clickhouse的数据备份和恢复功能在大数据运维中是非常常用的功能,目前也有很多比较优秀的开源方案可供选择,比如clickhouse-backup, 以及clickhouse自带的clickhouse-copier。
本文介绍使用clickhouse自带的BACKUP和RESTORE命令进行备份和恢复。
我认为,一个比较好的备份恢复工具,至少需要满足以下几个功能:
- 可以批量选择表
- 可以增量备份
- 可以比较方便地对数据进行恢复
- 支持集群操作
- 可以选择多个备份目的地,如Local、S3、HDFS等
- 为了方便恢复,元数据也需要一起备份
基本语法
BACKUP|RESTORE
TABLE [db.]table_name [AS [db.]table_name_in_backup]
[PARTITION[S] partition_expr [,...]] |
DICTIONARY [db.]dictionary_name [AS [db.]name_in_backup] |
DATABASE database_name [AS database_name_in_backup]
[EXCEPT TABLES ...] |
TEMPORARY TABLE table_name [AS table_name_in_backup] |
VIEW view_name [AS view_name_in_backup]
ALL TEMPORARY TABLES [EXCEPT ...] |
ALL DATABASES [EXCEPT ...] } [,...]
[ON CLUSTER 'cluster_name']
TO|FROM File('<path>/<filename>') | Disk('<disk_name>', '<path>/') | S3('<S3 endpoint>/<path>', '<Access key ID>', '<Secret access key>')
[SETTINGS base_backup = File('<path>/<filename>') | Disk(...) | S3('<S3 endpoint>/<path>', '<Access key ID>', '<Secret access key>')]
从该语法中,我们大致能读到以下信息:
- 可以指定某一张表的某个partition进行备份
- 可以指定某个数据库进行备份,且可以剔除该数据库中的某些表不进行备份
- 可以备份临时表,视图
- 可以全量备份所有表,所有数据库(支持黑名单排除)
- 支持在集群上做备份
- 支持备份到File、Disk和S3
- 支持压缩备份
- 支持增量备份
接下来我们以实战的方式,演示一下该命令的一些操作。
备份到文件
准备工作
配置准备
首先,我们需要在配置文件中加入以下内容:
<clickhouse>
<backups>
<allowed_path>/data01/backup</allowed_path>
</backups>
</clickhouse>
代表允许备份,且备份目录为/data01/backup。
数据准备
我当前集群信息如下:
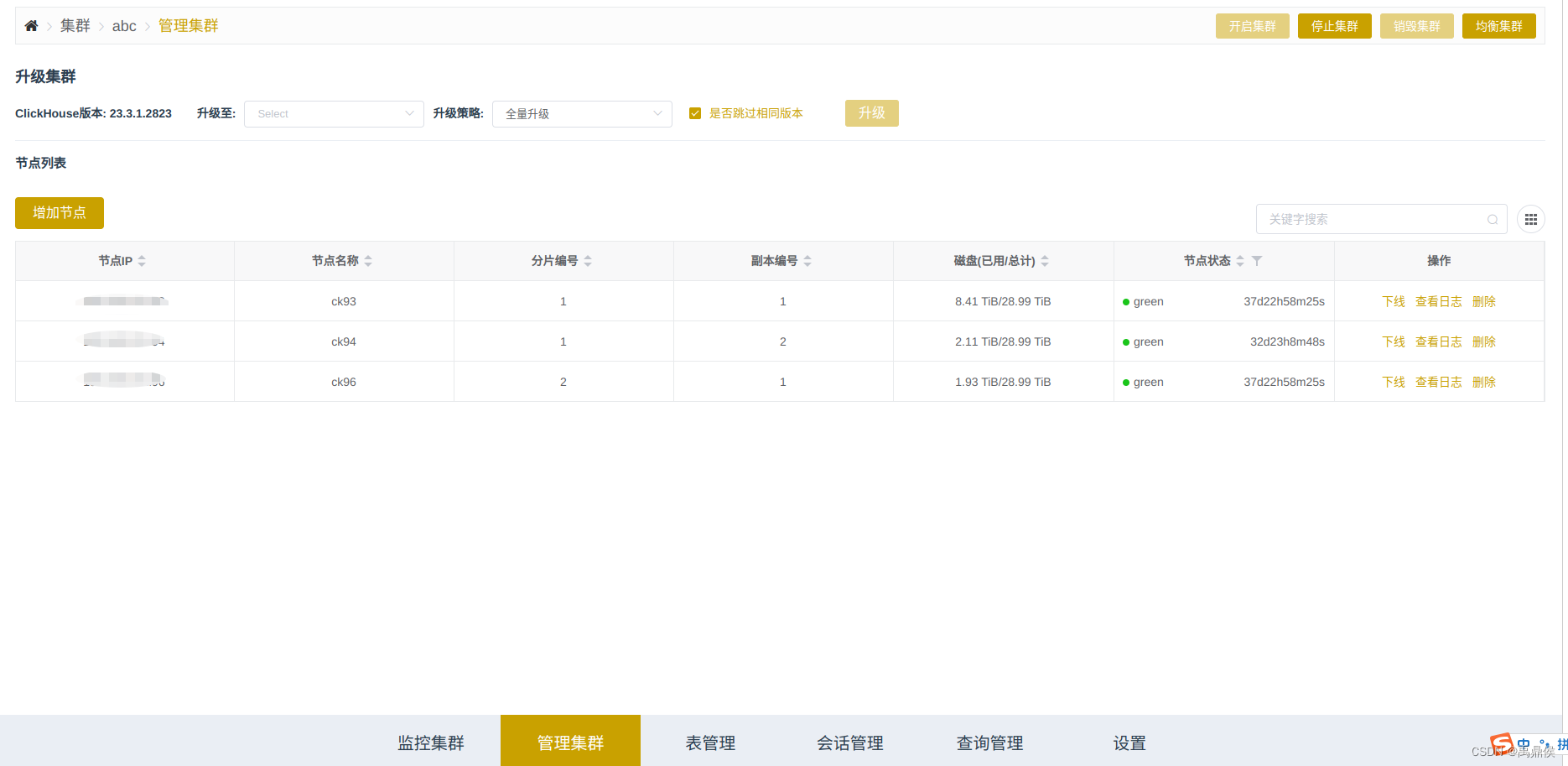
