文章目录
- 容器接口
- 容器实现
- BeanFactory容器实现
- ApplicationContext容器实现
- Bean的生命周期
- 模板方法设计模式
- Bean后处理器
- BeanFactory 后处理器
- 有关后处理器(PostProcessor)的调用时期
- Aware 接口 和 InitializingBean 接口
- 初始化和销毁
- Scope
容器接口
此节我们要:
- 了解BeanFactory能做那些事?
- ApplicationContext能有哪些拓展功能
- 事件解耦
Spring中比较有名的容器接口有两个一个就是BeanFactory接口、另一个就是ApplicationContext 接口。
-
BeanFactory 接口,典型功能有:- getBean
-
ApplicationContext 接口,是 BeanFactory 的子接口。它扩展了 BeanFactory 接口的功能,如:- 国际化
- 通配符方式获取一组 Resource 资源
- 整合 Environment 环境(能通过它获取各种来源的配置信息)
- 事件发布与监听,实现组件之间的解耦
我们平时使用SpringBoot跑一个项目的时候,启动类都是类似这样的:
public class HmDianPingApplication {
public static void main(String[] args) {
SpringApplication.run(HmDianPingApplication.class, args);
}
}
我们使用run方法来启动一个SpringBoot程序,它有两个参数:
- 启动类的类型
- main方法传过来的命令行参数
这个run方法其实有一个返回值,这个返回值就是我们的Spring容器:
ConfigurableApplicationContext context = SpringApplication.run(A01.class, args);
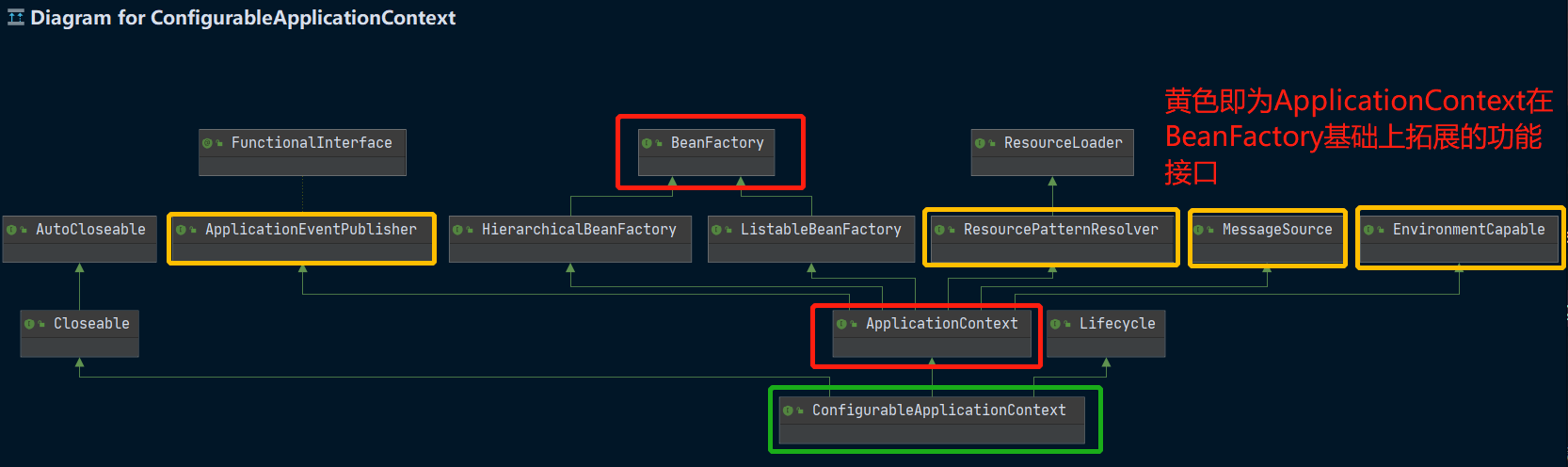
那么这个ConfigurableApplicationContext和我们的两个容器接口有什么关系吗?我们可以Ctrl + Alt + u 查看一下类图:
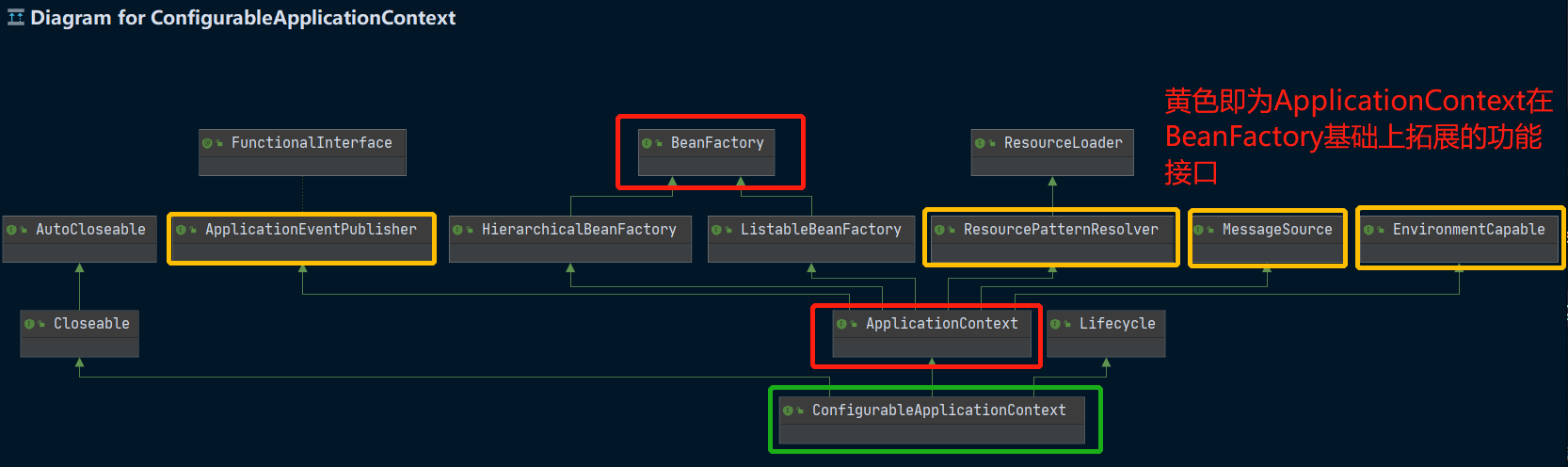
我们可以看到ConfigurableApplicationContext其实是继承于ApplicationContext接口,而ApplicationContext接口又是继承于BeanFactory接口,可想而知ApplicationContext接口应该是对BeanFactory接口做了一些功能拓展。
这个地方我们回答一个问题?到底什么是BeanFactory?
- 它是 ApplicationContext 的父接口
- 它才是 Spring 的核心容器, 主要的 ApplicationContext 实现都【组合】了它的功能
- 我们可以看看下面的代码,getBean方法直接就是调用的BeanFactory中的方法:
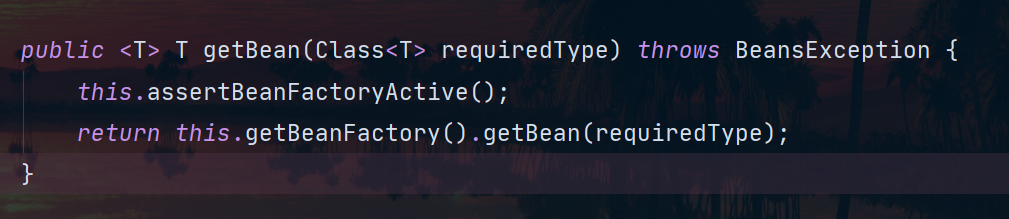
- BeanFactory是ApplicationContext 的一个成员变量
- 我们可以看看下面的代码,getBean方法直接就是调用的BeanFactory中的方法:
然后我们解决第二个问题:BeanFactory 能干点啥?
我们直接看这个接口中的抽象方法发现比较简单:
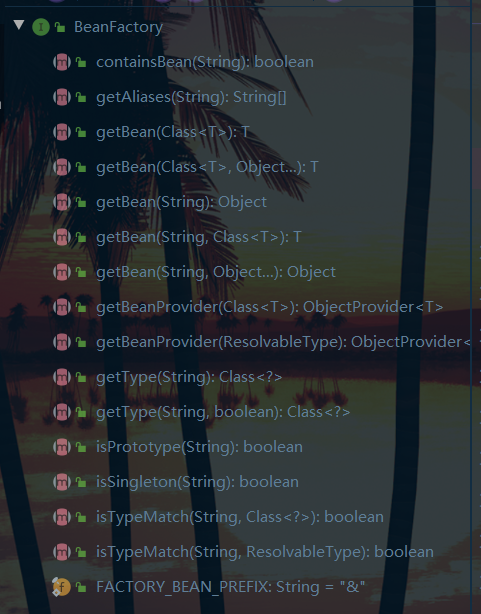
似乎比较有用的就是getBean方法,实际上我们不能光看接口还要看他的实现,控制反转、基本的依赖注入、直至 Bean 的生命周期的各种功能,都由它的实现类提供了。
而这个实现类是DefaultListableBeanFactory
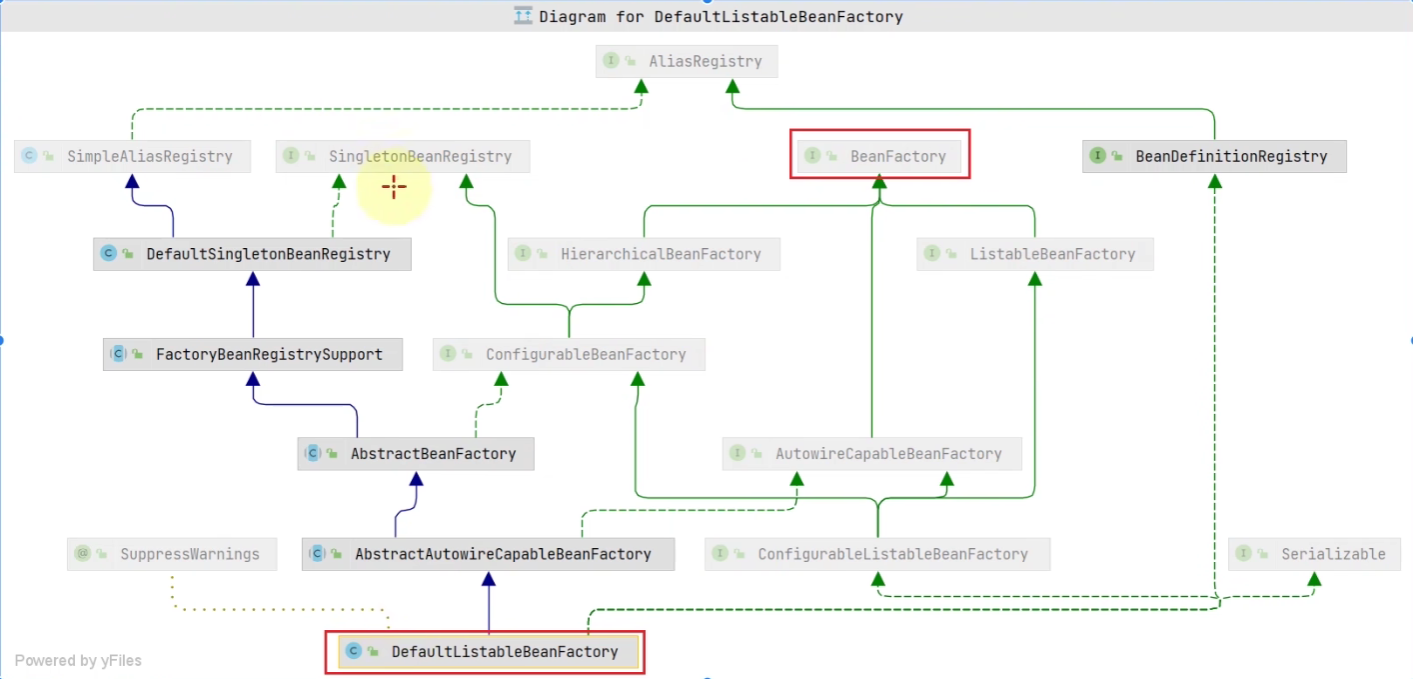
我们可以发现BeanFactory只是其实现的所有接口中一个很小的部分。
DefaultListableBeanFactory能管理所有的bean,其中我们最为熟悉的就是它可以管理单例对象,而这一功能就是他的一个父类DefaultSingletonBeanRegistry实现的,他有一个成员变量singletonObjects用来管理所有的单例对象:
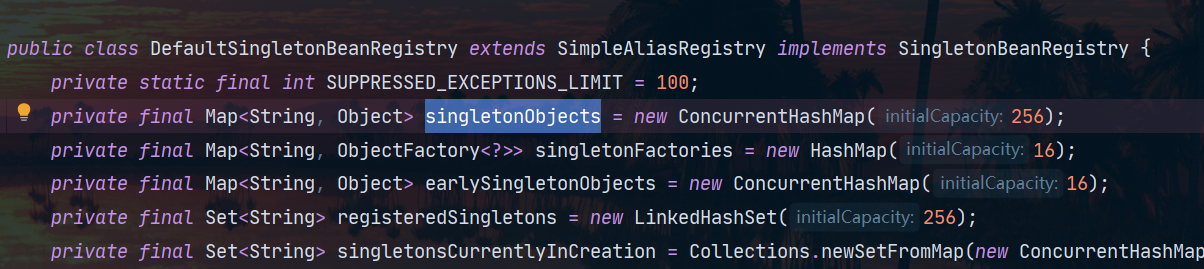
其中key是bean的名字,值就是对象的实例。为了能够更清楚的认识这个singletonObjects我们使用反射看一看他,这里我们定义了自己的两个bean我们找找看:
Field singletonObjects = DefaultSingletonBeanRegistry.class.getDeclaredField("singletonObjects");
singletonObjects.setAccessible(true);
ConfigurableListableBeanFactory beanFactory = context.getBeanFactory();
Map<String, Object> map = (Map<String, Object>) singletonObjects.get(beanFactory);
map.entrySet().stream().filter(e -> e.getKey().startsWith("component"))
.forEach(e -> {
System.out.println(e.getKey() + "=" + e.getValue());
});
然后我们解决最后一个问题:ApplicationContext 比 BeanFactory 多点啥?
