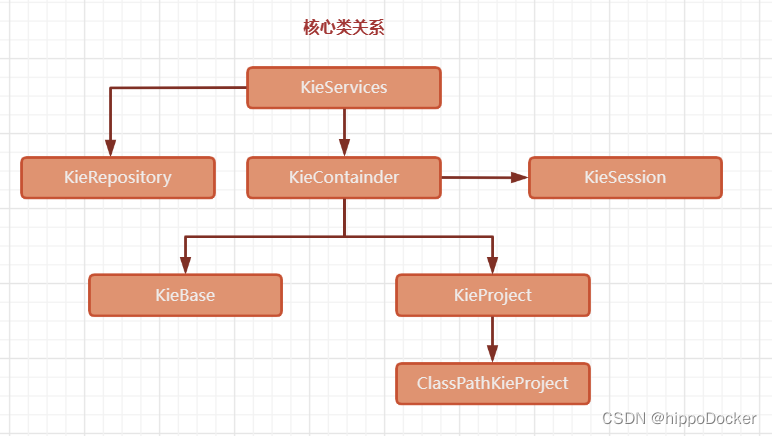
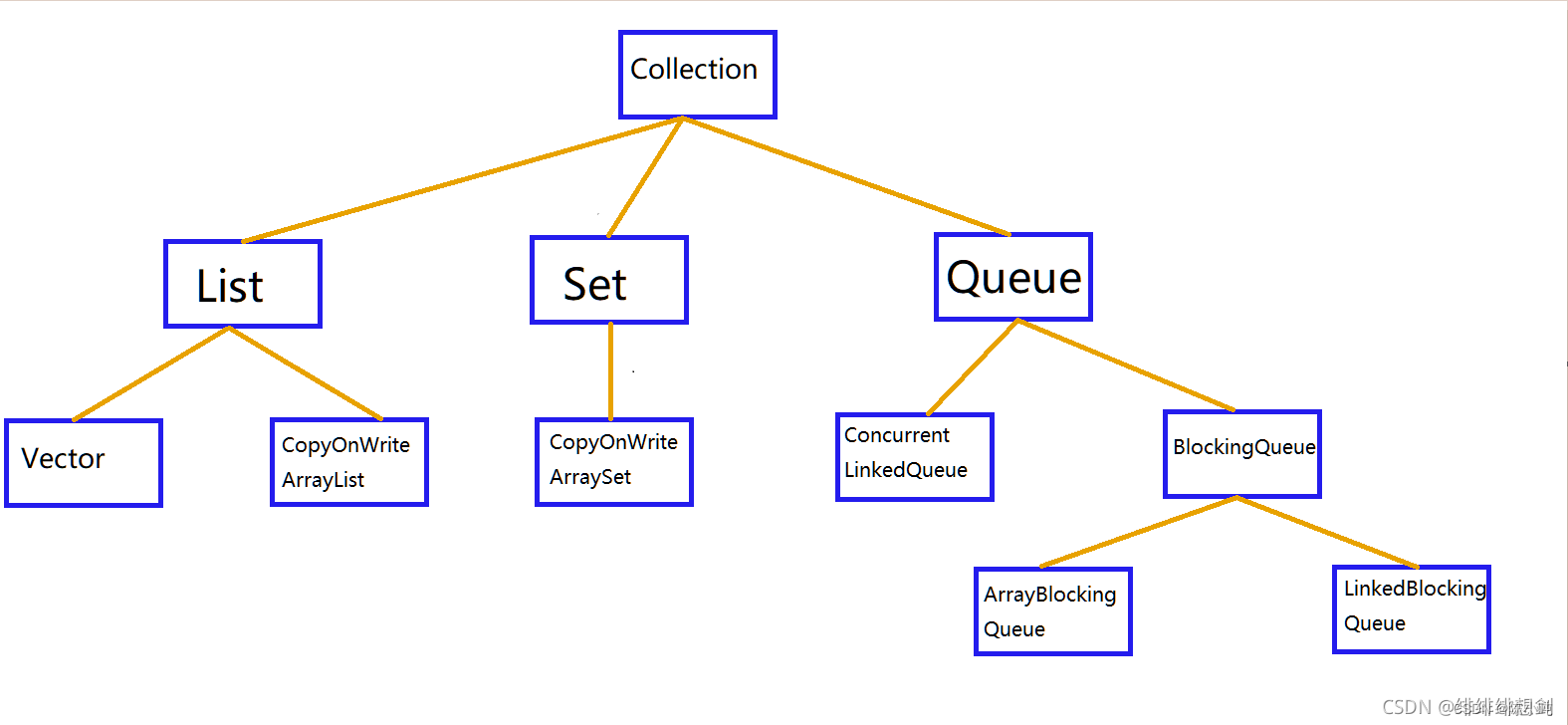
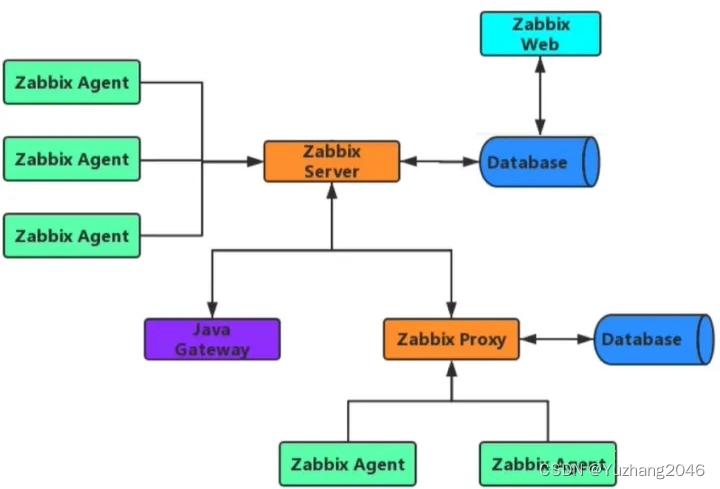
背景
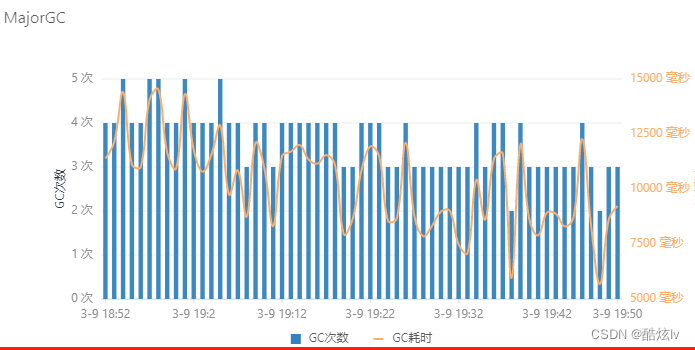
线上服务GC耗时过长,普遍10s+,此外GC后,内存回收不多
问题一
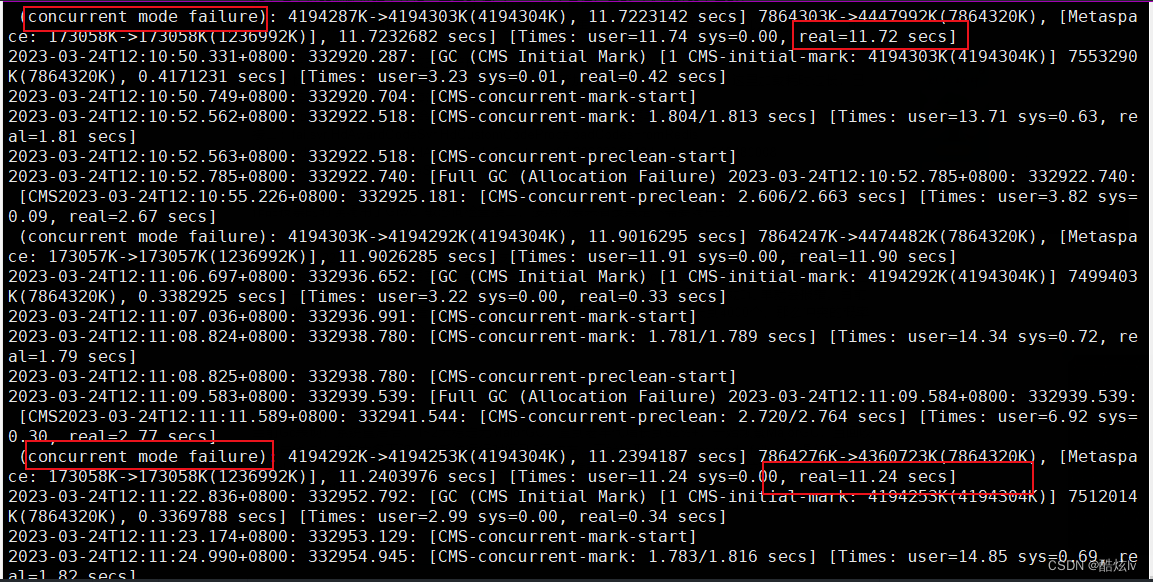
