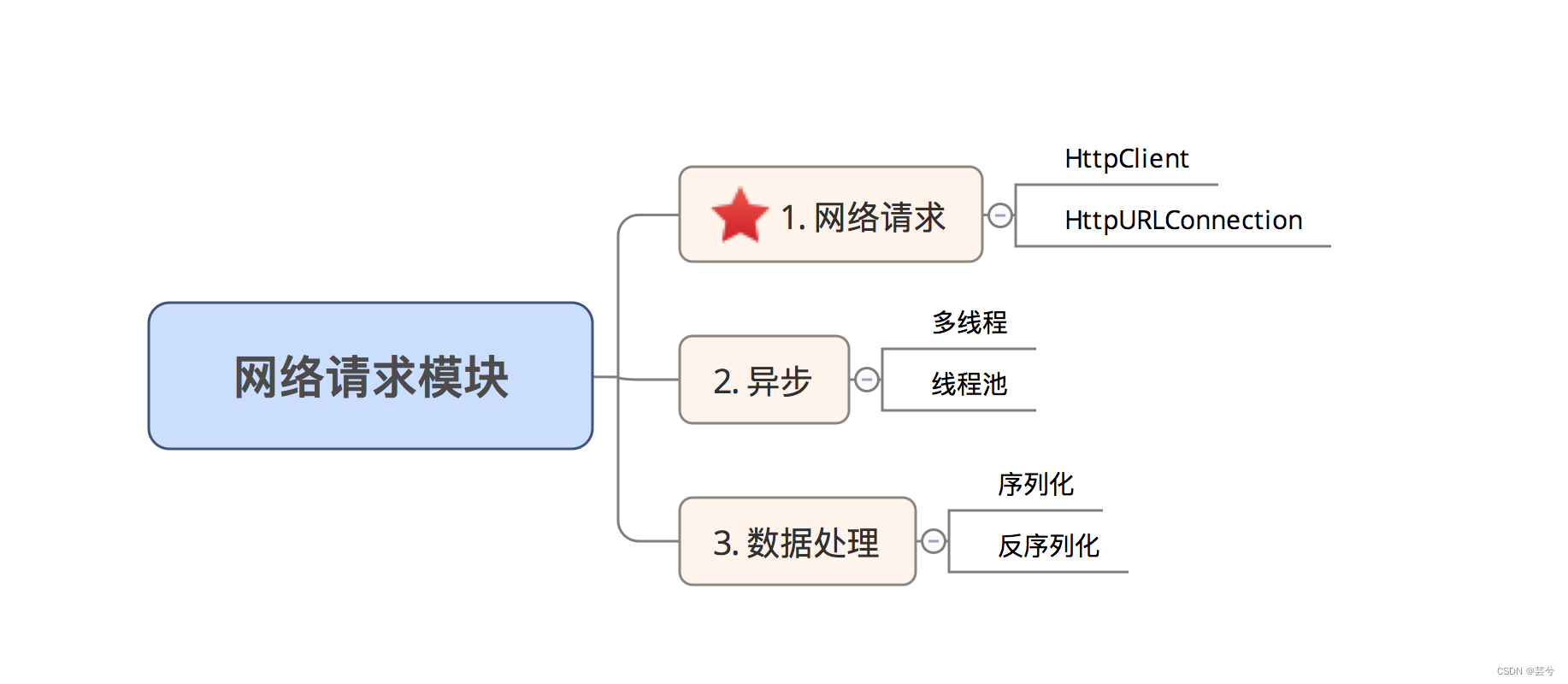
文章目录
- 概述
- HttpURLConnection
- GET和POST获取文本数据
- GET
- POST
- OKHttp
- 基本使用
- 依赖与权限
- 发起一个get请求
- 重要概念
- OkHttpClient
- Request
- Call
- RealCall
- AsyncCall
- 请求调度器Dispatcher
- 同步请求execute的执行
- 异步请求enqueue的执行
- 两种请求方式的总结
- OkHttp拦截器链
- 拦截器种类
- addInterceptor与addNetworkInterceptor有什么区别?
- 拦截器执行流程
- 拦截器在项目中的使用案例
- 网络缓存如何实现的?
- Http缓存原理
- OKHttp的缓存实现
- Okhttp缓存的启用
- 网络连接怎么实现复用?
