要采集整站lazada商品列表数据,需要先了解lazada网站的结构和数据源。Lazada是东南亚最大的电商平台之一,提供各种商品和服务。Lazada的数据源主要分为两种:HTML和API。
方法1:采集HTML数据
步骤1:确定采集目标
首先需要确定要采集的商品目标,例如:商品分类、商品价格、商品名称、商品图片等信息。
步骤2:分析网页结构
使用浏览器开发者工具,可以分析网页的HTML结构,找到目标数据所在的位置,确定采集数据所用到的标签和属性。
步骤3:编写Python程序
使用Python编写爬虫程序,通过requests库发送HTTP请求,获取网页HTML代码,并使用beautifulsoup库解析网页HTML代码,从中提取出目标数据。
代码如下:
import requests
from bs4 import BeautifulSoup
# 请求头
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"}
# 商品目标页面URL
url = 'https://www.lazada.com.my/catalog/?q=iphone&_keyori=ss&from=input&spm=a2o4k.home.search.go.4ad81f54EZZOHe'
# 发起请求
response = requests.get(url, headers=headers)
# 解析HTML
soup = BeautifulSoup(response.content, 'html.parser')
# 获取商品列表
item_list = soup.find_all('div', class_='c16H9d')
# 遍历商品列表,获取目标数据
for item in item_list:
name = item.find('div', class_='c16H9d').text.strip()
price = item.find('div', class_='c3gUW0').text.strip()
image = item.find('img', class_='c3KeDq').get('src')
print(name, price, image)
方法2:使用API获取数据
Lazada提供API接口,可以直接获取商品数据。使用API获取商品数据的好处是,数据已经经过处理和格式化,而且可以节省爬虫程序的时间和资源。
步骤1:获取API接口
在Lazada开发者平台注册账号并创建应用程序,获取API密钥和API接口地址。
步骤2:发送API请求
使用requests库发送API请求,获取商品数据。
步骤3:解析API响应
使用Python处理API响应,获取目标数据。
lazada.item_search-按关键词搜索lazada商品列表数据接口,支持多站点
1.请求方式:HTTPS POST GET
2.公共参数:
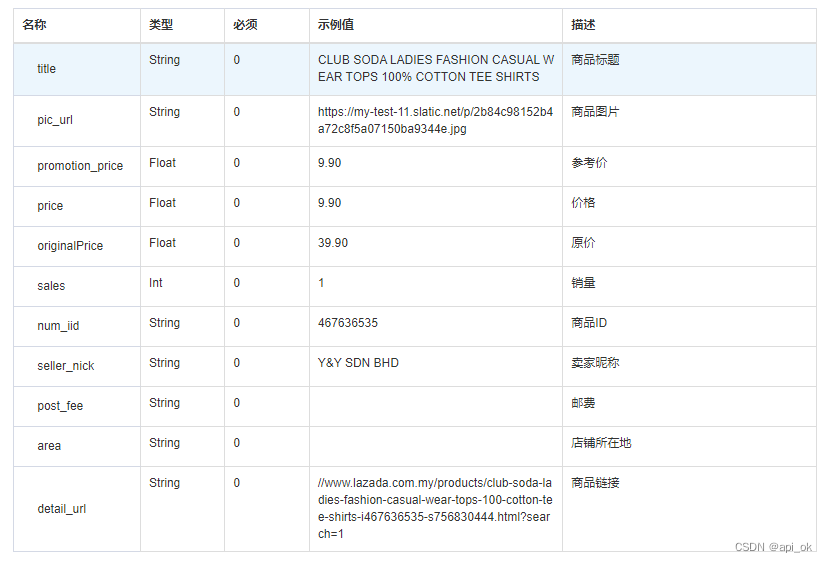
| 名称 | 类型 | 必须 | 描述 |
|---|---|---|---|
| key | String | 是 | 调用key(必须以GET方式拼接在URL中,复制Taobaoapi2014) |
| secret | String | 是 | 调用密钥 |
| api_name | String | 是 | API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等] |
| cache | String | 否 | [yes,no]默认yes,将调用缓存的数据,速度比较快 |
| result_type | String | 否 | [json,jsonu,xml,serialize,var_export]返回数据格式,默认为json,jsonu输出的内容中文可以直接阅读 |
| lang | String | 否 | [cn,en,ru]翻译语言,默认cn简体中文 |
| version | String | 否 | API版本 |
3.请求参数:
请求参数:q=shoe&start_price=&end_price=&page=1&page_size=40&nation=co.th
参数说明:q:搜索关键字(英文)
nation:国家
国家域名后缀可选值如下:co.id、com.my、com.ph、sg、co.th、vn
page:页数
4. 请求示例,支持高并发(CURL、PHP 、PHPsdk 、Java 、C# 、Python...)
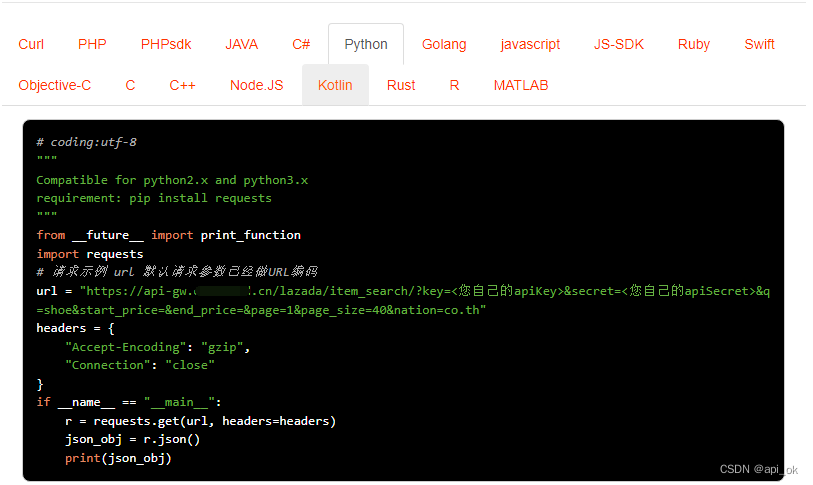
5.响应参数: