操作系统LRU算法
MySQL B+树
哈夫曼编码和解码
C++ 哈夫曼编码 【介绍编码过程】
哈夫曼树编码及其图形化的实现 【使用可视化方式展现最终编码效果】
Python中使用哈夫曼算法实现文件的压缩与解压缩 【Python实现】
哈夫曼树 C语言实现 【图解如何生成】
编码过程
1. 使用二进制流,统计当前文件有哪些字符
如python代码编写所示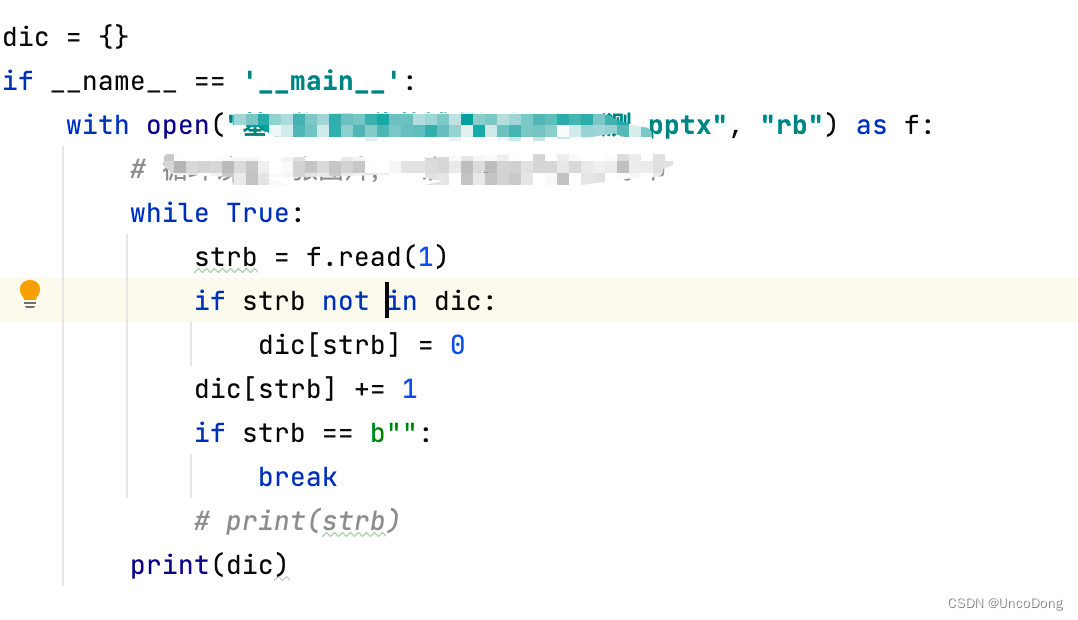

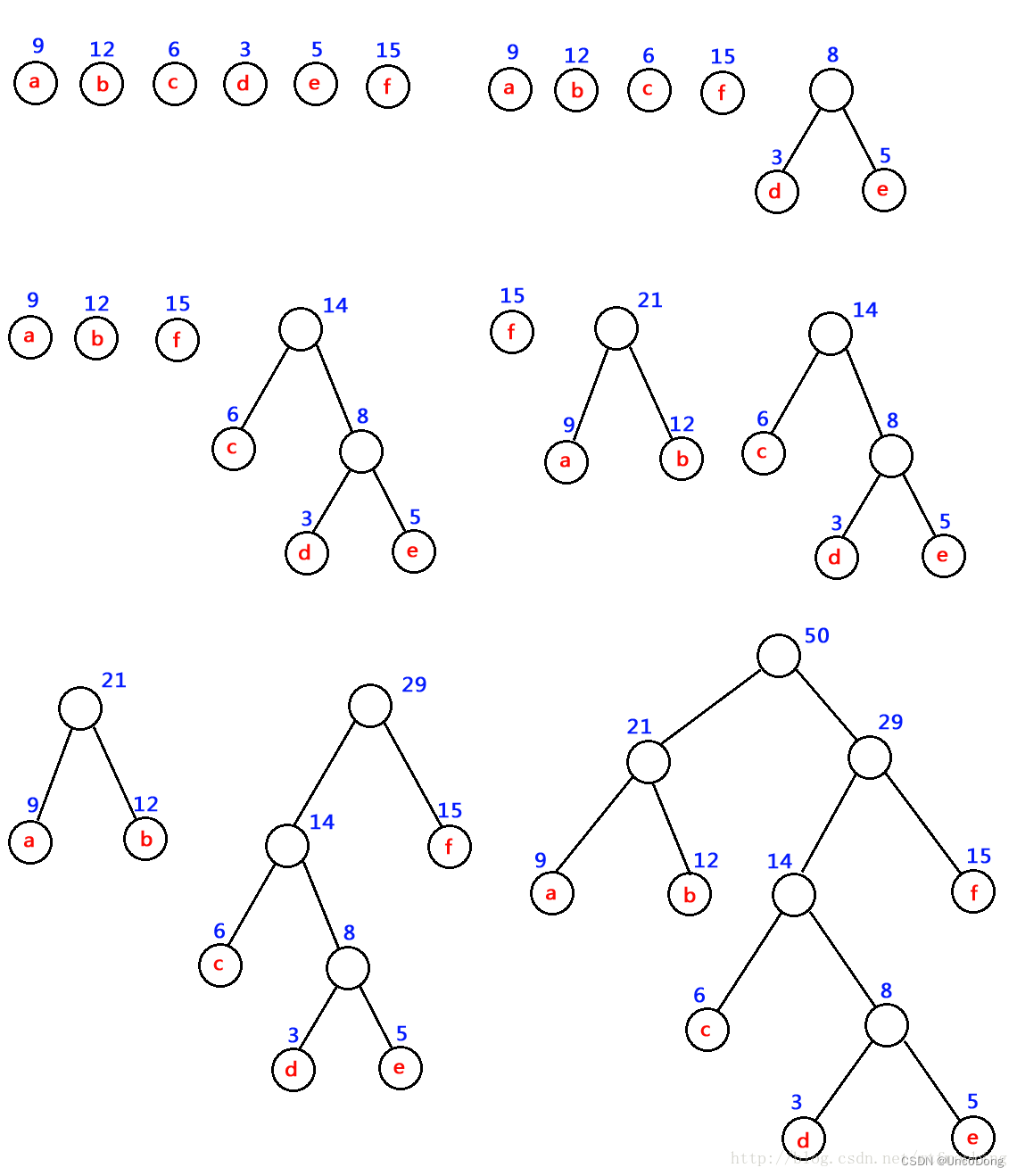
2. 为这些字符生成哈夫曼树。规则:
下文中的w权重,即为该字符的出现次数
(1) 将w1、w2、…,wn看成是有n 棵树的森林(每棵树仅有一个结点);
(2) 在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
