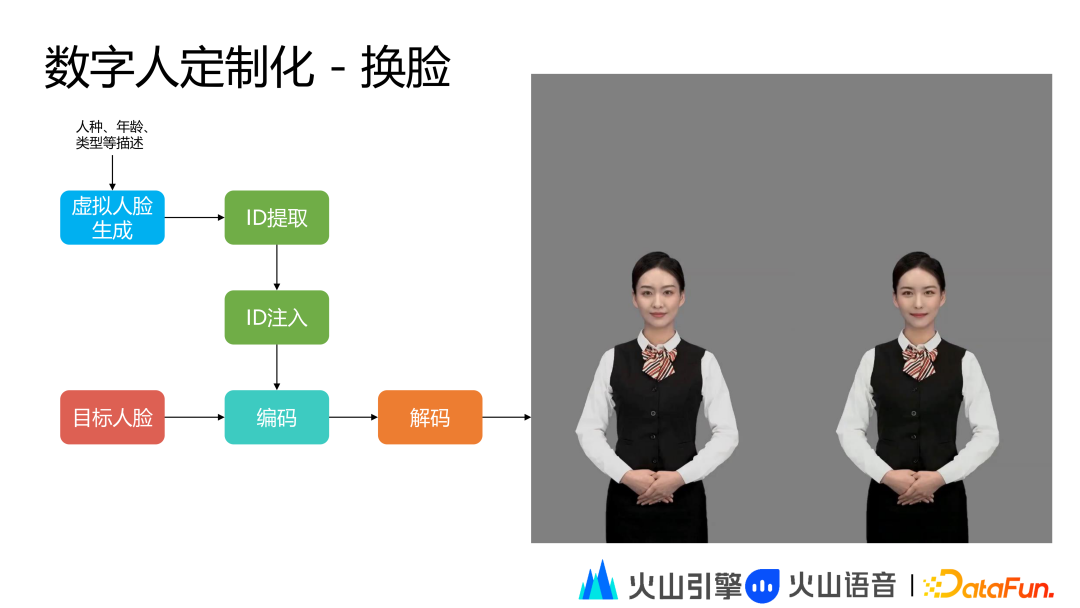
数字人定制化换脸,主要针对已经上线的主播对其头部尤其是面部特征进行定制化,这样做的好处是在规避版权风险的同时能够完成成熟能力的复制。常规定制一个数字人需要成本,如果数字人能定制化,就可以快速完成复制。比如现在我们可以对已上线的数字人进行换脸,或者五官的改变去替换 TA 的身份,这样我们就能快速上线一个新的主播。或者我们对它的人脸进行编辑,比如肤色、头发和年龄进行更改,这样就能丰富数字人的形象设置。
在换脸时,我们首先会描述目标形象的各类特征,然后通过虚拟人脸生成模块生成一个虚拟人脸,这里不用真人人脸的原因是使用真人人脸有版权风险。通过虚拟人脸生成出的虚拟人脸照片符合我们描述的人脸特征,然后我们用虚拟人脸的照片进行身份提取,将提取的身份用于替换目标人脸,编码出来的身份信息在解码后得到最终的换脸效果。
6. 2D 数字人核心优势

火山引擎 2D 数字人的核心优势主要包括以下 4 点:
-
效果优良:整体自然度 MOS 评测可以达到 3.9,唇形准确度高达 98.6%。
