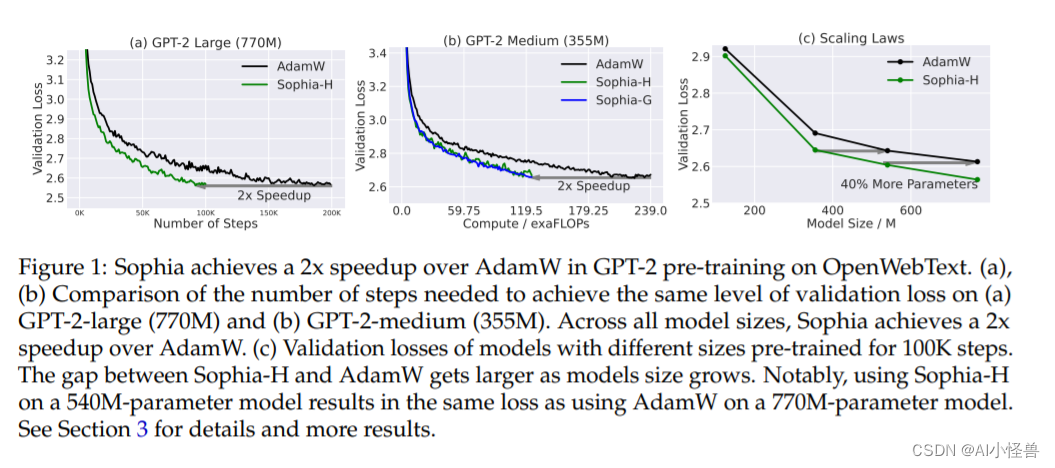
大家好,我是微学AI,今天给大家介绍一下人工智能基础部分20-生成对抗网络(GAN)的实现应用。生成对抗网络是一种由深度学习模型构成的神经网络系统,由一个生成器和一个判别器相互博弈来提升模型的能力。本文将从以下几个方面进行阐述:生成对抗网络的概念、GAN的原理、GAN的实验设计。
一、前言
随着近年来人工智能发展的不断加速,尤其是深度学习的出现,使得计算机视觉领域取得了许多重要突破。生成对抗网络(Generative Adversarial Networks, GAN)是其中一种具有广泛应用前景的技术。GAN是一种生成式模型,它的主要原理是通过博弈论的方式,将生成模型与判别模型进行对抗训练,从而实现生成图像、音频等数据的任务。本文将对GAN 的工作原理进行详细解释,并通过一个图像生成示例项目,展示如何使用 PyTorch 框架实现 GAN,并给出实验结果与完整代码。
二、生成对抗网络(GAN)原理
GAN的核心思想是让两个网络(生成器和判别器)进行博弈,最终迭代得到一个高质量的生成器。生成器的任务是生成与真实数据分布相近的伪数据,而判别器的任务则是判断输入数据是来源于真实数据还是伪数据。通过优化生成器与判别器的博弈过程,使得生成器逐渐改进,能够生成越来越接近真实数据的伪数据。

2.1 生成器
生成器的主要作用是以随机噪声为输入,输出生成的伪数据。随机噪声是一个高斯分布的向量,我们可以通过一个深度神经网络模型(如卷积神经网络、前馈神经网络等)将这个高斯分布的向量映射成我们想要输出的伪数据。
2.2 判别器
判别器是一个二分类神经网络模型,输入可能来自生成器也可能来自真实数据。其任务是对输入数据进行分类,输出一个概率值以判断输入数据是来自真实数据集还是生成器生成的伪数据。
2.3 博弈过程
生成器与判别器博弈的过程即是各自的训练过程。生成器训练的目标是使得判别器对其生成的数据预测为真实数据的概率最大;判别器训练的目标是使得自身对真实数据与生成的数据的分类准确率最高。通过反复迭代这个过程,最终生成器能够生成越来越接近真实数据的伪数据。
2.4 数学原理
生成对抗网络(Generative Adversarial Networks,简称 GAN)是一种基于博弈论的生成模型,其数学原理可以用以下公式表示:
假设表示真实数据的分布,
表示生成器输入随机噪声
的分布,
表示生成器的输出,其中
是生成器的参数,
表示判别器的输出,其中
是判别器的参数。
GAN 的目标是最小化以下损失函数:
其中 表示期望值,
表示自然对数。
这个损失函数的含义是:最小化生成器生成的数据与真实数据之间的差距,同时最大化判别器对生成器生成的数据和真实数据的区分度。具体来说,第一项表示真实数据被判别为真实数据的概率,第二项
表示生成器生成的虚构数据被判别为虚构数据的概率。
在训练过程中,GAN 会交替训练生成器和判别器,通过最小化损失函数 来优化模型参数。具体来说,对于每个训练迭代,我们首先固定生成器的参数,通过最大化损失函数
来优化判别器的参数。然后,我们固定判别器的参数,通过最小化损失函数
来优化生成器的参数。这个过程会一直迭代下去,直到达到预定的迭代次数或者损失函数收敛。
三、实验设计
本文使用 tensorflow 框架实现 GAN,并在图像生成任务上进行训练。实验workflow 分为以下五个步骤:数据准备\构建生成器与判别器\设置损失函数与优化器、训练过程,让我们先从数据准备开始。
四、代码实现
下面我们将使用MNIST(手写数字化)这一经典的数据集来展示GANs的实际应用效果。
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# 设置随机种子以获得可重现的结果
np.random.seed(42)
tf.random.set_seed(42)
# 加载MNIST数据集
(x_train, y_train), (_, _) = keras.datasets.mnist.load_data()
# 将数据规范化到[-1, 1]范围内
x_train = x_train.astype(np.float32) / 127.5 - 1
# 将数据集重塑为(-1, 28, 28, 1)
x_train = np.expand_dims(x_train, axis=-1)
# 创建生成器模型
def create_generator():
generator = keras.Sequential()
generator.add(layers.Dense(7 * 7 * 256, use_bias=False, input_shape=(100,)))
generator.add(layers.BatchNormalization())
generator.add(layers.LeakyReLU(alpha=0.2))
generator.add(layers.Reshape((7, 7, 256)))
generator.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias = False))
generator.add(layers.BatchNormalization())
generator.add(layers.LeakyReLU(alpha=0.2))
generator.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias = False))
