Bert模型的基本原理是什么?
BERT 来自 Google 的论文Pre-training of Deep Bidirectional Transformers for Language Understanding,BERT 是“Bidirectional Encoder Representations from Transformers”的首字母缩写,整体是一个自编码语言模型(Autoencoder LM),并且其设计了两个任务来预训练该模型。
-
第一个任务是采用$ MaskLM$ 的方式来训练语言模型,通俗地说就是在输入一句话的时候,随机地选一些要预测的词,然后用一个特殊的符号[MASK]来代替它们,之后让模型根据所给的标签去学习这些地方该填的词。
-
第二个任务在双向语言模型的基础上额外增加了一个句子级别的连续性预测任务,即预测输入 BERT 的两段文本是否为连续的文本,引入这个任务可以更好地让模型学到连续的文本片段之间的关系。
-
(模型学习到连续的文本片段之间的关系)
BERT 来自 Google 的论文Pre-training of Deep Bidirectional Transformers for Language Understanding,BERT 是“Bidirectional Encoder Representations from Transformers”的首字母缩写,整体是一个自编码语言模型(Autoencoder LM),并且其设计了两个任务来预训练该模型。 -
第一个任务是采用 MaskLM 的方式来训练语言模型,通俗地说就是在输入一句话的时候,随机地选一些要预测的词,然后用一个特殊的符号[MASK]来代替它们,之后让模型根据所给的标签去学习这些地方该填的词。
-
第二个任务在双向语言模型的基础上额外增加了一个句子级别的连续性预测任务,即预测输入 BERT 的两段文本是否为连续的文本,引入这个任务可以更好地让模型学到连续的文本片段之间的关系。
最后的实验表明BERT模型的有效性,并在11项中NLP任务中夺得SOTA结果。
BERT 相较于原来的 RNN、LSTM 可以做到并发执行,同时提取词在句子中的关系特征,并且能在多个不同层次提取关系特征,进而更全面反映句子语义。相较于 word2vec,其又能根据句子上下文获取词义,从而避免歧义出现。同时缺点也是显而易见的,模型参数太多,而且模型太大,少量数据训练时,容易过拟合。
(提取在句子中的关系特征)
Bert 怎么用transformer?
BERT 只使用了 Transformer 的 Encoder 模块,原论文中,作者分别用 12 层和 24 层 Transformer Encoder 组装了两套 BERT 模型,分别是:
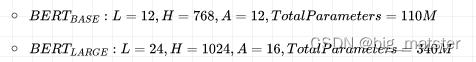
其中层的数量(即,Transformer Encoder 块的数量)为L ,隐藏层的维度为H ,自注意头的个数为A 。在所有例子中,我们将前馈/过滤器(Transformer Encoder 端的 feed-forward 层)的维度设置为4H ,即当 H=768 时是3072 ;当 H=1024 是 4096 。
图示如下:
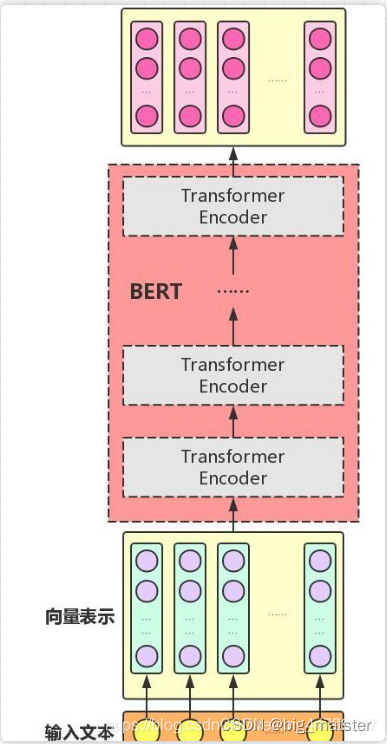
「需要注意的是,与 Transformer 本身的 Encoder 端相比,BERT 的 Transformer Encoder 端输入的向量表示,多了 Segment Embeddings。」
Bert训练过程是怎么样?
