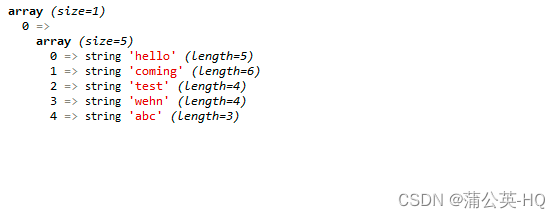语法
. (点) 匹配除换行符(\n、\r)之外的任何单个字符,相等于 [^\n\r]。
[\s\S] 匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行。
\d [0-9]
\D 非数字;
\w 匹配字母、数字、下划线。等价于 [A-Za-z0-9_];
\W 匹配\w的补集;

字符范围
$str = 'baidu o2o c2c xiling shuai 123 chou bage ';
//$patt= '/\b[a-zA-Z]+\b/';//加号表示多个不限;
$patt= '/\b[a-zA-Z]{5,}\b/';//最少有5个;
preg_match_all($patt,$str,$arr);
var_dump($arr);
结果:

找几个
- *( 匹配前面的子表达式零次或多次);
- +匹配前面的子表达式一次或多次;
- ?匹配前面的子表达式零次或一次;
- {n}n是一个非负整数。匹配确定的n次;
- {n,m}m和n均为非负整数,其中n<=m,最少匹配n次,最多匹配m次;
- {n,}n是一个非负整数。至少匹配n次;
$str='god goood gooooooood';
$patt='/go+d/';
echo preg_replace($patt,'god',$str);

或者的 用法 |
$str = '211 hello 0210oo dkj44';
$patt = '/\b[a-zA-Z]+\b|\b\d+\b/';
preg_match_all($patt,$str,$res);
var_dump($res);
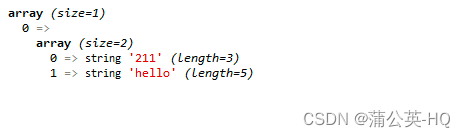
贪婪与非贪婪(正则默认是贪婪模式,在数量(+ * {n,})限定符后加?,非贪婪模式)
$str = 'ipad,iphone,imac,ipod,iamsorry,goood, god goooooooood jkl ljklkjklj';
//$patt = '/\bg.+d\b/';//贪婪模式 一直往后找
$patt = '/\bg.+?d\b/';//非贪婪模式 找到一个算一个
preg_match_all($patt,$str,$res);
var_dump($res);
贪婪模式结果

非贪婪模式结果

采集手机号
$str = '老王 买西瓜 联系15069091069,备用 电话 19935198152 QQ :1097848288,email 1097848289@qq.com,
xiguoahao 4576541244515069891526';
$patt = '/\b1[35879]\d{9}\b/';
preg_match_all($patt,$str,$res);
var_dump($res);

后向引用(第n个小括号内得子表达式,命中得内容,后面就佣\n来引用)
//找出首尾字母相同得单词
$str = 'txt hidffd hfihui jlkjlkj iuj hello bom mum';
$patt = '/\b([a-z])\w+\1\b/';
preg_match_all($patt,$str,$res);
var_dump($res);

//把手机号中间四位换成*
$str = '15069106959 19935198152';
$patt = '/\b(\d{3})\d{4}(\d{4})\b/';
//preg_match_all($patt,$str,$res);
$res=preg_replace($patt,'\1****\2',$str);
var_dump($res);

模式
模式修饰符,可以在一定程度上影响正则得解析行为
比如i,就代表正则不区分大小写,/[a-zA-Z]+/----->/[a-z]+/i
比如s,单行模式,就代表把整个文件看成一个“单行”
比如u 匹配中文
$str = 'hello world Chlha worLD';
//$patt = '/\b[a-z]+\b/'; //只匹配小写字母单词
$patt = '/\b[a-z]+\b/i'; //不区分大小写
preg_match_all($patt,$str,$res);
var_dump($res);


验证是否纯中文
$str = '时';
$patt = '/^[\x{4e00}-\x{9fa5}]$/u';// \x 按ASCII码查,大括号中是对应的码
echo preg_match_all($patt,$str)?'chun':'zha';
预查
//取ing结尾得单词得词根
$str = 'hello working coming test wehn i am';
//前瞻 断言 正预测 零宽度
$patt = '/\b\w+(?=ing\b)/';//?=ing 后面是ing
preg_match_all($patt,$str,$res);
var_dump($res);
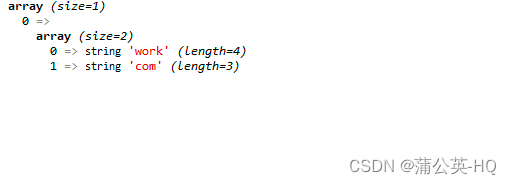
$str = 'hello unworking coming untest wehn i unam';
//零宽度 回顾 断言 正预测
$patt = '/(?<=\bun)\w+\b/';// < 往前看 正预测 是否 ,,, 是
preg_match_all($patt,$str,$res);
var_dump($res);

$str = 'hello unworking coming test wehn i am abc';
//前瞻 断言 负预测 零宽度
$patt = '/\b\w+(?!ing)\w{3}\b/';//满足3个且后三还不是ing得 单词长度大于3
preg_match_all($patt,$str,$res);
var_dump($res);

$str = 'hello unworking coming test wehn i am abc';
//找出不是un开头的单词
//回顾 断言 负预测 零宽度
$patt = '/\b\w{2}(?<!un)\w+\b/';
preg_match_all($patt,$str,$res);
var_dump($res);