1. 可视化分析
1.1 概述
可视化分析是数据分析中重要的一环,它可以帮助我们更直观地理解数据的特征、趋势和关系。在Python中,有多个库可以用于数据可视化,包括matplotlib、seaborn和plotly等。
1.2 常用的可视化方法和对应的库:
(1)折线图和曲线图:用于显示数据随时间或其他连续变量的变化趋势。可以使用matplotlib和seaborn来创建这些图形。
(2)柱状图和条形图:用于比较不同类别或组之间的数值。matplotlib和seaborn都可以创建这些图形。
(3)散点图:用于显示两个变量之间的关系和分布情况。matplotlib和seaborn都支持创建散点图。
(4)饼图:用于显示不同类别在总体中的比
例。matplotlib和seaborn都可以创建饼图。
(5)箱线图:用于显示数据的分布情况、中位数、四分位数和异常值等。matplotlib和seaborn都支持创建箱线图。
(6)热力图:用于显示两个变量之间的相关性,颜色的深浅表示相关性的强弱。seaborn和plotly都可以创建热力图。
(7)树状图:用于显示层次结构或分类关系。matplotlib和plotly都可以创建树状图。
这些只是常见的可视化方法,实际上还有很多其他类型的图表和图形可供选择。选择合适的可视化方法取决于数据的特点和分析目的。
2. 去除异常值
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv("./HR.csv")
# 去除异常值
df =df.dropna(how="any",axis=0)
df = df[df["last_evaluation"]<=1][df["salary"]!="nme"][df["department"]!="sale"]
df.head(5)
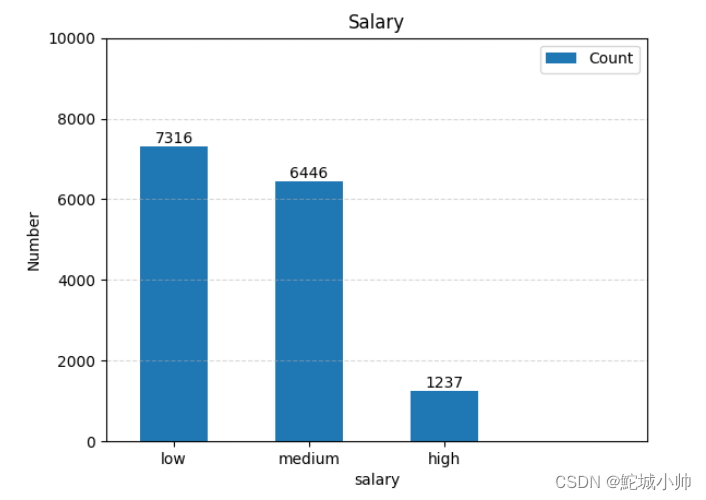
df["salary"].value_counts()3. 柱状图
3.1 matplotlib生成柱状图
以下是对代码进行注释的版本:
```python
import numpy as np
import pandas as pd
# 读取数据
df = pd.read_csv("data/HR.csv")
import matplotlib.pyplot as plt
# 创建柱状图
plt.title("Salary") # 设置图表标题为"Salary"
plt.xlabel("salary") # 设置x轴标签为"salary"
plt.ylabel("Number") # 设置y轴标签为"Number"
# 设置x轴刻度,使用DataFrame中"salary"列的唯一值作为刻度标签
plt.xticks(np.arange(len(df["salary"].value_counts()))+0.5, df["salary"].value_counts().index)
plt.axis([0, 4, 0, 10000]) # 设置坐标轴范围
plt.grid(axis='y', linestyle='--', alpha=0.5) # 添加y轴方向的网格线,线型为虚线,透明度为0.5
# 创建柱状图
plt.bar(np.arange(len(df["salary"].value_counts()))+0.5, df["salary"].value_counts(), width=0.5)