在论文原文中,作者提出了两个预训练任务****:Masked LM 和 Next Sentence Prediction。
Masked LM
任务描述为:给定一句话,随机抹去这句话中的一个词或几个词。
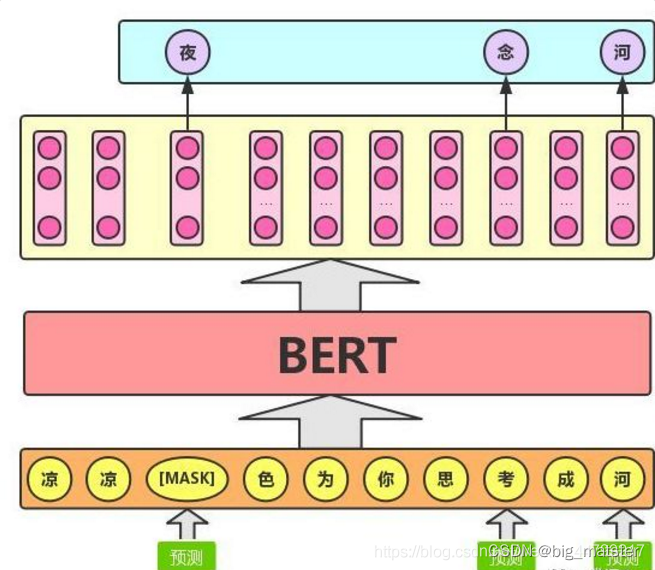
BERT 模型的这个预训练过程其实就是在模仿我们学语言的过程,思想来源于「完形填空」的任务。具体来说,文章作者在一句话中随机选择 15% 的词汇用于预测。对于在原句中被抹去的词汇, 80% 情况下采用一个特殊符号 [MASK] 替换, 10% 情况下采用一个任意词替换,剩余 10% 情况下保持原词汇不变。
这么做的主要原因是:在后续微调任务中语句中并不会出现 [MASK] 标记,而且这么做的另一个好处是:预测一个词汇时,模型并不知道输入对应位置的词汇是否为正确的词汇( 10% 概率),这就迫使模型更多地依赖于上下文信息去预测词汇,并且赋予了模型一定的纠错能力。上述提到了这样做的一个缺点,其实这样做还有另外一个缺点,就是每批次数据中只有 15% 的标记被预测,这意味着模型可能需要更多的预训练步骤来收敛。
Next Sentence Prediction
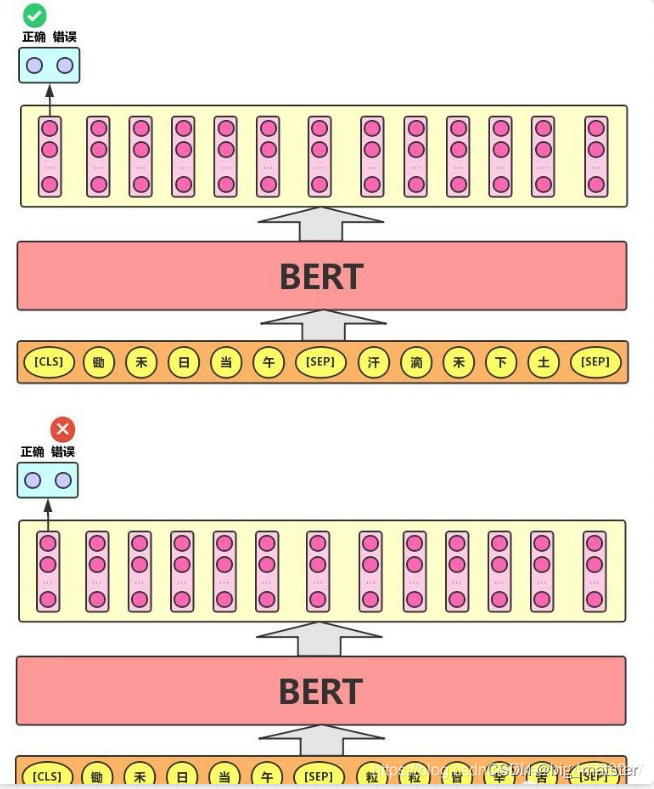
Next Sentence Prediction 的任务描述为:给定一篇文章中的两句话,判断第二句话在文本中是否紧跟在第一句话之后,如下图所示。
(判断第二句话在文本中是否紧跟在第一句之后)
-
这个类似于「段落重排序」的任务,即:将一篇文章的各段打乱,让我们通过重新排序把原文还原出来,这其实需要我们对全文大意有充分、准确的理解。
-
(一篇文章的各段落,打乱,通过重新排序把原文还原出来)
-
Next Sentence Prediction 任务实际上就是段落重排序的简化版:只考虑两句话,判断是否是一篇文章中的前后句。在实际预训练过程中,文章作者从文本语料库中随机选择 50% 正确语句对和 50% 错误语句对进行训练,与 Masked LM 任务相结合,让模型能够更准确地刻画语句乃至篇章层面的语义信息。
-
BERT 模型通过对 Masked LM 任务和 Next Sentence Prediction 任务进行联合训练,使模型输出的每个字 / 词的向量表示都能尽可能全面、准确地刻画输入文本(单句或语句对)的整体信息,为后续的微调任务提供更好的模型参数初始值。
