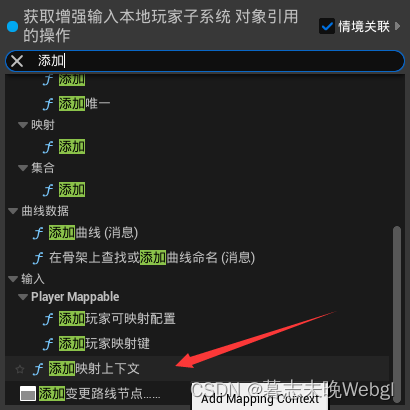
YOLO系列算法
从区域推荐到端到端
RCNN系列的方法和核心思想在于:先找出可能存在物体的区域,再确认物体的存在
这种思路归根溯源,来自传统的目标检测算法。
为了解决传统方法中的滑动窗口的方式,来找出可能存在目标的区域,从而提高检测效率。
这种方法固然取得了优秀的性能,但是存在一个关键问题:慢
一种更加直接的思路:端到端
对于先找到目标区域再预测的过程,我们可以采用一种更加直接的方式:让模型自动地识别出最终的目标。
我们只是为模型提供一个初始规则后,就可以让机器自动地识别出目标位置。
实际上,上述思路变换的本质来源于问题的定义的变换。
在之前的目标检测方法中,是将检测问题视为两个问题的组合:分类和回归(分类是核心问题)
然而,在端到端的问题上,是把检测问题视为一个典型的回归模型。
即然是回归模型,就是要预测一组数字,这个数字可以描述图像中目标的位置和类别。
那么我们用有序的位置组合以及onehot类别向量作为预期输出,即可实现可靠的目标检测。
端到端应该输出什么?
我们应当如何规定YOLO的输出,才可以直接得到目标位置?
为了检测出目标的输出,应当包含以下内容:
- 框的位置(4个点定义一个方框)
- 物体类别(n维one hot向量)
- 置信度(这个框和这个类别有多大的把握)
对于VOC数据集,每个框,我们可以得到一个(4+1+20=25)个长度的向量,作为ground truth。
