1.启动网络
在windows任务管理器启动服务vm Dhcp
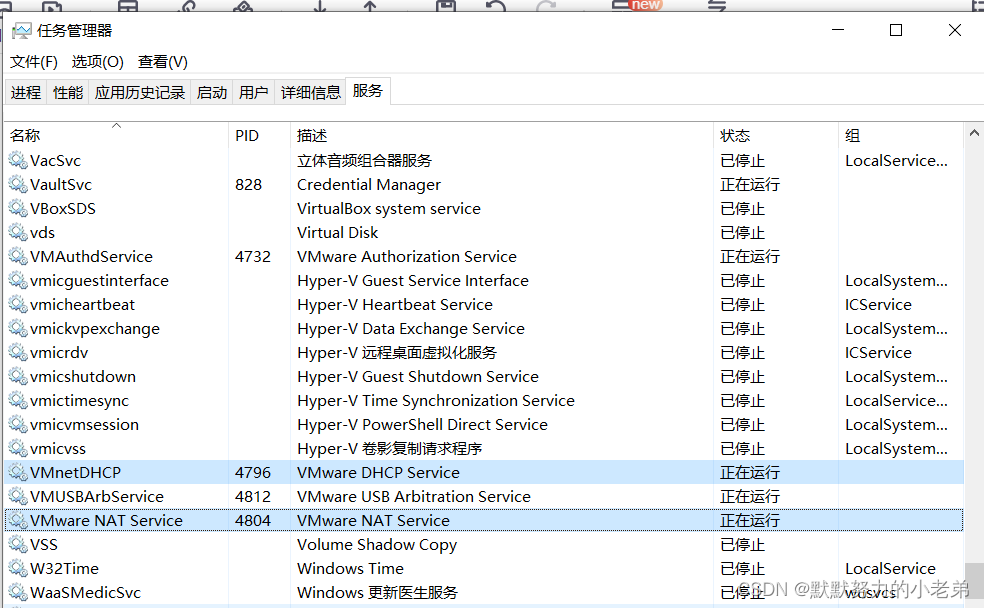
#由动态ip变为静态
#启动网卡
ifup ens33
#修改网卡配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTSTRAP=static
IPADDR=192.168.202.101
NETMASK=255.255.255.0
GATEWAY=192.168.202.2
DNS1=192.168.202.2
#重启网络
service network restart
2.安装mysql软件
1.二进制(要编译,难度高) rpm tar deb(yum 和rpm都要rpm包)
red hat package manager
rpm -ivh mysql*.rpm #有包依赖问题,需要其他包,自己要先下好rpm文件
yum search ifconfig #解决包依赖 yellow dog updater,使用互联网
yum install net-tools #查到相关不同名的包
#ftp下载多个connector包后
rpm -ivh mysql*.rpm
#mariadb与mysql冲突
yum remove mariadb-libs
msql -u root -p
#修改密码
set global validate_password_length=6;
set password=password('123456')
3.设置仓库
cd /etc/yum.repos.d/CentOsxxxx.repo
#查看文件配置文件
rpm -qc
4.部署模式
1.独立模式
2.伪分布式(一台机器,分布式)
3.完全分布式(多台机器部署)
5.安装hadoop java环境
1.解压文件
2.配置java全局变量
vi ~/.bashrc
#写入
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH:/url/local/hadoop/bin
#重新编译
source ~/.bashrc
#hadoop的是 sbin 和bin
hadoop version
java -v
cat output/* #查看多个文件
6.安装伪分布式,与独立式区分,它在hdfs存储,配置文件为空为单机模式
1.core-site.xml 设置hdfs的访问路径和存储位置
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
2.#vim etc/hadoop/hdfs-site.xml 设置集群份数和nn和dn的存储位置
<property>
<name>dfs.replication</name> #集群数据复制的份数,高可用
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
3.格式化hdfs
cd /usr/local/hadoop/
./bin/hdfs namenode -format
4.启动
sudo systemctl stop firewalld
sudo setenforce 0
#访问http://192.168.202.100:9870/ hdfs的网络路径
#创建多层文件夹
./bin/hdfs dfs -mkdir -p /user/hadoop
#创建文件夹
./bin/hdfs dfs -mkdir input
#放入本地文件到hdfs文件夹
./bin/hdfs dfs -put etc/hadoop/*.xml input
#查看文件夹的文件和目录
./bin/hdfs dfs -ls input
#运行hadoop自带的demo
./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar grep input output 'dfs[a-z.]+'
./bin/hdfs dfs -cat output/* #查看结果
./bin/hdfs dfs -rm -r output #删除结果
7.namenode存储数据 9000是内部进程通讯(多台机器一样配置文件) 9870对外端口 web-ui
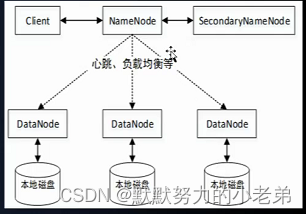
8.完全分布式
#克隆机器即可,ssh…配置文件自己配
#master nodemanager namenode secondarynode historyxxx
#slaver 都是namenode
#黑客可以改C:/sys32/etc/hosts文件 导致我们访问钓鱼网站…
#vmware 编辑–>粘贴
#直接上传配置文件
#远程连接hadoop,修改配置文件为ip即可,涉及集群安全.客户端也可以删除
cd /usr/local/hadoop/etc/hadoop/core-site.xml
hdfs dfs - ls
hdfs dfs -cat output/*
9.追加内容到文件
echo "export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin">>.bashrc
source .bashrc
10.hdfs 高容错性(备份) 不可以修改(一次写入多次查询,不支持并发,不适合大量的小文件)(元数据太多了,内存不够用)(namenode配置文件的指定dir/current可以查看snn和nn)
- namenode: 文件名和文件夹下的文件的信息(块) 如果文件丢失不能启动
- fsimage(元数据镜像文件)(在内存中)(文件树,文件夹)
- editLog(操作的日志) 怕突然死机数据丢失,定期更新
_inprogress文件是记录正在修改的信息2.secondaryNameNode: (备份nn数据 fsimg 和editlog) 定期清除 fsimage和editlog(合并后到 主namenode) 默认1小时执行一次,startup progress可以看启动信息 如图h2
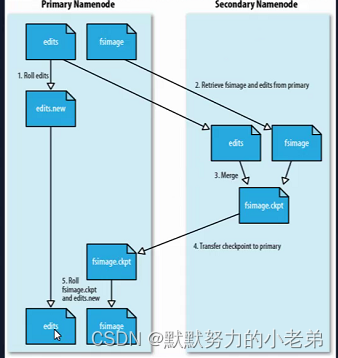
hdfs(原)元数据metadata: 像mysql元数据库的表保存了mysql表名用户名,可以实现sql注入
#ls -lh
11.hdfs数据块 block默认128m hdfs最小文件大小
master文件上传master文件都有存在块,
slave1上传slave1也存在块(因为slave1先存在本地,然后网络先发到cpu快,磁盘有多个节点时)
#删除目录
hdfs dfs -rm -r mydir
#查看日志文件
cd /usr/local/hadoop/tmp/dfs/name/current
hdfs oev -i edits_inprogress -o xxx.xml -p XML
cp与get的区别: get是服务器到本地,cp是服务器到服务器



![基于OpenCV [c++]——形态学操作(分析和应用)](https://img-blog.csdnimg.cn/c00451600d5d46f2b5005b409ad64b74.png)