该集群有3个节点 ,其中ck93和ck94组成一个分片,ck96单独一个分片。
我们在集群上创建一张表,并导入一些数据:
CREATE TABLE t1 ON CLUSTER abc
(
`id` Int64,
`timestamp` DateTime,
`value` Float32
)
ENGINE = ReplicatedMergeTree
PARTITION BY toYYYYMMDD(timestamp)
ORDER BY (id, timestamp)
并向该表写入了1亿条数据:
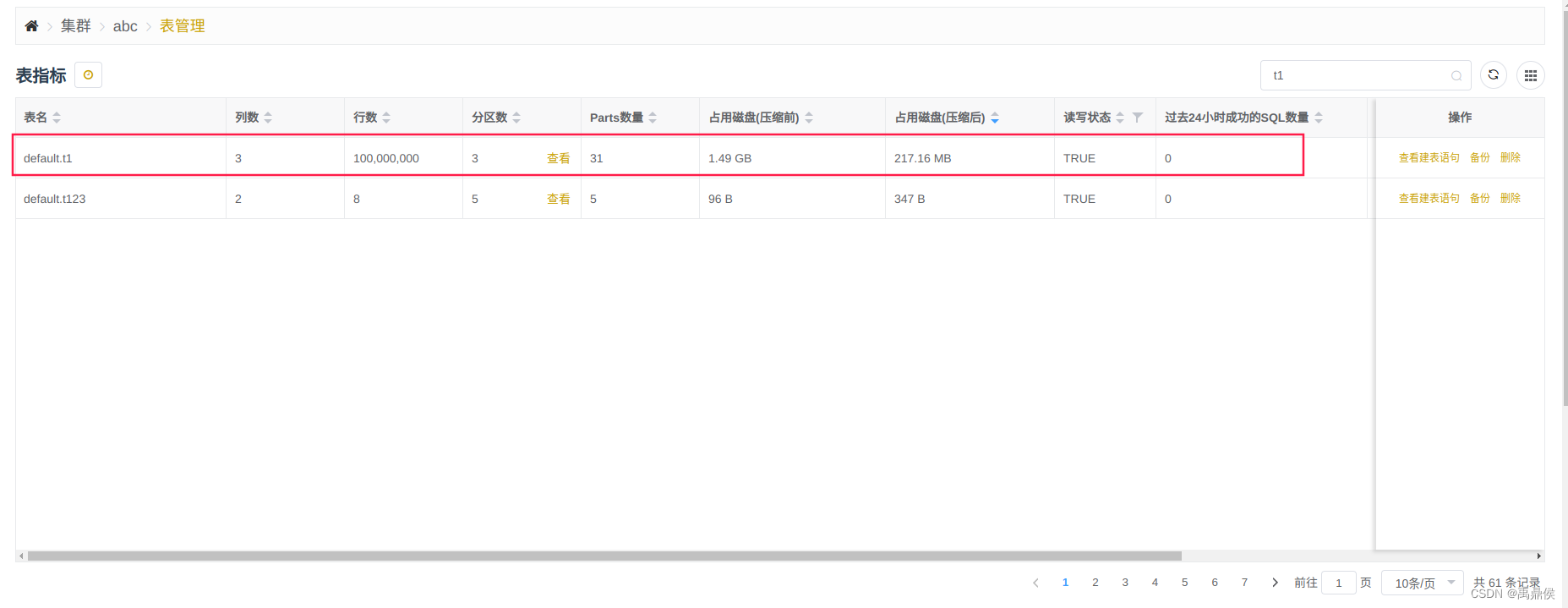
数据分布如下:
--shard1
ck94 :) select count() from t1;
SELECT count()
FROM t1
Query id: a9b4610b-daa9-48b3-806b-3136657d2d9e
┌──count()─┐
│ 50000000 │
└──────────┘
1 row in set. Elapsed: 0.002 sec.
--shard2
ck96 :) select count() from t1;
SELECT count()
FROM t1
Query id: f655d9ce-0176-4220-8e35-69d2261fc60d
┌──count()─┐
│ 50000000 │
└──────────┘
1 row in set. Elapsed: 0.003 sec.
备份
分别在shard1和shard2上执行backup命令如下:
--shard1
ck94 :) backup table default.t1 to File('20230528');
BACKUP TABLE default.t1 TO File('20230528')
Query id: c1214b1c-dc84-48f4-9d01-c9adebf21bf3
┌─id───────────────────────────────────┬─status─────────┐
│ 1d30a0c9-4094-43b7-b2b6-9645e79d7fc1 │ BACKUP_CREATED │
└──────────────────────────────────────┴────────────────┘
1 row in set. Elapsed: 0.050 sec.
--shard2
ck96 :) backup table default.t1 to File('20230528');
BACKUP TABLE default.t1 TO File('20230528')
Query id: 40df720f-8c2c-47c1-97d1-035186becac2
┌─id───────────────────────────────────┬─status─────────┐
│ 30c9a090-f6a5-4055-a157-5747b1d0772c │ BACKUP_CREATED │
└──────────────────────────────────────┴────────────────┘
1 row in set. Elapsed: 0.049 sec.
