1. 前言
在深入讲解Netty那些事儿之从内核角度看IO模型一文中曾对 Socket 文件在内核中的相关数据结构为大家做了详尽的阐述。
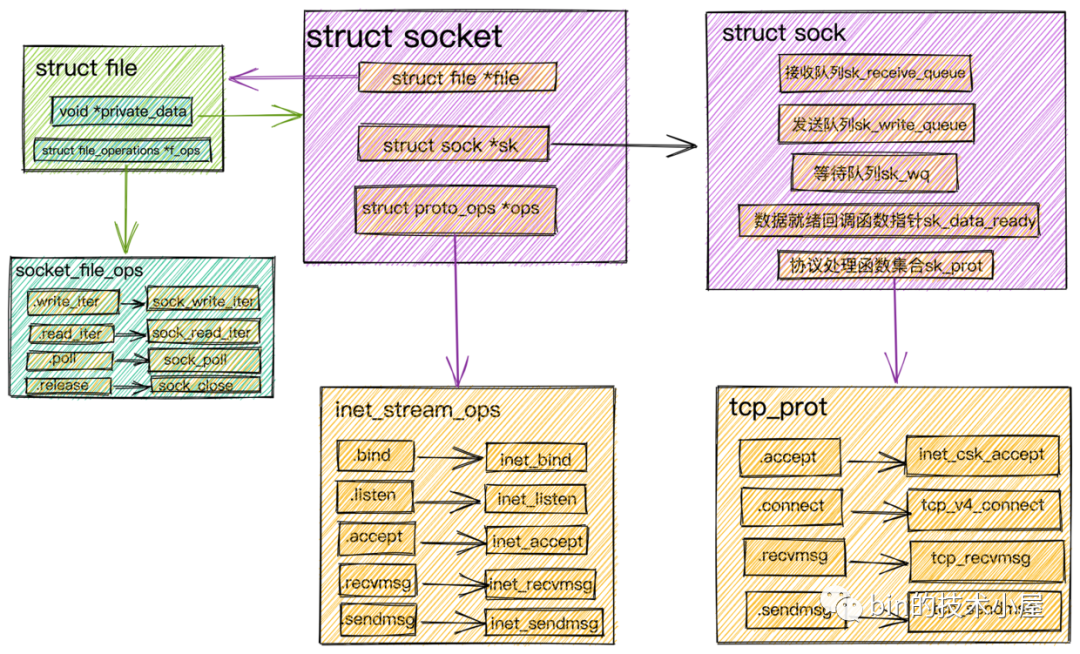
Socket内核结构.png
又在此基础之上介绍了针对 socket 文件的相关操作及其对应在内核中的处理流程:

系统IO调用结构.png
并与 epoll 的工作机制进行了串联:

数据到来epoll_wait流程.png
通过这些内容的串联介绍,我想大家现在一定对 socket 文件非常熟悉了,在我们利用 socket 文件接口在与内核进行网络数据读取,发送的相关交互的时候,不可避免的涉及到一个新的问题,就是我们如何在用户空间设计一个字节缓冲区来高效便捷的存储管理这些需要和 socket 文件进行交互的网络数据。
NIO Buffer 中的顶层抽象设计以及行为定义,随后我们选取了在网络应用程序中比较常用的 ByteBuffer 来详细介绍了这个Buffer具体类型的实现,并以 HeapByteBuffer 为例说明了JDK NIO 在不同字节序下的 ByteBuffer 实现。
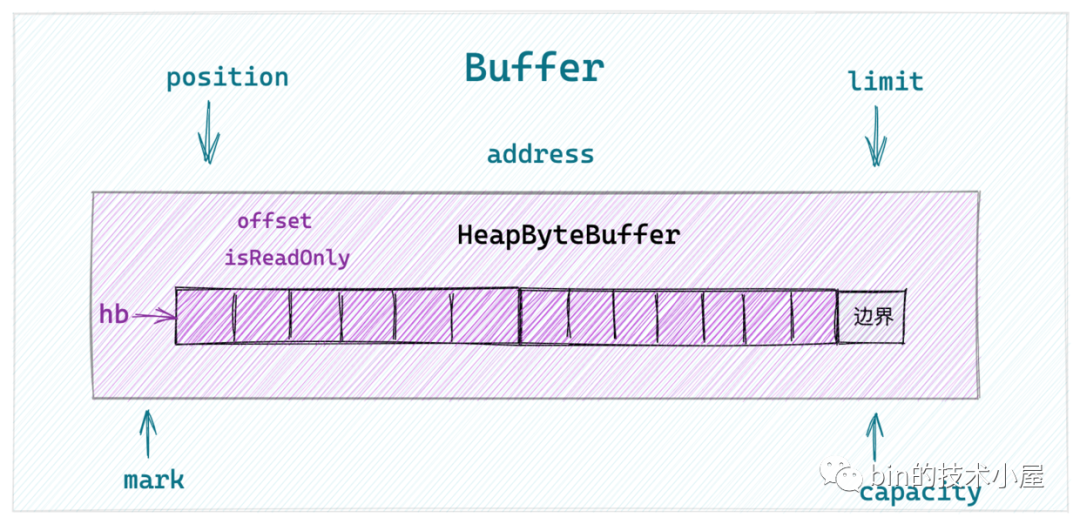
HeapByteBuffer结构.png
现在我们已经熟悉了 socket 文件的相关操作及其在内核中的实现,但笔者觉得这还不够,还是有必要在为大家介绍一下 JDK NIO 如何利用 ByteBuffer 对普通文件进行读写的相关原理及其实现,为大家彻底打通 Linux 文件操作相关知识的系统脉络,于是就有了本文的内容。
下面就让我们从一个普通的 IO 读写操作开始聊起吧~~~

本文概要.png
资料直通车:Linux内核源码技术学习路线+视频教程内核源码
学习直通车:Linux内核源码内存调优文件系统进程管理设备驱动/网络协议栈
2. JDK NIO 读取普通文件
我们先来看一个利用 NIO FileChannel 来读写普通文件的例子,由这个简单的例子开始,慢慢地来一步一步深入本质。
JDK NIO 中的 FileChannel 比较特殊,它只能是阻塞的,不能设置非阻塞模式。FileChannel的读写方法均是线程安全的。
注意:下面的例子并不是最佳实践,之所以这里引入 HeapByteBuffer 是为了将上篇文章的内容和本文衔接起来。事实上,对于 IO 的操作一般都会选择 DirectByteBuffer ,关于 DirectByteBuffer 的相关内容笔者会在后面的文章中详细为大家介绍。
FileChannel fileChannel = new RandomAccessFile(new File("file-read-write.txt"), "rw").getChannel();
ByteBuffer heapByteBuffer = ByteBuffer.allocate(4096);
fileChannel.read(heapByteBuffer);
我们首先利用 RandomAccessFile 在内核中打开指定的文件 file-read-write.txt 并获取到它的文件描述符 fd = 5000。
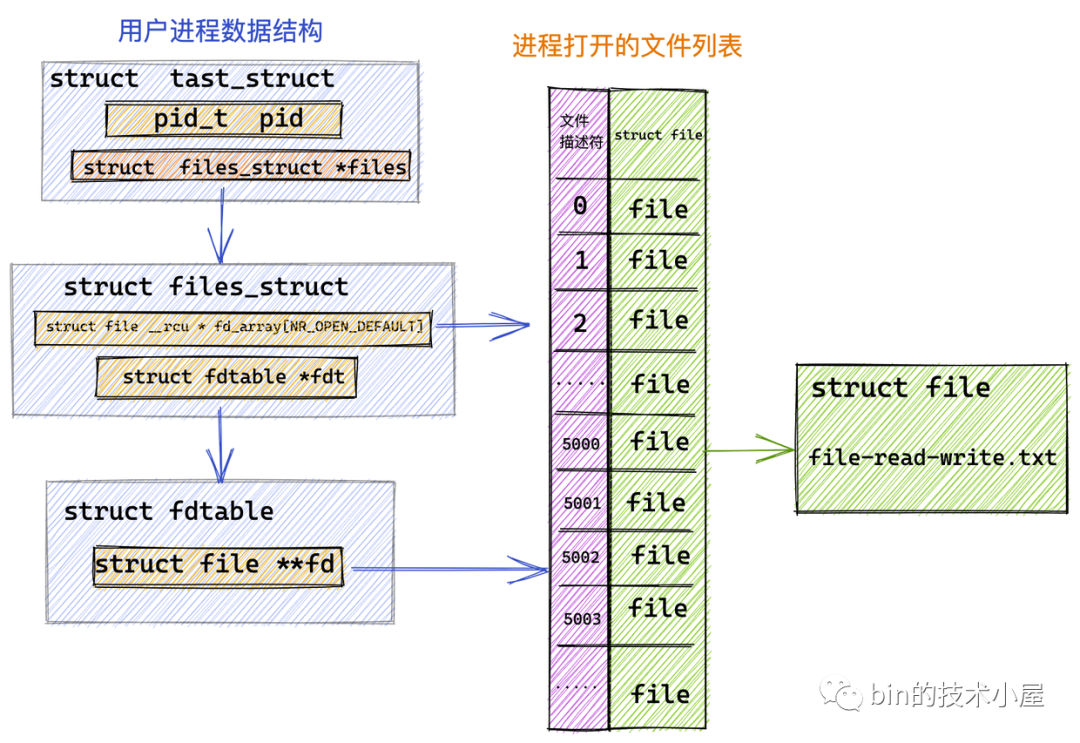
image.png
随后我们在 JVM 堆中开辟一块 4k 大小的虚拟内存 heapByteBuffer,用来读取文件中的数据。

image.png
操作系统在管理内存的时候是将内存分为一页一页来管理的,每页大小为 4k ,我们在操作内存的时候一定要记得进行页对齐,也就是偏移位置以及读取的内存大小需要按照 4k 进行对齐。具体为什么?文章后边会从内核角度详细为大家介绍。
最后通过 FileChannel#read 方法触发底层系统调用 read。进行文件读取。
public class FileChannelImpl extends FileChannel {
// 前边介绍打开的文件描述符 5000
private final FileDescriptor fd;
// NIO 中用它来触发 native read 和 write 的系统调用
private final FileDispatcher nd;
// 读写文件时加锁,前边介绍 FileChannel 的读写方法均是线程安全的
private final Object positionLock = new Object();
public int read(ByteBuffer dst) throws IOException {
synchronized (positionLock) {
.......... 省略 .......
try {
.......... 省略 .......
do {
n = IOUtil.read(fd, dst, -1, nd);
} while ((n == IOStatus.INTERRUPTED) && isOpen());
return IOStatus.normalize(n);
} finally {
.......... 省略 .......
}
}
}
}
我们看到在 FileChannel 中会调用 IOUtil 的 read 方法,NIO 中的所有 IO 操作全部封装在 IOUtil 类中。
而 NIO 中的 SocketChannel 以及这里介绍的 FileChannel 底层依赖的系统调用可能不同,这里会通过 NativeDispatcher 对具体 Channel 操作实现分发,调用具体的系统调用。对于 FileChannel 来说 NativeDispatcher 的实现类为 FileDispatcher。对于 SocketChannel 来说 NativeDispatcher 的实现类为 SocketDispatcher。
下面我们进入 IOUtil 里面来一探究竟~~
public class IOUtil {
static int read(FileDescriptor fd, ByteBuffer dst, long position,
NativeDispatcher nd)
throws IOException
{
.......... 省略 .......
.... 创建一个临时的directByteBuffer....
try {
int n = readIntoNativeBuffer(fd, directByteBuffer, position, nd);
.......... 省略 .......
.... 将directByteBuffer中读取到的内容再次拷贝到heapByteBuffer中给用户返回....
return n;
} finally {
.......... 省略 .......
}
}
private static int readIntoNativeBuffer(FileDescriptor fd, ByteBuffer bb,
long position, NativeDispatcher nd)
throws IOException
{
int pos = bb.position();
int lim = bb.limit();
assert (pos <= lim);
int rem = (pos <= lim ? lim - pos : 0);
.......... 省略 .......
if (position != -1) {
.......... 省略 .......