我们可以从ApplicationContext 多继承的接口来解决这个问题:
-
MessageSource:一个国际化的消息访问器,它的主要作用是根据 Locale 来解析消息,以支持国际化


将来这个Locale的信息是从浏览器的请求头中获取的
-
ResourcePatternResolver:一个资源模式解析器,它的主要作用是根据指定的位置和模式解析资源。
- 根据路径加载资源文件。可以加载类路径下的资源文件(classpath:),文件系统下的资源文件(file:),URL 等。
- 支持 Ant 风格的路径匹配,可以使用 ?、* 等通配符匹配多个资源。
- 资源可以是 properties 文件,XML 配置文件,图片,文本文件等。
- 找不到资源也不会报错,返回 null。
-
我们举一个例子:


- classpath代表从类路径下寻找,如果是file代表从磁盘目录下开始寻找
- 如果要寻找的文件在jar包里,就要加一个
*号,这样才能找到
-
ApplicationEventPublisher:一个事件发布器接口,它的主要作用是在 Spring 应用中发布事件。
-
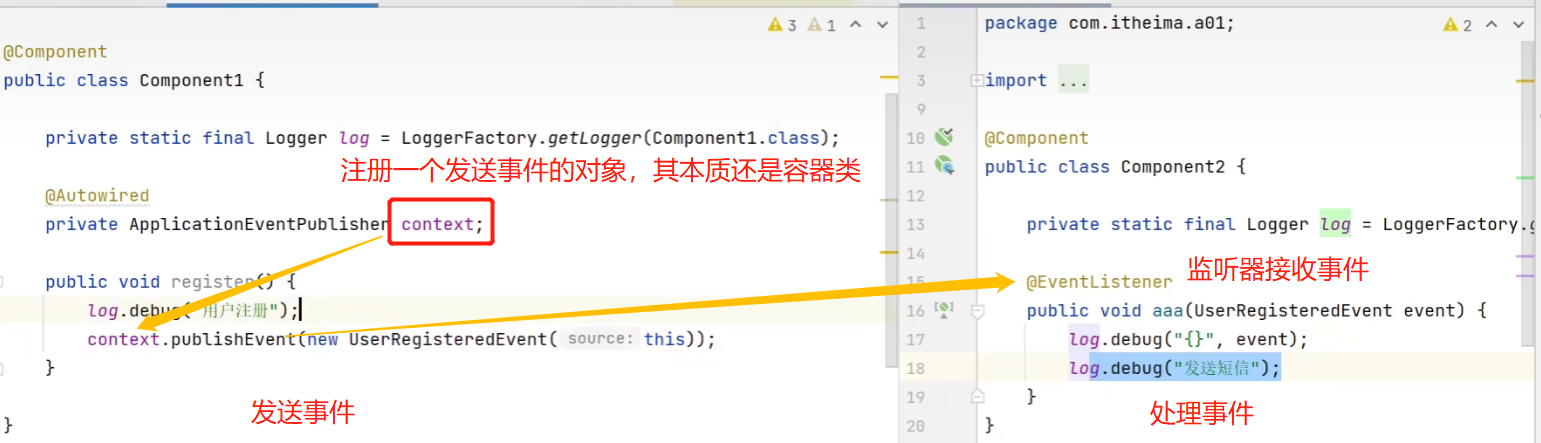
发送方:继承ApplicationEvent定义一个事件。然后使用容器的publishEvent方法发送。source代表事件的事件源。


-
接收方(监听器):在Spring中任何一个组件都可以作为监听器,发的是什么事件就要用对应的事件类型来接收:
-
事件的作用:给我们提供了一种解耦方式
-
-
EnvironmentCapable:其主要作用就是允许组件访问 Environment,从而读取环境变量、Profile()、配置文件等信息



最后我们进行一个总结:
-
到底什么是 BeanFactory
- 它是 ApplicationContext 的父接口
- 它才是 Spring 的核心容器, 主要的 ApplicationContext 实现都【组合】了它的功能,【组合】是指 ApplicationContext 的一个重要成员变量就是 BeanFactory
-
BeanFactory 能干点啥
- 表面上只有 getBean
- 实际上控制反转、基本的依赖注入、直至 Bean 的生命周期的各种功能,都由它的实现类提供
- 例子中通过反射查看了它的成员变量 singletonObjects,内部包含了所有的单例 bean
-
ApplicationContext 比 BeanFactory 多点啥
- ApplicationContext 组合并扩展了 BeanFactory 的功能
- 国际化、通配符方式获取一组 Resource 资源、整合 Environment 环境、事件发布与监听
- 新学一种代码之间解耦途径,事件解耦
注意
- 如果 jdk > 8, 运行时请添加 --add-opens java.base/java.lang=ALL-UNNAMED,这是因为这些版本的 jdk 默认不允许跨 module 反射
- 事件发布还可以异步,请自行查阅 @EnableAsync,@Async 的用法
容器实现
在此节我们将会了解到:
- BeanFactory实现的特点
- ApplicationContext的常见实现和用法
- 内嵌容器、注册DispatcherServlet
Spring 的发展历史较为悠久,因此很多资料还在讲解它较旧的实现,这里出于怀旧的原因,把它们都列出来,供大家参考
- DefaultListableBeanFactory,是 BeanFactory 最重要的实现,像控制反转和依赖注入功能,都是它来实现
- ClassPathXmlApplicationContext,从类路径查找 XML 配置文件,创建容器(旧)
- FileSystemXmlApplicationContext,从磁盘路径查找 XML 配置文件,创建容器(旧)
- XmlWebApplicationContext,传统 SSM 整合时,基于 XML 配置文件的容器(旧)
- AnnotationConfigWebApplicationContext,传统 SSM 整合时,基于 java 配置类的容器(旧)
- AnnotationConfigApplicationContext,Spring boot 中非 web 环境容器(新)
- AnnotationConfigServletWebServerApplicationContext,Spring boot 中 servlet web 环境容器(新)
- AnnotationConfigReactiveWebServerApplicationContext,Spring boot 中 reactive web 环境容器(新)
另外要注意的是,后面这些带有 ApplicationContext 的类都是 ApplicationContext 接口的实现,但它们是组合了 DefaultListableBeanFactory 的功能,并非继承而来
BeanFactory容器实现
这里我们以DefaultListableBeanFactory为例进行容器的创建。
我们刚开始创建一个容器对象的时候里面是没有bean的,所以我们要往其中添加一些bean的定义,然后容器会根据定义帮我们创建bean,最后我们就可以通过容器获得想要的bean。
bean 的定义包括以下几个方面:
- class:bean 的实际实现类。可以是普通类,也可以是抽象类或接口。
- name:bean 的名称。用于从容器中获取 bean 对象。
- scope:bean 的作用域。包括 singleton、prototype、request、session、application 等。
- constructor arguments:bean 构造方法的参数值。用于依赖注入。
- properties:bean 的属性值。用于依赖注入。
- autowire:bean 的自动装配方式。包括 no、byName、byType、constructor。
- lazy-init:bean 的延迟初始化。
- initialization and destruction methods:bean 的初始化方法和销毁方法。
- depends-on:bean 所依赖的其他 bean。
一个 bean 的定义示例:
<bean id="helloBean" name="hello" class="com.example.HelloBean" scope="singleton">
<constructor-arg value="HelloSpring"/>
<property name="message" value="Hello World"/>
</bean>
这个 bean 定义包含:
- id 和 name: helloBean 和 hello
- class: com.example.HelloBean
- scope: singleton
- constructor-arg: 为构造方法传入 “HelloSpring” 参数
- property: 为 message 属性设置 “Hello World” 值
在容器启动时,会根据 bean 的定义创建 bean 实例,即执行:
HelloBean bean = new HelloBean("HelloSpring");
bean.setMessage("Hello World");
创建的 bean 实例会存入单例缓存池中,key 为 bean 的名称,之后可以通过名称从容器中获取这个 bean 对象。
所以总结来说,bean 的定义决定了 bean 的特征, 告诉 Spring 要实例化什么,依赖关系是什么,作用域是什么,如何创建这个 bean 等。根据 bean 的定义,Spring 能够初始化 bean 并且将它插入到应用程序中。
我们来看一段代码:
public class TestBeanFactory {
public static void main(String[] args) {
//创建一个容器类
DefaultListableBeanFactory beanFactory = new DefaultListableBeanFactory();
// bean 的定义(class, scope, 初始化, 销毁)
//这里构建一个bean的定义,指明了类型和Scope
AbstractBeanDefinition beanDefinition =
BeanDefinitionBuilder.genericBeanDefinition(Config.class).setScope("singleton").getBeanDefinition();
//根据定义进行注册,执行bean的名称,创建bean
beanFactory.registerBeanDefinition("config", beanDefinition);
//打印一下现在容器中有的bean的定义
for (String name : beanFactory.getBeanDefinitionNames()) {
System.out.println(name);
}
}
@Configuration
static class Config {
@Bean
public Bean1 bean1() {
return new Bean1();
}
@Bean
public Bean2 bean2() {
return new Bean2();
}
}
static class Bean1 {
private static final Logger log = LoggerFactory.getLogger(Bean1.class);
public Bean1() {
log.debug("构造 Bean1()");
}
@Autowired
private Bean2 bean2;
public Bean2 getBean2() {
return bean2;
}
}
static class Bean2 {
private static final Logger log = LoggerFactory.getLogger(Bean2.class);
public Bean2() {
log.debug("构造 Bean2()");
}
}
}
Tips:
在上面的代码中我们可以看见registerBeanDefinition方法,这个方法是将一个BeanDefinition注册到BeanDefinitionRegistry中,也就是将一个bean定义纳入Spring IoC容器的管理。
BeanDefinitionRegistry是Spring容器中的一个接口,它定义了注册和获取BeanDefinition的方法。其典型实现是:
- DefaultListableBeanFactory:Spring中最常用的BeanFactory实现,它实现了BeanDefinitionRegistry接口。
- AnnotationConfigApplicationContext:注解式Spring应用上下文,它以 DefaultListableBeanFactory 作为delegate(装饰者模式),所以也实现了BeanDefinitionRegistry接口。
registerBeanDefinition方法是BeanDefinitionRegistry接口中的方法,其定义是:
void registerBeanDefinition(String beanName, BeanDefinition >beanDefinition) throws BeanDefinitionStoreException;它接收两个参数:
- beanName:注册的bean名称
- beanDefinition:用于描述bean的BeanDefinition实例
当调用registerBeanDefinition方法时,Spring容器就将接收到的BeanDefinition实例与指定的beanName绑定,并纳入管理。这意味着Spring会对该bean创建实例化,配置和初始化等过程的管理。
举个例子,在AnnotationConfigApplicationContext中,我们可以这样注册一个BeanDefinition:public static void main(String[] args) { AnnotationConfigApplicationContext ctx = new >AnnotationConfigApplicationContext(); RootBeanDefinition beanDefinition = new >RootBeanDefinition(Person.class); ctx.registerBeanDefinition("person", beanDefinition); ctx.refresh(); Person person = ctx.getBean(Person.class); // ... }这里,我们创建了一个RootBeanDefinition,描述了Person类型的bean,然后调用registerBeanDefinition方法注册到ApplicationContext中。在refresh()之后,该bean就可以从容器中获取了。
所以,registerBeanDefinition方法就是向Spring IoC容器注册一个新的bean的方式,将其纳入容器的管理之下,这是向容器中动态添加bean定义的手段。Bean定义一旦注册,容器就可以对其进行初始化、依赖注入等管理工作了。
根据结果我们发现现在容器中只有config的定义,但是根据我们的常识,这里的config是一种配置类,在里面加了@Bean注解之后,我们的容器中应该也有Bean1和Bean2的定义才对。
也就是说Config上的@Configuration注解,包括@Bean注解都没有被解析。换句话说我们这里的DefaultListableBeanFactory没有解析注解的能力,功能并不完整。
于是这里我们引入一个注解相关的工具类:AnnotationConfigUtils。他有一个静态方法registerAnnotationConfigProcessors(注册注释配置处理器),它可以给 BeanFactory 添加一些常用的后处理器(PostProcessor)(当然不只是BeanFactory的后处理器,还有Bean的后处理器,后面会说到)。其实就是对我们容器功能的拓展。
更详细的说AnnotationConfigUtils.registerAnnotationConfigProcessors方法的作用是注册用于处理注解配置的处理器,这些处理器将被用于处理@Configuration、@Import、@ComponentScan等注解。
具体来说,该方法会注册以下几个处理器:
-
ConfigurationClassPostProcessor:用于处理@Configuration注解,将@Configuration注解标注的类解析成一个或多个BeanDefinition对象,并将其注册到BeanFactory中。
-
AutowiredAnnotationBeanPostProcessor:用于处理@Autowired、@Value等注解,将这些注解标注的字段或方法参数注入对应的Bean实例。
-
CommonAnnotationBeanPostProcessor:用于处理JSR-250注解,如@Resource、@PostConstruct等。
-
PersistenceAnnotationBeanPostProcessor:用于处理JPA注解,如@PersistenceContext、@Transactional等。
通过注册这些处理器,Spring能够自动识别和处理各种注解配置,从而更加方便地进行依赖注入和组件扫描等操作。
我们在加上这个方法之后,然后执行每一个处理器,再次遍历容器:

这个时候就能看到我们在配置类中定义的两个Bean了。
但是当我们接下来去调用Bean1中的getBean2方法时却发现获得的是null:
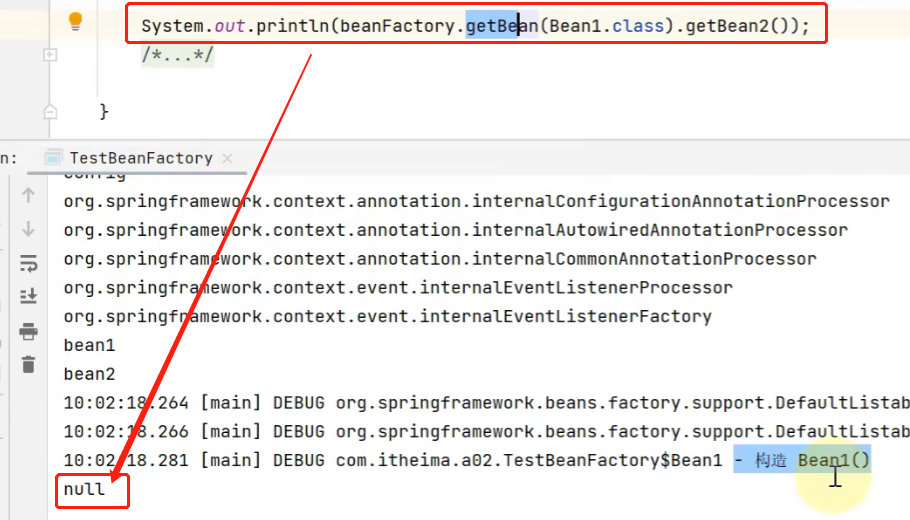
换句话说我们的@Autowired注解没有生效。那么我们怎么解决这个问题呢?