plt.legend(["Count"], loc='upper right') # 添加图例,标注柱状图表示的是"Count"
# 在每个柱状条上添加数值标签
for x, y in zip(np.arange(len(df["salary"].value_counts()))+0.5, df["salary"].value_counts()):
plt.text(x, y, y, ha="center", va="bottom")
# 显示图形
plt.show()执行run()运行代码后生成的柱状图如下:
3.2 seaborn生成柱状图
import numpy as np
import pandas as pd
import seaborn as sns
# 读取数据
df = pd.read_csv("data/HR.csv")
# 去除异常值
df = df.dropna(how="any", axis=0) # 删除含有空值的行
df = df[df["last_evaluation"] <= 1][df["salary"] != "nme"] # 过滤满足条件的数据
df.head(5) # 打印前5行数据
import matplotlib.pyplot as plt
# 设置绘图风格
sns.set(style="whitegrid") # 设置Seaborn的绘图风格为白色背景带网格线
sns.set_context(context="poster", font_scale=0.8) # 设置绘图上下文为poster大小,字体缩放比例为0.8
sns.set_palette("summer") # 设置调色板为summer风格的颜色
sns.set_palette(sns.color_palette("RdBu", n_colors=7)) # 设置调色板为RdBu风格的颜色,共有7种颜色
# 创建计数柱状图
sns.countplot(x="salary", hue="department", data=df) # 根据"salary"列和"department"列绘制计数柱状图
plt.show() # 显示图形
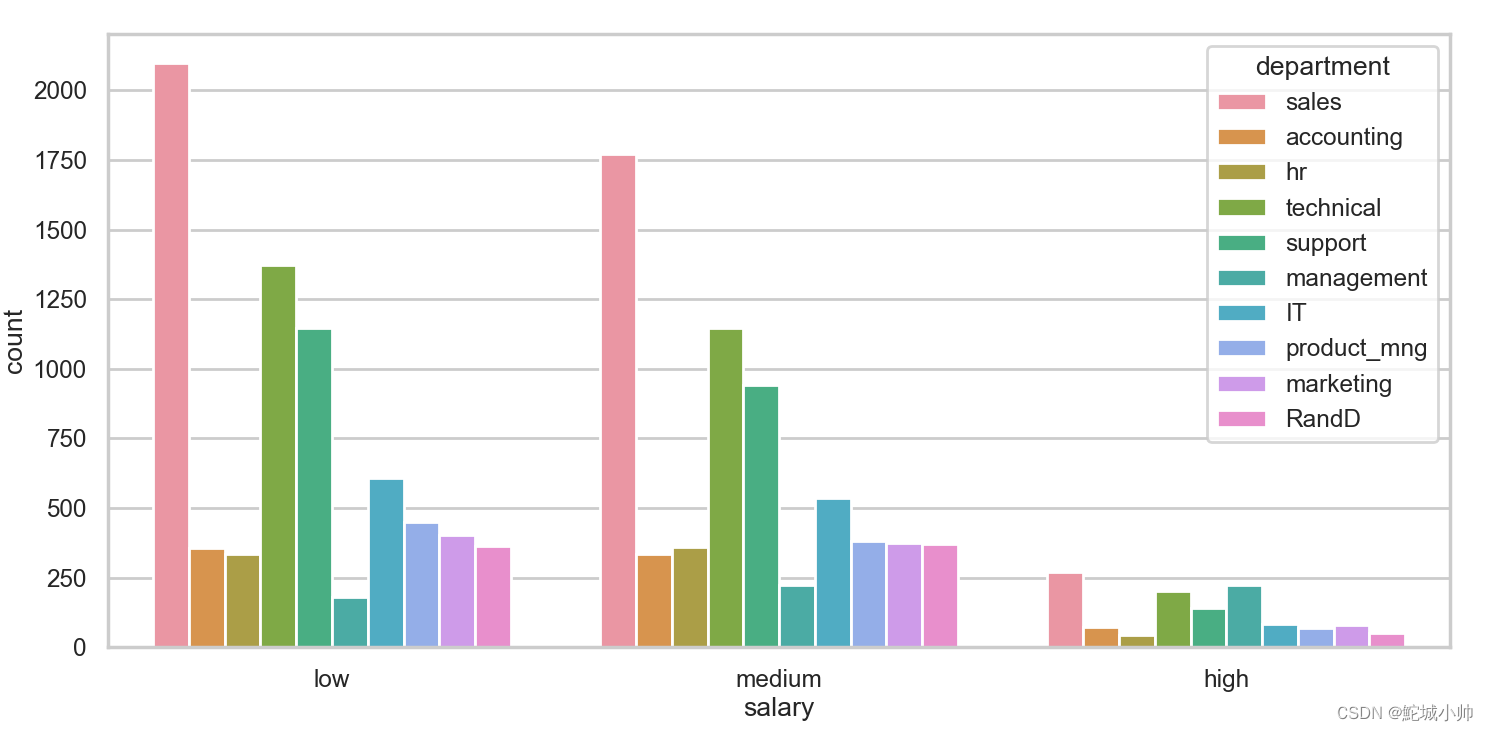
执行run()运行代码后生成的柱状图如下:
4. 直方图
# 读取数据
df = pd.read_csv("data/HR.csv")
# 去除异常值
df = df.dropna(how="any", axis=0)
df = df[df["last_evaluation"] <= 1][df["salary"] != "nme"]
# 设置绘图风格和字体大小
sns.set(style="whitegrid", font_scale=0.8)
# 创建子图,一行三列
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
# 绘制第一个直方图
sns.histplot(df["satisfaction_level"], bins=10, kde=True, ax=axes[0])
axes[0].set_title("Satisfaction Level")
# 绘制第二个直方图
sns.histplot(df["last_evaluation"], bins=10, kde=True, ax=axes[1])
axes[1].set_title("Last Evaluation")
