凌晨三点半了,太困了,还差一些,明天补上…
因为自己最近做的项目涉及到了缓存,所以水一篇缓存相关的文章,供大家作为参考,若发现文章有纰漏,希望大家多指正。
缓存涉及到的范围颇广,从CPU缓存,到进程内缓存,到进程外缓存。再加上已经凌晨一点了,我得保住我的几丝残发,本文不会将每一处的细枝末节都写到,见谅。
文章目录
- 关于CPU缓存
- 关于多级缓存
- 关于二级缓存
- 进程内缓存
- 进程内缓存有什么好处?
- 进程内缓存有什么缺点?
- 如何保证进程内缓存的数据一致性?
- 为什么不能频繁使用进程内缓存?
- 什么时候可以使用进程内缓存?
- 服务之间通过缓存传递数据的错误性
- 使用缓存未考虑雪崩的错误性
- 多服务共用缓存实例的错误性
- 缓存与数据库不一致的解决方案
- 先操作缓存,还是数据库
- Cache Aside Pattern方案
- 缓存为什么总是淘汰,不是修改
- 缓存相关的清除策略
- 为什么选Caffeine
- 为什么选Redis
- Redis最佳应用实践
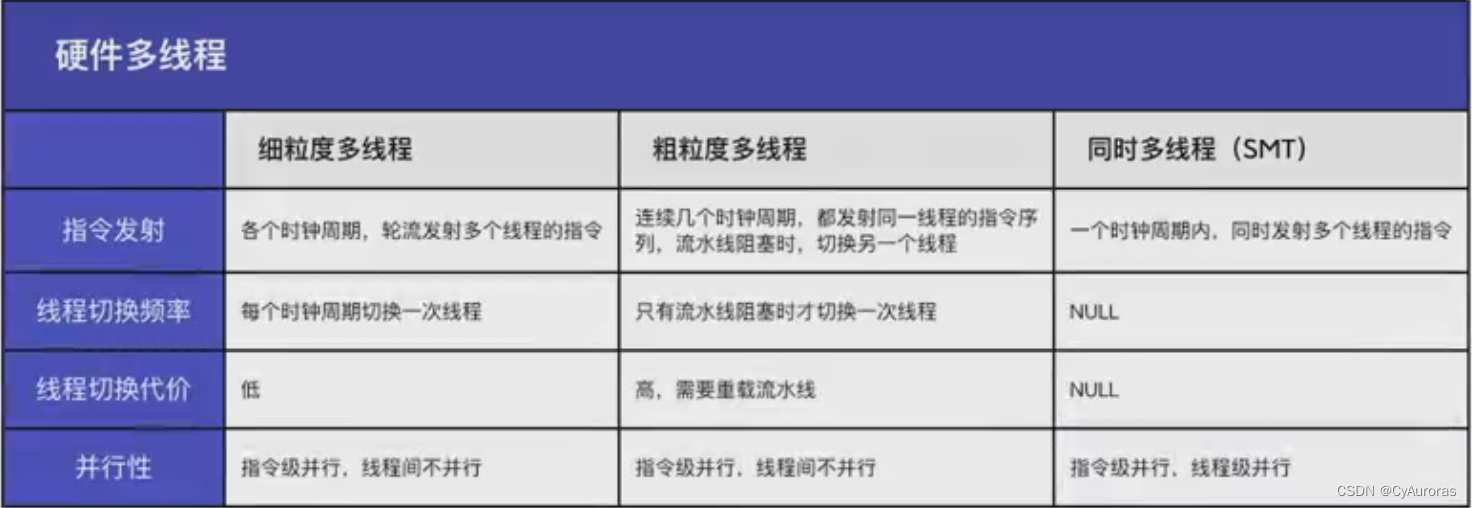
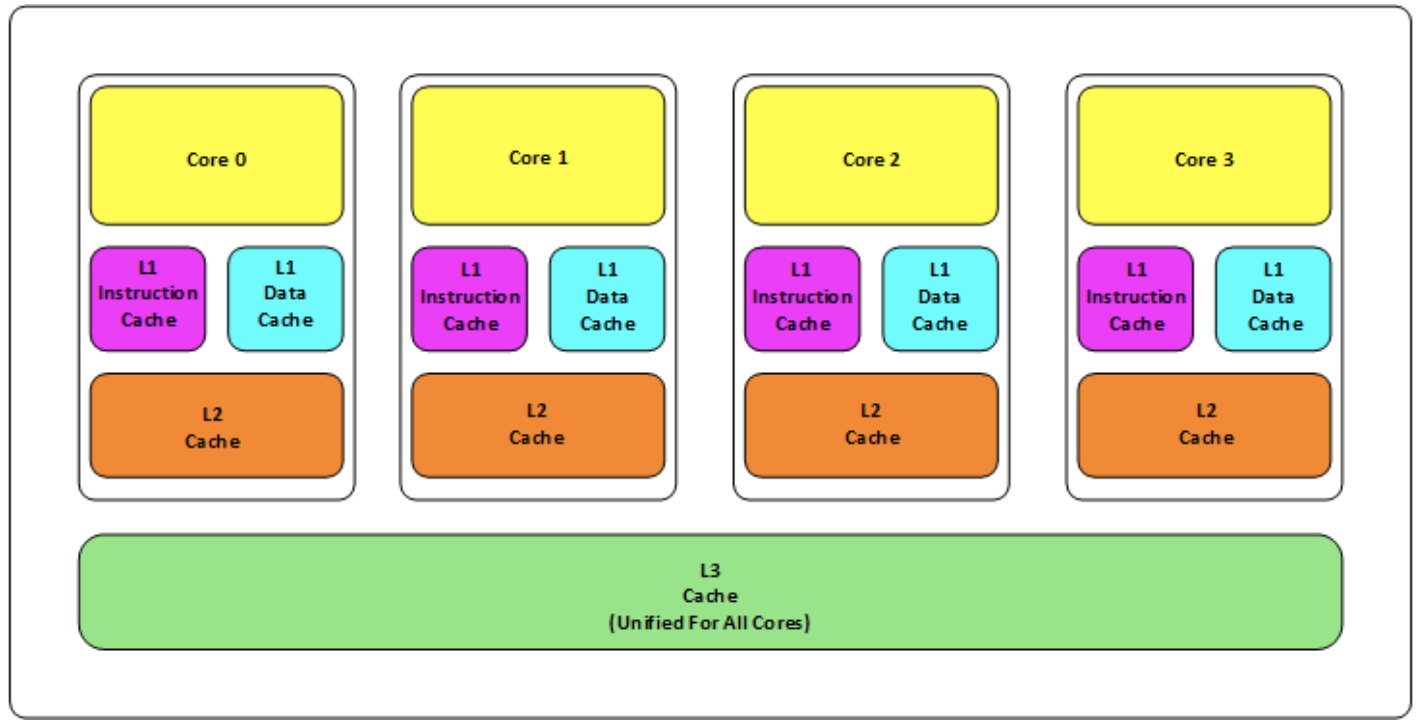
关于CPU缓存
这里提一句CPU缓存,因为缓存的核心思想都是那点事,命中、淘汰、一致性等。
以前着重写过CPU的一些东西,这里只附一张图。
ps:听说最近有哪个厂商的CPU把三级缓存架构和总线锁改了,有相关资源的小伙伴快发给我,我观摩一下,hhh~
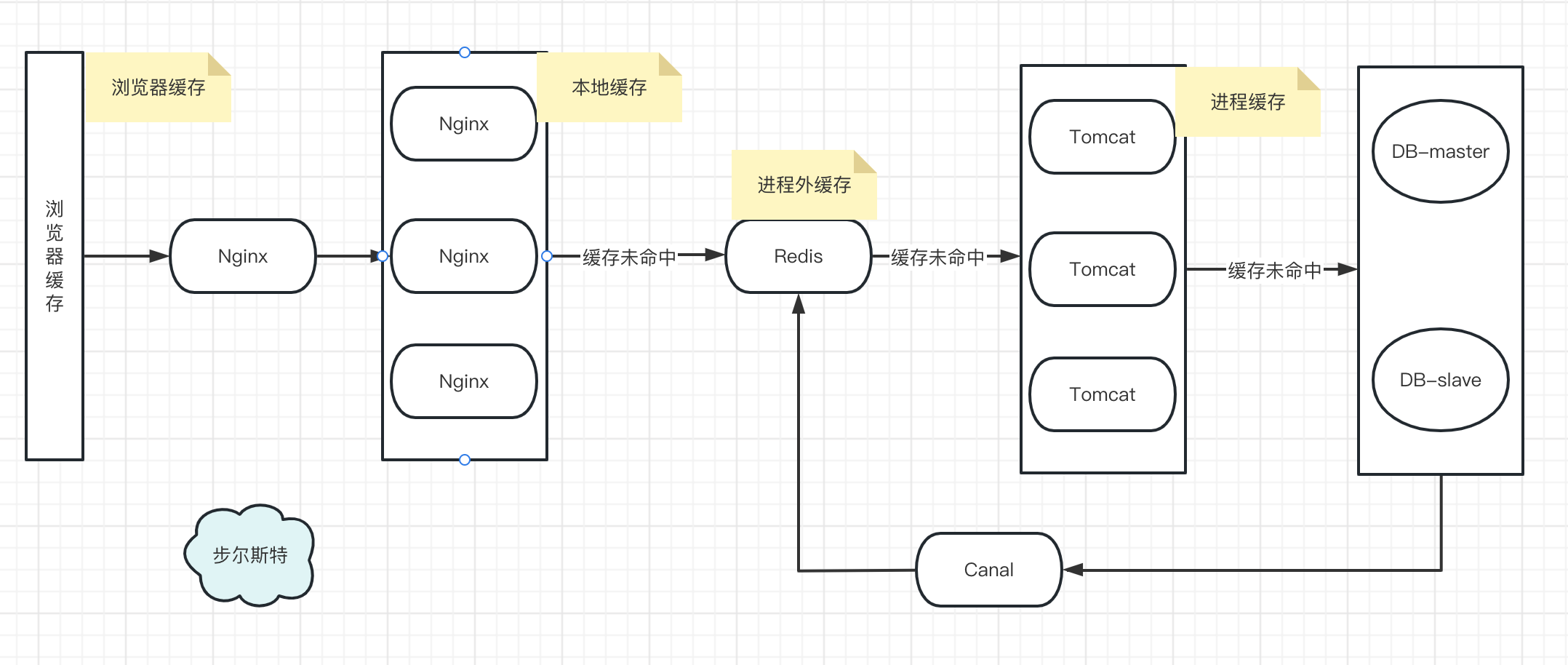
关于多级缓存
本文重点不在多级缓存,因为以前我也专门写过一篇关于多级缓存的详细设计。
简要步骤:
- 浏览器缓存
- Nginx反向代理,负载OpenResty集群
- OpenResty基于Nginx和Lua,可实现Lua业务编码,缓存性能很好,京东技术做过压测对比。
- 如果OpenResty缓存未命中,则查询Redis
- 若Redis缓存未命中,则查询进程缓存
- 为了保证缓存和DB的数据一致性,还可以用Canal和DTS做数据同步(基于Mysql的Binlog,和主从一个原理,伪装成slave)
关于二级缓存
二级缓存最佳实践:Caffeine + Redis
- 先走Caffeine,如果未命中,走Redis
- 为了保证数据一致性,可以用Canal / DTS做数据同步
- 进程缓存Caffeine的话,设置个定时同步就可以了
性能优化:
- 进程缓存应用Caffeine是因为其底层ConcurrentHashMap的结构,支持并发(后面会出各个进程缓存性能对比报告)
- 进程外缓存,我通常会无脑选Redis,基于其容错性,多数据结构等。(后面会出和memcache等对比分析)
市面上也有二级缓存框架,比如J2Cache,该框架本身并没有做额外工作,主要是集成了常见的进程内缓存和进程外缓存。
如果基于Spring开发,基于AOP设计的Spring Cache框架适配常用的缓存,自身的注解和策略天然和业务解耦,很不错,但是,如何集成Redis,这里需要特别注意!!!
