引言
在K8s环境中,由于就绪检查设置不合理的问题,导致出现网关不可用的情况。
本文将详细探讨这个问题的原因,并提供一些解决方案,帮助有需要的同学解决类似的问题。
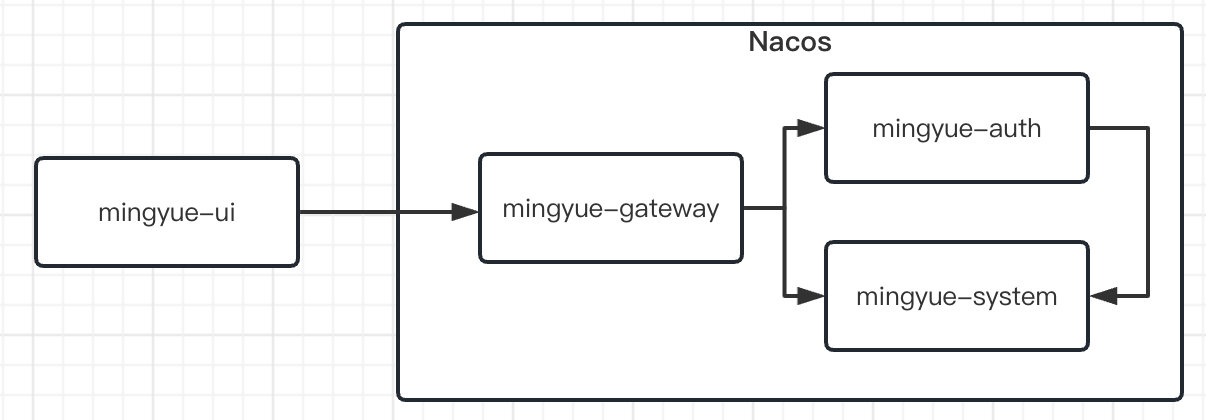
注:网关使用 spring-cloud-gateway
问题描述
描述
- 经用户反馈,进入小程序,首页空白一片,无商品数据展示。
- 研发收到反馈,进入小程序进行验证,发现小程序可正常使用。
- 这个过程大概有3分钟,过程中,一名前端同学通过抓包,发现部分API接口报503错误。
分析
- 这个问题就很诡异,从问题发生到自愈,没有做任何操作,自动就好了。
- 由于发现部分接口报503错误,所以直觉判断是网关有问题,因为从网关入手去分析。
- 通过告警信息,以及k8s事件日志,排查发现问题真的是出在网关上,具体原因见下。
问题原因
表象原因
- 通过k8s日志发现,网关触发了就绪检查的限制,将网关pod标记为不可用,导致用户请求报503错误。
根本原因
- 目前分析下来,大概率是k8s平台内部网络抖动等未知因素引起,但由于k8s底层无详细日志,暂无法继续往下深挖

问题原因分析
什么是就绪检查?
- 就绪检查,是一个用于验证应用程序是否准备就绪的机制。
- 当我们在K8s集群中部署网关时,我们希望确保该网关的所有依赖组件都已经准备就绪,然后才将流量引导到它。这个过程可以通过就绪检查来实现。
- 通常,就绪检查是通过在K8s的Pod配置中,定义一系列命令或HTTP请求来完成的。当这些命令或请求成功返回时,K8s会将该Pod标记为就绪。
就绪检查失败的可能原因?
- 就绪检查的超时设置不合理:如果就绪检查的超时时间设置得过短,而出现网络不稳定等未知情况,那么可能会出现超时的情况,导致就绪检查失败。
- 就绪检查的命令或请求有误:就绪检查的命令或请求可能存在错误,无法正确判断依赖组件是否准备就绪。
- 网关依赖组件的准备时间过长:如果网关所依赖的其他组件启动时间过长,超过了就绪检查的超时设置,就会导致就绪检查失败。
解决方案
通用方案
为了解决K8s 就绪检查 导致网关不可用的问题,我们可以采取以下措施:
调整就绪检查的超时设置:
- 通过适当增加就绪检查的超时时间,确保其能容纳依赖组件启动所需的时间。
- 这样可以防止就绪检查在依赖组件准备就绪之前失败。
优化就绪检查的命令或请求:
- 仔细检查就绪检查的命令或请求,并确保其正确性和可靠性。
- 确保命令或请求能够准确地判断依赖组件是否已经准备就绪。如果存在问题,及时修复并重新部署网关。
并行启动依赖组件:
- 如果网关所依赖的组件启动时间较长,可以考虑并行启动这些组件,以缩短整体的启动时间。
使用就绪探针:
- K8s提供了就绪探针(Readiness Probe)机制,可以用于检查应用程序是否准备就绪。
- 就绪探针是一种主动探测机制,可以定期发送请求或执行命令来验证应用程序的可用性。
- 与就绪检查不同,就绪探针不会导致Pod被标记为不可用,而只是在应用程序未准备就绪时暂停流量转发。
- 通过合理配置就绪探针,可以更灵活地控制网关的可用性。
实际改动
旧的健康检查机制
- 请求health接口,每10s检查一次,连续3次失败,1s超时,则将pod标记为不可用
新的健康检查机制
- 请求health接口,每10s检查一次,
**连续6次失败,2s超时**,则将pod标记为不可用
结论
Kubernetes就绪检查,是确保应用程序在流量流入前,已经准备就绪的重要机制。
然而,不正确的配置或使用可能导致网关不可用的问题。
作为架构师和开发人员,在设计和部署Kubernetes环境时,应密切关注就绪检查的配置,以避免类似问题的发生。