Instant-ngp
Instant-ngp简单介绍
Instant-ngp论文链接
英伟达实现的github链接
taichi实现Instant-ngp
taichi实现的github链接

渲染
采用体素渲染方法,从相机光线出发,逐步采样3D场景中的三维坐标点的颜色,即可渲染出3D画面。如果直接将3D场景的所有体素存储起来,将会消耗大量内存,所以采用一个神经网络来进行拟合映射。神经网络的输入数据是5维变量,分别是三维坐标和二维角度,输出是4维变量,分别是三维颜色和一维密度。
NeRF 训练和渲染的核心步骤是体渲染技术 (volume rendering)。体渲染可以把神经场“拍平”成一张 2D 图像,从而可以和基准图像进行比较。这个过程是可微的,从而可以用来训练网络。在介绍体渲染之前,先了解一下相机成像的基本原理。在图形学中,为了节约计算资源,会假设从相机发出的光线在击中场景中的点之后,该点的颜色就是光线与屏幕交点处像素的颜色。然而在渲染大气、烟雾等类似介质时,光线会穿过介质而不是仅仅在介质表面处停止。而且在光线前进的过程中,会有一定比例的光线被介质吸收掉(不考虑散射和自发光)。吸收光线的这部分介质会对光线的最终颜色有贡献。体密度高的地方吸收的光线就多,这部分介质的颜色就显得浓重。所以光线最终的颜色是光线沿途经过的点的颜色的积分。

假设相机位置
O
O
O,光线方向为
d
d
d,光线方程为
r
(
t
)
=
O
+
t
d
r(t)=O+td
r(t)=O+td,像素颜色为
c
(
r
)
c(r)
c(r)
c
(
r
)
=
∫
t
n
t
f
T
(
t
)
σ
(
t
)
c
(
r
(
t
)
,
d
)
d
t
c(r)=\int_{t_n}^{t_f}T(t)\sigma(t)c(r(t),d)dt
c(r)=∫tntfT(t)σ(t)c(r(t),d)dt
T
(
t
)
T(t)
T(t)表示透射到
t
t
t点的光线比例,
σ
(
t
)
d
t
\sigma(t)dt
σ(t)dt表示的是在
t
t
t点附近的一个小邻域内会挡住多少比例的光线比例,二者相乘就是到达
t
t
t且在
t
t
t点被拦下的光线比例,再乘上该点对应的颜色
c
(
r
(
t
)
,
d
)
c(r(t),d)
c(r(t),d) 就是这个点对光线最终颜色的贡献,积分区间
[
t
n
,
t
f
]
[t_n,t_f]
[tn,tf]表示射线与介质的最近交点
t
n
t_n
tn和
t
f
t_f
tf。在实际计算时我们需要用离散和来逼近积分值。也就是在光线上采集一些离散点,将它们的颜色加权求和。