这里我们就要引入一个新的概念叫做Bean的后处理器,前面使用的是BeanFactory的后处理器,他补充了一些Bean的定义。而Bean的后处理器针对Bean生命周期的各个阶段提供扩展,例如@Autowired、@Resource …
我们把这几个处理器进行调用(不用注册,因为前面已经注册过了),就能发现bean1中的bean2依赖被成功注入了:

然后我们很容易会发现,我们的容器是延时进行bean的创建的,也就是用的时候。它自身先开始只会保存一些bean的定义。但是对于一些单例对象来说,我们希望在getBean之前就将这些对象给创建好,这个时候我们就可以调用一个方法叫做DefaultListableBeanFactory.preInstantiateSingletons(),这个方法会预先实例化所有的单例对象。
这里我们小小的总结一下:
BeanFactory 不会做的事
- 不会主动调用 BeanFactory 后处理器
- 不会主动添加 Bean 后处理器
- 不会主动初始化单例
- 不会解析beanFactory 还不会解析 ${ } 与 #{ }
由此可见BeanFactory只是一个基础容器,他的很多功能事先都没有加入体系中来。而ApplicationContext就把这些准备工作给做好了,对开发人员更加的友好
还要注意一点:bean 后处理器会有排序的逻辑。
最后总结一下:
- beanFactory 可以通过 registerBeanDefinition 注册一个 bean definition 对象
- 我们平时使用的配置类、xml、组件扫描等方式都是生成 bean definition 对象注册到 beanFactory 当中
- bean definition 描述了这个 bean 的创建蓝图:scope 是什么、用构造还是工厂创建、初始化销毁方法是什么,等等
- beanFactory 需要手动调用 beanFactory 后处理器对它做增强
- 例如通过解析 @Bean、@ComponentScan 等注解,来补充一些 bean definition
- beanFactory 需要手动添加 bean 后处理器,以便对后续 bean 的创建过程提供增强
- 例如 @Autowired,@Resource 等注解的解析都是 bean 后处理器完成的
- bean 后处理的添加顺序会对解析结果有影响,见视频中同时加 @Autowired,@Resource 的例子
- beanFactory 需要手动调用方法来初始化单例
- beanFactory 需要额外设置才能解析 ${} 与 #{}
ApplicationContext容器实现
其有四个较为经典的实现类:
// ⬇️较为经典的容器, 基于 classpath 下 xml 格式的配置文件来创建
private static void testClassPathXmlApplicationContext() {
}
// ⬇️⬇️较为经典的容器, 基于磁盘路径下 xml 格式的配置文件来创建
private static void testFileSystemXmlApplicationContext() {
}
// ⬇️较为经典的容器, 基于 java 配置类来创建
private static void testAnnotationConfigApplicationContext() {
}
// ⬇️较为经典的容器, 基于 java 配置类来创建, 用于 web 环境
private static void testAnnotationConfigServletWebServerApplicationContext() {
}
我们先来看看前两种,他们比较类似,都是基于xml配置文件,一个是从磁盘路径下加载配置,另一个是从类路径下加载配置,使用情况如下:
// ⬇️较为经典的容器, 基于 classpath 下 xml 格式的配置文件来创建
private static void testClassPathXmlApplicationContext() {
ClassPathXmlApplicationContext context =
new ClassPathXmlApplicationContext("a02.xml");
for (String name : context.getBeanDefinitionNames()) {
System.out.println(name);
}
System.out.println(context.getBean(Bean2.class).getBean1());
}
// ⬇️基于磁盘路径下 xml 格式的配置文件来创建
private static void testFileSystemXmlApplicationContext() {
FileSystemXmlApplicationContext context =
new FileSystemXmlApplicationContext(
"src\\main\\resources\\a02.xml");
for (String name : context.getBeanDefinitionNames()) {
System.out.println(name);
}
System.out.println(context.getBean(Bean2.class).getBean1());
}
配置文件:
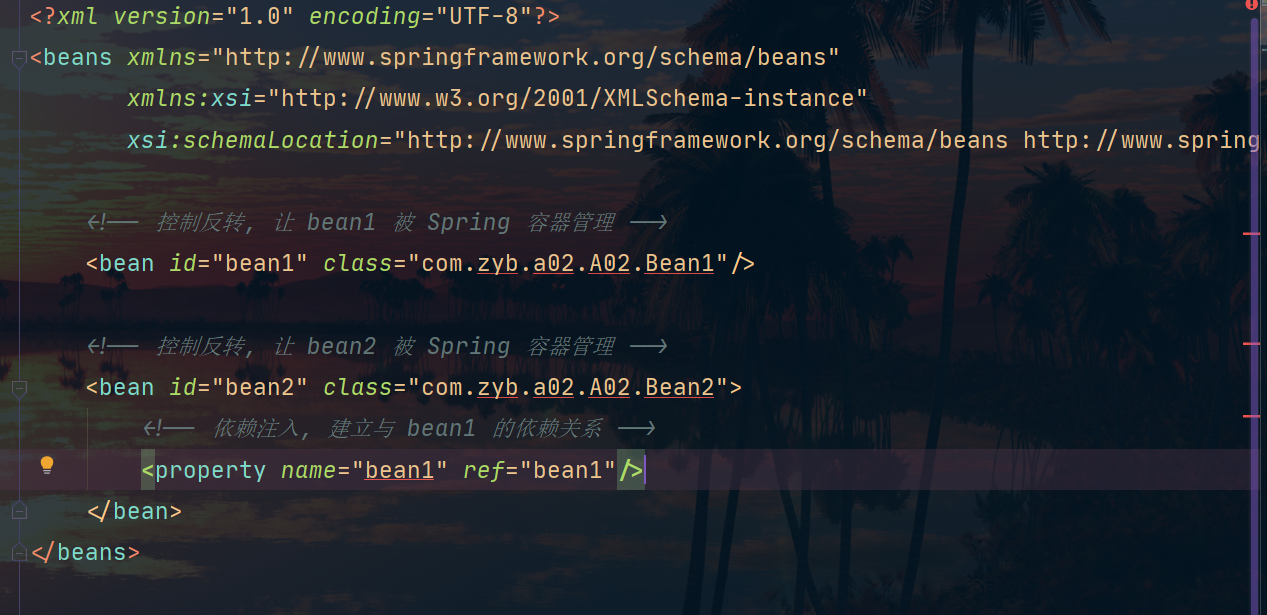
然后我们来说说他们的原理,这里以ClassPathXmlApplicationContext为例,我们前面也说过,其内部肯定需要BeanFactory的支持(BeanFactory负责bean的管理功能),那ClassPathXmlApplicationContext是怎么实现将xml文件解析完之后添加到BeanFactory中去的呢?
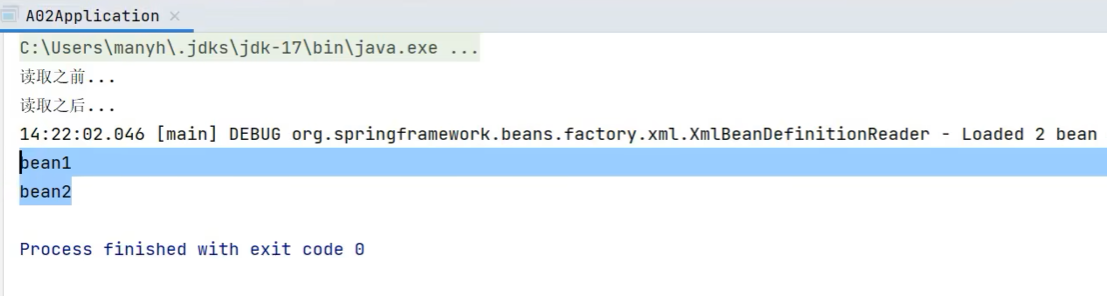
其内部是借助了XmlBeanDefinitionReader,我们可以使用下面的代码试验一下:
DefaultListableBeanFactory beanFactory = new DefaultListableBeanFactory();
System.out.println("读取之前...");
for (String name : beanFactory.getBeanDefinitionNames()) {
System.out.println(name);
}
System.out.println("读取之后...");
XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(beanFactory);
reader.loadBeanDefinitions(new FileSystemResource("src\\main\\resources\\a02.xml"));
for (String name : beanFactory.getBeanDefinitionNames()) {
System.out.println(name);
}
然后我们再来看看第三种实现:
// ⬇️较为经典的容器, 基于 java 配置类来创建
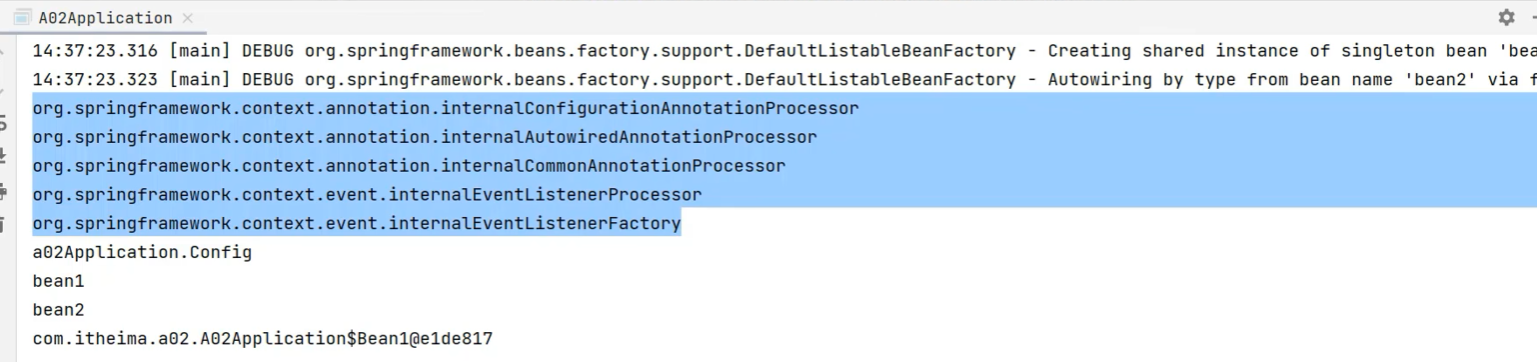
private static void testAnnotationConfigApplicationContext() {
AnnotationConfigApplicationContext context =
new AnnotationConfigApplicationContext(Config.class);
for (String name : context.getBeanDefinitionNames()) {
System.out.println(name);
}
System.out.println(context.getBean(Bean2.class).getBean1());
}
@Configuration
static class Config {
@Bean
public Bean1 bean1() {
return new Bean1();
}
@Bean
public Bean2 bean2(Bean1 bean1) {
Bean2 bean2 = new Bean2();
bean2.setBean1(bean1);
return bean2;
}
}
我们运行之后发现,跟前面的xml相比,容器中多了几个bean(我们前面提到过的后处理器):
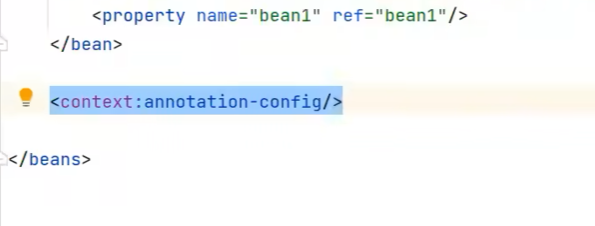
而如果使用前面那两种基于xml配置文件的ApplicationContext容器类的话,我们就需要手动配置一下:
最后我们来看看第四类:
// ⬇️较为经典的容器, 基于 java 配置类来创建, 用于 web 环境
private static void testAnnotationConfigServletWebServerApplicationContext() {
AnnotationConfigServletWebServerApplicationContext context =
new AnnotationConfigServletWebServerApplicationContext(WebConfig.class);
for (String name : context.getBeanDefinitionNames()) {
System.out.println(name);
}
}
@Configuration
static class WebConfig {
@Bean
public ServletWebServerFactory servletWebServerFactory(){
return new TomcatServletWebServerFactory();
}
@Bean
public DispatcherServlet dispatcherServlet() {
return new DispatcherServlet();
}
@Bean
public DispatcherServletRegistrationBean registrationBean(DispatcherServlet dispatcherServlet) {
return new DispatcherServletRegistrationBean(dispatcherServlet, "/");
}
}
要想启动一个web项目,那么容器中有三个bean不能少:
- ServletWebServerFactory
- DispatcherServlet
- DispatcherServletRegistrationBean
我们先来看看ServletWebServerFactory :
ServletWebServerFactory 是一个 Servlet Web 服务器工厂接口,用于在 Spring 应用中启动嵌入式的 Servlet 容器。
在Spring Boot 应用中,我们通常使用嵌入式 Tomcat、Jetty 或 Undertow 等 Servlet 容器,而不用打包成 WAR 文件部署到 standalone Servlet 容器中。
ServletWebServerFactory 接口的实现类就是这些嵌入式 Servlet 容器工厂,主要有:
- TomcatServletWebServerFactory:嵌入式 Tomcat 工厂
- JettyServletWebServerFactory:嵌入式 Jetty 工厂
- UndertowServletWebServerFactory:嵌入式 Undertow 工厂
在 Spring Boot 应用中,我们通常不需要手动配置这些工厂,因为根据你添加的依赖,Spring Boot 会自动选择一个工厂配置。例如:
- 添加 spring-boot-starter-tomcat,会自动使用 TomcatServletWebServerFactory
- 添加 spring-boot-starter-jetty,会自动使用 JettyServletWebServerFactory
- 添加 spring-boot-starter-undertow,会自动使用 UndertowServletWebServerFactory
