目录
一、索引机制的引入
1.索引机制🐂B在哪里?
2.索引机制提高查询速度的原理 :
二、索引的创建
1.索引分类 :
2.使用格式 :
3.代码演示 :
三、索引的删除
1.格式 :
2.演示 :
四、索引的查询
1.格式 :
2.演示 :
五、索引的使用规则
一、索引机制的引入
1.索引机制🐂B在哪里?
我们先来创建一张学生表,向表中随意添加一些数据后,利用蠕虫复制(自我复制)将表中的数据量扩展到百万级别,代码如下 :
CREATE TABLE IF NOT EXISTS `students`(
`s_id` MEDIUMINT UNSIGNED NOT NULL,
`s_name` VARCHAR(64) NOT NULL DEFAULT '',
`s_age` SMALLINT UNSIGNED NOT NULL DEFAULT 0
) CHARACTER SET utf8mb3 COLLATE utf8mb3_bin ENGINE INNODB;
INSERT INTO students
VALUES
(1, 'sdads', 22),
(1, 'Cyan', 22),
(3, 'Raln', 22),
(1, 'sdads', 22),
(122, 'sdads', 22),
(9, 'sdads', 22),
(1, 'NXOl', 22),
(34, 'DANz', 22),
(76, 'AMqwc', 22);
INSERT INTO students
SELECT * FROM students;经过几轮蠕虫复制后,我们可以利用COUNT函数来查询表中现在一共有多少条记录,如下 :
SELECT COUNT(*) FROM students;
可以看到,表中现在已经有900多万条数据了,这么大的数据量,在查询数据时需要消耗多长的时间捏🤔 。我们来测试一下 :
先向表中另外添加一条要查询的数据(避开蠕虫复制的id),然后进行查询,如下 :
INSERT INTO students
VALUES
(233, 'Ice', 21);
SELECT *
FROM students
WHERE s_id = 233;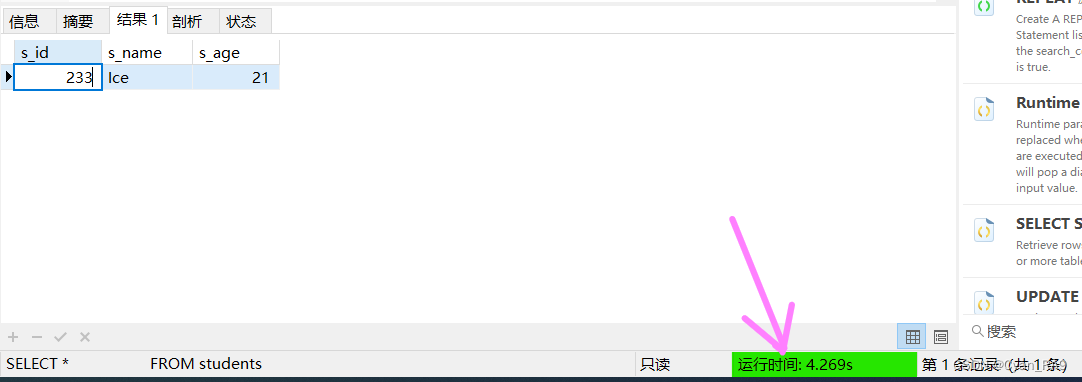
在无索引机制的情况下,通过id查询数据用了足足4s多,你可以想象下面的场景——月黑风高夜,夜深人静时,你正想趁着此般时机在某网站上大饱眼福,就比如说在CSDN上吧,你想要让无穷无尽的知识映入你的眼帘,但是你发现,你每用鼠标点击一次都得等待4s多才能给你反馈,反复多次以后,你想骂娘了,***流量都准备好了给我整这玩意儿?
没错,如果没有索引机制的加持,当数据量足够大时,比如达到百万级别以上,浏览网站将会是非常痛苦的一件事。那这时候可能就要有p小将(Personable小将,指风度翩翩的人)出来bb问了——你™BB一大堆说了个啥?索引机制呢?这踏🐎不是跑题水博文?
