写在前面
jvm调优不管是工作中还是面试中都异常重要,是衡量一个开发人员技术水平的重要指标,这也是个人的一个弱项,希望通过本文能够提高自我,也更能帮助到正在阅读文章的你,我们就开始吧!
1:重要的指标
如果是医生给病人看病,是需要根据各种指标的高低来对病人做出诊断的,分析jvm也是一样,这里我们主要看下两个指标,分别是分配速率和提升速率,解释如下:
分配速率:单位时间内eden生成的对象大小,单位m,即m/s
提升速率:单位时间内从young提升到old的对象大小,单位m,即m/s
1.1:分配速率
分配速率,我们并没有办法直接获取,但是可以通过GC日志来间接获取,方法是计算出某次GC距离上次GC新增的对象的数量,并除以两次GC间隔的时间就行了,如下的GC日志:
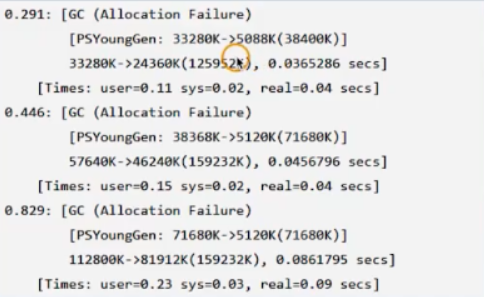
第一次GC:
生成的对象量是33280K,经历的时间是0.291s,分配速率为33.280m/0.291s=33280m/291s=114m/s
第二次GC:
生成的对象量是38368k-5088k=33280k,经历的时间是0.446-0.291=0.155,分配速率为33.280m/0.155s=33280m/155s=214.7m/s
第三次GC:
生成的对象量是71680k-5120k=66560k,经历的时间是0.829-0.446=0.383,分配速率为66.560m/0.383s=66560m/383s=173.7m/s
三次GC总共产生的对象量是33280K+33280K+66560k=133120k,总时间是0.829s,平均分配速率是133.120m/0.829s=133120m/829s=160.5m/s
当分配速率过高,就会导致young GC次数增多,进而造成stw时长增加,进而会降低系统的吞吐量。
1.2:提升速率
先看一个概念,提升过早,提升过早是指对象过早的从年轻代被提升到老年代,如果提升过早严重则就会导致频繁的major GC,major GC并不是为了频发回收而设计的,其更多的是一种兜底的方案,而衡量是否过早提升的的治疗就是提升速度,计算提升速度类似于分配速度,都可以通过gc日志的对象量以及时长信息反推出来,如下图:
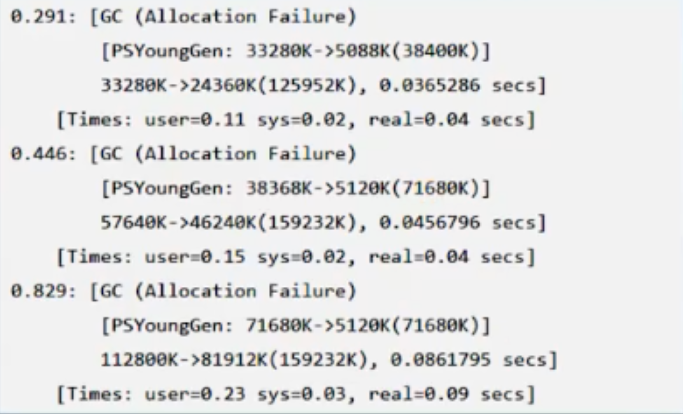
第一次GC:
年轻代减少了33280k-5088k=28192k,整个堆内存减少了33280k-24360k=8920k,因此晋升到老年代的对象大小是28192k-8920k=19272k,平均提升速率19272m/291m=66m/s
第二次GC:
年轻代减少了38368k-5120k=33248k,整个堆内存减少了57640k-46240k=11400k,因此晋升到老年代的对象大小是33248k-11400k=21848k,平均提升速率是21848m/(446-291)s=21848m/155s=140.9m/s
第三次GC:
年轻代减少了71680k-5120k=66560k,整个堆内存减少了112800k-81912k=30888k,因此晋升到老年代的对象大小是66560k-30888k=35672k,平均提升速率是35672m/(829s-446s)=35672m/383s=93.1m/s
三次GC晋升的对象总量是19272k+21848k+35672k=76792k,总的提升速率是76792m/829s=92.63m/s
1.3:调优实战
1.3.1:young GC时间长
现象是GC stw时长特别长,400多毫秒,长的达到了540多毫秒,怀疑是发生了full GC,但通过查看GC日志,并没有,因此确定是因为发生了young GC,因为当时使用的是jdk8,配置参数如下:
-Xmx4g -Xms4g
而jdk8默认的GC策略 是并行GC,并行GC是一种吞吐量优先的GC算法,所以我们就怀疑是垃圾收集器为了维持吞吐量而牺牲掉了stw时长,而G1在jdk8已经成熟,所以就考虑使用G1垃圾收集器,修改为G1后配置参数为:
-Xmx4g -Xms4g -XX:+UseG1GC -XX:MaxGCPauseMillis=50
接着重启服务,运行观察,表现优秀,GC时长基本上维持在50ms以下,但程序运行了一天多之后,突然出现了一次超长时间的GC stw,时间达到了1.2s,相当残暴,有些不知所措,没有什么好办法,就是上网各种查G1的坑,也都没解决,那就看日志吧,修改参数如下打印GC日志:
-Xmx4g -Xms4g -XX:+UseG1GC -XX:MaxGCPauseMillis=50 -XX:+PrintGCDetails -XX:+PrintGCStamps -Xloggc:/var/log/gc.log
,终于在日志中找到了如下的可疑信息:
[Parallel Time: 1861.0 ms, GC Workers: 48]
提示GC线程48个,这就奇怪了,因为我们的机器是4核的,GC线程怎么可能会这么高,虽然不知道为什么这么高,但严重怀疑这就是导致GC STW时长超长的真凶了,这么多的线程争抢4核势必造成非常严重的资源争抢,导致频繁上线文切换,所以先增加如下参数,限制GC线程数:
-XX:ParallelGCThreads=4
再重启,观察,问题解决,但为什么GC线程数会是48,之后经过和运维工程师的沟通,发现,是因为应用部署在k8s的环境中,k8s限制了pod只能使用4g的内存,只能使用4核cpu,但是物理机是72核的,而G1启动的工作线程数量的策略是这样的:
1:当核数小于等于8时,取核数
2:当核数大于8是,取(核数*(5/8)+3)
所以我们这里就是(72*(5/8)+3)=48,所以根本原因是JVM看到了物理机的72核,所以本质上,造成问题的原因是k8s的资源隔离不彻底,只是限制了pod使用4核,但是却让pod中的jvm看到了72核(其实是不应该看到的))。
1.3.2:young GC过于频繁
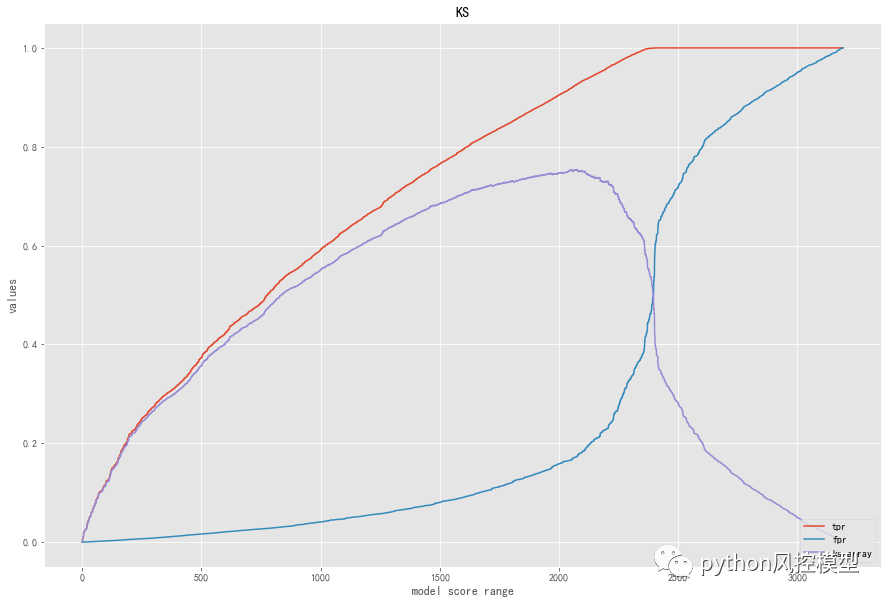