执行完成后,在ck94的/data01/backup目录下,有如下数据生成:
[root@ck94 backup]# tree
20230528/
├── data
│ └── default
│ └── t1
│ ├── 20230416_0_20_4
│ │ ├── checksums.txt
│ │ ├── columns.txt
│ │ ├── count.txt
│ │ ├── default_compression_codec.txt
│ │ ├── id.bin
│ │ ├── id.mrk2
│ │ ├── minmax_timestamp.idx
│ │ ├── partition.dat
│ │ ├── primary.idx
│ │ ├── timestamp.bin
│ │ ├── timestamp.mrk2
│ │ ├── value.bin
│ │ └── value.mrk2
│ ├── 20230416_21_51_6
│ │ ├── checksums.txt
│ │ ├── count.txt
│ │ ├── id.bin
│ │ ├── id.mrk2
│ │ ├── primary.idx
│ │ ├── timestamp.bin
│ │ ├── timestamp.mrk2
│ │ ├── value.bin
│ │ └── value.mrk2
│ ├── 20230416_52_52_0
│ │ ├── checksums.txt
│ │ ├── count.txt
│ │ ├── data.bin
│ │ ├── data.mrk3
│ │ ├── minmax_timestamp.idx
│ │ └── primary.idx
│ ├── 20230416_53_53_0
│ │ ├── checksums.txt
│ │ ├── count.txt
│ │ ├── data.bin
│ │ ├── data.mrk3
│ │ └── primary.idx
│ ├── 20230423_0_5_1
│ │ ├── checksums.txt
│ │ ├── count.txt
│ │ ├── id.bin
│ │ ├── id.mrk2
│ │ ├── minmax_timestamp.idx
│ │ ├── partition.dat
│ │ ├── primary.idx
│ │ ├── timestamp.bin
│ │ ├── timestamp.mrk2
│ │ ├── value.bin
│ │ └── value.mrk2
│ ├── 20230423_12_12_0
│ │ ├── checksums.txt
│ │ ├── count.txt
│ │ ├── id.bin
│ │ ├── id.mrk2
│ │ ├── primary.idx
│ │ ├── timestamp.bin
│ │ ├── timestamp.mrk2
│ │ ├── value.bin
│ │ └── value.mrk2
│ ├── 20230423_13_13_0
│ │ ├── checksums.txt
│ │ ├── id.bin
│ │ ├── id.mrk2
│ │ ├── primary.idx
│ │ ├── timestamp.bin
│ │ ├── timestamp.mrk2
│ │ ├── value.bin
│ │ └── value.mrk2
│ ├── 20230423_14_14_0
│ │ ├── checksums.txt
│ │ ├── id.bin
│ │ ├── id.mrk2
│ │ ├── minmax_timestamp.idx
│ │ ├── primary.idx
│ │ ├── timestamp.bin
│ │ ├── timestamp.mrk2
│ │ ├── value.bin
│ │ └── value.mrk2
│ ├── 20230423_15_15_0
│ │ ├── checksums.txt
│ │ ├── count.txt
│ │ ├── data.bin
│ │ ├── data.mrk3
│ │ └── primary.idx
│ ├── 20230423_16_16_0
│ │ ├── checksums.txt
│ │ ├── count.txt
│ │ ├── data.bin
│ │ ├── data.mrk3
│ │ ├── minmax_timestamp.idx
│ │ └── primary.idx
│ ├── 20230423_6_11_1
│ │ ├── checksums.txt
│ │ ├── id.bin
│ │ ├── id.mrk2
│ │ ├── primary.idx
│ │ ├── timestamp.bin
│ │ ├── timestamp.mrk2
│ │ ├── value.bin
│ │ └── value.mrk2
│ ├── 20230424_0_5_1
│ │ ├── checksums.txt
│ │ ├── id.bin
│ │ ├── id.mrk2
│ │ ├── minmax_timestamp.idx
│ │ ├── partition.dat
│ │ ├── primary.idx
│ │ ├── timestamp.bin
│ │ ├── timestamp.mrk2
│ │ ├── value.bin
│ │ └── value.mrk2
│ ├── 20230424_12_12_0
│ │ ├── checksums.txt
│ │ ├── id.bin
│ │ ├── id.mrk2
│ │ ├── primary.idx
│ │ ├── timestamp.bin
│ │ ├── timestamp.mrk2
│ │ ├── value.bin
│ │ └── value.mrk2
│ ├── 20230424_13_13_0
│ │ ├── checksums.txt
│ │ ├── id.bin
│ │ ├── id.mrk2
│ │ ├── primary.idx
│ │ ├── timestamp.bin
│ │ ├── timestamp.mrk2
│ │ ├── value.bin
│ │ └── value.mrk2
│ ├── 20230424_14_14_0
│ │ ├── checksums.txt
│ │ ├── id.bin
│ │ ├── id.mrk2
│ │ ├── primary.idx
│ │ ├── timestamp.bin
│ │ ├── timestamp.mrk2
│ │ ├── value.bin
│ │ └── value.mrk2
│ ├── 20230424_15_15_0
│ │ ├── checksums.txt
│ │ ├── id.bin
│ │ ├── id.mrk2
│ │ ├── primary.idx
│ │ ├── timestamp.bin
│ │ ├── timestamp.mrk2
│ │ ├── value.bin
│ │ └── value.mrk2
│ ├── 20230424_16_16_0
│ │ ├── checksums.txt
│ │ ├── id.bin
│ │ ├── id.mrk2
│ │ ├── primary.idx
│ │ ├── timestamp.bin
│ │ ├── timestamp.mrk2
│ │ ├── value.bin
│ │ └── value.mrk2
│ └── 20230424_6_11_1
│ ├── checksums.txt
│ ├── id.bin
│ ├── id.mrk2
│ ├── primary.idx
│ ├── timestamp.bin
│ ├── timestamp.mrk2
│ ├── value.bin
│ └── value.mrk2
└── metadata
└── default
└── t1.sql
ck98目录同样也是如此,这里就不贴出来了。
从以上目录结构,可以看出,备份的文件分为data和metadata两个子目录、data用来存储数据,metadata用来存储表结构,并且内部根据数据库、表、partition做了层级区分。
看一下ck96上备份目录大小:
[root@ck94 backup]# du -sh 20230528/
108M 20230528/
[root@ck96 backup]# du -sh 20230528/
112M 20230528/
可见备份的数据也是压缩后的数据。(压缩前有1.49G)
接下来,我们试试直接在集群层面进行备份:
ck94 :) backup table default.t1 on cluster abc to File('abc_20230528');
BACKUP TABLE default.t1 ON CLUSTER abc TO File('abc_20230528')
Query id: e0763743-a6bc-430a-a28b-c493c7fd6478
0 rows in set. Elapsed: 0.188 sec.
Received exception from server (version 23.3.1):
Code: 655. DB::Exception: Received from localhost:19000. DB::Exception: Got error from 192%2E168%2E101%2E93:19000. DB::Exception: Lock file .lock suddenly disappeared while writing backup File('abc_20230528'). (FAILED_TO_SYNC_BACKUP_OR_RESTORE)
它报了一个错,这个错误在github上有人提了issue:https://github.com/ClickHouse/ClickHouse/issues/41313,大意就是,在集群备份时,选取的备份的目录不能是各个节点自己的目录,需要一个远程共享目录(这一点对于to Disk是同样适用的)。这里我就没有尝试了,下次有暇可以测试一下使用NFS目录在集群层面进行备份。
由以上信息,可以得出以下结论:
- 备份速度非常快,1亿条数据基本不到1秒就能完成
- 备份的同时,元数据也进行了备份,因此可以快速恢复
- 备份是同比压缩备份的,不会出现数据膨胀
- 无法进行集群级别备份(除非设置为远程共享目录)
恢复
恢复主要使用RESTORE命令。
当原始表有数据时,直接恢复是会报错的:
ck94 :) RESTORE TABLE default.t1 FROM File('20230528');
RESTORE TABLE default.t1 FROM File('20230528')
Query id: e5d3eea4-5a58-4283-b9ce-d2fa9fa5fa1c
0 rows in set. Elapsed: 0.009 sec.
Received exception from server (version 23.3.1):
Code: 608. DB::Exception: Received from localhost:19000. DB::Exception: Cannot restore the table default.t1 because it already contains some data. You can set structure_only=true or allow_non_empty_tables=true to overcome that in the way you want: While restoring data of table default.t1. (CANNOT_RESTORE_TABLE)
原因是原表已经有数据了。解决方案有3个:
方案1:备份到另一张表
具体操作如下:
ck94 :) RESTORE TABLE default.t1 AS default.t2 FROM File('20230528');
RESTORE TABLE default.t1 AS default.t2 FROM File('20230528')
Query id: e39dc666-3a00-4556-b8df-69e0e8d7fb63
0 rows in set. Elapsed: 0.017 sec.
