https://www.cnblogs.com/cshaptx4869/p/10482500.html
1:通过 show status 了解各种的SQL的执行频率
2:定位执行频率低的SQL语句:
1):通过慢日志定位
慢日志:可以通过两个方式配置
方式一:配置文件,my.cnf
show_query_log = on/off #开启或关闭查询日志
log_show-queries = dir/filname #文件地址路径配置
log-query-time = n #设置查询秒数-最低
方式二:命令设置
set GLOBAL 参数
2):使用 show processlist 命令查看当前在运行的线程
MySQL数据库show processlist指令使用解析 - 编程宝库
在实际项目开发中,如果我们对数据库的压力比较大,比如有大批量的查询或者插入等sql,尤其是多线程插入等情况,针对部分执行比较慢的sql,我们可以将其kill掉,常用的一个命令就是show processlist。
3:通过explain 分析低效SQL
通过explain分析低效的SQL执行计划_weixin_34233679的博客-CSDN博客
之前我们讲过如何开启慢查询日志,这个日志的最大作用就是我们通过设定超时阈值,在执行SQL语句中的消耗时间大于这个阈值,将会被记录到慢查询日志里面。DBA通过这个慢查询日志定位到执行缓慢的sql语句,以便来进行优化。那我们今天就来学习一下如何分析抵消的SQL语句。
explain + sql语句:
示例:
mysql> explain select* from co3 where ctime=68776 \G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: co3
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 9471195
filtered: 10.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
我们主要对三个列说明一下:
select_type:表示SELECT 的类型,常见取值:SIMPLE、PRIMARY、UNION、SUBQUERY
table:输出的结果集的表。
KEY:表示执行语句中使用索引名。
type:表示MySQL在表中找到所需行的方式,或者叫访问类型。这个type的取值是我们重点学习的。主要有以下几个取值:
ALL | index | range | ref | eq_ref | const,system | NULL
从左到右,性能有最差到最好。4:通过show profile 分析SQL
MySQL 高级知识之 Show Profile_showprofile_十点摆码的博客-CSDN博客
1):介绍:Show Profile 是 MySQL 提供的可以用来分析当前查询 SQL 语句执行的资源消耗情况的工具,可用于 SQL 调优的测量。默认情况下处于关闭状态,开启会消耗一定的性能,一般在 SQL 分析和优化的时候使用,只保存最近15次的运行结果。
2):
①ALL:显示所有的开销信息。
②BLOCK IO:显示块IO开销。
③CONTEXT SWITCHES:上下文切换开销。
④CPU:显示CPU开销信息。
⑤IPC:显示发送和接收开销信息。
⑥MEMORY:显示内存开销信息。
⑦PAGE FAULTS:显示页面错误开销信息。
⑧SOURCE:显示和Source_function,Source_file,Source_line相关的开销信息。
⑨SWAPS:显示交换次数开销信息
5:通过trace分析优化器的选择
mysql通过trace分析优化器如何选择执行计划_chenlvzhou的博客-CSDN博客
mysqldumpslow 慢日志分析工具使用命令
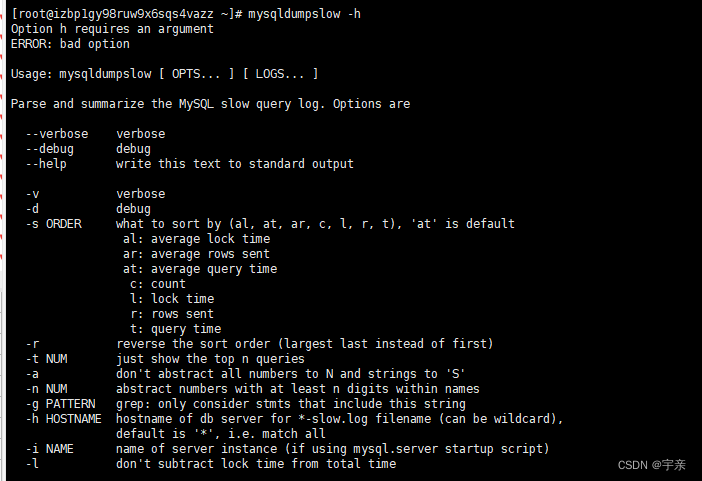
- -s 是order的顺序
- al 平均锁定时间
- ar 平均返回记录时间
- at 平均查询时间(默认)
- c 计数
- 锁定时间
- r 返回记录
- t 查询时间
- -t 是top n的意思,即为返回前面多少条的数据
- -g 后边可以写一个正则匹配模式,大小写不敏感的
-s,是order的顺序,说明写的不够详细,俺用下来,包括看了代码,主要有
c,t,l,r和ac,at,al,ar,分别是按照query次数,查询时间,lock的时间和返回的记录数来排序,前面加了a的平均数
-t,是top n的意思,即为返回前面多少条的数据
-g,后边可以写一个正则匹配模式,大小写不敏感的
