作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263?spm=1001.2101.3001.5343
邮箱 :291148484@163.com
本文地址:https://blog.csdn.net/qq_28550263/article/details/130877490
提示:当前尚未完成。可过两天后查看。
【介绍】:本文讲解 有限状态机(FSM)相关理论以及其在Rust 语言中的应用。
目 录
- 1. 概述
- 2. FSM 的两大类别
- 3. 好的建模是设计状态机的关键
- 3.1 理解 状态 是状态机建模的开始
- 3.2 “李华打球” 建模实战
- 3.3 建模流程与方法归纳
- 3.3.1 FSM 建模的通用流程
- 3.3.2 FSM 中的状态编码
- 1. 编码的目的
- 2. 编码的原则
- 3. 最省字节的编码:二进制数码
- 4. 高识别性的编码:独热码
- 5. 其它在 bit 层面的编码
- 6. 十进制数码
- 7. 字符串编码
- 8. 枚举编码
- 9. 其他自定义类型编码
- 3.3.3 使用 Visio 绘制标准的 UML 状态图
- 1. 关于 Visio
- 2. 使用Visio绘制标准的UML状态图
- 打开 Visio 的 UML状态图模板
- 添加状态
- 4. 状态机的实现方式类别
- 5. 基于条件语句的状态机 从理论到实战
- 6. 表驱动状态机 从理论到实战
- 7. 状态模式 从理论到实战
- 8. 事件驱动状态机 从理论到实战
- 9. 使用拆分法:编写 主从状态机
1. 概述
1.1 有限状态机简介
有限状态机(Finite State Machine,简称为 FSM)是一种抽象的计算模型,是一个来源于离散数学中的思想,它用于描述系统或对象在不同状态之间转换的行为。
它由一组状态、转移条件 和 动作 组成。其中:
- 状态:表示系统或对象所处的特定情况;
- 转移条件:定义了从一个状态到另一个状态的条件,在数字系统中它往往是外部输入(摩尔),以及自身的状态输出(米利);
- 动作:表示在状态转换发生时执行的操作。在基于有限状态机的数字电路系统设计中,动作 往往称之为 输出。(笔者是学电的出生)
1.2 有限状态的应用场景
有限状态机在软件以及硬件开发中有广泛的应用。
在电子信息工程中,实现有限状态机可以用于描述通信协议的不同状态和状态之间的转换,例如网络协议、串口通信协议等。
在用户界面设计领域,有限状态机可用于管理用户交互的不同状态,例如表单输入的验证、页面导航等。在游戏开发方向,游戏中的角色、游戏流程等可以使用有限状态机进行建模和管理。
在文本处理领域,状态机更是非常实用。我们可以轻松地使用状态机进行及其复杂的文本分析,比如使用状态机实现正则表达式(实际上很多语言提供的正则表达式底层大量使用了状态机实现),又或者是在计算机语言编译或者解释时完成 抽象语法树(AST)的构建。
在自动化控制系统中实现中,有限状态机可以描述设备或机器的工作状态和状态转换规则。
在计算机的核心部件——芯片设计中,有限状态机更加是占据相当重要的地位。笔者最早接触有限状态机大概在 2015 年还在学校学习数字电路设计的时候。当时我们使用 有限状态机 以及 EDA 技术,通过 FPGA 完成各种数字电路的设计作业。
2. FSM 的两大类别
依据有限状态机的状态是否与输出有关,将其分为两大类:莫尔型状态机(Moore State Machine)和 米利型状态机(Mealy State Machine)。
2.1 莫尔型状态机
在 莫尔型状态机(Moore State Machine)中,状态机的输出仅取决于当前状态,与输入无关。每个状态都定义了固定的输出动作,与状态转换无关。
2.2 米利型状态机
在 米利型状态机 (Mealy State Machine)中,状态机的输出取决于当前状态和输入。每个状态都可以定义输出动作,它们可以随着状态转换而改变。
3. 好的建模是设计状态机的关键
3.1 理解 状态 是状态机建模的开始
笔者在本文的开篇 1.1 有限状态机简介 中提到:状态:表示系统或对象所处的特定情况。这听起来还有一些抽象,因此本节带领大家进一步剖析何谓 状态。
3.2 “李华打球” 建模实战
从我们人类自生的生活中的心情情况来理解 状态,以前我写过一篇介绍机器学习划分数据集的博客(https://blog.csdn.net/qq_28550263/article/details/114892718),给出过这样一个例子:
李华是否打球的决策
以下是李华在过去9天是否打球的历史数据:

上次我们是从决策的角度引出了 决策树 的思想,这次我们仍然使用这个例子(笔者懒得画其它的图了),通过 状态机 的视角来分析与建模。
在这个例子中,其实只有 心情 一项是与李华自身因素有关的,而 是否上课、天气 相对于李华,都可以看作 外部条件。
因此,我们不妨考虑:
- 将李华的 心情 抽象为不同的状态(显然,这是几个状态可以看作是离散的取值点);
- 将 有课与否、天气情况,看作是 外部输入;
- 将 打球与否 看作是 输出(动作)。
- 将编号看成日期序号,表示时间尺度上的变化,体现后一个状态与前一个状态之间的逻辑;
- 假定日期序号切换,状态切换;
现在我们可以依据这九天的李华心情收到输入变化的规律做出以下 变化规律图:

这就是所谓 状态转换图,简称为 状态图。
得到 状态图 后,我们需要将状态变为 计算机能够接受的东西——毕竟计算机也不能理解人类的心情(即使AI也同样需要对现实数据进行抽象)。