概述
网络请求在 Android 开发中非常常见,为了降低开发周期和难度,我们经常会选用网络请求的开源库。
网络请求库的本质是 封装了网络请求 + 异步 + 数据处理功能的库。
其中网络请求功能则是基于Android网络请求原生的方法(HttpClient或者HttpURLConnection)
Android原生网络请求方法:

HttpURLConnection
HttpURLConnection是目前安卓原生仍然支持的网络请求方法。
使用网络请求,注意在manifest.xml中申请网络权限。
<uses-permission android:name="android.permission.INTERNET" />
GET和POST获取文本数据
GET
目标网址是 https://www.baidu.com/s?wd=abc ,这是百度搜索abc。
步骤:
- 创建 HttpURLConnection对象,打开指定url的网络连接。
- 设置连接请求头的参数:比如方法类型(post、get)、连接超时时间、请求体参数等。
- 获取连接请求的返回码,如果是200,表示请求成功。
- 准备数组字节输出流 ByteArrayOutputStream 和字节数组in,读取连接的输入流conn.getInputStream(),写入到字节数组in中。
try {
URL url = new URL("https://www.baidu.com/s?wd=abc");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
conn.setConnectTimeout(10 * 1000);
conn.setRequestProperty("Cache-Control", "max-age=0");
conn.setDoOutput(true);
int code = conn.getResponseCode();
if (code == 200) {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
InputStream inputStream = conn.getInputStream();
byte[] in = new byte[1024];
int len;
while ((len = inputStream.read(in)) > -1) {
baos.write(in, 0, len);
}
final String content = new String(baos.toByteArray());
baos.close();
inputStream.close();
conn.disconnect();
}
} catch (Exception e) {
e.printStackTrace();
}
POST
和上文的GET类似,都是url开启连接拿到conn,然后设置参数。 这里我们用POST方法,并且带有body。服务器能收到我们传上去的参数。 假设服务器接受的是json格式。
try {
URL url = new URL("http://sample.com/sample");
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("POST");
conn.setConnectTimeout(10 * 1000);
// 这里是示例
JSONObject bodyJson = new JSONObject();
bodyJson.put("imei", "获取imei");
bodyJson.put("deviceSn", "获取sn");
bodyJson.put("deviceBrand", Build.BRAND);
String body = bodyJson.toString();
conn.setRequestProperty("Content-Type", "application/json"); // 类型设置
conn.setRequestProperty("Cache-Control", "max-age=0");
conn.setDoOutput(true);
conn.getOutputStream().write(body.getBytes());
int code = conn.getResponseCode();
if (code == 200) {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
InputStream inputStream = conn.getInputStream();
byte[] in = new byte[1024];
int len;
while ((len = inputStream.read(in)) > -1) {
baos.write(in, 0, len);
}
String content = new String(baos.toByteArray());
baos.close();
inputStream.close();
conn.disconnect();
JSONObject jsonObject = new JSONObject(content);
// 根据定义好的数据结构解析出想要的东西
}
} catch (Exception e) {
e.printStackTrace();
}
OKHttp
OkHttp 是一个基于Android原生网络请求的高效的 Http请求框架 ,旨在简化客户端网络请求,提高网络请求开发效率。
OKHttp具体的设计思想与特性如下:
- 连接复用 :避免在每个请求之间重新建立连接。使用连接池 降低了请求延迟 (HTTP/2不可用情况下);
- 自动重试 :在请求失败时自动重试请求,从而提高请求可靠性。
- 自动处理缓存 :会按照预定的缓存策略处理缓存,以便最大化网络效率。
- 支持HTTP/2, 并且允许对同一个主机的所有请求共享一个套接字(HTTP/2);
- 简化Api:Api设计简单明了,易于使用,可以轻松发起请求获取响应,并处理异常。
- 支持gzip压缩 :OkHttp支持gzip压缩,以便通过减少网络数据的大小来提高网络效率
总的来说,其设计思想是通过 简化请求过程 、提高请求效率、提高请求可靠性,从而提供 更快的网络请求响应速度 。
基本使用
依赖与权限
// build.gradle
implementation "com.squareup.okhttp3:okhttp:4.10.0"
// Android Manifest.xml
<uses-permission android:name="android.permission.INTERNET" />
发起一个get请求
public void request() {
String url = "http://www.baidu.com";
//'1. 生成OkHttpClient实例对象'
OkHttpClient okHttpClient = new OkHttpClient();
//'2. 生成Request对象'
Request request = new Request.Builder().url(url).build();
//'3. 生成Call对象'
Call call = okHttpClient.newCall(request);
//'4. 如果要执行同步请求:'
try {
call.execute();
} catch (IOException e) {
e.printStackTrace();
}
//'5. 如果要执行异步请求:'
call.enqueue(new Callback() {
@Override
public void onFailure(Call call, IOException e) {
}
@Override
public void onResponse(Call call, Response response) throws IOException {
}
});
}
总结下来就是下边几步:
- 创建
okHttpClient对象 - 构建
Request - 调用okHttpClient执行request请求
- 同步阻塞或者异步回调方式接收结果
Call
重要概念
OKHttp的基本执行流程如下:
在执行同步或者异步前,我们需要先准备好okHttpClient、Request、Call对象。
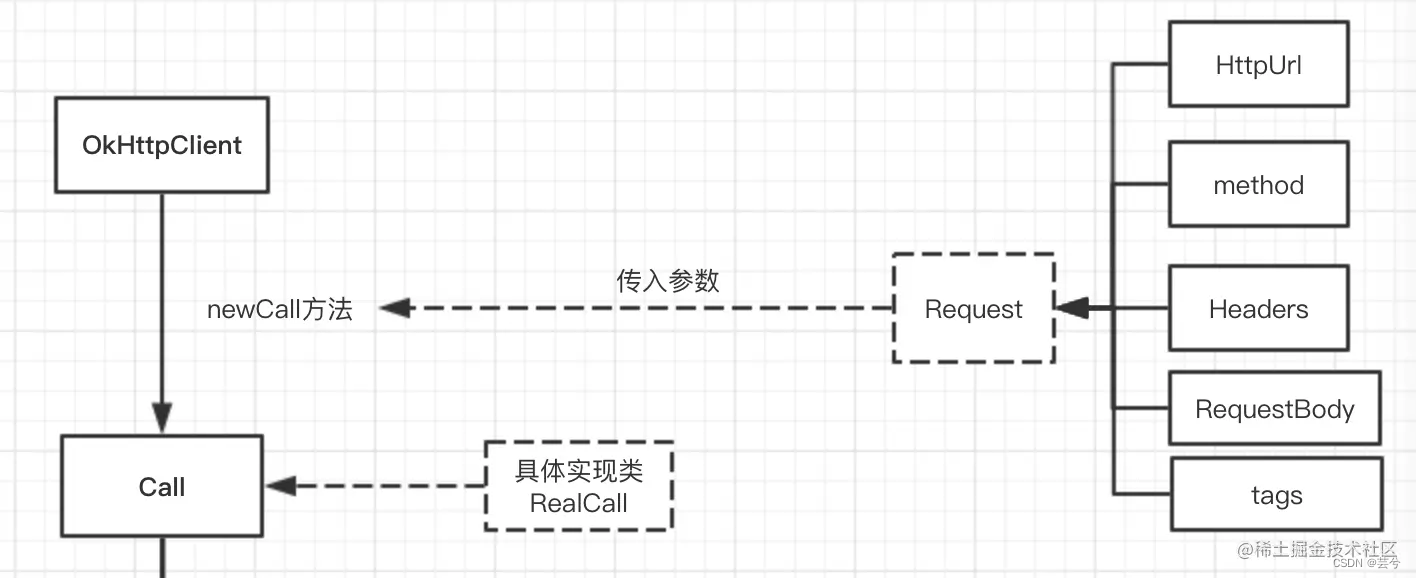
OkHttpClient
OkHttpClient:okHttp连接的客户端对象;
我们在代码中new一个客户端对象:
OkHttpClient okHttpClient = new OkHttpClient();
发生了什么?
