点个关注👆跟腾讯工程师学技术

引言| 足球作为世界第一运动,充满了速度和力量的结果,团队与谋略的对抗。人们也说,足球是圆的,恰恰也表明了足球比赛的不可预知性,一切结果都皆有可能。强如巴萨,也有可能被联赛副班长逆转,弱如第三世界的朝鲜队也可闯进世界杯八强。天气、场地、球星、战术、伤病、裁判,每一个因素都可能会影响一场比赛的结果。有言道,在足球比赛里,不到最后一刻,你永远不知道事情的结果。对于足彩爱好者来说,不仅在欣赏足球荡气回肠、悬念丛生的魅力,更是在与博彩公司进行一场心理与策略的博弈(其实是为了投注赚钱)。彩民看基本面,算计博彩盘口、统计历史战绩,只希望在投注前猜中比赛结果。
伟大的福尔特博·普利迪特说过:球无假球,盘皆假盘,信息的不对称才是造成贫富差距的根本原因。在这大数据时代,能否在数据的帮助下,减少这种信息的不对称,从而成功地对足球比赛进行预测?本文从数据层面出发,通过挖掘足球比赛相关的数据特征,结合机器学习的模型方法,对足球比赛的胜、平、负结果进行预测。进一步根据预测结果指导足彩单场竞猜的投注,以期实现有效盈利,甚至是稳定盈利的投注方法。
挖掘足球比赛数据特征
构建预测模型
预测比赛结果概率(胜、平、负)
分析足彩投注策略
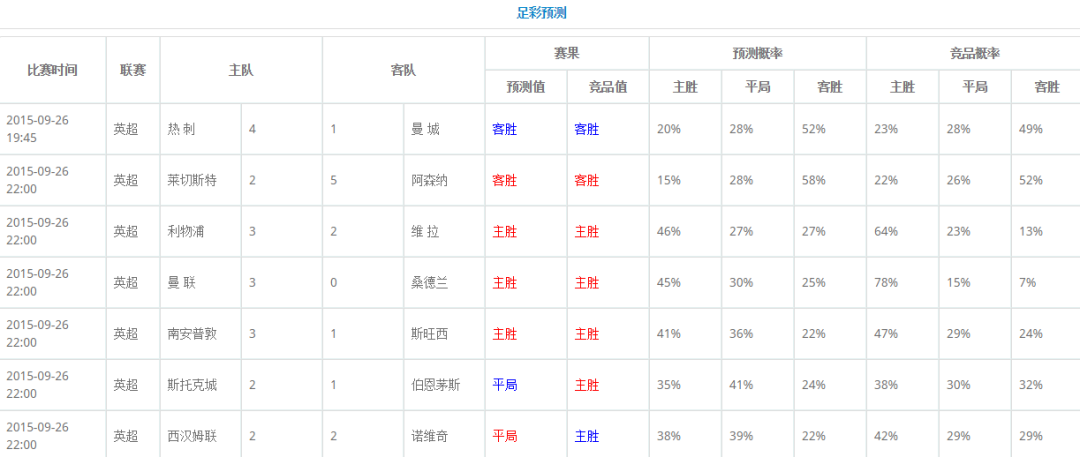
在使用本文提出的投注策略下,对英超2015赛季100场比赛,投注了其中20场比赛。若均为单注投注(2元一注),投注20场比赛可盈利22.18元,盈利率达到55%!下面将以2015年的欧洲五大联赛数据为例,详细地介绍如何通过数据和简单的机器学习方法,构建一个实用有效的足彩预测系统。