实际上,在计算机内部,它并不会关心你状态文字表述的背后含义,仅仅需要机械式地考虑以区分状态的不同。因此对于建模人员来说,我们往往考虑使用最计算机中简单的东西去表示状态,这个过程就称之为 编码。编码方式有很多种,如最省字节的 独热码,等等。不过在软件开发中,出于对编码者的友好,我们更多地使用的是以有具体含义的 字符串 来标识状态。关于 编码 的更多内容我们将在后面继续讨论。
3.3 建模流程与方法归纳
3.3.1 FSM 建模的通用流程
通过上面给出的小案例,我们已经对从时间经过分析到绘制状态转换图的过程有了一定的了解。
对事物建立状态机模型可以通过以下几个步骤完成:
-
分析归纳:通过对事物的行为进行观察和分析,确定状态和状态转换条件,并将其抽象为状态机模型。
-
制作状态表格:将状态和状态转换以表格的形式表示,表格中列出了所有可能的输入和对应的状态转换。
-
绘制状态转换图:使用状态图(State Diagram)绘制状态和状态转换的图形表示。状态图使用状态节点表示状态,使用箭头表示状态之间的转换条件和动作。绘制状态图时,可以使用 UML(Unified Modeling Language)标准中的状态图符号和表示法。在状态图中,状态以圆角矩形或椭圆形节点表示,状态之间的转换使用箭头表示,并标注转换条件和动作。此外,还可以使用初始状态和终止状态符号表示状态机的起始和结束点。
-
编码状态:有限状态机中的 状态 是离散的有限取值,这样我们可以将其一一列出来,通过一种能区分每个状态的方式对他们进行标识。
3.3.2 FSM 中的状态编码
1. 编码的目的
通过对状态的编码,实现让每一个状态都有自己的 唯一标识符,这个唯一标识符是我们接下来编程中区别不同状态的基础。
2. 编码的原则
原则是依据目的所拟出来的,最重要的一点就是能够区分所有的不同状态以达到能够作为 唯一标识符的目的。此外,我们还希望状态机的编码尽可能让我们自己好理解,这样能够便于维护,等等。归纳起来,在有限状态机中对状态进行编码时,需要注意以下原则:
-
唯一性:每个状态的编码应该是唯一的,不与其他状态冲突。确保每个状态都有一个独立的编码,以避免混淆和歧义。
-
可读性:状态编码应该具有良好的可读性,便于人类理解和记忆。使用清晰、有意义的命名方式,以便于开发人员阅读和维护状态机代码。
-
紧凑性:尽可能使用较短的编码来表示状态,以减少存储和传输的开销。对于状态数量较多的情况,可以考虑使用压缩编码方式,如独热码。
-
顺序性:状态编码的顺序应该与状态转换图中状态的顺序保持一致,便于查找和对比不同状态之间的关系。
-
扩展性:为了支持未来的扩展和变更,状态编码应该设计为可以扩展的形式。确保在需要添加新状态时,能够方便地进行编码的扩展而不会影响现有的编码。
-
一致性:在整个状态机中,保持状态编码的一致性。即相同的状态在不同的上下文中应该具有相同的编码,以避免混淆和错误。
-
编码冲突的解决:当出现状态编码冲突时,需要采取适当的解决措施,例如使用更长的编码、重新设计编码方案或使用其他编码方式。
考虑以上这些原则可以帮助设计和实现清晰、可读性高且易于维护的有限状态机。根据具体的应用场景和项目需求,可以选择合适的编码方式和策略。
3. 最省字节的编码:二进制数码
首先我要告诉各位读者的是,在实际开发尤其是软件领域,几乎没有使用二进制码来标识状态的,但是这种编码方式包含了一个思想,即 在计算机底层是怎么考虑最小区分不同事物的。
二进制数码(Binary Encoding)是一种使用自然二进制数进行编码的方式。学过数字电路的读者对于二进制可谓很熟悉了,与十进制数中有 0-9 这十个数码不一样,二进制数只有 0、1 这两个数码,并且1就进位。
在 1 位二进制数中,它有两个数码:0、1,因此使用 1 位二进制数最多 可以标识 21 个不同的状态。
类似地,2位 二进制数中,一共有 00、01、10、11这四个数字,因此最多 可以标识 22 个不同地状态。
以此类推,n位 二进制数 最多 可以标识 2n 个不同的状态。
这是我们在编码时考虑使用多少个 bit 的理论依据。
4. 高识别性的编码:独热码
虽然同样是在 bit 层面考虑,但是与二进制数编码将 bit 用到极致不一样,独热码为了提升状态的可识别性,规定 n 位独热码中最多有且只有1位为1,其余位全为0。
比如:
2位独热码有:01、10,这2个状态
3位独热码有:001、010、100,这3个状态
4位独热码有:0001、0010、0100、1000,这4个状态
以此类推,
n 位独热码一共仅仅可以表示 n 个状态。
独热码在状态数量较多时仍然保持编码长度的最小化,并且具有良好的可识别性。然而,随着状态数量增加,独热码的编码长度将线性增长,可能导致较高的存储和计算成本。
5. 其它在 bit 层面的编码
在 bit 层面的编码方式还有很多如:
-
8421码(BCD码):BCD码是二进制编码的十进制表示方式,每个十进制数字使用4位二进制进行编码。BCD码中的每一位表示十进制数中的一个数字,范围为0-9。例如,数字7用BCD码表示为0111。
-
5421码:5421码也是一种二进制编码的十进制表示方式,每个十进制数字使用4位二进制进行编码。不同于BCD码,5421码中的每一位表示十进制数中的权重,分别为5、4、2和1。通过将权重位上的二进制数相加,可以得到对应的十进制数字。例如,数字7用5421码表示为0111。
等等。
6. 十进制数码
需要指出的是,bit 表示的是由 0/1 表示的一个二进制位,是计算机存储的最小的单元。而 1 Byte 相当于 8 bit,是我们操作数据的最小单元。由于我们几乎不会直接在 bit 层面对数据进行手动修改。因此,不论是 二进制数码 还是 独热码 等等这类基于操作 bit 的编码方式都不会在软件开发中用到。嗯,除非你是搞硬件开发的。
有二进制数编码则当然可以有十进制数码,这在编程语言中都是直接支持的。与二进制数编码方式类似:
n位 十进制数 最多 可以标识 10n 个不同的状态。
这是我们在编码时考虑至少要几位十进制数才能表示我们所有状态的理论依据。
需要指出的是,在软件开发领域,这种使用整数来表示状态,如 0、1、2 等。每个状态都对应一个唯一的数字编码。这种编码方式简单直观,易于理解和实现。但是当状态数量较多时,数字编码可能变得晦涩难懂,不易于维护和调试。
以下是一个使用十进制数编码状态的例子:
const STATE_0: u32 = 0;
const STATE_1: u32 = 1;
const STATE_2: u32 = 2;
fn main() {
let state: u32 = STATE_2;
match state {
STATE_0 => {
println!("Current state is STATE_0");
},
STATE_1 => {
println!("Current state is STATE_1");
},
STATE_2 => {
println!("Current state is STATE_2");
},
_ => {
println!("Invalid state");
},
}
}
7. 字符串编码
使用字符串来表示状态,每个状态对应一个唯一的字符串。字符串编码具有较好的可读性和可理解性,易于扩展和维护。使用字符串编码时,可以使用有意义的状态名称来提高代码的可读性。但是字符串编码可能会增加内存消耗,并且比较操作可能较慢。
以下是一个使用字符串编码状态例子:
const STATE_0: &str = "State0";
const STATE_1: &str = "State1";
const STATE_2: &str = "State2";
const STATE_3: &str = "State3";
fn main() {
let state: &str = STATE_2;
match state {
STATE_0 => {
println!("Current state is STATE_0");
},
STATE_1 => {
println!("Current state is STATE_1");
},
STATE_2 => {
println!("Current state is STATE_2");
},
STATE_3 => {
println!("Current state is STATE_3");
},
_ => {
println!("Invalid state");
},
}
}
8. 枚举编码
在 Rust 语言中恰好为我们提供了 枚举,因此我们还可以使用 枚举 来表示状态,每个状态都是枚举的一个成员。
枚举编码提供了更具可读性的状态表示方式,使得状态的含义更加清晰。同时,枚举编码也避免了数字编码的晦涩性。
但是有时候当状态数量较多时,枚举编码可能导致代码冗长,并且不够灵活。
以下是一个使用枚举编码状态的例子:
enum State {
A,
B,
C,
}
fn main() {
let mut state = State::A;
loop {
match state {
State::A => {
println!("In state A");
state = State::B;
}
State::B => {
println!("In state B");
state = State::C;
}
State::C => {
println!("In state C");
state = State::A;
}
}
}
}
9. 其他自定义类型编码
只要能够有效地区分状态,在使用有限状态机时,你当然可以自定义一种编码类型对状态进行编码。
有时候,通过定义状态类型的属性和方法,可以更灵活地表示和操作状态。自定义类型编码可以提供更多的语义和上下文信息,使代码更易于理解和维护。不过自定义类型编码可能会增加代码设计的难度,要求开发者需要有更多的设计经验。
最后需要指出的是,每种状态编码方式都有其适用的场景和优缺点。选择适合的编码方式取决于具体的需求和项目要求。在实际应用中,可以根据状态机的复杂度、可读性需求、代码维护性等因素来选择合适的编码方式。在某些情况下,也可以结合不同的编码方式来满足不同的需求。
3.3.3 使用 Visio 绘制标准的 UML 状态图
1. 关于 Visio
Visio是一款流程图和图表绘制工具,由微软公司开发。它提供了丰富的图形和模板库,使用户能够创建各种类型的图表,包括流程图、组织结构图、网络图、UML图等。Visio的用户界面直观易用,适合专业人士和非专业人士使用。
在绘制UML(统一建模语言)方面,Visio是一个常用的工具。UML是一种用于软件系统建模的标准化语言,用于描述系统的结构、行为和交互。Visio提供了专门用于UML的模板和工具,使用户可以轻松地创建各种UML图,如用例图、类图、时序图、活动图和状态图等。
通过Visio的UML模板和工具,用户可以按照UML标准绘制各种UML图形,并使用图形符号和关系来表示系统的不同方面。用户可以添加和连接各种UML元素,如类、接口、对象、状态、行为和关系等。此外,Visio还提供了布局、样式和注释等功能,使用户能够改善图形的外观和可读性。
目前 Visio 几乎是出版界的标准工具,就行 Auto CAD 是工业制图界的标准工具。使用 Visio 绘制 UML 图的的优势在于
- 可视化:通过图形化表示,更直观地展示系统的结构和行为。
- 易于理解:UML图形符号和关系具有标准化的含义,使得其他人能够快速理解和解读图形。
- 可编辑性:Visio提供了编辑和修改UML图的功能,使用户能够灵活地调整和更新图形。
- 可扩展性:Visio支持添加新的UML元素和自定义符号,以满足不同项目的需求。