源码如下:
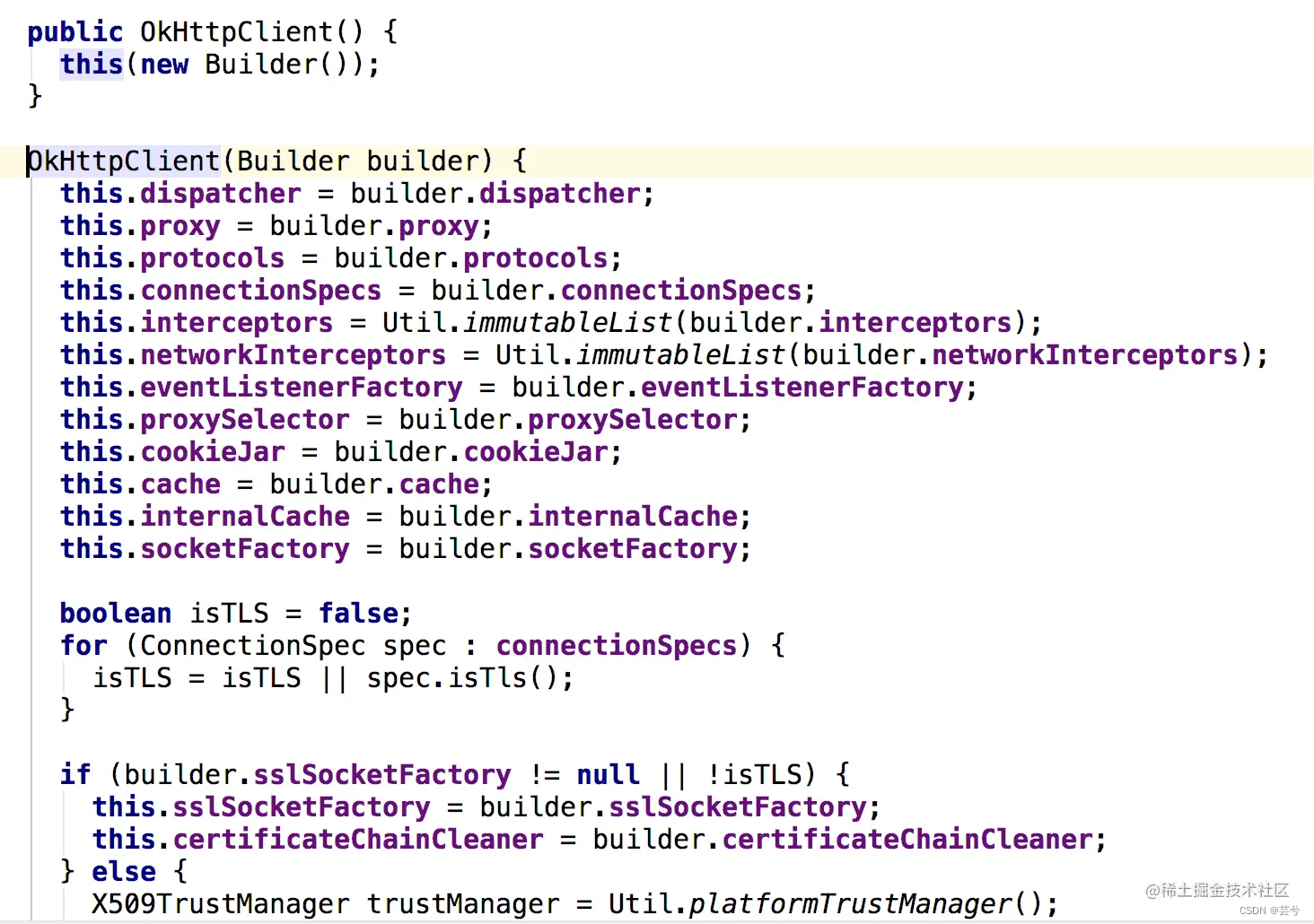
OkHttpClient除了空参数的构造函数,还有一个传入Builder的构造函数,而我们的new OkHttpClient()最终也是调用了传入Builder的构造函数,只不过传入默认的Builder对象值:
可以看到默认的连接超时,读取超时,写入超时,都为10秒。

如果不想使用默认的这些参数设置,可以构建我们自己想要的Builder:
注意构建好builder后,不能直接使用那个传入Builder对象的OkHttpClient的构造函数,因为该构造函数的方法不是public的,应该使用builder的build()方法
OkHttpClient.Builder builder = new OkHttpClient.Builder();
builder.connectTimeout(20,TimeUnit.SECONDS);
builder.readTimeout(20,TimeUnit.SECONDS);
builder.writeTimeout(20,TimeUnit.SECONDS);
OkHttpClient okHttpClient = builder.build();
//这里不能直接使用那个传入Builder对象的OkHttpClient的构造函数,因为该构造函数的方法不是public的
OkHttpClient okHttpClient = new OkHttpClient(builder);//这样是错误的
builder.build();的源码是:
public OkHttpClient build() {
return new OkHttpClient(this);
}
除了时延参数,Builder的属性还包括:
-
Dispatch:调度器,用于连接请求分发调度。
-
Protocal:网络协议类(比如http1.1、http2.0、http3.0)
-
Interceptor:拦截器。
-
Cache:网络缓存,okhttp默认只能设置缓存GET请求,不缓存POST请求,毕竟POST请求很多都是交互的,缓存下来也没有什么意义。
Request
Request:请求,这里实际上是http协议的请求头、请求体的实例对象。
查看Request代码:
可以看到Request具体包含了
- url:网络请求路径
- method:请求方法类型
- header:请求头
- requestbody:请求体
public final class Request {
final HttpUrl url; //网络请求路径
final String method; //get、post.....