足彩预测
“我们可以把宇宙现在的状态视为其过去的果以及未来的因。如果一个智者能知道某一刻所有自然运动的力和所有自然构成的物件的位置,假如他也能够对这些数据进行分析,那宇宙里最大的物体到最小的粒子的运动都会包含在一条简单公式中。对于这智者来说没有事物会是含糊的,而未来只会像过去般出现在他面前。”——法国数学家皮埃尔·西蒙·拉普拉斯
1.
2.
一、数据特征
那究竟如何才能做到先知先觉,事先一窥足球比赛的结果呢?对于足球比赛,是否存在一种合理有效的预测方法,进而在足球彩票投注中实现较为稳定的盈利呢?
拉普拉斯提出的拉普拉斯妖是机械决定论的典型代表,他认为只要拥有宇宙所有力的分布和物体状态,便可以通过一个牛逼的AI去预测未来的所有,然而这样的论断被薛定谔的那只猫给否定了。拉普拉斯妖虽然有其自身的局限性,但在宏观动力学中原则上仍是适用的。就像布拉德·皮特主演的电影《MoneyBall》讲述的真实故事,一支屌丝球会通过数据分析,挖掘出合适的球员,最终组合成一支总薪金低却能与豪门洋基竞争冠军的球队。影响一场足球比赛结果的因素千千万,不管是普通球迷还是职业足球评论家都可以提出一系列的影响因子,球队排名、历史战绩、攻防数据、近期表现、主场优势、红牌裁判等等。
现有业界的足球比赛预测方法众多,下面简要介绍下常见的几种方法:
1.基于进球数预测方法。基于进球数预测的方法[1]把比赛结果的预测转化为利用泊松分布模型估计对战双方的攻防能力,进而通过进球数预测比赛最终的结果。
2.基于概率回归模型。论文[2]提出由多个不同的解释变量来组成一个概率回归模型,主要考虑球队水平、近期表现、比赛重要程度、主客队位置距离等。
3.利用贝叶斯网络进行预测。主要采用与比赛相关的主观和客观数据对贝叶斯网络的进行训练建模,进而对比赛结果进行预测。
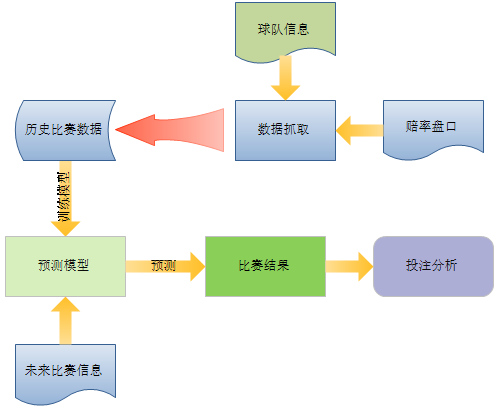
参考多篇关于football prediction的论文,其预测比赛利用的数据主要分为两方面,一是球队基本面信息,二是公开的赔率盘口。这里的足彩预测实现主要也是考虑了这两方面的数据。
球队基本面信息