} else {
n = nd.read(fd, ((DirectBuffer)bb).address() + pos, rem);
}
if (n > 0)
bb.position(pos + n);
return n;
}
}
我们看到 FileChannel 的 read 方法最终会调用到 NativeDispatcher 的 read 方法。前边我们介绍了这里的 NativeDispatcher 就是 FileDispatcher 在 NIO 中的实现类为 FileDispatcherImpl,用来触发 native 方法执行底层系统调用。
class FileDispatcherImpl extends FileDispatcher {
int read(FileDescriptor fd, long address, int len) throws IOException {
return read0(fd, address, len);
}
static native int read0(FileDescriptor fd, long address, int len)
throws IOException;
}
最终在 FileDispatcherImpl 类中触发了 native 方法 read0 的调用,我们继续到 FileDispatcherImpl.c 文件中去查看 native 方法的实现。
// FileDispatcherImpl.c 文件
JNIEXPORT jint JNICALL Java_sun_nio_ch_FileDispatcherImpl_read0(JNIEnv *env, jclass clazz,
jobject fdo, jlong address, jint len)
{
jint fd = fdval(env, fdo);
void *buf = (void *)jlong_to_ptr(address);
// 发起 read 系统调用进入内核
return convertReturnVal(env, read(fd, buf, len), JNI_TRUE);
}
系统调用 read(fd, buf, len) 最终是在 native 方法 read0 中被触发的。下面是系统调用 read 在内核中的定义。
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count){
...... 省略 ......
}
这样一来我们就从 JDK NIO 这一层逐步来到了用户空间与内核空间的边界处 --- OS 系统调用 read 这里,马上就要进入内核了。

image.png
下面我们就来看一下当系统调用 read 发起之后,用户进程在内核态具体做了哪些事情?
3. 从内核角度探秘文件读取本质
内核将文件的 IO 操作根据是否使用内存(页高速缓存 page cache)做磁盘热点数据的缓存,将文件 IO 分为:Buffered IO 和 Direct IO 两种类型。
进程在通过系统调用 open() 打开文件的时候,可以通过将参数 flags 赋值为 O_DIRECT 来指定文件操作为 Direct IO。默认情况下为 Buffered IO。
int open(const char *pathname, int flags, mode_t mode);
而 Java 在 JDK 10 之前一直是不支持 Direct IO 的,到了 JDK 10 才开始支持 Direct IO。但是在 JDK 10 之前我们可以使用第三方的 Direct IO 框架 Jaydio 来通过 Direct IO 的方式对文件进行读写操作。
Jaydio GitHub :https://github.com/smacke/jaydio
下面笔者就带大家从内核角度深度剖析下这两种 IO 类型各自的特点:
3.1 Buffered IO
大部分文件系统默认的文件 IO 类型为 Buffered IO,当进程进行文件读取时,内核会首先检查文件对应的页高速缓存 page cache 中是否已经缓存了文件数据,如果有则直接返回,如果没有才会去磁盘中去读取文件数据,而且还会根据非常精妙的预读算法来预先读取后续若干文件数据到 page cache 中。这样等进程下一次顺序读取文件时,想要的数据已经预读进 page cache 中了,进程直接返回,不用再到磁盘中去龟速读取了,这样一来就极大地提高了 IO 性能。
比如一些著名的消息队列中间件 Kafka , RocketMq 对消息日志文件进行顺序读取的时候,访问速度接近于内存。这就是 Buffered IO 中页高速缓存 page cache 的功劳。在本文的后面,笔者会为大家详细的介绍这一部分内容。
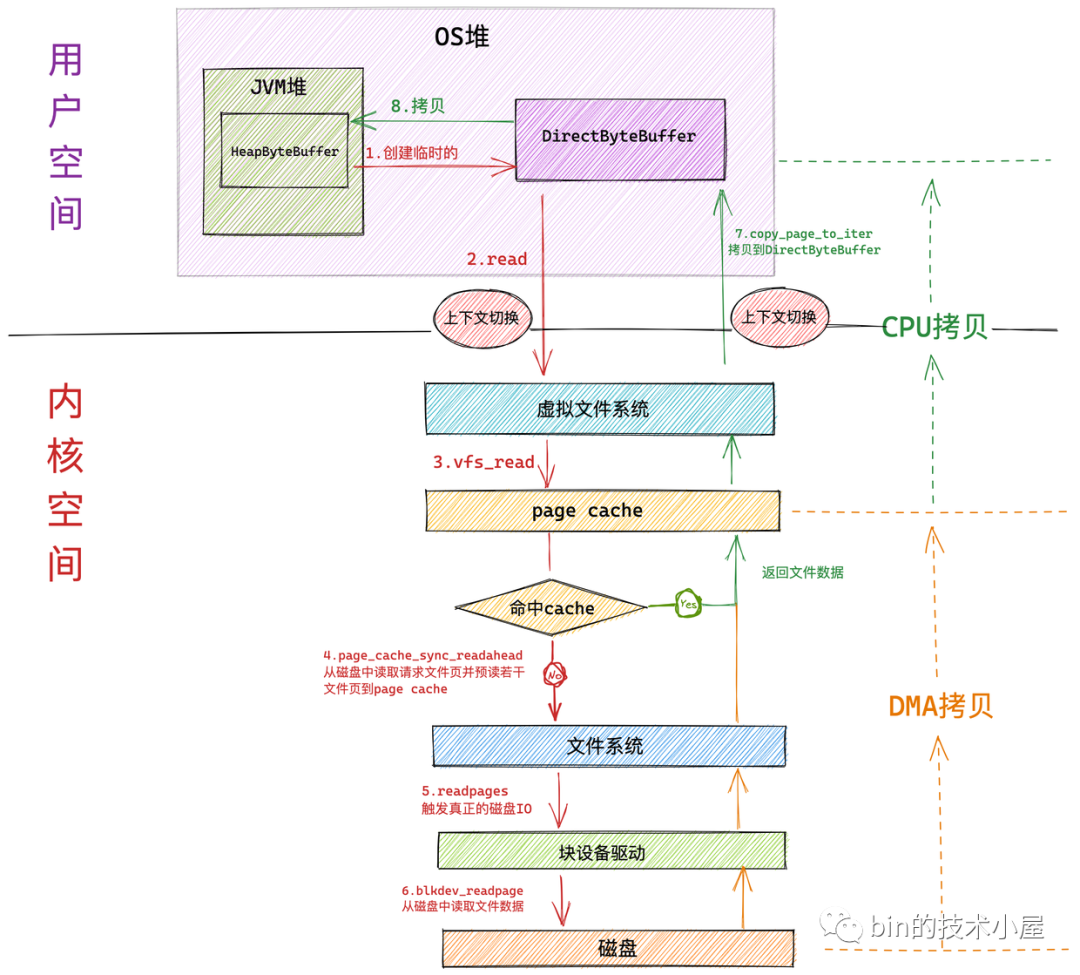
HeapByteBuffer 来接收 NIO 读取文件数据的时候,整个文件读取的过程分为如下几个步骤:
-
NIO 首先会将创建一个临时的 DirectByteBuffer 用于临时接收文件数据。
具体为什么会创建一个临时的 DirectByteBuffer 来接收数据以及关于 DirectByteBuffer 的原理笔者会在后面的文章中为大家详细介绍。这里大家可以把它简单看成在 OS 堆中的一块虚拟内存地址。
-
随后 NIO 会在用户态调用系统调用 read 向内核发起文件读取的请求。此时发生第一次上下文切换。
-
用户进程随即转到内核态运行,进入虚拟文件系统层,在这一层内核首先会查看读取文件对应的页高速缓存 page cache 中是否含有请求的文件数据,如果有直接返回,避免一次磁盘 IO。并根据内核预读算法从磁盘中异步预读若干文件数据到 page cache 中(文件顺序读取高性能的关键所在)。
在内核中,一个文件对应一个 page cache 结构,注意:这个 page cache 在内存中只会有一份。
-
如果进程请求数据不在 page cache 中,则会进入文件系统层,在这一层调用块设备驱动程序触发真正的磁盘 IO。并根据内核预读算法同步预读若干文件数据。请求的文件数据和预读的文件数据将被一起填充到 page cache 中。
-
在块设备驱动层完成真正的磁盘 IO。在这一层会从磁盘中读取进程请求的文件数据以及内核预读的文件数据。
-
磁盘控制器 DMA 将从磁盘中读取的数据拷贝到页高速缓存 page cache 中。发生第一次数据拷贝。
-
随后 CPU 将 page cache 中的数据拷贝到 NIO 在用户空间临时创建的缓冲区 DirectByteBuffer 中,发生第二次数据拷贝。
-
最后系统调用 read 返回。进程从内核态切换回用户态。发生第二次上下文切换。
-
NIO 将 DirectByteBuffer 中临时存放的文件数据拷贝到 JVM 堆中的 HeapBytebuffer 中。发生第三次数据拷贝。
我们看到如果使用 HeapByteBuffer 进行 NIO 文件读取的整个过程中,一共发生了 两次上下文切换和三次数据拷贝,如果请求的数据命中 page cache 则发生两次数据拷贝省去了一次磁盘的 DMA 拷贝。
3.2 Direct IO
在上一小节中,笔者介绍了 Buffered IO 的诸多好处,尤其是在进程对文件进行顺序读取的时候,访问性能接近于内存。
但是有些情况,我们并不需要 page cache。比如一些高性能的数据库应用程序,它们在用户空间自己实现了一套高效的高速缓存机制,以充分挖掘对数据库独特的查询访问性能。所以这些数据库应用程序并不希望内核中的 page cache起作用。否则内核会同时处理 page cache 以及预读相关操作的指令,会使得性能降低。
另外还有一种情况是,当我们在随机读取文件的时候,也不希望内核使用 page cache。因为这样违反了程序局部性原理,当我们随机读取文件的时候,内核预读进 page cache 中的数据将很久不会再次得到访问,白白浪费 page cache 空间不说,还额外增加了预读的磁盘 IO。
基于以上两点原因,我们很自然的希望内核能够提供一种机制可以绕过 page cache 直接对磁盘进行读写操作。这种机制就是本小节要为大家介绍的 Direct IO。
下面是内核采用 Direct IO 读取文件的工作流程:
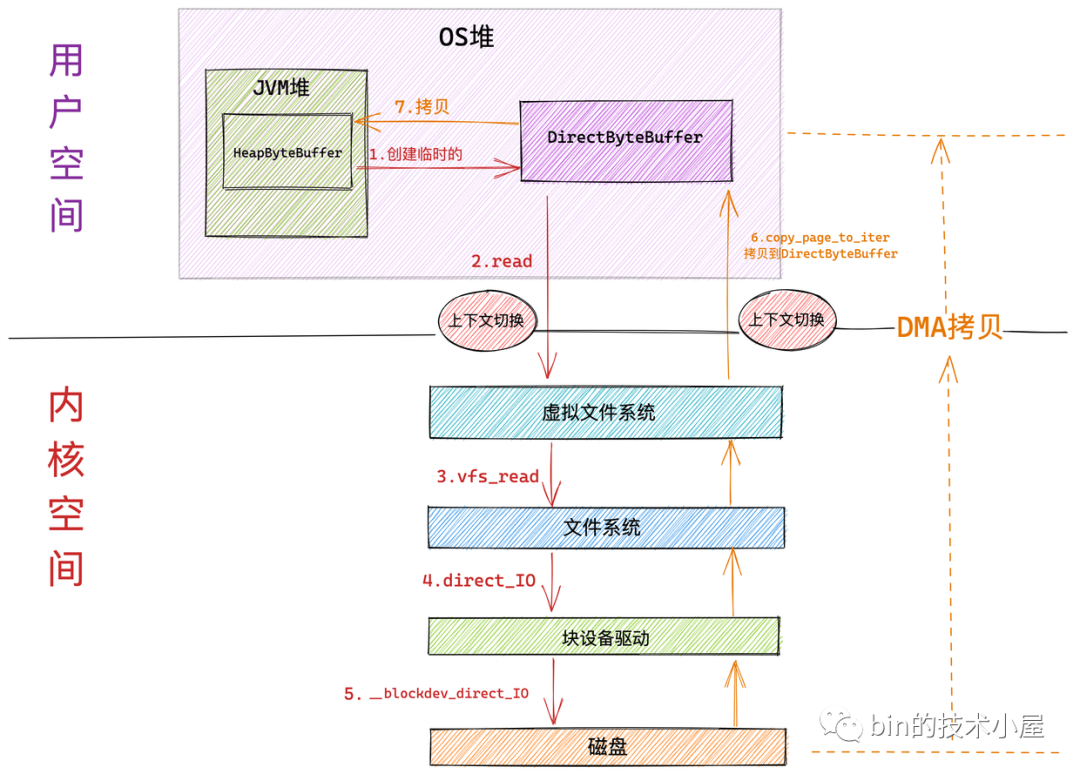
image.png
Direct IO 和 Buffered IO 在进入内核虚拟文件系统层之前的流程全部都是一样的。区别就是进入到虚拟文件系统层之后,Direct IO 会绕过 page cache 直接来到文件系统层通过 direct_io 调用来到块驱动设备层,在块设备驱动层调用 __blockdev_direct_IO 对磁盘内容直接进行读写。
-
和 Buffered IO 一样,在系统调用 read 进入内核以及 Direct IO 完成从内核返回的时候各自会发生一次上下文切换。共两次上下文切换
-
磁盘控制器 DMA 从磁盘中读取数据后直接拷贝到用户空间缓冲区 DirectByteBuffer 中。只发生一次 DMA 拷贝
-
随后 NIO 将 DirectByteBuffer 中临时存放的数据拷贝到 JVM 堆 HeapByteBuffer 中。发生第二次数据拷贝。
-
注意块设备驱动层的 __blockdev_direct_IO 需要等到所有的 Direct IO 传送数据完成之后才会返回,这里的传送指的是直接从磁盘拷贝到用户空间缓冲区中,当 Direct IO 模式下的 read() 或者 write() 系统调用返回之后,进程就可以安全放心地去读取用户缓冲区中的数据了。
从整个 Direct IO 的过程中我们看到,一共发生了两次上下文的切换,两次的数据拷贝。
4. Talk is cheap ! show you the code
下面是系统调用 read 在内核中的完整定义:
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count) {
// 根据文件描述符获取文件对应的 struct file结构
struct fd f = fdget_pos(fd);
.....
// 获取当前文件的读取位置 offset
loff_t pos = file_pos_read(f.file);
// 进入虚拟文件系统层,执行具体的文件操作
ret = vfs_read(f.file, buf, count, &pos);
......
}
首先会根据文件描述符 fd 通过 fdget_pos 方法获取 struct fd 结构,进而可以获取到文件的 struct file 结构。
struct fd {
struct file *file;
int need_put;
};
file_pos_read 获取当前文件的读取位置 offset,并通过 vfs_read 进入虚拟文件系统层。
ssize_t __vfs_read (struct file *file, char __user *buf, size_t count, loff_t *pos) {
if (file->f_op->read)
return file->f_op->read(file, buf, count, pos);
else if (file->f_op->read_iter)
return new_sync_read(file, buf, count, pos);
else
return -EINVAL;
}
这里我们看到内核对文件的操作全部定义在 struct file 结构中的 f_op 字段中。
struct file {
const struct file_operations *f_op;
}
对于 Java 程序员来说,file_operations 大家可以把它当做内核针对文件相关操作定义的一个公共接口(其实就是一个函数指针),它只是一个接口。具体的实现根据不同的文件类型有所不同。
比如我们在深入讲解Netty那些事儿之从内核角度看IO模型一文中详细介绍过的 Socket 文件。针对 Socket 文件类型,这里的 file_operations 指向的是 socket_file_ops。
static const struct file_operations socket_file_ops = {
.owner = THIS_MODULE,
.llseek = no_llseek,
.read_iter = sock_read_iter,
.write_iter = sock_write_iter,
.poll = sock_poll,
.unlocked_ioctl = sock_ioctl,
.mmap = sock_mmap,
.release = sock_close,
.fasync = sock_fasync,
.sendpage = sock_sendpage,
.splice_write = generic_splice_sendpage,
.splice_read = sock_splice_read,
};
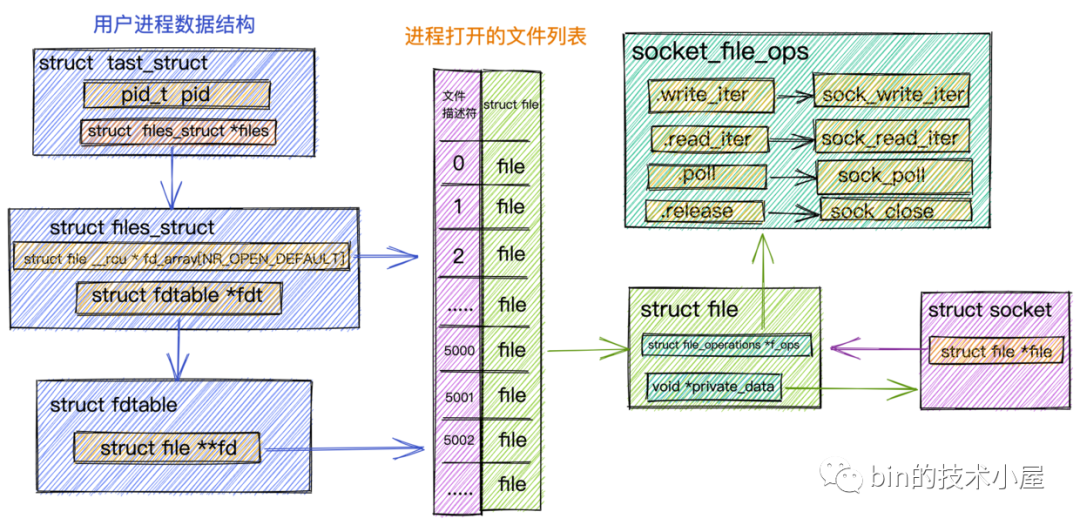
进程中管理文件列表结构.png
而本小节中我们讨论的是对普通文件的操作,针对普通文件的操作定义在具体的文件系统中,这里我们以 Linux 中最为常见的 ext4 文件系统为例说明:
在 ext4 文件系统中管理的文件对应的 file_operations 指向 ext4_file_operations,专门用于操作 ext4 文件系统中的文件。
const struct file_operations ext4_file_operations = {
......省略........
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
......省略.........
}
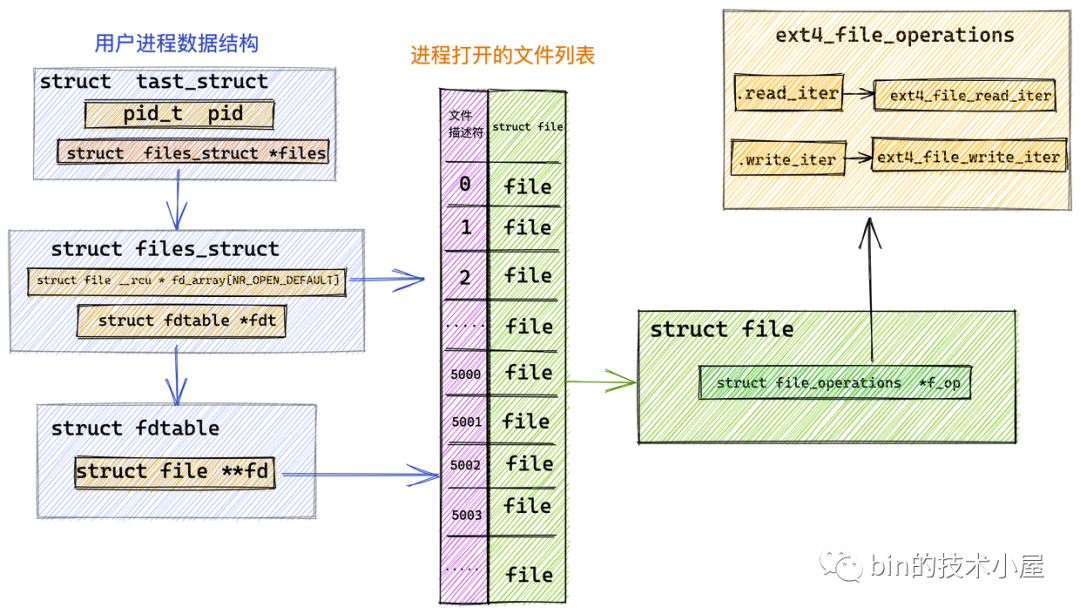
image.png
从图中我们可以看到 ext4 文件系统定义的相关文件操作 ext4_file_operations 并未定义 .read 函数指针。而是定义了 .read_iter 函数指针,指向 ext4_file_read_iter 函数。
ssize_t __vfs_read (struct file *file, char __user *buf, size_t count, loff_t *pos) {
if (file->f_op->read)
return file->f_op->read(file, buf, count, pos);
else if (file->f_op->read_iter)
return new_sync_read(file, buf, count, pos);
else
return -EINVAL;
}
所以在虚拟文件系统 VFS 中,__vfs_read 调用的是 new_sync_read 方法,在该方法中会对系统调用传进来的参数进行重新封装。比如:
-
struct file *filp :要读取文件的 struct file 结构。
-
char __user *buf :用户空间的 Buffer,这里指的我们例子中 NIO 创建的临时 DirectByteBuffer。
-
size_t count :进行读取的字节数。也就是我们传入的用户态缓冲区 DirectByteBuffer 剩余可容纳的容量大小。
-
loff_t *pos :文件当前读取位置偏移 offset。
将这些参数重新封装到 struct iovec 和 struct kiocb 结构体中。
ssize_t new_sync_read(struct file *filp, char __user *buf, size_t len, loff_t *ppos)
{
// 将 DirectByteBuffer 以及要读取的字节数封装进 iovec 结构体中
struct iovec iov = { .iov_base = buf, .iov_len = len };
struct kiocb kiocb;
struct iov_iter iter;
ssize_t ret;
// 利用文件 struct file 初始化 kiocb 结构体
init_sync_kiocb(&kiocb, filp);
// 设置文件读取偏移
kiocb.ki_pos = *ppos;
// 读取文件字节数
kiocb.ki_nbytes = len;
// 初始化 iov_iter 结构
iov_iter_init(&iter, READ, &iov, 1, len);
// 最终调用 ext4_file_read_iter
ret = filp->f_op->read_iter(&kiocb, &iter);
.......省略......
return ret;
}
struct iovec 结构体主要用来封装用来接收文件数据用的用户缓存区相关的信息:
struct iovec
{
void __user *iov_base; // 用户空间缓存区地址 这里是 DirectByteBuffer 的地址
__kernel_size_t iov_len; // 缓冲区长度
}
但是内核中一般会使用 struct iov_iter 结构体对 struct iovec 进行包装,iov_iter 中可以包含多个 iovec。这一点从 struct iov_iter 结构体的命名关键字 iter 上可以看得出来。
struct iov_iter {
......省略.....
const struct iovec *iov;
}
之所以使用 struct iov_iter 结构体来包装 struct iovec 是为了兼容 readv() 系统调用,它允许用户使用多个用户缓存区去读取文件中的数据。JDK NIO Channel 支持的 scatter 操作底层原理就是 readv 系统调用。
FileChannel fileChannel = new RandomAccessFile(new File("file-read-write.txt"), "rw").getChannel();
ByteBuffer heapByteBuffer1 = ByteBuffer.allocate(4096);
ByteBuffer heapByteBuffer2 = ByteBuffer.allocate(4096);
ByteBuffer[] scatter = { heapByteBuffer1, heapByteBuffer2 };
fileChannel.read(scatter);
struct kiocb 结构体则是用来封装文件 IO 相关操作的状态和进度信息:
struct kiocb {
struct file *ki_filp; // 要读取的文件 struct file 结构
loff_t ki_pos; // 文件读取位置偏移,表示文件处理进度
void (*ki_complete)(struct kiocb *iocb, long ret); // IO完成回调
int ki_flags; // IO类型,比如是 Direct IO 还是 Buffered IO
........省略.......
};
当 struct iovec 和 struct kiocb 在 new_sync_read 方法中被初始化好之后,最终通过 file_operations 中定义的函数指针 .read_iter 调用到 ext4_file_read_iter 方法中,从而进入 ext4 文件系统执行具体的读取操作。
static ssize_t ext4_file_read_iter(struct kiocb *iocb, struct iov_iter *to)
{
........省略........
return generic_file_read_iter(iocb, to);
}
ssize_t generic_file_read_iter(struct kiocb *iocb, struct iov_iter *iter)
{
........省略........
if (iocb->ki_flags & IOCB_DIRECT) {
........ Direct IO ........
// 获取 page cache
struct address_space *mapping = file->f_mapping;
........省略........
// 绕过 page cache 直接从磁盘中读取数据
retval = mapping->a_ops->direct_IO(iocb, iter);
}
........ Buffered IO ........
// 从 page cache 中读取数据
retval = generic_file_buffered_read(iocb, iter, retval);
}
generic_file_read_iter 会根据 struct kiocb 中的 ki_flags 属性判断文件 IO 操作是 Direct IO 还是 Buffered IO。
4.1 Direct IO
image.png
我们可以通过 open 系统调用在打开文件的时候指定相关 IO 操作的模式是 Direct IO 还是 Buffered IO:
int open(const char *pathname, int flags, mode_t mode);
-
char *pathname :指定要文件的路径。
-
int flags :指定文件的访问模式。比如:O_RDONLY(只读),O_WRONLY,(只写), O_RDWR(读写),O_DIRECT(Direct IO)。默认为 Buffered IO。
-
mode_t mode :可选,指定打开文件的权限
而 Java 在 JDK 10 之前一直是不支持 Direct IO,到了 JDK 10 才开始支持 Direct IO。
Path path = Paths.get("file-read-write.txt");
FileChannel fc = FileChannel.open(p, ExtendedOpenOption.DIRECT);
如果在文件打开的时候,我们设置了 Direct IO 模式,那么以后在对文件进行读取的过程中,内核将会绕过 page cache,直接从磁盘中读取数据到用户空间缓冲区 DirectByteBuffer 中。这样就可以避免一次数据从内核 page cache 到用户空间缓冲区的拷贝。
当应用程序期望使用自定义的缓存算法从而可以在用户空间实现更加高效更加可控的缓存逻辑时(比如数据库等应用程序),这时应该使用直接 Direct IO。在随机读取,随机写入的场景中也是比较适合用 Direct IO。
操作系统进程在接下来使用 read() 或者 write() 系统调用去读写文件的时候使用的是 Direct IO 方式,所传输的数据均不经过文件对应的高速缓存 page cache (这里就是网上常说的内核缓冲区)。
我们都知道操作系统是将内存分为一页一页的单位进行组织管理的,每页大小 4K ,那么同样文件中的数据在磁盘中的组织形式也是按照一块一块的单位来组织管理的,每块大小也是 4K ,所以我们在使用 Direct IO 读写数据时必须要按照文件在磁盘中的组织单位进行磁盘块大小对齐,缓冲区的大小也必须是磁盘块大小的整数倍。具体表现在如下几点:
-
文件的读写位置偏移需要按照磁盘块大小对齐。
-
用户缓冲区 DirectByteBuffer 起始地址需要按照磁盘块大小对齐。
-
使用 Direct IO 进行数据读写时,读写的数据大小需要按照磁盘块大小进行对齐。这里指 DirectByteBuffer 中剩余数据的大小。
当我们采用 Direct IO 直接读取磁盘中的文件数据时,内核会从 struct file 结构中获取到该文件在内存中的 page cache。而我们多次提到的这个 page cache 在内核中的数据结构就是 struct address_space 。我们可以根据 file->f_mapping 获取。
struct file {
// page cache
struct address_space *f_mapping;
}
和前面我们介绍的 struct file 结构中的 file_operations 一样,内核中将 page cache 相关的操作全部定义在 struct address_space_operations 结构中。这里和前边介绍的 file_operations 的作用是一样的,只是内核针对 page cache 操作定义的一个公共接口。
struct address_space {
const struct address_space_operations *a_ops;
}
具体的实现会根据文件系统的不同而不同,这里我们还是以 ext4 文件系统为例:
static const struct address_space_operations ext4_aops = {
.direct_IO = ext4_direct_IO,
};
内核通过 struct address_space_operations 结构中定义的 .direct_IO 函数指针,具体函数为 ext4_direct_IO 来绕过 page cache 直接对磁盘进行读写。
采用 Direct IO 的方式对文件的读写操作全部是在 ext4_direct_IO 这一个函数中完成的。
由于磁盘文件中的数据是按照块为单位来组织管理的,所以文件系统其实就是一个块设备,通过 ext4_direct_IO 绕过 page cache 直接来到了文件系统的块设备驱动层,最终在块设备驱动层调用 __blockdev_direct_IO 来完成磁盘的读写操作。
注意:块设备驱动层的 __blockdev_direct_IO 需要等到所有的 Direct IO 传送数据完成之后才会返回,这里的传送指的是直接从磁盘拷贝到用户空间缓冲区中,当 Direct IO 模式下的 read() 或者 write() 系统调用返回之后,进程就可以安全放心地去读取用户缓冲区中的数据了。
4.2 Buffered IO
image.png
Buffered IO 相关的读取操作封装在 generic_file_buffered_read 函数中,其核心逻辑如下:
-
由于文件在磁盘中是以块为单位组织管理的,每块大小为 4k,内存是按照页为单位组织管理的,每页大小也是 4k。文件中的块数据被缓存在 page cache 中的缓存页中。所以首先通过 find_get_page 方法查找我们要读取的文件数据是否已经缓存在了 page cache 中。
-
如果 page cache 中不存在文件数据的缓存页,就需要通过 page_cache_sync_readahead 方法从磁盘中读取数据并缓存到 page cache 中。于此同时还需要同步预读若干相邻的数据块到 page cache 中。这样在下一次顺序读取的时候,直接就可以从 page cache 中读取了。
-
如果此次读取的文件数据已经存在于 page cache 中了,就需要调用 PageReadahead 来判断是否需要进一步预读数据到缓存页中。如果是,则从磁盘中异步预读若干页到 page cache 中。具体预读多少页是根据内核相关预读算法来动态调整的。
-
经过上面几个流程,此时文件数据已经存在于 page cache 中的缓存页中了,最后内核调用 copy_page_to_iter 方法将 page cache 中的数据拷贝到用户空间缓冲区 DirectByteBuffer 中。
static ssize_t generic_file_buffered_read(struct kiocb *iocb,
struct iov_iter *iter, ssize_t written)
{
// 获取文件在内核中对应的 struct file 结构
struct file *filp = iocb->ki_filp;
// 获取文件对应的 page cache
struct address_space *mapping = filp->f_mapping;
// 获取文件的 inode
struct inode *inode = mapping->host;
...........省略...........
// 开始 Buffered IO 读取逻辑
for (;;) {
// 用于从 page cache 中获取缓存的文件数据 page
struct page *page;
// 根据文件读取偏移计算出 第一个字节所在物理页的索引
pgoff_t index;
// 根据文件读取偏移计算出 第一个字节所在物理页中的页内偏移
unsigned long offset;
// 在 page cache 中查找是否有读取数据在内存中的缓存页
page = find_get_page(mapping, index);
if (!page) {
if (iocb->ki_flags & IOCB_NOWAIT) {
....... 如果设置的是异步IO,则直接返回 -EAGAIN ......
}
// 要读取的文件数据在 page cache 中没有对应的缓存页
// 则从磁盘中读取文件数据,并同步预读若干相邻的数据块到 page cache中
page_cache_sync_readahead(mapping,
ra, filp,
index, last_index - index);
// 再一次触发缓存页的查找,这一次就可以找到了
page = find_get_page(mapping, index);
if (unlikely(page == NULL))
goto no_cached_page;
}
//如果读取的文件数据已经在 page cache 中了,则判断是否进行近一步的预读操作
if (PageReadahead(page)) {
//异步预读若干文件数据块到 page cache 中
page_cache_async_readahead(mapping,
ra, filp, page,
index, last_index - index);
}
..............省略..............
//将 page cache 中的数据拷贝到用户空间缓冲区 DirectByteBuffer 中
ret = copy_page_to_iter(page, offset, nr, iter);
}
}

image.png
到这里关于文件读取的两种模式 Buffered IO 和 Direct IO 在内核中的主干逻辑流程笔者就为大家介绍完了。
但是大家可能会对 Buffered IO 中的两个细节比较感兴趣:
-
如何在 page cache 中查找我们要读取的文件数据 ?也就是说上面提到的 find_get_page 函数是如何实现的?
-
文件预读的过程是怎么样的?内核中的预读算法又是什么样的呢?
在为大家解答这两个疑问之前,笔者先为大家介绍一下内核中的页高速缓存 page cache。
5. 页高速缓存 page cache
CPU 的高速缓存时曾提到过,根据摩尔定律:芯片中的晶体管数量每隔 18 个月就会翻一番。导致 CPU 的性能和处理速度变得越来越快,而提升 CPU 的运行速度比提升内存的运行速度要容易和便宜的多,所以就导致了 CPU 与内存之间的速度差距越来越大。
CPU 与内存之间的速度差异到底有多大呢?我们知道寄存器是离 CPU 最近的,CPU 在访问寄存器的时候速度近乎于 0 个时钟周期,访问速度最快,基本没有时延。而访问内存则需要 50 - 200 个时钟周期。
所以为了弥补 CPU 与内存之间巨大的速度差异,提高 CPU 的处理效率和吞吐,于是我们引入了 L1 , L2 , L3 高速缓存集成到 CPU 中。CPU 访问高速缓存仅需要用到 1 - 30 个时钟周期,CPU 中的高速缓存是对内存热点数据的一个缓存。

CPU缓存结构.png
而本文我们讨论的主题是内存与磁盘之间的关系,CPU 访问磁盘的速度就更慢了,需要用到大概约几千万个时钟周期.
我们可以看到 CPU 访问高速缓存的速度比访问内存的速度快大约10倍,而访问内存的速度要比访问磁盘的速度快大约 100000 倍。
引入 CPU 高速缓存的目的在于消除 CPU 与内存之间的速度差距,CPU 用高速缓存来存放内存中的热点数据。那么同样的道理,本小节中我们引入的页高速缓存 page cache 的目的是为了消除内存与磁盘之间的巨大速度差距,page cache 中缓存的是磁盘文件的热点数据。
另外我们根据程序的时间局部性原理可以知道,磁盘文件中的数据一旦被访问,那么它很有可能在短期被再次访问,如果我们访问的磁盘文件数据缓存在 page cache 中,那么当进程再次访问的时候数据就会在 page cache 中命中,这样我们就可以把对磁盘的访问变为对物理内存的访问,极大提升了对磁盘的访问性能。
程序局部性原理表现为:时间局部性和空间局部性。时间局部性是指如果程序中的某条指令一旦执行,则不久之后该指令可能再次被执行;如果某块数据被访问,则不久之后该数据可能再次被访问。空间局部性是指一旦程序访问了某个存储单元,则不久之后,其附近的存储单元也将被访问。
在前边的内容中我们多次提到操作系统是将物理内存分为一个一个的页面来组织管理的,每页大小为 4k ,而磁盘中的文件数据在磁盘中是分为一个一个的块来组织管理的,每块大小也为 4k。
page cache 中缓存的就是这些内存页面,页面中的数据对应于磁盘上物理块中的数据。page cache 中缓存的大小是可以动态调整的,它可以通过占用空闲内存来扩大缓存页面的容量,当内存不足时也可以通过回收页面来缓解内存使用的压力。
正如我们上小节介绍的 read 系统调用在内核中的实现逻辑那样,当用户进程发起 read 系统调用之后,内核首先会在 page cache 中检查请求数据所在页面是否已经缓存在 page cache 中。
-
如果缓存命中,内核直接会把 page cache 中缓存的磁盘文件数据拷贝到用户空间缓冲区 DirectByteBuffer 中,从而避免了龟速的磁盘 IO。
-
如果缓存没有命中,内核会分配一个物理页面,将这个新分配的页面插入 page cache 中,然后调度磁盘块 IO 驱动从磁盘中读取数据,最后用从磁盘中读取的数据填充这个物里页面。
根据前面介绍的程序时间局部性原理,当进程在不久之后再来读取数据的时候,请求的数据已经在 page cache 中了。极大地提升了文件 IO 的性能。
page cache 中缓存的不仅有基于文件的缓存页,还会缓存内存映射文件,以及磁盘块设备文件。这里大家只需要有这个概念就行,本文我们主要聚焦于基于文件的缓存页。在笔者后面的文章中,我们还会再次介绍到这些剩余类型的缓存页。
在我们了解了 page cache 引入的目的以及 page cache 在磁盘 IO 中所发挥的作用之后,大家一定会很好奇这个 page cache 在内核中到底是怎么实现的呢?