-
高并发:T4 单卡 20 核 1080P/25fps 视频流支持 10 路并发,支持公有云接口调用及私有化部署。
-
功能全面:支持打断以及通过 SSML 的形式插入动作,支持任意背景更换,支持音色切换,多语种、多方言。
-
低成本:5min 数据即可完成基本定制,自动化平台支持自动化训练及上线。
03/3D 数字人技术体系
1. 3D 数字人技术全景
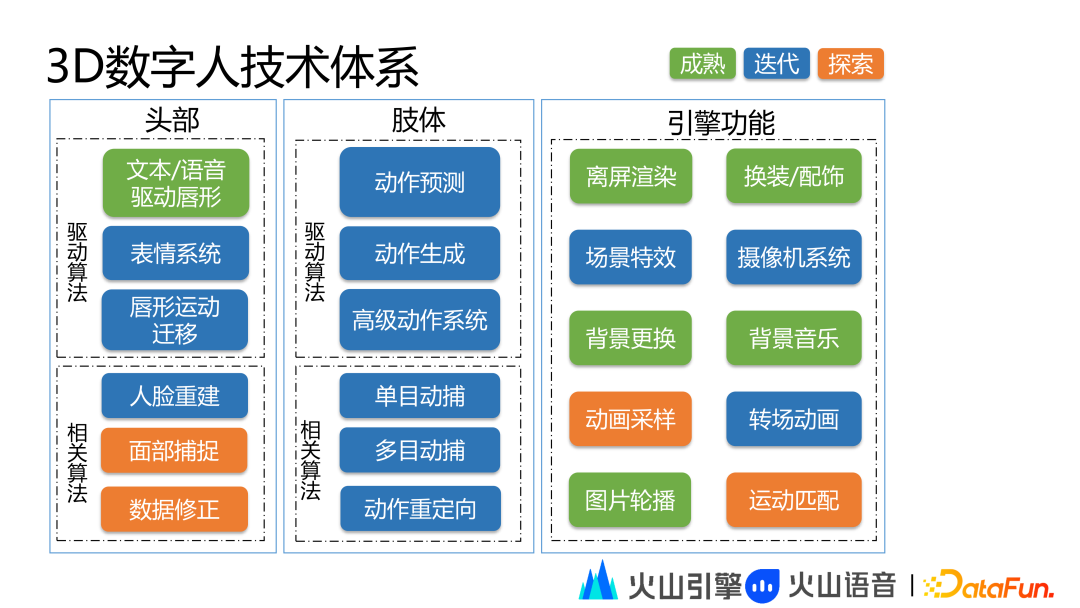
3D 数字人技术体系分为头部、肢体和系统三大部分。
头部层面主要包括驱动算法和相关算法。头动驱动算法的主要功能是驱动头动、唇形运动和表情等。驱动算法包括文本/语音驱动唇形、表情系统、唇形运动迁移等技术。相关算法主要用于 3D 人像建模和驱动。相关算法包括人脸重建、面部捕捉和数据修正。
肢体主要包括驱动算法和相关算法。驱动算法包括动作预测、动作生成、动作切换和高级动作系统。相关算法包括单目动捕、多目动捕和动作重定向。