想象中,我们可以将一张图像的框生成一个25维的向量,用CNN去预测出这些向量。解析结果以后,可以得到目标位置和类别。
然而,他会造成一个新的问题:每个图像的框可能并不一致,因此需要预测不同的输出尺寸。
显然,这在CNN中行不通。
YOLO v1的输出格式
yolo v1的输出为一个 N×N×M的三维向量。
具体上:
第一步:将图像定义成N×N个区域,如下:

第二步:每个区域会产生两个proposal

第三步:对于每个proposal,都有:
* 置信度:1维向量
* 框坐标:4维向量
* 分类值:20维向量
因此,一个proposal的分类值为1+4+20=25.
然而,由于一个区域要产生两个框,因此proposal为(1+4)*2 + 20 = 30
假设一个图像被划分成7*7的区域,则最终的输出尺寸为: 7×7×30(2个anchor)
YOLO v1的算法细节

- 图像输入后,经过卷积池化等步骤,得到一个7×7×1024的feature map
- 特征图链接fc后,得到一个4096维的向量
- 4096的向量进而进入fc后,得到一个1470的特征向量
- 将特征reshape后,得到一个的向量7×7×30的向量
预测
在预测阶段,一张图像输入后,得到7×7×30张量
对于每个30维的向量,都可以得到两个bounding box。