# 绘制第三个直方图
sns.histplot(df["average_monthly_hours"], bins=10, kde=True, ax=axes[2])
axes[2].set_title("Average Monthly Hours")
# 调整子图之间的间距
plt.tight_layout()
# 显示图形
plt.show()
效果图:
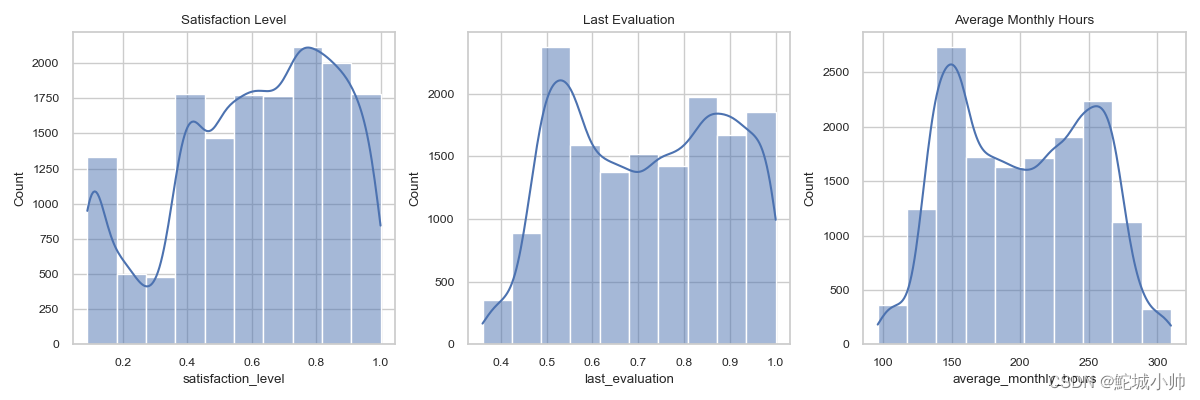
由上图,可以看出:satisfaction_level大部分集中在右边,last_evaluation有个小的波动,每个月的工作时长基本上呈现两极分布。
代码段说明:
sns.histplot(df["average_monthly_hours"], bins=10, kde=True, ax=axes[2])
sns.histplot(): 这是 seaborn 库提供的函数,用于绘制直方图和核密度估计图。df["average_monthly_hours"]: 这是从数据框df中选择 "average_monthly_hours" 列,表示要绘制直方图的数据。bins=10: 这是直方图的箱体数目,指定了将数据划分成多少个等宽的区间。kde=True: 这表示在直方图上绘制核密度估计曲线。核密度估计是一种对数据分布进行平滑估计的方法,可以用曲线表示数据的概率密度分布。ax=axes[2]: 这表示将该直方图绘制在指定的子图axes[2]上。axes[2]是在前面创建的子图数组中的第三个子图。
综合起来,该行代码的作用是在第三个子图上绘制 "average_monthly_hours" 列的直方图,并添加核密度估计曲线。通过指定箱体数目为 10,可以将数据分成 10 个区间,并在图上显示数据的分布情况。
5. 箱线图
# 读取数据
df = pd.read_csv("data/HR.csv")
# 去除异常值
df = df.dropna(how="any", axis=0)
df = df[df["last_evaluation"] <= 1][df["salary"] != "nme"]
# 设置绘图风格和字体大小
sns.set(style="whitegrid", font_scale=0.8)
# 绘制第一个直方图
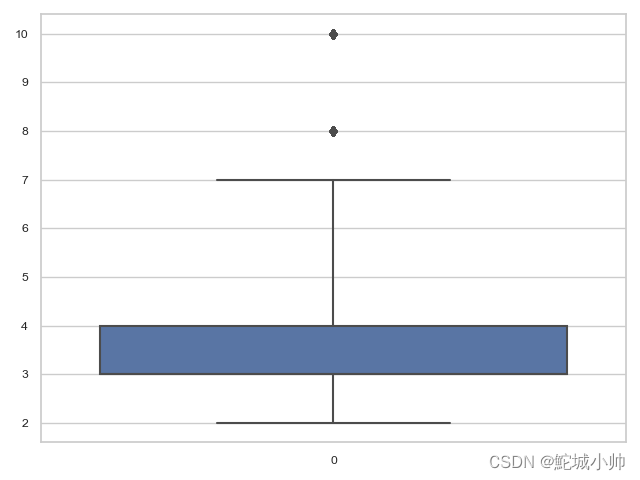
sns.boxplot(df["time_spend_company"], saturation=0.75, whis=3)
# 显示图形
plt.show()
效果图:
6. 折线图
# 读取数据
df = pd.read_csv("data/HR.csv")
# 去除异常值
df = df.dropna(how="any", axis=0)
df = df[df["last_evaluation"] <= 1][df["salary"] != "nme"]
# 设置绘图风格和字体大小
sns.set(style="whitegrid", font_scale=0.8)
# 创建图形和子图
fig, ax = plt.subplots()
# 绘制点图
sns.pointplot(x="time_spend_company", y="left", data=df, ax=ax)
# 设置图表标题和轴标签
ax.set_title("Employee Attrition by Time Spent in Company")