并且现在很多国内的相关软件也基本是跟着 Visio 的动态走。不断地被各种友商所模仿。
2. 使用Visio绘制标准的UML状态图
打开 Visio 的 UML状态图模板
首先你需要打开Visio:启动Visio并选择“新建”以创建新的绘图。
选择UML状态图模板:在Visio中,选择“流程图”类别,然后选择“UML状态图”模板。这将为您提供一个空白的UML状态图画布。
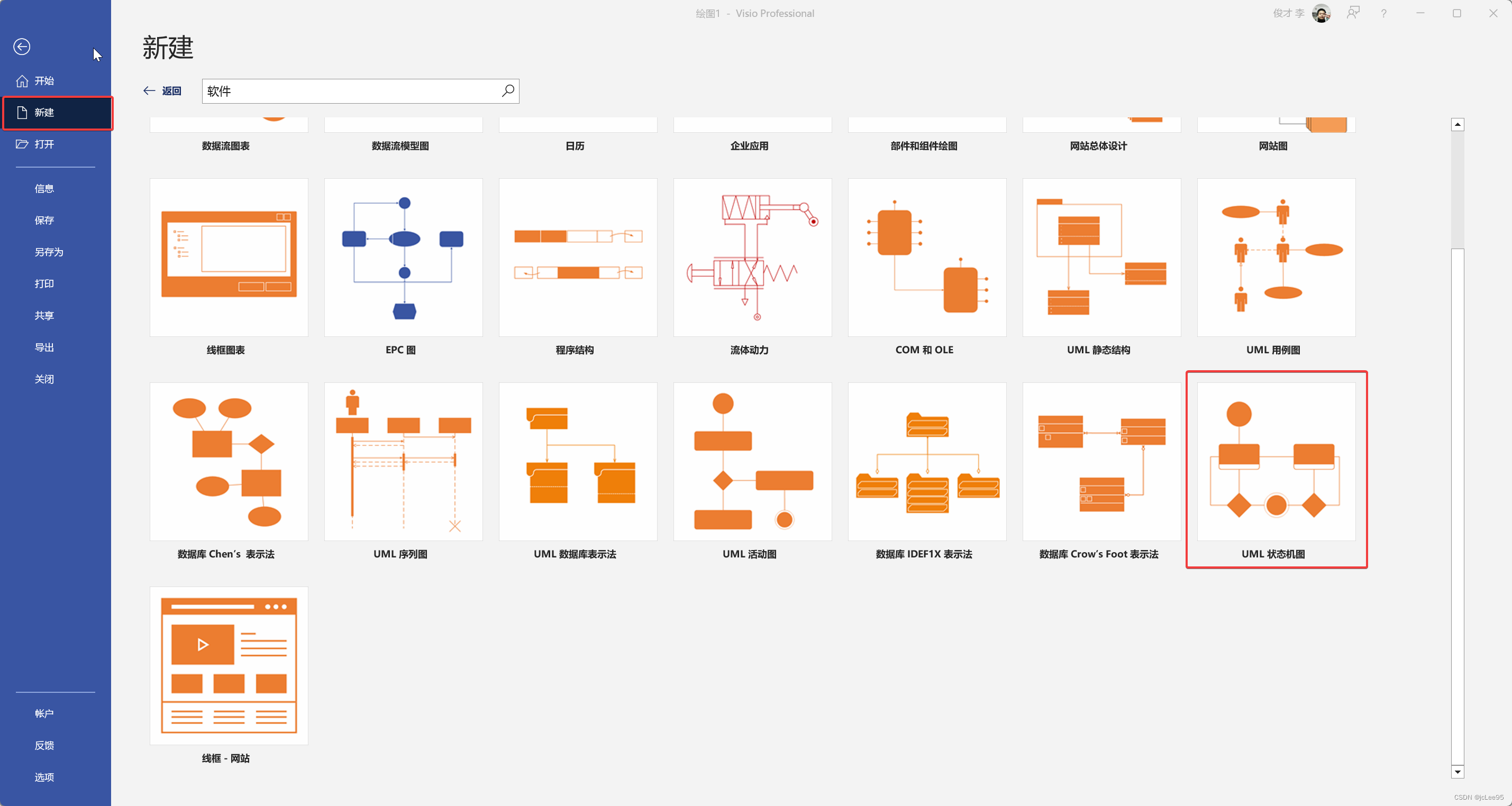
添加状态
4. 状态机的实现方式类别
在 软件设计中1 根据实现方式的不同,有限状态机可以分为以下几种类型:表驱动状态机、基于条件语句的状态机、基于状态模式的状态机、事件驱动状态机:
-
基于条件语句的状态机(Conditional Statement-Based State Machine):使用条件语句(例如 if-else、switch(相当于 rust 中用 match))来定义状态转换和动作执行逻辑。
-
表驱动状态机(Table-Driven State Machine):使用状态转换表来定义状态和转换条件,通过查表实现状态转换和动作执行。
-
状态模式(State Pattern):利用 面向对象编程的特性,将* 状态* 封装为 对象,并通过状态对象之间的切换实现状态转换和动作执行。
-
事件驱动状态机(Event-Driven State Machine):基于事件和事件处理机制来驱动状态转换和动作执行,常见于异步编程和事件驱动的系统中。
本节我们先给出分类,在后面的章节中,我们将一一讲解并给出实际案例。
5. 基于条件语句的状态机 从理论到实战
5.1 基于条件语句的状态机 简介
基于条件语句的状态机(Conditional Statement State Machine)通过在 不同的状态下 执行不同的条件语句 来 实现状态的转换和相关逻辑。
每个状态由一个或多个条件语句来描述,并且根据条件语句的结果选择下一个状态。状态机中的状态和状态之间的转换通常通过条件判断来确定。
5.1.1 优势
这种状态机具有以下优点:
- 简单直观:基于条件语句的状态机实现相对简单,易于理解和调试。状态和状态转换的逻辑直接体现在条件语句中,代码结构清晰明了。
- 灵活性:使用条件语句可以方便地对每个状态进行个性化的处理,根据不同的条件执行不同的代码逻辑。可以灵活地根据具体需求来设计和修改状态机。
5.1.2 缺陷
当然它还具有以下不足:
- 可读性 和 可维护性:随着状态机的状态和转换规则的增加,条件语句的数量和复杂度可能会迅速增加,导致代码可读性和可维护性下降。维护大型状态机可能会变得困难。
- 扩展性:当需要添加新的状态或修改现有状态时,可能需要修改大量的条件语句,可能会导致代码的脆弱性增加。随着状态机的增长,添加新状态或修改现有状态的复杂度会增加。
5.1.3 适用情况
这种方式适用于 简单 和 小型 的 状态机,逻辑相对直观和简单的情况下,实现简单且易于理解。但对于复杂的状态机,特别是具有大量状态和状态转换的情况,使用条件语句实现可能会导致代码的可读性、可维护性和扩展性的问题。在这种情况下,使用其他更为结构化和模块化的状态机实现方式,如表驱动的状态机或基于类和方法的状态机,可能更合适。
5.2 基于 INI 文件进行建模
5.1.1 INI 文件格式解析
INI(Initialization)文件格式是一种常见的配置文件格式,用于存储和组织应用程序的配置信息。它由一系列的配置项组成,每个配置项由一个键值对表示。INI文件采用了一种分区(Section)的结构来组织配置项,允许将相关的配置项归类到不同的部分。
以下是INI文件中的主要元素:
-
Section(部分):Section是INI文件中的顶层结构,用于将相关的配置项进行分组。Section由方括号([])括起来,并位于配置项之前。Section的名称在方括号内,并且通常是唯一的,用于标识不同的配置区域。
示例:
[Section1] -
Property(属性):Property是配置项的键值对,表示具体的配置信息。每个Property由一个键(Key)和一个值(Value)组成,中间使用等号(=)分隔。键用于标识配置项,值则表示配置项的具体数值。
示例:
Key1 = Value1 -
Comment(注释):Comment是INI文件中的注释部分,用于提供对配置的说明和备注。注释通常以分号(;)开头,可以在Section、Property或文件任意位置使用。注释不会影响配置项的解析,仅作为文档的一部分。
示例:
; This is a comment -
其他规则:
- 空行:INI文件中的空行会被忽略,可以用于提高可读性和分隔配置区域。
- 键值对的格式:键值对之间使用等号(=)进行分隔,键和值两侧可以有空格,但通常是不包含空格的。
- 键和值的转义:在键或值中包含特殊字符时,可以使用转义字符进行处理,如
\n表示换行符。 - 多行值:有些INI解析器支持多行值,可以使用特定的转义字符或换行符来表示一个跨越多行的值。
INI文件格式的简洁性和易读性使其广泛应用于各种应用程序的配置文件、设置文件等场景。虽然INI文件没有严格的规范和标准,但通常可以通过解析器来解析和处理INI文件,以获取其中的配置信息。
use std::collections::HashMap;
// 定义状态枚举
enum StatesEnum {
Start, // 起始状态,表示解析器刚开始解析INI字符串
Section, // 节状态,表示当前解析的是节(section)
Property, // 属性状态,表示当前解析的是属性(property)
Comment, // 注释状态,表示当前解析的是注释
}
