前言:Hello大家好,我是Dream。 OpenCV是一个开源的计算机视觉库,可以用于实现各种图像和视频处理任务,包括红绿灯识别。可以帮助自动驾驶汽车、智能交通系统等设备准确地识别红绿灯的状态,以便做出正确的决策。今天,就有Dream带领大家复盘一下计算机视觉中最经典的实验:OpenCV进行红绿灯识别,一起来看看吧~
本文目录:
- 一、背景介绍
- 二、数据集介绍
- 三、加载数据集
- 1.导入库
- 2.图像数据目录
- 3.加载数据集
- 四、数据可视化
- 五、数据预处理
- 1.输入
- 2.输出
- 六、特征提取
- 1.RGB to HSV
- 2.创建图像特征
- 七、测试数据集
- 八、测试
- 九、输出准确率
- 结论
一、背景介绍
红绿灯分为导向灯和圆形灯。一般圆形灯在路口只有一盏灯,红灯亮时禁止直行和左转,可以右转弯。导向灯市带有箭头的,可以有两个或三个,分别指示不同方向的行车和停车。按指示的灯即可,没有右转向导向灯的情况下可以视为可以右转。
RGB颜色空间以R(Red:红)、G(Green:绿色)、 B(Blue:蓝)三种基本色为基础,进行不同程度的叠加,产生丰富而广泛的颜色,所以俗称三基色模式。在大自然中有无穷多种不同的颜色,而人眼只能分辨有限种不同的颜色,RGB棋式可表示一千六百多万种不同的颜色,在人跟看起来它非常接近大自然的颜色,故又称为自然色彩模式。红绿蓝代表可见光谱中的三种基木颜色或称为三原色,每一种颜色按其亮度的不同分为256个等级。当色光三原色重叠时,由于不同的混色比例能产生各种中间色。
RGB颜色空间最大的优点就是直观,容易理解。缺点是R、G、B这三个分量是高度相关的,即如果一个颜色的某一个分量发生了一定程度的改变,那么这个相色很可能要发生改变;人眼对于常见的 红绿蓝三色的敏感程度是不一样的,因此RGB颜色空间的均匀性非常差,且两种颜色之间的知觉差异色差不能表示为改颜色空间中两点间的距离,但是利用线性或非线性变换,则可以从RGB颜色空间推导出其他的颜色特征空间。
而在HSV颜色空间中,颜色的参数分别是:色调(H),饱和度(S),明度(V)。色调H,用角度度量。饱和度S表示颜色接近光谱色的程度。一种颜色,可以看成是某种光谱色于白色混合的结果。其中光谱色所占的比例愈大,颜色接近光谱色的程度就愈高,颜色的饱和度也就愈高。饱和度高,颜色则深而艳。光谱色的白光成分为0,饱和度达到最高。通常取值范围为0 % − 100 % 0%-100%0%−100%,值越大,颜色越饱和。明度V表示颜色明亮的程度,对于光源色,明度值与发光体的光亮度有关;对于物体色,此值和物体的透射比或反射比有关。相对于RGB空间,HSV空间能够非常直观的表达色彩的明暗,色调,以及鲜艳程度,方便进行颜色之间的对比。将图片从传统的RGB颜色空间转换到HSV模型空间,能够大大提高目标识别与检测的抗干扰能力,使得检测结果更为精确。
二、数据集介绍
首先我们第一步是导入数据,并在RGB及HSV色彩空间可视化部分数据。这里的数据,我们采用MIT自动驾驶课程的图片,
总共三类:红绿黄,1187张图片,其中,723张红色交通灯图片,429张绿色交通灯图片,35张黄色交通灯图片。
723张红色交通灯图片:
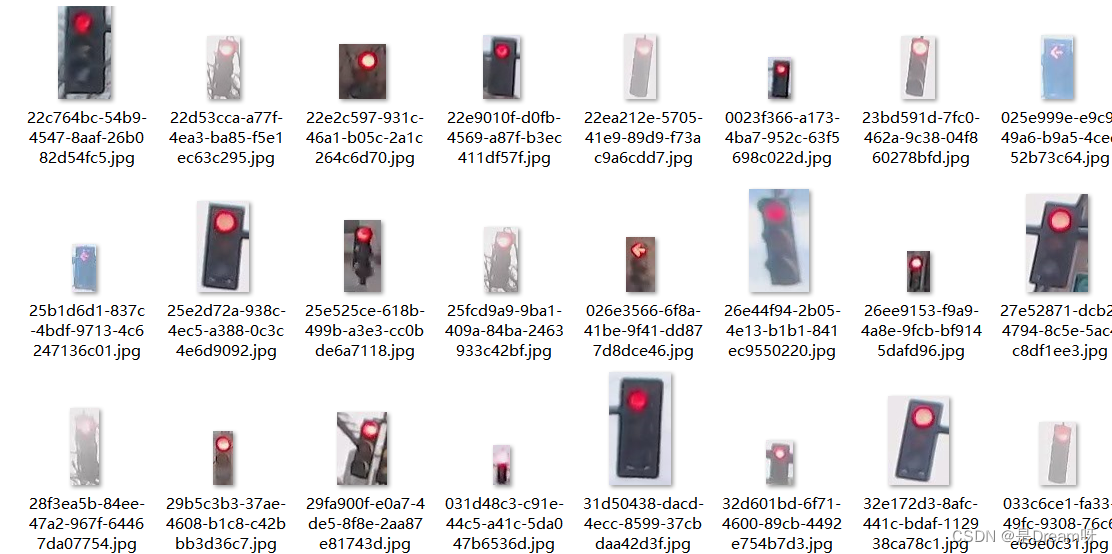
429张绿色交通灯图片:

35张黄色交通灯图片:

三、加载数据集
1.导入库
# import some libs
import cv2
import os
import glob
import random
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
%matplotlib inline
2.图像数据目录
IMAGE_DIR_TRAINING = "traffic_light_images/training/"