球队基本面信息由比赛双方球队在球队实力、赛前状态、对战历史、场地效应、攻防能力这五个方面组成。我们把这主队客队在这五个方面的能力量化为17维的连续特征。

赔率盘口
球队基本面信息很容易理解,而赔率盘口与足球比赛的结果有什么具体的联系呢?赔率的基本条件是概率,但又不仅仅是概率。简单来说,博彩公司对某场比赛进行一系列科学的分析和判断后,得出胜、平、负三种结果,赢面大的一方,相应的赔率自然就低,赢面小的一方,其赔率就相对的高。概率的高低并非对应最终的结果,但一旦形成市场行为,博彩公司便将概率转化为赔率去销售。公开的赔率数据为了切合市场预期和体现它的存在价值,势必要或多或少与实际比赛概率产生联系,从而去迎合大众投注心理,而最终形成的赔率则是包含着庄家市场预期值、比赛信息以及结果概率的综合体。
赔率是两支球队实力的体现
赔率基于比赛结果的基本概率
赔率融合了庄家的市场预期
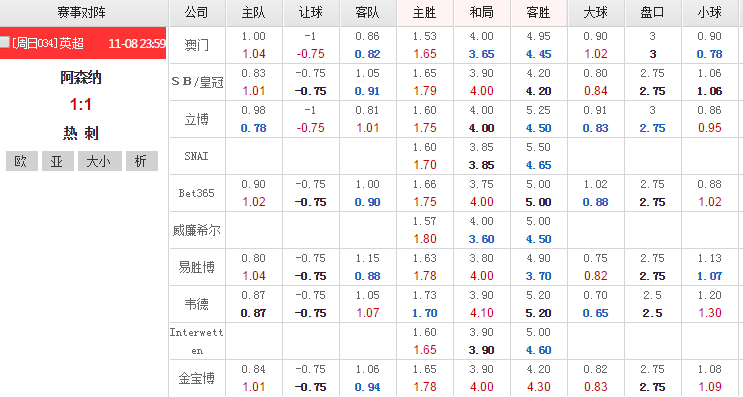
可以看到,博彩公司公开的赔率本身蕴含了比赛相关的信息,但掺杂了庄家的市场期望和闲家的投注倾向,附着了许多商业利益。赔率从最初开出到比赛开始都有可能发生变化,当博彩公司获得更多的信息时,会依据球队动态和投注倾向做出一定的调整。有经验的彩民常常通过观察不同博彩公司的初始赔率以及赔率的变化来决定自己的投注。不同的比赛赔率不尽相同,赔率从初赔到终赔变化多样,而我们希望通过机器学习的方法让模型代替人去理解这其中的含义,进而预测足球比赛的结果。
二、数据的准备
这里以欧洲五大联赛的预测为示例,下面我们针对欧洲五大联赛进行数据折挖掘和准备。
针对杯赛,如欧洲杯、美洲杯、世界杯等的预测方法类似,但面临的数据问题有些许的不同,该问题将在本节最后部分做简单的讨论。
需要的数据主要有:
1.比赛的主要信息:联赛、主队、客队、比分
2.赔率信息:各博彩公司对比赛给出的欧洲赔率(胜、平、负)
通过抓取,现已获得从2010年至2015年欧洲五大联赛比赛的信息,以及17家主流博彩公司公开的赔率信息。各个联赛具体数据情况如下:

球队基本面信息特征可以通过对历史联赛积分排名以及球队参赛信息统计得到,共17维球队特征。对于赔率而言,由于每家博彩公司在开赛前给出的最终赔率并没有统一的时间标准,故现版本只采用各主流博彩公司公开的初次胜、平、负赔率,17家博彩公司共51维赔率特征。
三、预测模型
非线性模型
现有比赛数据从2010年7月27日开始累积,其中包含了五个完整的赛季以及2015年的赛季数据。以英超联赛为例,我们从前五个赛季中各随机选择55场比赛以及最新赛季的90场比赛,共365场组成测试集合,其余数据作为训练集合。比赛数据中存在一些强弱对抗且爆冷的比赛,我们认为这样的数据为奇异的样本在训练过程中进行了剔除,得到1339场的训练集合。
在线性LR模型下,英超联赛的测试集的预测准确率为38.18%,而在SVM模型下准确率提升为51.23%。SVM模型对比赛胜、平、负预测结果的预测的混淆矩阵如下:

根据英超联赛的预测结果来看,SVM模型的预测准确率比LR模型的预测准确率提高了13.05%,我们猜测非线性模型在足球比赛结果的预测上具有更好的表现。我们采用同样的训练集和测试集,尝试了多个不同的非线性模型。

由实验结果我们发现,除了法甲联赛,其他联赛在非线性模型,尤其是随机森林(RandomForest)模型上都具有较好的效果,预测准确率达到了53%以上。但是为什么唯独法甲联赛的预测准确率相对其他联赛更低呢?
从球迷的角度来看,相比其他四大联赛法甲联赛本身竞争力较低,球员中以非洲为代表的第三世界外援比例高,比赛战术性和纪律性都较弱,比赛常常依靠明星球员的个人表现。香农理论证明了熵与信息内容的不确定程度有等价关系,也就是物体的信息熵越大,混沌程度越高,其信息的不确定性就越大。对于足球比赛来说,对战双方实力越为接近,比赛结果的偶然性则越大,想要准确地预测比赛结果也就越为困难。
球队在每场比赛中的真实实力是很难去人为衡量的,在这里我们简单地把球队的联赛积分排名作为球队实力的一个衡量标准。在联赛中,根据球队积分排名的一个波动情况衡量整个联赛的混沌程度。计算方法如下:
1.根据联赛积分排名,排名第1的球队得20分,第2名的球队得19分,以此类推,第20名的球队得1分,降级球队得0分;
2.计算每支球队在近10个联赛赛季的排名方差;
3.由每支球队的排名方差的平均值计算得到联赛的混沌程度得分。
联赛混沌程度得分