ax.set_xlabel("Time Spent in Company (years)")
ax.set_ylabel("Attrition Rate")
# 调整子图之间的间距
plt.tight_layout()
# 显示图形
plt.show()
效果图:
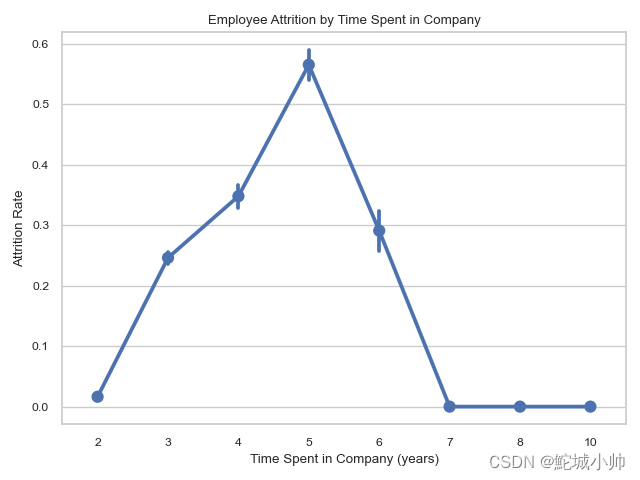
我们可以看到,数据集中的员工在公司呆5年的时候,离职率最高4年其次6年第三所以,5年前后离职率比较大随着时间越来越久,离职率会下来时间越短,离职率也不高。
7. 饼图
# 读取数据
df = pd.read_csv("data/HR.csv")
# 去除异常值
df = df.dropna(how="any", axis=0)
df = df[df["last_evaluation"] <= 1][df["salary"] != "nme"]
# 使用matplotlib绘制饼图,因为seaborn中没有饼图的功能
# 提取部门标签
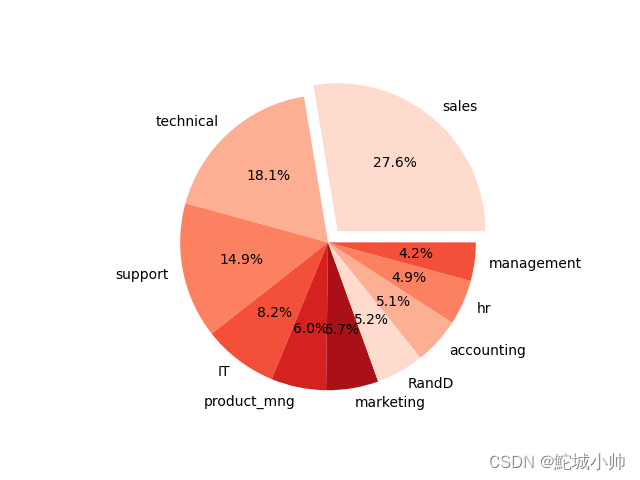
labels = df["department"].value_counts().index
# 设置部门间隔,突出显示某个部门(这里以"sales"为例)
explodes = [0.1 if i == "sales" else 0 for i in labels]
# 绘制饼图
plt.pie(df["department"].value_counts(normalize=True), labels=labels, explode=explodes, autopct="%1.1f%%", colors=sns.color_palette("Reds"))
# 显示图形
plt.show()
效果图:
代码段解析:
plt.pie(df["department"].value_counts(normalize=True), labels=labels, explode=explodes, autopct="%1.1f%%", colors=sns.color_palette("Reds"))
该代码片段使用plt.pie()函数绘制饼图。
-
df["department"].value_counts(normalize=True):该部分计算df["department"]列中每个部门出现的频率,并使用normalize=True将频率转换为百分比,即每个部门在整个数据集中的占比。 -
labels=labels:将部门标签作为参数传递给labels参数,用于标记每个扇区的标签。 -
explode=explodes:explode参数用于控制是否将某个扇区凸显出来。在这里,我们根据部门是否为"sales"来决定是否设置凸显,使用预定义的explodes列表来设置。 -
autopct="%1.1f%%":autopct参数用于控制在饼图中显示每个扇区的百分比值。%1.1f%%表示显示一位小数的百分比值。 -
colors=sns.color_palette("Reds"):colors参数用于设置饼图中每个扇区的颜色。在这里,我们使用sns.color_palette("Reds")生成红色调色板,以便更好地区分不同的部门。
最后,plt.show()用于显示绘制好的饼图。
结尾:除了上述的图形外,还有散点图,气泡图,雷达图等。