IMAGE_DIR_TEST = "traffic_light_images/test/"
3.加载数据集
此处用于用于加载图像数据集。函数的输入参数是一个字符串类型的变量image_dir,表示存储图像数据集的目录路径。
函数的输出结果是一个列表类型的变量im_list,其中包含了所有图像及其对应的标签。每个元素都是一个元组,包含了一个图像数组和一个字符串类型的标签,表示该图像所属的类别(红灯、黄灯或绿灯)。
具体实现过程是首先定义了一个包含三种颜色类别的列表image_types,然后遍历每一种颜色类别的文件夹,使用glob模块获取该文件夹下所有文件的路径,并读取每个文件的图像数据。如果读取成功,则将该图像及其对应的标签加入到im_list列表中。
最后,函数返回im_list列表作为输出结果,并且在调用函数时传入训练集目录路径IMAGE_DIR_TRAINING作为输入参数。
def load_dataset(image_dir):
'''
This function loads in images and their labels and places them in a list
image_dir:directions where images stored
'''
im_list =[]
image_types= ['red','yellow','green']
#Iterate through each color folder
for im_type in image_types:
file_lists = glob.glob(os.path.join(image_dir,im_type,'*'))
print(len(file_lists))
for file in file_lists:
im = mpimg.imread(file)
if not im is None:
im_list.append((im,im_type))
return im_list
IMAGE_LIST = load_dataset(IMAGE_DIR_TRAINING)
四、数据可视化
此处使用matplotlib库展示了数据集中的三张图像,分别对应红灯、黄灯和绿灯,以及它们的标签信息。
首先,使用plt.subplots()函数创建一个包含1行3列的子图,每个子图大小为5*2英寸。然后,从数据集中选取三张图像,分别是第一张、第731张和第801张,并将它们存储在变量img_red、img_yellow和img_green中。
接下来,分别将这三张图像和它们的标签信息绘制在三个子图中。具体实现过程是:
-
对于第一个子图,使用
ax[0].imshow()函数显示红灯图像,使用ax[0].annotate()函数添加标签信息,使用ax[0].axis('off')函数关闭坐标轴,使用ax[0].set_title()函数设置标题,最后使用plt.show()函数显示图像。 -
对于第二个子图和第三个子图,分别使用类似的方式显示黄灯图像和绿灯图像,并添加对应的标签信息和标题。
-
最后,使用
plt.show()函数显示整个图像。
_,ax = plt.subplots(1,3,figsize=(5,2))
#red
img_red = IMAGE_LIST[0][0]
ax[0].imshow(img_red)
ax[0].annotate(IMAGE_LIST[0][1],xy=(2,5),color='blue',fontsize='10')
ax[0].axis('off')
ax[0].set_title(img_red.shape,fontsize=10)
#yellow
img_yellow = IMAGE_LIST[730][0]
ax[1].imshow(img_yellow)
ax[1].annotate(IMAGE_LIST[730][1],xy=(2,5),color='blue',fontsize='10')