由以上方法计算得到的结果可以看到,法甲的混沌程度得分远高于其他的四大联赛,和球迷在感性上的认识是一致的,这就导致了利用同样的数据信息,对法甲的预测准确率远低其它的四大联赛。
到此为止,我们在采用随机森林模型对英超联赛能取得53.42%的预测准确率,除了进一步挖掘更多的特征,还有没有方法可以进一步提高准确率呢?下面我们先来看下现有的特征在随机森林模型下对目标值的作用权重。

其中最后17维特征为球队基本面特征,其余的为赔率特征。在随机森林模型下,球队基本面特征普遍的作用权重偏低,对目标结果的影响有限,特征作用更大的主要存在于赔率特征向量中。
DNN模型
特征是机器学习系统的原材料,对模型最终的效果影响是最大的。如果原始数据可以通过合适的特征更好地表达出来,哪怕是简单的模型也可以达到更高的精度。然而特征工程是一个枯燥而费力的工作,同时要求需要有大量的经验和专业知识。对于足球比赛而言,普通球迷与专业足球分析师观察的点可能完全不一样。手工选择和处理特征很大程度上需要依靠专业经验,甚至是运气,同时需要耗费大量的时间。近年来大热的Deep learning恰好可以解决这样的问题。Deep learning的另一个名字叫做 unsupervised features learning,即非监督的特征学习方法。它最为强大的地方就在于,在包含众多隐含层的神经网络中,可以利用其中的某一层的输出当作是输入数据的另一种表达形式,能够更准确地“表达”和“理解”事物的特征,从而有效地提升预测的准确性。
传统的Neural Network在训练过程中采用back propagation的方式进行,即根据当前输出和label之间的误差,利用梯度下降法调整前面各层的参数,直至模型收敛。但在实际工程中存在明显的缺点:
1.容易收敛到局部最小值,陷入局部最优。
2.训练数据不足时,容易过拟合。
3.要求训练数据为有标签的数据。
4.训练速度慢,计算性能要求高。

为了解决多层神经网络在训练过程中存在的问题,Hinton提出了另一种训练方法,无监督逐层训练greedy layer-wise training。训练方法主要分为两大步骤:
1.逐层训练构建神经元,使得每一层网络的输入和输出所蕴含的信息差别最小。这一步是无监督的训练过程。
2.通过有标签的训练数据,误差自顶向下对各层网络的参数进行微调。

利用深度神经网络的多重非线性变换,我们便可得到输入数据特征的另一种更加有效的表示,实现了对足彩数据特征的有效学习。如此,我们可以利用深度学习网络的隐层输出作为新的输入特征,结合其他的非线性统计模型训练得到最后的输出结果。
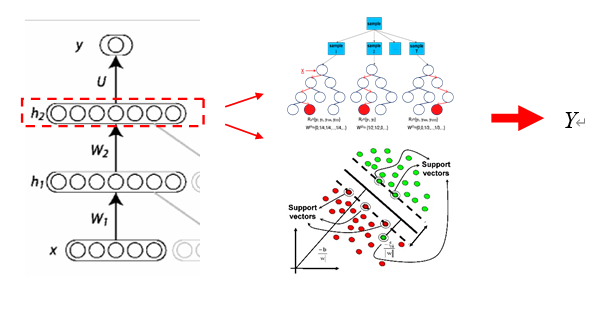
以英超联赛为例,结合深度神经网络的Ensemble方法对比赛结果的预测准确率有了明显的提高。