final Headers headers;//请求头
final @Nullable RequestBody body;//请求体
/**
你可以通过tags来同时取消多个请求。
当你构建一请求时,使用RequestBuilder.tag(tag)来分配一个标签。
之后你就可以用OkHttpClient.cancel(tag)来取消所有带有这个tag的call。.
*/
final Map<Class<?>, Object> tags;
.......
.......
.......
}
Call
Call:请求调用接口,表示这个请求已经准备好可以执行。
RealCall
我们生成的Request实例,会传给OkHttpClient实例的newÇall方法,每一个Request对应用一个Call,实际上Call是一个接口,newCall()方法真正返回的对象是Call的具体实现类RealCall。
创建RealCall对象后,就要调用同步或异步请求方法,所以它里面还包含同步请求 execute() 与异步请求 enqueue()方法。
Request request = new Request.Builder().url(url).build();
Call call = okHttpClient.newCall(request);
call.execute();或者 call.enqueue(....);
Call类代码:
@Override public Call newCall(Request request) {
return RealCall.newRealCall(this, request, false /* for web socket */);
}
RealCall类代码:
static RealCall newRealCall(OkHttpClient client, Request originalRequest, boolean forWebSocket) {
// Safely publish the Call instance to the EventListener.
RealCall call = new RealCall(client, originalRequest, forWebSocket);
call.eventListener = client.eventListenerFactory().create(call);
return call;
}
AsyncCall
异步请求调用,是RealCall的一个内部类,就是一个Runnable,被调度器中的线程池所执行,在执行异步请求时,会将请求转为AsyncCall,它最终被加入到线程池中执行。
再回过头看这张图:
请求调度器Dispatcher
不管是同步执行的call.execute(),还是异步执行的call.enqueue();,请求的执行都是交由调度器Dispatcher统一管理。
Dispacher的成员:
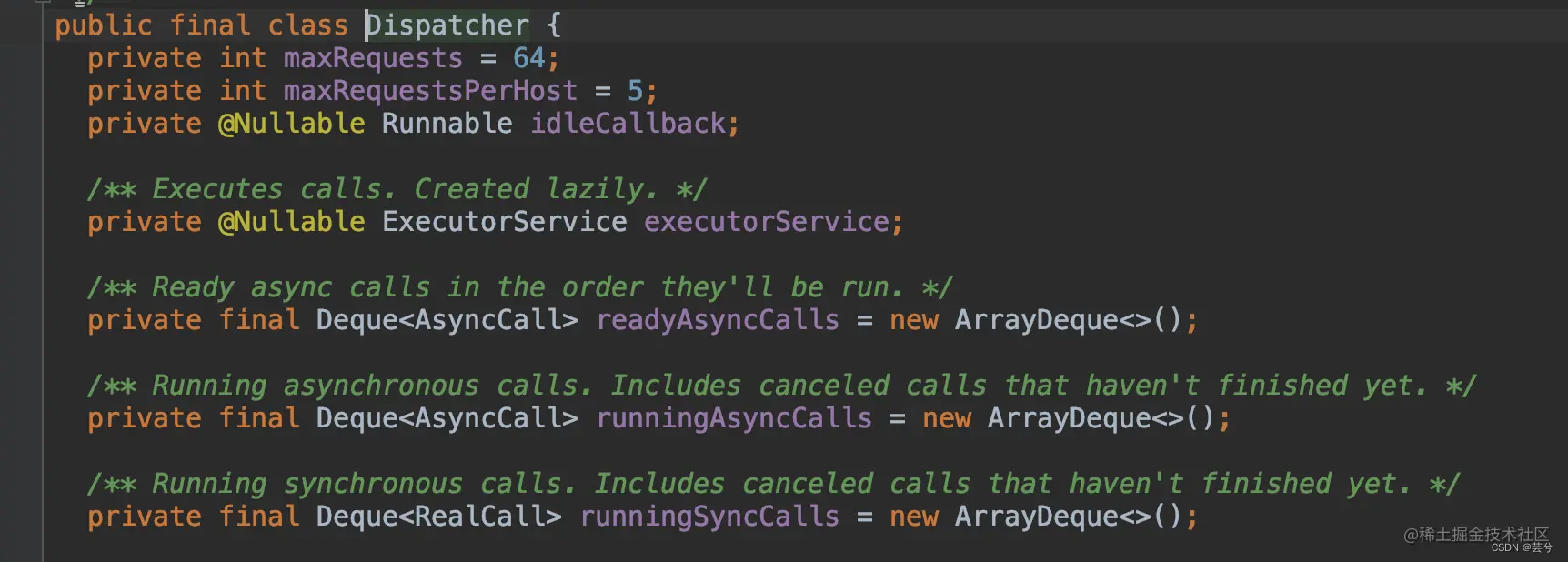
- maxRequests:最多存在64个请求;
- maxRequestsPerHost:每个主机最多同时请求数为5;
- idleCallback:程序空闲时的回调;
- executorService:线程池;
- readyAsyncCalls:就绪的异步请求队列,使用
enqueue()方法将请求添加到 Call 对象时,它会首先进入异步请求就绪队列。调度器会根据并发限制和请求的优先级从这个队列中选取请求进行执行。 - runningAsyncCalls:正在运行的异步请求队列,调度器会从
readyAsyncCalls队列中选取请求,并将其移动到这个队列中,然后执行请求。一旦请求执行完成,它会从这个队列中移除。 - runningSyncCalls:正在运行的同步请求队列,这个队列包含当前正在执行的同步网络请求 (
execute())。同步请求会阻塞当前线程,直到请求完成,从队列移除。
同步请求是在调用者所在线程执行,并会堵塞所在线程。而所有的异步请求,调度器dispatcher最终交由自己的线程池executorService实际执行的。dispatcher的线程池的创建:
public synchronized ExecutorService executorService() {
if (executorService == null) {
executorService = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60, TimeUnit.SECONDS,
new SynchronousQueue<>(), Util.threadFactory("OkHttp Dispatcher", false));
}
return executorService;
}
核心线程为0,每隔60秒会清空空闲的线程,而最大线程无限制,但是已经通过成员变量来进行控制了,没啥影响;这个线程池类似于cacheThreadPool,没有核心线程,最大线程无限制。
同步请求execute的执行
@Override
public Response execute() throws IOException {
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
captureCallStackTrace();
eventListener.callStart(this);
try {
//'1. 执行了dispatcher的executed方法'
client.dispatcher().executed(this);
//'2. 调用了getResponseWithInterceptorChain方法'
Response result = getResponseWithInterceptorChain();
if (result == null) throw new IOException("Canceled");
return result;
} catch (IOException e) {
eventListener.callFailed(this, e);
throw e;
} finally {
//'3. 最后一定会执行dispatcher的finished方法'
client.dispatcher().finished(this);
}
}
核心步骤就是3个:
- 执行了dispatcher的
executed()方法,将此同步请求Call加入到正在运行的同步请求队列。

- 调用了getResponseWithInterceptorChain方法,这个方法与拦截器有关,后边再讲。
- 执行client.dispatcher().
finished(this),将执行完毕的请求从队列移出。