但是,如果需要定制嵌入式 Servlet 容器的配置,我们可以手动添加一个 ServletWebServerFactory bean。例如:
@Bean
public ServletWebServerFactory servletContainer() {
TomcatServletWebServerFactory factory = new TomcatServletWebServerFactory();
factory.setPort(9000);
factory.setSessionTimeout(10 * 60);
return factory;
}
这里我们定制了 Tomcat 服务器,设置端口为 9000 和 session 超时时间为 10 分钟。
ServletWebServerFactory 的其他用法还有:
- 添加多个 ServletWebServerFactory 来启动多个嵌入式 Servlet 容器实例。
- 根据环境不同选择不同的 ServletWebServerFactory,例如在 Windows 环境下选择 Undertow。
- 进行更深层次的 Servlet 容器配置。ServletWebServerFactory 只暴露了部分配置选项,深层次配置可以直接调用 Servlet 容器的 API。
所以,总结来说,ServletWebServerFactory 的主要作用是:
- 在 Spring Boot 应用中启动嵌入式的 Servlet 容器(Tomcat、Jetty、Undertow)
- 可以定制 Servlet 容器配置,覆盖默认配置
- 启动多个 Servlet 容器实例
- 根据环境选择不同的 Servlet 容器
至于DispatcherServlet这个大家应该都熟悉,对网络请求进行拦截,我们一般叫他前置控制器,相当于Springweb程序的入口。
现在内嵌web容器有了,DispatcherServlet有了,但是他们两个还没有联系,我们要将DispatcherServlet注册在web容器中。
而DispatcherServletRegistrationBean 是一个 Servlet 注册 bean,用于向 Servlet 容器注册 DispatcherServlet。
有了这三个bean之后,我们就能启动一个web项目了,但是我们还什么都不能,于是我们再添加一个控制器Controller:
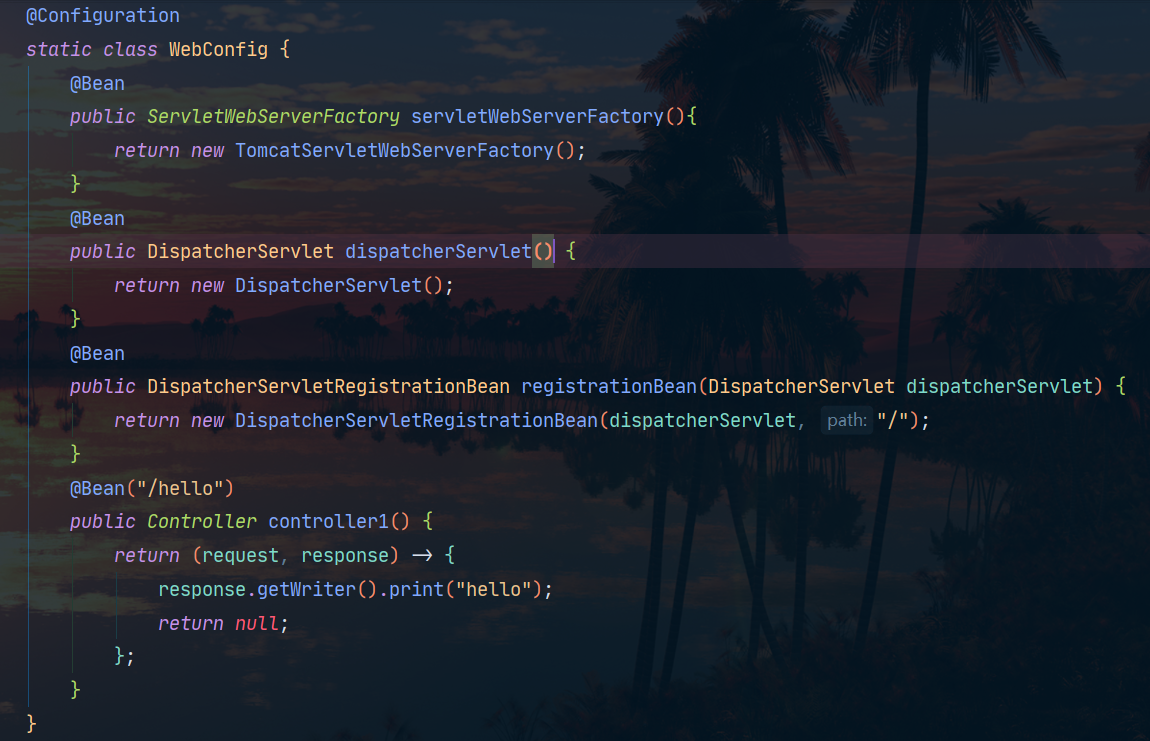
这里注意:约定如果bean的name是/开头的,就代表拦截路径。
Bean的生命周期
一个受 Spring 管理的 bean,生命周期主要阶段有
- 创建:根据 bean 的构造方法或者工厂方法来创建 bean 实例对象
- 依赖注入:根据 @Autowired,@Value 或其它一些手段,为 bean 的成员变量填充值、建立关系
- 初始化:回调各种 Aware 接口,调用对象的各种初始化方法
- 销毁:在容器关闭时,会销毁所有单例对象(即调用它们的销毁方法)
- prototype 对象也能够销毁,不过需要容器这边主动调用
我们使用代码来验证一下:
@Component
public class LifeCycleBean {
private static final Logger log = LoggerFactory.getLogger(LifeCycleBean.class);
public LifeCycleBean() {
log.debug("构造");
}
@Autowired
public void autowire(@Value("${JAVA_HOME}") String home) {
log.debug("依赖注入: {}", home);
}
@PostConstruct
public void init() {
log.debug("初始化");
}
@PreDestroy
public void destroy() {
log.debug("销毁");
}
}
测试类:
@SpringBootApplication
public class A03 {
public static void main(String[] args) {
ConfigurableApplicationContext context = SpringApplication.run(A03.class, args);
context.close();
}
}
运行结果:
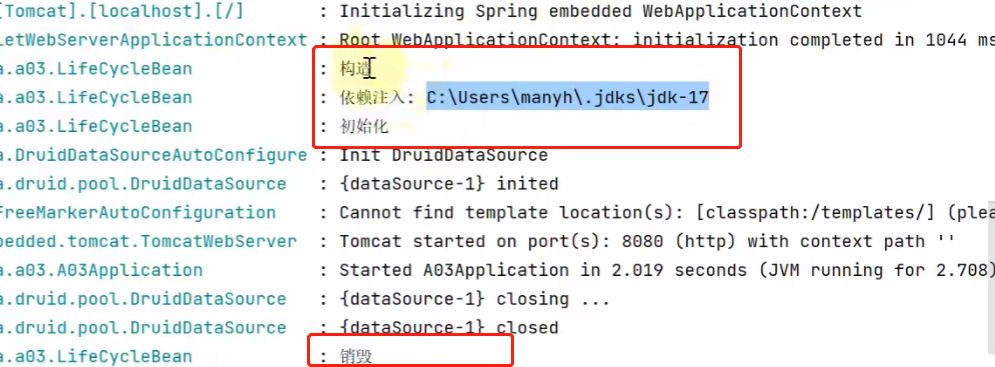
大家应该还记得我们前面提到过的Bean后处理器,它与我们bean的生命周期息息相关,它可以为bean生命周期的各个阶段提供功能的拓展,我们接下来看一段代码:
@Component
public class MyBeanPostProcessor implements InstantiationAwareBeanPostProcessor, DestructionAwareBeanPostProcessor {
private static final Logger log = LoggerFactory.getLogger(MyBeanPostProcessor.class);
@Override
public void postProcessBeforeDestruction(Object bean, String beanName) throws BeansException {
if (beanName.equals("lifeCycleBean"))
log.debug("<<<<<< 销毁之前执行, 如 @PreDestroy");
}
@Override
public Object postProcessBeforeInstantiation(Class<?> beanClass, String beanName) throws BeansException {
if (beanName.equals("lifeCycleBean"))
log.debug("<<<<<< 实例化之前执行, 这里返回的对象会替换掉原本的 bean");
return null;
}
@Override
public boolean postProcessAfterInstantiation(Object bean, String beanName) throws BeansException {
if (beanName.equals("lifeCycleBean")) {
log.debug("<<<<<< 实例化之后执行, 这里如果返回 false 会跳过依赖注入阶段");
// return false;
}
return true;
}
@Override
public PropertyValues postProcessProperties(PropertyValues pvs, Object bean, String beanName) throws BeansException {
if (beanName.equals("lifeCycleBean"))
log.debug("<<<<<< 依赖注入阶段执行, 如 @Autowired、@Value、@Resource");
return pvs;
}
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
if (beanName.equals("lifeCycleBean"))
log.debug("<<<<<< 初始化之前执行, 这里返回的对象会替换掉原本的 bean, 如 @PostConstruct、@ConfigurationProperties");
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (beanName.equals("lifeCycleBean"))
log.debug("<<<<<< 初始化之后执行, 这里返回的对象会替换掉原本的 bean, 如代理增强");
return bean;
}
}
我们执行一下:


创建前后的增强
- postProcessBeforeInstantiation
- 这里返回的对象若不为 null 会替换掉原本的 bean,并且仅会走 postProcessAfterInitialization 流程
- postProcessAfterInstantiation
- 这里如果返回 false 会跳过依赖注入阶段
依赖注入前的增强
- postProcessProperties
- 如 @Autowired、@Value、@Resource
初始化前后的增强
- postProcessBeforeInitialization
- 这里返回的对象会替换掉原本的 bean
- 如 @PostConstruct、@ConfigurationProperties
- postProcessAfterInitialization
- 这里返回的对象会替换掉原本的 bean
- 如代理增强
销毁之前的增强
- postProcessBeforeDestruction
- 如 @PreDestroy
模板方法设计模式
模板方法模式通过定义一个算法骨架,并将某些步骤的实现延迟到子类,使得子类可以在不改变算法结构的情况下,重新定义该算法的某些特定步骤,从而实现算法的扩展与封装。
模板方法中使用动静结合的方式实现方法的可拓展性:
- 动:不确定的部分,抽象成子类或者接口,进行回调
- 静:固定的算法骨架
通俗点说指大流程已经固定好了, 通过接口回调(bean 后处理器)在一些关键点前后提供扩展
我们看一个例子:
现在我们模拟一个BeanFactory容器:
// 模板方法 Template Method Pattern
static class MyBeanFactory {
public Object getBean() {
Object bean = new Object();
System.out.println("构造 " + bean);
System.out.println("依赖注入 " + bean); // @Autowired, @Resource
System.out.println("初始化 " + bean);
return bean;
}
}
刚开始我们设计代码的时候没有考虑到后期的扩展性,后面要添加新的功能,我们只能不断的往里面积累代码,最后这个方法会变得庞大冗杂。
这里我们可以使用模板方法设计模式改造一下上面的代码:
例如我们想在依赖注入之后添加一些逻辑,那么我们可以把依赖注入后的逻辑抽象成一个接口,然后再在依赖注入之后一个个进行调用
public class TestMethodTemplate {
public static void main(String[] args) {
MyBeanFactory beanFactory = new MyBeanFactory();
beanFactory.addBeanPostProcessor(bean -> System.out.println("解析 @Autowired"));
beanFactory.addBeanPostProcessor(bean -> System.out.println("解析 @Resource"));
beanFactory.getBean();
}
// 模板方法 Template Method Pattern
static class MyBeanFactory {
public Object getBean() {
Object bean = new Object();
System.out.println("构造 " + bean);
System.out.println("依赖注入 " + bean); // @Autowired, @Resource
for (BeanPostProcessor processor : processors) {
processor.inject(bean);
}
System.out.println("初始化 " + bean);
return bean;
}
private List<BeanPostProcessor> processors = new ArrayList<>();
