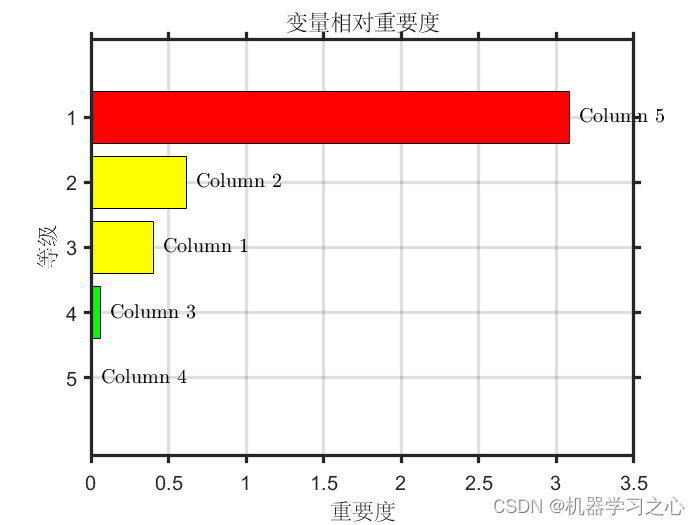
1.对比mapreduce和spark

mapreduce里 map的第3条就是说,比如我存了很多条数据,如果一条一条写进磁盘,肯定有很多次IO,我先归并到一个缓存里面再溢写磁盘。
spark与其的差别就是用map代替了buffer,因为map存的key唯一,用map的话可以直接完成combiner操作,且map的key里也有分区的key,避免了一定的排序操作。
除此之外,spark溢写也是必须触发磁盘的
但是多次利用的数据可以放入内存
=======================================================================