引擎功能层面主要包括离屏渲染、换装/配饰、场景特效、摄像机系统、背景更换、背景音乐、动画采样、转场动环、图片轮播和运动匹配等。
2. 3D 数字人制作流程

3D 数字人的制作流程首先需要描述数字人的需求,然后根据需求进行原画设计,当设计稿敲定后,就可以进行灰模制作,灰模制作后将进行材质制作,材质制作完成后将进行面部和肢体绑定。
完成绑定后需要在渲染引擎中进行渲染测试。渲染测试通过后需要根据训练需求进行数据采集,这里主要有两方面的数据采集,一方面是面部捕捉,另一方面是动作捕捉。
面捕和动捕的数据都需要进行数据精修。面捕的数据主要用于面部驱动能力的训练,动捕的数据主要用于肢体驱动能力的训练,然后下一步进入驱动模型的训练,最后集成引擎能力完成 3D 数字人的上线。
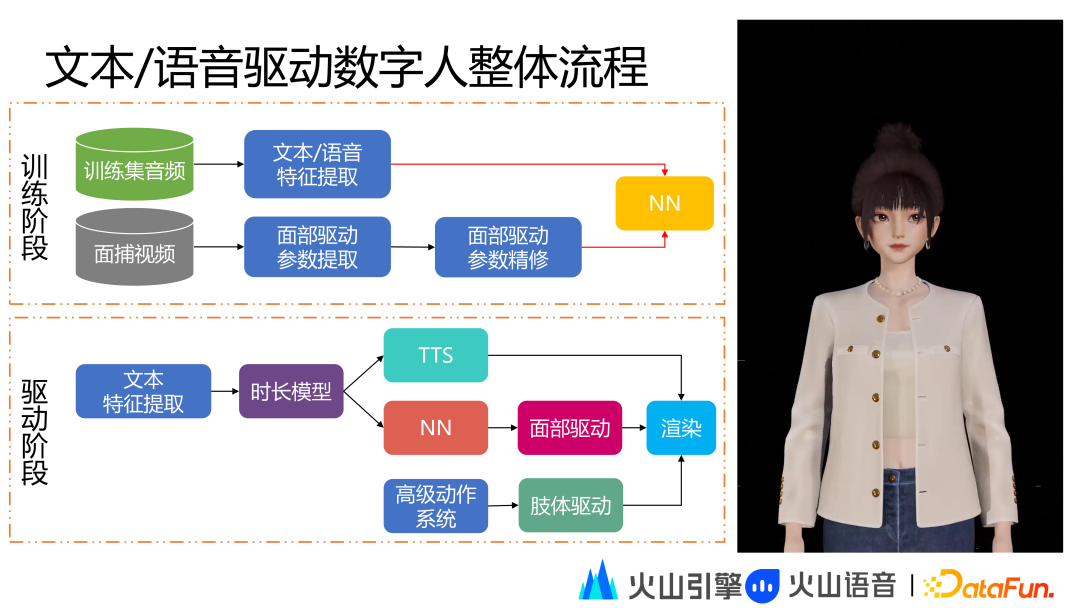
3D 数字人在训练阶段的技术处理过程和 2D 数字人相似,刚刚提到的面部驱动参数的精修数据相当于输出特征,然后再学习文本语音特征和面部精修数据之间的映射关系。