(3)从森林中删除选取的两棵树,并将新树加入森林;
(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树。
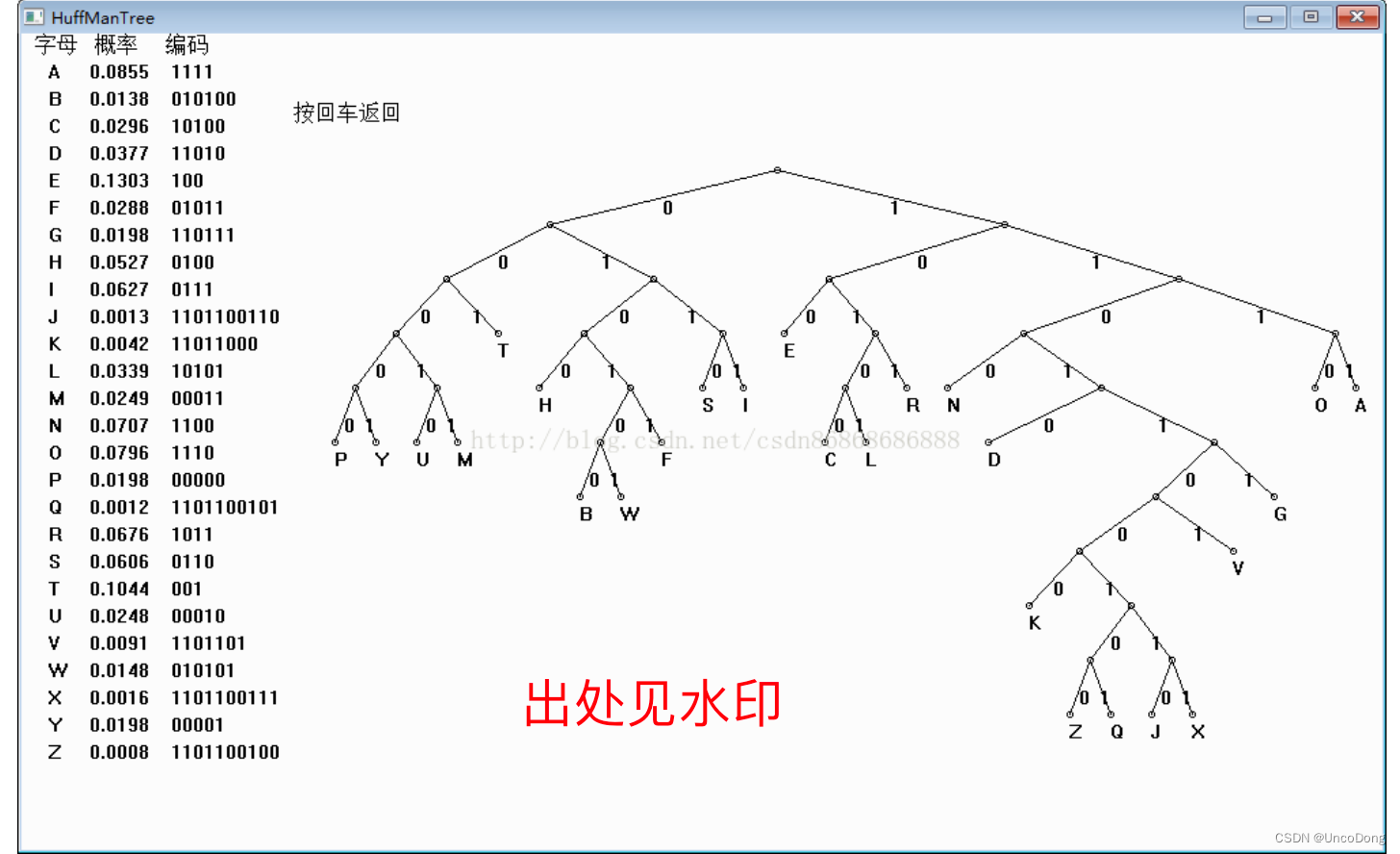
3. 生成编码
- 从叶子结点出发,如果该结点为父结点的左孩子,则在编码追加“0”;如果为其右孩子,则编码追加“1”,
- 编码结束后记得把字符串倒过来。因此编码是从叶子结点从下往上的,而解码需要从根节点从上往下
4. 压缩
压缩的文件头需要保存哈夫曼的信息
- 写入文件的原名
- 写入节点数量
- 计算最大频率的字节数,并写入
- 写入节点和对应频率
- 循环写入数据,每次凑够一个字节
5. 解压
- 读取写入文件名
- 读取节点数量
- 读取位宽
- 根据节点数量和位宽,读取节点和对应频率,重构哈夫曼树
- 循环读取数据,按照哈夫曼编码解码