四、杯赛预测和比分预测
杯赛预测
以上的数据特征挖掘和预测均以欧洲五大联赛为例,但杯赛或其他比赛的预测方法是相似的。不过杯赛相比联赛的预测难度更大,主要有以下两大原因:
1.比赛数量更少
英超联赛有20支队伍,正常赛季有380场比赛。而一届杯赛的总场次是远远小于这个数量的。2016年扩军后,欧洲杯24支参赛队伍,共51场比赛;世界杯32支参赛队伍,共64场比赛。这使得杯赛相关数据的总量都远小于联赛。
2.数据质量更为波动
由于杯赛往往4年举办一届,参赛队伍变动大,队伍的实力变化大。这就导致对战队伍的历史对局相对较少,同时历史对战数据的指导性变弱。如在世界杯上,能够与中国队一战的队伍不过巴西、哥斯达黎加、土耳其,数据极少。
综上所述,杯赛的预测相对联赛来说更难。结合上面对法甲联赛的分析,杯赛相当于一个混沌程度更高的“联赛”,预测的结果具有更大的随机性。
比分预测
比分预测的方法与赛果预测的方法相近,上游的数据获取和特征抽象均可以复用,主要是把预测目标转换为对比赛结果比分的预测,如下图所示
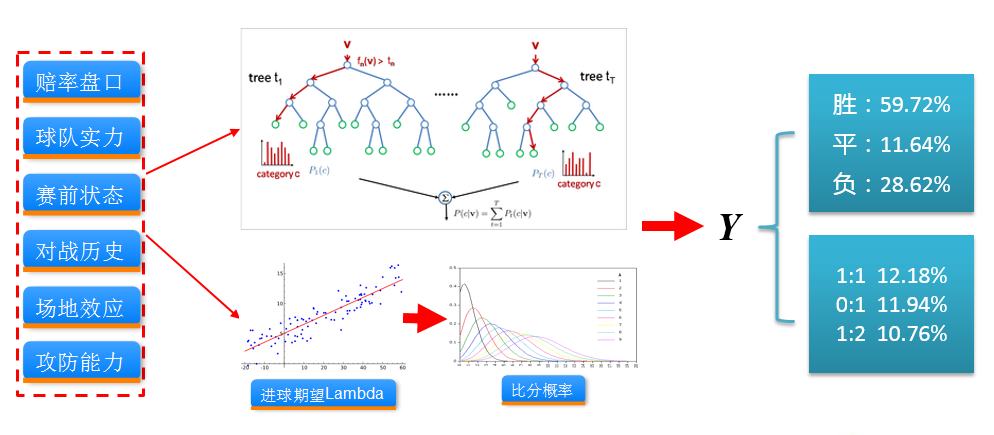
比分预测在实际实现中,我们可以把它当作一种回归问题或分类问题。这里,我们举两种比较简单实用的方法作为示例。
1.泊松分布方法
泊松分布(Poisson distribution)是由法国数学家西莫恩·德尼·泊松在1838年提出来的,它描述的是单位时间内随机事件发生的次数的概率分布。这里,我们可以假设比赛双方的进球数符合泊松分布(这是很强、很朴素的假设),仅对其中的lambda参数进行建模,得到最终比赛的最大概率进球比分。

2.多分类方法
多分类方法则是把比分预测看作是一个多分类问题。经过数据统计我们发现,大多数比赛的单场进球数小于或等于4,如欧洲杯中97%的场次进球数小于5。如此,我们可以把比分预测看到是一个25(5*5)类别的分类问题,用Softmax函数对每种可能的比分进行建模
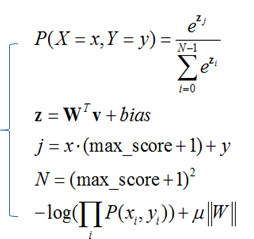
PS:下表为2016年欧洲杯和2018年世界杯的赛果预测和比分预测情况(可以看到预测准确率波动特别大)


投注策略分析
实际足彩中有多种彩种玩法,如竞彩足球中就包括胜平负游戏、比分游戏、总进球游戏、半全场胜平负游戏、过关组合玩法等等。那基于前面得到的足彩预测系统,能不能对我们的足彩投注有所指导。好吧,就是能不能赚钱。

