文章目录
- 一、项目简介
- 二、算法原理
- 2.1、每个体素都有两个值:TSDF值(用于生成重建表面)、RGB灰度值(给重建表面贴上彩色纹理)
- 2.2、TSDF算法
- 步骤一:体素体建立
- 步骤二:划分网格(体素化)
- 步骤三:迭代更新:TSDF值 + 权重值
- 步骤四:找等值面
- 三、项目说明
- 3.1、源码下载(Github)
- 3.2、数据集说明
- 3.3、文件说明
- 四、环境配置 + 工具安装
- 4.0、ImportError: DLL load failed while importing _arpack: 找不到指定的程序。
- 4.1、环境配置
- 4.1.1、Anaconda + Pycharm + OpenCV
- 4.1.2、安装pycuda
- 4.1.3、安装numba
- 4.1.4、安装scikit-image(运行成功)
- 4.2、MeshLab安装(查看三维模型mesh.ply)
- 五、代码详解
- 5.1、demo.py:主函数文件
- 5.2、fusion.py:预定义文件

一、项目简介
主要流程:计算每个体素在深度图像中的TSDF值,然后基于前一个体素的TSDF值更新后一个(加权平均),最后得到所有体素的结果,拼接为3D模型。
TSDF需要非常大的显存空间,GPU需要大概
2KB存储单个体素的所有信息。因此,只适用于小场景下的三维重建(如室内环境)。
(1)项目中指定x与y大小为:[3, 2],单位米(m)
(2)项目中指定体素大小为:0.02,单位为米(m)
(3)总内存:(3 x 2 x 1) / (0.02 x 0.02 x0.02) * 2KB = (750000)*2KB = 1464.844MB =1.43GB
备注:1 KB = 1024 B(字节)、1 MB = 1024 KB 、1 GB = 1024 MB、1 TB = 1024 GB
支持GPU和CPU
- 在
Fusion.py文件的TSDFVolume类中,通过参数use_gpu=False选择是否使用GPU,两者速度相差极大。如果为False,既选择CPU;若为True,则需要安装CUDA和PyCUDA。- 把TSDF地图从CPU存储中移动到GPU中需要两步:(1)调用
cuda.mem_alloc在GPU中提前开辟一块内存空间;(2)调用cuda.memcpy_htod用开辟的内存空间存储TSDF地图数据。
备注:htod表示host to device,即从CPU存数据到GPU。如果是反过来的话,就使用cuda.memcpy_dtoh。- 最终输出结果为
mesh.ply文件,想要打开该文件的工具有很多。此处会介绍其中的MeshLab软件。
二、算法原理
2.1、每个体素都有两个值:TSDF值(用于生成重建表面)、RGB灰度值(给重建表面贴上彩色纹理)
像素(pixel)是2D图像的最小单位,而体素(voxel)是3D立方体的最小单位,体素体由一个个小立方体组成的3D模型。
每个体素都有两个值:
TSDF值(用于生成重建表面)、RGB灰度值(给重建表面贴上彩色纹理)
备注:在三维重建的初始化阶段,长方体内所有体素的TSDF值被填充为1,而RGB值被填充为0。
其中:TSDF的取值范围为
[-1, 1],其表示体素与最近的物体表面的距离。
- 1:表示体素x 位于相机与物体表面之间。
- -1:表示体素位于物体表面之后。
- 趋近于0:即认为体素在物体表面。
2.2、TSDF算法
基于截断(T)的带符号距离函数(Truncated Signed Distance Function,TSDF)
- 是一种常见的计算等势面(物体表面)的3D重建方法。
- SDF于2003年由Sosher提出,而
TSDF在SDF的基础上提出截断距离(T)。
举例:若体素的SDF值大于30,赋值30;若小于15的部分,赋值15。最终,所有体素得到的SDF值都在[15, 30]范围内,即截断。
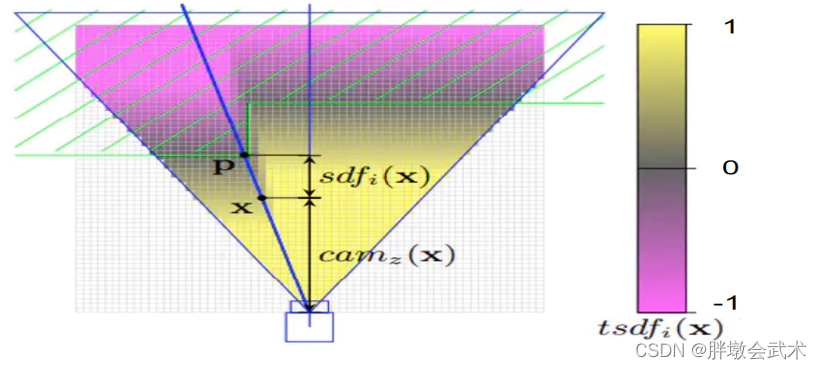
一个体素的SDF值,表示它到最近的物体表面的距离。T表示截断,将太近或太远的SDF值设定为恒定值。
- 白色的小方格:表示TSDF地图中的体素。
- 蓝色的三角形:表示相机的视场范围。
- 绿色截线:表示物体的横截面。
- 绿色虚线:物体截面的深度信息。
- 深蓝色直线:沿着相机的光心与体素X做一条直线,该直线与物体的截面有一个交点P。该交点是平面上离体素X最近的点。小白科研笔记:从零学习基于TSDF的三维重建
步骤一:体素体建立
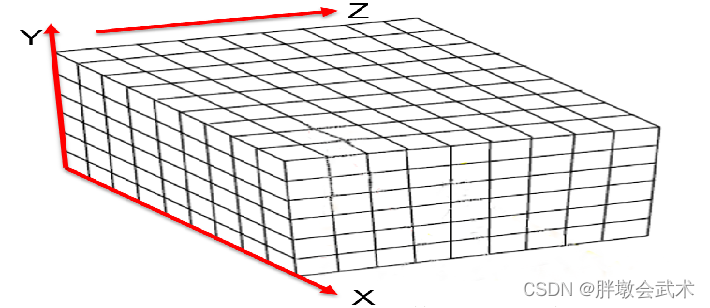
根据实拍环境以及待重建点云分布情况,构建一个足够大的长方体,使得所有3D图像的三维点都在X Y Z = [L x W x H]长方体中(能够完全包围要重建的物体)。项目中指定x与y大小为:[3, 2],单位米(m)
假设
z方向为相机的拍摄位置, 则x与y方向上的极值就是图像的边界。
- (1)四条边界得到四个交汇点(边界点):
(0, 0), (W, 0), (0, H), (W, H)- (2)z 方向上深度范围:
0 ~ L- 最终得到长方体的八个顶点(边界点):
(0, 0, 0)、(W, 0, 0)、(W, H, 0)、(0, H, 0)、(0, 0, L)、(W, 0, L)、(W, H, L)、(0, H, L)。
步骤二:划分网格(体素化)
将长方体的内部空间划分成一个个小立方体(体素),用户可自定义体素大小。其中:体素越小,最终搭建模型的体素个数越多,建模精度越高,但运行速度越慢。项目中指定体素大小为:0.02,单位为米(m)
举例理解:在
[-1, 1]范围内,指定体素大小为0.02m,则可以划分出50个体素。最终,每个体素的8个顶点坐标可以通过世界坐标(-1+0.02x, -1+0.02y, -1+0.02*z)计算得到。
步骤三:迭代更新:TSDF值 + 权重值
投影世界坐标系下的体素体,通过逆变换到相机坐标系,再投影到图像坐标系。
- (1)计算当前帧图像的TSDF值及权重。此时需要遍历所有的体素:计算每个体素TSDF值 + 截断每个体素的TSDF值 + 更新每个体素的TSDF值 + 计算每个体素的权值。
- (2)当前帧图像与全局融合结果进行融合。
备注:若当前帧为第一帧,则第一帧就是融合结果,否则需要当前帧与之前的融合结果进行融合。
(1)举例推导:以任意一个体素在世界坐标系的
三维坐标点p为例。世界坐标即最终生成的3D模型(体素体),由世界坐标 -> 相机坐标 -> 像素坐标
- 坐标变换。由深度图像的相机位姿矩阵,求世界坐标系下点P在相机坐标系下的
映射点v;并由相机内参矩阵及反映射V点求深度图像中的对应像素点x。- 计算坐标点p的tsdf值。
- 此时坐标点p的sdf值:
sdf( p ) = value( x ) - distance( v )。其中:像素点x的深度值为value( x )、点v到相机坐标原点距离为distance( v )。- 然后
引入截断距离计算tsdf( p )。
判断1:在截断距离 U = [-1, 1] 以内:tsdf( p ) = sdf( p ) / | U |;
判断2:如果sdf( p ) > 0,tsdf( p ) = 1;
判断3:若果sdf( p ) < 0,tsdf( p ) = -1;- 计算坐标点p的权重:w( p ) = cos(θ) / distance( v )。其中,θ为投影光线与表面法向量的夹角。
- 然后就是每添加一帧深度图像,执行以上步骤。最终将输出结果给Marching Cube计算物体表面。TSDF算法学习
(2)通过当前帧tsdf( p ) 更新 融合后的TSDF值。
备注1:即多帧图像有很多重叠部分,需要对多个重叠部分进行融合。即分别计算多帧图像上对应该体素的TSDF值以及权重,最终取加权平均值。
备注2:该更新模式采用的是增量式更新。即第二帧结果与第一帧进行加权平均,第三帧与第二帧进行加权平均,以此类推。
备注3:实时更新3D模型,即每计算一帧更新一次结果,而不是等所有深度图都计算完一起出结果。
公式如下:TSDF算法原理及源码解析
其中:
TSDF( p )表示体素 p 融合后的TSDF值;
W( p )表示体素 p 融合后的权重值;
tsdf( p )表示体素 p 当前帧的TSDF值;
w( p )表示体素 p 当前帧的权重值;
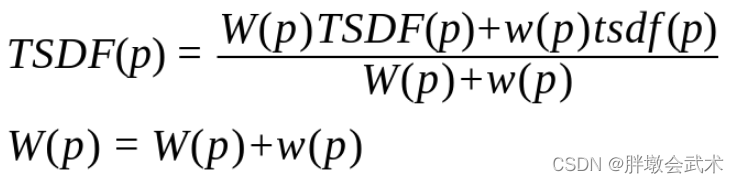
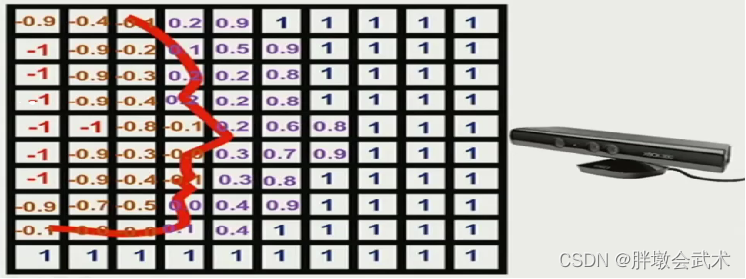
步骤四:找等值面
用marching cubes算法在TSDF网格中寻找dist加权和为0的等值面,即物体表面。
- 加粗红色曲线:物体表面(人脸)
- 物体内部
- 橙色数字:负值。且离物体表面越远,数值越大。
- 红色数字:负值。截断。
- 物体外部
- 紫色数字:正值。且离物体表面越远,数值越大。
- 暗蓝数字:正值。截断。
三、项目说明
3.1、源码下载(Github)
Github官网下载:https://github.com/andyzeng/tsdf-fusion-python
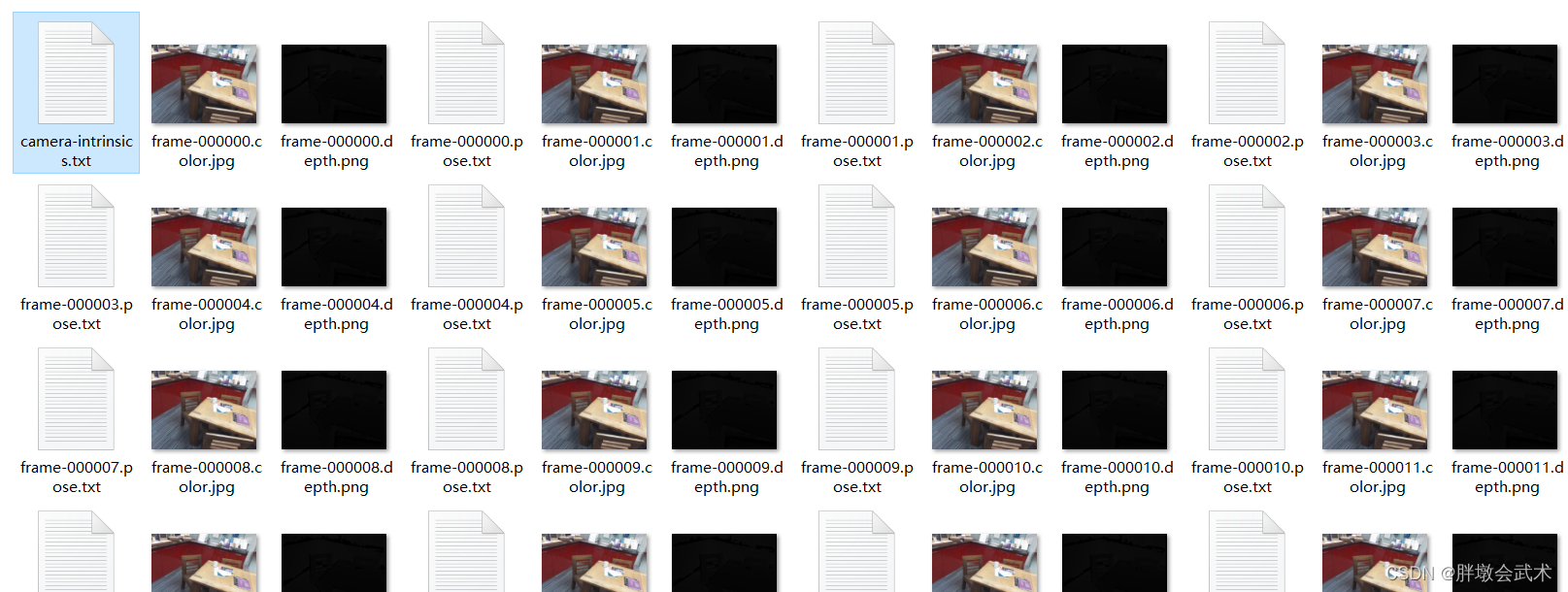
3.2、数据集说明
数据集来源于RGB-D Dataset 7-Scenes,即将7个场景数据集中的1000张RGB深度图像,融合为2cm分辨率的TSDF体素体(3D表面网格和点云)。
| 数据集(data)参数 | 说明 | 数据格式 | 举例 |
|---|---|---|---|
| 相机内参 | 相机的内部参数(硬件) | txt矩阵格式 | camera-intrinsics.txt |
| RGB图像 | 一个场景多个视角拍摄的图像 | frame-000000.color.jpg | |
| 深度图 | 表示物体远近程度的图像 | frame-000000.depth.png | |
| 相机位姿 | 由于图像是多视角的,故每个视角的相机位姿也不同 | txt矩阵格式 | frame-000000.pose.txt |
备注1:只有一个相机内参文件,而1000张图像的每个数据都对应有一个RGB图像、深度图、相机位姿。
备注2:相机内参和相机位姿主要用于坐标系转换。
备注3:深度图可通过高级相机获取、或通过RGB图像进行深度估计获取。
3.3、文件说明
整个项目分三个部分:两个文件夹、两个(.py)文件、两个(.ply)文件。
文件夹
data:存放数据集
images:存放一张3D重建过程图(fusion-movie.gif)
文件
demo.py:主函数文件
fusion.py:预定义文件
README.md:官网的项目简介
生成的结果文件
mesh.ply:是一种多边形网格文件格式。
- 包含了多个三角形或四边形面片,每个面片由若干个顶点组成。还可能包含每个顶点的颜色、法线、纹理坐标等信息。
- 常用于计算机图形学、三维建模和可视化等领域。
pc.ply:是一种点云文件格式。
- 只包含了若干个点的坐标信息,每个点可能还有其他的属性(如:颜色、法线、强度等)。
- 常用于三维扫描、激光雷达、遥感、医学图像等领域。点云数据可以用于建立三维模型、分析形状和结构、检测缺陷和异常等。
相同点:都是描述三维场景或物体的点云文件格式。
区别点:mesh.ply更注重表面的细节和形状,而pc.ply更注重点的位置和属性。
四、环境配置 + 工具安装
4.0、ImportError: DLL load failed while importing _arpack: 找不到指定的程序。
原因分析:缺少依赖项、scipy包存在缺失、没有正确配置环境变量、python版本不兼容。
(1)安装依赖项(NumPy和SciPy)。
(2)scipy包存在缺失。卸载pip uninstall scipy、安装最新版本pip install scipy。备注:尝试安装了低版本scipy,仍有问题。
(2)检查环境变量。特别是,确保PATH环境变量包含了Python和相关依赖项的安装路径。
(3)升级Python版本。有时候在较旧的版本中可能会出现一些兼容性问题。
以上四个原因是在查阅资料时总结得到,博主的问题最后定位到是由于 " scipy包存在缺失 " 的原因,通过上述方法可解决,
4.1、环境配置
该项目基于Numpy + opencv + pycuda + numba + skimage即可完成。
4.1.1、Anaconda + Pycharm + OpenCV
【深度学习环境配置】Anaconda + Pycharm + CUDA +cuDNN + Pytorch + Opencv(资源已上传)
4.1.2、安装pycuda
安装pycuda:
pip install pycuda。通常会安装失败,可以使用pycuda.whl下载地址轮子安装。详细教程如下:【GPU加速】安装pycuda异常:Failed to build pycuda ERROR: Could not build wheels for pycuda
4.1.3、安装numba
BUG提示:ImportError:Numba needs NumPy 1.22 or less
安装numba:pip install numba。该方法会自动检测numba版本,若numpy版本与之不对应,将自动卸载当前numpy然后重新安装对应版本。切记:不可删除llvmlite文件夹,否则项目运行时会提示没有该模块。ERROR: Cannot uninstall ‘llvmlite’. It is a distutils installed project.
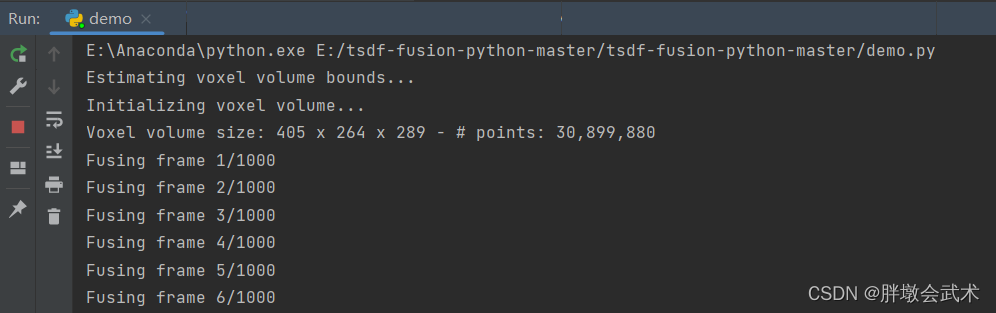
4.1.4、安装scikit-image(运行成功)
步骤一:上述几个环境都配置好之后,可以正常运行,如下图:
- (1)在Fusion.py文件的TSDFVolume类中,通过参数use_gpu=False选择是否使用GPU
- (2)在Demo.py文件中,点击Run运行。
步骤二:在生成结果文件时,出现以下异常:
BUG提示:AttributeError: module ‘skimage.measure’ has no attribute ‘marching_cubes_lewiner’
报错原因:是由于scikit-image(skimage)简介版本的问题导致的。在旧版本的scikit-image中,marching_cubes_lewiner函数是在skimage.measure模块中定义的,但在新版本中,它已经被移动到了一个单独的模块中。
解决方法:
- 若是旧版本的scikit-image,可以尝试升级版本来解决这个问题。
- 11、
pip list查看已安装的scikit-image版本号为0.19.2。- 22、
pip uninstall scikit-image卸载。- 33、安装scikit-image:
pip install scikit-image。默认安装最新版本。上述BUG提示的链接中提到的方法是将0.19.2版本(python3.9)换成0.16.2版本(python3.8)就能解决问题,故需要通过scikit-image.whl下载地址安装。但是该方法需要同时切换python版本,由于本人使用的是python3.9,但是在官网中没有找到对应的scikit-image版本,尝试了一些版本但未成功。- 若是新版本的scikit-image,则可能是导入时使用了错误的名称。可通过以下代码使用:marching_cubes_lewiner:
from skimage import measure
verts, faces, _, _ = measure.marching_cubes_lewiner(volume, level)最终基于新版本的scikit-image,项目运行成功,并生成mesh.ply + pc.ply文件。
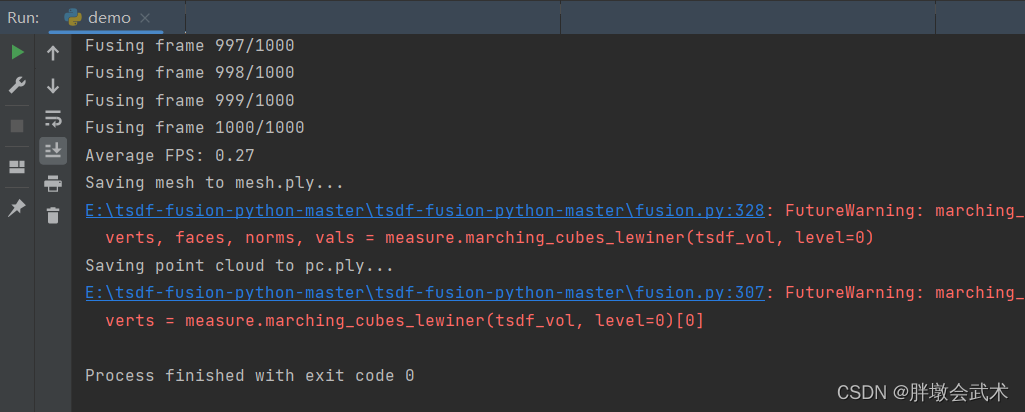
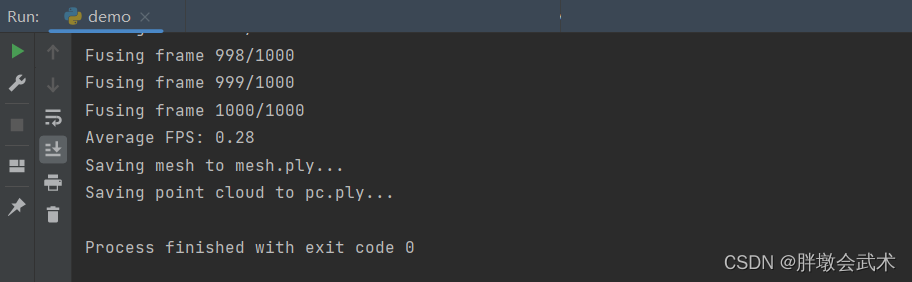
步骤三:前两个步骤已经可以正常生成结果文件,但是系统有两个警告,虽然不影响使用,但只需要将measure.marching_cubes_lewiner 更换为 measure.marching_cubes即可消除该问题。项目运行成功,并生成mesh.ply + pc.ply文件。
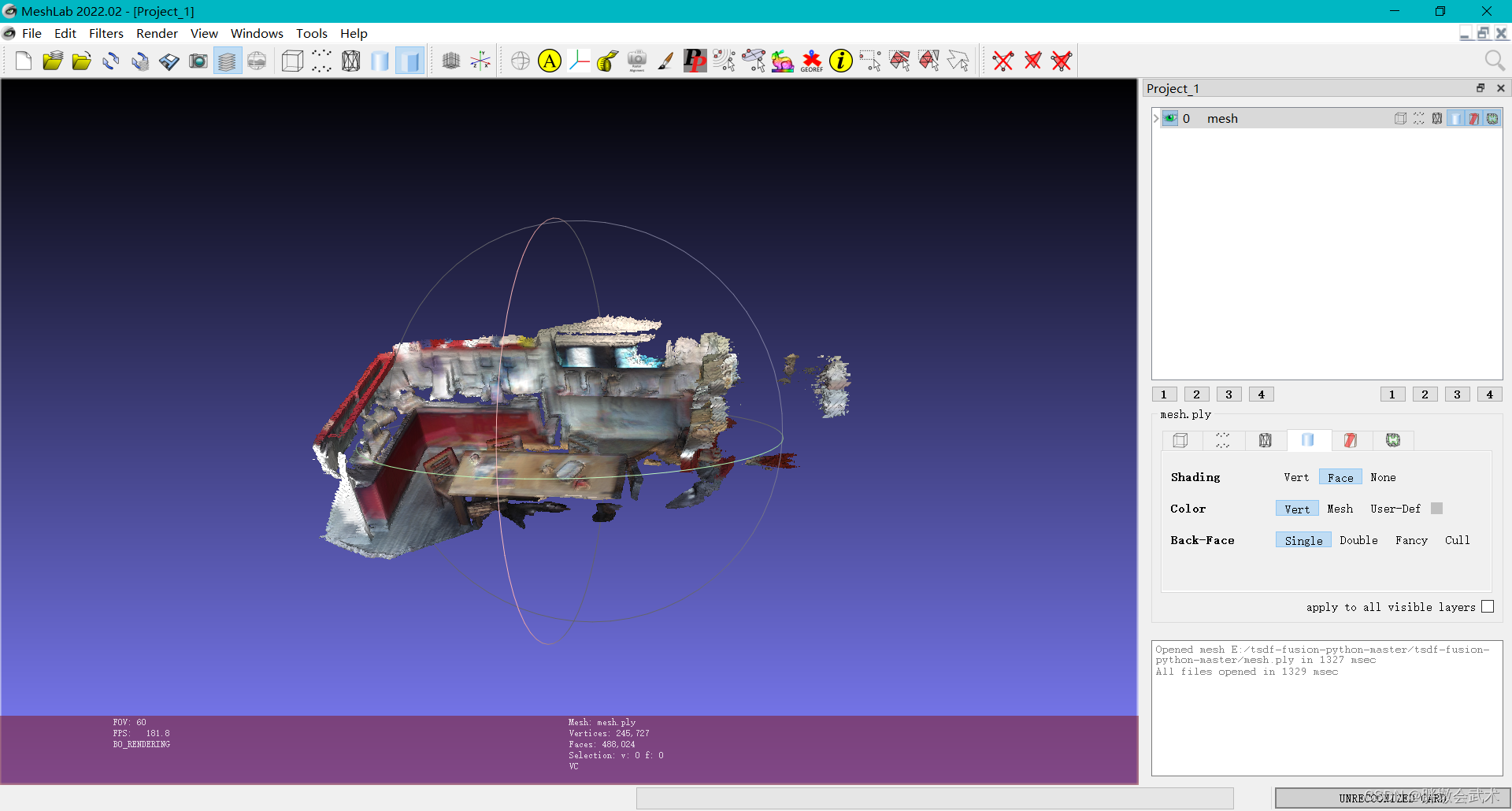
4.2、MeshLab安装(查看三维模型mesh.ply)
三维几何处理系统(MeshLab):简介 + 安装 + 使用教程
- MeshLab是开源的3D三角网格编辑与处理系统,可以对3D网格进行全面的编辑与处理,包括编辑,清理,修复,检查,渲染,纹理和转换网格等。
- 另外,它还具备了处理由3D数字化工具 / 设备生成的原始数据,并提供3D模型打印功能,从而能够为用户实现工业化的模型创建。
- MeshLab官网下载地址:默认最新版本(支持多种平台)
- Github官网下载地址:累计发布版本(支持多种平台)
五、代码详解
TSDF算法原理、推导过程、源码解析: def __ init __()、def integrate()、def get_mesh(self)
注:只分析CPU版本源码,可以深入理解TSDF原理。而GPU版本主要内容:体素是如何通过多线程去索引并提取。
5.1、demo.py:主函数文件
"""
Fuse 1000 RGB-D images from the 7-scenes dataset into a TSDF voxel volume with 2cm resolution.
"""
import time
import cv2
import numpy as np
import fusion
if __name__ == "__main__":
# ======================================================================================================== #
# (1)估计体素体边界
# ======================================================================================================== #
print("Estimating voxel volume bounds...")
n_imgs = 1000 # 1.1、指定数据集中的RGB图像总个数
cam_intr = np.loadtxt("data/camera-intrinsics.txt", delimiter=' ') # 1.2、读取相机内参
vol_bnds = np.zeros((3, 2)) # 1.3、以米为单位指定xyz边界(min/max)。
for i in range(n_imgs):
depth_im = cv2.imread("data/frame-%06d.depth.png" % i, -1).astype(float) # 1.4、读取深度图像
depth_im /= 1000. # 单位为毫米。图像深度(depth)保存为16位PNG格式。
depth_im[depth_im == 65.535] = 0 # 将无效的图像深度设置为0(特定于7场景数据集)
cam_pose = np.loadtxt("data/frame-%06d.pose.txt" % i) # 1.5、读取相机位姿: 4x4刚性变换矩阵
view_frust_pts = fusion.get_view_frustum(depth_im, cam_intr, cam_pose) # 1.6、计算相机的视锥体和扩展凸包
vol_bnds[:, 0] = np.minimum(vol_bnds[:, 0], np.amin(view_frust_pts, axis=1))
vol_bnds[:, 1] = np.maximum(vol_bnds[:, 1], np.amax(view_frust_pts, axis=1))
# 视锥体是摄像机可见的空间,看上去像截掉顶部的金字塔。
# ======================================================================================================== #
# (2)RGB-D图像的TSDF体积融合
# ======================================================================================================== #
print("Initializing voxel volume...")
########## 函数: fusion.TSDFVolume ##########
tsdf_vol = fusion.TSDFVolume(vol_bnds, voxel_size=0.02) # 初始化体素大小=0.02m(即2cm)
# ======================================================================================================== #
# (3)循环RGB-D图像更新每个体素的TSDF值,并将它们融合在一起。
# ======================================================================================================== #
t0_elapse = time.time()
for i in range(n_imgs):
print("Fusing frame %d/%d" % (i+1, n_imgs))
color_image = cv2.cvtColor(cv2.imread("data/frame-%06d.color.jpg" % i), cv2.COLOR_BGR2RGB) # 读取彩色图像
depth_im = cv2.imread("data/frame-%06d.depth.png" % i, -1).astype(float) # 读取深度图像
depth_im /= 1000.
depth_im[depth_im == 65.535] = 0
cam_pose = np.loadtxt("data/frame-%06d.pose.txt" % i) # 读取相机位姿
########## 函数: fusion.integrate ##########
tsdf_vol.integrate(color_image, depth_im, cam_intr, cam_pose, obs_weight=1.) # 将观测结果整合到体素体中(假设颜色与深度对齐)
# ======================================================================================================== #
# (4)打印FPS,并输出.ply文件
# ======================================================================================================== #
# 4.1、打印平均FPS:(表示画面每秒传输帧数)
fps = n_imgs / (time.time() - t0_elapse)
print("Average FPS: {:.2f}".format(fps))
# 4.2、从体素体中获取3D网格,并保存为多边形.ply文件到磁盘(可以使用Meshlab查看)
print("Saving mesh to mesh.ply...")
verts, faces, norms, colors = tsdf_vol.get_mesh() # 使用marching cubes体素级重建方法计算网格
########## 函数: fusion.meshwrite ##########
fusion.meshwrite("mesh.ply", verts, faces, norms, colors)
# 4.3、从体素体积中获取点云,并保存为多边形.ply文件到磁盘(可以使用Meshlab查看)
print("Saving point cloud to pc.ply...")
point_cloud = tsdf_vol.get_point_cloud() # 从体素体中提取点云
########## 函数: fusion.pcwrite ##########
fusion.pcwrite("pc.ply", point_cloud)
5.2、fusion.py:预定义文件
# Copyright (c) 2018 Andy Zeng
import numpy as np
from numba import njit, prange
from skimage import measure
# 默认使用GPU,若不使用需更改为: try 0; 否则需要安装pycuda.
try:
import pycuda.driver as cuda
import pycuda.autoinit
from pycuda.compiler import SourceModule
FUSION_GPU_MODE = 1
except Exception as err:
print('Warning: {}'.format(err))
print('Failed to import PyCUDA. Running fusion in CPU mode.')
FUSION_GPU_MODE = 0
class TSDFVolume:
"""
Volumetric TSDF Fusion of RGB-D Images.(RGB-D图像的TSDF体积融合)
"""
def __init__(self, vol_bnds, voxel_size, use_gpu=False):
"""构造函数
Args:
vol_bnds (ndarray): 以米为单位指定XYZ边界(min/max)。形状为(3,2)的数组(固定值)。
voxel_size (float): 以米为单位的体素大小(可自定义)。备注:体素越小,最终构成模型的体素个数越多,但运行速度越慢。
use_gpu=False: 是否使用GPU。若使用,需安装pycuda.
"""
# (1)将点云分布边界转换成numpy数组
vol_bnds = np.asarray(vol_bnds) # 数据类型转换: array转asarray. 区别在于是否共享内存
assert vol_bnds.shape == (3, 2), "[!] `vol_bnds` should be of shape (3, 2)."
# (2)定义体素体参数
self._vol_bnds = vol_bnds # 体素体xyz边界
self._voxel_size = float(voxel_size) # 体素体每个立方体边长
self._trunc_margin = 5 * self._voxel_size # 截断距离,设置为体素边长的5倍
self._color_const = 256 * 256 # 辅助参数,用于提取rgb值
# (3)调整体积边界以及索引顺序(order='C': 表示最后一个索引变化最快)
self._vol_dim = np.ceil((self._vol_bnds[:, 1]-self._vol_bnds[:, 0])/self._voxel_size).copy(order='C').astype(int)
self._vol_bnds[:, 1] = self._vol_bnds[:, 0]+self._vol_dim*self._voxel_size
self._vol_origin = self._vol_bnds[:, 0].copy(order='C').astype(np.float32)
# (4)打印TSDF地图的尺寸: [L, W, H]
print("Voxel volume size: {} x {} x {} - # points: {:,}" .format(self._vol_dim[0], self._vol_dim[1], self._vol_dim[2],
self._vol_dim[0]*self._vol_dim[1]*self._vol_dim[2]))
# 初始化保存体素体信息的容器
self._tsdf_vol_cpu = np.ones(self._vol_dim).astype(np.float32) # 用于保存每个体素栅格的tsdf值
self._weight_vol_cpu = np.zeros(self._vol_dim).astype(np.float32) # 用于保存每个体素栅格的权重值
self._color_vol_cpu = np.zeros(self._vol_dim).astype(np.float32) # 用于保存每个体素栅格的颜色值(将rgb三个值压缩成一个float32值表示)
self.gpu_mode = use_gpu and FUSION_GPU_MODE
# 将体素体积复制到GPU
if self.gpu_mode:
self._tsdf_vol_gpu = cuda.mem_alloc(self._tsdf_vol_cpu.nbytes)
cuda.memcpy_htod(self._tsdf_vol_gpu, self._tsdf_vol_cpu)
self._weight_vol_gpu = cuda.mem_alloc(self._weight_vol_cpu.nbytes)
cuda.memcpy_htod(self._weight_vol_gpu, self._weight_vol_cpu)
self._color_vol_gpu = cuda.mem_alloc(self._color_vol_cpu.nbytes)
cuda.memcpy_htod(self._color_vol_gpu, self._color_vol_cpu)
# Cuda内核函数(c++) 功能: 在GPU下的体素是如何通过多线程去索引并提取
self._cuda_src_mod = SourceModule("""
__global__ void integrate(float * tsdf_vol,
float * weight_vol,
float * color_vol,
float * vol_dim,
float * vol_origin,
float * cam_intr,
float * cam_pose,
float * other_params,
float * color_im,
float * depth_im) {
// Get voxel index
int gpu_loop_idx = (int) other_params[0];
int max_threads_per_block = blockDim.x;
int block_idx = blockIdx.z*gridDim.y*gridDim.x+blockIdx.y*gridDim.x+blockIdx.x;
int voxel_idx = gpu_loop_idx*gridDim.x*gridDim.y*gridDim.z*max_threads_per_block
+block_idx*max_threads_per_block+threadIdx.x;
int vol_dim_x = (int) vol_dim[0];
int vol_dim_y = (int) vol_dim[1];
int vol_dim_z = (int) vol_dim[2];
if (voxel_idx > vol_dim_x*vol_dim_y*vol_dim_z)
return;
// Get voxel grid coordinates (note: be careful when casting)
float voxel_x = floorf(((float)voxel_idx)/((float)(vol_dim_y*vol_dim_z)));
float voxel_y = floorf(((float)(voxel_idx-((int)voxel_x)*vol_dim_y*vol_dim_z))/((float)vol_dim_z));
float voxel_z = (float)(voxel_idx-((int)voxel_x)*vol_dim_y*vol_dim_z-((int)voxel_y)*vol_dim_z);
// Voxel grid coordinates to world coordinates
float voxel_size = other_params[1];
float pt_x = vol_origin[0]+voxel_x*voxel_size;
float pt_y = vol_origin[1]+voxel_y*voxel_size;
float pt_z = vol_origin[2]+voxel_z*voxel_size;
// World coordinates to camera coordinates
float tmp_pt_x = pt_x-cam_pose[0*4+3];
float tmp_pt_y = pt_y-cam_pose[1*4+3];
float tmp_pt_z = pt_z-cam_pose[2*4+3];
float cam_pt_x = cam_pose[0*4+0]*tmp_pt_x+cam_pose[1*4+0]*tmp_pt_y+cam_pose[2*4+0]*tmp_pt_z;
float cam_pt_y = cam_pose[0*4+1]*tmp_pt_x+cam_pose[1*4+1]*tmp_pt_y+cam_pose[2*4+1]*tmp_pt_z;
float cam_pt_z = cam_pose[0*4+2]*tmp_pt_x+cam_pose[1*4+2]*tmp_pt_y+cam_pose[2*4+2]*tmp_pt_z;
// Camera coordinates to image pixels
int pixel_x = (int) roundf(cam_intr[0*3+0]*(cam_pt_x/cam_pt_z)+cam_intr[0*3+2]);
int pixel_y = (int) roundf(cam_intr[1*3+1]*(cam_pt_y/cam_pt_z)+cam_intr[1*3+2]);
// Skip if outside view frustum
int im_h = (int) other_params[2];
int im_w = (int) other_params[3];
if (pixel_x < 0 || pixel_x >= im_w || pixel_y < 0 || pixel_y >= im_h || cam_pt_z<0)
return;
// Skip invalid depth
float depth_value = depth_im[pixel_y*im_w+pixel_x];
if (depth_value == 0)
return;
// Integrate TSDF
float trunc_margin = other_params[4];
float depth_diff = depth_value-cam_pt_z;
if (depth_diff < -trunc_margin)
return;
float dist = fmin(1.0f,depth_diff/trunc_margin);
float w_old = weight_vol[voxel_idx];
float obs_weight = other_params[5];
float w_new = w_old + obs_weight;
weight_vol[voxel_idx] = w_new;
tsdf_vol[voxel_idx] = (tsdf_vol[voxel_idx]*w_old+obs_weight*dist)/w_new;
// Integrate color
float old_color = color_vol[voxel_idx];
float old_b = floorf(old_color/(256*256));
float old_g = floorf((old_color-old_b*256*256)/256);
float old_r = old_color-old_b*256*256-old_g*256;
float new_color = color_im[pixel_y*im_w+pixel_x];
float new_b = floorf(new_color/(256*256));
float new_g = floorf((new_color-new_b*256*256)/256);
float new_r = new_color-new_b*256*256-new_g*256;
new_b = fmin(roundf((old_b*w_old+obs_weight*new_b)/w_new),255.0f);
new_g = fmin(roundf((old_g*w_old+obs_weight*new_g)/w_new),255.0f);
new_r = fmin(roundf((old_r*w_old+obs_weight*new_r)/w_new),255.0f);
color_vol[voxel_idx] = new_b*256*256+new_g*256+new_r;
}""")
self._cuda_integrate = self._cuda_src_mod.get_function("integrate")
# 确定GPU上的块/网格大小
gpu_dev = cuda.Device(0)
self._max_gpu_threads_per_block = gpu_dev.MAX_THREADS_PER_BLOCK
n_blocks = int(np.ceil(float(np.prod(self._vol_dim))/float(self._max_gpu_threads_per_block)))
grid_dim_x = min(gpu_dev.MAX_GRID_DIM_X, int(np.floor(np.cbrt(n_blocks))))
grid_dim_y = min(gpu_dev.MAX_GRID_DIM_Y, int(np.floor(np.sqrt(n_blocks/grid_dim_x))))
grid_dim_z = min(gpu_dev.MAX_GRID_DIM_Z, int(np.ceil(float(n_blocks)/float(grid_dim_x*grid_dim_y))))
self._max_gpu_grid_dim = np.array([grid_dim_x, grid_dim_y, grid_dim_z]).astype(int)
self._n_gpu_loops = int(np.ceil(float(np.prod(self._vol_dim))/float(np.prod(self._max_gpu_grid_dim)*self._max_gpu_threads_per_block)))
else:
# 获取每个体素网格的坐标
xv, yv, zv = np.meshgrid(range(self._vol_dim[0]), range(self._vol_dim[1]), range(self._vol_dim[2]), indexing='ij')
self.vox_coords = np.concatenate([xv.reshape(1, -1), yv.reshape(1, -1), zv.reshape(1, -1)], axis=0).astype(int).T
@staticmethod
@njit(parallel=True)
def vox2world(vol_origin, vox_coords, vox_size):
"""
Convert voxel grid coordinates to world coordinates.(将体素网格坐标转换为世界坐标。)
"""
vol_origin = vol_origin.astype(np.float32)
vox_coords = vox_coords.astype(np.float32)
cam_pts = np.empty_like(vox_coords, dtype=np.float32)
for i in prange(vox_coords.shape[0]):
for j in range(3):
cam_pts[i, j] = vol_origin[j] + (vox_size * vox_coords[i, j])
return cam_pts
@staticmethod
@njit(parallel=True)
def cam2pix(cam_pts, intr):
"""
Convert camera coordinates to pixel coordinates.(将相机坐标转换为像素坐标。)
"""
intr = intr.astype(np.float32)
fx, fy = intr[0, 0], intr[1, 1]
cx, cy = intr[0, 2], intr[1, 2]
pix = np.empty((cam_pts.shape[0], 2), dtype=np.int64)
for i in prange(cam_pts.shape[0]):
pix[i, 0] = int(np.round((cam_pts[i, 0] * fx / cam_pts[i, 2]) + cx))
pix[i, 1] = int(np.round((cam_pts[i, 1] * fy / cam_pts[i, 2]) + cy))
return pix
@staticmethod
@njit(parallel=True)
def integrate_tsdf(tsdf_vol, dist, w_old, obs_weight):
"""
Integrate the TSDF volume.
"""
tsdf_vol_int = np.empty_like(tsdf_vol, dtype=np.float32)
w_new = np.empty_like(w_old, dtype=np.float32)
for i in prange(len(tsdf_vol)):
w_new[i] = w_old[i] + obs_weight
tsdf_vol_int[i] = (w_old[i] * tsdf_vol[i] + obs_weight * dist[i]) / w_new[i]
return tsdf_vol_int, w_new
def integrate(self, color_im, depth_im, cam_intr, cam_pose, obs_weight=1.):
"""Integrate an RGB-D frame into the TSDF volume.
Args:
color_im (ndarray): An RGB image of shape (H, W, 3).
depth_im (ndarray): A depth image of shape (H, W).
cam_intr (ndarray): The camera intrinsics matrix of shape (3, 3).
cam_pose (ndarray): The camera pose (i.e. extrinsics) of shape (4, 4).
obs_weight (float): The weight to assign for the current observation. A higher value
"""
im_h, im_w = depth_im.shape # 获取图像尺寸
# 将RGB彩色图像折叠成单通道图像(将rgb三个值表示的颜色通道信息转换成一个用float32表示的单通道信息)
color_im = color_im.astype(np.float32)
color_im = np.floor(color_im[..., 2]*self._color_const + color_im[..., 1]*256 + color_im[..., 0])
# 【GPU mode】: 集成体素体积(调用CUDA内核)
if self.gpu_mode:
for gpu_loop_idx in range(self._n_gpu_loops):
self._cuda_integrate(self._tsdf_vol_gpu,
self._weight_vol_gpu,
self._color_vol_gpu,
cuda.InOut(self._vol_dim.astype(np.float32)),
cuda.InOut(self._vol_origin.astype(np.float32)),
cuda.InOut(cam_intr.reshape(-1).astype(np.float32)),
cuda.InOut(cam_pose.reshape(-1).astype(np.float32)),
cuda.InOut(np.asarray([gpu_loop_idx, self._voxel_size, im_h, im_w, self._trunc_margin, obs_weight], np.float32)),
cuda.InOut(color_im.reshape(-1).astype(np.float32)),
cuda.InOut(depth_im.reshape(-1).astype(np.float32)),
block=(self._max_gpu_threads_per_block, 1, 1),
grid=(int(self._max_gpu_grid_dim[0]), int(self._max_gpu_grid_dim[1]), int(self._max_gpu_grid_dim[2]), )
)
# 【CPU mode】: 整合体素体积(矢量化实现)
else:
# 将体素网格坐标转换为像素坐标
cam_pts = self.vox2world(self._vol_origin, self.vox_coords, self._voxel_size) # 体素坐标系转换到世界坐标系
cam_pts = rigid_transform(cam_pts, np.linalg.inv(cam_pose)) # 世界坐标系转换到相机坐标系
pix_z = cam_pts[:, 2]
pix = self.cam2pix(cam_pts, cam_intr) # 相机坐标系转换到像素坐标系
pix_x, pix_y = pix[:, 0], pix[:, 1]
# 消除视界外的像素(移除像素边界之外的投影点)
valid_pix = np.logical_and(pix_x >= 0, np.logical_and(pix_x < im_w, np.logical_and(pix_y >= 0, np.logical_and(pix_y < im_h, pix_z > 0))))
depth_val = np.zeros(pix_x.shape)
depth_val[valid_pix] = depth_im[pix_y[valid_pix], pix_x[valid_pix]] # 获取体素(x,y)在深度图像中的值
# 更新每个体素网格的tsdf值及对应的权重
depth_diff = depth_val - pix_z # 计算SDF值
valid_pts = np.logical_and(depth_val > 0, depth_diff >= -self._trunc_margin) # 确定出有效深度值(即sdf值的值要大于负的截断值)
dist = np.minimum(1, depth_diff / self._trunc_margin) # 计算截断值
valid_vox_x = self.vox_coords[valid_pts, 0]
valid_vox_y = self.vox_coords[valid_pts, 1]
valid_vox_z = self.vox_coords[valid_pts, 2]
w_old = self._weight_vol_cpu[valid_vox_x, valid_vox_y, valid_vox_z] # 提取上个循环对应体素的权重
tsdf_vals = self._tsdf_vol_cpu[valid_vox_x, valid_vox_y, valid_vox_z] # 提取上个循环对应体素的tsdf值
valid_dist = dist[valid_pts]
tsdf_vol_new, w_new = self.integrate_tsdf(tsdf_vals, valid_dist, w_old, obs_weight) # 计算体素新的权重和tsdf值
self._weight_vol_cpu[valid_vox_x, valid_vox_y, valid_vox_z] = w_new # 将新的权值和tsdf值更新到体素信息容器中
self._tsdf_vol_cpu[valid_vox_x, valid_vox_y, valid_vox_z] = tsdf_vol_new
# 更新每个体素网格的颜色值(按照旧权重与新权重的加权,更新每个体素栅格的rgb值)
old_color = self._color_vol_cpu[valid_vox_x, valid_vox_y, valid_vox_z]
old_b = np.floor(old_color / self._color_const)
old_g = np.floor((old_color-old_b*self._color_const)/256)