-
(为后续微雕任务,提供更好的模型参数初始值)
Bert的输入和输出分别是什么?
BERT 模型的主要输入是文本中各个字/词(或者称为 token)的原始词向量,该向量既可以随机初始化,也可以利用 Word2Vector 等算法进行预训练以作为初始值;输出是文本中各个字/词融合了全文语义信息后的向量表示,如下图所示(为方便描述且与 BERT 模型的当前中文版本保持一致,统一以「字向量」作为输入):
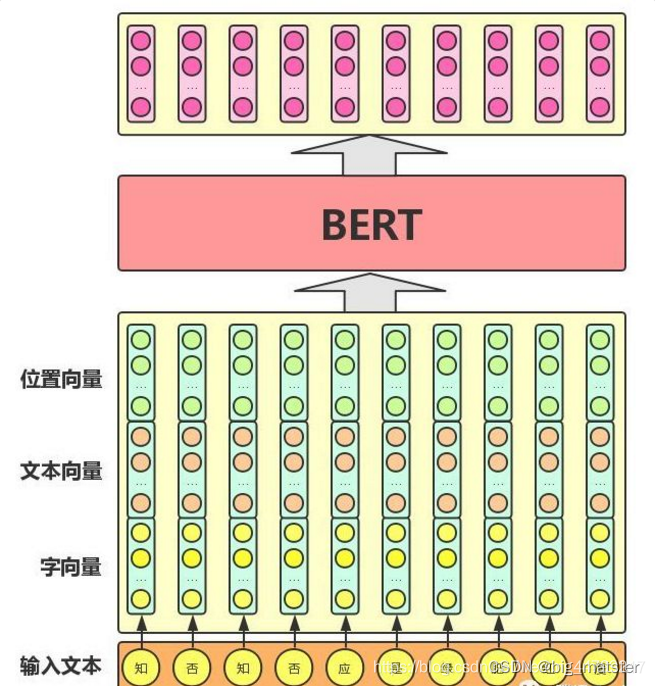
从上图中可以看出,**BERT 模型通过查询字向量表将文本中的每个字转换为一维向量,作为模型输入;模型输出则是输入各字对应的融合全文语义信息后的向量表示。**此外,模型输入除了字向量(英文中对应的是 Token Embeddings),还包含另外两个部分:
-
文本向量(英文中对应的是 Segment Embeddings):该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合
-
位置向量(英文中对应的是 Position Embeddings):由于出现在文本不同位置的字/词所携带的语义信息存在差异(比如:“我爱你”和“你爱我”),因此,BERT 模型对不同位置的字/词分别附加一个不同的向量以作区分
-
最后,BERT 模型将字向量、文本向量和位置向量的加和作为模型输入。特别地,在目前的 BERT 模型中,文章作者还将英文词汇作进一步切割,划分为更细粒度的语义单位(WordPiece),例如:将 playing 分割为 play 和##ing;此外,对于中文,目前作者未对输入文本进行分词,而是直接将单字作为构成文本的基本单位。
-
(将单字作为构成文本的基本单位)
-
需要注意的是,上图中只是简单介绍了单个句子输入 BERT 模型中的表示,实际上,在做 Next Sentence Prediction 任务时,在第一个句子的首部会加上一个[CLS] token,在两个句子中间以及最后一个句子的尾部会加上一个[SEP] token。
针对句子语义相似度任务
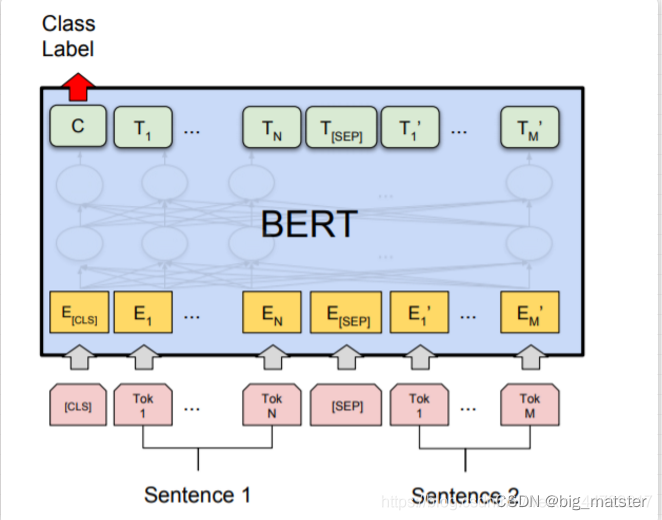