spark bypasshandle那个 就是map的时候直接根据最终分区号,直接将记录存入磁盘对应分区文件,中间什么都不干,也不对记录暂存排序,等到数据都map完得到一个个分区内的文件,最后线性IO拼接成一个大文件,并用一个索引文件记录每个分区对应的偏移量
而mapreduce是内存中开辟一个哈希环,每次记录存入环中,等到达到80%阈值,就用一个线程对环内数据进行排序,并溢写到一个磁盘小文件里面,这个小文件包含了各种分区,但内部有序。最终通过归并算法,再把各种小文件读到内存进行归并,IO拼接
java object有浪费空间的嫌疑,哈希表是用数组加链表形成,比如数组里面存的都是一个个元素,给他们指定了类型其实存的也就是一个个object对象,所以数组里面不仅仅是元素,还有各种对象头 链表等元数据,还有指针要指向堆里具体数据。这些加在一起都很浪费空间。 想做哈希表,可以直接数组里面直接指向堆里数据
前者速度快,浪费空间,后者速度慢需要cpu但剩空间,spark会用到后者,因为要保留内存
缺点就是 当分区数过多,每个分区内的文件大小就会很小,且文件数量会很多,在读取的时候,由于文件在磁盘的位置随机,就会有一个随机读写的情况,性能就会特别慢
所以 想走这种handle他还有一个限制,就是分区数小于两百,大于两百的话就只能走开辟内存的sortshuffle
===========================================================================
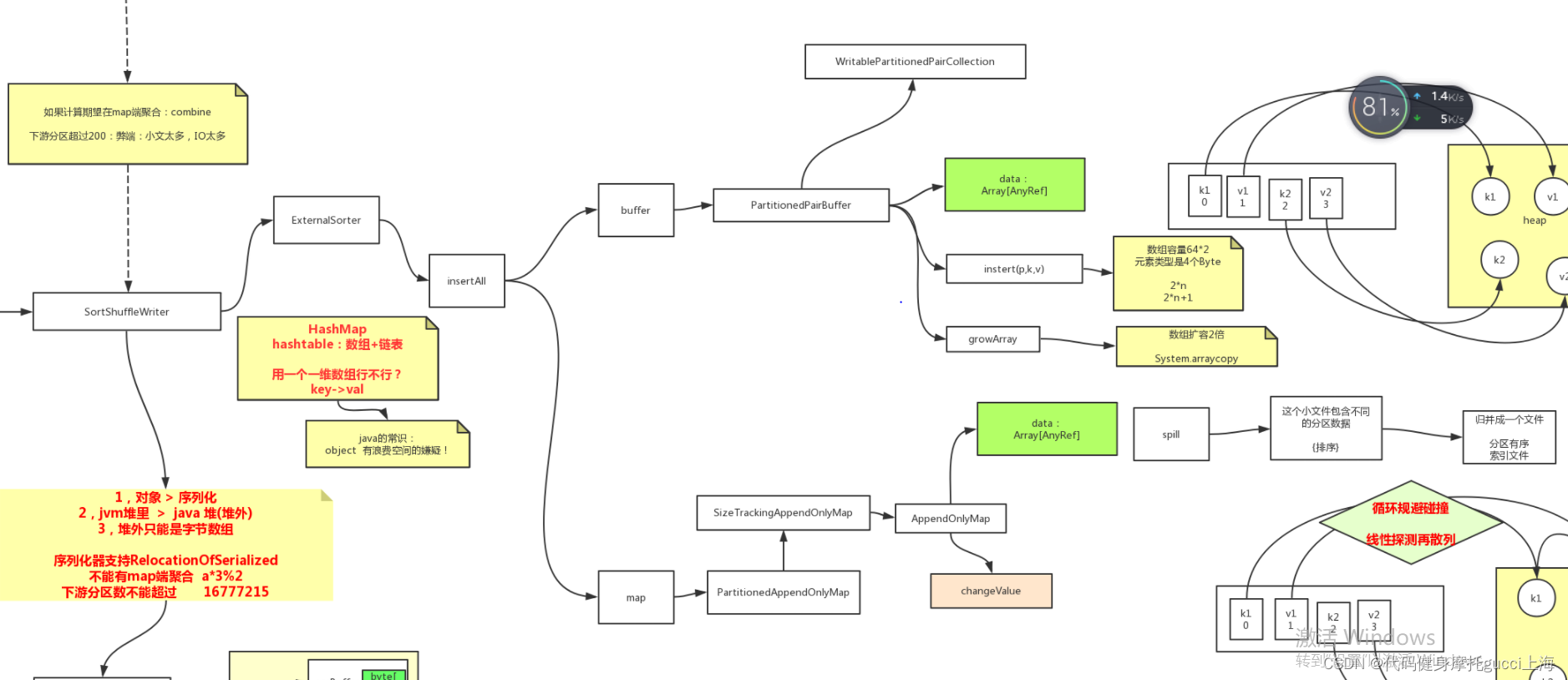
在sortshuffle里,如果是上述不开启合并但是分区数又特别多的情况会把数据存入内存缓冲区,内存缓冲区是一个数组,数组里存的都是对象引用,真正数据都在jvm堆里,相当于存了引用。 每次用insert方法像内存缓冲区去插入,且key为p和k,如果溢出了会调用growarry方法,扩大array至两倍
mapreduce和这个区别就是,它存放的内存是一个字节数组,或者说字节哈希表,也就是他是环形的,前面存具体的序列化后的数据kv,后面存其对应的索引位置,kv由于有大有小,所以每次占用空间不同,如果溢出会占用索引的位置来存放,在排序的时候,也是比较真实的key,而移动索引!
相同点就是,这两种情况在溢写时由于小文件内存的都是不同分区的数据,最终一定会发生排序,造成分区有序,然后再来一个归并排序IO,并生成相应的分区位置索引文件
如果是正常的比如reducebykey用的必须进行合并,他用的就是map,但是本质上还是一个数组,里面存的还是引用,不过在存的时候会根据key进行哈希运算确定未来最终要在数组存的位置,存的方式就是一个线性再探测法,比如先看你这个位置有没有存过,如果没存过直接放进去,存过就线性再探测。 如果已经存过相同key的,会有一个自定义的update函数来进行更新操作。 和mapreduce的区别就是,他直接在内存进行了聚合,而且存的全是引用不是具体值
=========================================================================
unsafesortshuffle
之所以有unsafesortshuffle,就是因为有以下一个常识,我们之前的放内存缓冲区是一个数组里面放了对象引用,jvm堆里放具体数据,但是这些都没有序列化(字节数组),真实的对象体积是大于序列化后体积,放jvm堆里也不如放java堆里(堆外)方便,因为最终要放磁盘如果是jvm堆是要用内核IO的,有个状态切换的过程浪费效率。注意,堆外只能是字节数组
unsafesortshuffle就是在以上优化下进行,但也有图中的限制条件