p哥教训的是😭。这就来演示一下——如果我们用了索引机制,在相同的查询条件下,会用多长的时间。但是,演示之前我们先来看一下,目前900多万条的数据占了多大的空间,如下 : (ibd后缀,表示文件为INNODB存储引擎下保存的表数据和索引的文件)。
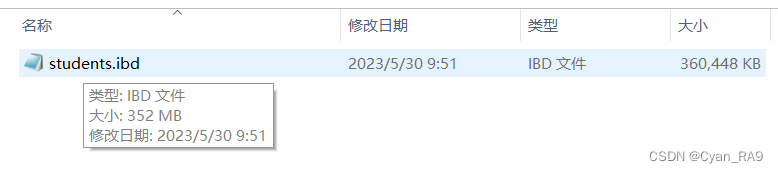
为s_id字段创建索引(创建索引也需要时间),并进行相同的查询,如下 :
CREATE INDEX id_index ON students(s_id);SELECT *
FROM students
WHERE s_id = 233;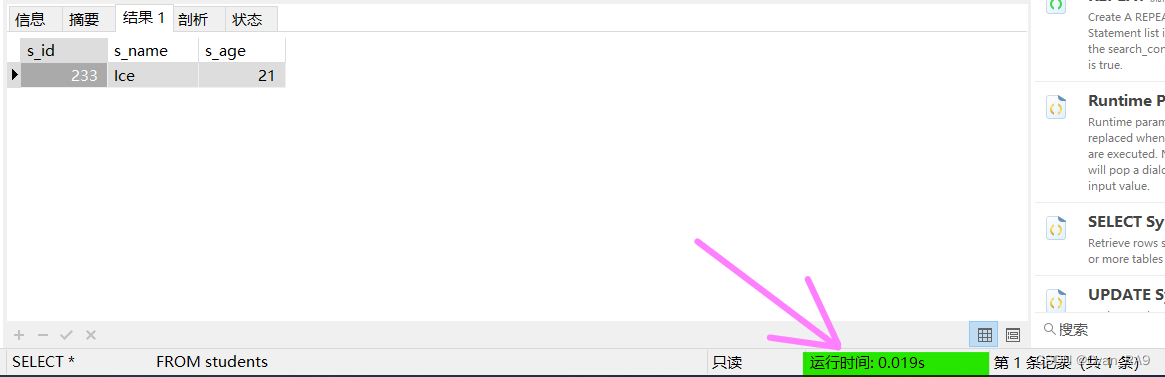
发现没有,相同的查询语句,添加索引前后的时间之比 = 4.269 / 0.019 ≈ 225,上百倍的性能差距。那么,我们再来看一下建立索引机制后,该表的数据发生了什么变化? 如下 :
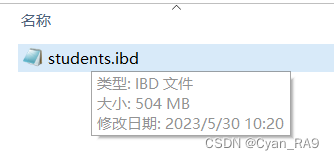
可以发现,索引机制的本质,其实就是——以空间换时间,即索引本身的建立也是需要占用空间的。
2.索引机制提高查询速度的原理 :
以往常规的查询中,不管你查询什么数据,它都是从表头第一条记录开始查找,一直找到表的末尾,即扫描了全表。比方说你要查询一条id = 100的记录,就算在表中找到了一条id = 100的记录,但是仍然不能保证该记录下方的记录中没有id = 100的,因此,就算表中真的只有一条id = 100的记录,最终还是扫描了全表。
那么在表数据量庞大的情况下,全表扫描带来的弊端是相当明显的,我们方才也看到了,查询一次都得4s以上,甲方不得喷死你?
那么索引机制又是如何解决这个问题的呢?