generator.add(layers.BatchNormalization())
generator.add(layers.LeakyReLU(alpha=0.2))
generator.add(
layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias = False, activation ='tanh'))
return generator
generator = create_generator()
# 创建鉴别器模型
def create_discriminator():
discriminator = keras.Sequential()
discriminator.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same', input_shape = (28, 28, 1)))
discriminator.add(layers.LeakyReLU(alpha=0.2))
discriminator.add(layers.BatchNormalization())
discriminator.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
discriminator.add(layers.LeakyReLU(alpha=0.2))
discriminator.add(layers.BatchNormalization())
discriminator.add(layers.Flatten())
discriminator.add(layers.Dropout(0.2))
discriminator.add(layers.Dense(1, activation='sigmoid'))
return discriminator
discriminator = create_discriminator()
# 编译鉴别器
discriminator_optimizer = keras.optimizers.Adam(lr=0.0002, beta_1=0.5)
discriminator.compile(optimizer=discriminator_optimizer, loss='binary_crossentropy', metrics = ['accuracy'])
# 创建和编译整体GAN结构
discriminator.trainable = False
gan_input = keras.Input(shape=(100,))
gan_output = discriminator(generator(gan_input))
gan = keras.Model(gan_input, gan_output)
gan_optimizer = keras.optimizers.Adam(lr=0.0002, beta_1=0.5)
gan.compile(optimizer=gan_optimizer, loss='binary_crossentropy')
# 模型训练函数
def train_gan(epochs=100, batch_size=128):
num_examples = x_train.shape[0]
num_batches = num_examples // batch_size
for epoch in range(epochs):
for batch_idx in range(num_batches):
noise = np.random.normal(size=(batch_size, 100))
generated_images = generator.predict(noise)
real_images = x_train[(batch_idx * batch_size):((batch_idx + 1) * batch_size)]
all_images = np.concatenate([generated_images, real_images])
labels = np.zeros(2 * batch_size)
labels[batch_size:] = 1
# 在噪声上加一点随机数,提高生成器的鲁棒性
labels += 0.05 * np.random.rand(2 * batch_size)
discriminator_loss = discriminator.train_on_batch(all_images, labels)
noise = np.random.randn(batch_size, 100)
misleading_targets = np.ones(batch_size)
generator_loss = gan.train_on_batch(noise, misleading_targets)
if (batch_idx + 1) % 50 == 0:
print(
f"Epoch:{epoch + 1}/{epochs} Batch:{batch_idx + 1}/{num_batches} Discriminator Loss: {discriminator_loss[0]} Generator Loss:{generator_loss}")
train_gan()以上实现了生成对抗网络是训练过程,实际中我们可以替换数据训练自己的数据模型。