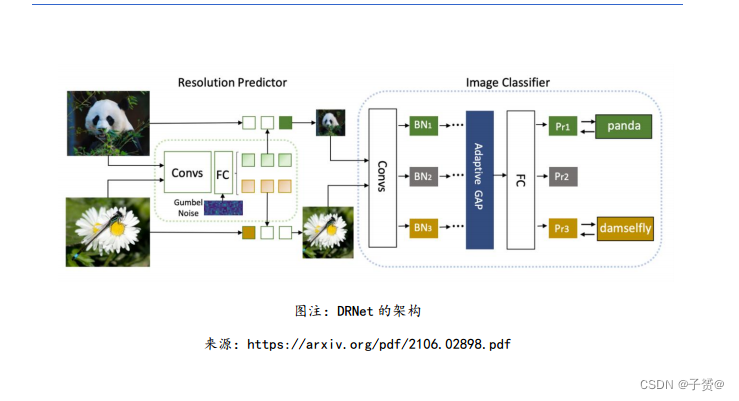
华为诺亚实验室等研究者提出动态分辨率网络 DRNet
深度卷积神经网络通畅采用精细的设计,有着大量的可学习参数,在视觉任务上实现很高精
确度要求。为了降低将网络部署在移动端成本较高的问题,近来发掘在预定义架构上的冗余
已经取得了巨大的成果,但对于 CNN 输入图像清晰度的冗余问题还没有被完全研究过,即当
前输入图像的清晰度都是固定的。10 月,华为诺亚实验室、中国科学院大学等机构研究者提
出一种新型的视觉神经网络 DRNet(Dynamic Resolution Network)。基于每个输入样本,
该网络可以动态地决定输入图像的清晰度。该网络中设置了一个清晰度预测器,其计算成本
几乎可以忽略,能够和整个网络共同进行优化。该预测器可以对图像学到其需要的最小清晰
度,甚至能够实现超过过去识别准确率的性能。实验结果显示,DRNet 可以嵌入到任何成熟
的网络架构中,实现显著的计算复杂度降低。例如,DR-ResNet-50 在实现同样性能表现的
前提下可以降低 34%的计算,相比 ResNet-50 在 ImageNet 上提升 1.4 个点的性能同时能够
降低 10%的计算。
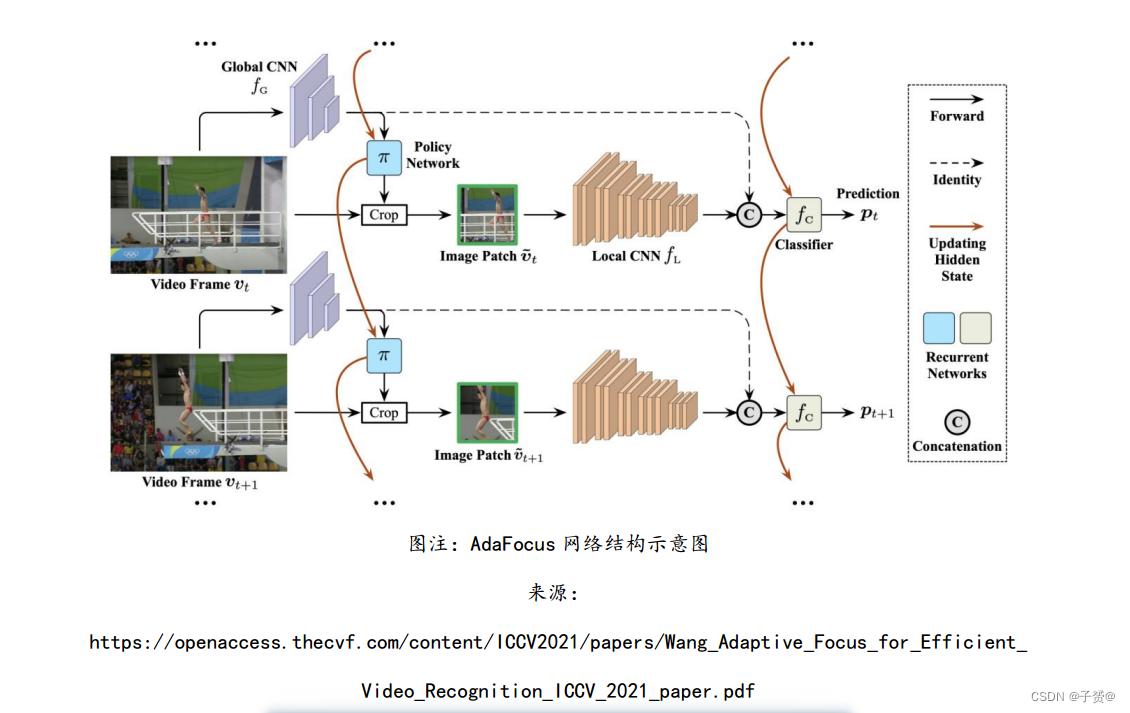
智源、清华研究者提出时空自适应动态神经网络 AdaFocus
10 月,来自北京智源人工智能研究院和清华大学的研究者提出高效视频分析框架 AdaFocus。
该方法突破了传统深度神经网络的静态推理范式,实现了在时间、空间两个维度自适应定位
与目标任务相关性最强的视频帧和关键区域,有效降低了基于深度视频分析方法的计算冗余
性。在 Sth-Sth V2、ActivityNet 等主流视频处理数据集上,AdaFocus 可将模型总体推理AI Frontiers Report 科研发展情况效率相较现有方法提高 2-3 倍。该方法在边缘计算、视频监控、视频推荐等场景有较大的应用前景,也为设计低延迟、低能耗的深度学习基础模型提供了启发性的思路。
https://openaccess.thecvf.com/content/ICCV2021/papers/Wang_Adaptive_Focus_for_Efficient_ Video_Recognition_ICCV_2021_paper.pdf
谷歌研究者提出多任务训练策略 TAG
多任务学习能够让模型通过在一个任务上学习信息,提升在其他任务上训练的性能。然而,
简单地让模型在所有任务上一块训练可能导致模型性能的下降,且完全搜索所有的任务组合
的成本很高。因此,高效地找到对于训练有提升的任务是一个重要的研究问题。10 月,谷歌
的研究者提出了名为 TAG(Task Affinity Groupings)的多任务训练策略,能够通过一次
运行训练所有任务,并量化单个任务的梯度对于其他任务损失的影响。通过在视觉任务上的
实验,研究者发现这一方法相比单纯同时训练所有任务降低了 10%的测试损失,并且比当前
最佳的任务分组策略快 11.6 倍。

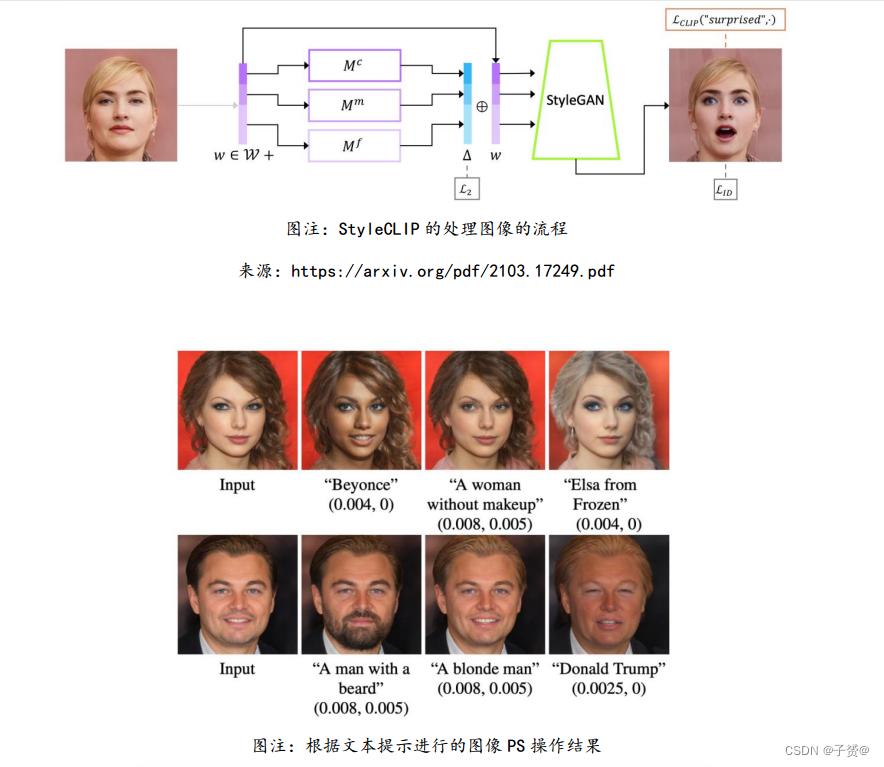
以色列希伯来大学等提出文生高清图模型 StyleCLIP
3 月,以色列希伯来大学、Adobe 研究院等将 StyleGAN 和 CLIP 模型结合,提出了一种能
够根据文本提示生成高清晰度图像的模型,名为 StyleCLIP。研究者认为,StyleCLIP 能够
结合预训练模型学习到的语义知识,加上生成对抗网络的图像生成能力,能够创造出更逼真
的图像,在实际应用中有一定的优势。
智源、清华等研究者提出文生图模型 CogView