Received exception from server (version 23.3.1):
Code: 253. DB::Exception: Received from localhost:19000. DB::Exception: Replica /clickhouse/tables/abc/default/t1/1/replicas/192.168.101.94 already exists: While creating table default.t2. (REPLICA_ALREADY_EXISTS)
上述操作报了一个错,该报错的原因是我们在创建t2表时,zk路径已经存在了。
这是由于我们设置的zk默认路径如下:
<default_replica_name>{replica}</default_replica_name>
<default_replica_path>/clickhouse/tables/{cluster}/{database}/{table}/{shard}</default_replica_path>
而我们创建t1表时,指定的engine为ReplicatedMergeTree,没有带任何参数,默认使用的就是这个地址,因此我们创建t2表时,zoopath冲突,导致不能恢复成功。
我们尝试手动建表来恢复,仍然不能成功,原因是我们备份的元数据中,t1表的zoopath已经与t2表不一致了,无法恢复。
ck94 :) create table t2 on cluster abc AS t1 ENGINE=ReplicatedMergeTree() PARTITION BY toYYYYMMDD(timestamp) ORDER BY (id, timestamp);
CREATE TABLE t2 ON CLUSTER abc AS t1
ENGINE = ReplicatedMergeTree
PARTITION BY toYYYYMMDD(timestamp)
ORDER BY (id, timestamp)
Query id: 61d6f3eb-5c58-4e88-a5aa-63712d538d8c
┌─host───────────┬──port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ x.x.x.x │ 19000 │ 0 │ │ 2 │ 0 │
│ x.x.x.x │ 19000 │ 0 │ │ 1 │ 0 │
│ x.x.x.x │ 19000 │ 0 │ │ 0 │ 0 │
└────────────────┴───────┴────────┴───────┴─────────────────────┴──────────────────┘
3 rows in set. Elapsed: 0.115 sec.
ck94 :) RESTORE TABLE default.t1 AS default.t2 FROM File('20230528');
RESTORE TABLE default.t1 AS default.t2 FROM File('20230528')
Query id: fa2086ec-3a65-436e-b871-eb7cf960c11e
0 rows in set. Elapsed: 0.007 sec.
Received exception from server (version 23.3.1):
Code: 608. DB::Exception: Received from localhost:19000. DB::Exception: The table has a different definition: CREATE TABLE default.t2 (`id` Int64, `timestamp` DateTime, `value` Float32) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{cluster}/default/t2/{shard}', '{replica}') PARTITION BY toYYYYMMDD(timestamp) ORDER BY (id, timestamp) SETTINGS index_granularity = 8192 comparing to its definition in the backup: CREATE TABLE default.t2 (`id` Int64, `timestamp` DateTime, `value` Float32) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{cluster}/default/t1/{shard}', '{replica}') PARTITION BY toYYYYMMDD(timestamp) ORDER BY (id, timestamp) SETTINGS index_granularity = 8192: While checking table default.t2. (CANNOT_RESTORE_TABLE)
因此,这个方案无解,除非我们修改掉zoopath的规则。
方案2:设置允许非空表备份
ck94 :) RESTORE TABLE default.t1 FROM File('20230528') SETTINGS allow_non_empty_tables=true;
RESTORE TABLE default.t1 FROM File('20230528') SETTINGS allow_non_empty_tables = 1
Query id: 8bc125ef-5a48-4595-9b1a-977b62e98f4e
┌─id───────────────────────────────────┬─status───┐
│ 7f2662a8-8bab-4b4b-bdc3-24a3df5231f9 │ RESTORED │
└──────────────────────────────────────┴──────────┘
1 row in set. Elapsed: 0.114 sec.
这种方案是可行的,但是,我们查询一下恢复后的数据:
ck94 :) select count() from t1;
SELECT count()
FROM t1
Query id: 7510842d-7278-4bf7-9539-4c5c34b38043
┌───count()─┐
│ 100000000 │
└───────────┘
1 row in set. Elapsed: 0.002 sec.
ck94 :)
它在原有的数据基础上翻了个倍。等于说数据冗余了一倍,如果设置的不是去重的引擎,那么这些数据将一直存在,将会大大影响磁盘占用和查询效率。
因此,这种手段只适用于原表已经不存在,或者原表数据清空的情况下做恢复。
方案3: 设置仅恢复structure
ck94 :) RESTORE TABLE default.t1 FROM File('20230528') SETTINGS structure_only=true;
RESTORE TABLE default.t1 FROM File('20230528') SETTINGS structure_only = 1
Query id: 77ce87fd-2eb3-47df-8a96-3423c248a54d
┌─id───────────────────────────────────┬─status───┐
│ a0d63803-4b32-49be-983f-6d71d8c7451f │ RESTORED │
└──────────────────────────────────────┴──────────┘
1 row in set. Elapsed: 0.004 sec.
ck94 :) select count() from t1;
SELECT count()
FROM t1
Query id: cd0404cd-1dd0-49f0-a828-de3e6fa4e8d9
┌───count()─┐
│ 100000000 │
└───────────┘
1 row in set. Elapsed: 0.003 sec.
该操作数据并没有翻倍,但是,该操作仅仅是同步了表schema,并没有同步数据,假如原表数据因为某种原因缺失了(比如只剩下了100w条),当我们执行restore语句,仍然是100w条数据,而没有把原始的5000w条数据都恢复回来。
ck94 :) select count() from t1;
SELECT count()
FROM t1
Query id: b8f19f4a-0339-44d7-8618-f3d741ebc679
┌─count()─┐
│ 1000000 │
└─────────┘
1 row in set. Elapsed: 0.003 sec.
ck94 :) RESTORE TABLE default.t1 FROM File('20230528') SETTINGS structure_only=true;
RESTORE TABLE default.t1 FROM File('20230528') SETTINGS structure_only = 1
Query id: 94e70a0d-4910-4802-8af2-3606fc3a7a1e
┌─id───────────────────────────────────┬─status───┐
│ d18869cc-880a-42d0-9405-863e6ac33216 │ RESTORED │
└──────────────────────────────────────┴──────────┘
1 row in set. Elapsed: 0.003 sec.
ck94 :) select count() from t1;
SELECT count()
FROM t1
Query id: 32df3010-00c2-48a1-9f3d-cfc42c69ad12
┌─count()─┐
│ 1000000 │
└─────────┘
1 row in set. Elapsed: 0.002 sec.