private <T> void finished(Deque<T> calls, T call) {
Runnable idleCallback;
synchronized (this) {
// 移除队列的请求
if (!calls.remove(call)) throw new AssertionError("Call wasn't in-flight!");
idleCallback = this.idleCallback;
}
// 执行请求
boolean isRunning = promoteAndExecute();
if (!isRunning && idleCallback != null) {
// 触发空闲线程执行
idleCallback.run();
}
}
异步请求enqueue的执行
call.enqueue()
这个函数主要做重复入队同步锁判断,同一个Call对象,同时请求了二次。这时候就会进入我们的同步锁判断,只要一个执行过了,里面 executed会为true,也就会抛出异常。
@Override public void enqueue(Callback responseCallback) {
//'1. 这里有个同步锁的抛异常操作'
synchronized (this) {
if (executed) throw new IllegalStateException("Already Executed");
executed = true;
}
captureCallStackTrace();
eventListener.callStart(this);
//'2. 调用Dispatcher里面的enqueue方法'
client.dispatcher().enqueue(new AsyncCall(responseCallback));
}
client.dispatcher().enqueue(new AsyncCall(responseCallback))
这里不再是像同步操作一样,直接把RealCall传入,而是传入一个AsyncCall对象,AsyncCall继承自NamedRunnable ,而NamedRunnable 实现了runnable接口,最终在promoteAndExecute()是在线程池中执行的异步请求。
void enqueue(AsyncCall call) {
synchronized (this) {
readyAsyncCalls.add(call);
// Mutate the AsyncCall so that it shares the AtomicInteger of an existing running call to
// the same host.
if (!call.get().forWebSocket) {
AsyncCall existingCall = findExistingCallWithHost(call.host());
if (existingCall != null) call.reuseCallsPerHostFrom(existingCall);
}
}
promoteAndExecute();
}
promoteAndExecute()函数,这个函数的意思是从异步请求就绪队列中弹出请求,并尝试把它加入到正在执行的异步请求队列中。
注意:asyncCall.executeOn(executorService());
private boolean promoteAndExecute() {
assert (!Thread.holdsLock(this));
List<AsyncCall> executableCalls = new ArrayList<>();
boolean isRunning;
synchronized (this) {
// 1、遍历准备要执行的请求队列
for (Iterator<AsyncCall> i = readyAsyncCalls.iterator(); i.hasNext(); ) {
AsyncCall asyncCall = i.next();
// 2、判断当前正在执行的请求个数大于最大请求个数时,则取消请求
if (runningAsyncCalls.size() >= maxRequests) break; // Max capacity.
// 3、判断当前主机的连接数超过5个时,则跳过当前请求;
if (asyncCall.callsPerHost().get() >= maxRequestsPerHost) continue; // Host max capacity.
i.remove();
asyncCall.callsPerHost().incrementAndGet();
executableCalls.add(asyncCall);
// 添加请求到正在执行的队列中
runningAsyncCalls.add(asyncCall);
}
isRunning = runningCallsCount() > 0;
}
for (int i = 0, size = executableCalls.size(); i < size; i++) {
AsyncCall asyncCall = executableCalls.get(i);
// 执行请求;
asyncCall.executeOn(executorService());
}
return isRunning;
}
- executeOn,当我们将任务添加到线程池后,当任务被执行时,触发execute()方法,最终还是会执行
getResponseWithInterceptorChain()
void executeOn(ExecutorService executorService) {
assert (!Thread.holdsLock(client.dispatcher()));
boolean success = false;
try {
// 线程池实际执行的函数
executorService.execute(this);
success = true;
} catch (RejectedExecutionException e) {
InterruptedIOException ioException = new InterruptedIOException("executor rejected");
ioException.initCause(e);
transmitter.noMoreExchanges(ioException);
responseCallback.onFailure(RealCall.this, ioException);
} finally {
if (!success) {
client.dispatcher().finished(this); // This call is no longer running!