fn parse_ini_string(input: &str) -> HashMap<String, HashMap<String, String>> {
// 初始化解析器的状态和其他变量
let mut state = StatesEnum::Start;
let mut current_section = String::new();
let mut properties: HashMap<String, HashMap<String, String>> = HashMap::new();
let mut comments: HashMap<String, Vec<String>> = HashMap::new();
// 遍历输入的每一行
for line in input.lines() {
let line = line.trim();
// 如果行以 ';' 开头,表示是注释行
if line.starts_with(';') {
// 提取注释内容,并根据当前状态将注释添加到对应的section中
let comment = line[1..].trim().to_owned();
match state {
StatesEnum::Start | StatesEnum::Section | StatesEnum::Property => {
comments
.entry(current_section.clone())
.or_insert_with(Vec::new)
.push(comment);
}
_ => {}
}
state = StatesEnum::Comment;
}
// 如果行以 '[' 开头并以 ']' 结尾,表示是section行
else if line.starts_with('[') && line.ends_with(']') {
// 提取section名称,并更新当前section变量
let section = line[1..line.len() - 1].trim().to_owned();
current_section = section.clone();
// 在properties中插入新的section,并初始化该section的属性HashMap
properties.entry(section).or_insert_with(HashMap::new);
state = StatesEnum::Section;
}
// 如果行包含 '=',表示是属性行
else if let Some(index) = line.find('=') {
// 提取key和value,并将其添加到当前section的属性HashMap中
let key = line[..index].trim().to_owned();
let value = line[index + 1..].trim().to_owned();
properties
.entry(current_section.clone())
.or_insert_with(HashMap::new)
.insert(key, value);
state = StatesEnum::Property;
}
// 其他情况下,表示是注释行或空行
else {
// 根据当前状态将注释添加到对应的section中
match state {
StatesEnum::Start | StatesEnum::Section | StatesEnum::Property => {
let comment = line.to_owned();
comments
.entry(current_section.clone())
.or_insert_with(Vec::new)
.push(comment);
}
_ => {}
}
state = StatesEnum::Comment;
}
}
properties
}
上面的 if-else 语句该用 后,以后会更好维护:
use std::collections::HashMap;
// 定义状态枚举
enum StatesEnum {
Start, // 起始状态,表示解析器刚开始解析INI字符串
Section, // 节状态,表示当前解析的是节(section)
Property, // 属性状态,表示当前解析的是属性(property)
Comment, // 注释状态,表示当前解析的是注释
}
// 解析 INI 字符串
fn parse_ini_string(input: &str) -> HashMap<String, HashMap<String, String>> {
let mut state = StatesEnum::Start;
let mut current_section = String::new();
let mut properties: HashMap<String, HashMap<String, String>> = HashMap::new();
let mut comments: HashMap<String, Vec<String>> = HashMap::new();
// 逐行处理文本
for line in input.lines() {
let line = line.trim();
// 描述各个状态的转换规律
match state {
// 起始状态(Start)
StatesEnum::Start => {
// 如果行以 ';' 开头,则为注释
if line.starts_with(';') {
let comment = line[1..].trim().to_owned();
comments