补充知识,内存的管理有一个page这个单位,主要原因是,数据存在内存中,还要存储其对应的索引、偏移量元数据等信息,也就是其在内存中的位置,这个时候,数据存储的单位越小,比如bit或byte,那么索引就会用大量空间记录其文件的位置,比如一个文件有4KB,用bit存储的话索引就是 第1bit第二个bit第三个bit。。。。什么什么是我的1号文件,这个时候如果数据存储的单位越大,那么其索引的占用空间就会越小,所以有了page概念,他的大小不是固定的。可以说他类似于虚拟映射

ShuffleExternalSorter这部分这个地方就是,我把读取的数据他本来是对象,我给他序列化成字节数组(方便存在缓冲区里面),然后我可以得到page的真实地址以及他的索引位置,(真实位置需要得到page的基地址和偏移量),然后我有一个inMemSorter来排序这些索引!

上图是executor的具体构造
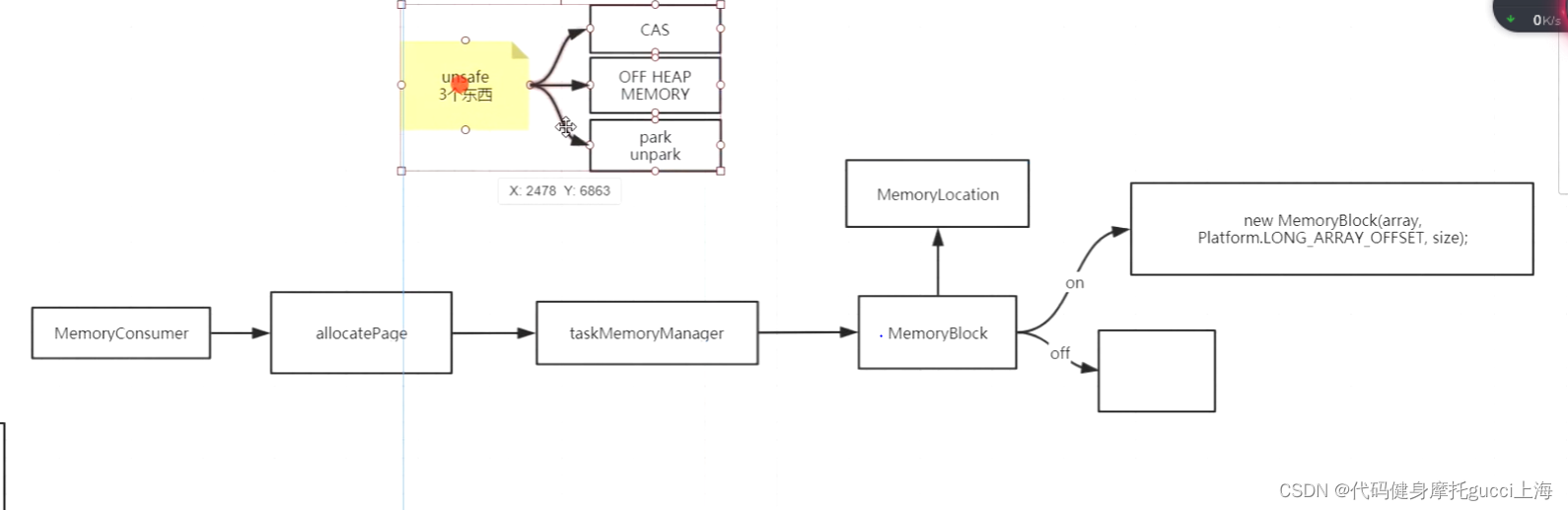
上图是在分配page时候的一系列方法,主要是分为使用jvm堆内空间分配或者是堆wai空间
之所以有unsafeSortShuffle,就是为了节省内存利用,顺而减少磁盘溢写次数,尽量减少 序列化反序列化这种过程,比如你从磁盘拿到数据它是一个序列化后的字节数组,你拿到内存去给他进行操作,有些操作它是不需要你反序列化成对象去操作的(比如filter),这个时候你如果直接给他走一个unsafe放到堆外,他就不用反序列化,又替内存节省空间(因为序列化比反序列化占用空间小),又能最快速度(堆外是内核读到地址就能走,另一种还要涉及jvm里面代码一些流程来换算地址)
它是为了追求内存最高利用率
unsafeShuffleWriter里也有写在堆上和堆外的,主要是多了一个堆上有对象头这种信息,每次放数据的时候,还有一个对象头的偏移量要算进去,详细看图片
========================================================================
shuffle读