因为集成Redis时,Spring Cache的清除策略,在从Redis中删除缓存时使用的是 keys指令,keys指令时间复杂度是O(N),如果缓存数量较大会产生明显的阻,因此在生产环境中Redis会禁用这个指令,导致报错。
//keys 指令
byte[][] keys = Optional.ofNullable(connection.keys(pattern)).orElse(Collections.emptySet())
.toArray(new byte[0][]);
if (keys.length > 0) {
statistics.incDeletesBy(name, keys.length);
connection.del(keys);
}
所以,我们可以重写DefaultRedisCacheWriter(spring cache提供的默认的Redis缓存写出器,其内部封装了缓存增删改查等逻辑)
使用scan命令代替keys命令
//使用scan命令代替keys命令
Cursor<byte[]> cursor = connection.scan(new ScanOptions.ScanOptionsBuilder().match(new String(pattern)).count(1000).build());
Set<byte[]> byteSet = new HashSet<>();
while (cursor.hasNext()) {
byteSet.add(cursor.next());
}
byte[][] keys = byteSet.toArray(new byte[0][]);
讲真的,多级缓存和二级缓存这东西,不要为了炫技乱用,可能会增加没必要的开发成本和未知问题,而且还要做好数据量的评估,别搞了缓存,造成雪崩,那就真的血本无归了。
至理名言:不结合业务的技术都是耍流氓。
进程内缓存
进程内缓存有什么好处?
与没有缓存相比,进程内缓存的好处是,数据读取不再需要访问后端,例如数据库。
与进程外缓存相比(例如redis/memcache),进程内缓存省去了网络开销,所以一来节省了内网带宽,二来响应时延会更低。
进程内缓存有什么缺点?
如果数据缓存在站点和服务的多个节点内,数据存了多份,一致性比较难保障。
如何保证进程内缓存的数据一致性?
- 可以通过单节点通知其他节点。
- 可以通过MQ通知其他节点。
- 为了避免耦合,降低复杂性,干脆放弃了“实时一致性”,每个节点启动一个timer,定时从后端拉取最新的数据,更新内存缓存。在有节点更新后端数据,而其他节点通过timer更新数据之间,会读到脏数据。
为什么不能频繁使用进程内缓存?
站点与服务的进程内缓存,实际上违背了分层架构设计的无状态准则
什么时候可以使用进程内缓存?