public void addBeanPostProcessor(BeanPostProcessor processor) {
processors.add(processor);
}
}
static interface BeanPostProcessor {
public void inject(Object bean); // 对依赖注入阶段的扩展
}
}
Bean后处理器
- @Autowired 等注解的解析属于 bean 生命周期阶段(依赖注入, 初始化)的扩展功能,这些扩展功能由 bean 后处理器来完成
- 每个后处理器各自增强什么功能
- AutowiredAnnotationBeanPostProcessor 解析 @Autowired 与 @Value
- CommonAnnotationBeanPostProcessor 解析 @Resource、@PostConstruct、@PreDestroy
- ConfigurationPropertiesBindingPostProcessor 解析 @ConfigurationProperties
- 另外 ContextAnnotationAutowireCandidateResolver 负责获取 @Value 的值,解析 @Qualifier、泛型、@Lazy 等(该注解较为复杂,后面会详细讲解)
然后我们来详细说说AutowiredAnnotationBeanPostProcessor这个Bean后处理器的运行原理。
要向了解这个方法,我们就把他单拿出来用,我们写了下面的测试代码:
// AutowiredAnnotationBeanPostProcessor 运行分析
public class DigInAutowired {
public static void main(String[] args) throws Throwable {
DefaultListableBeanFactory beanFactory = new DefaultListableBeanFactory();
beanFactory.registerSingleton("bean2", new Bean2()); // 创建过程,依赖注入,初始化
beanFactory.registerSingleton("bean3", new Bean3());
beanFactory.setAutowireCandidateResolver(new ContextAnnotationAutowireCandidateResolver()); // @Value
AutowiredAnnotationBeanPostProcessor processor = new AutowiredAnnotationBeanPostProcessor();
processor.setBeanFactory(beanFactory); //依赖注入部分跟Bean有关,需要得到BeanFactory的支持
Bean1 bean1 = new Bean1();
System.out.println(bean1);
processor.postProcessProperties(null, bean1, "bean1"); // 执行依赖注入 @Autowired @Value
System.out.println(bean1);
}
}
这里我们的bean1中需要三种依赖:
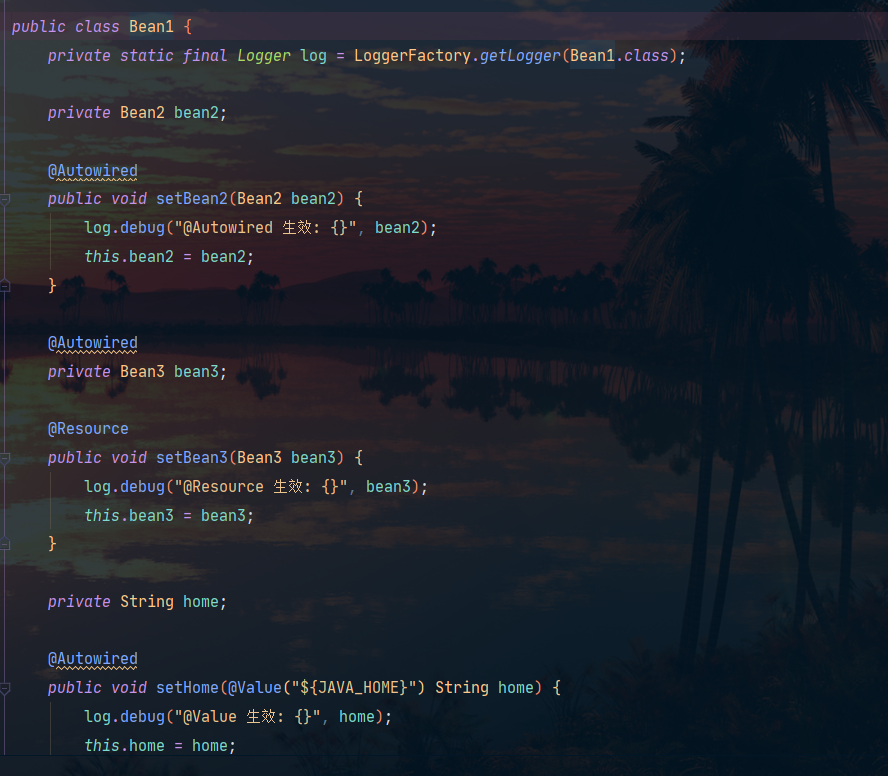
图片勘误:此时Bean3上是没有@Autowired注解的
在 Spring 中,@Autowired 注解标注在方法上表示该方法需要自动注入依赖的 bean。Spring 会在调用该方法时,自动从上下文中查找名称与参数类型相匹配的 bean,并将其注入方法。
运行结果:

这里的${}没有被解析,我们可以加一句:
beanFactory.addEmbeddedValueResolver(new StandardEnvironment()::resolvePlaceholders); // ${} 的解析器
在调用了AutowiredAnnotationBeanPostProcessor中的postProcessProperties方法之后,我们的依赖成功注入,说明就是这个方法起到了作用,接下来我们就来看看它是如何执行的:
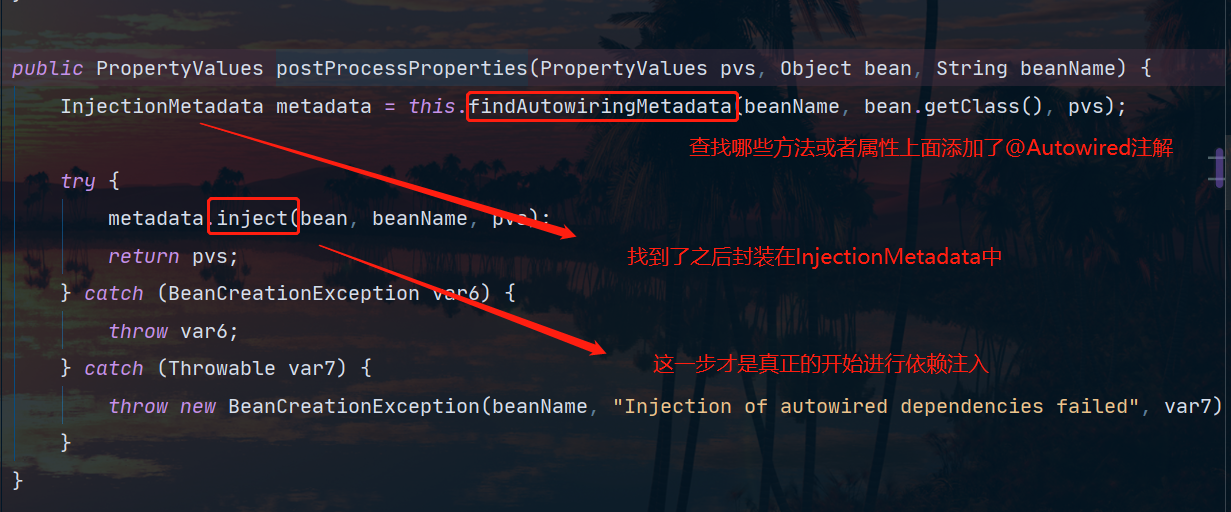
我们可以打断点看一下,这个InjectionMetadata:
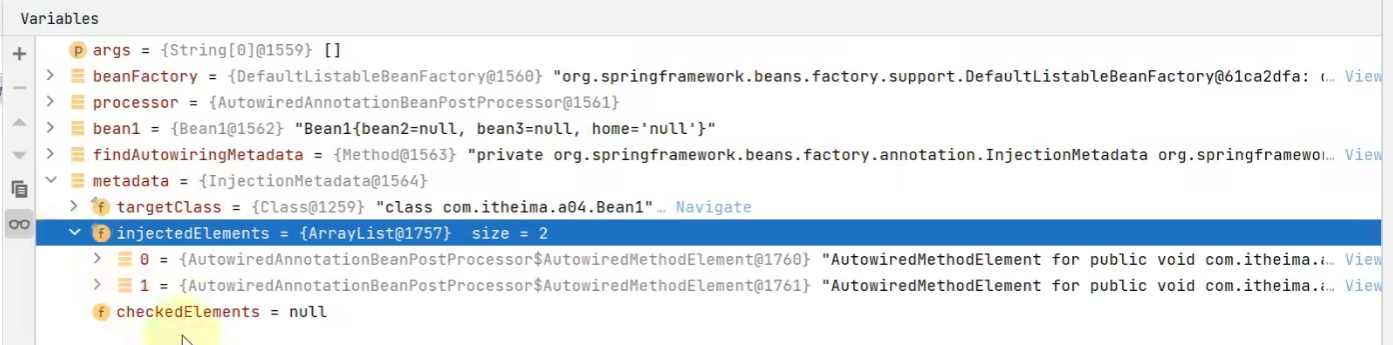

与我们这两个方法正好对应:
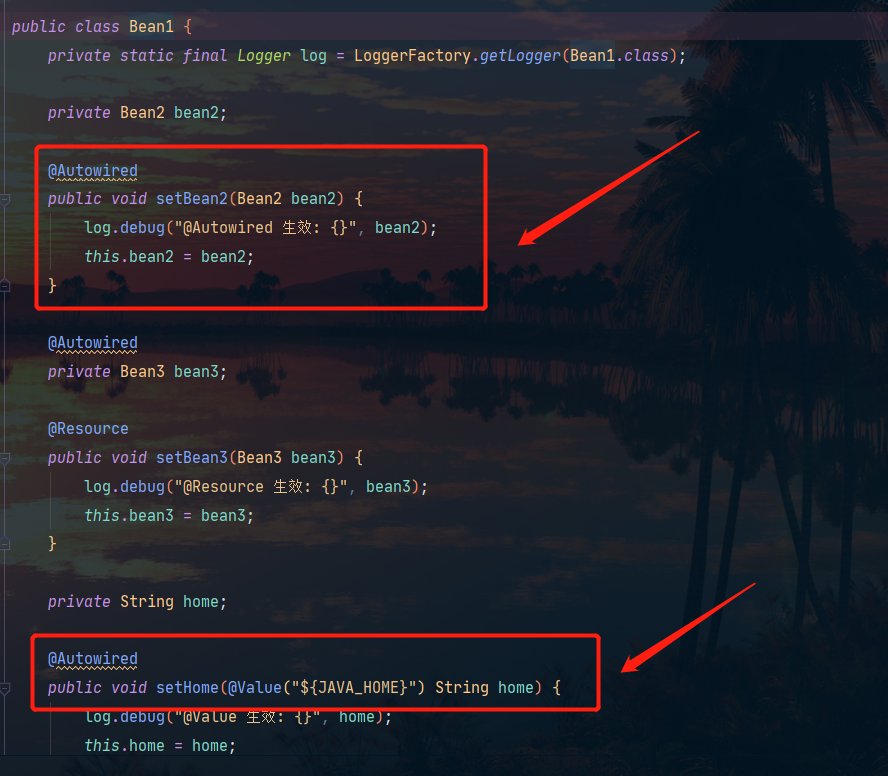
图片勘误:此时Bean3上是没有@Autowired注解的
而在inject方法中,其逻辑就是将方法参数或者属性使用DependencyDescriptor 包一层,然后我们就可以借助beanFactory.doResolveDependency 方法进行查找,过程如下:
//@Autowired作用于Bean3
Field bean3 = Bean1.class.getDeclaredField("bean3");
DependencyDescriptor dd1 = new DependencyDescriptor(bean3, false);
Object o = beanFactory.doResolveDependency(dd1, null, null, null);
System.out.println(o);
//@Autowired作用于setBean2方法
Method setBean2 = Bean1.class.getDeclaredMethod("setBean2", Bean2.class);
DependencyDescriptor dd2 =
new DependencyDescriptor(new MethodParameter(setBean2, 0), true);
Object o1 = beanFactory.doResolveDependency(dd2, null, null, null);
System.out.println(o1);
//@Autowired作用于setHome方法
Method setHome = Bean1.class.getDeclaredMethod("setHome", String.class);
DependencyDescriptor dd3 = new DependencyDescriptor(new MethodParameter(setHome, 0), true);
Object o2 = beanFactory.doResolveDependency(dd3, null, null, null);
System.out.println(o2);
对应下图中的三部分:
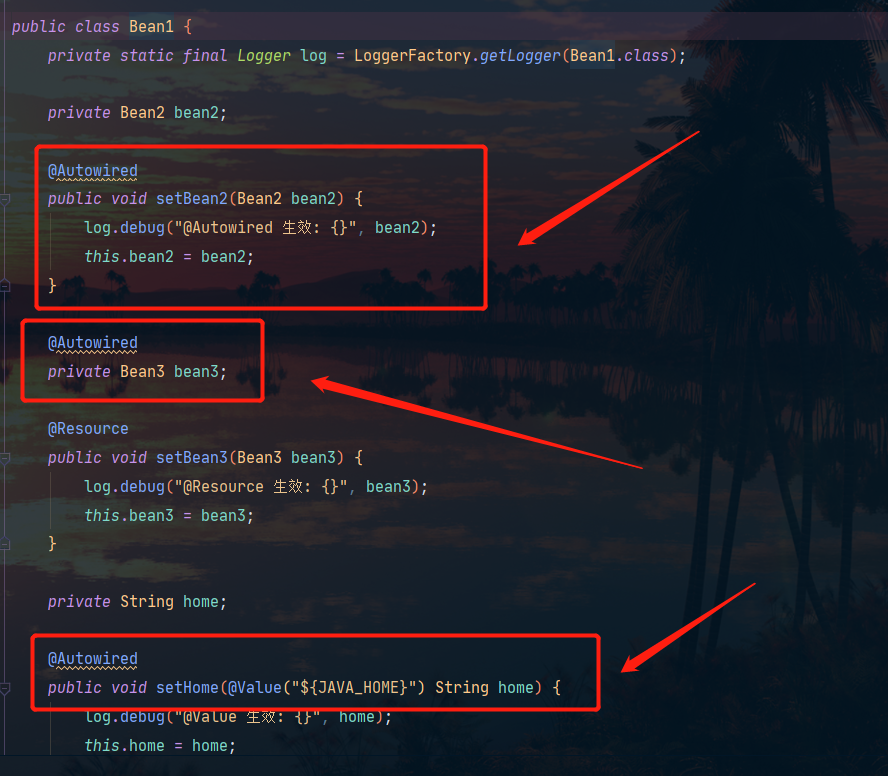
最后我们总结一下AutowiredAnnotationBeanPostProcessor这个Bean后处理器的运行原理:
- AutowiredAnnotationBeanPostProcessor.findAutowiringMetadata 用来获取某个 bean 上加了 @Value @Autowired 的成员变量,方法参数的信息,表示为 InjectionMetadata
- InjectionMetadata 可以完成依赖注入
- InjectionMetadata 内部根据成员变量,方法参数封装为 DependencyDescriptor 类型
- 有了 DependencyDescriptor,就可以利用 beanFactory.doResolveDependency 方法进行基于类型的查找
BeanFactory 后处理器
实验代码如下,跟前面的思路差不多(控制变量):
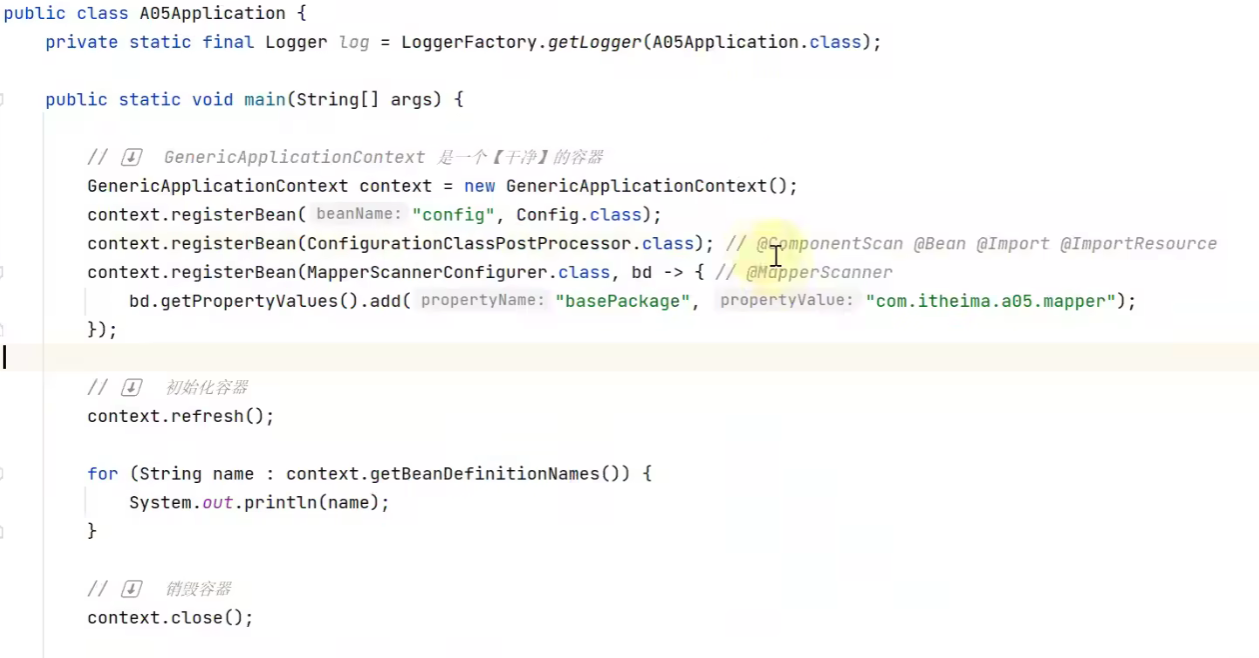
这里的初始化容器会有两个操作:
- 会把BeanFactory的后处理器执行完
- 创建每个单例Bean
可以得出结论:
- ConfigurationClassPostProcessor 可以解析
- @ComponentScan
- @Bean
- @Import
- @ImportResource
- MapperScannerConfigurer 可以解析
- Mapper 接口
- @ComponentScan, @Bean, @Mapper 等注解的解析属于核心容器(即 BeanFactory)的扩展功能
- 这些扩展功能由不同的 BeanFactory 后处理器来完成,其实主要就是补充了一些 bean 定义
接下来我们通过模拟来弄清ConfigurationClassPostProcessor是如何解析@ComponentScan注解的。
//在初始化容器的时候会回调这个BeanFactory后处理器
public class ComponentScanPostProcessor implements BeanDefinitionRegistryPostProcessor {
@Override // context.refresh
public void postProcessBeanFactory(ConfigurableListableBeanFactory configurableListableBeanFactory) throws BeansException {
}
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry beanFactory) throws BeansException {
try {
//在指定的类、方法、字段或者构造器上查找指定类型的注解。如果找到,则返回该注解,否则返回 null。
ComponentScan componentScan = AnnotationUtils.findAnnotation(Config.class, ComponentScan.class);
if (componentScan != null) {
for (String p : componentScan.basePackages()) {
//System.out.println(p);
//将包名转化为路径名方便后面资源的查找
// com.zyb.a05.component -> classpath*:com/zyb/a05/component/**/*.class
String path = "classpath*:" + p.replace(".", "/") + "/**/*.class";
//System.out.println(path);
CachingMetadataReaderFactory factory = new CachingMetadataReaderFactory();
Resource[] resources = new PathMatchingResourcePatternResolver().getResources(path);
//一个工具类:根据类上的注解生成 bean 的名称
AnnotationBeanNameGenerator generator = new AnnotationBeanNameGenerator();
for (Resource resource : resources) {
// System.out.println(resource);
MetadataReader reader = factory.getMetadataReader(resource);
// System.out.println("类名:" + reader.getClassMetadata().getClassName());
AnnotationMetadata annotationMetadata = reader.getAnnotationMetadata();
// System.out.println("是否加了 @Component:" + annotationMetadata.hasAnnotation(Component.class.getName()));
// System.out.println("是否加了 @Component 派生:" + annotationMetadata.hasMetaAnnotation(Component.class.getName()));