每个bounding box都存在一个置信度,设置一个阈值,删除掉置信度较低的框
剩余的框画在图像,就有:

其中,框越粗,置信度越高。
将7*7的类别对图像涂色,有
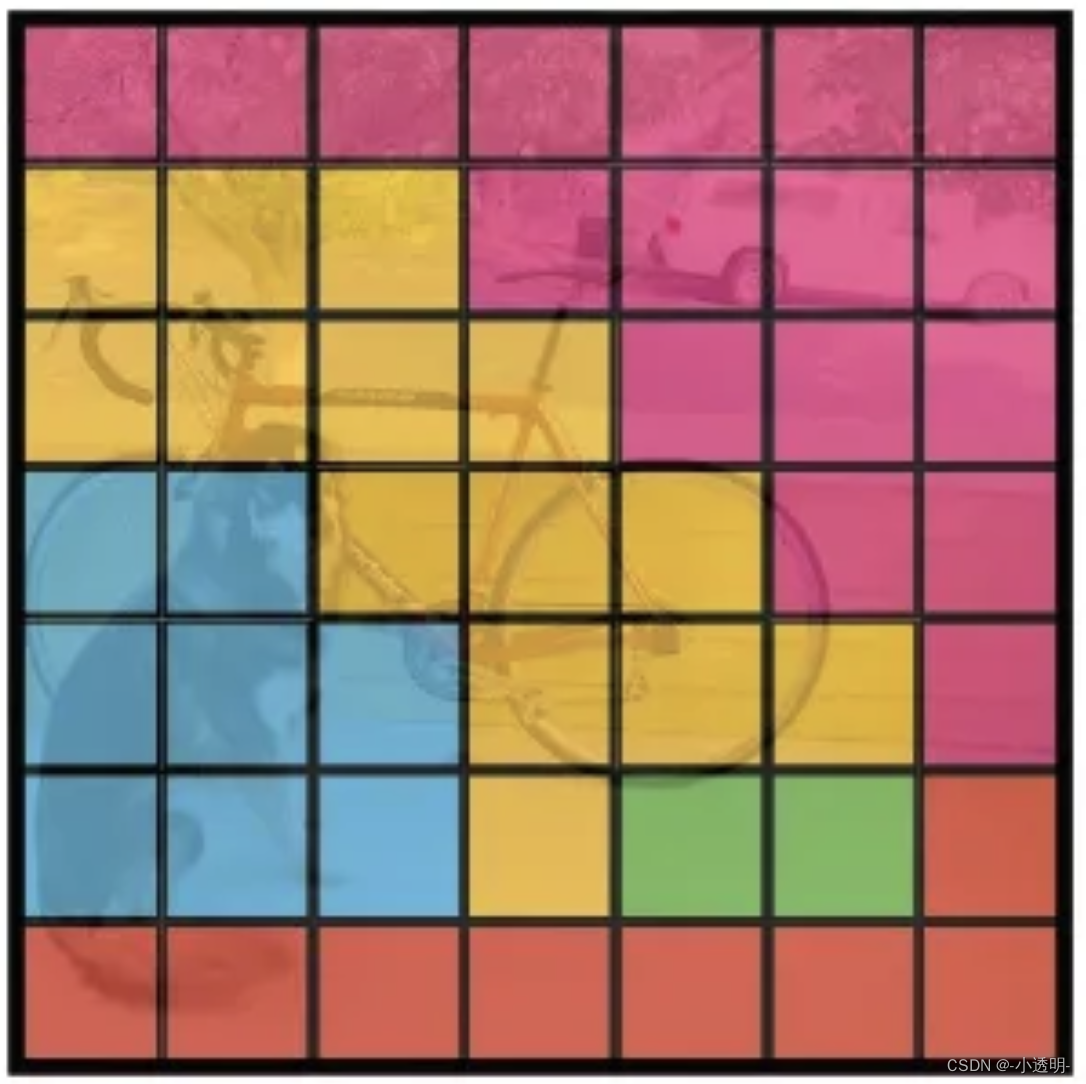
最后,利用NMS对同类框进行抑制,得到最终的框如下

训练
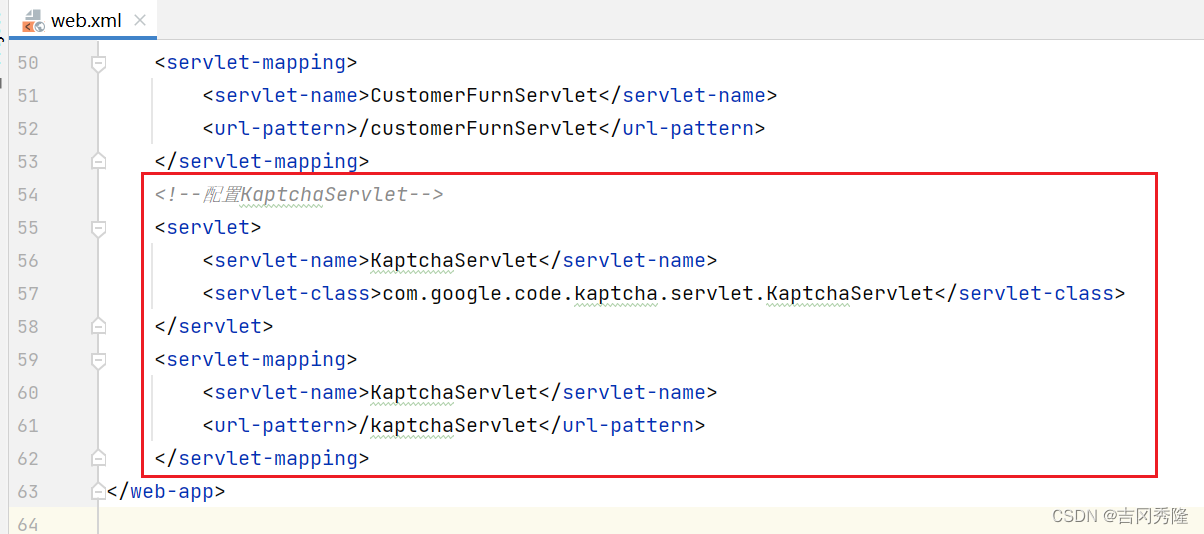
损失函数是实现回归的最重要问题。
对于一个这样的输出,应当设置什么样的损失函数?
分段特征的损失
针对一个向量中不同的内容,应当设置不同的损失函数。

第一项:
中心点损失:采用均方误差来实现
第二项:
缩放损失:采用均方误差实现,为了统一不同尺度目标的结果,采用了平方根的方法归一化
第三项:
含有目标的置信度损失,赋予较大的权重,增加目标区域对于置信度的影响
第四项:
不含目标的置信度损失,赋予较小的权重,减少非目标区域对于置信度的影响
第五项:
分类损失
其他细节
如何将ground truth转换成yolo的输出?
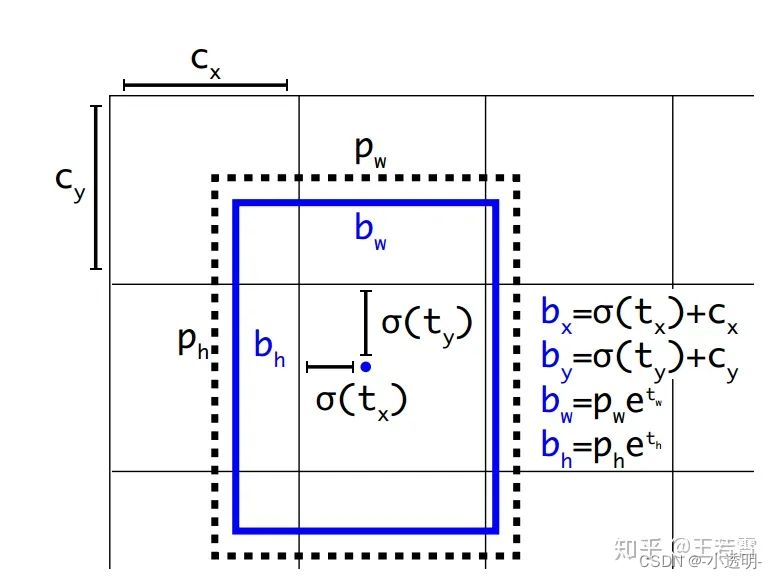
为了便于回归,将目标框的坐标变换为0-1的值。
对于x,y:是目标框的中心点,到对应区域中的比例。
例如,对应区域的左上角为原点(0, 0)
而后,目标框的中心点,相对于原点的偏移量的比例,即为xy值
关于置信度:
所有包含了目标的区域都视为1,其他区域都视为0.(标注过程)
