深度学习自然语言处理 原创
作者:辰宜
今天下午突然发现了一篇陈丹琦大佬的巨作~ 大家一起来简单瞅瞅。
本文旨在介绍一种用于fine-tuning语言模型(LM)的低内存优化器——MeZO,内存减少多达12倍。使用单个A100 800G GPU,MeZO可以训练一个300亿参数的模型。

论文:Fine-Tuning Language Models with Just Forward Passes
地址:https://arxiv.org/abs/2305.17333
代码:https://github.com/princeton-nlp/MeZO
过去的方法存在的问题,用于优化大型LM的反向传播算法需要大量的内存,因此需要一种低内存优化器。
本文提出的MeZO算法是一种低内存零阶优化器,通过SPSA算法来计算梯度估计,仅需要两次前向传递。MeZO算法可以在不影响LM性能的情况下,大幅减少内存占用,优化各种模型和下游任务。
方法与实验
本文的MeZO算法是基于零阶优化的理论基础。

MeZO算法基于SPSA算法的低内存优化器,通过同时扰动每个权重矩阵来节省计算时间,并且可以与其他梯度优化器结合使用,例如SGD with momentum和Adam。
其在各种模型和下游任务中表现出色,相比于Adam的完全fine-tuning,性能相当,并大幅降低了内存成本。MeZO还可以优化非可微分目标,并且适用于全参数调整和前缀调整。
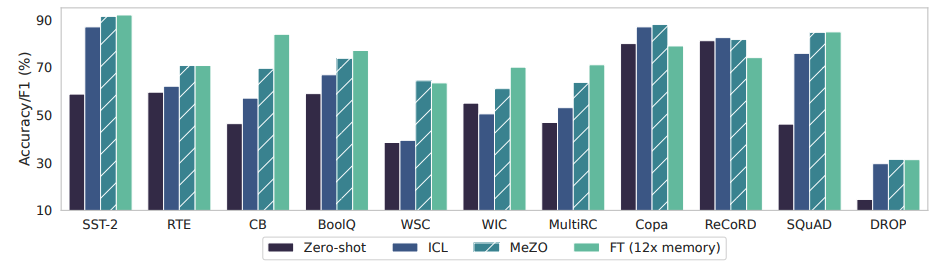
下面看下所有的实验情况:
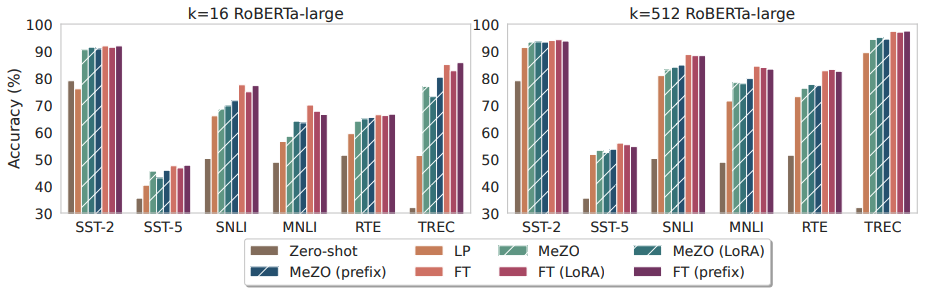
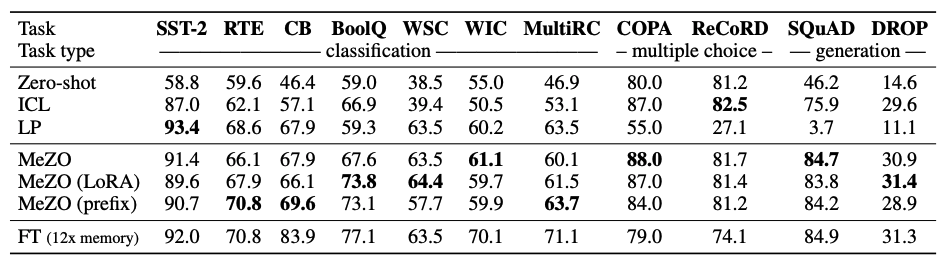
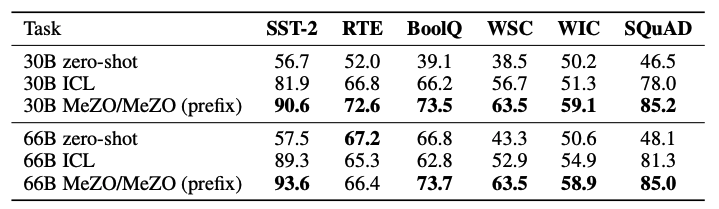
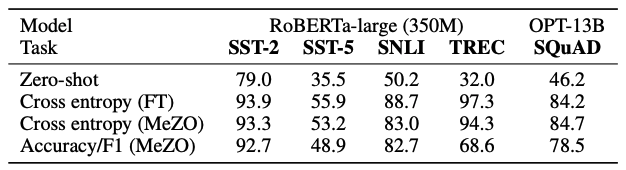
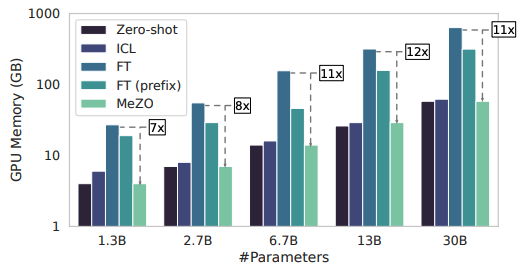
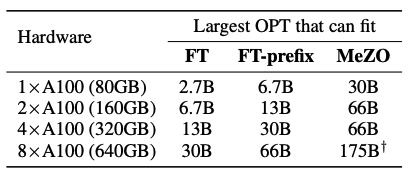
做个总结
最后总结下本文的所有内容:
MeZO算法可以极大的减少内存的使用,并不影响LM性能。
用零阶优化理论可以优化具有高维参数的大型LM。
基于全局和局部有效秩,可以证明零阶随机梯度下降的收敛速度,以及全局收敛速度会因有效秩而变慢。
接下来需要将MeZO和其他低内存方法相结合,并研究MeZO在其他领域(如精简和数据集选择)中的适用性。
这可是个大创新,又向人人都能训练大模型迈进一大步,好开心~
进NLP群—>加入NLP交流群