让我们先从 page cache 在内核中的数据结构开始聊起~~~~
6. page cache 在内核中的数据结构
page cache 在内核中的数据结构是一个叫做 address_space 的结构体:struct address_space。
这个名字起的真是有点词不达意,从命名上根本无法看出它是表示 page cache 的,所以大家在日常开发中一定要注意命名的精准规范。
每个文件都会有自己的 page cache。struct address_space 结构在内存中只会保留一份。
什么意思呢?比如我们可以通过多个不同的进程打开一个相同的文件,进程每打开一个文件,内核就会为它创建 struct file 结构。这样在内核中就会有多个 struct file 结构来表示同一个文件,但是同一个文件的 page cache 也就是 struct address_space 在内核中只会有一个。
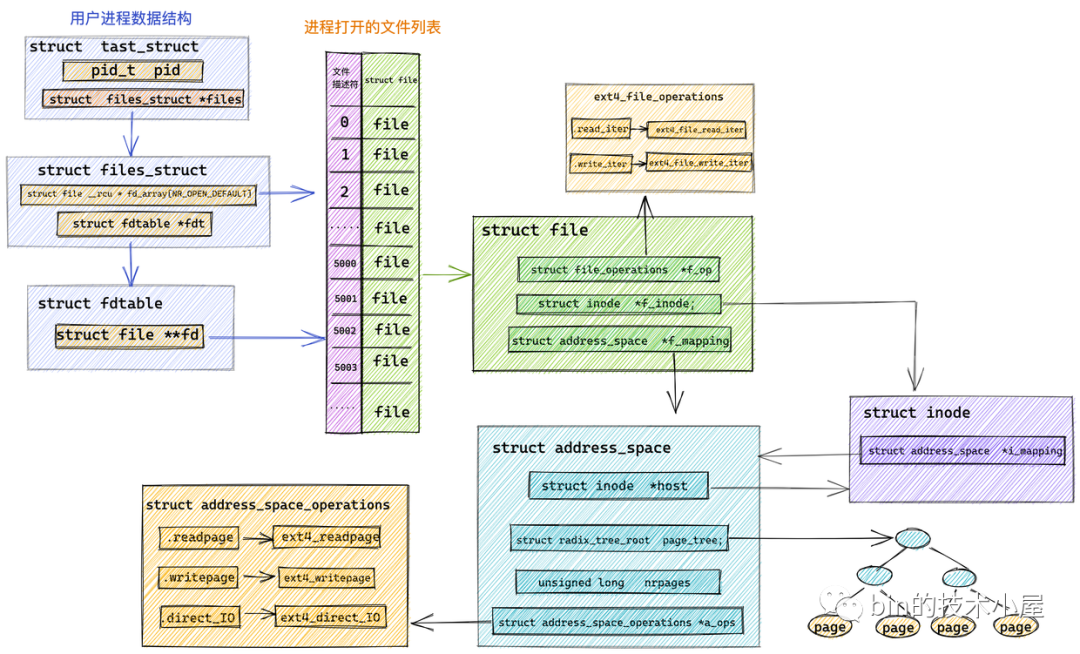
image.png
struct address_space {
struct inode *host; // 关联 page cache 对应文件的 inode
struct radix_tree_root page_tree; // 这里就是 page cache。里边缓存了文件的所有缓存页面
spinlock_t tree_lock; // 访问 page_tree 时用到的自旋锁
unsigned long nrpages; // page cache 中缓存的页面总数
..........省略..........
const struct address_space_operations *a_ops; // 定义对 page cache 中缓存页的各种操作方法
..........省略..........
}
-
struct inode *host:一个文件对应一个 page cache 结构 struct address_space ,文件的 inode 描述了一个文件的所有元信息。在 struct address_space 中通过 host 指针与文件的 inode 关联。而在 inode 结构体 struct inode 中又通过 i_mapping 指针与文件的 page cache 进行关联。
struct inode {
struct address_space *i_mapping; // 关联文件的 page cache
}
-
struct radix_tree_root page_tree: page cache 中缓存的所有文件页全部存储在 radix_tree 这样一个高效搜索树结构当中。在文件 IO 相关的操作中,内核需要频繁大量地在 page cache 中搜索请求页是否已经缓存在页高速缓存中,所以针对 page cache 的搜索操作必须是高效的,否则引入 page cache 所带来的性能提升将会被低效的搜索开销所抵消掉。 -
unsigned long nrpages:记录了当前文件对应的 page cache 缓存页面的总数。 -
const struct address_space_operations *a_ops:a_ops 定义了 page cache 中所有针对缓存页的 IO 操作,提供了管理 page cache 的各种行为。比如:常用的页面读取操作 readPage() 以及页面写入操作 writePage() 等。保证了所有针对缓存页的 IO 操作必须是通过 page cache 进行的。
struct address_space_operations {
// 写入更新页面缓存
int (*writepage)(struct page *page, struct writeback_control *wbc);
// 读取页面缓存
int (*readpage)(struct file *, struct page *);
// 设置缓存页为脏页,等待后续内核回写磁盘
int (*set_page_dirty)(struct page *page);
// Direct IO 绕过 page cache 直接操作磁盘
ssize_t (*direct_IO)(struct kiocb *, struct iov_iter *iter);
........省略..........
}
前边我们提到 page cache 中缓存的不仅仅是基于文件的页,它还会缓存内存映射页,以及磁盘块设备文件,况且基于文件的内存页背后也有不同的文件系统。所以内核只是通过 a_ops 定义了操作 page cache 缓存页 IO 的通用行为定义。而具体的实现需要各个具体的文件系统通过自己定义的 address_space_operations 来描述自己如何与 page cache 进行交互。比如前边我们介绍的 ext4 文件系统就有自己的 address_space_operations 定义。
static const struct address_space_operations ext4_aops = {
.readpage = ext4_readpage,
.writepage = ext4_writepage,
.direct_IO = ext4_direct_IO,
........省略.....
};
在我们从整体上了解了 page cache 在内核中的数据结构 struct address_space 之后,我们接下来看一下 radix_tree 这个数据结构是如何支持内核来高效搜索文件页的,以及 page cache 中这些被缓存的文件页是如何组织管理的。
7. 基树 radix_tree
正如前边我们提到的,在文件 IO 相关的操作中,内核会频繁大量地在 page cache 中查找请求页是否在页高速缓存中。还有就是当我们访问大文件时(linux 能支持大到几个 TB 的文件),page cache 中将会充斥着大量的文件页。
基于上面提到的两个原因:一个是内核对 page cache 的频繁搜索操作,另一个是 page cache 中会缓存大量的文件页。所以内核需要采用一个高效的搜索数据结构来组织管理 page cache 中的缓存页。
本小节我们就来介绍下,page cache 中用来存储缓存页的数据结构 radix_tree。
在 linux 内核 5.0 版本中 radix_tree 已被替换成 xarray 结构。感兴趣的同学可以自行了解下。
在 page cache 结构 struct address_space 中有一个类型为 struct radix_tree_root 的字段 page_tree,它表示的是 radix_tree 的根节点。
struct address_space {
struct radix_tree_root page_tree; // 这里就是 page cache。里边缓存了文件的所有缓存页面
..........省略..........
}
struct radix_tree_root {
gfp_t gfp_mask;
struct radix_tree_node __rcu *rnode; // radix_tree 根节点
};
radix_tree 中的节点类型为 struct radix_tree_node。
struct radix_tree_node {
void __rcu *slots[RADIX_TREE_MAP_SIZE]; //包含 64 个指针的数组。用于指向下一层节点或者缓存页
unsigned char offset; //父节点中指向该节点的指针在父节点 slots 数组中的偏移
unsigned char count;//记录当前节点的 slots 数组指向了多少个节点
struct radix_tree_node *parent; // 父节点指针
struct radix_tree_root *root; // 根节点
..........省略.........
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS]; // radix_tree 中的二维标记数组,用于标记子节点的状态。
};
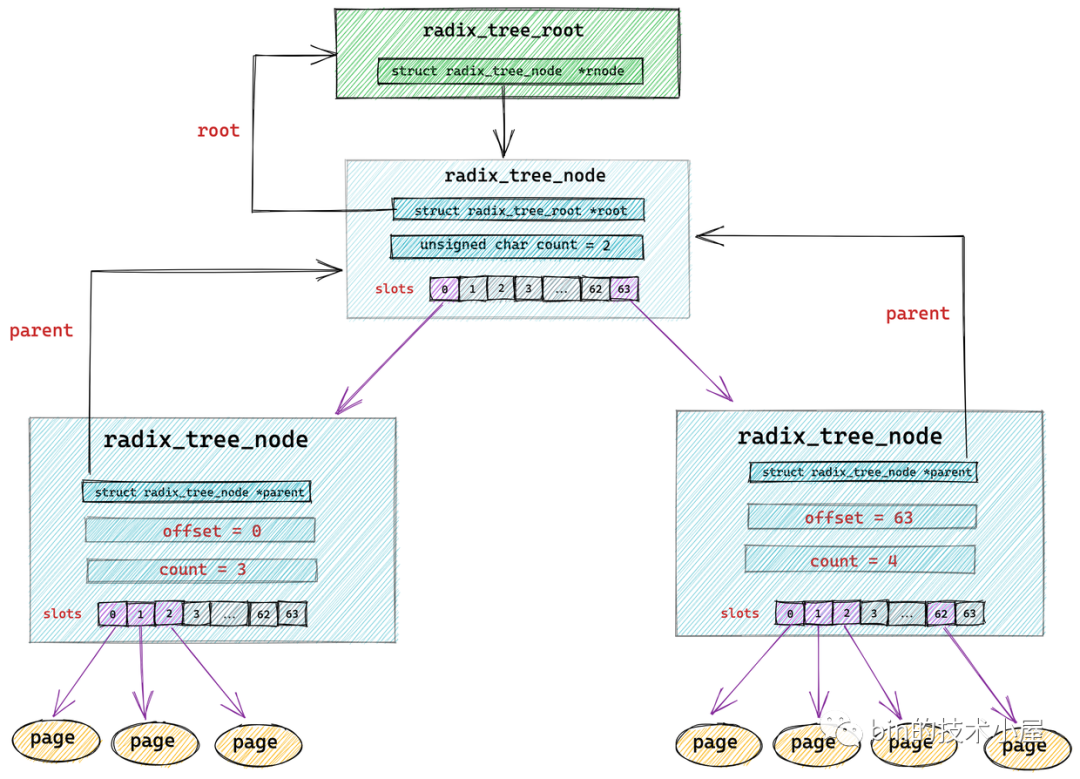
image.png
void __rcu *slots[RADIX_TREE_MAP_SIZE] :radix_tree 树中的每个节点中包含一个 slots ,它是一个包含 64 个指针的数组,每个指针指向它的下一层节点或者缓存页描述符 struct page。
radix_tree 将缓存页全部存放在它的叶子结点中,所以它的叶子结点类型为 struct page。其余的节点类型为 radix_tree_node。最底层的 radix_tree_node 节点中的 slots 指向缓存页描述符 struct page。
unsigned char offset 用于表示父节点的 slots 数组中指向当前节点的指针,在父节点的slots数组中的索引。
unsigned char count 用于记录当前 radix_tree_node 的 slots 数组中指向的节点个数,因为 slots 数组中的指针有可能指向 null 。
这里大家可能已经注意到了在 struct radix_tree_node 结构中还有一个 long 型的 tags 二维数组 tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS]。那么这个二维数组到底是用来干嘛的呢?我们接着往下看~~
7.1 radix_tree 的标记
经过前面的介绍我们知道,页高速缓存 page cache 的引入是为了在内存中缓存磁盘的热点数据尽可能避免龟速的磁盘 IO。
而在进行文件 IO 的时候,内核会频繁大量的在 page cache 中搜索请求数据是否已经缓存在 page cache 中,如果是,内核就直接将 page cache 中的数据拷贝到用户缓冲区中。从而避免了一次磁盘 IO。
这就要求内核需要采用一种支持高效搜索的数据结构来组织管理这些缓存页,所以引入了基树 radix_tree。
到目前为止,我们还没有涉及到缓存页的状态,不过在文章的后面我们很快就会涉及到,这里提前给大家引出来,让大家脑海里先有个概念。
那么什么是缓存页的状态呢?