通过查询gc日志可以发现,CMS进行垃圾回收的时候报concurrent mode failure错误,该错误是因为CMS进行垃圾回收的时候,新生代进行GC产生的对象晋升到老年代时,老年代空间无法满足需求,从而导致该异常
影响:当出现该异常时,CMS垃圾回收机制会退化成Serial Old,也就是说原本并行多线程进行垃圾回收退化成单线程回收,此时垃圾回收停顿时间就会变长,则就是为毛GC耗时长的原因
解决方案:
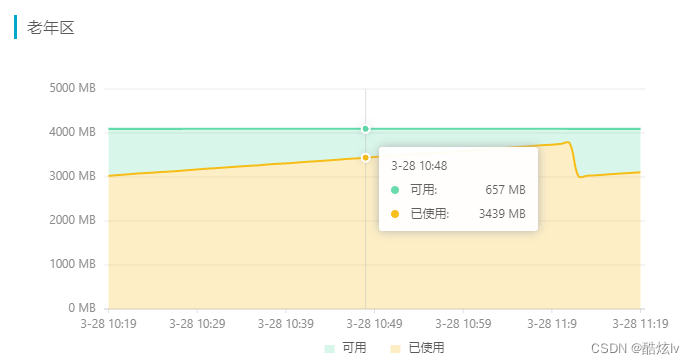
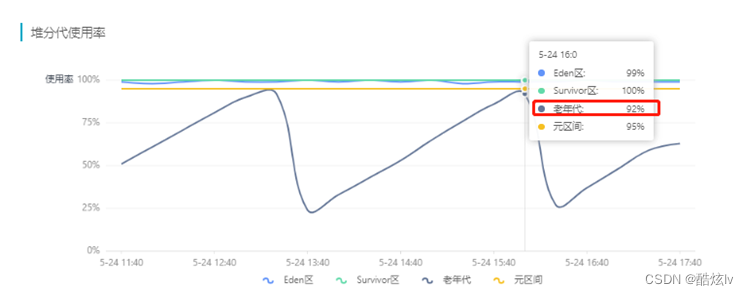