3.
一、如何才能盈利
足球彩票品种多得让人剁手,这里只针对竞彩足球中最为简单的竞彩单场玩法进行分析。单场固定单注奖金计算公式为:所选场次的单场赔率×2元×倍数。
假设大壮投注n+m场比赛,其中猜对了n场比赛,猜中的n场比赛赔率分别为,则大壮可以用来给小美买包的总利润计算如下:
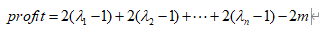
令总利润profit>0,对上式做一下简单的推导:

表明,若想最后总利润大于零,则要求投注比赛的预测准确率的倒数小于猜中比赛的平均赔率,即要求满足如下公式:

对于我们现有表现最好的模型(NN+SVM)来说,在英超训练集(1339场)和测试集(365场)中,预测结果如下:
预测准确率 | 准确率倒数 | 猜中场次平均赔率 |
54.55% | 1.8332 | 1.800802 |
结果仍然不满足公式(1)的要求,也就是说当我们完全根据模型预测结果进行投注时,从长远来看必定是亏本买卖。
二、分析模型的预测概率区间
模型预测的比赛结果给出了对应的概率,是否存在在一定的区间内,预测结果的概率值满足公式(1),如此只需要根据预测概率调整投注策略就可以了。
除了原来的测试集(365场),另随机产生了100场、200场、300场以及2015新赛季的100场英超比赛作为测试集进行测试,结果展示如下:
1/precise为预测比赛准确率的倒数
Bet_odds_avg为预测正确的比赛对应的赔率平均值
Odds_avg为各区间比赛结果对应的赔率平均值




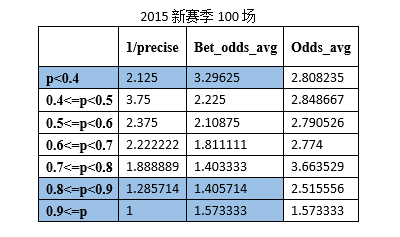
可以看到当前训练集(1339场,无爆冷比赛)训练得到的SVM模型,对于英超比赛的预测,在概率p<0.4和p>=0.9的区间是满足公式(1)的,即足彩预测系统预测概率在此类区间时,如果进行投注能够盈利。根据这样的投注策略进行模拟投注,符合概率要求的均只投一注,可以得到以下数据:

推而广之,这样的投注策略在其他四大联赛中是否适用呢。同样的,我们随机地产生100场、200场和300场训练集分别对西甲、意甲、德甲和法甲进行测试。

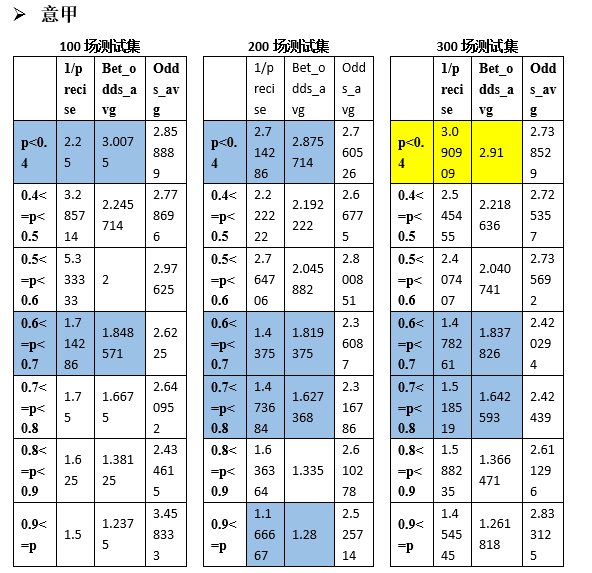


可以看到其它联赛也存在类似的满足盈利公式(1)的概率区间,统计如下:

三、存在的问题
1.现在得到的盈利投注区间规律只在各个联赛300场左右的测试集进行过测试,是否具有更加普适性的可能,还需要有更多的比赛数据进行测试和验证。
2.现有的投注策略受限于预测概率区间,投注场次与总场次之比还不够高,如英超为20%,而法甲由于准确率较低的缘故,投注比例只有7%。
3.由于投注场次的赔率会有波动,导致盈利率在不同的训练集上变化较大,难以确保一个高而稳定的盈利率。

One more thing
看到这里,胸怀大志又好学的同(du)学(gou)已经跃跃欲试,准备在这届世界杯大展拳脚了。更有学有余力的同学开始举一反三,准备投身更大的应用场景上,如股票预测。股票预测,或者专业点叫金融量化,是利用大数据和专业数理模型代替人为主观判断进行选股、择时,以期获得稳定、持续的超额回报。与足彩的预测相似,金融量化同样的需要有数据获取、特征挖掘、预测模型模块。但同时还需要更为复杂的选股器和交易系统。下图为一简单的金融量化交易系统示意图。

随着近20年AI技术的蓬勃发展,大力推动了量化交易的自动化、数据化和智能化发展。但量化交易作为一个涉及到多领域、大量数理知识、金融知识以及系统工程的问题,在实际运用中更为复杂,相比理论假设有更多的非理性因素和消息不透明等情况,还涉及到交易策略等股票实操问题。量化交易的完整讲述甚至只是简单介绍都值得另开一篇拙文,这里只是抛砖引玉,对前文足彩预测中的方法简单扩展。下面主要从信号挖掘和预测模块两个方面,简要介绍如何与股票预测作结合应用。

一、信号挖掘
相比足球预测的数据信息,股票相关的信号众多,不管是从数量上,还是特征维度上都是爆炸式的增长。从最基本的开盘价收盘价,到股票技术性指标,如MACD,KDJ等,再到股票基本面信息的抽象。信号和特征维度众多,关键在于:一是如何挖掘更多具有股票相关性的信号;二是相关性量化和特征分析。
1.挖掘有效的相关信号
除了常见的公开股票信息,如何挖掘到更多有效的相关信号,将很大程度上决定预测效果的好坏。如事件驱动、社交媒体热点等等。这就要求需要构建一个完整且成体系的数据信号收集系统,扩大信息来源的基数。
大量的热度指数
媒体热度
搜索热度
社交热度
意想不到的数据关联性
啤酒vs尿布
股市大盘vs社交网络恐慌指数
流感疫情vs搜索热词
2.量化特征相关性
有了大量的数据信号之后,需要建立特征相关性的评估体系,去粗取精,尽可能地减少干扰噪声,选择预测能力强的解释变量,提高信息来源的质量。
常用的有以下几种方法:
1.相关系数分析法:

2.KL信息量分析法:

3.假设检验:P-Value
4.利用深度学习网络的embedding信息提取
二、预测模型
量化投资的类型有量化选股、量化择时、统计套利等等,这里仅以预测股票涨跌为例考虑预测模型。预测涨跌,除了能够使用与上文足彩预测相同的机器学习传统模型外,股票数据的特点非常适合采用深度学习模型和时序相关的复杂模型,如DNN、LSTM,还有当前大热的transformer模型。
股票信息足够“大数据”

股票信息具备天然的“时序”特点

从下面的测试集合收益回测对比实验可以看到,结合LSTM的深度神经网络模型具有更高的预测准确率,超额收益Alpha和交易收益率也显著提高。
简单模型vs LSTM模
型

