CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.Text2NeRF: Text-Driven 3D Scene Generation with Neural Radiance Fields

标题:Text2NeRF:具有神经辐射场的文本驱动 3D 场景生成
作者:Jingbo Zhang, Xiaoyu Li, Ziyu Wan, Can Wang, Jing Liao
文章链接:https://arxiv.org/abs/2305.11588
项目代码:https://eckertzhang.github.io/Text2NeRF.github.io/



摘要:
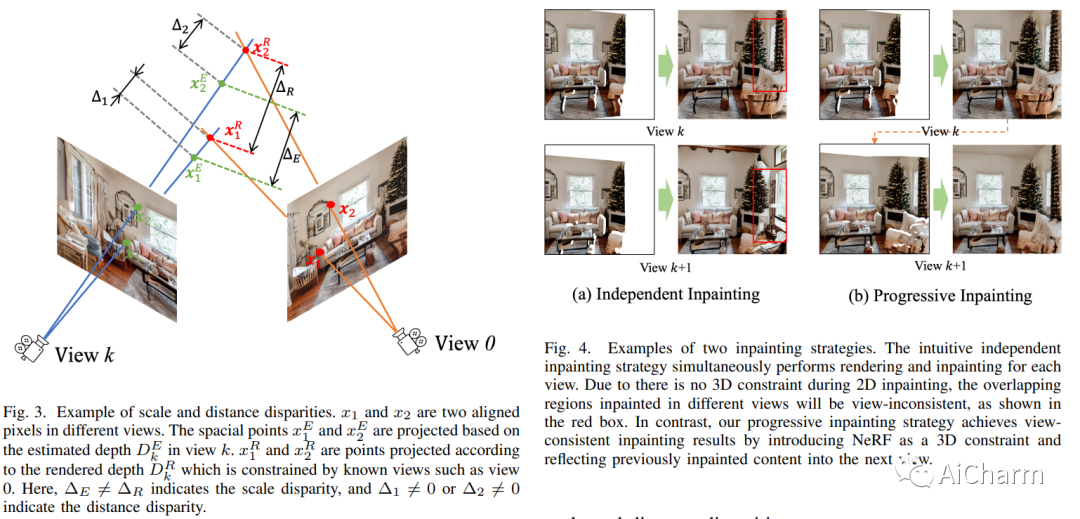
文本驱动的 3D 场景生成广泛适用于对 3D 场景有大量需求的视频游戏、电影行业和元宇宙应用。然而,现有的文本到 3D 生成方法仅限于生成具有简单几何形状和缺乏真实感的梦幻风格的 3D 对象。