- 只读数据,可以考虑在进程启动时加载到内存。(实现InitializingBean)
- 极其高并发的,如果透传后端压力极大的场景,可以考虑使用进程内缓存。(秒杀)
- 一定程度上允许数据不一致业务。
服务之间通过缓存传递数据的错误性
- 数据管道场景,MQ比cache更合适;
- 多个服务不应该公用一个cache实例,应该垂直拆分解耦;
- 服务化架构,不应该绕过service读取其后端的cache/db,而应该通过RPC接口访问。
使用缓存未考虑雪崩的错误性
如果缓存挂掉,所有的请求会压到数据库,如果未提前做容量预估,可能会把数据库压垮(在缓存恢复之前,数据库可能一直都起不来),导致系统整体不可服务。
应提前做容量预估,如果缓存挂掉,数据库仍能扛住,才能执行上述方案。
否则,就要进一步设计:
使用高可用缓存集群(例如主备),一个缓存实例挂掉后,能够自动做故障转移。
使用缓存水平切分,一个缓存实例挂掉后,不至于所有的流量都压到数据库上。
多服务共用缓存实例的错误性
- 可能导致key冲突,彼此冲掉对方的数据;(可做namespace:key的方式来做key,隔离)
- 不同服务对应的数据量,吞吐量不一样,共用一个实例容易导致一个服务把另一个服务的热数据挤出去;
- 共用一个实例,会导致服务之间的耦合,与微服务架构的“数据库,缓存私有”的设计原则是相悖的;
例如,我做过的一个单体架构项目,缓存用Caffeine,每个业务都会有一个Caffeine实例。
缓存与数据库不一致的解决方案
- 主从同步;
- 通过工具(DTS/cannal)订阅从库的binlog,这里能够最准确的知道,从库数据同步完成的时间;
- 从库执行完写操作,向缓存再次发起删除,淘汰这段时间内可能写入缓存的旧数据;
先操作缓存,还是数据库
- 读请求,先读缓存,如果没有命中,读数据库,再set回缓存
- 写请求
- 先缓存,再数据库
- 缓存,使用delete,而不是set
Cache Aside Pattern方案
对于读请求:
(1)先读cache,再读db;
(2)如果,cache hit,则直接返回数据;
(3)如果,cache miss,则访问db,并将数据set回缓存;
对于写请求:
(1)淘汰缓存,而不是更新缓存;
(2)先操作数据库,再淘汰缓存;
缓存为什么总是淘汰,不是修改
修改成本太大了,无脑选淘汰,问题不大
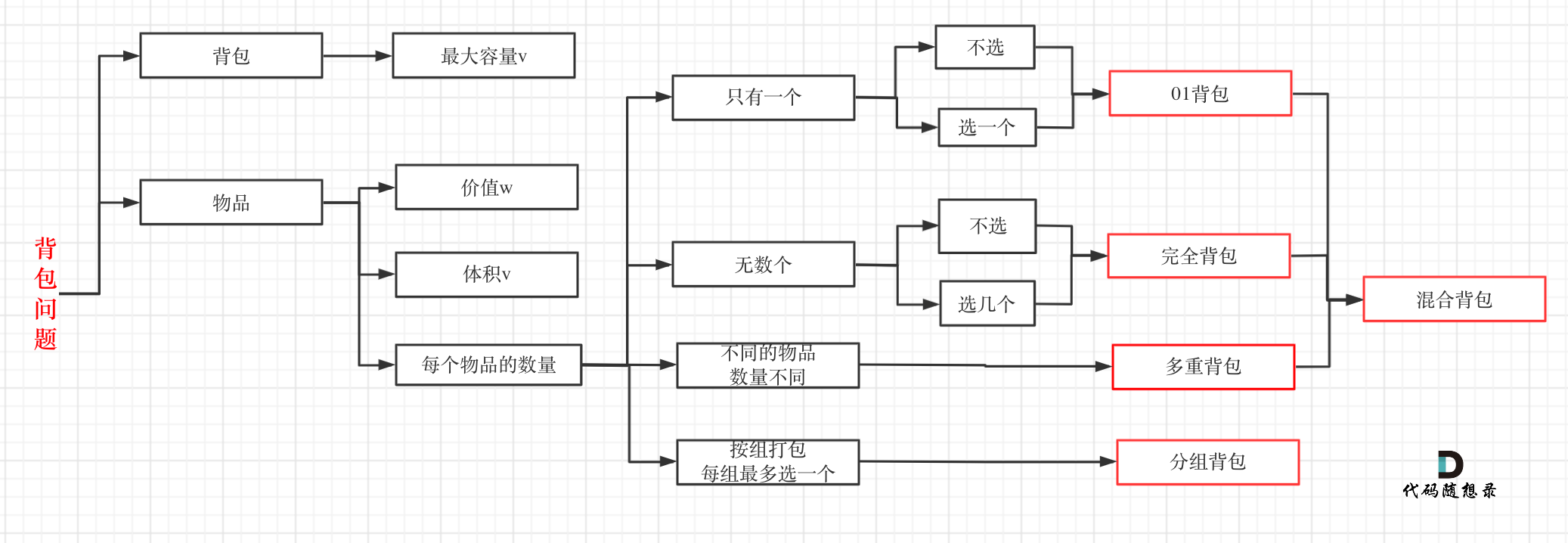
缓存相关的清除策略
FIFO(first in first out)
先进先出策略,最先进入缓存的数据在缓存空间不够的情况下(超出最大元素限制)会被优先被清除掉,以腾出新的空间接受新的数据。策略算法主要比较缓存元素的创建时间。在数据实效性要求场景下可选择该类策略,优先保障最新数据可用。
LFU(less frequently used)
最少使用策略,无论是否过期,根据元素的被使用次数判断,清除使用次数较少的元素释放空间。策略算法主要比较元素的hitCount(命中次数)。在保证高频数据有效性场景下,可选择这类策略。