if (annotationMetadata.hasAnnotation(Component.class.getName())
|| annotationMetadata.hasMetaAnnotation(Component.class.getName())) {
//创建一个Bean的定义
AbstractBeanDefinition bd = BeanDefinitionBuilder
.genericBeanDefinition(reader.getClassMetadata().getClassName())
.getBeanDefinition();
//根据类上的注解生成 bean 的名称
String name = generator.generateBeanName(bd, beanFactory);
//根据定义注册Bean
beanFactory.registerBeanDefinition(name, bd);
}
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
这里该类实现的BeanDefinitionRegistryPostProcessor也是一种BeanFactory后处理器:
在Spring容器初始化时,它会自动检测并调用所有注册的BeanDefinitionRegistryPostProcessor,对Bean定义进行处理,然后再将其实例化。
该后处理器允许我们在Spring bean定义加载完成后,实例化bean之前,修改bean定义。
BeanDefinitionRegistryPostProcessor接口定义了两个方法:
- postProcessBeanDefinitionRegistry():在bean定义加载后,实例化前被调用。可以修改bean定义。
- postProcessBeanFactory():在bean定义加载后,实例化前被调用。可以在这里获得BeanFactory,但是此时不能获得bean实例。

基本逻辑就是:
- 通过ComponentScan注解拿到扫描的包
- 拿到包下的所有类文件
- 判断哪些类文件上有Component注解或者其派生注解
- 将符合要求的类进行注册
注意点:
-
有关路径中的符号:
*代表 0 到多个字符,例如:*.txt代表所有 txt 文件**代表 0 到多个文件夹,例如:/app1/**、/app2/**代表 app1 文件夹下任意层文件夹,以及其下的 app2 任意层文件夹
-
在 Spring 中,我们可以使用 MetadataReader 来读取类信息,例如类名称、接口、注解等。但是获取 MetadataReader 对象的开销是比较大的,每次都从类路径下加载类信息会影响性能。
-
CachingMetadataReaderFactory 就是为了解决这个问题而存在的。它 内部维护了一个 MetadataReader 实例的缓存,可以重用已经创建的 MetadataReader 实例,而不需要每次都完全重新加载类信息。
总结一下:
- Spring 操作元数据的工具类 CachingMetadataReaderFactory
- 通过注解元数据(AnnotationMetadata)获取直接或间接标注的注解信息
- 通过类元数据(ClassMetadata)获取类名,AnnotationBeanNameGenerator 生成 bean 名
- 解析元数据是基于 ASM 技术
ASM 是一个 Java 字节码操控框架。它允许我们以二进制形式修改字节码,或者动态生成类。
ASM 可以用于:
- 动态生成类:在运行时根据某些规则生成类的字节码。
- 修改类:在运行时为类添加字段或方法,修改类中的方法体等。
- 分析类:在运行时获取类的详细信息,如类继承关系,类中的方法,字段等。
- 转换类:在运行时将类文件从一种格式转换成另一种格式,如从 Java class 文件转换为 dex 文件等。
ASM 的工作原理是:它分析类文件的字节码,将之转换为更高层的 ASM 元素(称为 Node)来表示,如 MethodNode、FieldNode 等。我们可以通过添加或修改这些 Node 来生成新的类,或修改已有类。
接下来我们还要注意一点:
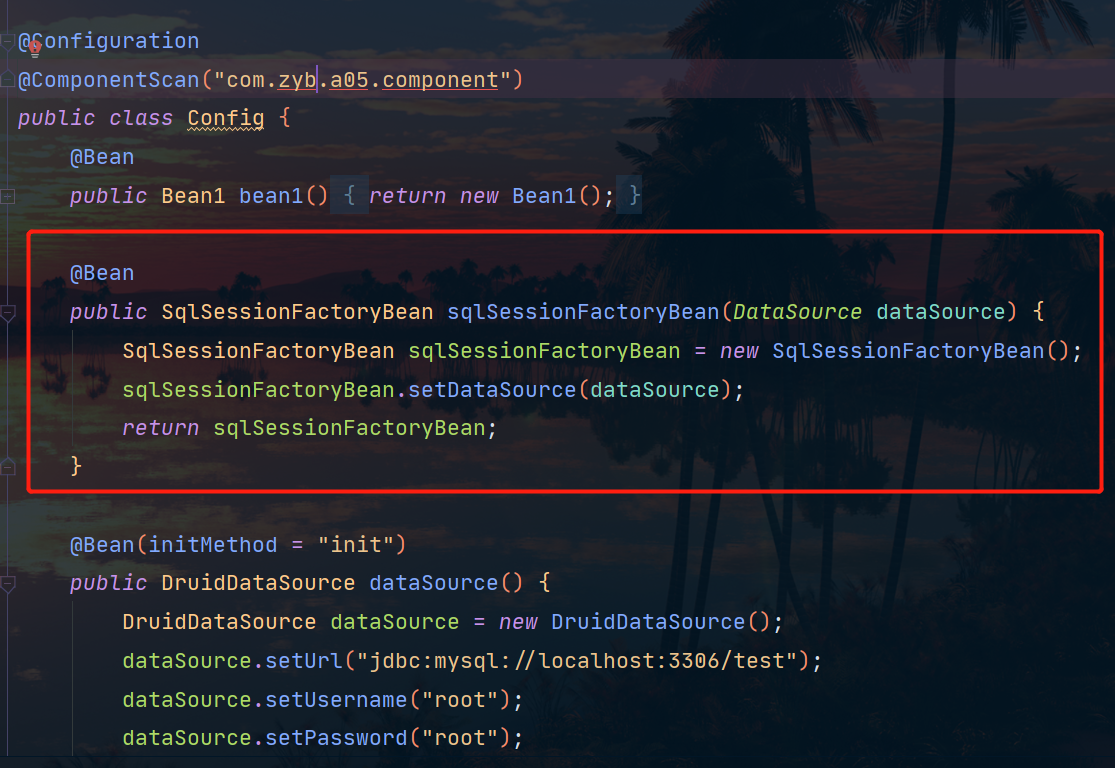
在这一段配置类代码中我们其实可以看见两种定义bean的方法:
- Configuration类 + @Bean
- Configuration类 + 工厂Bean(图中红方框部分)
第一种我们非常熟悉,那第二种中的工厂Bean是什么呢?
在Spring中,FactoryBean接口是一个工厂bean的接口。实现这个接口的bean会在 Spring 容器中被当做工厂bean。当一个bean依赖工厂bean时,会调用getObject()方法获得bean实例。它允许你在 Bean 的实例化过程中执行一些自定义的逻辑。
工厂Bean通常遵循以下模式:
- 实现 org.springframework.beans.factory.FactoryBean 接口
- 在 getObject() 方法中返回要从工厂中生成的 Bean 实例
- 返回要生成的 Bean 的类型,在 getObjectType() 方法中指定
- 在 isSingleton() 方法中指定生成的 Bean 是否为单例
工厂Bean可以和@Configuration配置类很好地结合来定义bean。
比如,我们可以在配置类中定义一个工厂后处理器方法,使用@Bean注解来注册这个工厂后处理器:
@Configuration
public class AppConfig {
@Bean
public MyFactoryBean myFactoryBean() {
return new MyFactoryBean();
}
}
然后工厂后处理器MyFactoryBean可以在getObject()方法中定义bean:
public class MyFactoryBean implements FactoryBean<Example> {
@Override
public Example getObject() throws Exception {
return new Example();
}
}
在这种方式下,Spring会:
- 实例化配置类AppConfig
- 调用myFactoryBean()方法,并将返回的MyFactoryBean实例注册为一个bean
- 从MyFactoryBean获取最终bean实例,调用getObject()方法返回的Example实例也会被注册为一个bean
所以,最终会注册两个bean:
- myFactoryBean:MyFactoryBean实例
- example:Example实例
并且example bean是由myFactoryBean工厂后处理器生成的。
客户端可以像注入普通bean一样注入example:
public class Client {
@Autowired
private Example example;
}
这样,我们就通过配置类和工厂Bean灵活地定义了bean。配置类定义工厂Bean,工厂Bean又自定义了最终的bean。
这种方式将工厂Bean的灵活性和@Configuration带来的便利性很好结合在一起,是在Spring中定义bean的一种很实用的模式。
在我们的代码中就符合这种模式,如图:
接下来我们还是使用代码模拟一下这个解析过程:
public class AtBeanPostProcessor implements BeanDefinitionRegistryPostProcessor {
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory configurableListableBeanFactory) throws BeansException {
}
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry beanFactory) throws BeansException {
try {
//首先建立一个元数据读取工厂,方便后面的元数据读取
CachingMetadataReaderFactory factory = new CachingMetadataReaderFactory();
//对指定路径上的类资源进行元数据读取
MetadataReader reader = factory.getMetadataReader(new ClassPathResource("com/itheima/a05/Config.class"));
//得到所有带有@Bean注解的方法
Set<MethodMetadata> methods = reader.getAnnotationMetadata().getAnnotatedMethods(Bean.class.getName());
for (MethodMetadata method : methods) {
System.out.println(method);
//创建BeanDefinitionBuilder
BeanDefinitionBuilder builder = BeanDefinitionBuilder.genericBeanDefinition();
//提供工厂方法的名字,同时指定工厂对象
builder.setFactoryMethodOnBean(method.getMethodName(), "config");
//因为 工厂方法有参数我们这里要设置自动装配的模式
builder.setAutowireMode(AbstractBeanDefinition.AUTOWIRE_CONSTRUCTOR);
//得到bean定义
AbstractBeanDefinition bd = builder.getBeanDefinition();
//通过BeanFactory进行bean的注册
beanFactory.registerBeanDefinition(method.getMethodName(), bd);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
注意:
- 因为 工厂方法有参数,所以我们这里要设置自动装配的模式
- 对于工厂方法和构造方法的参数,如果想使用自动装配的话,都是
AbstractBeanDefinition.AUTOWIRE_CONSTRUCTOR类型 - 我们可以把配置类想象成一个工厂的角色,配置类中用@Bean标注的方法充当的是工厂方法的角色。
最后我们来模拟解析Mapper 接口:
首先我们要弄明白Mapper接口是怎么被Spring管理的?
Spring会根据Mapper接口自动生成代理实现类,这就是Spring管理Mapper接口的方式。
具体步骤是:
- 在Spring配置中注册Mapper接口,通常使用@MapperScan注解扫描包下的所有Mapper接口:
@MapperScan("com.example.mapper") @Configuration public class AppConfig { } - Spring会根据 Mapper接口生成对应的代理对象,代理对象会实现Mapper接口的方法。
- 当调用Mapper接口的方法时,实际执行的是代理对象的方法。代理对象会从SqlSessionFactory中获得SqlSession,并调用SqlSession执行数据库操作。
- SqlSession是由Spring使用SqlSessionFactory创建的。SqlSessionFactory是根据DataSource和Mapper XML或注解配置获得的。
所以,整个流程是:
- 注册Mapper接口(通常使用@MapperScan)
- Spring生成Mapper接口的代理对象
- 程序调用Mapper接口方法,实际上调用的是代理对象方法
- 代理对象通过SqlSession执行数据库操作
- SqlSession是从SqlSessionFactory获得的,SqlSessionFactory是从DataSource配置的
看完上面这个流程之后,我们可以很容易产生一个疑问:这个Mapper的代理对象是从哪里来的?