索引机制会根据定义索引的字段建立一个索引的数据结构,这个数据结构可能是二叉树,B+树等等。比方说,我们上文中对s_id字段建立了索引,那么以最简单的二叉树为例,如下图所示 :
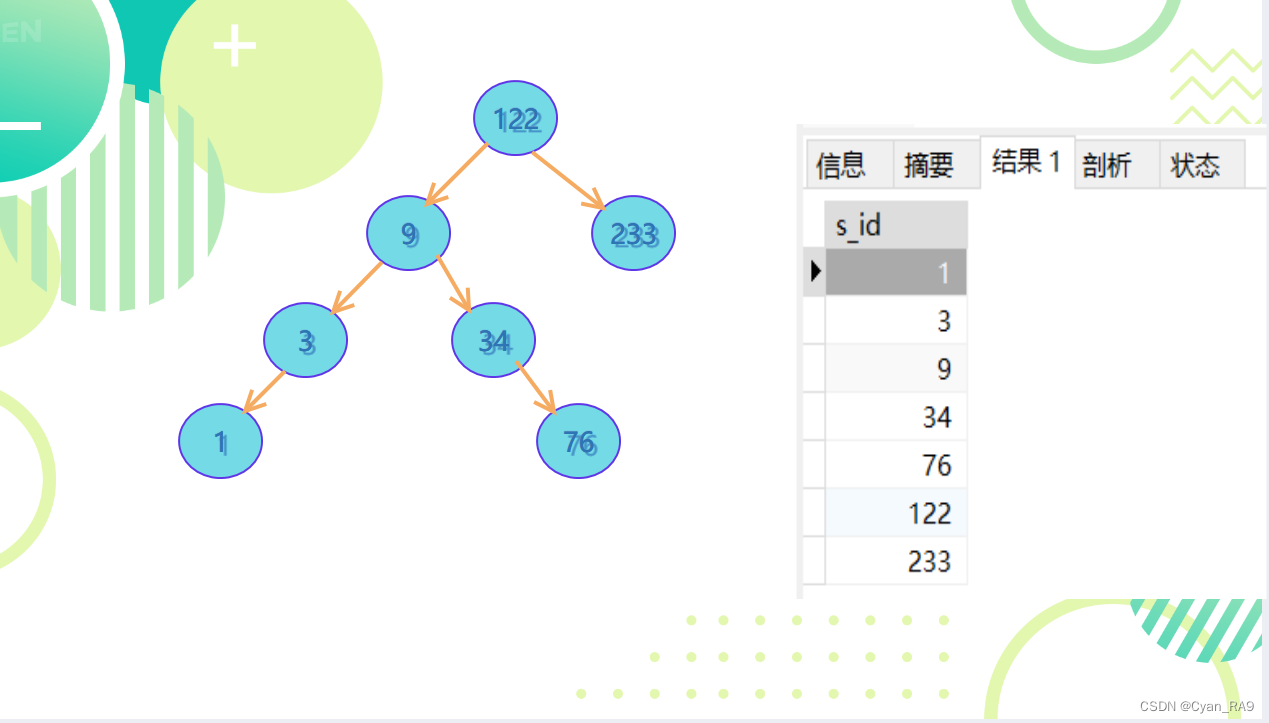
采用“折半”的思想,取中位数为根结点,左子树的结点一定都比根结点小,右子树的结点一定都比根结点大。 那么,当我们要查询id = 233的学生时,只需要先和122判断,233比122大,直接就去122的右子树查询了,122的左子树一个都不需要比较,就大大减少了查询的次数,进而缩短了查询时间,提高了查询性能。
但是,俗话说的好——甘瓜苦蒂,天下物无全美!
索引机制也存在自己的缺点——
①首先最直观的一点,由于索引采用了“以空间换时间”的思想,所以建立索引一定会增大对空间的开销;
②其次,对于所引建立的数据结构,若表中数据出现了诸如"增加,删除,更改"这些DML(Data Manipulation Language) 时,就需要对这个数据结构进行维护,影响了DML的执行效率。
实际上,两害取其轻,由于在日常的项目开发和维护中,DQL(Data Query Language) 的使用频率远远高过DML,两者的使用频率之比接近9 : 1;因此,我们往往还是乐于去建立索引,以极大提高查询语句的性能,毕竟21世纪,时间才是最珍贵嘛😋。
二、索引的创建
1.索引分类 :
1° 主键索引:当表中定义了主键(PRIMARY KEY)时,主键自动为主索引,可以说,主键是一个特殊的索引,有主键限制的查询语句,查询速度会很快。
2° 唯一索引:当表中定义了UNIQUE约束时,自动建立唯一索引(也可以手动创建),有UNIQUE限制的查询语句,查询速度也很快。
3° 普通索引:就是INDEX;虽然普通,但使用频率却是最高的,因为更加灵活;普通索引允许数据重复,比如说name字段。
4° 全文索引:FULLTEXT;适用于MyISAM存储引擎。PS :由于MySQL自带的全文索引比较LOW,没法用,因此实际开发中使用最多的是Solr和ElasticSearch(ES)。
2.使用格式 :
1° 创建唯一索引 :
CREATE UNIQUE INDEX index_name ON table_name(field_name);
2° 创建普通索引 :
CREATE INDEX index_name ON table_name(field_name);
ALTER TABLE table_name ADD INDEX index_name(field_name);
3° 创建主键索引 :
ALTER TABLE table_name ADD PRIMARY KEY (field_name);
3.代码演示 :
建立一张动物表animals,令动物编号a_no为主键,动物名字a_name为UNIQUE,使用"SHOW INDEXES FROM table_name"指令来查看动物表的索引情况,代码如下 :
CREATE TABLE IF NOT EXISTS `animals`(
`a_no` MEDIUMINT UNSIGNED PRIMARY KEY,
`a_name` VARCHAR(64) UNIQUE NOT NULL,
`a_habitat` VARCHAR(64) NOT NULL DEFAULT ''
) CHARACTER SET utf8mb3 COLLATE utf8mb3_bin ENGINE INNODB;
SHOW INDEXES FROM animals;
可以看到,Non_unique均是0,表示主键索引和唯一索引均不允许数据重复;Column_name则表示当前索引添加在了哪个字段上。
尝试通过手动添加的方式建立唯一索引,如下 :
CREATE UNIQUE INDEX a_nameIndex ON animals(a_name);
CREATE UNIQUE INDEX a_nameIndex2 ON animals(a_name);
SHOW INDEXES FROM animals;
可见,MySQL允许在同一字段上创建名称不同的多个索引;当然,主键索引除外,每张表最多只允许存在一个主键。