ax[1].axis('off')
ax[1].set_title(img_yellow.shape,fontsize=10)
#green
img_green = IMAGE_LIST[800][0]
ax[2].imshow(img_green)
ax[2].annotate(IMAGE_LIST[800][1],xy=(2,5),color='blue',fontsize='10')
ax[2].axis('off')
ax[2].set_title(img_green.shape,fontsize=10)
plt.show()
得到输出结果:

五、数据预处理
在导入了上述数据后,接下来我们需要标准化输入及输出
1.输入
从上图,我们可以看出,每张图片的大小并不一样,我们需要标准化输入将每张图图片的大小resize成相同的大小,因为对于分类任务来说,我们需要在每张图片上应用相同的算法,因此标准化图像尤其重要。
此处我们的输入参数是一个列表类型的变量image_list,其中包含了所有图像及其对应的标签。每个元素都是一个元组,包含了一个图像数组和一个字符串类型的标签,表示该图像所属的类别(红灯、黄灯或绿灯)。输出结果是一个列表类型的变量standard_list,其中包含了所有标准化后的图像及其对应的标签。每个元素也是一个元组,包含了一个标准化后的图像数组和一个独热编码后的标签数组,表示该图像所属的类别。
具体实现过程是首先遍历每个图像及其对应的标签,使用standardize_input()函数将图像标准化为指定大小,并使用one_hot_encode()函数将标签进行独热编码。然后,将标准化后的图像及其独热编码后的标签加入到standard_list列表中。
最后,函数返回standard_list列表作为输出结果,其中包含了所有标准化后的图像及其对应的标签。
# 标准化输入图像,这里我们resize图片大小为32x32x3,这里我们也可以对图像进行裁剪、平移、旋转
def standardize(image_list):
'''
This function takes a rgb image as input and return a standardized version
image_list: image and label
'''
standard_list = []
#Iterate through all the image-label pairs
for item in image_list:
image = item[0]
label = item[1]
# Standardize the input
standardized_im = standardize_input(image)
# Standardize the output(one hot)
one_hot_label = one_hot_encode(label)
# Append the image , and it's one hot encoded label to the full ,processed list of image data
standard_list.append((standardized_im,one_hot_label))
return standard_list
def standardize_input(image):
#Resize all images to be 32x32x3
standard_im = cv2.resize(image,(32,32))
return standard_im
2.输出
这里我们的标签数据是类别数据:‘red’,‘yellow’,‘green’,因此我们可以利用one_hot方法将类别数据转换成数值数据
def one_hot_encode(label):
#return the correct encoded label.