YOLO v1的缺陷
- 对于重叠/小物体,检测性能差;
- 只支持相同尺寸的图像输入;
- 对于尺度不同的物体,检测框的位置存在误差
YOLO v2
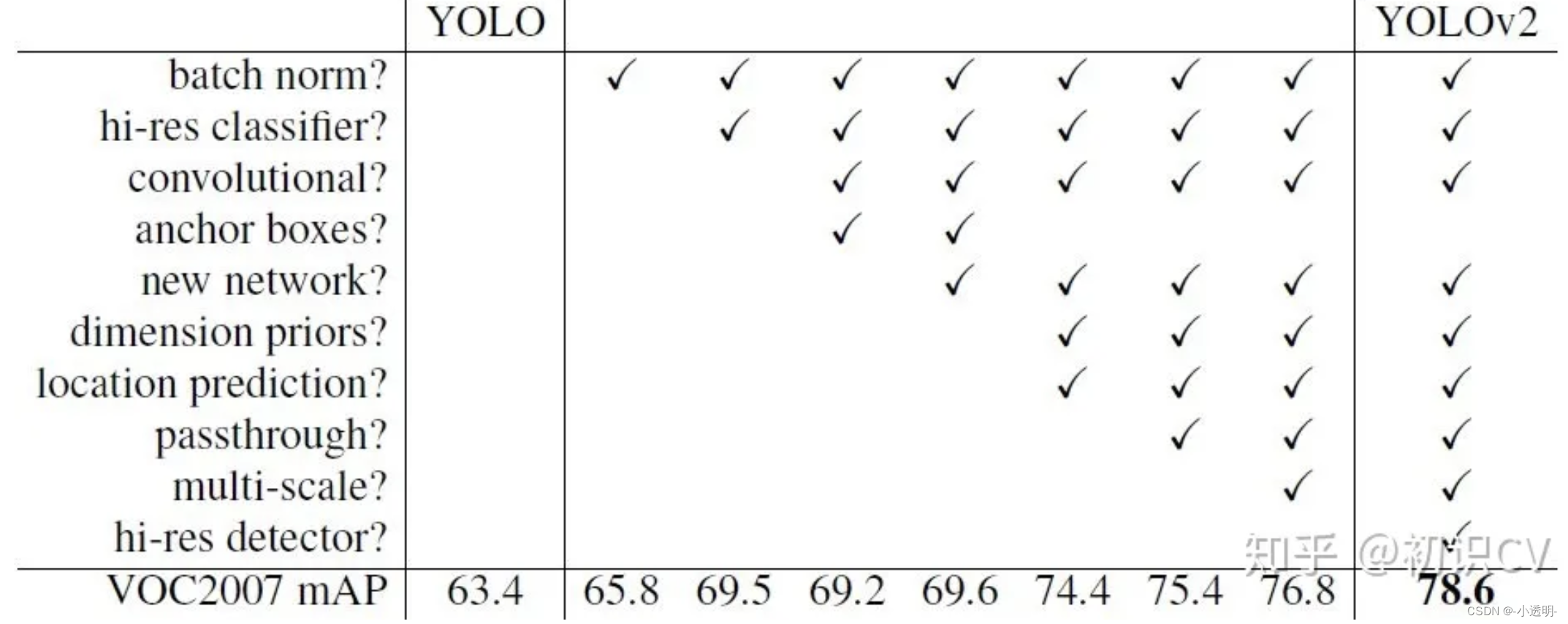
改进1: 模型
-
去除所有的dropout, 加入batch norm
-
将训练图像的输入改为448*448,而不是v1中的224*224

- anchor boxes
在faster rcnn中,anchor采用了3中固定尺度和3种固定比例。
虽然这些是通过对数据集考察后确定下来的,但却不够精确。
YOLOv2中,采用了新的方式来确定模板框的尺寸
将voc中每种框的wh列出来,作为一个数据,然后进行聚类处理。(kmeans)
那么具体聚多少类?手动设定(超参数)
如果类别数量非常大,则会导致计算量增加
如果类别数量非常少,则会不够精确。
实验结果表明,anchor boxes选择为5,则会产生最优的平衡。
注意,这里的框之间的距离公式(不是欧氏距离)是1−IOU
- 特征融合
直接对最后一层输出的feature map做回归,则会产生一个问题:对小尺度物体不够友好。

解决小目标检测的举措之一:用更大视野的图进行检测。
YOLO v3: 更快更准
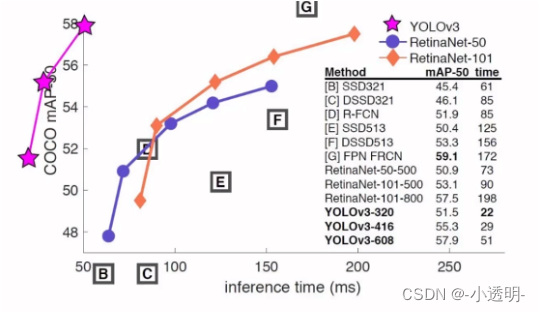
改进1: 多尺度检测
三种尺度进行检测

那么你会如何实现这样的方式?