在驱动阶段不同于 2D 数字人的是会根据 NN 模型拿到面部驱动参数,同时通过高级动作系统进行肢体驱动,然后将面部动画和肢体动画以及语音通过渲染合成得到最终的数字人视频流。
3. 3D 数字人唇形迁移技术
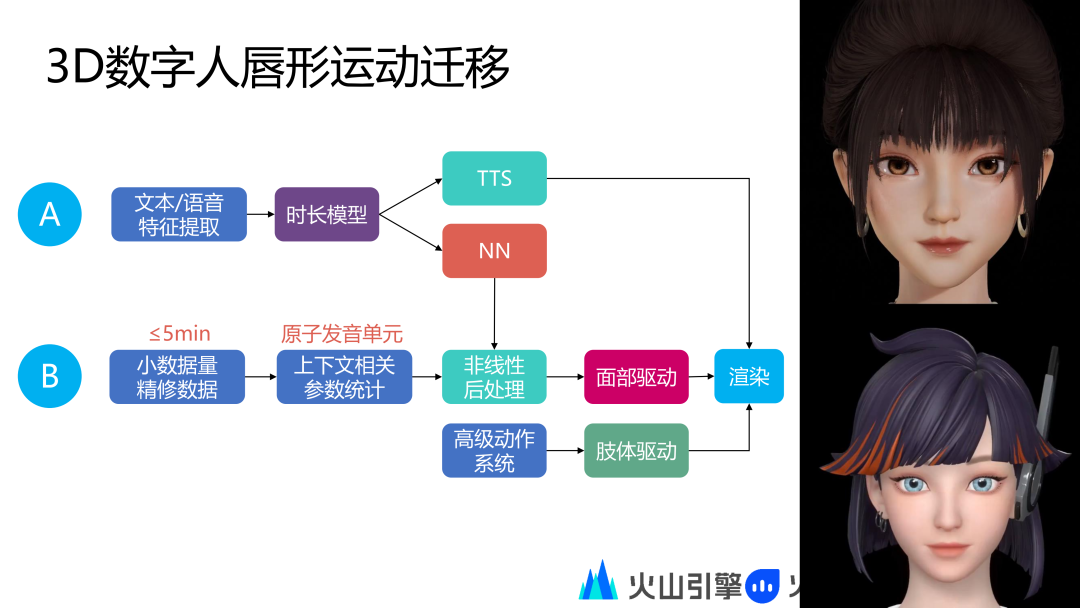
我们当前定制出自然唇形效果时需要录制小时级数据,同时小时级数据又需要精修,这里的数据录入和训练成本比较高。为了优化成本,我们提出一种迁移方案,即通过已经制作好的数字人 A 的唇形效果迁移到数字人 B 上,这样数字人 B 只需要录制少量的数据即可完成唇形训练。
当前火山引擎已经实现该技术方案,我们的数字人只需要录制 5 分钟以内的小数据量即可实现之前的效果。在技术流程上,数字人 B 录制的小数据量精修数据会在原子发音单元实现上下文相关参数统计,然后在结合数字人A成熟的 NN 驱动模型自动推导出非线性后处理模块,在这个非线性后处理模块调整数字人 NN 模块的输出,这里输出的面部驱动参数可以适配到数字人 B 上,后面和前述流程一样,最终通过渲染合成得到展示效果。
