1 场景构造
drop table student;
create table student(sno int primary key, sname varchar(10), ssex int);
insert into student values(1, 'stu1', 0);
insert into student values(2, 'stu2', 1);
insert into student values(3, 'stu3', 1);
insert into student values(4, 'stu4', 0);
drop table course;
create table course(cno int primary key, cname varchar(10), tno int);
insert into course values(10, 'meth', 1);
insert into course values(11, 'english', 2);
drop table teacher;
create table teacher(tno int primary key, tname varchar(10), tsex int);
insert into teacher values(1, 'te1', 1);
insert into teacher values(2, 'te2', 0);
drop table score;
create table score (sno int, cno int, degree int);
insert into score values (1, 10, 100);
insert into score values (1, 11, 89);
insert into score values (2, 10, 99);
insert into score values (2, 11, 90);
insert into score values (3, 10, 87);
insert into score values (3, 11, 20);
insert into score values (4, 10, 60);
insert into score values (4, 11, 70);
case1
SELECT * FROM STUDENT a WHERE a.sno > ANY (SELECT b.sno from STUDENT b);
sno | sname | ssex
-----+-------+------
2 | stu2 | 1
3 | stu3 | 1
4 | stu4 | 0
explain SELECT * FROM STUDENT a WHERE a.sno > ANY (SELECT b.sno from STUDENT b);
QUERY PLAN
-------------------------------------------------------------------------------------------
Nested Loop Semi Join (cost=0.15..208.42 rows=367 width=46)