LRU(least recently used)
最近最少使用策略,无论是否过期,根据元素最后一次被使用的时间戳,清除最远使用时间戳的元素释放空间。策略算法主要比较元素最近一次被get使用时间。在热点数据场景下较适用,优先保证热点数据的有效性。
除此之外,还有一些简单策略比如:
根据过期时间判断,清理过期时间最长的元素;
根据过期时间判断,清理最近要过期的元素;
随机清理;
根据关键字(或元素内容)长短清理等。
为什么选Caffeine
底层数据结构,W-TinyLFU算法,当然还有权威给出个各个组件性能对比图,谁不愿意用好的呢,对吧。(关于Caffeine源码,改天单写一篇)
为什么选Redis
没有为什么,无脑选就完了,下周我写一篇Redis7的源码文章,你就懂了。
Redis最佳应用实践
- 在主页中显示最新的项目列表:Redis使用的是常驻内存的缓存,速度非常快。LPUSH用来插入一个内容ID,作为关键字存储在列表头部。LTRIM用来限制列表中的项目数最多为5000。如果用户需要的检索的数据量超越这个缓存容量,这时才需要把请求发送到数据库。
- 删除和过滤:如果一篇文章被删除,可以使用LREM从缓存中彻底清除掉。
- 排行榜及相关问题:排行榜(leader board)按照得分进行排序。ZADD命令可以直接实现这个功能,而ZREVRANGE命令可以用来按照得分来获取前100名的用户,ZRANK可以用来获取用户排名,非常直接而且操作容易。
- 按照用户投票和时间排序:排行榜,得分会随着时间变化。LPUSH和LTRIM命令结合运用,把文章添加到一个列表中。一项后台任务用来获取列表,并重新计算列表的排序,ZADD命令用来按照新的顺序填充生成列表。列表可以实现非常快速的检索,即使是负载很重的站点。
- 过期项目处理:使用Unix时间作为关键字,用来保持列表能够按时间排序。对current_time和time_to_live进行检索,完成查找过期项目的艰巨任务。另一项后台任务使用ZRANGE…WITHSCORES进行查询,删除过期的条目。
- 计数:进行各种数据统计的用途是非常广泛的,比如想知道什么时候封锁一个IP地址。INCRBY命令让这些变得很容易,通过原子递增保持计数;GETSET用来重置计数器;过期属性用来确认一个关键字什么时候应该删除。
- 特定时间内的特定项目:这是特定访问者的问题,可以通过给每次页面浏览使用SADD命令来解决。SADD不会将已经存在的成员添加到一个集合。
- Pub/Sub:在更新中保持用户对数据的映射是系统中的一个普遍任务。Redis的pub/sub功能使用了SUBSCRIBE、UNSUBSCRIBE和PUBLISH命令,让这个变得更加容易。
- 队列:在当前的编程中队列随处可见。除了push和pop类型的命令之外,Redis还有阻塞队列的命令,能够让一个程序在执行时被另一个程序添加到队列。