04/火山引擎虚拟数字人应用
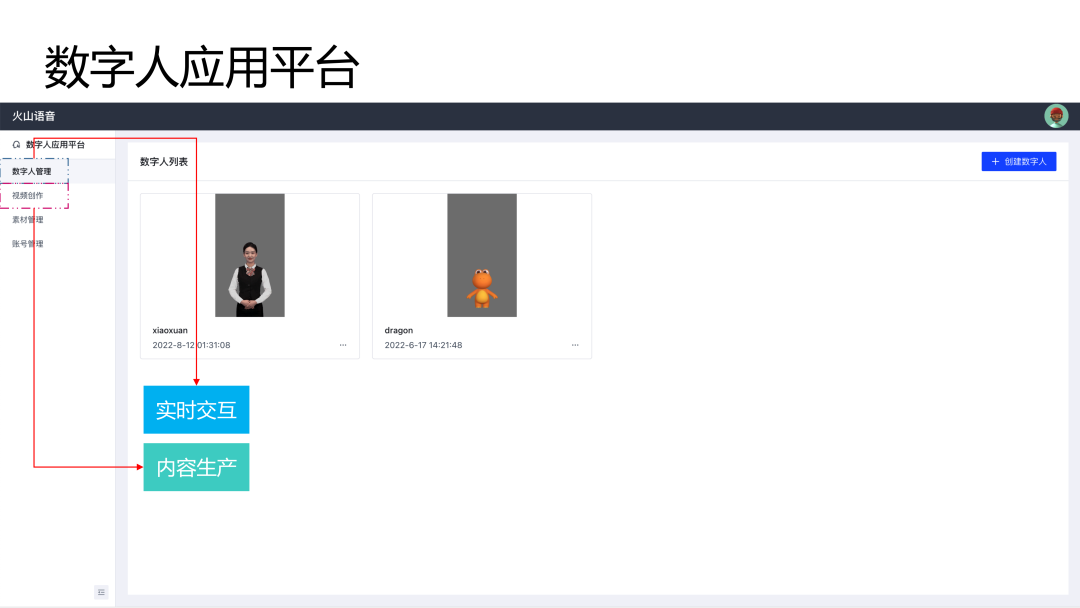
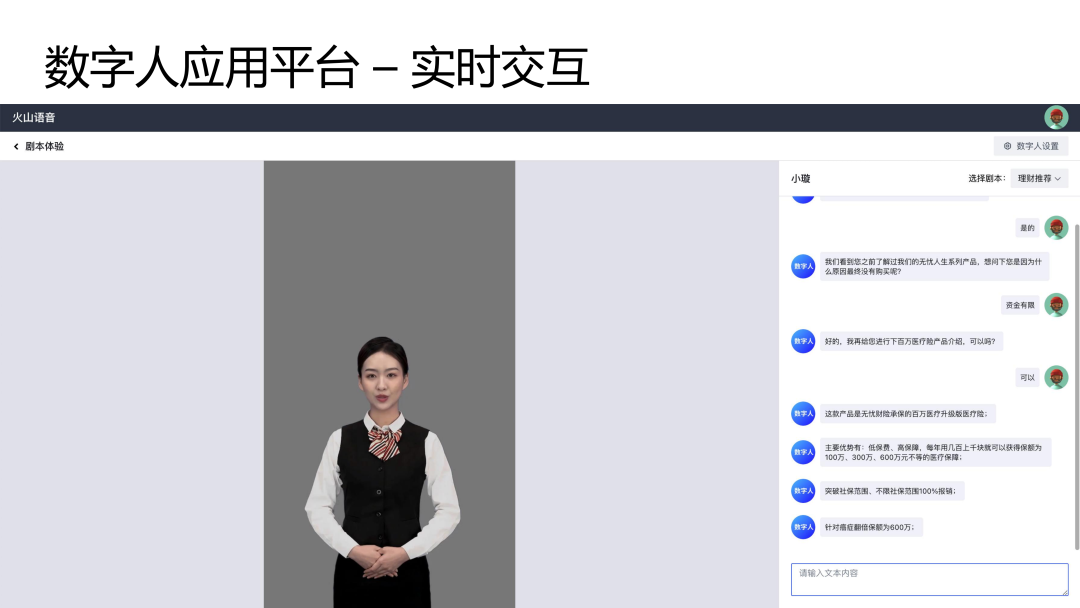
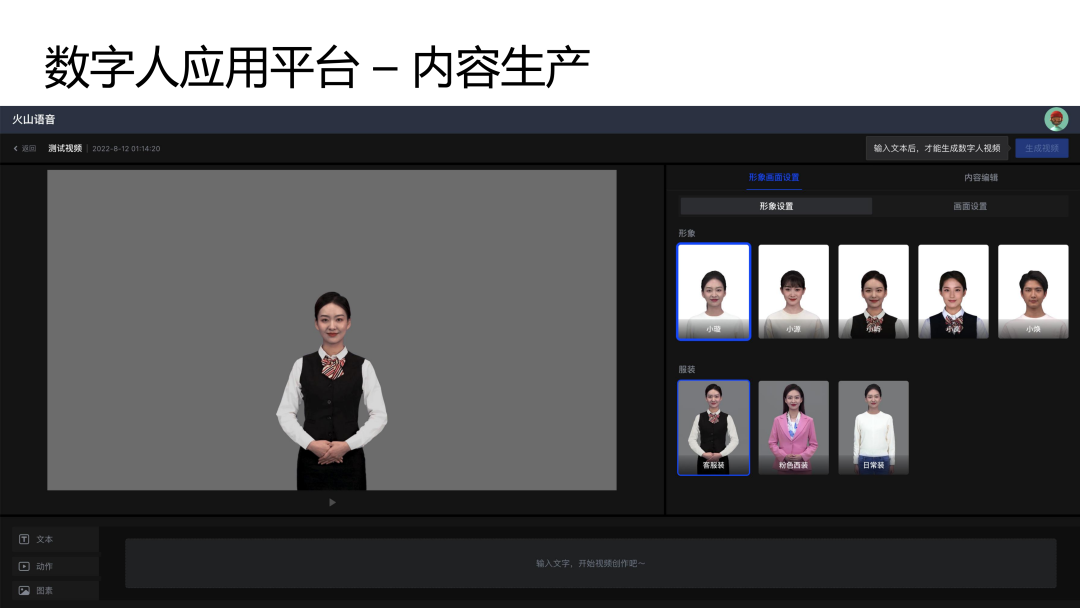
火山引擎数字人应用平台集成了上述所有技术能力。这里主要有两部分功能需要重点介绍:数字人管理和视频创作。数字人管理页面可以配置数字人,在配置完成之后可以进行实时交互。视频创作主要用于内容生产。
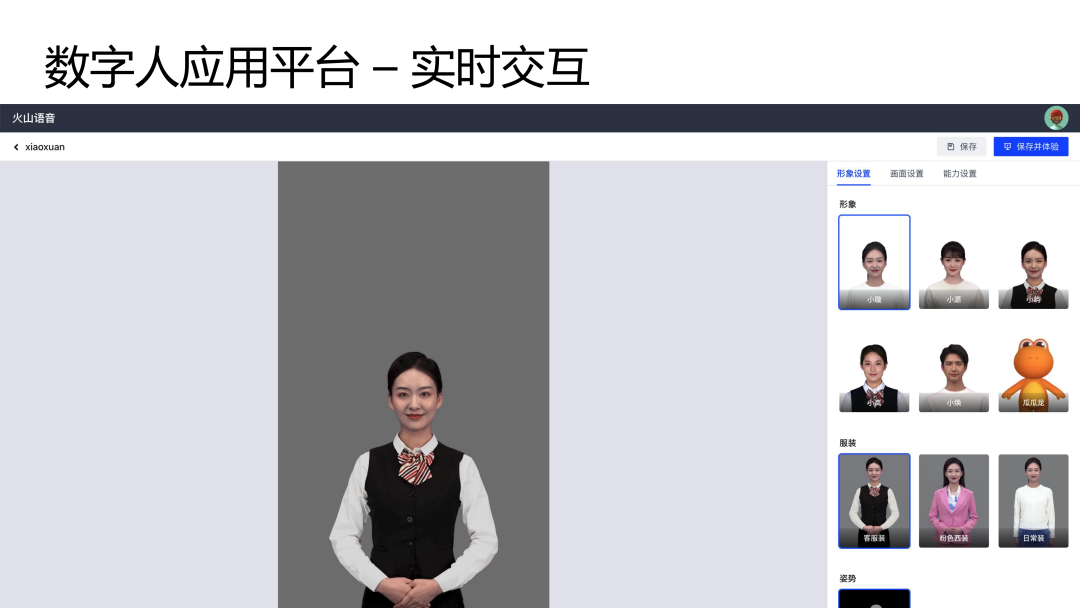
在以上页面支持选择已经支持的数字人形象,包括 2D 数字人形象和 3D数字人形象,选择完成后支持形象设置、画面设置和能力设置,配置完成后保存数字人即可进行实时交互。
以上是视频创作页面,这里包括三个不同的轨道,包括文本轨道、动作轨道和图素轨道。
我们还可以在数字人播报的任意时刻插入指定动作。
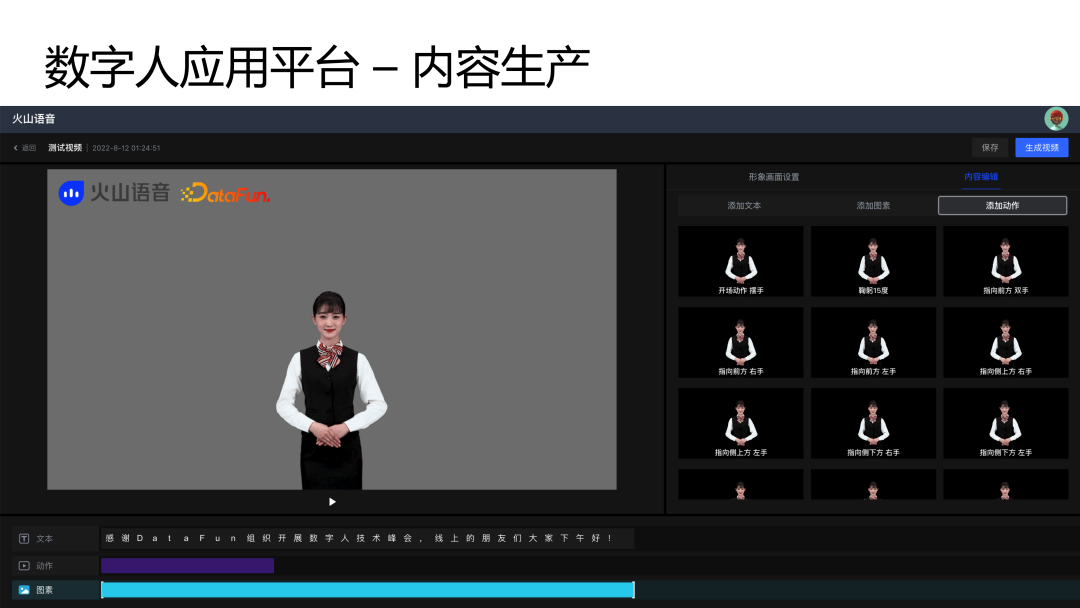