- 图像金字塔?
- 特征金字塔?
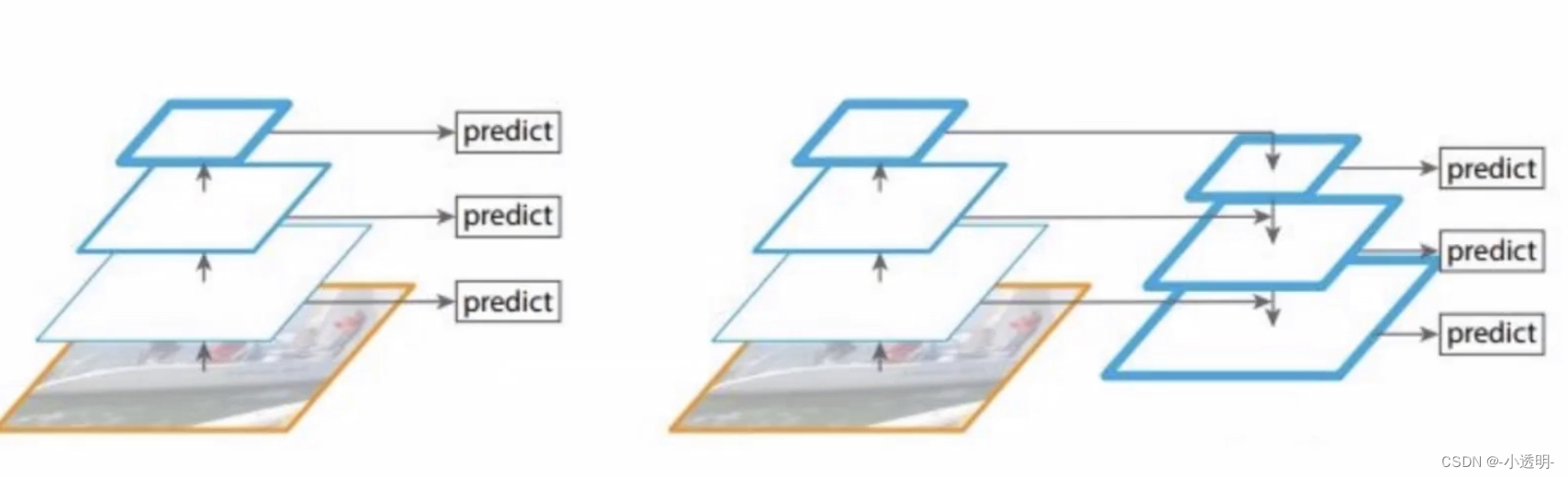
注意:这种方式共产生多少个anchor?