现象是这样子的,young GC很频繁,每秒1次,有时候每秒2次,每次GC 60ms 左右,不算长,通过jstat -gcutil ${pid} 1000 1000每秒打印1次,打印1000次,如下图:
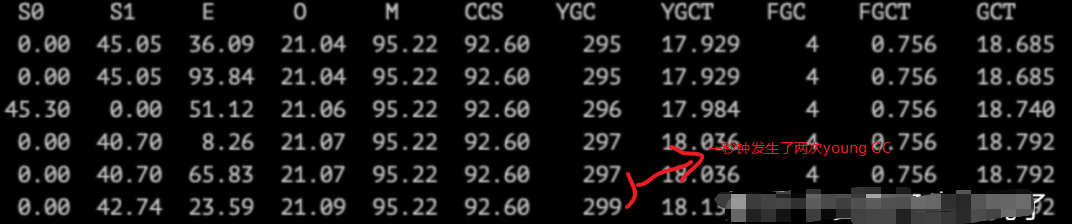
为了进一步的印证young GC 过于频繁,我们将GC日志上传到gceasy.io , 发现其吞吐量只有93%。线上当前的配置如下:
-Xmx8g -Xms8g -Xmn2g -XX:+UseConcMarkSweepGC
很明显,young GC发生频繁,而且几乎没有full GC,所以是不存在内存泄漏问题,问题的原因是young区的内存大小太小了,所以就需要调大-Xmn,即增加年轻代的大小,以将young GC每4秒钟到5秒钟发生一次,作为优化目标来调整该参数,最终调整参数为-Xmn2.9g,但又发现gc 时长增加到了80ms左右,虽然时间也可以接受,但还是继续尝试优化这个时间,jvm使用的GC是CMS,而cms在年轻代使用的垃圾收集器是ParNew,ParNew采用的垃圾收集算法是复制算法,所以我们就希望能够减少在s0,s1之间复制对象的量来降低young gc的时间,想要实现这个效果,就需要调整参数-XX:MaxTenturingThreshold={age},这里age的默认值15,即15次young gc之后才会被提升到老年代,降低这个参数值,可以让对象提早提升到老年代就可以实现我们的目标了,但如何确定合适的年龄也是个问题,太小了,可能会导致会导致full GC,为了确定这个年轻,增加了参数-XX:PrintTenuringDistribution,配置如下:
-Xmx8g -Xms8g -Xmn2.9g -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:d:\\test\\gc1423.log -XX:+PrintTenuringDistribution -Dfile.encoding=UTF-8
打印出不同分代对象的个数和大小信息,如下图(来自gceasy.io 分析结果):
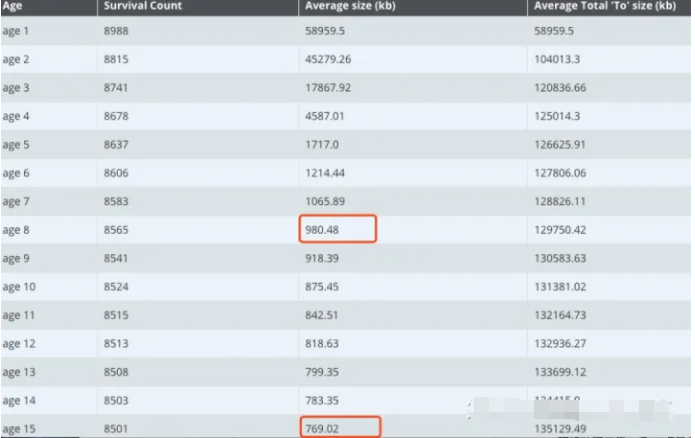
可以看到存活区15岁的对象个数是8501,8岁的对象个数是8565,比例为8501/8565=99.2%,可以看到只要存活区到8岁的对象,存活到15岁的比例达到了99.2%,也就是达到8岁的对象就可以直接让其晋升到老年代了,因此调整参数-XX:MaxTenturingThreshold=7,这样就节省了8次大量存活对象从一个survivor区复制到另一个survivor区的成本,优化后,gc时间维持在了71ms左右,吞吐量也提高到了97%左右。
写在后面
参考文章列表
SuperBenchmarker(简称“sb“)压力测试工具详解 。
JVM工具之Arthas使用 .
一次线上JVM Young GC调优,搞懂了这么多东西! 。
线上问题排查思路