在这项工作中,我们展示了 Text2NeRF,它能够纯粹从文本提示生成具有复杂几何结构和高保真纹理的各种 3D 场景。为此,我们采用 NeRF 作为 3D 表示,并利用预训练的文本到图像扩散模型来约束 NeRF 的 3D 重建以反映场景描述。具体来说,我们采用扩散模型将与文本相关的图像推断为先验内容,并使用单目深度估计方法提供几何先验。内容和几何先验都用于更新 NeRF 模型。为了保证不同视图之间的纹理和几何一致性,我们引入了一种渐进式场景修复和更新策略,用于场景的新视图合成。我们的方法不需要额外的训练数据,只需要场景的自然语言描述作为输入。大量实验表明,我们的 Text2NeRF 在根据各种自然语言提示生成逼真、多视图一致和多样化的 3D 场景方面优于现有方法。
2.Segment Any Anomaly without Training via Hybrid Prompt Regularization

标题:通过混合提示正则化无需训练即可分割任何异常
作者:Yunkang Cao, Xiaohao Xu, Chen Sun, Yuqi Cheng, Zongwei Du, Liang Gao, Weiming Shen
文章链接:https://arxiv.org/abs/2305.10724
项目代码:https://github.com/caoyunkang/Segment-Any-Anomaly

摘要:
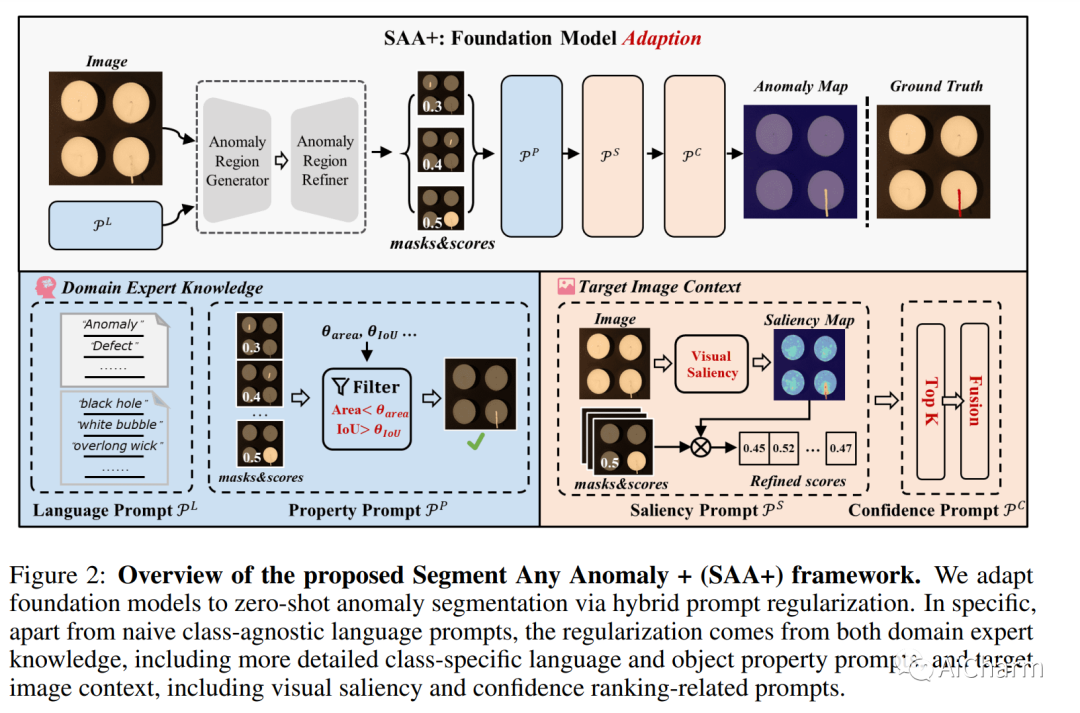
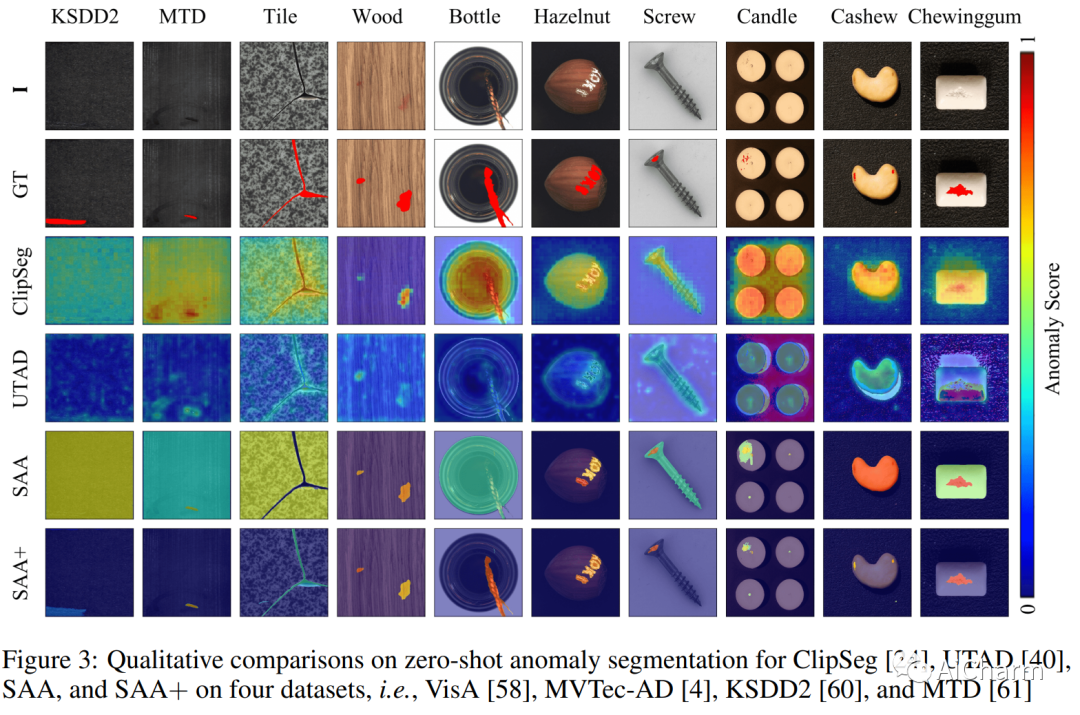
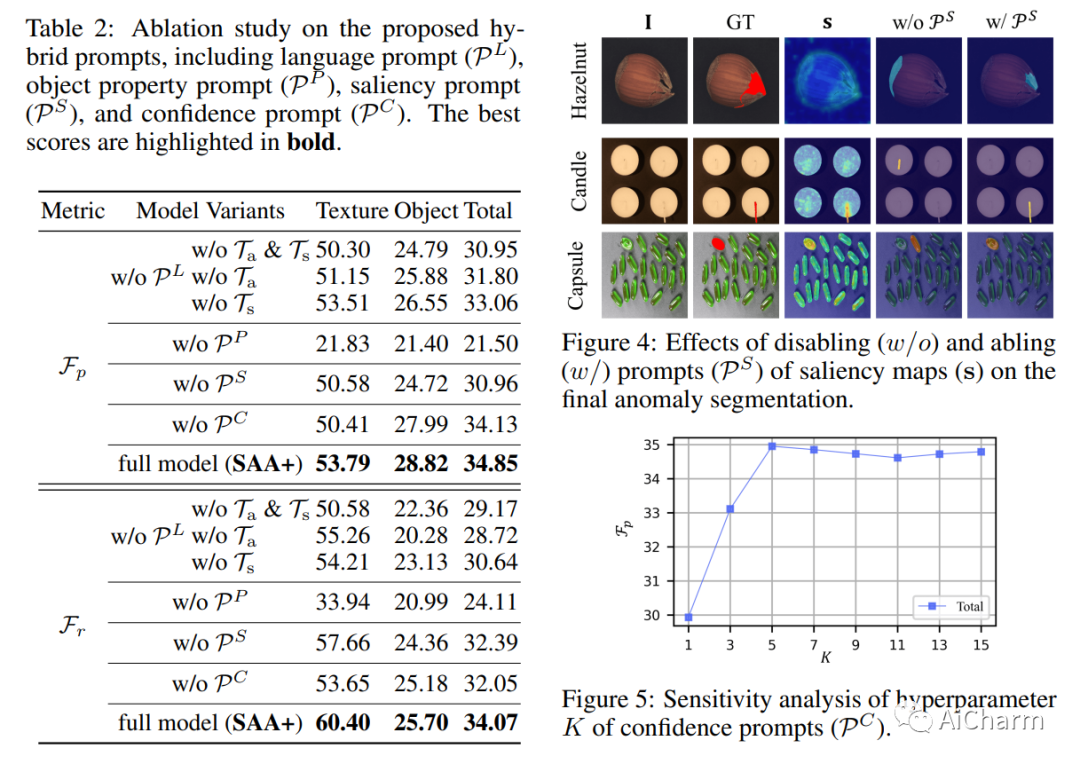
我们提出了一个新的框架,即 Segment Any Anomaly + (SAA+),用于零样本异常分割和混合提示正则化,以提高现代基础模型的适应性。现有的异常分割模型通常依赖于特定领域的微调,限制了它们在无数异常模式中的泛化。在这项工作中,受到 Segment Anything 等基础模型强大的零样本泛化能力的启发,我们首先探索它们的组装,以利用各种多模态先验知识进行异常定位。对于非参数基础模型适应异常分割,我们进一步引入从领域专家知识和目标图像上下文派生的混合提示作为正则化。我们提出的 SAA+ 模型在零样本设置中在多个异常分割基准(包括 VisA、MVTec-AD、MTD 和 KSDD2)上实现了最先进的性能。