5 月,智源研究院、清华大学、阿里达摩院的研究者发布了 CogView 文生图模型论文,其将
VQ-VAE 和 40 亿参数的 Transformer 模型结合,通过在风格学习、超高清图像生成、文- 图排序和时尚设计等多个下游任务上进行微调,并采用了消除 NaN 损失等稳定预训练的方法。
实验结果显示,CogView 在模糊化后的 MS COCO dataset 数据集上取得了最高的 FID 结果,
高于以往的 GAN 和 DALL·E。

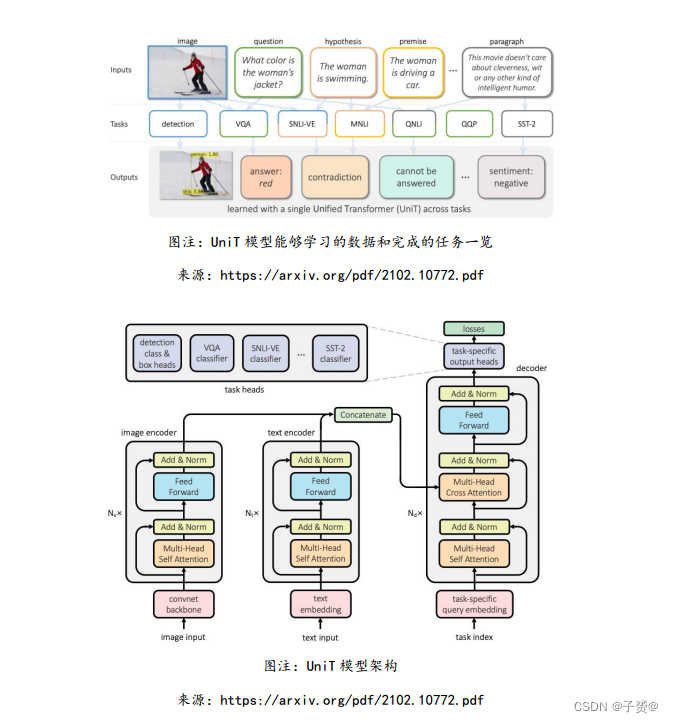
Facebook 研究者提出多任务多模态统一模型 UniT
8 月,Facebook 研究团队提出了名为 UniT 的多任务多模态统一 Transformer 模型,其基
于统一的 Transformer Encoder-Decoder 架构,能够同时解决视觉、多模态、语言等领域
中的一系列任务,包括目标检测、视觉-文本推理、自然语言理解等。论文表示,该模型在 7
个任务上都有较强的性能。
清华等研究者提出跨模态提示学习模型 CPT
9 月,清华和新加坡国立大学的研究者提出了跨模态提示学习模型 CPT,其利用颜色对跨模
态预训练模型进行基于提示学习的微调,在视觉定位、场景图生成任务的少次学习场景下较
基线模型取得显著提升。

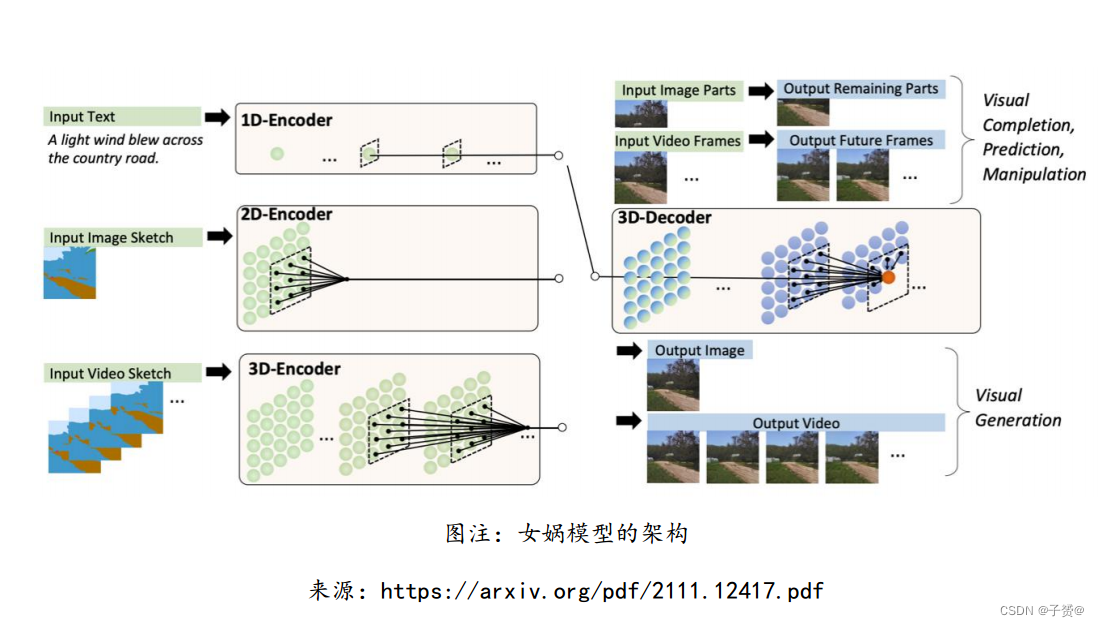
微软亚洲研究院、北大研究者提出涵盖三种模态数据的预训练模型 NÜWA(女娲)
11 月,微软亚洲研究院、北大研究者提出统一多模态预训练模型 NÜWA。该模型采用 3D
Transformer 架构,能够生成视觉(图像或视频)信息。通过将该模型在 8 个下游任务上进
行试验,女娲模型在文生图、文生视频、视频预测等任务上实现最佳性能。