'''
# one_hot_encode("red") should return: [1, 0, 0]
# one_hot_encode("yellow") should return: [0, 1, 0]
# one_hot_encode("green") should return: [0, 0, 1]
'''
if label=='red':
return [1,0,0]
elif label=='yellow':
return [0,1,0]
else:
return [0,0,1]
六、特征提取
在这里我们将使用色彩空间、形状分析及特征构造
1.RGB to HSV
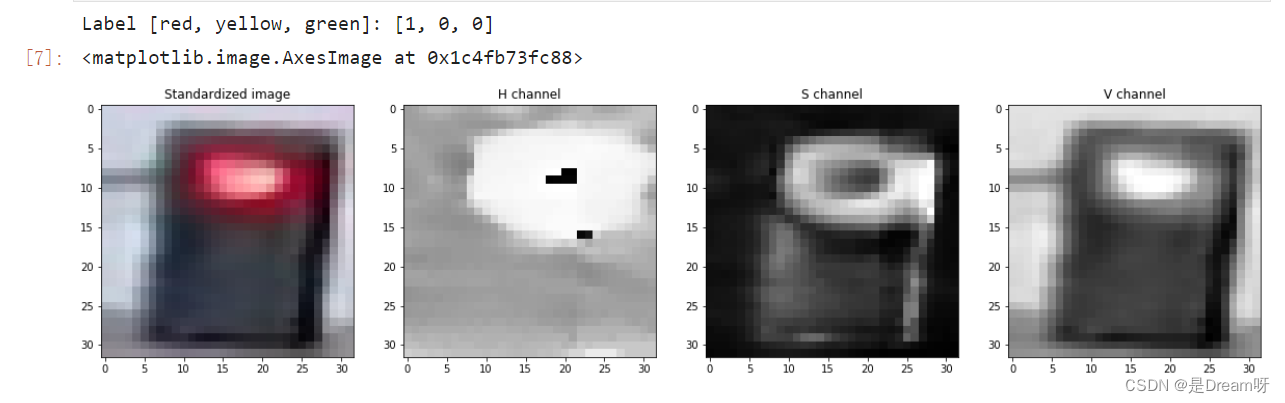
首先可视化标准化后的图像及其HSV颜色空间中的三个通道。
定义一个整数变量image_num,表示要可视化的图像在训练集中的索引。然后,从标准化后的训练集Standardized_Train_List中获取该图像及其对应的标签,并将它们分别存储在变量test_im和test_label中。
接下来,使用OpenCV库的cvtColor()函数将RGB格式的图像转换为HSV格式,并将其存储在变量hsv中。然后,分别从hsv数组中获取H、S、V三个通道的数组,并将它们分别存储在变量h、s和v中。
最后,使用matplotlib库创建一个包含四个子图的图像窗口,分别显示原始的标准化后的图像、H通道、S通道和V通道,并添加相应的标题。其中,使用imshow()函数显示图像,使用cmap='gray'参数设置为灰度颜色映射。
#Visualize
image_num = 0
test_im = Standardized_Train_List[image_num][0]
test_label = Standardized_Train_List[image_num][1]
#convert to hsv
hsv = cv2.cvtColor(test_im, cv2.COLOR_RGB2HSV)
# Print image label
print('Label [red, yellow, green]: ' + str(test_label))
h = hsv[:,:,0]
s = hsv[:,:,1]
v = hsv[:,:,2]
# Plot the original image and the three channels
_, ax = plt.subplots(1, 4, figsize=(20,10))
ax[0].set_title('Standardized image')
ax[0].imshow(test_im)
ax[1].set_title('H channel')
ax[1].imshow(h, cmap='gray')
ax[2].set_title('S channel')
ax[2].imshow(s, cmap='gray')
ax[3].set_title('V channel')
ax[3].imshow(v, cmap='gray')
输出结果:
HSV即色相、饱和度、明度(英语:Hue, Saturation, Value),又称HSB:
色相(H)是色彩的基本属性,就是平常所说的颜色名称,如红色、黄色等。
饱和度(S)是指色彩的纯度,越高色彩越纯,低则逐渐变灰,取0-100%的数值。
明度(V),亮度(L),取0-100%。
2.创建图像特征
函数create_feature()用于计算图像的基本亮度特征。输入参数rgb_image是一张RGB格式的图像,函数会将其转换为HSV格式,并计算HSV颜色空间中V通道的平均值作为亮度特征。
def create_feature(rgb_image):
'''
Basic brightness feature
rgb_image : a rgb_image
'''
hsv = cv2.cvtColor(rgb_image,cv2.COLOR_RGB2HSV)
sum_brightness = np.sum(hsv[:,:,2])
area = 32*32
avg_brightness = sum_brightness / area#Find the average
return avg_brightness
函数high_saturation_pixels()用于计算图像的高饱和度像素的红色和绿色通道的平均值。输入参数rgb_image是一张RGB格式的图像,函数会将其转换为HSV格式,并遍历32*32个像素点,找到饱和度大于阈值threshold的像素点,然后计算这些像素点的红色和绿色通道的平均值。如果没有找到符合条件的像素点,则调用函数highest_sat_pixel()查找最饱和度的像素点,并判断该像素点的红色和绿色通道哪个更高。
def high_saturation_pixels(rgb_image,threshold=80):
'''
Returns average red and green content from high saturation pixels
Usually, the traffic light contained the highest saturation pixels in the image.