预测准确率平均提升3%
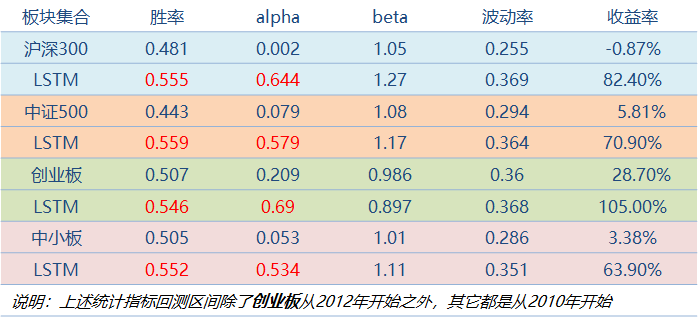
不同板块均有稳定的超额alpha

结语
大刘在《三体》后记中写道“在体育场的最后一排看足球,球员本身的复杂技术动作已经被距离隐去,球场上出现的只是由二十三个点和一个特殊的点足球构成的不断变化的矩阵。球类运动中只有足球比赛呈现出如此清晰的数学结构,这也可能是这门运动的魅力之一。”在90分钟的时间里,充满精彩悬念的绿茵场是足球最摄人的魅力,而不断探索未知,渴望预测未来则是人类本能的追求。本文介绍的足彩预测模型方法基于赔率和球队基本面特征,实现了对欧洲五大联赛比赛结果的预测,对英超联赛的预测准确率达到了54.55%。基于本文提出的足彩预测模型,可以根据预测概率值实行有效的足彩单场胜平负竞猜和比分预测。
但是当前版本的预测系统还存在着许多不足的地方:
1.数据样本仍然需要进一步积累,进一步扩充比赛数据样本,增加中超联赛以及欧冠、亚冠等杯赛数据;
2.特征挖掘。对于DNN模型来说,现在的特征维度仍然偏少,有效的特征不多。有效特征的进一步挖掘是接下来重要的工作之一。如赔率变化值,对战阵形、球员疲劳程度、比赛重要度,球队重大新闻等等,进一步挖掘和分析对比赛有影响的因子。
3.当前利用足彩预测概率进行投注的策略仍然比较简单,其稳定性和适用性仍然需要在更大量的数据集上进行测试和调整。
4.增加对比赛其他结果的预测,如进球数,强弱队比赛爆冷概率等等。
本文方法并不是一个完美的“拉普拉斯妖”,结合更新更全的数据,以及当前最新的大模型AI方法,大家可以发挥自己想象力和领域知识构建一个更加完善的足球预测系统。在欣赏绿茵场上激情对抗的同时,体验数据和机器学习的无穷魅力。
参考文献
[1] Dixon, M., & Pope, P. (2004). The value of statistical forecasts in the UK associationfootball betting market. International Journal of Forecasting, 20, 697-711
[2] Goddard J, Asimakopoulos I. Forecasting football results and the efficiency of fixed‐odds betting[J]. Journal of Forecasting, 2004, 23(1): 51-66.
[3] Constantinou A C, Fenton N E, Neil M. pi-football: A Bayesian network model for forecasting Association Football match outcomes[J]. Knowledge-Based Systems, 2012, 36: 322-339.
[4] Mittal A, Goel A. Stock prediction using twitter sentiment analysis[J]. Standford University, CS229 (2011 http://cs229. stanford. edu/proj2011/GoelMittal-StockMarketPredictionUsingTwitterSentimentAnalysis. pdf), 2012, 15: 2352.
[5] Ding X, Zhang Y, Liu T, et al. Deep learning for event-driven stock prediction[C]//Twenty-fourth international joint conference on artificial intelligence. 2015.
注:本文为技术分享,请大家以娱乐心态参与,快乐购彩、理性投注。
腾讯工程师技术干货直达:
1.超强总结!GPU 渲染管线和硬件架构
2.从鹅厂实例出发!分析Go Channel底层原理
3.快收藏!最全GO语言实现设计模式【下】
4.如何成为优秀工程师之软技能篇





![[激光原理与应用-31]:典型激光器 -3- 光纤激光器](https://img-blog.csdnimg.cn/img_convert/3a78d1df5b3831b9f0e523a338948b87.png)
![[附源码]计算机毕业设计JAVA学生宿舍管理系统](https://img-blog.csdnimg.cn/15e757d4791d4d96a1e739aa06a51054.png)


![[附源码]Python计算机毕业设计Django教务管理系统](https://img-blog.csdnimg.cn/10ea5196b9c949c08d931774a1a4e1be.png)