如果表不存在,我们使用该命令进行恢复,也仅仅恢复的是表schema,而不是所有数据:
ck94 :) drop table t1 sync;
DROP TABLE t1 SYNC
Query id: f3a596b8-f18e-4606-908d-8da26d5efd37
Ok.
0 rows in set. Elapsed: 0.022 sec.
ck94 :) RESTORE TABLE default.t1 FROM File('20230528') SETTINGS structure_only=true;
RESTORE TABLE default.t1 FROM File('20230528') SETTINGS structure_only = 1
Query id: 5c27980f-857c-4b87-93ab-70375ef51c78
┌─id───────────────────────────────────┬─status───┐
│ 7191ab88-f59a-477b-924f-93ce34ed3dea │ RESTORED │
└──────────────────────────────────────┴──────────┘
1 row in set. Elapsed: 0.606 sec.
ck94 :) select count() from t1;
SELECT count()
FROM t1
Query id: 2a11f16e-11ad-44cd-88f7-66e0008f8c16
┌─count()─┐
│ 0 │
└─────────┘
1 row in set. Elapsed: 0.002 sec.
当然,如果表都不存在了,我们使用最原始的命令就能恢复:
ck94 :) RESTORE TABLE default.t1 FROM File('20230528');
RESTORE TABLE default.t1 FROM File('20230528')
Query id: efb398bb-8368-4aa8-9efa-dacb316faca0
┌─id───────────────────────────────────┬─status───┐
│ 54a3b913-e91e-456b-84ce-d3aa10237ff6 │ RESTORED │
└──────────────────────────────────────┴──────────┘
1 row in set. Elapsed: 0.146 sec.
ck94 :) select count() from t1;
SELECT count()
FROM t1
Query id: a6fa6b7b-834c-4c41-bf9c-658695b19bc7
┌──count()─┐
│ 50000000 │
└──────────┘
1 row in set. Elapsed: 0.003 sec.
增量备份
表的增量备份应该是数据备份最基本的需求,如果每次只支持全量备份,第一,效率上难以保证(虽然这种备份看起来速度很快,因为相当于直接拷贝了数据目录),二来磁盘空间限制,不太可能频繁全量备份。
我们在ck96上插入100条数据:
ck96 :) insert into t1 select * from t1 limit 100;
INSERT INTO t1 SELECT *
FROM t1
LIMIT 100
Query id: a4515af0-f32d-4af2-b4ec-fae2b08425e7
Ok.
0 rows in set. Elapsed: 0.010 sec.
ck96 :) select count() from t1;
SELECT count()
FROM t1
Query id: 63c7b438-3dcd-4ea7-bb98-c6ed90021eac
┌──count()─┐
│ 50000100 │
└──────────┘
1 row in set. Elapsed: 0.004 sec.
我们的诉求是只备份这增量的100条数据,而不备份存量的5000w条数据。
我们可以通过设置base_backup来完成,即:在某次备份的基础上进行备份。
操作如下:
ck96 :) backup table default.t1 to File('20230529') SETTINGS base_backup = File('20230528');
BACKUP TABLE default.t1 TO File('20230529') SETTINGS base_backup = File('20230528')
Query id: 41e871ae-63bf-420a-956d-254a18c7a4af
┌─id───────────────────────────────────┬─status─────────┐
│ dd5fcaf4-303c-4246-a255-f75ac664af4d │ BACKUP_CREATED │
└──────────────────────────────────────┴────────────────┘
1 row in set. Elapsed: 0.027 sec.
可以看到,在备份目录下,出现了20230529的目录:
[root@ck96 backup]# ll
total 8
drwxr-x--- 4 clickhouse clickhouse 4096 May 29 07:06 20230528
drwxr-x--- 3 clickhouse clickhouse 4096 May 29 07:38 20230529
[root@ck96 backup]# du -sh *
112M 20230528
72K 20230529
并且该目录是没有元数据的,只有数据目录:
[root@ck96 backup]# tree 20230529
20230529
└── data
└── default
└── t1
└── 20230416_55_55_0
├── checksums.txt
├── count.txt
├── data.bin
├── data.mrk3
├── minmax_timestamp.idx
└── primary.idx
查看count.txt,可见此次备份的数据条数为100条:
[root@ck96 backup]# cat 20230529/data/default/t1/20230416_55_55_0/count.txt
100[root@ck96 backup]#
备份到Disk
配置准备
我们在存储策略里增加一个backup的Disk:
<storage_configuration>
<disks>
<backup>
<path>/data01/ssd1/</path>
<type>local</type>
</backup>
</disks>
</storage_configuration>
然后在backups中增加允许备份的磁盘:
<backups>
<allowed_disk>backup</allowed_disk>
<allowed_path>/data01/backup</allowed_path>
</backups>
数据备份
我们仍以t1表为例, 备份命令为:
ck94 :) BACKUP TABLE default.t1 TO Disk('backup', 't1.zip');
BACKUP TABLE default.t1 TO Disk('backup', 't1.zip')
Query id: 07df2cf7-de21-4a9a-bf0d-98e96d5e5a08
Connecting to localhost:19000 as user default.
Connected to ClickHouse server version 23.3.1 revision 54462.
┌─id───────────────────────────────────┬─status─────────┐
│ e0765c7a-afe4-4475-843c-92769d7b8089 │ BACKUP_CREATED │
└──────────────────────────────────────┴────────────────┘
1 row in set. Elapsed: 2.754 sec.