1.[Camera paramertes] 在准备好一组拍摄的 2D 图像后,首先解算每张图像对应的相机位姿参数。这一步可以使用如 COLMAP 等现成工具。COLMAP 会匹配不同图像中出现的场景共同点来计算相机位姿。此外我们假设整个场景位于范围是
[
−
1
,
1
]
3
[-1,1]^3
[−1,1]3的立方体盒子内。
2.[3D point sampling] 对一张真实图像,从相机发出一条光线,光线穿过图像进入场景。光线和图像的交点
p
p
p的像素值
I
(
p
)
I(p)
I(p)是基准颜色。我们在这条光线上离散采样得到若干个点。把这些采样点的空间坐标
(
x
,
y
,
z
)
(x,y,z)
(x,y,z)和第一步解算出的对应的相机的姿态
θ
,
ϕ
\theta,\phi
θ,ϕ组合起来作为神经网络的输入。
3.[NeRF model] 通过神经网络预测光线上每个采样点的颜色和密度。
4.[Rendering] 通过体渲染,我们可以用上一步神经网络输出的采样点的颜色和密度作离散和,近似计算对应光线的像素值
I
^
(
p
)
\hat{I}(p)
I^(p)。
5.[Photometric loss] 把
I
^
(
p
)
\hat{I}(p)
I^(p)和光线颜色的真值
I
(
p
)
I(p)
I(p)比较计算误差和梯度,就可以对神经网络进行训练。
Instant NGP
原始版本的 NeRF 给出的效果已经十分惊艳,但它的训练速度较慢,通常需要一到两天左右。这里主要的原因是 NeRF 使用的神经网络还是有点“大”了,2022 年 NVIDIA 的论文 Instant NGP 大大改进了这一点。Instant NGP 相对于 NeRF 的核心改进在于它采用了“多分辨率哈希编码” (Multi-resolution hash encoding) 的数据结构。你可以理解为 Instant NGP 把原始 NeRF 中神经网络的大部分参数扔掉,换成一个小得多的神经网络;同时额外训练一组编码参数 (feature vectors),这些编码参数是存储在网格的顶点上的,这样的网格一共有
L
L
L层,它们按照分辨率从低到高,用于学习场景不同层次的细节。在每次训练时,小神经网络的参数和每层网格上只有点
(
x
,
y
,
z
)
(x,y,z)
(x,y,z)周围的 8 个顶点中的编码参数会被更新。Instant NGP 的另一个重要的工程优化是将整个网络实现在一个CUDA kernel中(Fully-fused MLP),使得网络的所有计算都在 GPU 的 local cache 中进行。据论文所称这会带来10x的效率提升。
Instant-ngp主要用于解决NeRF在对全连接神经网络进行参数化时的效率问题。该方法提出一种编码方式,使得可以使用一个较小规模的网络来实现NeRF同时不会产生精度的损失。该网络由特征向量的多分辨率哈希表实现增强,基于随机梯度下降执行优化。多分辨率结构有助于GPU并行,能够通过消除哈希冲突减少计算。该方法最大的亮点是将NeRF以小时计的时间开销提升到秒级。下图为一些渲染样例,可以看到渲染时间有显著的提升。由简介可知,Instant-ngp项目最大的亮点在于提出了一个基于哈希搜索的编码方法,仅需一个小规模神经网络就能够实现全连接网络的效果,而且不损失精度。因此,该文章的核心要点可被分为两个部分:1). 多分辨率哈希编码的设计与实现;2). 基于编码的神经网络训练。
稍微了解哈希搜索的人都应该了解其算法效率,根据内容就能直接定位数据位置。即使需要二次搜索相同哈希值下的候选,只要在设计时保持数据分布的平衡,依然可保持高效计算。假设提供一个全连接层m(y;Φ), Instant-ngp设计一个针对输入的再赋权:y=enc(x,𝜃)用来提升拟合质量和训练速度,同时避免额外的计算开销。这使得 Instant-ngp不仅拥有可训练的权重值Φ,同时还拥有可训练的编码权重𝜃。这些权重被安排再L层中,每层包含T个特征向量,伴随F维的数据。这些超参数值被表示在下表中:


该图表示了利用不同分辨率的体素结构来编码点云数据的方式。红色方框表示的是分辨率较高的体素网格,蓝色方框对应的是分辨率较低的提速网格。根据网格顶点的数值以及对应的位置,可以实现对网格内部点的编码。该过程可以较快执行的原因在于整个编码过程是面向数值本身实现的,因此不需要搜索,仅需要比较计算即可实现快速精确定位与编码,并输出最终我们需要的T个L维特征向量。L对应的是特定分辨率体素对应的编码层,按照之前表格给出的超参数,层数被设置为16,即体素分辨率变化分为16级,对应的分辨率随级别变化。
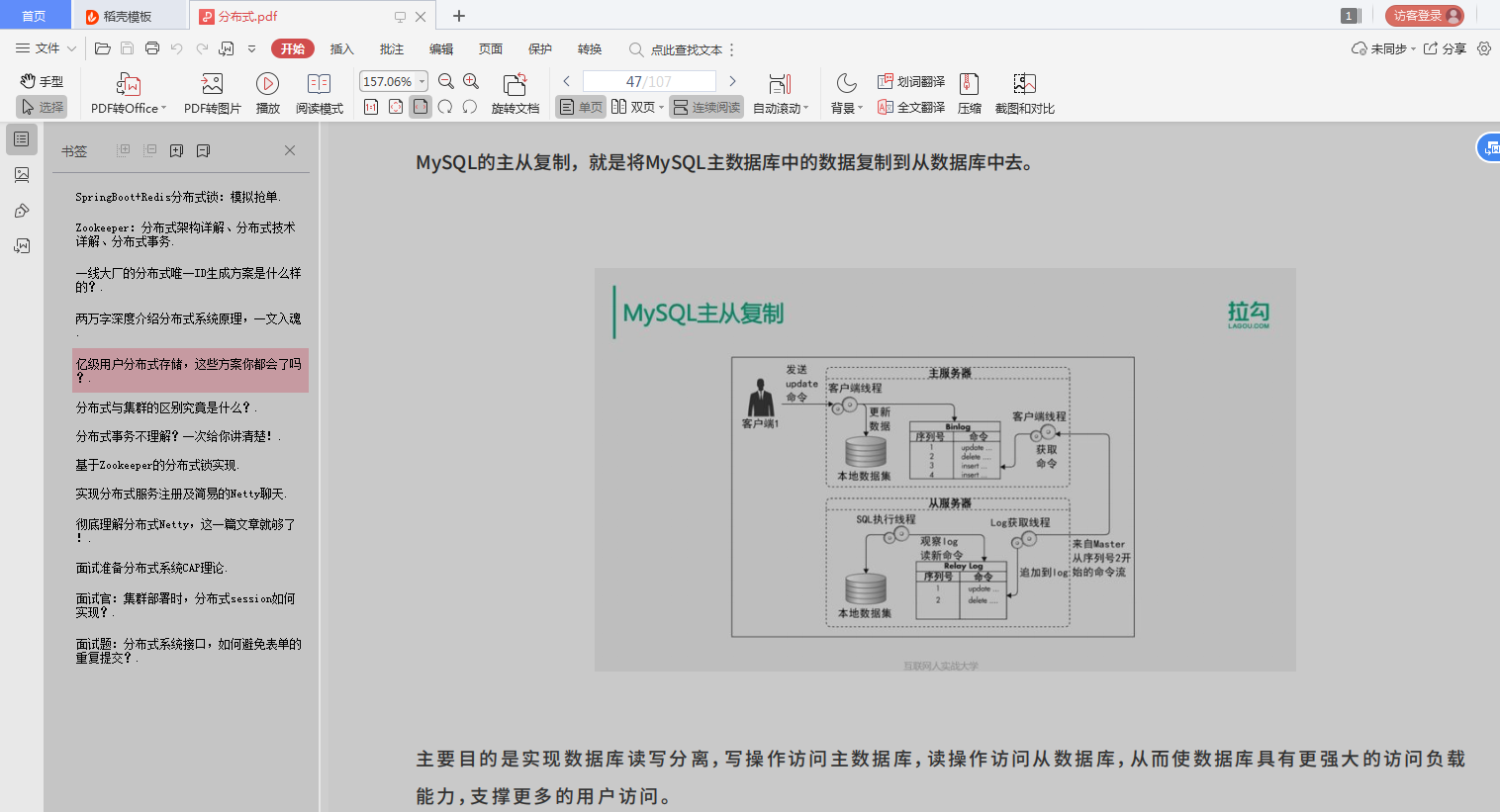







![基于OpenCV [c++]——形态学操作(分析和应用)](https://img-blog.csdnimg.cn/c00451600d5d46f2b5005b409ad64b74.png)