首先我们需要了解CMS进行Full GC触发的时机是什么?从监控看当老年代达到92%时,则会触发GC,该值在jdk1.8后默认是92%(其实是可以计算出来的),可以通过-XX:+UseCMSInitiatingOccupancyOnly进行设置大小
问题二
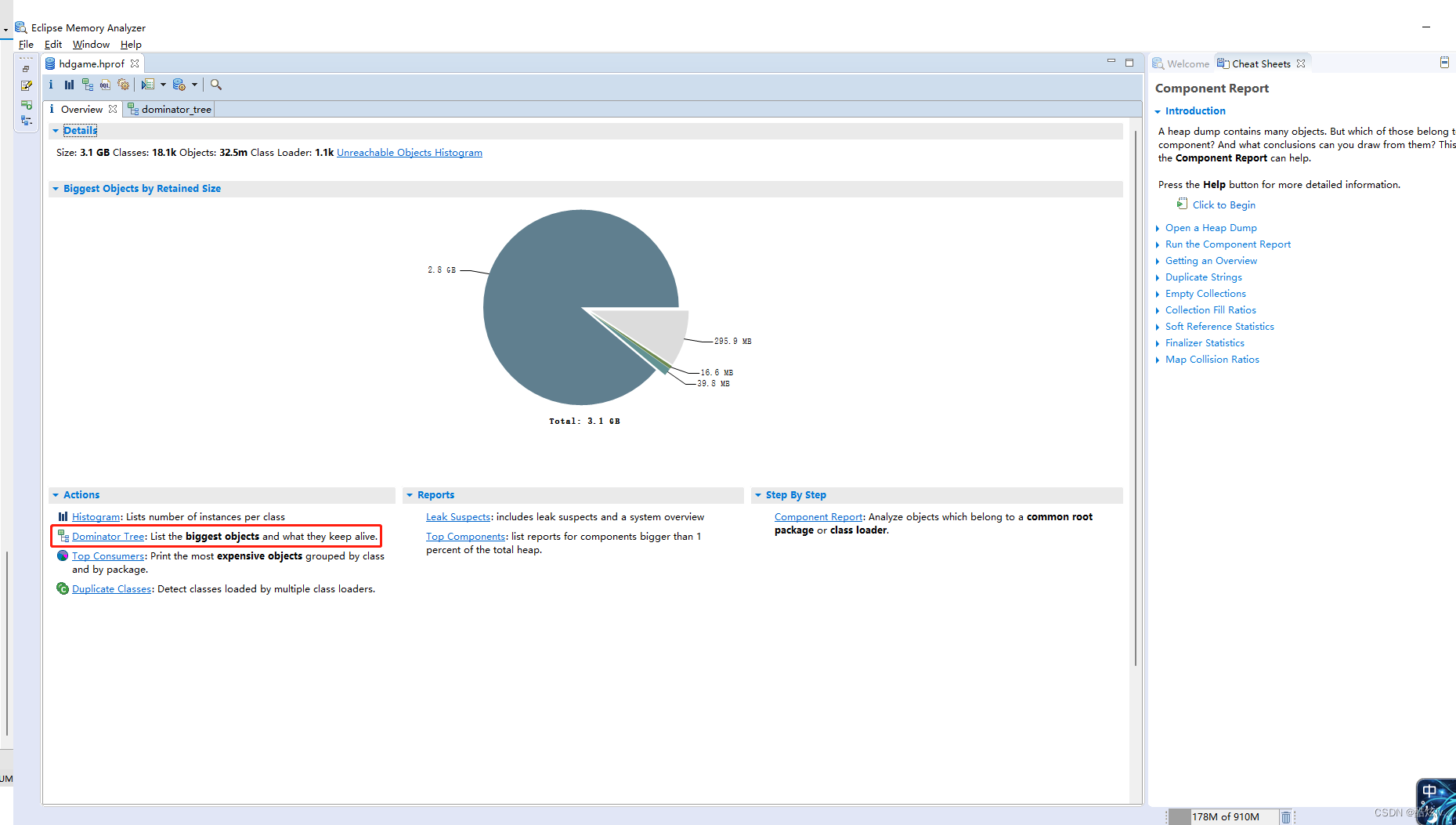
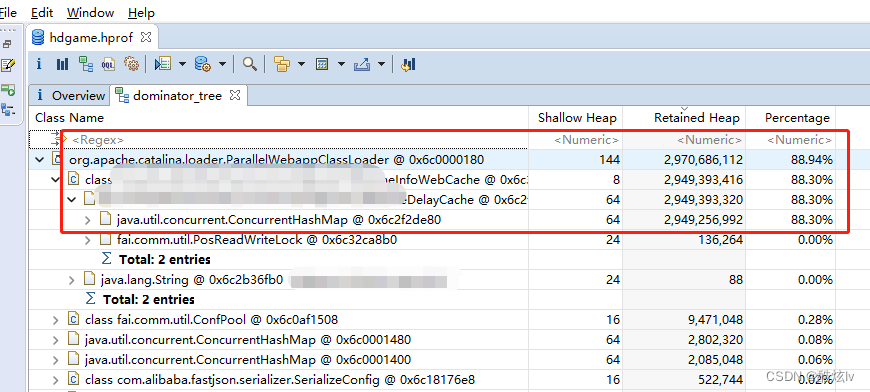
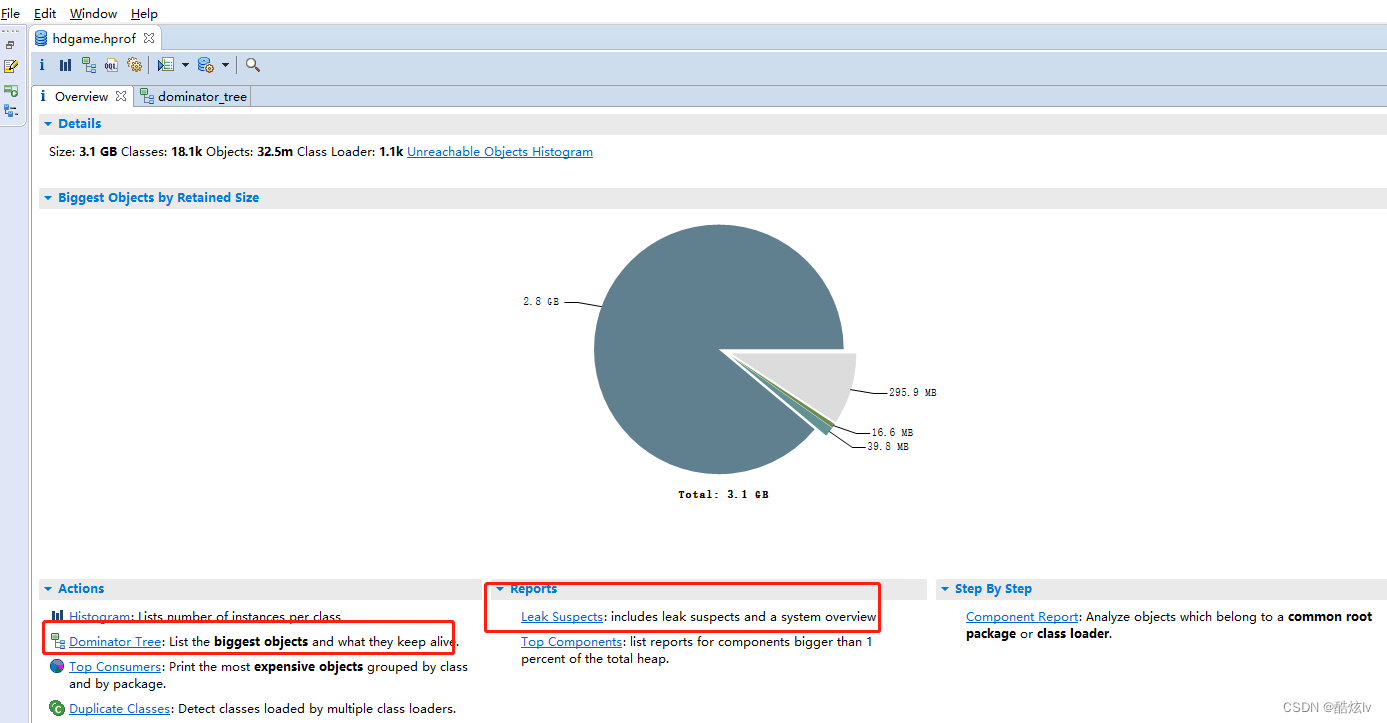