可以看到,同样是5000w条数据,该操作就比直接备份到File要慢近100倍左右。它这个慢,主要在于,备份到File,是直接目录拷贝,而备份到Disk,则多了压缩的过程。
但是我们同时也看到,备份后的数据是以zip压缩的,压缩后数据大小为69M,比之原始数据的108M要小将近1倍。
[root@ck94 ssd1]# du -sh t1.zip
69M t1.zip
我们将该zip文件解压出来:
[root@ck94 ssd1]# du -sh *
108M data
4.0K metadata
69M t1.zip
可见原始数据仍然是108M大小 。
至于集群层面备份,以及增量备份 、数据恢复,与File都是一样的,这里就不多做演示了 。
还有一些精细的玩法,如备份到磁盘时对压缩包进行加密,仅备份某一个partition,以及指定压缩算法和压缩等级等。
由于Disk本身的特性,我们甚至可以将Disk设置到HDFS以及S3上,因此可以使用该功能,将数据直接备份到这些对象存储之上。
当然备份到S3,还有另外的方案。BACKUP和RESTORE命令是直接支持了备份到S3的。接下来我们就来演示一下。
备份到S3
S3环境准备
我们使用docker启动一个minio来模拟S3环境。启动命令如下:
docker run --restart=always -itd --name minio \
--publish 49000:9000 \
--publish 49001:9001 \
--privileged=true \
-e TZ="Asia/Shanghai" \
-e MINIO_ROOT_USER=minio \
-e MINIO_ROOT_PASSWORD=minio@123 \
-e MINIO_REGION_NAME=zh-west-1 \
bitnami/minio:latest
启动后,进入http://localhost:49001/browser 即可打开前端页面。

我们在用户名和密码处填写启动docker时传入的环境变量,即: minio/minio@123, 登陆进去后界面如下所示:
数据备份到S3需要以下信息:
- endpoint
- Access key ID
- Secret access key
endpoint我们已经有了,接下来我们创建一组access key。
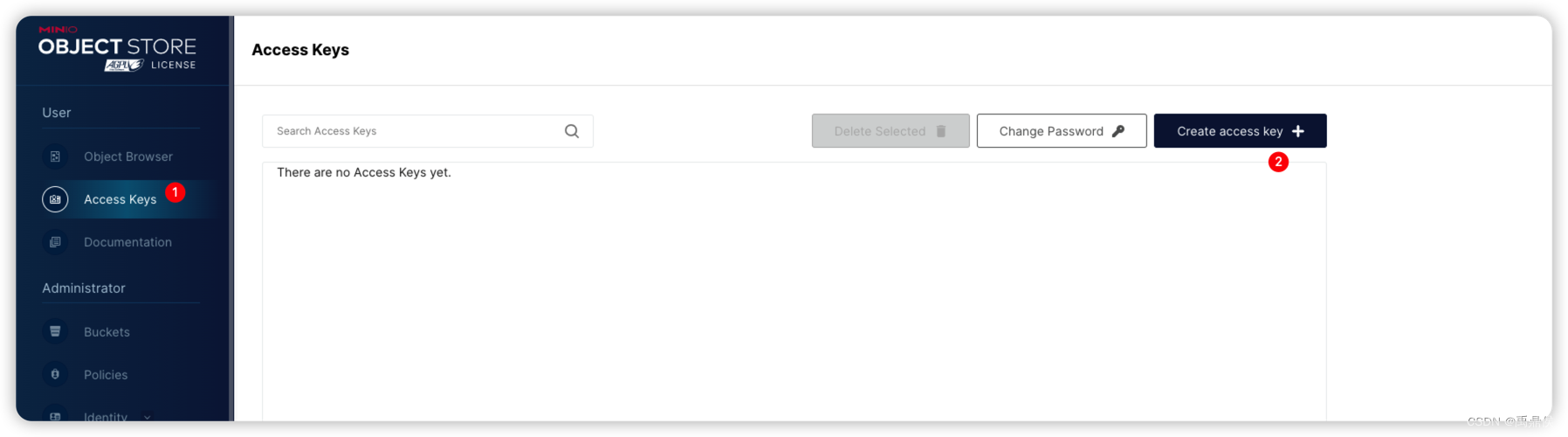
如下图所示,依次点击Access Keys, Create Access key:
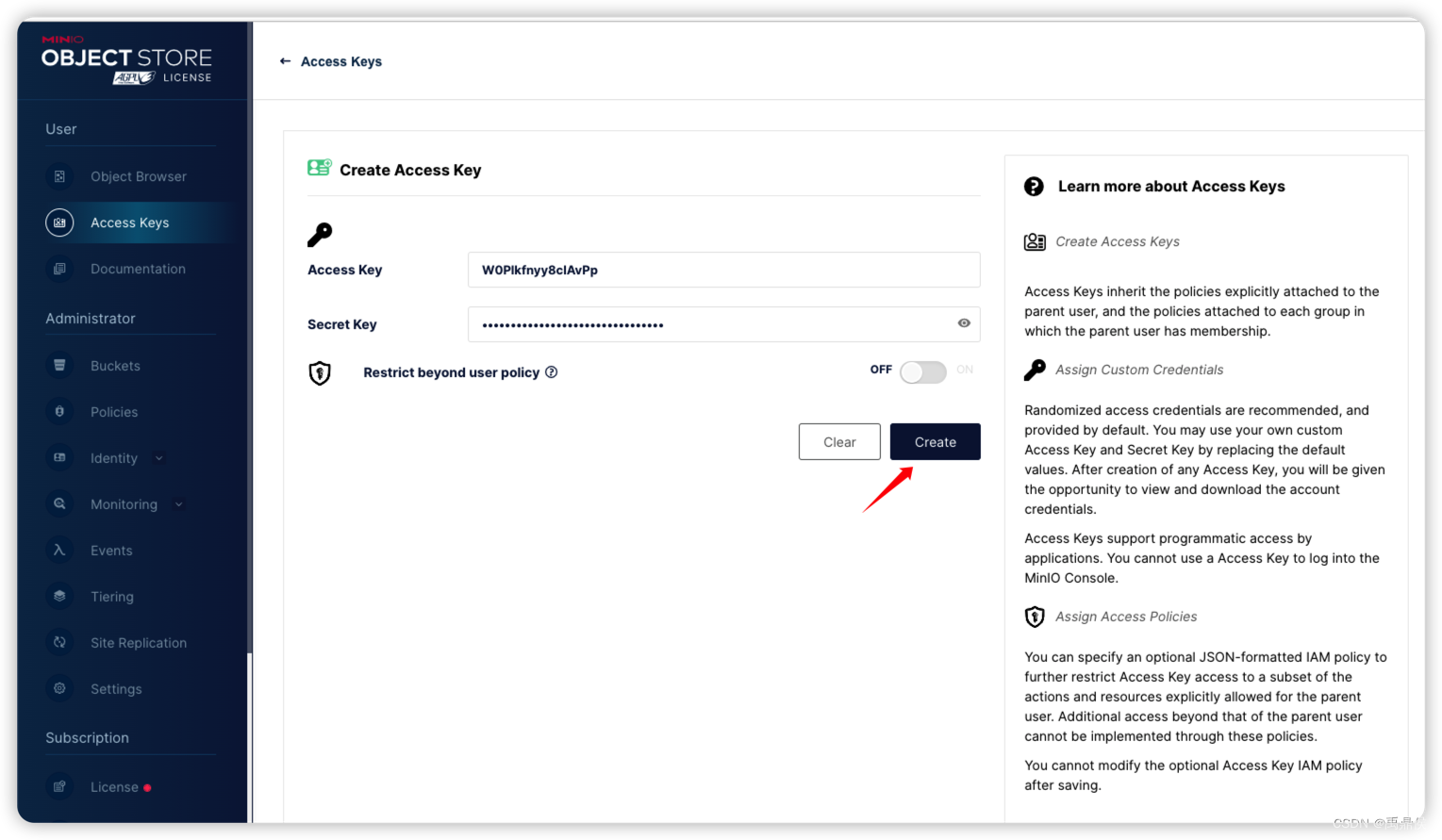
点击Create:
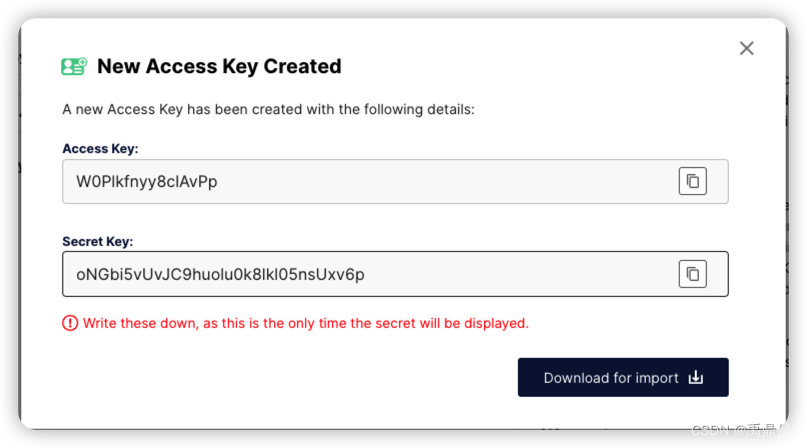
我们需要将这一组access key 和secret key记下来:
数据备份是要备份到bucket下面的,我们需要提前创建好bucket:
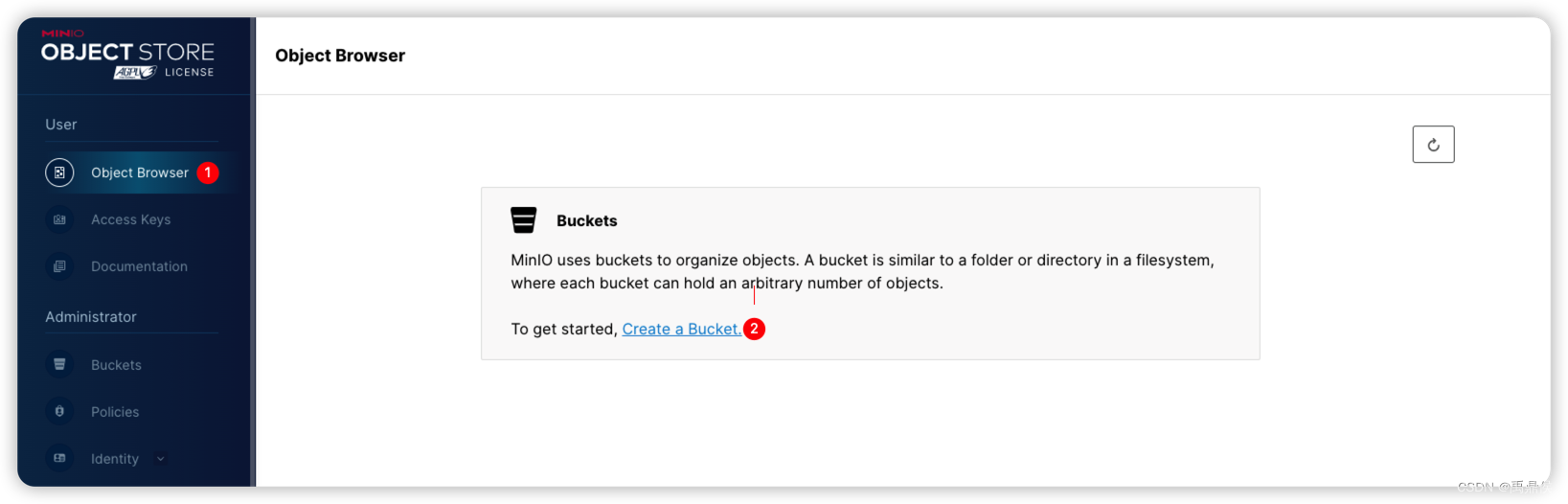
如图,我提前创建了一个名为backup的bucket:
至此,准备工作完成。
数据备份
我们依然备份t1表,命令如下:
ck94 :) BACKUP TABLE default.t1 TO S3('http://192.168.101.94:49000/backup/t1', 'W0Plkfnyy8clAvPp', 'oNGbi5vUvJC9huolu0k8lkl05nsUxv6p');
BACKUP TABLE default.t1 TO S3('http://192.168.101.94:49000/backup/t1', 'W0Plkfnyy8clAvPp', 'oNGbi5vUvJC9huolu0k8lkl05nsUxv6p')
Query id: a02479c8-d54e-4bdc-b3f6-0bb638754dcc
┌─id───────────────────────────────────┬─status─────────┐
│ 040d8cb6-7d2c-45c4-95ad-844aa4e87ce2 │ BACKUP_CREATED │
└──────────────────────────────────────┴────────────────┘
1 row in set. Elapsed: 0.515 sec.
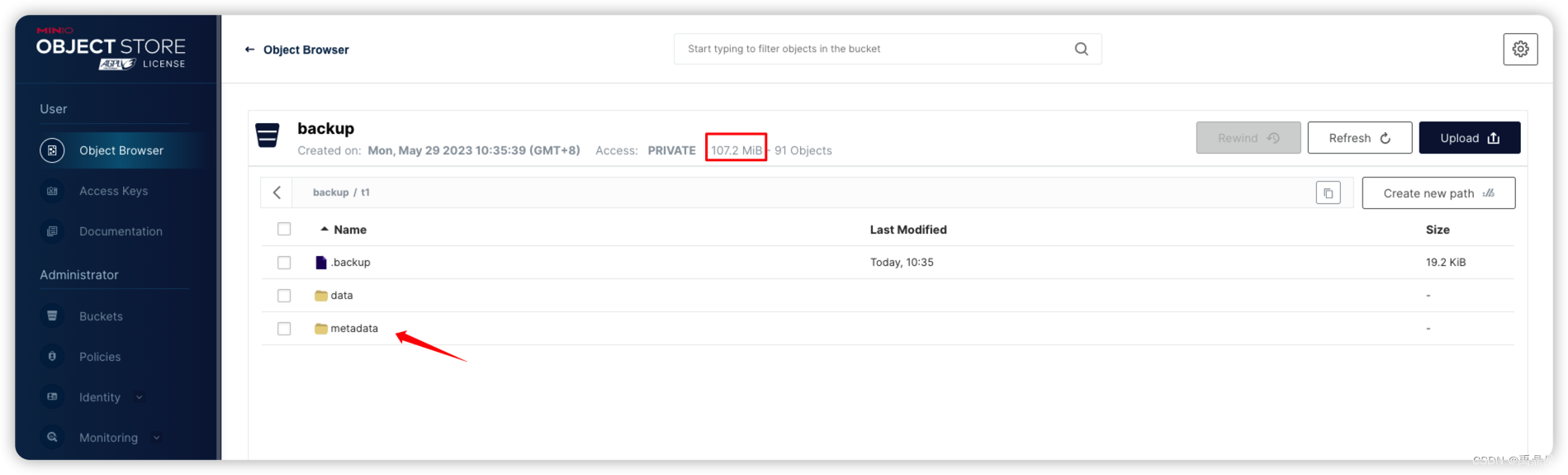
这时,我们上浏览器已经能查看到数据了:
我们尝试在集群上备份数据:
ck94 :) BACKUP TABLE default.t1 ON CLUSTER abc TO S3('http://192.168.101.94:49000/backup/t1_all', 'W0Plkfnyy8clAvPp', 'oNGbi5vUvJC9huolu0k8lkl05nsUxv6p');
BACKUP TABLE default.t1 ON CLUSTER abc TO S3('http://192.168.101.94:49000/backup/t1_all', 'W0Plkfnyy8clAvPp', 'oNGbi5vUvJC9huolu0k8lkl05nsUxv6p')
Query id: e88f933b-3f73-47e1-8502-25a44c8727cd
┌─id───────────────────────────────────┬─status─────────┐
│ a846e557-953e-4f9c-bbe2-d512baf0a030 │ BACKUP_CREATED │
└──────────────────────────────────────┴────────────────┘
1 row in set. Elapsed: 6.653 sec.