The threshold was experimentally determined to be 80
'''
high_sat_pixels = []
hsv = cv2.cvtColor(rgb,cv2.COLOR_RGB2HSV)
for i in range(32):
for j in range(32):
if hsv[i][j][1] > threshold:
high_sat_pixels.append(rgb_image[i][j])
if not high_sat_pixels:
return highest_sat_pixel(rgb_image)
sum_red = 0
sum_green = 0
for pixel in high_sat_pixels:
sum_red+=pixel[0]
sum_green+=pixel[1]
# use sum() instead of manually adding them up
avg_red = sum_red / len(high_sat_pixels)
avg_green = sum_green / len(high_sat_pixels)*0.8
return avg_red,avg_green
def highest_sat_pixel(rgb_image):
'''
Finds the highest saturation pixels, and checks if it has a higher green
or a higher red content
'''
hsv = cv2.cvtColor(rgb_image,cv2.COLOR_RGB2HSV)
s = hsv[:,:,1]
x,y = (np.unravel_index(np.argmax(s),s.shape))
if rgb_image[x,y,0] > rgb_image[x,y,1]*0.9:
return 1,0 #red has a higher content
return 0,1
这两个函数都返回一个包含特征信息的元组,其中第一个元素是亮度特征或红色通道的平均值,第二个元素是绿色通道的平均值。
七、测试数据集
使用HSV和实验确定每个图像中的红色、绿色和黄色内容确定的阈值。返回基于值的分类
def estimate_label(rgb_image,display=False):
'''
rgb_image:Standardized RGB image
'''
return red_green_yellow(rgb_image,display)
def findNoneZero(rgb_image):
rows,cols,_ = rgb_image.shape
counter = 0
for row in range(rows):
for col in range(cols):
pixels = rgb_image[row,col]
if sum(pixels)!=0:
counter = counter+1
return counter
def red_green_yellow(rgb_image,display):
hsv = cv2.cvtColor(rgb_image,cv2.COLOR_RGB2HSV)
sum_saturation = np.sum(hsv[:,:,1])# Sum the brightness values
area = 32*32
avg_saturation = sum_saturation / area #find average
sat_low = int(avg_saturation*1.3)#均值的1.3倍,工程经验
val_low = 140
#Green
lower_green = np.array([70,sat_low,val_low])
upper_green = np.array([100,255,255])
green_mask = cv2.inRange(hsv,lower_green,upper_green)
green_result = cv2.bitwise_and(rgb_image,rgb_image,mask = green_mask)
#Yellow
lower_yellow = np.array([10,sat_low,val_low])
upper_yellow = np.array([60,255,255])
yellow_mask = cv2.inRange(hsv,lower_yellow,upper_yellow)
yellow_result = cv2.bitwise_and(rgb_image,rgb_image,mask=yellow_mask)
# Red
lower_red = np.array([150,sat_low,val_low])
upper_red = np.array([180,255,255])
red_mask = cv2.inRange(hsv,lower_red,upper_red)
red_result = cv2.bitwise_and(rgb_image,rgb_image,mask = red_mask)
if display==True:
_,ax = plt.subplots(1,5,figsize=(20,10))
ax[0].set_title('rgb image')
ax[0].imshow(rgb_image)
ax[1].set_title('red result')
ax[1].imshow(red_result)
ax[2].set_title('yellow result')
ax[2].imshow(yellow_result)
ax[3].set_title('green result')
ax[3].imshow(green_result)