.entry(current_section.clone())
.or_insert_with(Vec::new)
.push(comment);
state = StatesEnum::Comment;
}
// 如果行以 '[' 开头,以 ']' 结尾,则为节(section)
else if line.starts_with('[') && line.ends_with(']') {
let section = line[1..line.len() - 1].trim().to_owned();
current_section = section.clone();
properties.entry(section).or_insert_with(HashMap::new);
state = StatesEnum::Section; // 进入节状态
}
// 如果行包含 '=',则为属性(property)
else if let Some(index) = line.find('=') {
let key = line[..index].trim().to_owned();
let value = line[index + 1..].trim().to_owned();
properties
.entry(current_section.clone())
.or_insert_with(HashMap::new)
.insert(key, value);
state = StatesEnum::Property; // 进入属性状态
}
// 其他情况为注释
else {
let comment = line.to_owned();
comments
.entry(current_section.clone())
.or_insert_with(Vec::new)
.push(comment);
state = StatesEnum::Comment; // 进入注释状态
}
}
// 节状态(Section)
StatesEnum::Section => {
// 如果行以 ';' 开头,则为注释
if line.starts_with(';') {
let comment = line[1..].trim().to_owned();
comments
.entry(current_section.clone())
.or_insert_with(Vec::new)
.push(comment);
state = StatesEnum::Comment; // 进入注释状态
}
// 如果行包含 '=',则为属性(property)
else if let Some(index) = line.find('=') {
let key = line[..index].trim().to_owned();
let value = line[index + 1..].trim().to_owned();
properties
.entry(current_section.clone())
.or_insert_with(HashMap::new)
.insert(key, value);
state = StatesEnum::Property; // 进入属性状态
}
// 如果行以 '[' 开头,以 ']' 结尾,则为节(section)
else if line.starts_with('[') && line.ends_with(']') {
let section = line[1..line.len() - 1].trim().to_owned();
current_section = section.clone();
properties.entry(section).or_insert_with(HashMap::new);
}
// 其他情况为注释
else {
let comment = line.to_owned();
comments
.entry(current_section.clone())
.or_insert_with(Vec::new)
.push(comment);
}
}
// 属性状态(Property)
StatesEnum::Property => {
// 如果行以 ';' 开头,则为注释
if line.starts_with(';') {
let comment = line[1..].trim().to_owned();
comments
.entry(current_section.clone())
.or_insert_with(Vec::new)
.push(comment);
state = StatesEnum::Comment; // 进入注释状态
}
// 如果行以 '[' 开头,以 ']' 结尾,则为节(section)
else if line.starts_with('[') && line.ends_with(']') {
let section = line[1..line.len() - 1].trim().to_owned();
current_section = section.clone();
properties.entry(section).or_insert_with(HashMap::new);
state = StatesEnum::Section; // 进入节状态
}
// 如果行包含 '=',则为属性(property)
else if let Some(index) = line.find('=') {
let key = line[..index].trim().to_owned();
let value = line[index + 1..].trim().to_owned();