下面我们另建一张表,演示一下手动创建主键,以及普通索引的创建,代码如下 :
CREATE TABLE IF NOT EXISTS `animals_EX`(
`no` MEDIUMINT UNSIGNED,
`name` VARCHAR(64) UNIQUE NOT NULL,
`habitat` VARCHAR(64) NOT NULL DEFAULT ''
) CHARACTER SET utf8mb3 COLLATE utf8mb3_bin ENGINE INNODB;
# 手动添加主键
ALTER TABLE `animals_EX` ADD PRIMARY KEY(`no`);
# 手动添加普通索引
ALTER TABLE `animals_EX` ADD INDEX index_nameTest(`name`);
CREATE INDEX `index_nameTest2` ON animals_EX(`name`);
CREATE INDEX `index_habitatTest` ON animals_EX(habitat);
# 查看表的索引信息
SHOW INDEXES FROM animals_EX;
可以看到,普通索引的Non_unique栏下是1,也就是允许有重复数据。
三、索引的删除
1.格式 :
1° 删除非主键索引 :
DROP INDEX index_name ON table_name;
2° 删除主键索引 :
ALTER TABLE table_name DROP PRIMARY KEY;
PS :
若想修改索引——①删除当前索引;②添加新的索引。
2.演示 :
对于上文创建的animals_EX表的索引,如下图所示 :

要求删除该表的所有索引,如下 :
# 删除主键索引
ALTER TABLE `animals_EX` DROP PRIMARY KEY;
# 删除非主键索引
DROP INDEX `name` ON `animals_EX`;
DROP INDEX index_nameTest ON animals_EX;
DROP INDEX index_nameTest2 ON animals_EX;
DROP INDEX index_habitatTest ON animals_EX;
SHOW INDEXES FROM animals_EX;
四、索引的查询
1.格式 :
1° SHOW INDEX FROM table_name;
2° SHOW INDEXES FROM table_name;
3° SHOW KEYS FROM table_name;
4° DESC table_name; (不如前三种方式的信息详细)
2.演示 :
以动物表animals为例,查询其索引的定义情况。
注意,前三种方式得到的结果是一模一样的。
SHOW INDEX FROM animals;
SHOW INDEXES FROM animals;
SHOW KEYS FROM animals;
第四种方式DESC table_name,本质上就是查看表的结构,不过也可以看出一些关于索引的信息。如下 :
DESC animals;
五、索引的使用规则
1° 较频繁的作为查询条件的字段应该建立索引
eg : SELECT * FROM emp WHERE eno = 100; (雇员编号)
2° 对于唯一性太差的字段,即使频繁作为查询条件也不适合单独建立索引
eg : SELECT * FROM emp WHERE esex = 'male'; (性别往往非男即女,存在大量重复数据)
3° 更新较为频繁的字段不适合建立索引
eg : SELECT * FROM emp WHERE attendance_times; (若字段频繁更新,就需要对该字段索引的数据结构进行频繁的维护,会消耗较多性能,维护代价高)。
4° 不会出现在WHERE子句中的字段不适合创建索引。(用不上)
System.out.println("END------------------------------------------------------------------------------");