}
}
}
@Override protected void execute() {
boolean signalledCallback = false;
transmitter.timeoutEnter();
try {
// 可以看到,异步请求最终还是走到getResponseWithInterceptorChain()这个函数。
Response response = getResponseWithInterceptorChain();
signalledCallback = true;
responseCallback.onResponse(RealCall.this, response);
} catch (IOException e) {
if (signalledCallback) {
// Do not signal the callback twice!
Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e);
} else {
responseCallback.onFailure(RealCall.this, e);
}
} catch (Throwable t) {
cancel();
if (!signalledCallback) {
IOException canceledException = new IOException("canceled due to " + t);
canceledException.addSuppressed(t);
responseCallback.onFailure(RealCall.this, canceledException);
}
throw t;
} finally {
client.dispatcher().finished(this);
}
}
}
两种请求方式的总结
同步请求execute()核心步骤是三步:
- 将
call请求任务加入到正在运行的同步队列runningSyncCalls中 - 调用基于拦截器链获取返回值方法
getResponseWithInterceptorChain() - 请求结束后,从同步队列
runningSyncCalls移除。
同步请求是阻塞式的。
异步请求enqueue()的核心步骤是五步。
- 判断是否
call对象重复添加,采用同步锁机制,第一次添加时,将标志executed赋值为true,后续根据executed的值判断是否重复添加。 - 将
Call转为AsynCall,交由调度器把异步请求加入到异步请求就绪队列readyAsyncCalls。 - 执行
promoteAndExecute,尝试把异步请求从就绪队列readyAsyncCalls加入到正在运行的异步请求队列runningAsyncCalls。 - 遍历从
readyAsyncCalls取出的异步请求,在线程池中执行getResponseWithInterceptorChain() - 执行完毕也是需要将请求从异步请求队列
runningAsyncCalls移除。
OkHttp拦截器链
在上面我们知道,异步请求和同步请求最终都走到了RealCall.getResponseWithInterceptorChain() 方法,即使用 拦截器链 获取本次请求的响应内容。
具体源码如下:
Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
List<Interceptor> interceptors = new ArrayList<>();
// 1、添加用户自定义的拦截器
interceptors.addAll(client.interceptors());
// 2、添加OKhttp自有的5大拦截器
interceptors.add(new RetryAndFollowUpInterceptor(client));
interceptors.add(new BridgeInterceptor(client.cookieJar()));
interceptors.add(new CacheInterceptor(client.internalCache()));
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
interceptors.addAll(client.networkInterceptors());
}
interceptors.add(new CallServerInterceptor(forWebSocket));
// 3、将所有拦截器合并为拦截器链
Interceptor.Chain chain = new RealInterceptorChain(interceptors, transmitter, null, 0,
originalRequest, this, client.connectTimeoutMillis(),
client.readTimeoutMillis(), client.writeTimeoutMillis());
boolean calledNoMoreExchanges = false;
try {
// 4、执行责任链的proceed()
Response response = chain.proceed(originalRequest);
if (transmitter.isCanceled()) {
closeQuietly(response);
throw new IOException("Canceled");
}
return response;
} catch (IOException e) {
calledNoMoreExchanges = true;
throw transmitter.noMoreExchanges(e);
} finally {
if (!calledNoMoreExchanges) {
transmitter.noMoreExchanges(null);
}
}
}
上述的逻辑非常简单,内部会先创建一个局部拦截器集合interceptors :
- 添加用户自定义的拦截器
- 添加OKhttp自有的5大拦截器
- 将所有拦截器连接成链
- 执行拦截器链的
proceed方法
拦截器种类
OkHttp 内置了 5 个核心的拦截器用来完成请求生命周期中的关键处理,同时它也支持在连接开始时(应用拦截器)和响应前(网络拦截器)这两个地方通过自定义的拦截器来增强和扩展 Http 客户端。
这些拦截器通过责任链模式串联起来,允许将请求沿着处理者链发送。 收到请求后, 每个处理者均可对请求进行处理, 或将其传递给链上的下一个处理者。
按照拦截器在责任链中的顺序:

- client.interceptors:也称应用拦截器,这是由开发者设置的,会在所有的拦截器处理之前进行最早的拦截处理,可用于添加一些公共参数,如自定义header、自定义log等等。
RetryAndFollowUpInterceptor:这里会对连接做一些初始化工作,处理错误重试和重定向。BridgeInterceptor:是客户端与服务器之间的沟通桥梁,负责将用户构建的请求转换为服务器需要的请求,以及将网络请求返回回来的响应转换为用户可用的响应。主要工作是为请求添加cookie、添加固定的header,比如Host、Content-Length、Content-Type、User-Agent等等,然后保存响应结果的cookie,如果响应使用gzip压缩过,则还需要进行解压。CacheInterceptor:缓存拦截器,如果命中缓存则不会发起网络请求。ConnectInterceptor:连接拦截器,内部会维护一个连接池,负责连接复用、创建连接(TCP三次握手、TSL)、释放连接以及创建连接上的socket流。- client.networkInterceptors:网络拦截器,这里也是开发者自己设置的,通常用于监控网络层的数据传输。
CallServerInterceptor:这里就是进行网络数据的请求和响应了,也就是实际的网络I/O操作,将请求头与请求体发送给服务器,以及解析服务器返回的response。
addInterceptor与addNetworkInterceptor有什么区别?
