1.IOC
控制反转
把对象的生命周期的控制权由程序员反转给其他人。
控制反转减少了代码的耦合性。
哪里发生了反转?f
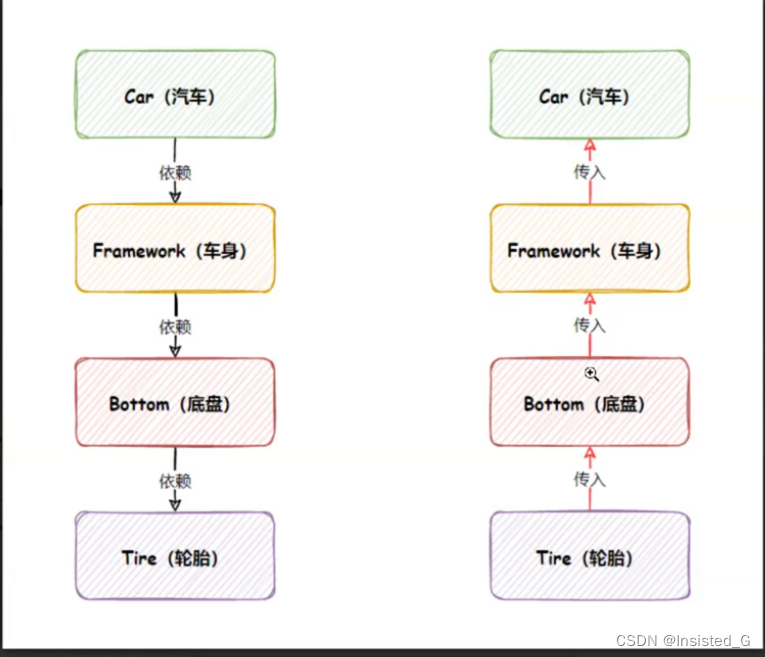
1.对象生命周期的控制权由程序员转交给Spring
2.对象创建的顺序反转了,原本程序员通过new来创建的是从外层到内层的,控制反转的话是从内到外的,内部改变的话由于要把内部传给外部,外部不需要改变。

2.Spring
Spring是一个包含了众多工具和方法的IOC容器
说白了就是Spring来帮助你管理对象的生命周期

3.DI
dependecy injection 依赖注入
DI就是在程序运行期间,动态的将某个对象引入当前类的机制/行为。



4.Spring项目的创建和bean对象的存取
Spring项目的创建
1.创建maven项目
2.引入spring.xml依赖在resource里面
存入Bean对象
1.创建Bean对象
Bean对象就是一个普通的对象
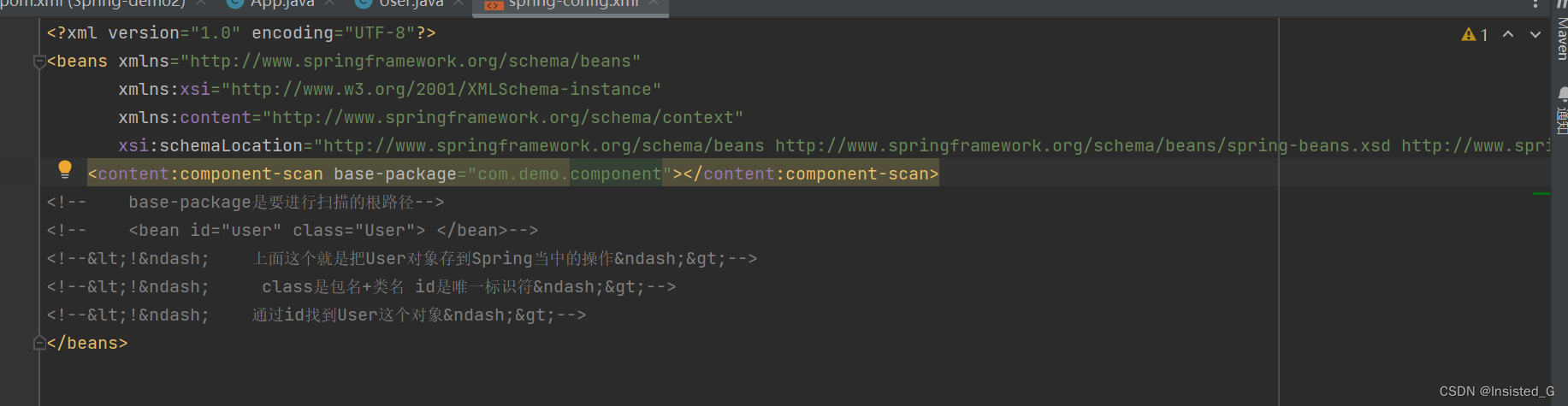
2.将类注册到Spring当中(逻辑上的存储,不是物理上的。只是声明了一下)
首先需要在resource里面配置Spring的配置文件
只需要在resource里面创建一个文件然后把spring配置文件CV进去。
添加配置文件的目的就是让Spring启动的时候把bean带进去启动

3.获取并使用bean对象
1.得到Spring对象(Spring上下文对象,一个意思)
2. 从spring中取出bean对象
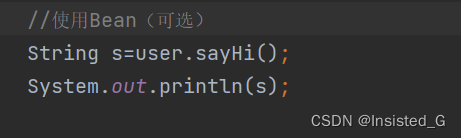
3.使用Bean


这个spring配置文件的目的就是告诉spring一些信息,比如说我写了这个

就是告诉Spring你加载的时候不要忘记带上我User类
xml就是记录一些要干的事情(记事本)是一个描述性的指导性文件

我们看到上面那个从spring中取出bean对象需要强转,那么如果getBean()里面的id不存在就会得到null,对null进行强转就会报错
不存在users,对null进行了强转
那么引出来了,另一种找到bean对象的方法
applicationContext.getBean("user",User.class) 第一个参数是id 第二个参数是类型(class) 这种是主推的获取bean对象的方法

5.ApplicationContext 和BeanFactory 的区别?

不必认为ApplicationContext加载所有的类会消耗资源,实际上Spring在设置的时候是根据你的硬件资源来决定加载多少的,硬件越强,加载的越多.
资源够的情况下,直接饿汉模式一次性全部加载,一般认为也是这样的
BeanFactory是懒加载,ApplicationContext是饿加载。后者性能高,并且后者是前者的子类,包含父类的所有方法,此外还有一些更多的功能......

总结:BeanFactory是懒汉模式,它在调用getBean方法的时候才会实例这个对象。
ApplicationContext是饿汉模式,它在实例化的时候已经实例化所有的bean对象
6.更好的方法去存取和读取bean对象(注解)
MySQL三大核心:连表查询 索引 和事务
1.前置工作:配置扫描bean的路径
2.添加注解
方法注解是将方法返回的对象存储到Spring当中(存到spring当中最小的是对象,不是方法)

五大类注解实现注解
1.Controller:控制器
2.Service :服务
3.Repository :仓库 repository
4.Component :组件
5.Configuration :配置
方法注解实现类注解
将当前方法返回的对象存储到Spring当中
7.注解的具体实现
就是在
写入路径,然后在类或者方法上加注解 在注册个Spring上下文getBean即可
8.五大类注解
为什么要有五种类注解呢?
1.通过类注解可以了解当前类的用途(比如看到车牌陕A就知道这是西安的车)
2.功能有轻微的不同