old_r = old_color - old_b*self._color_const - old_g*256
new_color = color_im[pix_y[valid_pts], pix_x[valid_pts]]
new_b = np.floor(new_color / self._color_const)
new_g = np.floor((new_color - new_b*self._color_const) / 256)
new_r = new_color - new_b*self._color_const - new_g*256
new_b = np.minimum(255., np.round((w_old*old_b + obs_weight*new_b) / w_new))
new_g = np.minimum(255., np.round((w_old*old_g + obs_weight*new_g) / w_new))
new_r = np.minimum(255., np.round((w_old*old_r + obs_weight*new_r) / w_new))
self._color_vol_cpu[valid_vox_x, valid_vox_y, valid_vox_z] = new_b*self._color_const + new_g*256 + new_r
def get_volume(self):
if self.gpu_mode:
cuda.memcpy_dtoh(self._tsdf_vol_cpu, self._tsdf_vol_gpu)
cuda.memcpy_dtoh(self._color_vol_cpu, self._color_vol_gpu)
return self._tsdf_vol_cpu, self._color_vol_cpu
def get_point_cloud(self):
"""
Extract a point cloud from the voxel volume.(从体素体中提取点云。)
"""
tsdf_vol, color_vol = self.get_volume()
# Marching cubes
verts = measure.marching_cubes(tsdf_vol, level=0)[0]
verts_ind = np.round(verts).astype(int)
verts = verts*self._voxel_size + self._vol_origin
# Get vertex colors
rgb_vals = color_vol[verts_ind[:, 0], verts_ind[:, 1], verts_ind[:, 2]]
colors_b = np.floor(rgb_vals / self._color_const)
colors_g = np.floor((rgb_vals - colors_b*self._color_const) / 256)
colors_r = rgb_vals - colors_b*self._color_const - colors_g*256
colors = np.floor(np.asarray([colors_r, colors_g, colors_b])).T
colors = colors.astype(np.uint8)
pc = np.hstack([verts, colors])
return pc
def get_mesh(self):
"""
Compute a mesh from the voxel volume using marching cubes.(使用marching cubes体素级重建方法计算网格)
"""
tsdf_vol, color_vol = self.get_volume() # 获取体素栅格的tsdf值及对应的颜色值
# 直接使用scikit-image工具包中封装的Marching cubes算法接口提取等值面
verts, faces, norms, vals = measure.marching_cubes(tsdf_vol, level=0)
verts_ind = np.round(verts).astype(int)
verts = verts*self._voxel_size+self._vol_origin # voxel grid coordinates to world coordinates
# 为每个体素赋值颜色
rgb_vals = color_vol[verts_ind[:, 0], verts_ind[:, 1], verts_ind[:, 2]]
colors_b = np.floor(rgb_vals/self._color_const)
colors_g = np.floor((rgb_vals-colors_b*self._color_const)/256)
colors_r = rgb_vals-colors_b*self._color_const-colors_g*256
colors = np.floor(np.asarray([colors_r, colors_g, colors_b])).T
colors = colors.astype(np.uint8)
return verts, faces, norms, colors
def rigid_transform(xyz, transform):
"""
世界坐标系转换到相机坐标系: Applies a rigid transform to an (N, 3) pointcloud.(对(N, 3)点云应用刚性变换。)
"""
xyz_h = np.hstack([xyz, np.ones((len(xyz), 1), dtype=np.float32)])
xyz_t_h = np.dot(transform, xyz_h.T).T
return xyz_t_h[:, :3]
def get_view_frustum(depth_im, cam_intr, cam_pose):
"""
Get corners of 3D camera view frustum of depth image.(获取三维相机视角的深度图像)
"""
im_h = depth_im.shape[0]
im_w = depth_im.shape[1]
max_depth = np.max(depth_im)
view_frust_pts = np.array([(np.array([0, 0, 0, im_w, im_w])-cam_intr[0, 2]) * np.array([0, max_depth, max_depth, max_depth, max_depth])/cam_intr[0, 0],
(np.array([0, 0, im_h, 0, im_h])-cam_intr[1, 2]) * np.array([0, max_depth, max_depth, max_depth, max_depth])/cam_intr[1, 1],
np.array([0, max_depth, max_depth, max_depth, max_depth])
])
view_frust_pts = rigid_transform(view_frust_pts.T, cam_pose).T
return view_frust_pts
def meshwrite(filename, verts, faces, norms, colors):
"""
Save a 3D mesh to a polygon .ply file.(将3D网格保存为多边形.ply文件。)
"""
# Write header
ply_file = open(filename, 'w')
ply_file.write("ply\n")
ply_file.write("format ascii 1.0\n")
ply_file.write("element vertex %d\n" % (verts.shape[0]))
ply_file.write("property float x\n")
ply_file.write("property float y\n")
ply_file.write("property float z\n")
ply_file.write("property float nx\n")
ply_file.write("property float ny\n")
ply_file.write("property float nz\n")
ply_file.write("property uchar red\n")
ply_file.write("property uchar green\n")
ply_file.write("property uchar blue\n")
ply_file.write("element face %d\n" % (faces.shape[0]))
ply_file.write("property list uchar int vertex_index\n")
ply_file.write("end_header\n")
# Write vertex list
for i in range(verts.shape[0]):
ply_file.write("%f %f %f %f %f %f %d %d %d\n" % (verts[i, 0], verts[i, 1], verts[i, 2],
norms[i, 0], norms[i, 1], norms[i, 2],
colors[i, 0], colors[i, 1], colors[i, 2],))
# Write face list
for i in range(faces.shape[0]):
ply_file.write("3 %d %d %d\n" % (faces[i, 0], faces[i, 1], faces[i, 2]))
ply_file.close()
def pcwrite(filename, xyzrgb):
"""
Save a point cloud to a polygon .ply file.(保存点云到多边形.ply文件。)
"""
xyz = xyzrgb[:, :3]
rgb = xyzrgb[:, 3:].astype(np.uint8)
# Write header
ply_file = open(filename, 'w')
ply_file.write("ply\n")
ply_file.write("format ascii 1.0\n")
ply_file.write("element vertex %d\n" % (xyz.shape[0]))
ply_file.write("property float x\n")
ply_file.write("property float y\n")
ply_file.write("property float z\n")
ply_file.write("property uchar red\n")
ply_file.write("property uchar green\n")
ply_file.write("property uchar blue\n")
ply_file.write("end_header\n")
# Write vertex list
for i in range(xyz.shape[0]):
ply_file.write("%f %f %f %d %d %d\n" % (xyz[i, 0], xyz[i, 1], xyz[i, 2], rgb[i, 0], rgb[i, 1], rgb[i, 2],))