这里我们就要引入另外一个重要的组件:MapperFactoryBean
MapperFactoryBean是一个工厂bean,用于生成Mapper接口代理对象。也就是说,Spring实际上是通过MapperFactoryBean来管理Mapper接口的。
当我们在Spring配置中注册一个Mapper接口 bean 时,Spring会使用MapperFactoryBean来生成这个bean。
整个过程是:
- 在 Spring 配置中定义 Mapper接口bean,并指定 class 为 MapperFactoryBean:
<bean id="userMapper" class="org.mybatis.spring.mapper.MapperFactoryBean"> <property name="mapperInterface" value="com.example.mapper.UserMapper" /> </bean> - Spring会实例化一个MapperFactoryBean,并注入指定的mapperInterface属性。
- Spring会从MapperFactoryBean中调用getObject()方法获取bean实例。
- 在getObject()方法中,MapperFactoryBean会构建Mapper接口的代理对象并返回。
- 返回的代理对象会被注册为id为userMapper的bean,这个bean就是UserMapper接口的代理实现。
- 然后我们可以像注入普通bean那样注入UserMapper,实际获得的是一个代理对象。
所以,MapperFactoryBean起到了一个工厂bean该有的作用 - 根据某些属性生成一个bean实例。这里,它根据mapperInterface属性生成了Mapper接口的代理对象bean。
可以看出,Spring管理Mapper接口的关键步骤之一就是使用MapperFactoryBean生成代理对象。而MapperFactoryBean正是MyBatis-Spring模块提供的一个工厂bean,用于这一目的。
接下来我们开始写模拟代码,效果如下图:
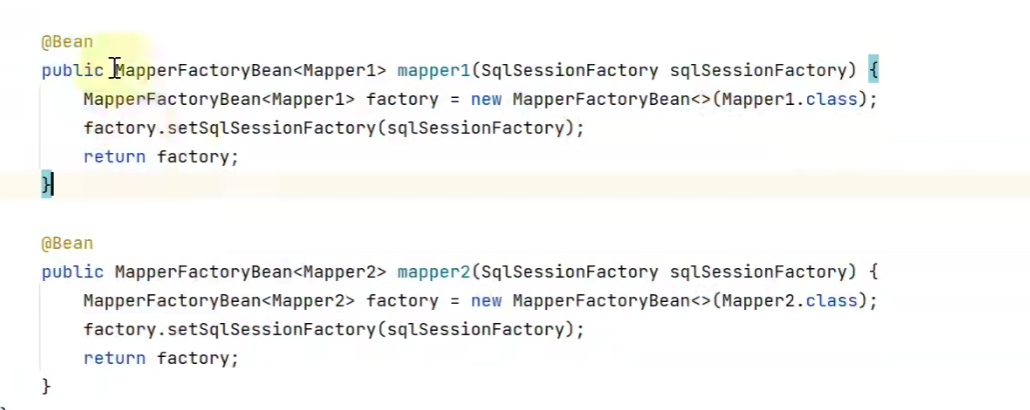
public class MapperPostProcessor implements BeanDefinitionRegistryPostProcessor {
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry beanFactory) throws BeansException {
try {
//创建一个路径匹配资源解析器
PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
//获取该路径下的所有class文件
Resource[] resources = resolver.getResources("classpath:com/zyb/a05/mapper/**/*.class");
//创建一个注解beanname生成器,方便后面bean的命名
AnnotationBeanNameGenerator generator = new AnnotationBeanNameGenerator();
//创建MetadataReader的工厂,为MetadataReader的使用做准备
CachingMetadataReaderFactory factory = new CachingMetadataReaderFactory();
for (Resource resource : resources) {
//拿到MetadataReader
MetadataReader reader = factory.getMetadataReader(resource);
//获得类的元数据
ClassMetadata classMetadata = reader.getClassMetadata();
//判断当前类是不是接口
if (classMetadata.isInterface()) {
//开始生成对应MapperFactoryBean的定义
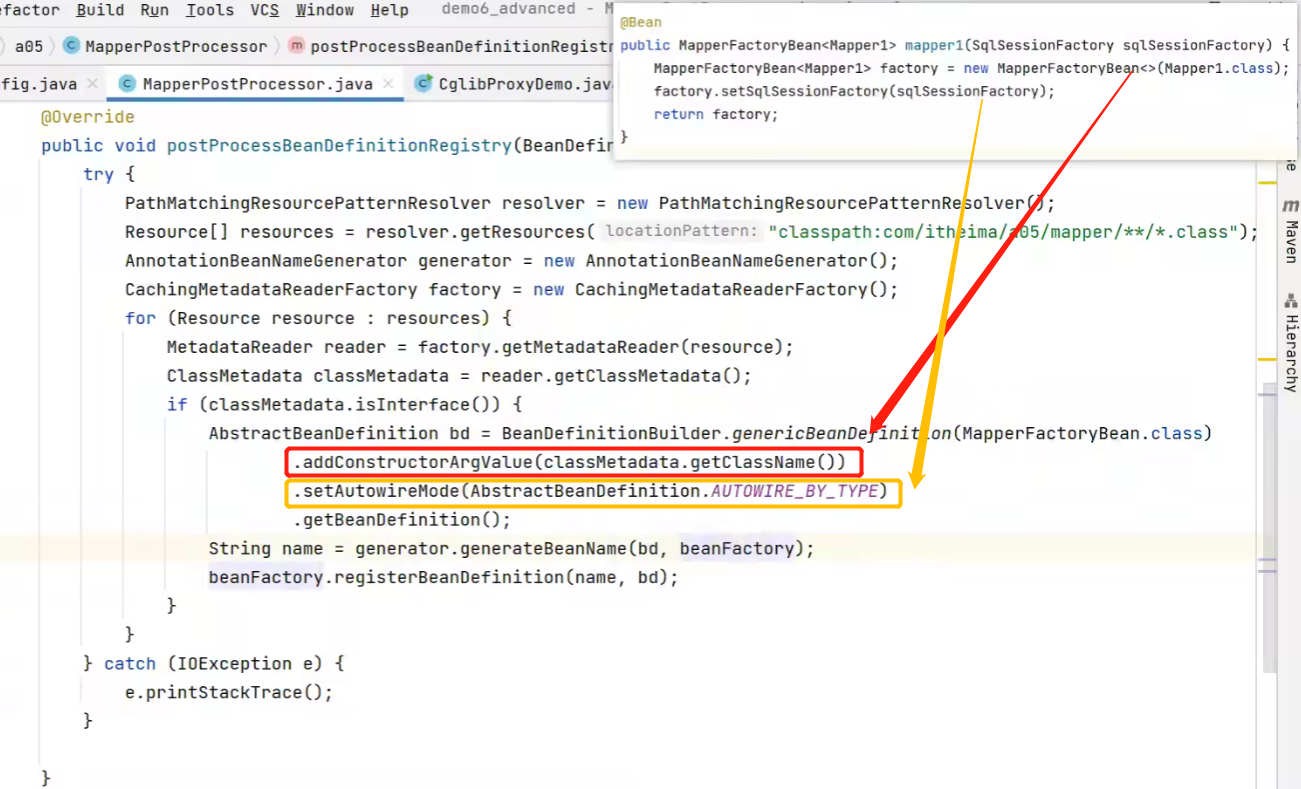
AbstractBeanDefinition bd = BeanDefinitionBuilder.genericBeanDefinition(MapperFactoryBean.class) //指定Bean的类型
.addConstructorArgValue(classMetadata.getClassName())
.setAutowireMode(AbstractBeanDefinition.AUTOWIRE_BY_TYPE)
.getBeanDefinition();
//这里的定义仅仅只是为了生成名字,所以我们后面没有向容器里进行注册
AbstractBeanDefinition bd2 = BeanDefinitionBuilder.genericBeanDefinition(classMetadata.getClassName()).getBeanDefinition();
String name = generator.generateBeanName(bd2, beanFactory);
//使用bd的定义、bd2的name进行注册
beanFactory.registerBeanDefinition(name, bd);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
}
}
有关后处理器(PostProcessor)的调用时期
BeanFactoryPostProcessor 的 postProcessBeanFactory() 方法会在以下时机被调用:
- 所有 BeanDefinition 被加载,但是还未实例化任何 bean 之前。
- 也就是说,它会在初始化容器时,修改 bean 的定义,为接下来的 bean 实例初始化做准备。
其调用时机在 Spring 容器初始化阶段,大致流程如下:
- Spring 资源加载,读取xml/注解等并解析生成 BeanDefinition。
- 调用 BeanDefinitionRegistryPostProcessor 的 postProcessBeanDefinitionRegistry() 方法。此处可以添加/移除 BeanDefinition。
- 调用 BeanFactoryPostProcessor 的 postProcessBeanFactory() 方法。此处可以修改 BeanDefinition 属性等。
- bean 实例化阶段 - 根据 BeanDefinition 创建 bean 实例。
- 调用 BeanPostProcessor 的 postProcessBeforeInitialization() 方法。
- 调用初始化回调方法如@PostConstruct 或 init-method。
- 调用 BeanPostProcessor 的 postProcessAfterInitialization() 方法。
- 整个 Spring 容器加载完成。
一定心中有一个大致的顺序,Spring容器在初始化的时候首先解析得到bean的定义,根据定义在容器中注册bean,注册bean之后开始进入Bean的生命周期:创建 --> 依赖注入 --> 初始化 --> 可用 --> 销毁
所以,BeanFactoryPostProcessor 的调用时机明确在第 3 步 - 在所有的 BeanDefinition 加载完成但在任何 bean 实例化之前。我们可以利用这个时机点对 BeanDefinition 进行批量修改。
举个简单的例子:
public class MyBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) {
for (String beanName : beanFactory.getBeanDefinitionNames()) {
BeanDefinition definition = beanFactory.getBeanDefinition(beanName);
if (definition.getScope().equals(BeanDefinition.SCOPE_PROTOTYPE)) {
definition.setScope(BeanDefinition.SCOPE_SINGLETON);
}
}
}
}
这个后置处理器会将所有 prototype 作用域的 bean 修改为 singleton 作用域。它的调用时机就在所有的 BeanDefinition 加载完成后,bean 实例化之前。所以它可以对 bean 进行批量修改。
另外,BeanDefinitionRegistryPostProcessor 的调用时机在 BeanFactoryPostProcessor 之前,它允许添加或移除 BeanDefinition。所以,如果同时实现了这两个接口,需要注意在 postProcessBeanDefinitionRegistry() 中定义的 BeanDefinition 在 postProcessBeanFactory() 中是可用的。
总结一下:
- BeanFactoryPostProcessor 在 bean 实例化之前,BeanDefinition 加载完成后被调用。
- 它可以批量修改 BeanDefinition 的属性,为后续的 bean 实例化做准备。
- 其调用时机在 Spring 容器初始化过程中的一个阶段,在 BeanDefinitionRegistryPostProcessor 之后,bean 实例化之前。
- 理解其调用时机,有助于我们更好地利用 BeanFactoryPostProcessor 定制化 bean 定义。
- 当同时实现 BeanFactoryPostProcessor 和 BeanDefinitionRegistryPostProcessor 时,需要注意二者调用顺序及其影响。
BeanFactoryPostProcessor 为我们提供了一个强大的扩展点,让我们可以在容器启动时定制修改 BeanDefinition。
Aware 接口 和 InitializingBean 接口
首先我们要知道Aware接口有什么用?
Aware接口是Spring框架中的一个接口,它可以让Bean感知到自己所处的环境,例如感知到Spring容器、应用上下文等。Spring框架提供了多个Aware接口,可以让Bean感知到不同的环境。
具体来说,当一个Bean实现了某个Aware接口时,Spring容器会自动调用该Bean对应的接口方法,并将相应的环境信息作为参数传递给该方法。通过这种方式,Bean可以获取到自己所处的环境信息,并进行相应的处理。
也就是说:实现这些Aware接口,我们就可以在bean初始化的时候获得Spring容器中的一些对象,进而对bean进行进一步的操作。一句话说Aware 接口提供了一种【内置】 的注入手段
下面是几个常用的Aware接口:
-
BeanNameAware:该接口可以让Bean感知到自己在Spring容器中的名称。 -
ApplicationContextAware:该接口可以让Bean感知到自己所处的应用上下文。 -
BeanFactoryAware:该接口可以让Bean感知到自己所处的Bean工厂。
例如,以下代码演示了一个实现了ApplicationContextAware接口的Bean:
public class MyBean implements ApplicationContextAware {
private ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
public void doSomething() {
// 使用ApplicationContext进行相应的处理
}
}
在这个例子中,MyBean实现了ApplicationContextAware接口,并重写了setApplicationContext方法。在该方法中,我们保存了传入的ApplicationContext实例,以便在后续的处理中使用。
需要注意的是,Aware接口只是一种感知机制,它并不会改变Bean的行为。因此,如果一个Bean实现了Aware接口,但没有对相应的环境信息进行处理,那么该接口就没有实际作用。
然后我们再来看看InitializingBean接口,这是个什么东东?
InitializingBean是一个接口,它有一个方法:
void afterPropertiesSet() throws Exception;
实现这个接口的bean会在容器设置完所有必要属性之后,且在初始化之前调用afterPropertiesSet()方法。
跟Aware接口一样我们可以把它理解为:
InitializingBean 接口提供了一种【内置】的初始化手段
这给我们提供了一个机会,在bean初始化之前对其进行一些自定义的初始化处理。比如,在afterPropertiesSet()方法中,我们可以:
- 检查必要的属性是否都被设置
- 对某些属性做最后的处理
- 调用初始化方法等
一个简单的例子:
public class MyBean implements InitializingBean {
private String message;
public void setMessage(String message) {
this.message = message;
}
@Override
public void afterPropertiesSet() {
System.out.println(message);
}
}
然后在Spring配置中定义这个bean:
<bean id="myBean" class="com.example.MyBean">
<property name="message" value="Init done!" />
</bean>
在Spring容器初始化这个bean时,会发生以下流程:
- 通过setter方法设置必要属性,此时message属性被设置为"Init done!"
- 调用afterPropertiesSet()方法,打印出message属性的值
- bean初始化完成
所以,afterPropertiesSet()方法就提供了一个回调,让我们在bean初始化之前加入自定义逻辑。这也是与Aware接口类似的一个目的,只不过方式上稍有不同:
- Aware接口回调发生在依赖注入之后
- 而InitializingBean回调发生在依赖注入之后,但在初始化之前。
- Aware接口和InitializingBean接口的回调时机是在Bean实例化之后,因此它们都可以获取到Bean的实例,并进行相应的操作。但是,Aware接口的回调时机在依赖注入之前,因此它无法获取到其他Bean的实例。而InitializingBean接口的回调时机在依赖注入之后,因此它可以获取到其他Bean的实例,并进行相应的初始化工作。
关于Aware 接口 和 InitializingBean 接口,我们还要说:
- 内置的注入和初始化不受扩展功能的影响,总会被执行
- 而扩展功能受某些情况影响可能会失效
- 因此 Spring 框架内部的类常用内置注入和初始化
这几句话可能不是很好理解,我们举一个例子:
有的功能用 @Autowired 就能实现啊, 为啥还要用 Aware 接口呢?