改进2: 跳层连接(resnet)
改进3: 网络结构
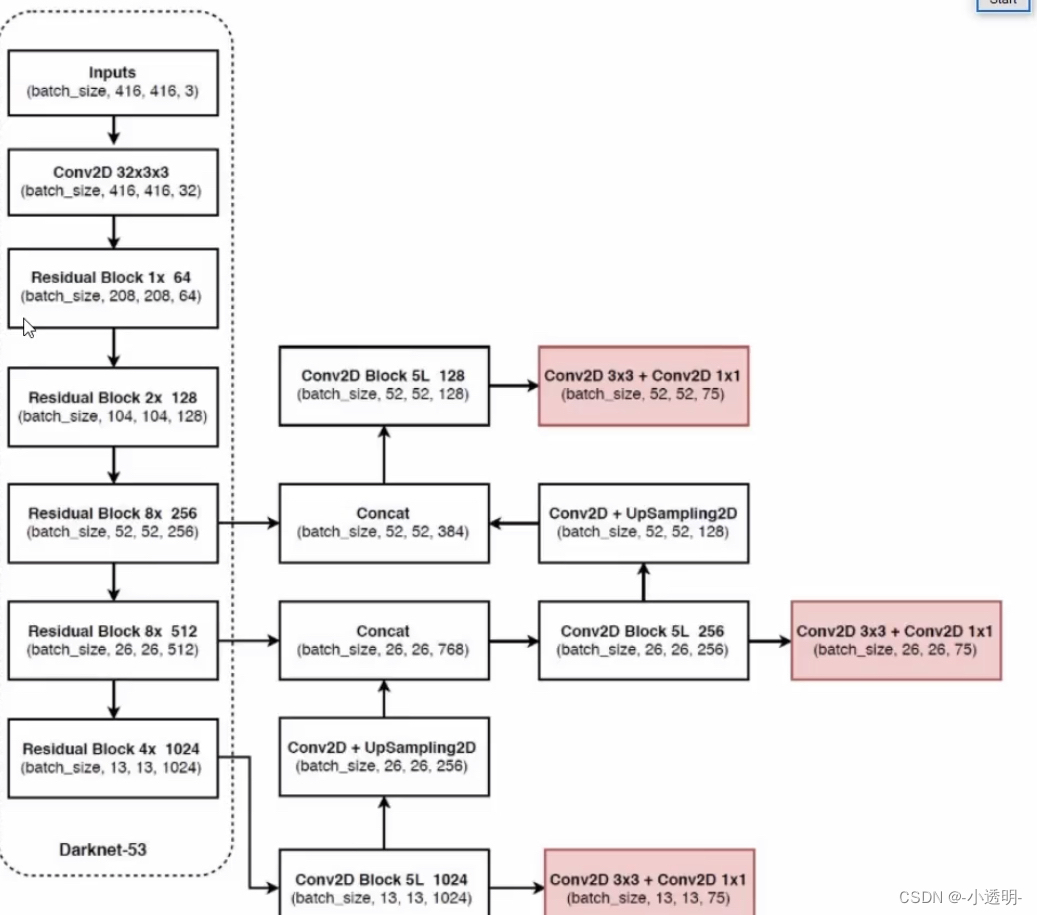
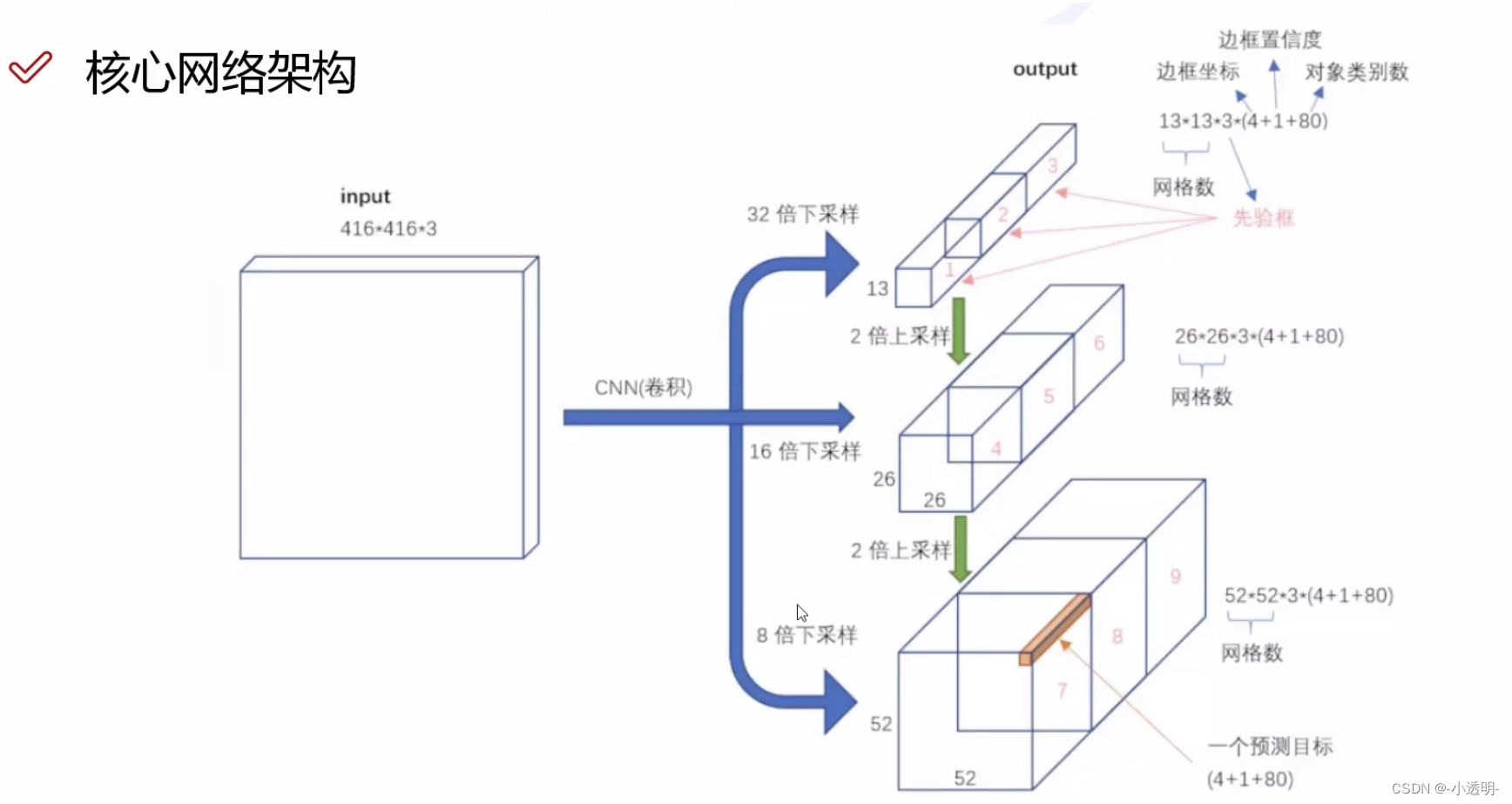
总结:
Yolov1是一种基于深度学习的目标检测算法,其主要特点是快速和高效。以下是关于Yolov1的一些精髓:
-
Yolov1使用单个神经网络来同时进行目标检测和分类,而不是像其他算法那样需要多个网络。
-
Yolov1使用全卷积神经网络,可以对不同大小的输入图像进行处理。
-
Yolov1将输入图像划分为S x S个网格,并为每个网格预测B个边界框和每个边界框的置信度和类别概率。
-
Yolov1使用非极大值抑制(NMS)来消除重叠的边界框。
-
Yolov1的训练数据集使用了数据增强技术,包括随机裁剪、旋转、缩放等。
以下是一些关于Yolov1的链接:
-
Yolov1论文:https://arxiv.org/abs/1506.02640
-
Yolov1代码实现:darknet/src at master · pjreddie/darknet · GitHub
-
Yolov1视频演示:https://www.youtube.com/watch?v=9s_FpMpdYW8
-
Yolov1在COCO数据集上的结果:COCO - Common Objects in Context
V1:将分类问题-->回归问题(CNN+reshape)
loss:加根号目的:缓解尺度问题
loss正负例分别算,负例前乘以λ(0<<1)原因:一张图片中大多为负例(90%)为保持模型对正负例预测性能的平衡
V2:去掉了fc层,不限制输入图像尺寸
聚类:距离采用:1-IOU
26*26:分辨率高;13*13:分辨率低,提高了对小目标检测的精度。
V3:
特征金字塔(高分辨(细节)特征)+上采样(泛化较好的特征)--> 较好的识别目标(大中小)

![[C++][opencv]opencv填充透明色到不规则polygon区域](https://img-blog.csdnimg.cn/579fe75cf947424eb8e4fc124a183967.jpeg)