例子
mysqldumpslow -t 10 -s t -g “left join” host-slow.log
使用mysqldumpslow的分析结果不会显示具体完整的sql语句,
说明:
1:假如真正的sql语句如下:SELECT * FROM sms_send WHERE service_id=10 GROUP BY content LIMIT 0, 1000;
mysqldumpslow显示的结果会是:
Count: 1 Time=1.91s (1s) Lock=0.00s (0s) Rows=1000.0 (1000), vgos_dba[vgos_dba]@[10.130.229.196]
SELECT * FROM sms_send WHERE service_id=N GROUP BY content LIMIT N, N;
2:如果我们再执行一条SELECT * FROM sms_send WHERE service_id=20 GROUP BY content LIMIT 10000, 1000;
mysqldumpslow显示的结果会是:
Count: 2 Time=2.79s (5s) Lock=0.00s (0s) Rows=1.0 (2), vgos_dba[vgos_dba]@[10.130.229.196]
SELECT * FROM sms_send WHERE service_id=N GROUP BY content LIMIT N, N;
虽然这两条语句条件不一样,
1:一个是server_id=10,一个是server_id=20
2:一个是LIMIT 0, 1000,一个是LIMIT 10000, 1000
但是mysqldumpslow分析会认为这是一种类型的语句,会合并显示。
3:假设我们执行SELECT * FROM sms_send WHERE service_id<=10 GROUP BY content LIMIT 0, 1000;
执行mysqldumpslow结果是
Count: 1 Time=2.91s (2s) Lock=0.00s (0s) Rows=1000.0 (1000), vgos_dba[vgos_dba]@[10.130.229.196]
SELECT * FROM sms_send WHERE service_id<=N GROUP BY content LIMIT N, N;
可以看出它和上面我们写的sql语句是两种类型
mysqldumpslow的分析结果
Count会告诉我们这种类型的语句执行了几次,Time会告诉我们这种类型的语句执行的最大时间,Time=2.79s (5s)中(5s)
是指这类型的语句执行总共花费的时间
Count: 2 Time=2.79s (5s) Lock=0.00s (0s) Rows=1.0 (2), vgos_dba[vgos_dba]@[10.130.229.196]
告诉我们执行了2次,最大时间是2.79s,总共花费时间5s,lock时间0s,单次返回的结果数是1条记录,2次总共返回2条记录m
mysqldumpslow -s t -t 10 slow.log
查询的结果是10条执行时间最慢的sql语句,其中-s t是指此类类型的语句的执行总时长
Count: 1 Time=2.91s (2s) Lock=0.00s (0s) Rows=1000.0 (1000), vgos_dba[vgos_dba]@[10.130.229.196]
和
Count: 2 Time=2.79s (5s) Lock=0.00s (0s) Rows=1.0 (2), vgos_dba[vgos_dba]@[10.130.229.196]
比较的结果是
Count: 2 Time=2.79s (5s) Lock=0.00s (0s) Rows=1.0 (2), vgos_dba[vgos_dba]@[10.130.229.196]排在前面,
以为比较的时长是(5s)和(2s),而不是2.79s和2.91s
-s at比较的也是(5s)/count:2和(2s)/Count: 1
所以:-s at是Count: 1 Time=2.91s (2s) Lock=0.00s (0s) Rows=1000.0 (1000), vgos_dba[vgos_dba]@[10.130.229.196]排在前面。
Rows=1.0 (2) 是按照以下逻辑展示的
(2)是指在Count: 2次数总共返回了2条记录集;row=1.0显示(2)/Count: 2,如果此时Count是3,
那么row的计算方式是Rows=2/3,Rows=0.67