我们知道在 Buffered IO 模式下,对于文件 IO 的操作都是需要经过 page cache 的,后面我们即将要介绍的 write 系统调用就会将数据直接写到 page cache 中,并将该缓存页标记为脏页(PG_dirty)直接返回,随后内核会根据一定的规则来将这些脏页回写到磁盘中,在会写的过程中这些脏页又会被标记为 PG_writeback,表示该页正在被回写到磁盘。
PG_dirty 和 PG_writeback 就是缓存页的状态,而内核不仅仅是需要在 page cache 中高效搜索请求数据所在的缓存页,还需要高效搜索给定状态的缓存页。
比如:快速查找 page cache 中的所有脏页。但是如果此时 page cache 中的大部分缓存页都不是脏页,那么顺序遍历 radix_tree 的方式就实在是太慢了,所以为了快速搜索到脏页,就需要在 radix_tree 中的每个节点 radix_tree_node 中加入一个针对其所有子节点的脏页标记,如果其中一个子节点被标记被脏时,那么这个子节点对应的父节点 radix_tree_node 结构中的对应脏页标记位就会被置 1 。
而用来存储脏页标记的正是上小节中提到的 tags 二维数组。其中第一维 tags[] 用来表示标记类型,有多少标记类型,数组大小就为多少,比如 tags[0] 表示 PG_dirty 标记数组,tags[1] 表示 PG_writeback 标记数组。
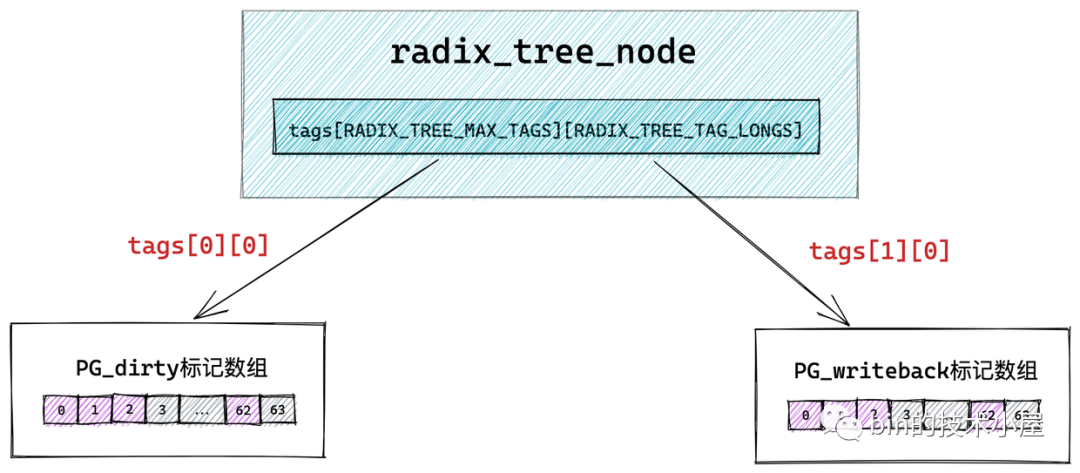
image.png
第二维 tags[][] 数组则表示对应标记类型针对每一个子节点的标记位,因为一个 radix_tree_node 节点中包含 64 个指针指向对应的子节点,所以二维 tags[][] 数组的大小也为 64 ,数组中的每一位表示对应子节点的标记。tags[0][0] 指向 PG_dirty 标记数组,tags[1][0] 指向PG_writeback 标记数组。
而缓存页( radix_tree 中的叶子结点)这些标记是存放在其对应的页描述符 struct page 里的 flag 中。
struct page {
unsigned long flags;
}
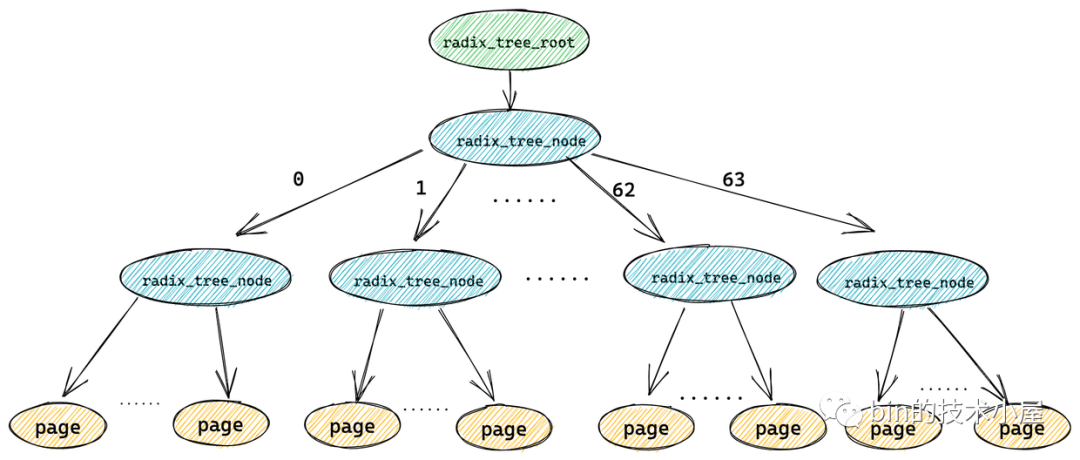
image.png
只要一个缓存页(叶子结点)被标记,那么从这个叶子结点一直到 radix_tree 根节点的路径将会全部被标记。这就好比你在一盆清水中滴入一滴墨水,不久之后整盆水就会变为黑色。
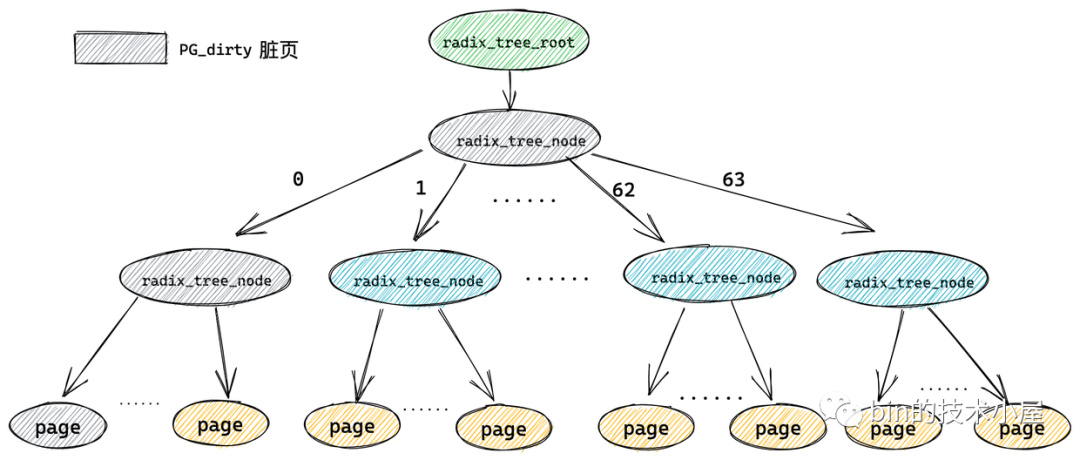
image.png
这样内核在 radix_tree 中搜索被标记的脏页(PG_dirty)或者正在回写的页(PG_writeback)时,就可以迅速跳过哪些标记为 0 的中间节点的所有子树,中间节点对应的标记为 0 说明其所有的子树中包含的缓存页(叶子结点)都是干净的(未标记)。从而达到在 radix_tree 中迅速搜索指定状态的缓存页的目的。
8. page cache 中查找缓存页
在我们明白了 radix_tree 这个数据结构之后,接下来我们来看一下在《4.2 Buffered IO》小节中遗留的问题:内核如何通过 find_get_page 在 page cache 中高效查找缓存页?
在介绍 find_get_page 之前,笔者先来带大家看看 radix_tree 具体是如何组织和管理其中的缓存页 page 的。

image.png
经过上小节相关内容的介绍,我们了解到在 radix_tree 中每个节点 radix_tree_node 包含一个大小为 64 的指针数组 slots 用于指向它的子节点或者缓存页描述符(叶子节点)。
一个 radix_tree_node 节点下边最多可容纳 64 个子节点,如果 radix_tree 的深度为 1 (不包括叶子节点),那么这颗 radix_tree 就可以缓存 64 个文件页。而每页大小为 4k,所以一颗深度为 1 的 radix_tree 可以缓存 256k 的文件内容。
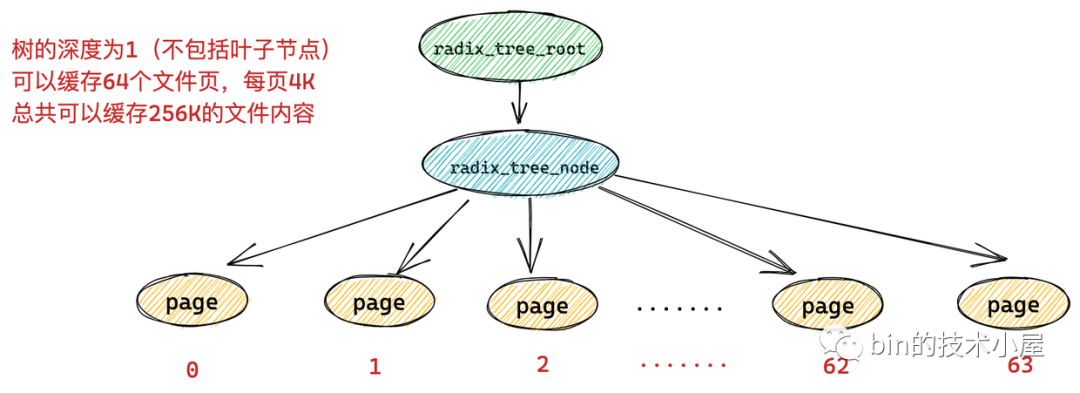
image.png
而如果一颗 radix_tree 的深度为 2,那么它就可以缓存 64 * 64 = 4096 个文件页,总共可以缓存 16M 的文件内容。
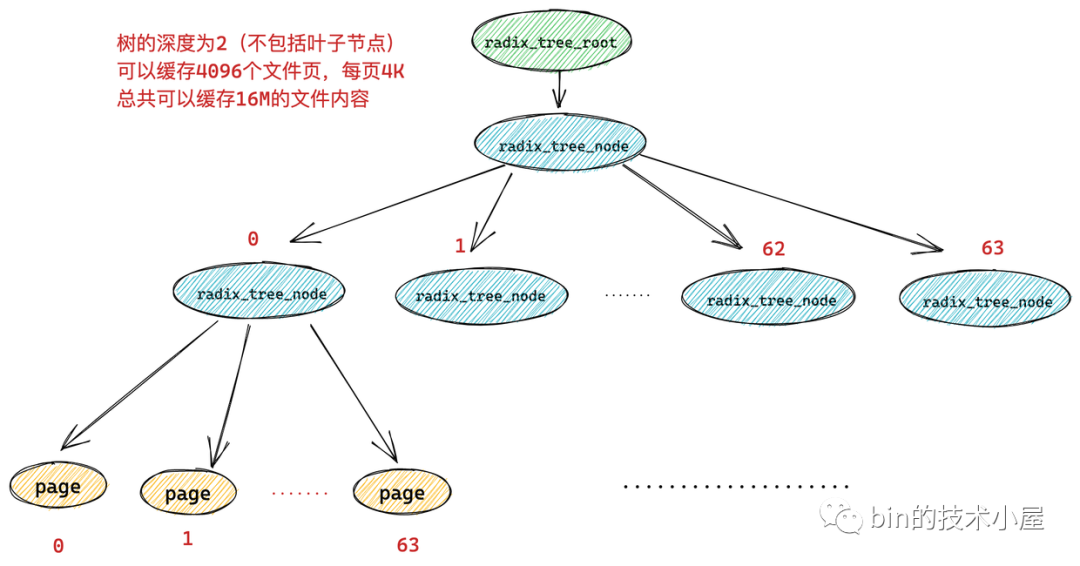
image.png
依次类推我们可以得到不同的 radix_tree 深度可以缓存多大的文件内容:
| radix_tree 深度 | page 最大索引值 | 缓存文件大小 |
|---|---|---|
| 1 | 2^6 - 1 = 63 | 256K |
| 2 | 2^12 - 1 = 4095 | 16M |
| 3 | 2^18 - 1 = 262143 | 1G |
| 4 | 2^24 -1 =16777215 | 64G |
| 5 | 2^30 - 1 | 4T |
| 6 | 2^36 - 1 | 64T |
通过以上内容的介绍,我们看到在 radix_tree 是根据缓存页的 index (索引)来组织管理缓存页的,内核会根据这个 index 迅速找到对应的缓存页。在缓存页描述符 struct page 结构中保存了其在 page cache 中的索引 index。
struct page {
unsigned long flags; //缓存页标记
struct address_space *mapping; // 缓存页所在的 page cache
unsigned long index; // 页索引
...