ax[4].set_title('hsv image')
ax[4].imshow(hsv)
plt.show()
sum_green = findNoneZero(green_result)
sum_red = findNoneZero(red_result)
sum_yellow = findNoneZero(yellow_result)
if sum_red >= sum_yellow and sum_red>=sum_green:
return [1,0,0]#Red
if sum_yellow>=sum_green:
return [0,1,0]#yellow
return [0,0,1]#green
八、测试
我们选择三张图片来看看测试效果:
img_test = [(img_red,'red'),(img_yellow,'yellow'),(img_green,'green')]
standardtest = standardize(img_test)
for img in standardtest:
predicted_label = estimate_label(img[0],display = True)
print('Predict label :',predicted_label)
print('True label:',img[1])

九、输出准确率
此处计算分类器在测试集上的准确率,并找到所有被错误分类的图像。
首先,定义一个函数get_misclassified_images(),该函数接受一个测试集列表作为输入参数,并遍历其中的每个图像。对于每个图像,从其中获取真实标签和预测标签,并将其进行比较。如果两者不相等,则将该图像、预测标签和真实标签组成一个元组,并将其加入到misclassified_images_labels列表中。最后,函数返回misclassified_images_labels列表作为输出结果,其中包含了所有被错误分类的图像及其预测标签和真实标签。
然后,调用get_misclassified_images()函数并传入标准化后的测试集STANDARDIZED_TEST_LIST作为输入参数,得到所有被错误分类的图像列表MISCLASSIFIED。
接下来,计算分类器在测试集上的准确率。具体实现过程是,首先计算测试集的总数total,然后从总数中减去被错误分类的图像数,得到分类正确的图像数num_correct。最后,将num_correct除以total,得到分类器在测试集上的准确率accuracy。
最后,输出准确率和被错误分类的图像数量。
def get_misclassified_images(test_images,display=False):
misclassified_images_labels = []
for image in test_images:
# 获取真实数据
im = image[0]
true_label = image[1]
assert (len(true_label)==3),'This true_label is not the excepted length (3).'
#从分类器中获取预测标签
predicted_label = estimate_label(im,display=False)
assert(len(predicted_label)==3),'This predicted_label is not the excepted length (3).'
#比较真实标签和预测标签
if(predicted_label!=true_label):
#如果这些标签不相等,则图像被错误分类
misclassified_images_labels.append((im,predicted_label,true_label))
return misclassified_images_labels
# 查找给定测试集中所有分类错误的图像
MISCLASSIFIED = get_misclassified_images(STANDARDIZED_TEST_LIST,display=False)
#准确率计算
total = len(STANDARDIZED_TEST_LIST)
num_correct = total-len(MISCLASSIFIED)
accuracy = num_correct / total
print('Accuracy:'+str(accuracy))
print('Number of misclassfied images = '+str(len(MISCLASSIFIED))+' out of '+str(total))
输出结果:
Accuracy:0.9797979797979798
Number of misclassfied images = 6 out of 297
结论
我们可以看到准确率达到了接近于98%,这个准确率是指在使用OpenCV库实现的红绿灯检测算法在测试集上的分类准确率。具体来说,它表示在测试集中有 97.98%的图像被正确分类为红灯、黄灯或绿灯,而仅有2.02%的图像被错误分类。
这个准确率较高,表明使用OpenCV库实现的红绿灯检测算法在测试集上具有较好的分类性能,可以比较可靠地识别图像中的红灯、黄灯和绿灯。但需要注意的是,这个准确率只是在特定的测试集上得到的结果,可能并不能完全代表算法的性能,我们可以在更多的数据集上进行验证和测试,这个留给我们以后在学习的时候再继续探讨吧!
本期推荐:
人工智能基础 ChatGPT背后的逻辑

抽奖方式:评论区随机抽取四位小伙伴免费送出
参与方式:关注博主、点赞、收藏、评论区评论“人生苦短,我用Python!”(切记要点赞+收藏,否则抽奖无效,每个人最多评论三次!)
活动截止时间:2023-06-05 20:00:00