3.VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks

标题:VisionLLM:大型语言模型也是用于以视觉为中心的任务的开放式解码器
作者:Wenhai Wang, Zhe Chen, Xiaokang Chen, Jiannan Wu, Xizhou Zhu, Gang Zeng, Ping Luo, Tong Lu, Jie Zhou, Yu Qiao, Jifeng Dai
文章链接:https://arxiv.org/abs/2305.11175
项目代码:https://github.com/OpenGVLab/VisionLLM


摘要:
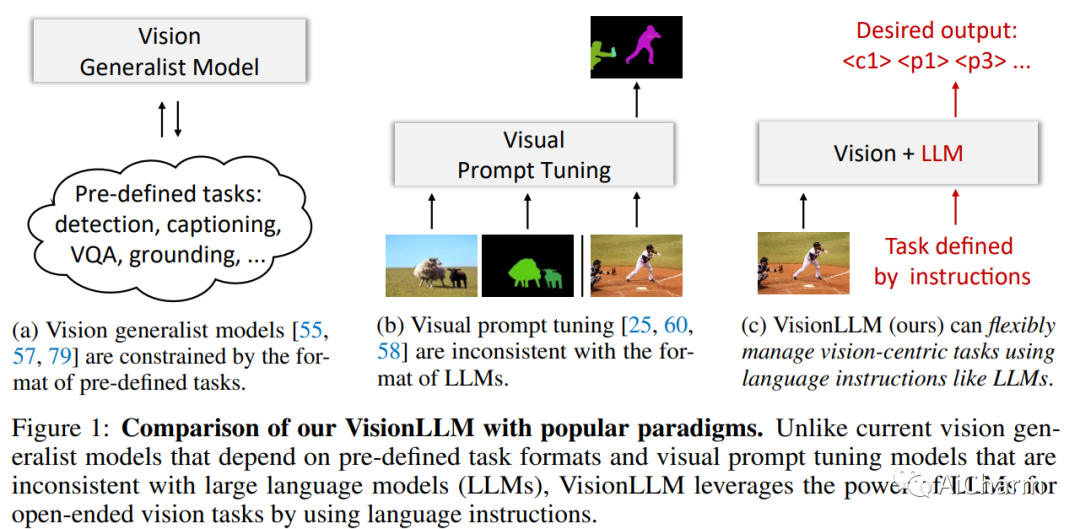
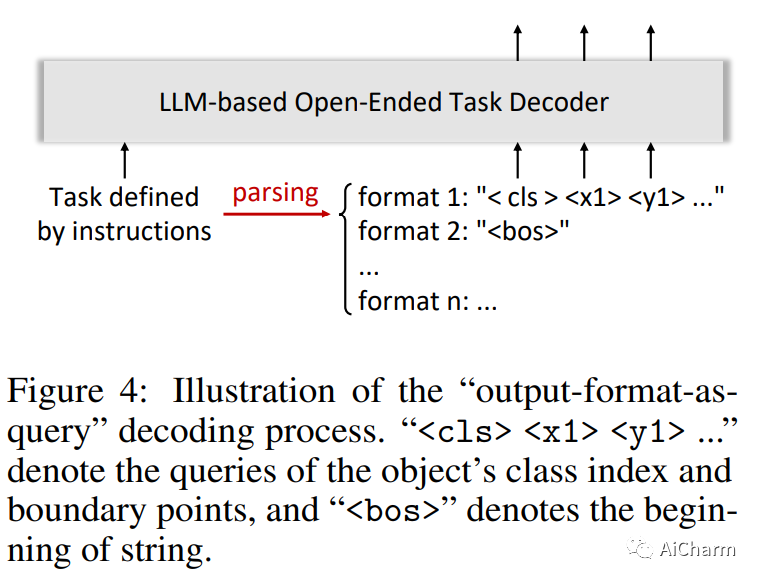
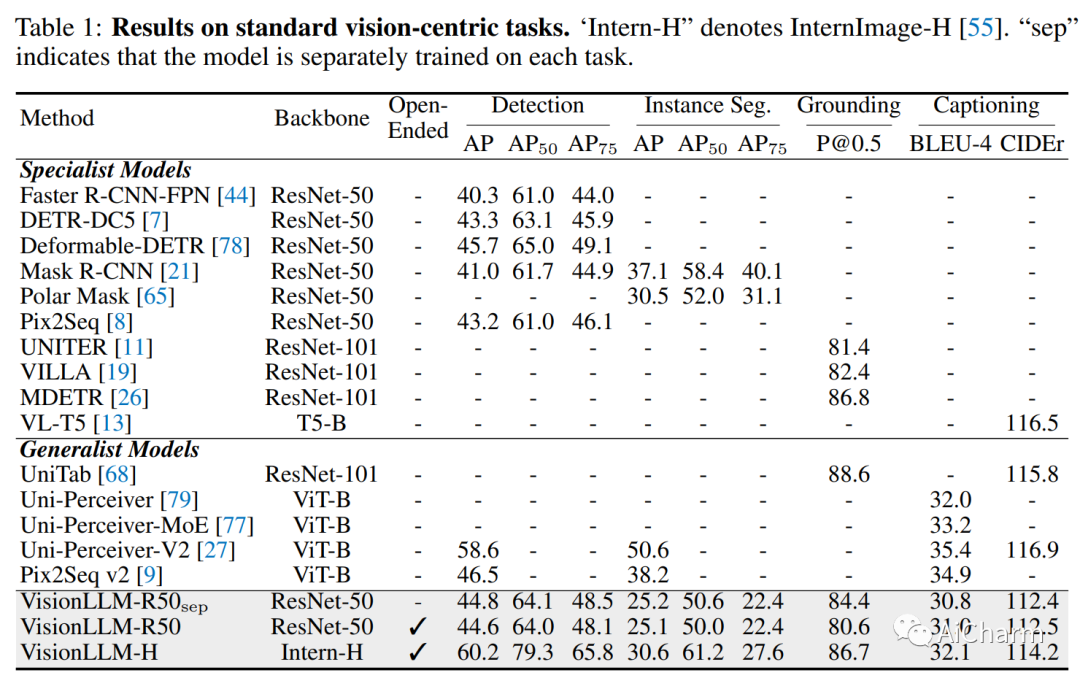
大型语言模型 (LLM) 显着加快了通用人工智能 (AGI) 的进展,其针对用户定制任务的零样本能力令人印象深刻,赋予它们在一系列应用程序中的巨大潜力。然而,在计算机视觉领域,尽管有众多强大的视觉基础模型(VFM)可用,但它们仍然局限于预定义形式的任务,难以匹配 LLM 的开放式任务能力。在这项工作中,我们为以视觉为中心的任务提出了一个基于 LLM 的框架,称为 VisionLLM。该框架通过将图像视为外语并将以视觉为中心的任务与可以使用语言指令灵活定义和管理的语言任务对齐,为视觉和语言任务提供了统一的视角。然后,基于 LLM 的解码器可以根据这些指令为开放式任务做出适当的预测。大量实验表明,所提出的 VisionLLM 可以通过语言指令实现不同级别的任务定制,从细粒度的对象级到粗粒度的任务级定制,都取得了良好的效果。值得注意的是,使用基于通用 LLM 的框架,我们的模型可以在 COCO 上实现超过 60% 的 mAP,与检测特定模型相当。我们希望这个模型可以为通用视觉和语言模型设置一个新的基线。
更多Ai资讯:公主号AiCharm