}
事实上 find_get_page 函数也是根据缓存页描述符中的这个 index 来在 page cache 中高效查找对应的缓存页。
static inline struct page *find_get_page(struct address_space *mapping,
pgoff_t offset)
{
return pagecache_get_page(mapping, offset, 0, 0);
}
-
struct address_space *mapping: 为读取文件对应的 page cache 页高速缓存。 -
pgoff_t offset:为所请求的缓存页在 page cache 中的索引 index,类型为 long 型。
那么在内核是如何利用这个 long 型的 offset 在 page cache 中高效搜索指定的缓存页呢?
经过前边我们对 radix_tree 结构的介绍,我们已经知道 radix_tree 中每个节点 radix_tree_node 包含一个大小为 64 的指针数组 slots 用于指向它的子节点或者缓存页描述符。
一个 radix_tree_node 节点下边最多可容纳 64 个子节点,如果 radix_tree 的深度为 1 (不包括叶子节点),那么这颗 radix_tree 就可以缓存 64 个文件页。只能表示 0 - 63 的索引范围,所以 long 型的缓存页 offset 的低 6 位可以表示这个范围,对应于第一层 radix_tree_node 节点的 slots 数组下标。
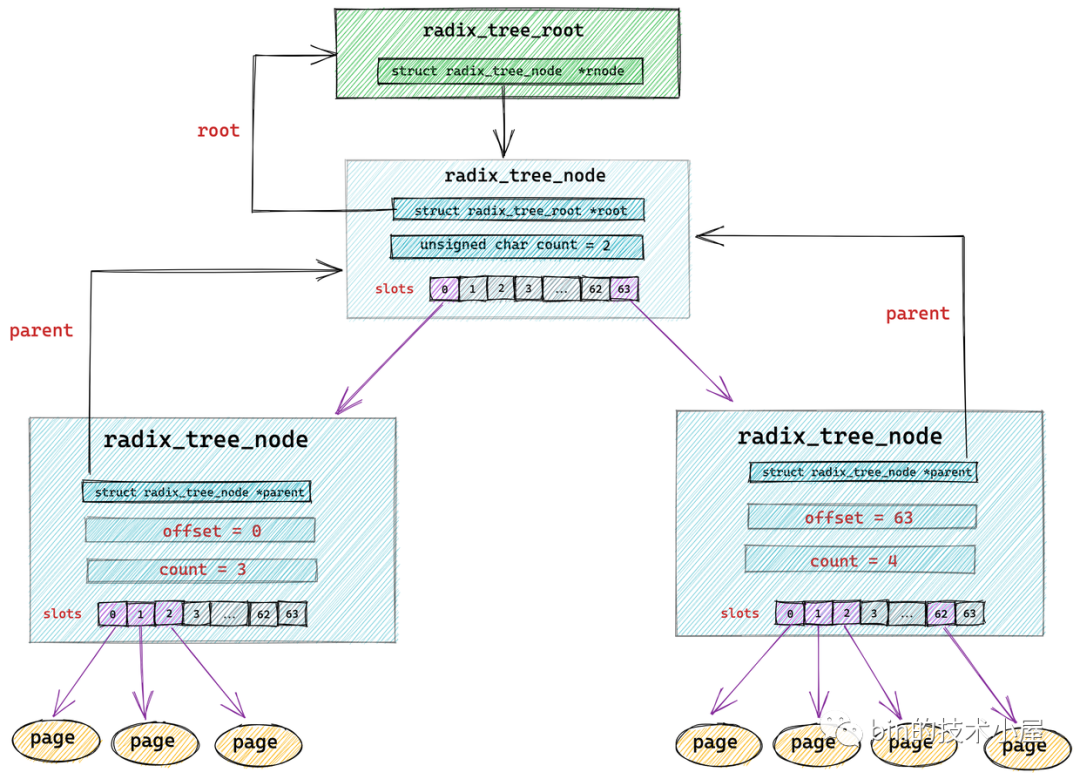
image.png
如果一颗 radix_tree 的深度为 2(不包括叶子节点),那么它就可以缓存 64 * 64 = 4096 个文件页,表示的索引范围为 0 - 4095,在这种情况下,缓存页索引 offset 的低 12 位可以分成 两个 6 位的字段,高位的字段用来表示第一层节点的 slots 数组的下标,低位字段用于表示第二层节点的 slots 数组下标。
依次类推,如果 radix_tree 的深度为 6 那么它可以缓存 64T 的文件页,表示的索引范围为:0 到 2^36 - 1。缓存页索引 offset 的低 36 位可以分成 六 个 6 位的字段。缓存页索引的最高位字段来表示 radix_tree 中的第一层节点中的 slots 数组下标,接下来的 6 位字段表示第二层节点中的 slots 数组下标,这样一直到最低的 6 位字段表示第 6 层节点中的 slots 数组下标。
通过以上根据缓存页索引 offset 的查找过程,我们看出内核在 page cache 查找缓存页的时间复杂度和 radix_tree 的深度有关。
在我们理解了内核在 radix_tree 中的查找缓存页逻辑之后,再来看 find_get_page 的代码实现就变得很简单了~~
struct page *pagecache_get_page(struct address_space *mapping, pgoff_t offset,
int fgp_flags, gfp_t gfp_mask)
{
struct page *page;
repeat:
// 在 radix_tree 中根据 缓存页 offset 查找缓存页
page = find_get_entry(mapping, offset);
// 缓存页不存在的话,跳转到 no_page 处理逻辑
if (!page)
goto no_page;
.......省略.......
no_page:
if (!page && (fgp_flags & FGP_CREAT)) {
// 分配新页
page = __page_cache_alloc(gfp_mask);
if (!page)
return NULL;
if (fgp_flags & FGP_ACCESSED)
//增加页的引用计数
__SetPageReferenced(page);
// 将新分配的内存页加入到页高速缓存 page cache 中
err = add_to_page_cache_lru(page, mapping, offset, gfp_mask);
.......省略.......
}
return page;
}
-
内核首先调用 find_get_entry 方法根据缓存页的 offset 到 page cache 中去查找看请求的文件页是否已经在页高速缓存中。如果存在直接返回。
-
如果请求的文件页不在 page cache 中,内核则会首先会在物理内存中分配一个内存页,然后将新分配的内存页加入到 page cache 中,并增加页引用计数。
-
随后会通过 address_space_operations 重定义的 readpage 激活块设备驱动从磁盘中读取请求数据,然后用读取到的数据填充新分配的内存页。
static const struct address_space_operations ext4_aops = {
.readpage = ext4_readpage,
.writepage = ext4_writepage,
.direct_IO = ext4_direct_IO,
........省略.....
};
9. 文件页的预读
之前我们在引入 page cache 的时候提到过,根据程序时间局部性原理:如果进程在访问某一块数据,那么在访问的不久之后,进程还会再次访问这块数据。所以内核引入了 page cache 在内存中缓存磁盘中的热点数据,从而减少对磁盘的 IO 访问,提升系统性能。
而本小节我们要介绍的文件页预读特性是根据程序空间局部性原理:当进程访问一段数据之后,那么在不就的将来和其临近的一段数据也会被访问到。所以当进程在访问文件中的某页数据的时候,内核会将它和临近的几个页一起预读到 page cache 中。这样当进程再次访问文件的时候,就不需要进行龟速的磁盘 IO 了,因为它所请求的数据已经预读进 page cache 中了。
我们常提到的当你顺序读取文件的时候,性能会非常的高,因为相当于是在读内存,这就是文件预读的功劳。
但是在我们随机访问文件的时候,文件预读不仅不会提高性能,返回会降低文件读取的性能,因为随机读取文件并不符合程序空间局部性原理,因此预读进 page cache 中的文件页通常是无效的,下一次根本不会再去读取,这无疑是白白浪费了 page cache 的空间,还额外增加了不必要的预读磁盘 IO。
事实上,在我们对文件进行随机读取的场景下,更适合用 Direct IO 的方式绕过 page cache 直接从磁盘中读取文件,还能减少一次从 page cache 到用户缓冲区的拷贝。
所以内核需要一套非常精密的预读算法来根据进程是顺序读文件还是随机读文件来精确地调控预读的文件页数,或者直接关闭预读。
-
进程在读取文件数据的时候都是逐页进行读取的,因此在预读文件页的时候内核并不会考虑页内偏移,而是根据请求数据在文件内部的页偏移进行读取。

image.png
-
如果进程持续的顺序访问一个文件,那么预读页数也会随着逐步增加。
-
当发现进程开始随机访问文件了(当前访问的文件页和最后一次访问的文件页 offset 不是连续的),内核就会逐步减少预读页数或者彻底禁止预读。
-
当内核发现进程再重复的访问同一文件页时或者文件中的文件页已经几乎全部缓存在 page cache 中了,内核此时就会禁止预读。
以上几点就是内核的预读算法的核心逻辑,从这个预读逻辑中我们可以看出,进程在进行文件读取的时候涉及到两种不同类型的页面集合,一个是进程可以请求的文件页(已经缓存在 page cache 中的文件页),另一个是内核预读的文件页。
而内核也确实按照这两种页面集合分为两个窗口:
-
当前窗口(current window): 表示进程本次文件请求可以直接读取的页面集合,这个集合中的页面全部已经缓存在 page cache 中,进程可以直接读取返回。当前窗口中包含进程本次请求的文件页以及上次内核预读的文件页集合。表示进程本次可以从 page cache 直接获取的页面范围。
-
预读窗口(ahead window):预读窗口的页面都是内核正在预读的文件页,它们此时并不在 page cache 中。这些页面并不是进程请求的文件页,但是内核根据空间局部性原理假定它们迟早会被进程请求。预读窗口内的页面紧跟着当前窗口后面,并且内核会动态调整预读窗口的大小(有点类似于 TCP 中的滑动窗口)。
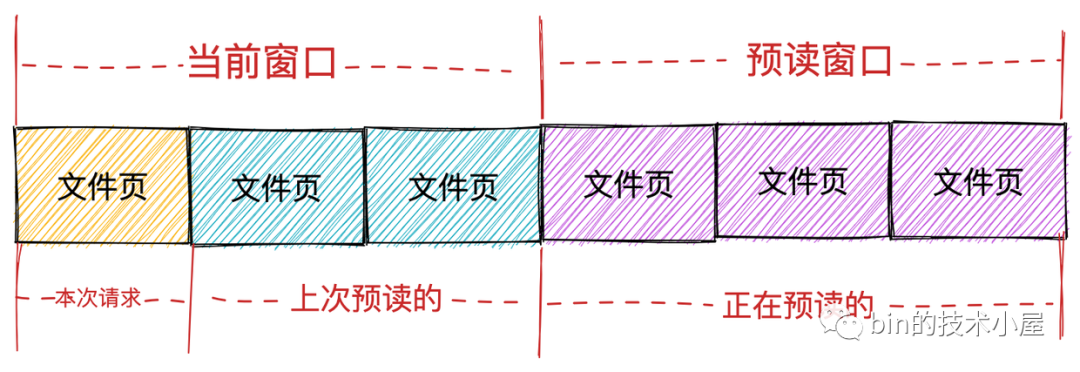
image.png
如果进程本次文件请求的第一页的 offset,紧跟着上一次文件请求的最后一页的 offset,内核就认为是顺序读取。在顺序读取文件的场景下,如果请求的第一页在当前窗口内,内核随后就会检查是否建立了预读窗口,如果没有就会创建预读窗口并触发相应页的读取操作。
在理想情况下,进程会继续在当前窗口内请求页,于此同时,预读窗口内的预读页同时异步传送着,这样进程在顺序读取文件的时候就相当于直接读取内存,极大地提高了文件 IO 的性能。
以上包含的这些文件预读信息,比如:如何判断进程是顺序读取还是随机读取,当前窗口信息,预读窗口信息。全部保存在 struct file 结构中的 f_ra 字段中。
struct file {
struct file_ra_state f_ra;
}
用于描述文件预读信息的结构体在内核中用 struct file_ra_state 结构体来表示:
struct file_ra_state {
pgoff_t start; // 当前窗口第一页的索引
unsigned int size; // 当前窗口的页数,-1表示临时禁止预读
unsigned int async_size; // 异步预读页面的页数
unsigned int ra_pages; // 文件允许的最大预读页数
loff_t prev_pos; // 进程最后一次请求页的索引
};
内核可以根据 start 和 prev_pos 这两个字段来判断进程是否在顺序访问文件。
ra_pages 表示当前文件允许预读的最大页数,进程可以通过系统调用 posix_fadvise() 来改变已打开文件的 ra_page 值来调优预读算法。
int posix_fadvise(int fd, off_t offset, off_t len, int advice);
该系统调用用来通知内核,我们将来打算以特定的模式 advice 访问文件数据,从而允许内核执行适当的优化。
advice 参数主要有下面几种数值:
-
POSIX_FADV_NORMAL :设置文件最大预读页数 ra_pages 为默认值 32 页。
-
POSIX_FADV_SEQUENTIAL :进程期望顺序访问指定的文件数据,ra_pages 值为默认值的两倍。
-
POSIX_FADV_RANDOM :进程期望以随机顺序访问指定的文件数据。ra_pages 设置为 0,表示禁止预读。
后来人们发现当禁止预读后,这样一页一页的读取性能非常的低下,于是 linux 3.19.8 之后 POSIX_FADV_RANDOM 的语义被改变了,它会在 file->f_flags 中设置 FMODE_RANDOM 属性(后面我们分析内核预读相关源码的时候还会提到),当遇到 FMODE_RANDOM 的时候内核就会走强制预读的逻辑,按最大 2MB 单元大小的 chunk 进行预读。
This fixes inefficient page-by-page reads on POSIX_FADV_RANDOM.