-> Seq Scan on student a (cost=0.00..21.00 rows=1100 width=46)
-> Index Only Scan using student_pkey on student b (cost=0.15..6.62 rows=367 width=4)
Index Cond: (sno < a.sno)
首先从逻辑上分析这条SQL是可以做子连接提升的,因为子连接中的结果sno和外部表达式判断的sno是同一字段,这样a表可以作为半连接的外表,b表作为内表,利用半连接的特性,一旦内表找到一条连接终止。这样就实现了any的语义,也没有生成subplan,提升了性能。
下面是一个反例:
这里的子连接无法提升,因为子连接的结果集cno和外部判断条件ssex没有关系,只能生成subplan拿到所有结果后返回给上层,这种执行计划效率明显是不如上面case。
case2
explain SELECT * FROM student WHERE ssex < ANY (SELECT cno FROM score WHERE student.sno = student.sno);
QUERY PLAN
-----------------------------------------------------------------------
Seq Scan on student (cost=0.00..19551.50 rows=550 width=46)
Filter: (SubPlan 1)
SubPlan 1
-> Result (cost=0.00..30.40 rows=2040 width=4)
One-Time Filter: (student.sno = student.sno)
-> Seq Scan on score (cost=0.00..30.40 rows=2040 width=4)
2 代码分析
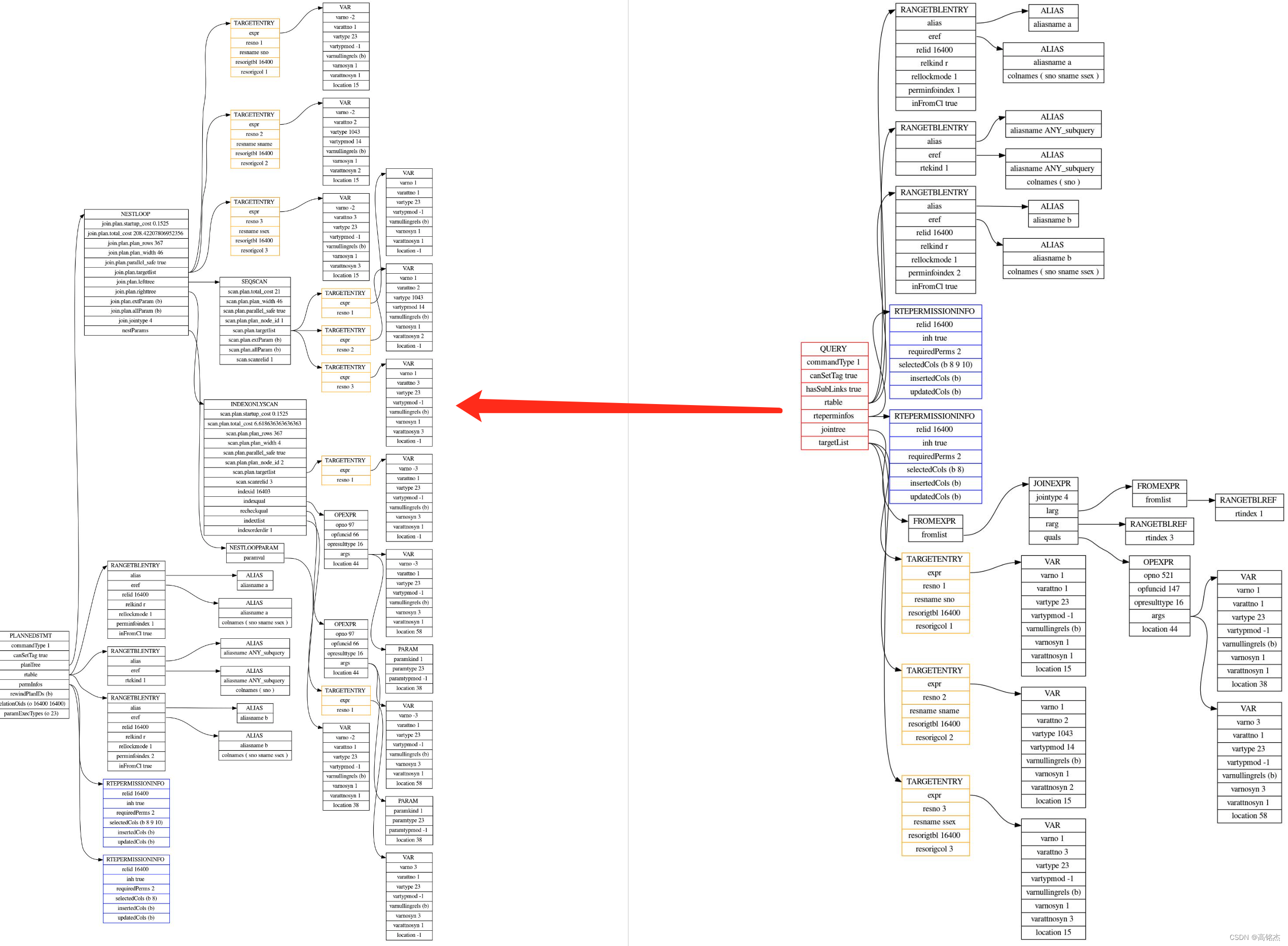
下面以explain SELECT * FROM STUDENT a WHERE a.sno > ANY (SELECT b.sno from STUDENT b); 为例,尝试分析这条SQL是如何做逻辑优化的。
2.1 打印Query结构
p elog_node_display(LOG, "parse tree", root->parse, true)
日志中获取
2023-05-29 11:32:51.634 CST,"mingjie","postgres",14113,"[local]",647408f7.3721,7,"EXPLAIN",2023-05-29 10:07:51 CST,3/59095,0,LOG,00000,"parse tree:"," {QUERY
:commandType 1
:querySource 0
:canSetTag true
:utilityStmt <>
:resultRelation 0
...
...
导入pgNodeGraph工具,生成结果:

2.2 pull_up_sublinks_jointree_recurse
recurse第一层:pull_up_sublinks_jointree_recurse
pull_up_sublinks_jointree_recurse
else if (IsA(jtnode, FromExpr))
FromExpr *f = (FromExpr *) jtnode;
foreach(l, f->fromlist)
newchild = pull_up_sublinks_jointree_recurse(root, lfirst(l), &childrelids);

recurse第二层:pull_up_sublinks_jointree_recurse
pull_up_sublinks_jointree_recurse
else if (IsA(jtnode, RangeTblRef))
// varno == 1
int varno = ((RangeTblRef *) jtnode)->rtindex;
*relids = bms_make_singleton(varno);
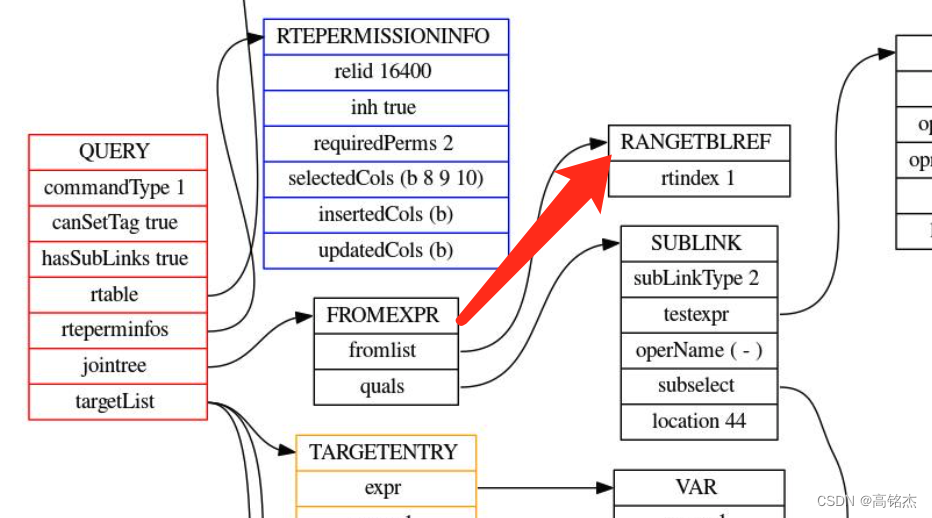
recurse退回第一层:pull_up_sublinks_jointree_recurse
else if (IsA(jtnode, FromExpr))
foreach(l, f->fromlist)
pull_up_sublinks_jointree_recurse // 执行结束
...
newf->quals = pull_up_sublinks_qual_recurse(root, f->quals,
&jtlink, frelids,
NULL, NULL);
传入SUBLINK

recurse进入pull_up_sublinks_qual_recurse→convert_ANY_sublink_to_join处理quals
收到SUBLINK
第一步:contain_vars_of_level检查子连接里面有没有引用父Query的var,如果没有可以继续,walker函数为contain_vars_of_level_walker,只检查Var、CurrentOfExpr、PlaceHolderVar;如果发现还有子Query,把context记录的sublevels_up++(一开始是0)后,在进去递归子Query;因为该逻辑只是检查有没有相邻的上层引用,跨层不管。
pull_up_sublinks_qual_recurse
if (IsA(node, SubLink))
convert_ANY_sublink_to_join
if (contain_vars_of_level((Node *) subselect, 1))
return NULL;
...
...
contain_vars_of_level函数调用walker宏遍历sublink树。
bool
contain_vars_of_level(Node *node, int levelsup)
{
int sublevels_up = levelsup;
return query_or_expression_tree_walker(node,
contain_vars_of_level_walker,
(void *) &sublevels_up,
0);
}

第二步:pull_varnos检查子连接的test表达式必须包含父查询的var,否则也没办法改成join。
pull_up_sublinks_qual_recurse
if (IsA(node, SubLink))
convert_ANY_sublink_to_join
if (contain_vars_of_level((Node *) subselect, 1))
return NULL;
...
...
upper_varnos = pull_varnos(root, sublink->testexpr);
if (bms_is_empty(upper_varnos))
return NULL;
pull_varnos函数
Relids
pull_varnos(PlannerInfo *root, Node *node)
{
pull_varnos_context context;
context.varnos = NULL;
context.root = root;
context.sublevels_up = 0;
query_or_expression_tree_walker(node,
pull_varnos_walker,
(void *) &context,
0);
return context.varnos;
}
遍历完成后,记录了一个varno==1到upper_varnos中。

第三步:convert_ANY_sublink_to_join构造新的join结构
{JOINEXPR
:jointype 4
:isNatural false
:larg <>
:rarg
{RANGETBLREF
:rtindex 2
}
:usingClause <>
:join_using_alias <>
:quals
{OPEXPR
:opno 521
:opfuncid 147
:opresulttype 16
:opretset false
:opcollid 0
:inputcollid 0
:args (
{VAR
:varno 1
:varattno 1
:vartype 23
:vartypmod -1
:varcollid 0
:varnullingrels (b)
:varlevelsup 0
:varnosyn 1
:varattnosyn 1
:location 38
}
{VAR
:varno 2
:varattno 1
:vartype 23
:vartypmod -1
:varcollid 0
:varnullingrels (b)
:varlevelsup 0
:varnosyn 2
:varattnosyn 1
:location -1
}
)
:location 44
}
:alias <>
:rtindex 0
}
convert_ANY_sublink_to_join返回JoinExpr结构
第四步:pull_up_sublinks_qual_recurse继续补完JoinExpr结构
2.3 pull_up_sublinks返回新的jointree
2.4 (逻辑解析最后形态)pull_up_subqueries子查询合并到rangetblentry
2.5 grouping_planner后