二者通常的叫法为应用拦截器和网络拦截器。
从整个责任链路来看,应用拦截器是最先执行的拦截器,也就是用户自己设置request属性后的原始请求,而网络拦截器位于ConnectInterceptor和CallServerInterceptor之间,此时网络链路已经准备好,只等待发送请求数据。
- 首先,应用拦截器在RetryAndFollowUpInterceptor和CacheInterceptor之前,所以一旦发生错误重试或者网络重定向,网络拦截器可能执行多次,因为相当于进行了二次请求,但是应用拦截器永远只会触发一次。另外如果在CacheInterceptor中命中了缓存就不需要走网络请求了,因此会存在短路网络拦截器的情况。
- 从使用场景看,应用拦截器因为只会调用一次,通常用于统计客户端的网络请求发起情况;而网络拦截器一次调用代表了一定会发起一次网络通信,因此通常可用于统计和监控网络链路上传输的数据。
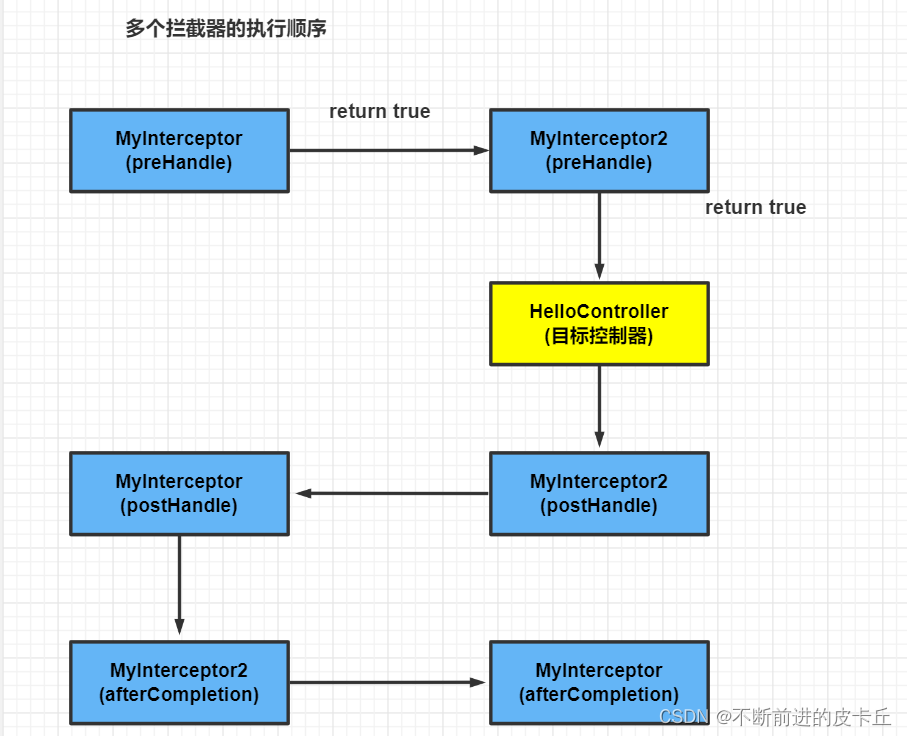
拦截器执行流程
上述的各种拦截器在连接成链后,构成了责任链模式,每个拦截器在处理请求时调用了chain.proceed(request)方法,它会将请求传递给下一个拦截器继续处理。类似地,如果一个拦截器在处理响应时调用了 chain.proceed(response) 方法,它会将响应传递给下一个拦截器继续处理。
如下图,request和response是两个相反的责任链处理的流程方向。

为保证责任链能依次进行下去,必须保证除最后一个拦截器(CallServerInterceptor)外,其他所有拦截器intercept方法内部必须调用一次chain.proceed()方法,如此一来整个责任链就运行起来了。
经过责任链一级一级的递推下去,最终会执行到CallServerInterceptor的intercept方法,此方法会将网络响应的结果封装成一个Response对象并return。之后沿着责任链一级一级的回溯,最终就回到getResponseWithInterceptorChain方法的返回。
拦截器在项目中的使用案例
在我们的项目中,有一类请求需要在请求头 Header 中添加认证信息,使用拦截器来实现可以极大地简化代码,提高代码可读性和可维护性。核心代码只需要实现符合业务需要的拦截器如下:
第一步:
构建我们自己的拦截器类,实现拦截器接口:
public class EncryptInterceptor implements Interceptor {
@Override
public Response intercept(Chain chain) throws IOException {
Request originRequest = chain.request();
// 计算认证信息
String authorization = this.encrypt(originRequest);
// 添加请求头
Request request = originRequest.newBuilder()
.addHeader("Authorization", authorization)
.build();
// 向责任链后面传递
return chain.proceed(request);
}
}
第二步
在创建OkHttpClient 客户端的时候,使用 addInterceptor() 方法将我们的拦截器注册成应用程序拦截器,即可实现自动地、无感地向请求头中添加实时的认证信息的功能。
OkHttpClient client = new OkHttpClient.Builder().addInterceptor(new EncryptInterceptor()).build();
网络缓存如何实现的?