POSIX_FADV_RANDOM used to set ra_pages=0, which leads to poor
performance: a 16K read will be carried out in 4 _sync_ 1-page reads.
-
POSIX_FADV_WILLNEED :通知内核,进程指定这段文件数据将在不久之后被访问。
而触发内核进行文件预读的场景,分为以下几种:
-
当进程采用 Buffered IO 模式通过系统调用 read 进行文件读取时,内核会触发预读。
-
通过 POSIX_FADV_WILLNEED 参数执行系统调用 posix_fadvise,会通知内核这个指定范围的文件页不就将会被访问。触发预读。
-
当进程显示执行 readahead() 系统调用时,会显示触发内核的预读动作。
-
当内核为内存文件映射区域分配一个物理页面时,会触发预读。关于内存映射的相关内容,笔者会在后面的文章为大家详细介绍。
-
和 posix_fadvise 一样的道理,系统调用 madvise 主要用来指定内存文件映射区域的访问模式。可通过 advice = MADV_WILLNEED 通知内核,某个文件内存映射区域中的指定范围的文件页在不久将会被访问。触发预读。
int madvise(caddr_t addr, size_t len, int advice);
从触发内核预读的这几种场景中我们可以看出,预读分为主动触发和被动触发,在《4.2 Buffered IO》小节中遗留的 page_cache_sync_readahead 函数为被动触发,接下来我们来看下它在内核中的实现逻辑。
9.1 page_cache_sync_readahead
void page_cache_sync_readahead(struct address_space *mapping,
struct file_ra_state *ra, struct file *filp,
pgoff_t offset, unsigned long req_size)
{
// 禁止预读,直接返回
if (!ra->ra_pages)
return;
if (blk_cgroup_congested())
return;
// 通过 posix_fadvise 设置了 POSIX_FADV_RANDOM,内核走强制预读逻辑
if (filp && (filp->f_mode & FMODE_RANDOM)) {
// 按最大2MB单元大小的chunk进行预读
force_page_cache_readahead(mapping, filp, offset, req_size);
return;
}
// 执行预读逻辑
ondemand_readahead(mapping, ra, filp, false, offset, req_size);
}
!ra->ra_pages 表示 ra_pages 设置为 0 ,预读被禁止,直接返回。
如果进程通过前边介绍的 posix_fadvise 系统调用并且 advice 参数设置为 POSIX_FADV_RANDOM。在 linux 3.19.8 之后文件的 file->f_flags 属性会被设置为 FMODE_RANDOM,这样内核会走强制预读逻辑,按最大 2MB 单元大小的 chunk 进行预读。
int posix_fadvise(int fd, off_t offset, off_t len, int advice);
// mm/fadvise.c
switch (advice) {
.........省略........
case POSIX_FADV_RANDOM:
.........省略........
file->f_flags |= FMODE_RANDOM;
.........省略........
break;
.........省略........
}
而真正的预读逻辑封装在 ondemand_readahead 函数中。
9.2 ondemand_readahead
该方法中封装了前边介绍的预读算法逻辑,动态的调整当前窗口以及预读窗口的大小。
/*
* A minimal readahead algorithm for trivial sequential/random reads.
*/
static unsigned long
ondemand_readahead(struct address_space *mapping,
struct file_ra_state *ra, struct file *filp,
bool hit_readahead_marker, pgoff_t offset,
unsigned long req_size)
{
struct backing_dev_info *bdi = inode_to_bdi(mapping->host);
unsigned long max_pages = ra->ra_pages; // 默认32页
unsigned long add_pages;
pgoff_t prev_offset;
........预读算法逻辑,动态调整当前窗口和预读窗口.........
//根据条件,计算本次预读最大预读取多少个页,一般情况下是max_pages=32个页
if (req_size > max_pages && bdi->io_pages > max_pages)
max_pages = min(req_size, bdi->io_pages);
//offset即page index,如果page index=0,表示这是文件第一个页,
//内核认为是顺序读,跳转到initial_readahead进行处理
if (!offset)
goto initial_readahead;
initial_readahead:
// 当前窗口第一页的索引
ra->start = offset;
// get_init_ra_size初始化第一次预读的页的个数,一般情况下第一次预读是4个页
ra->size = get_init_ra_size(req_size, max_pages);
// 异步预读页面个数也就是预读窗口大小
ra->async_size = ra->size > req_size ? ra->size - req_size : ra->size;
// 默认情况下是 ra->start=0, ra->size=0, ra->async_size=0 ra->prev_pos=0
// 但是经过第一次预读后,上面三个值会出现变化
if ((offset == (ra->start + ra->size - ra->async_size) ||
offset == (ra->start + ra->size))) {
ra->start += ra->size;
ra->size = get_next_ra_size(ra, max_pages);
ra->async_size = ra->size;
goto readit;
}
//异步预读的时候会进入这个判断,更新ra的值,然后预读特定的范围的页
//异步预读的调用表示Readahead出来的页连续命中
if (hit_readahead_marker) {
pgoff_t start;
rcu_read_lock();
// 这个函数用于找到offset + 1开始到offset + 1 + max_pages这个范围内,第一个不在page cache的页的index
start = page_cache_next_miss(mapping, offset + 1, max_pages);
rcu_read_unlock();
if (!start || start - offset > max_pages)
return 0;
ra->start = start;
ra->size = start - offset; /* old async_size */
ra->size += req_size;
// 由于连续命中,get_next_ra_size会加倍上次的预读页数
// 第一次预读了4个页
// 第二次命中以后,预读8个页
// 第三次命中以后,预读16个页
// 第四次命中以后,预读32个页,达到默认情况下最大的读取页数
// 第五次、第六次、第N次命中都是预读32个页
ra->size = get_next_ra_size(ra, max_pages);
ra->async_size = ra->size;
goto readit;
........ 省略.........
return __do_page_cache_readahead(mapping, filp, offset, req_size, 0);
}
-
struct address_space *mapping: 读取文件对应的 page cache 结构。 -
struct file_ra_state *ra: 文件对应的预读状态信息,封装在 file->f_ra 中。 -
struct file *filp: 读取文件对应的 struct file 结构。 -
pgoff_t offset: 本次请求文件页在 page cache 中的索引。(文件页偏移) -
long req_size: 要完成当前读操作还需要读取的页数。
在预读算法逻辑中,内核通过 struct file_ra_state 结构中封装的文件预读信息来判断文件的读取是否为顺序读。比如:
-
通过检查 ra->prev_pos 和 offset 是否相同,来判断当前请求页是否和最近一次请求的页相同,如果重复访问同一页,预读就会停止。
-
通过检查 ra->prev_pos 和 offset 是否相邻,来判断进程是否顺序读取文件。如果是顺序访问文件,预读就会增加。
-
当进程第一次访问文件时,并且请求的第一个文件页在文件中的偏移量为 0 时表示进程从头开始读取文件,那么内核就会认为进程想要顺序的访问文件,随后内核就会从文件的第一页开始创建一个新的当前窗口,初始的当前窗口总是 2 的次幂,窗口具体大小与进程的读操作所请求的页数有一定的关系。请求页数越大,当前窗口就越大,直到最大值 ra->ra_pages 。
static unsigned long get_init_ra_size(unsigned long size, unsigned long max)
{
unsigned long newsize = roundup_pow_of_two(size);
if (newsize <= max / 32)
newsize = newsize * 4;
else if (newsize <= max / 4)
newsize = newsize * 2;
else
newsize = max;
return newsize;
}
-
相反,当进程第一次访问文件,但是请求页在文件中的偏移量不为 0 时,内核就会假定进程不准备顺序读取文件,函数就会暂时禁止预读。
-
一旦内核发现进程在当前窗口内执行了顺序读取,那么预读窗口就会被建立,预读窗口总是紧挨着当前窗口的最后一页。
-
预读窗口的大小和当前窗口有关,如果已经被预读的页不在 page cache 中(可能内存紧张,预读页被回收),那么预读窗口就会是
当前窗口大小 - 2,最小值为 4。否则预读窗口就会是当前窗口的4倍或者2倍。 -
当进程继续顺序访问文件时,最终预读窗口就会变为当前窗口,随后新的预读窗口就会被建立,随着进程顺序地读取文件,预读会越来越大,但是内核一旦发现对于文件的访问 offset 相对于上一次的请求页 ra->prev_pos 不是顺序的时候,当前窗口和预读窗口就会被清空,预读被暂时禁止。
当内核通过以上介绍的预读算法确定了预读窗口的大小之后,就开始调用 __do_page_cache_readahead 从磁盘去预读指定的页数到 page cache 中。
9.3 __do_page_cache_readahead
unsigned int __do_page_cache_readahead(struct address_space *mapping,
struct file *filp, pgoff_t offset, unsigned long nr_to_read,
unsigned long lookahead_size)
{
struct inode *inode = mapping->host;
struct page *page;
unsigned long end_index; /* The last page we want to read */
int page_idx;
unsigned int nr_pages = 0;
loff_t isize = i_size_read(inode);
end_index = ((isize - 1) >> PAGE_SHIFT);
/*
* 尽可能的一次性分配全部需要预读的页 nr_to_read
* 注意这里是尽可能的分配,意思就是能分配多少就分配多少,并不一定要全部分配
*/
for (page_idx = 0; page_idx < nr_to_read; page_idx++) {
pgoff_t page_offset = offset + page_idx;
if (page_offset > end_index)
break;
.......省略.....
// 首先在内存中为预读数据分配物理页面
page = __page_cache_alloc(gfp_mask);
if (!page)
break;
// 设置新分配的物理页在 page cache 中的索引
page->index = page_offset;
// 将新分配的物理页面加入到 page cache 中
list_add(&page->lru, &page_pool);
if (page_idx == nr_to_read - lookahead_size)
// 设置页面属性为 PG_readahead 后续会开启异步预读
SetPageReadahead(page);
nr_pages++;
}
/*
* 当需要预读的页面分配完毕之后,开始真正的 IO 动作,从磁盘中读取
* 数据填充 page cache 中的缓存页。
*/
if (nr_pages)
read_pages(mapping, filp, &page_pool, nr_pages, gfp_mask);
BUG_ON(!list_empty(&page_pool));
out:
return nr_pages;
}
内核调用 read_pages 方法激活磁盘块设备驱动程序从磁盘中读取文件数据之前,需要为本次进程读取请求所需要的所有页面尽可能地一次性全部分配,如果不能一次性分配全部页面,预读操作就只在分配好的缓存页面上进行,也就是说只从磁盘中读取数据填充已经分配好的页面。
文章篇幅有限,下文继续讲解

![[附源码]计算机毕业设计springboot作业管理系统](https://img-blog.csdnimg.cn/f3e184df1c9a4d7786cfa2158058e6d0.png)




![[附源码]JAVA毕业设计教学成果管理平台(系统+LW)](https://img-blog.csdnimg.cn/59b085d15b00453fa9b71794c7a4a8f3.png)


![[附源码]Python计算机毕业设计Django拉勾教育课程管理系统](https://img-blog.csdnimg.cn/e6eb28991ac649869bde836b30f4148d.png)

![[附源码]JAVA毕业设计教学辅助系统(系统+LW)](https://img-blog.csdnimg.cn/6cf8c2ea58e144f092580a9a3209e14a.png)
![[附源码]计算机毕业设计springboo酒店客房管理系统](https://img-blog.csdnimg.cn/bef4bdd7237243499b89ce7c0ec23782.png)