简单地说:
- @Autowired 的解析需要用到 bean 后处理器, 属于扩展功能
- 而 Aware 接口属于内置功能, 不加任何扩展, Spring 就能识别
某些情况下, 扩展功能会失效, 而内置功能不会失效
我们看一段代码:
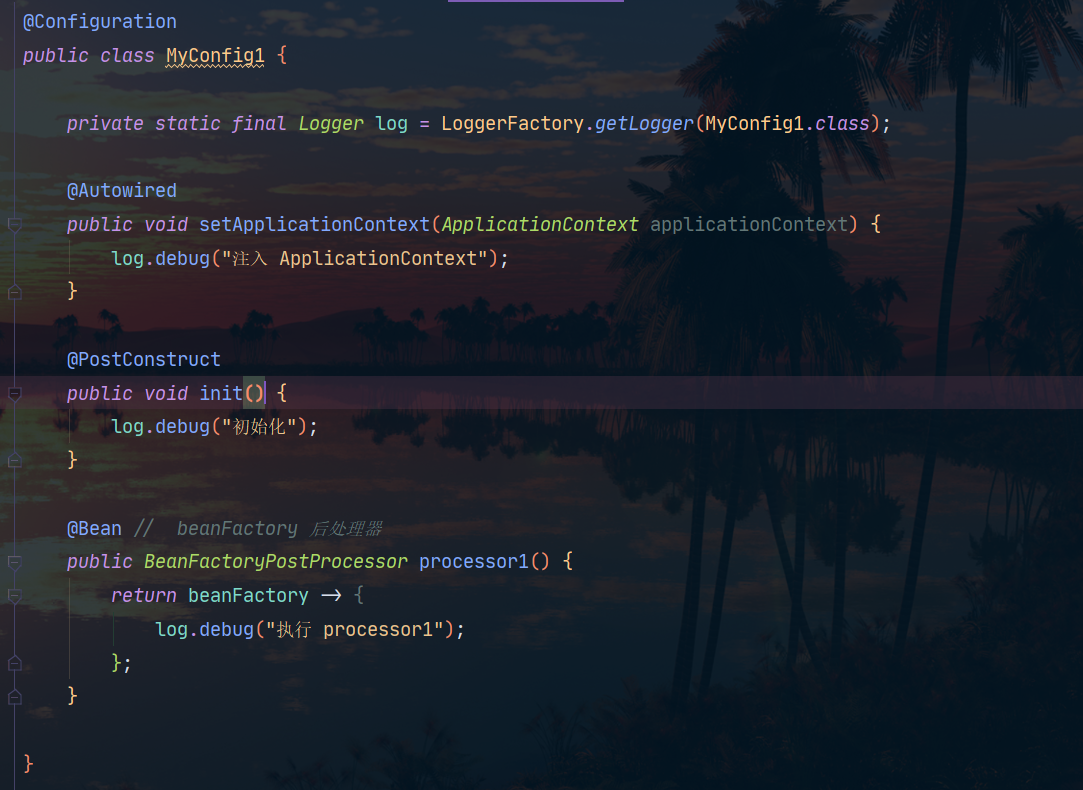
@Configuration
public class MyConfig1 {
private static final Logger log = LoggerFactory.getLogger(MyConfig1.class);
@Autowired
public void setApplicationContext(ApplicationContext applicationContext) {
log.debug("注入 ApplicationContext");
}
@PostConstruct
public void init() {
log.debug("初始化");
}
@Bean // beanFactory 后处理器
public BeanFactoryPostProcessor processor1() {
return beanFactory -> {
log.debug("执行 processor1");
};
}
}
测试类:
/*
Aware 接口及 InitializingBean 接口
*/
public class A06 {
private static final Logger log = LoggerFactory.getLogger(A06.class);
public static void main(String[] args) {
GenericApplicationContext context = new GenericApplicationContext();
context.registerBean("myConfig1", MyConfig1.class);
context.registerBean(AutowiredAnnotationBeanPostProcessor.class);
context.registerBean(CommonAnnotationBeanPostProcessor.class);
context.registerBean(ConfigurationClassPostProcessor.class);
/*
Java 配置类在添加了 bean 工厂后处理器后,
你会发现用传统接口方式的注入和初始化仍然成功, 而 @Autowired 和 @PostConstruct 的注入和初始化失败
*/
context.refresh(); // 1. beanFactory 后处理器, 2. 添加 bean 后处理器, 3. 初始化单例
context.close();
}
}
在执行了refresh()方法之后,容器中会大致依次执行以下操作:
- beanFactory 后处理器
- 添加 bean 后处理器
- 初始化单例
结果:

可以看出来@PostConstruct、@Autowired注解都失效了,这是为什么呢?
此处想要完全理解一定要弄清楚后处理器、 Aware 接口及 InitializingBean 接口的回调时机!!!
首先我们要理解配置类本身就是一个BeanFactoryPostProcessor!!!!!
首先我们要理解配置类本身就是一个BeanFactoryPostProcessor!!!!!
首先我们要理解配置类本身就是一个BeanFactoryPostProcessor!!!!!
配置类通过 @Configuration 注解标识,Spring 会将其视为 bean 定义的来源。当 Spring 解析 @Configuration 标注的类时,会使用该类定义的 @Bean 方法创建 bean 实例化注册到容器中。
也就是说,配置类其实扮演了两个角色:
- bean 定义的来源 - @Configuration 标识这一点。
- BeanFactoryPostProcessor - 它在 bean 实例化之前修改了 bean 定义,添加了由其 @Bean 方法定义的 bean。
所以,从这个意义上讲,配置类本身就具有 BeanFactoryPostProcessor 的效果。
我们可以这样理解这个过程:
- Spring 找到 @Configuration 标注的配置类
- Spring 使用 ConfigurationClassPostProcessor 解析配置类 - 这一步相当于调用 BeanFactoryPostProcessor.postProcessBeanFactory()
- 在解析配置类的过程中,Spring 找到 @Bean 方法,并使用这些方法定义的 bean 添加到容器 - 这相当于 BeanFactoryPostProcessor 中注册 bean
- bean 实例化后,可以使用 @Configuration 类中定义的 @Bean bean
所以,当我们的配置类被解析时,等同于其 BeanFactoryPostProcessor.postProcessBeanFactory() 方法被调用,其定义的 @Bean bean 被注册到容器。这也就证明了配置类具有 BeanFactoryPostProcessor 的效果。
举个示例:
@Configuration
public class AppConfig {
@Bean
public MyBean myBean() {
return new MyBean();
}
}
与下面的 BeanFactoryPostProcessor 等效:
public class MyBeanFactoryPostProcessor implements BeanFactoryPostProcessor {
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) {
beanFactory.registerSingleton("myBean", new MyBean());
}
}
可以看出,AppConfig 中的 @Bean 方法与 MyBeanFactoryPostProcessor.postProcessBeanFactory() 中的注册逻辑作用相同。
所以,当我们需要利用 @Bean 方法自定义 bean 的定义时,我们其实就已经使用了配置类 BeanFactoryPostProcessor 的能力。配置类 + @Bean 就具备了后置处理 bean 定义的效果。
总结来说,配置类之所以具有 BeanFactoryPostProcessor 的效果,是因为:
- @Configuration 标识它是 bean 定义的来源
- 它使用 @Bean 方法在 bean 实例化前注册 bean,相当于 BeanFactoryPostProcessor#postProcessBeanFactory()
- Spring 在解析配置类时,相当于调用了 BeanFactoryPostProcessor#postProcessBeanFactory() 方法
- 所以,通过配置类自定义 bean 定义,我们已经使用了 BeanFactoryPostProcessor 的能力
- 配置类 + @Bean == BeanFactoryPostProcessor
了解之后我们再分析这一段代码:
在这个配置类中,因为定义了一个BeanFactoryPostProcessor,它会在Spring容器加载BeanDefinition之后、实例化Bean之前执行。而@Autowired和@PostConstruct注解是用来对Bean进行依赖注入和初始化的,它们需要在Bean实例化之后才能执行。所以,当BeanFactoryPostProcessor执行时,Bean还没有实例化,因此@Autowired和@PostConstruct注解会失效。
具体来说,当Spring容器启动时,会按照以下顺序执行:
- 加载BeanDefinition
- 执行BeanFactoryPostProcessor
- 实例化Bean
- 执行Autowired和@PostConstruct注解
在这个配置类中,BeanFactoryPostProcessor会在第2步执行,而@Autowired和@PostConstruct注解会在第4步执行。因此,当BeanFactoryPostProcessor执行时,Bean还没有实例化,所以@Autowired和@PostConstruct注解会失效。
如果需要在BeanFactoryPostProcessor中使用@Autowired和@PostConstruct注解,可以考虑使用ApplicationContextAware接口和InitializingBean接口来实现依赖注入和初始化。具体来说,可以实现ApplicationContextAware接口来获取ApplicationContext实例,然后使用该实例来进行依赖注入;同时,可以实现InitializingBean接口来实现Bean的初始化逻辑。
例如:
@Configuration
public class MyConfig1 implements ApplicationContextAware, InitializingBean {
private static final Logger log = LoggerFactory.getLogger(MyConfig1.class);
private ApplicationContext applicationContext;
@Override
public void setApplicationContext(ApplicationContext applicationContext) {
this.applicationContext = applicationContext;
log.debug("注入 ApplicationContext");
}
@Override
public void afterPropertiesSet() {
log.debug("初始化");
}
@Bean
public BeanFactoryPostProcessor processor1() {
return beanFactory -> {
log.debug("执行 processor1");
};
}
}
在这个例子中,实现了ApplicationContextAware接口和InitializingBean接口,分别用于依赖注入和初始化。这样,在BeanFactoryPostProcessor执行时,可以通过ApplicationContext实例来进行依赖注入;同时,在Bean实例化后,可以通过InitializingBean接口的实现方法来进行初始化。
初始化和销毁
Spring 提供了多种初始化手段,除了@PostConstruct,@Bean(initMethod) 之外,还可以实现 InitializingBean 接口来进行初始化,如果同一个 bean 用了以上手段声明了 3 个初始化方法,那么它们的执行顺序是
- @PostConstruct 标注的初始化方法
- InitializingBean 接口的初始化方法
- @Bean(initMethod) 指定的初始化方法
与初始化类似,Spring 也提供了多种销毁手段,执行顺序为
- @PreDestroy 标注的销毁方法
- DisposableBean 接口的销毁方法
- @Bean(destroyMethod) 指定的销毁方法
示例代码:
@SpringBootApplication
public class A07_1 {
public static void main(String[] args) {
ConfigurableApplicationContext context = SpringApplication.run(A07_1.class, args);
context.close();
}
@Bean(initMethod = "init3")
public Bean1 bean1() {
return new Bean1();
}
@Bean(destroyMethod = "destroy3")
public Bean2 bean2() {
return new Bean2();
}
}
public class Bean1 implements InitializingBean {
private static final Logger log = LoggerFactory.getLogger(Bean1.class);
@PostConstruct
public void init1() {
log.debug("初始化1");
}
@Override
public void afterPropertiesSet() throws Exception {
log.debug("初始化2");
}
public void init3() {
log.debug("初始化3");
}
}
public class Bean2 implements DisposableBean {
private static final Logger log = LoggerFactory.getLogger(Bean2.class);
@PreDestroy
public void destroy1() {
log.debug("销毁1");
}
@Override
public void destroy() throws Exception {
log.debug("销毁2");
}
public void destroy3() {
log.debug("销毁3");
}
}
Scope
在当前版本的 Spring 和 Spring Boot 程序中,支持五种 Scope
- singleton,容器启动时创建(未设置延迟),容器关闭时销毁(单例与容器同生共死)
- prototype,每次使用时创建,不会自动销毁,需要调用 DefaultListableBeanFactory.destroyBean(bean) 销毁(也就是说多例的销毁不归容器管理)
- request,每次请求用到此 bean 时创建,请求结束时销毁
- session,每个会话用到此 bean 时创建,会话结束时销毁
- application,web 容器用到此 bean 时创建,容器停止时销毁
有些文章提到有 globalSession 这一 Scope,也是陈旧的说法,目前 Spring 中已废弃
但要注意,如果在 singleton 注入其它 scope 都会有问题,解决方法有
- @Lazy
- @Scope(proxyMode = ScopedProxyMode.TARGET_CLASS)
- ObjectFactory
- ApplicationContext.getBean
解决方法虽然不同,但理念上殊途同归: 都是推迟其它 scope bean 的获取
我们举一个例子:
以单例注入多例为例
有一个单例对象 E
@Component
public class E {
private static final Logger log = LoggerFactory.getLogger(E.class);
private F f;
public E() {
log.info("E()");
}
@Autowired
public void setF(F f) {
this.f = f;
log.info("setF(F f) {}", f.getClass());
}
public F getF() {
return f;
}
}
要注入的对象 F 期望是多例
@Component
@Scope("prototype")
public class F {
private static final Logger log = LoggerFactory.getLogger(F.class);
public F() {
log.info("F()");
}
}
测试
E e = context.getBean(E.class);
F f1 = e.getF();
F f2 = e.getF();
System.out.println(f1);
System.out.println(f2);
输出
com.zyb.demo.cycle.F@6622fc65
com.zyb.demo.cycle.F@6622fc65
发现它们是同一个对象,而不是期望的多例对象
对于单例对象来讲,依赖注入仅发生了一次,后续再没有用到多例的 F,因此 E 用的始终是第一次依赖注入的 F
解决
- 仍然使用 @Lazy 生成代理
- 代理对象虽然还是同一个,但当每次使用代理对象的任意方法时,由代理创建新的 f 对象
@Component
public class E {
@Autowired
@Lazy
public void setF(F f) {
this.f = f;
log.info("setF(F f) {}", f.getClass());
}
// ...
}
注意
- @Lazy 加在也可以加在成员变量上,但加在 set 方法上的目的是可以观察输出,加在成员变量上就不行了
- @Autowired 加在 set 方法的目的类似
输出
E: setF(F f) class com.zyb.demo.cycle.F$$EnhancerBySpringCGLIB$$8b54f2bc
F: F()
com.zyb.demo.cycle.F@3a6f2de3
F: F()
com.zyb.demo.cycle.F@56303b57
从输出日志可以看到调用 setF 方法时,f 对象的类型是代理类型
![[java]关于会话Session](https://img-blog.csdnimg.cn/7473bf535abf4a39ae175154f049b46a.png)