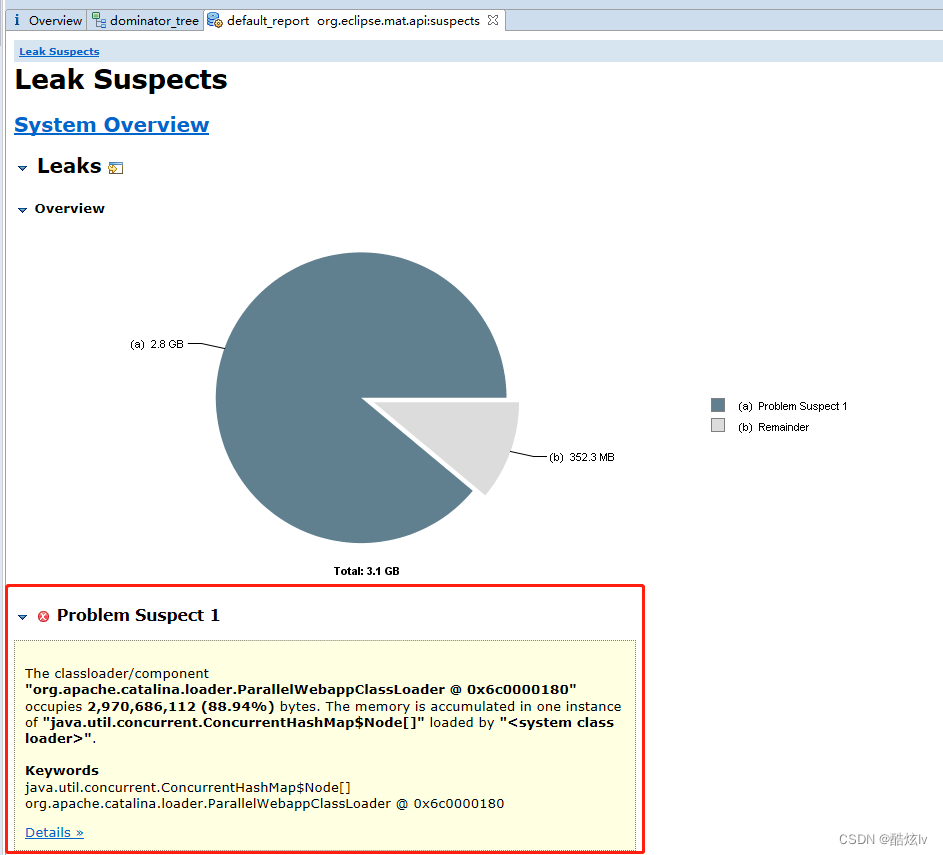
为什么GC后,老年代回收内存这么少?通过arthas dump下线上日志,利用Eclipse Meory Analyzer 进行分析,可以很直观看到是线上存活的WebCache中的ConcurrentHashMap对象占用过多,再根据代码进行分析即可找到问题所在
总结
从以上分析可以了解到,其实是因为内存溢出导致老年代回收不及时,新生代晋升到老年代时空间不足,从而触发了CMS退化成Serial Old,导致GC耗时过长,从而拖垮整个系统性能。