要读肯定要先去拉取数据,这个时候就分为远端数据和本地数据来拉取,本地的不用说,主要是远端的,他会先定义一个targetRequestSize来指定一次拉取多少,一般他会指定1/48M。上图就是他在拉取远端数据,在一个address中(一台机器上)会有多个块需要拉,但是由于它限制了这个1/48M,就是他不会一口气把一台机器的全部块都拉取过来,而是每台机器都拉个1/48M,这样就不会造成单台机器阻塞。类似于计算机cpu轮询
shuffle的使用场景:
1. 下游分区数量改变 这种情况对应于你上游task很多,但是每个里面的数据很小,开那么多task就很没必要,毕竟浪费进程线程生成和消亡等,可以在shuffle的时候让他们分区数变少来改善
2. 需要聚合 就比如reduce groupByKey
3. 需要全排序,这个时候肯定是shuffle拉取所有主机数据
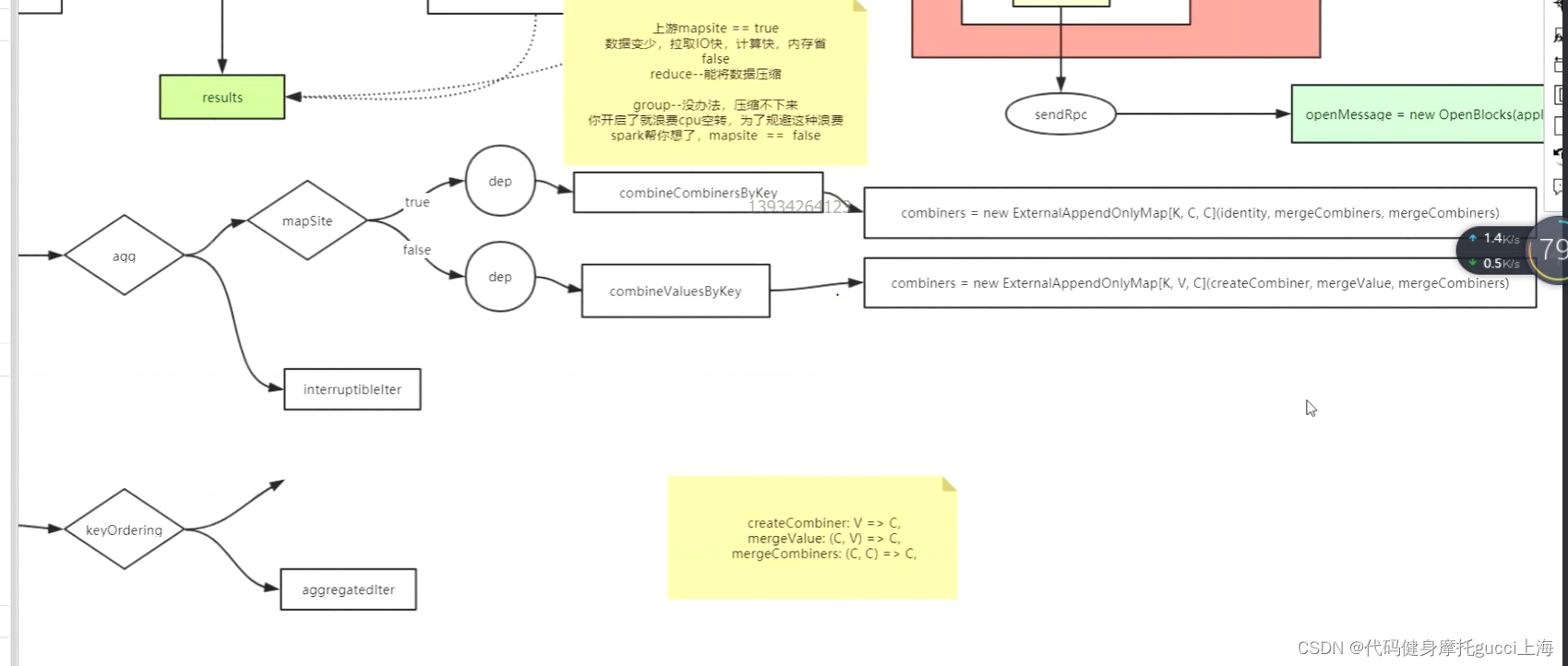
在拉取完全部数据后就是开始读取,但是他会根据几个条件走不同分支,首先是根据map的时候是否发生aggregator 我这边读也给他聚合,比如map端已经聚合过了,后面就不用聚合,map端如果没有聚合,后面就要聚合。有这种设置是因为比如reduceByKey和groupByKey。(聚合就是combineByKey那三条算子,第一条怎么搞,后续的怎么搞,最终怎么溢写)
reduceByKey是map端发生聚合,shuffle读的时候就不用聚合了,因为你一条一条数据在map端直接聚合的话,可以让数据量变少,IO也就快,计算和内存占用量也会少。这种map直接聚合 shuffle拉取过来不用聚合就会很方便
groupByKey如果也是map端聚合的话,他就显得很没必要,首先 就算你map的时候也开启聚合了,让相同key的放在一起,这个时候你shuffle读的话,IO传输和内存占用一点没少,因为还是一条一条被传过来,数据量没变,白白浪费map端的cpu空转时间。这种情况还不如直接在map端直接传过来,我shuffle读的时候去进行聚合。
=========================================================================
RDD持久化
调优:
rdd执行过程中,如果有重复调用的地方可以用rdd.cache()或rdd.persist(级别)来暂时存储到内存或磁盘。
但是 上述情况只能在task中间去执行调优,如果是shuffle read之后的rdd,就不用去暂时保存,spark内部会自动帮你跳过shuffle之前的东西,自动调优
另一个调优是为了系统的可靠性,比如你用persist存储在本地磁盘,但是如果这台机器挂了,那么来之不易的查询结果也就丢了,可以用setCheckPointDir() 和 checkpoint()来存储到hdfs系统中,让他更加可靠