properties
.entry(current_section.clone())
.or_insert_with(HashMap::new)
.insert(key, value);
}
// 其他情况为注释
else {
let comment = line.to_owned();
comments
.entry(current_section.clone())
.or_insert_with(Vec::new)
.push(comment);
state = StatesEnum::Comment; // 进入注释状态
}
}
// 注释状态(Comment)
StatesEnum::Comment => {
// 如果行以 '[' 开头,以 ']' 结尾,则为节(section)
if line.starts_with('[') && line.ends_with(']') {
let section = line[1..line.len() - 1].trim().to_owned();
current_section = section.clone();
properties.entry(section).or_insert_with(HashMap::new);
state = StatesEnum::Section; // 进入节状态
}
// 如果行包含 '=',则为属性(property)
else if let Some(index) = line.find('=') {
let key = line[..index].trim().to_owned();
let value = line[index + 1..].trim().to_owned();
properties
.entry(current_section.clone())
.or_insert_with(HashMap::new)
.insert(key, value);
state = StatesEnum::Property; // 进入属性状态
}
// 其他情况为注释
else {
let comment = line.to_owned();
comments
.entry(current_section.clone())
.or_insert_with(Vec::new)
.push(comment);
}
}
}
}
properties
}
6. 表驱动状态机 从理论到实战
7. 状态模式 从理论到实战
8. 事件驱动状态机 从理论到实战
9. 使用拆分法:编写 主从状态机
有时候如果遇到了一个比较复杂的事物,尤其是事物的某个环节
use std::collections::HashMap;
// 定义主状态
#[derive(Debug)]
enum MainState {
Start,
Section,
Comment,
}
// 定义子状态
#[derive(Debug)]
enum SubState {
Start,
Comment,
Key,
}
// 解析 INI 字符串
fn parse_ini_string(input: &str) -> HashMap<String, HashMap<String, String>> {
let mut main_state = MainState::Start;
let mut sub_state = SubState::Start;
let mut properties: HashMap<String, HashMap<String, String>> = HashMap::new();
let mut current_section: Option<String> = None;
// 逐行解析 INI 字符串
for line in input.lines() {
let line = line.trim();
match main_state {
MainState::Start => {
if line.starts_with('[') && line.ends_with(']') {
// 当遇到新的 Section 时,创建新的 Section 对应的 HashMap
let section = line[1..line.len() - 1].trim().to_owned();
properties.insert(section.clone(), HashMap::new());
current_section = Some(section);
main_state = MainState::Section;
} else if line.starts_with(';') {
main_state = MainState::Comment;
}
}
MainState::Section => {
if line.starts_with('[') && line.ends_with(']') {
// 当遇到新的 Section 时,创建新的 Section 对应的 HashMap
let section = line[1..line.len() - 1].trim().to_owned();
properties.insert(section.clone(), HashMap::new());
current_section = Some(section);
} else if line.starts_with(';') {
sub_state = SubState::Comment;
} else if !line.is_empty() {
if let Some(section) = ¤t_section {