从中一个是需要处理内存溢出问题,第二个是可以通过-XX:+UseCMSInitiatingOccupancyOnly参数对GC触发的时机进行调节即可
其他
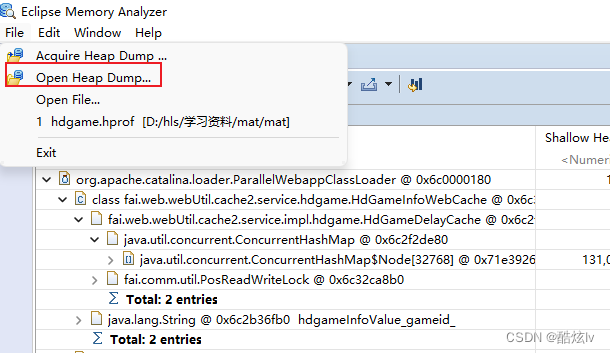
1.通过arthas 导出dump文件,可以使用命令 heapdump --live /tmp/dump.hprof
2.使用Eclipse Meory Analyzer 导入dump文件进行分析,可以使用Dominator Tree 或者Leak Suspects功能进行分析都是很强大的。
参考:
了解CMS GC触发时机:CMS的CMSInitiatingOccupancyFraction解析_insomsia的博客-CSDN博客

![[PyTorch][chapter 37][经典卷积神经网络-2 ]](https://img-blog.csdnimg.cn/2bae29152c4343d88a2b594a6b074798.png)



![[原创]集权设施保护之LDAP协议](https://img-blog.csdnimg.cn/img_convert/c89684aa348c07154a7dec27722a3c33.png)