Http缓存原理
在HTTP 1.0时代,响应使用Expires头标识缓存的有效期,其值是一个绝对时间,当客户端再次发出网络请求时可比较当前时间 和上次响应的expires时间进行比较,来决定是使用缓存还是发起新的请求。
使用Expires头最大的问题是它依赖客户端的本地时间,如果用户自己修改了本地时间,就会导致无法准确的判断缓存是否过期。
因此,从HTTP 1.1 开始使用Cache-Control头表示缓存状态,它的优先级高于Expires,常见的取值为下面的一个或多个。
- private,默认值,标识那些私有的业务逻辑数据,比如根据用户行为下发的推荐数据。该模式下网络链路中的代理服务器等节点不应该缓存这部分数据,因为没有实际意义。
- public 与private相反,public用于标识那些通用的业务数据,比如获取新闻列表,所有人看到的都是同一份数据,因此客户端、代理服务器都可以缓存。
- no-cache 可进行缓存,但在客户端使用缓存前必须要去服务端进行缓存资源有效性的验证,即下文的对比缓存部分,我们稍后介绍。
- max-age 表示缓存时长单位为秒,指一个时间段,比如一年,通常用于不经常变化的静态资源。
- no-store 任何节点禁止使用缓存。
强制缓存:在上述缓存头规约基础之上,强制缓存是指网络请求响应header标识了Expires或Cache-Control带了max-age信息,而此时客户端计算缓存并未过期,则可以直接使用本地缓存内容,而不用真正的发起一次网络请求。
协商缓存:强制缓存最大的问题是,一旦服务端资源有更新,直到缓存时间截止前,客户端无法获取到最新的资源(除非请求时手动添加no-store头),另外大部分情况下服务器的资源无法直接确定缓存失效时间,所以使用协商缓存更灵活一些。
使用Last-Modify / If-Modify-Since头实现协商缓存,具体方法是服务端响应头添加Last-Modify头标识资源的最后修改时间,单位为秒,当客户端再次发起请求时添加If-Modify-Since头并赋值为上次请求拿到的Last-Modify头的值。
服务端收到请求后自行判断缓存资源是否仍然有效,如果有效则返回状态码304同时body体为空,否则下发最新的资源数据。客户端如果发现状态码是304,则取出本地的缓存数据作为响。
使用这套方案有一个问题,那就是资源文件使用最后修改时间有一定的局限性:
- Last-Modify单位为秒,如果某些文件在一秒内被修改则并不能准确的标识修改时间。
- 资源修改时间并不能作为资源是否修改的唯一依据,比如资源文件是每天都会生成新的,但是其实际内容可能并未改变。
因此,HTTP 还提供了另外一组头信息来处理缓存,ETag/If-None-Match。流程与Last-Modify一样,只是把服务端响应的头变成Last-Modify,客户端发出的头变成If-None-Match。ETag是资源的唯一标识符
,服务端资源变化一定会导致ETag变化。具体的生成方式有服务端控制,场景的影响因素包括,文件最终修改时间、文件大小、文件编号等等。
OKHttp的缓存实现
上面讲了这么多,实际上OKHttp就是将上述流程用代码实现了一下,即:
- 第一次拿到响应后根据头信息决定是否缓存。
- 下次请求时判断是否存在本地缓存,是否需要使用对比缓存、封装请求头信息等等。
- 如果缓存失效或者需要对比缓存则发出网络请求,否则使用本地缓存。
Okhttp缓存的启用
要开启使用Okhttp的缓存其实很简单,只需要给OkHttpClient对象设置一个Cache对象即可,创建一个Cache时指定缓存保存的目录和缓存最大的大小即可,OKhttp默认只支持get请求的缓存,缓存系统内部使用LRU作为缓存的淘汰算法。
//新建一个cache,指定目录为外部目录下的okhttp_cache目录,大小为100M
Cache cache = new Cache(new File(Environment.getExternalStorageDirectory() + "/okhttp_cache/"), 100 * 1024 * 1024);
//将cache设置到OkHttpClient中,这样缓存就开始生效了。
OkHttpClient client = new OkHttpClient.Builder().cache(cache).build();
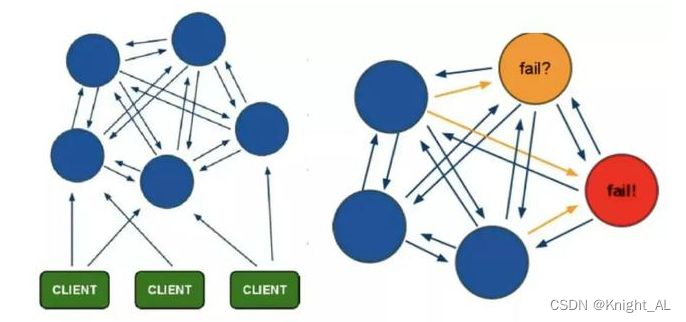
网络连接怎么实现复用?
Okhttp内部维护了网络连接池,查找当前请求是否有对应可用的连接,避免每次请求重新建立和断开TCP连接。
OkHttp 实现连接复用的基本流程:
- 创建连接池:首先,创建一个连接池对象,用于管理网络连接。可以使用 ConnectionPool 类的构造函数来指定连接池的参数,例如最大空闲连接数、连接的保持时间等。
- 请求发送:当发起一个网络请求时,OkHttp 会从连接池中获取一个可用的连接对象。如果连接池中没有可用连接,则会创建一个新的连接。
- 连接复用:在获取到连接后,OkHttp 会检查连接是否可复用。这涉及到检查连接是否空闲(没有被其他请求使用)以及是否满足复用的条件(如是否在同一主机上)。如果连接满足复用条件,那么它会被复用,否则将被标记为不可复用。
- 请求响应:使用复用的连接发送请求后,等待服务器的响应。一旦收到响应,OkHttp 将处理响应数据,并根据响应的状态决定是否将连接放回连接池供其他请求复用。
- 连接回收:在请求完成后,如果连接可以复用,则会将连接返回给连接池,供后续的请求使用。否则,连接将被关闭和丢弃。
通过连接池的机制,OkHttp 能够有效地复用网络连接,避免了频繁创建和关闭连接的开销,提高了网络请求的性能和效率。连接池中的连接会在空闲一段时间后被自动关闭,以确保连接池中的连接不会无限增长。