let section_properties = properties.get_mut(section).unwrap();
if let Some(key_value) = extract_key_value(line) {
let (key, value) = key_value;
// 将键值对添加到当前 Section 的 HashMap 中
section_properties.insert(key, value);
}
}
sub_state = SubState::Key;
}
}
MainState::Comment => {
if line.starts_with('[') && line.ends_with(']') {
// 当遇到新的 Section 时,创建新的 Section 对应的 HashMap
let section = line[1..line.len() - 1].trim().to_owned();
properties.insert(section.clone(), HashMap::new());
current_section = Some(section);
main_state = MainState::Section;
}
}
}
match sub_state {
SubState::Start => {
if line.starts_with(';') {
sub_state = SubState::Comment;
} else if !line.is_empty() {
if let Some(section) = ¤t_section {
let section_properties = properties.get_mut(section).unwrap();
if let Some(key_value) = extract_key_value(line) {
let (key, value) = key_value;
// 将键值对添加到当前 Section 的 HashMap 中
section_properties.insert(key, value);
}
}
sub_state = SubState::Key;
}
}
SubState::Comment => {
if line.starts_with('[') && line.ends_with(']') {
// 当遇到新的 Section 时,创建新的 Section 对应的 HashMap
let section = line[1..line.len() - 1].trim().to_owned();
properties.insert(section.clone(), HashMap::new());
current_section = Some(section);
main_state = MainState::Section;
sub_state = SubState::Start;
} else if !line.starts_with(';') && !line.is_empty() {
if let Some(section) = ¤t_section {
let section_properties = properties.get_mut(section).unwrap();
if let Some(key_value) = extract_key_value(line) {
let (key, value) = key_value;
// 将键值对添加到当前 Section 的 HashMap 中
section_properties.insert(key, value);
}
}
sub_state = SubState::Key;
}
}
SubState::Key => {
if line.starts_with(';') {
sub_state = SubState::Comment;
} else if !line.is_empty() {
if let Some(section) = ¤t_section {
let section_properties = properties.get_mut(section).unwrap();
if let Some(key_value) = extract_key_value(line) {
let (key, value) = key_value;
// 将键值对添加到当前 Section 的 HashMap 中
section_properties.insert(key, value);
}
}
}
}
}
}
properties
}
其中:
// 用于提取键值对
fn extract_key_value(line: &str) -> Option<(String, String)> {
let parts: Vec<&str> = line.splitn(2, '=').map(str::trim).collect();
if parts.len() == 2 {
let key = parts[0].to_owned();
let value = parts[1].to_owned();
Some((key, value))
} else {
None
}
}
可以使用该
这里不包括硬件电路设计。电气工程领域采用状态机设计数字电路,所使用的用于描述硬件编程方式称作 硬件描述语言,如 VHDL、Verilog HDL,往往将状态机的实现方式分为 一段论、二段论、三段论。有兴趣的读者可以自行了解,不过硬件语言是所有电路同时存在同时执行的,不像计算机语言是一条一条执行来执行的,由于区别太大,可能对于仅仅想做软件的读者帮助不大。 ↩︎