从它的目录排布,它已经自动按照shard做了区分:
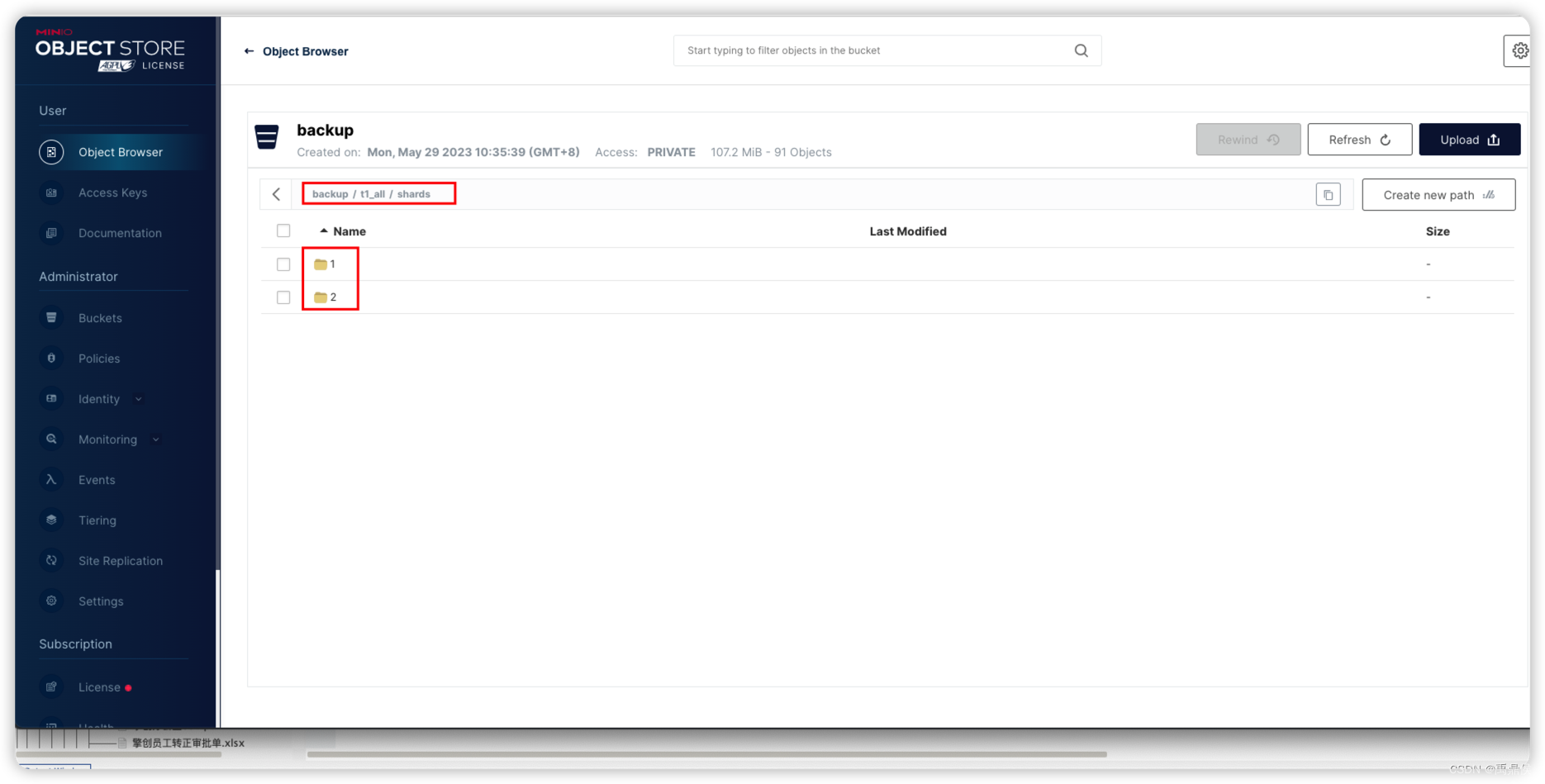
由于S3是远程共享目录,是可以执行的,不过整个执行过程比较耗时。1亿一条数据,用时接近6秒。不过从单节点备份只耗时0.5秒来看,该时间并不是随着数据量的增加而正比例递增的,而是主要耗时在与zookeeper的交互,获取元数据上。
增量备份与数据恢复与File类似,此处就不多做介绍了。
总结
BACKUP和RESTORE命令的备份恢复的优点是显而易见的:
- 无论是备份还是恢复,执行效率都非常高
- 同压缩比备份,支持不同的备份目的地
- 支持增量备份
但缺点也是有的,我认为主要是以下几点:
- 需要开放配置,操作性上不太友好
- 集群备份到本地时,必须要选共享目录,如果每个分片单独备份,则无法进行数据汇总,存留于节点自身,与没有备份没什么区别,还不如多加副本
- 数据恢复功能尚不太完备
推荐一个零声学院免费教程,个人觉得老师讲得不错,分享给大家:[Linux,Nginx,ZeroMQ,MySQL,Redis,
fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,
TCP/IP,协程,DPDK等技术内容,点击立即学习: C/C++Linux服务器开发/高级架构师