=========================================
广播变量 broadcast

比如上述的list 这个东西是我们driver端编写好逻辑 推送给executor执行,结果再拿给driver
下面的闭包是发生在driver的,每次执行再发送给executor,之间的来回发送就浪费效率
可以使用广播包(像那种闭包必须序列化才能发,也就是你写代码定义的东西是在driver端生成的,最终的执行还是在executor,executor想要用你的东西,必须让driver序列化一下,然后发送给executor那里反序列化,那边用完就直接销毁了,driver用的东西和executor根本不是一个东西)
广播变量就是driver 发出去之后存在executor的blockManager
上述是下面方法的一种调优
场景 : 一个数据量大 一个数据量小 用来做关联 不想用shuffle(IO是最大的瓶颈)
low方法: 就是list是一个rdd 我的data也是一个rdd,两个rdd去做一个join操作,但是中间会涉及到shuffle,这样就会导致效率低下,我们的广播变量可以让数据量小的直接发送到数据量多的那个主机,然后直接本地进行操作更方便 没有shuffle
广播变量的方式一可以减少IO,二他不同于于taskbinary,taskbinary虽然也是发送到blockManager,但是他只能作用于单个任务,换了别的任务还是需要driver重新发送相同的数据,而使用broadcast的话,只发送一次给所以executor,不管是谁的任务都可以直接使用变量
所以如果只是单个job,直接taskbinary就行,多个job就把他变广播变量
![[附源码]JAVA毕业设计教学辅助系统(系统+LW)](https://img-blog.csdnimg.cn/6cf8c2ea58e144f092580a9a3209e14a.png)
![[附源码]计算机毕业设计springboo酒店客房管理系统](https://img-blog.csdnimg.cn/bef4bdd7237243499b89ce7c0ec23782.png)

![[附源码]计算机毕业设计疫情期间小学生作业线上管理系统Springboot程序](https://img-blog.csdnimg.cn/9c1d21fccde84676b435e0bed5e2e0b1.png)