实际操作时,上述最后一句话之后还会加一个[SEP] token,语义相似度任务将两个句子按照上述方式输入即可,之后与论文中的分类任务一样,将**[CLS] token 位置对应的输出**,接上 softmax 做分类即可**(实际上 GLUE 任务中就有很多语义相似度的数据集**)。
针对多标签分类任务数据集
-
多标签分类任务,即 MultiLabel,指的是一个样本可能同时属于多个类,即有多个标签。以商品为例,一件 L 尺寸的棉服,则该样本就有至少两个标签——型号:L,类型:冬装。
-
对于多标签分类任务,显而易见的朴素做法就是不管样本属于几个类,就给它训练几个分类模型即可,然后再一一**判断在该类别中,其属于那个子类别,**但是这样做未免太暴力了,而多标签分类任务,其实是可以「只用一个模型」来解决的。
-
利用 BERT 模型解决多标签分类问题时,其输入与普通单标签分类问题一致,得到其 embedding 表示之后(也就是 BERT 输出层的 embedding),有几个 label 就连接到几个全连接层(也可以称为 projection layer),然后再分别接上 softmax 分类层,这样的话会得到 ,最后再将所有的 loss 相加起来即可。这种做法就相当于将 n 个分类模型的特征提取层参数共享,得到一个共享的表示(其维度可以视任务而定,由于是多标签分类任务,因此其维度可以适当增大一些),最后再做多标签分类任务。
总结
慢慢的到这里为止,明天慢慢的将Bert model 总结一波。
慢慢的进行学习都行啦的样子与打算。
会自己深刻领悟
B
e
r
t
m
o
d
e
l
Bert model
Bertmodel
![[静态时序分析简明教程(八)]虚假路径](https://img-blog.csdnimg.cn/b7bb17870a764c6f923d00c99379c0a5.png)

![[附源码]计算机毕业设计springboot医疗器械公司公告管理系统](https://img-blog.csdnimg.cn/9c2d8d3841234e129d9f75ec69edfcf2.png)

![[附源码]计算机毕业设计学生综合数据分析系统Springboot程序](https://img-blog.csdnimg.cn/8fac5d93f1514737bde372a85756aa66.png)