图片素材这部分可以插入 Logo 还有图片视频相关的元素。
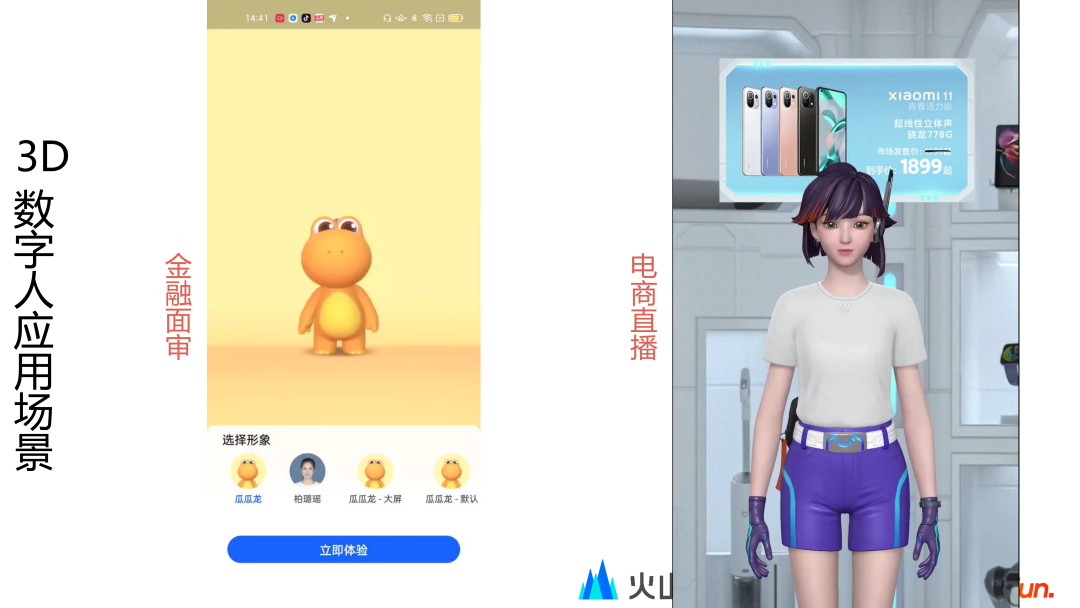
火山引擎数字人也支持应用于金融面审和电商直播等场景。
05/火山引擎虚拟数字人展望

火山引擎虚拟数字人接下来主要有以下方面的展望:
-
提升表现力:2D 数字人支持大姿态面部合成;提升面部合成情感表现力;提升肢体动作表现力。
-
增强感知能力:引入多模态感知能力,包括环境感知、活体检测和人脸识别等相关能力;提升数字人可控度,探索支持大姿态的头部运动,提升数字人适配多模态感知能力输出信号的可控度。
-
加强定制化能力:2D 数字人引入更多人脸相关能力,以便完成更丰富的形象配置;3D 数字人完善引擎能力建设,支持灯光等各类场景特效;3D 数字人探索角色定制,包括捏脸、体型定制、换装换肤等。
-
降低数据成本:积累大数据模型,探索小数据量边界;完善迁移方案,小成本完成成熟能力复制。
今天的分享就到这里,谢谢大家。
分享嘉宾

樊博|字节跳动AI-Lab智能语音 算法研究员
樊博,硕士,西北工业大学优秀毕业生。曾任职于IBM中国研究院、搜狗、Bigo,获得搜狗CEO特别奖等奖励。目前在字节跳动AI-Lab担任算法工程师职位,主要负责多模态数字人整体框架设计与技术迭代,探索ToB、ToC等落地场景。曾在Interspeech、ICASSP等会议发表论文6篇。
![[附源码]计算机毕业设计基于SpringBoot的毕业生就业系统](https://img-blog.csdnimg.cn/89662899c35d4816835a5ba889142b38.png)


![[附源码]计算机毕业设计springboot医院挂号住院管理系统](https://img-blog.csdnimg.cn/7ae5cd8d7dfa4c009e1165a89f1ae39f.png)









![[附源码]计算机毕业设计springboot演唱会门票售卖系统](https://img-blog.csdnimg.cn/9c1c84ef0e3a4f128253c383afac3ed9.png)