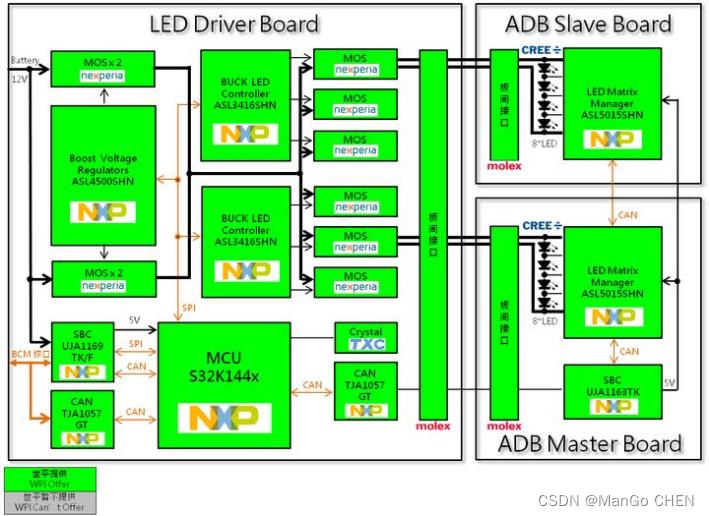
HTTP应用层协议
文章目录
- JavaEE & HTTP应用层协议
- 1. HTTP的报文协议格式
- 1.1 fiddler介绍
- 1.2 HTTP请求
- 1.3 HTTP响应
- 2. HTTP请求与响应
- 2.1 首行
- 2.1.1 http方法
- 2.1.2 URL
- 2.1.3 版本号
- 2.2 header与空行
- 2.2.1 Host
- 2.2.2 Content-Type 与 Content-Length
- 2.2.3 User-Agent(简称UA)
- 2.2.4 Referer
- 2.2.5 Cookie

JavaEE & HTTP应用层协议
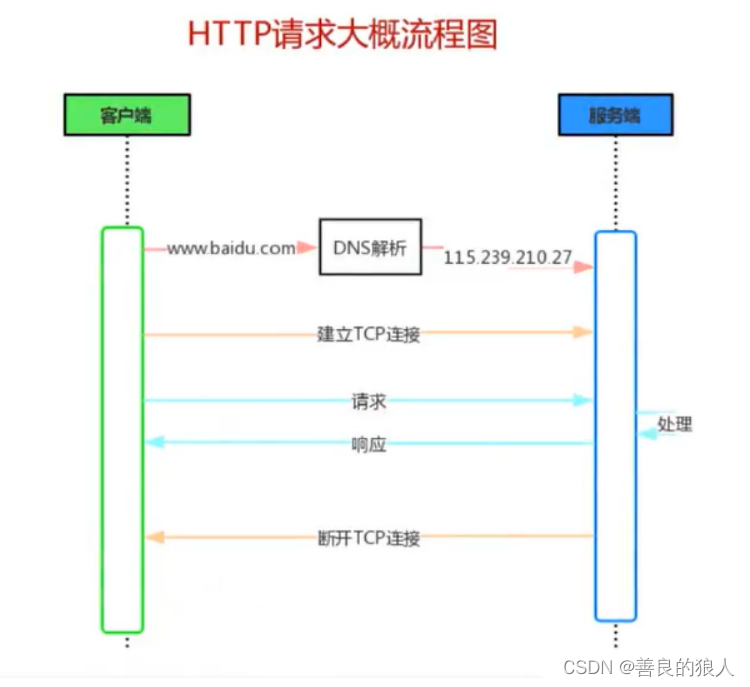
超文本传输协议(Hyper Text [Transfer Protocol](https://baike.baidu.com/item/Transfer Protocol/612755?fromModule=lemma_inlink),HTTP)是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。请求和响应消息的头以ASCII形式给出;而 [9] 消息内容则具有一个类似MIME的格式。
- 本质就是想TCP socket上写东西和拿东西罢了
这个简单模型是早期Web成功的有功之臣,因为它使开发和部署非常地直截了当。
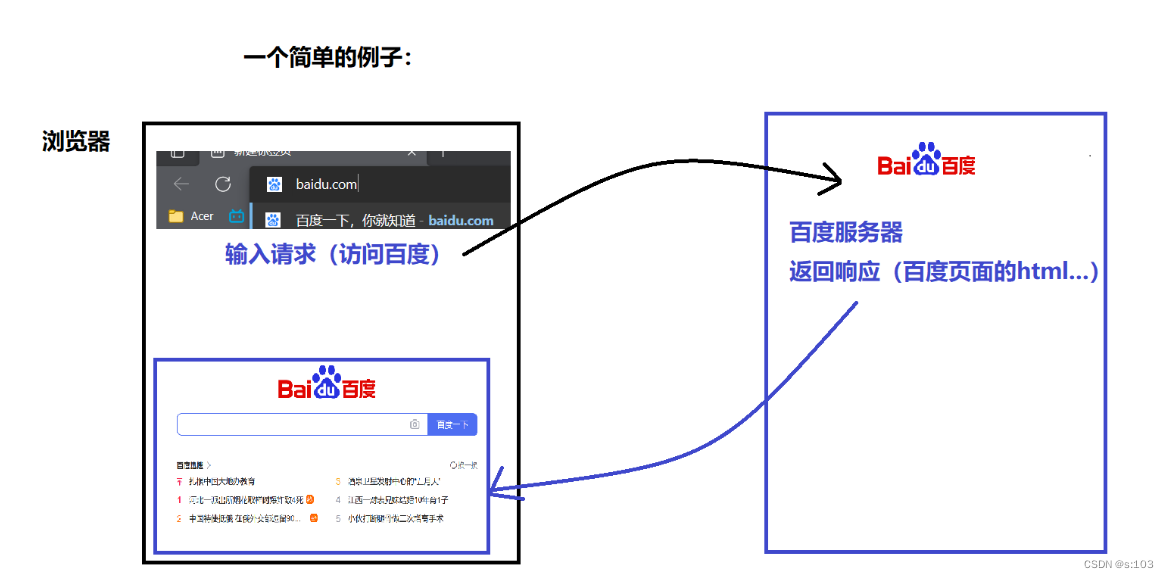
- 这里,浏览器就相当于客户端,百度服务器就是服务器
- 我们看到的网页html,一般是由对应的服务器通过http(css,js…)响应返回给浏览器上,才能显示的~
1. HTTP的报文协议格式
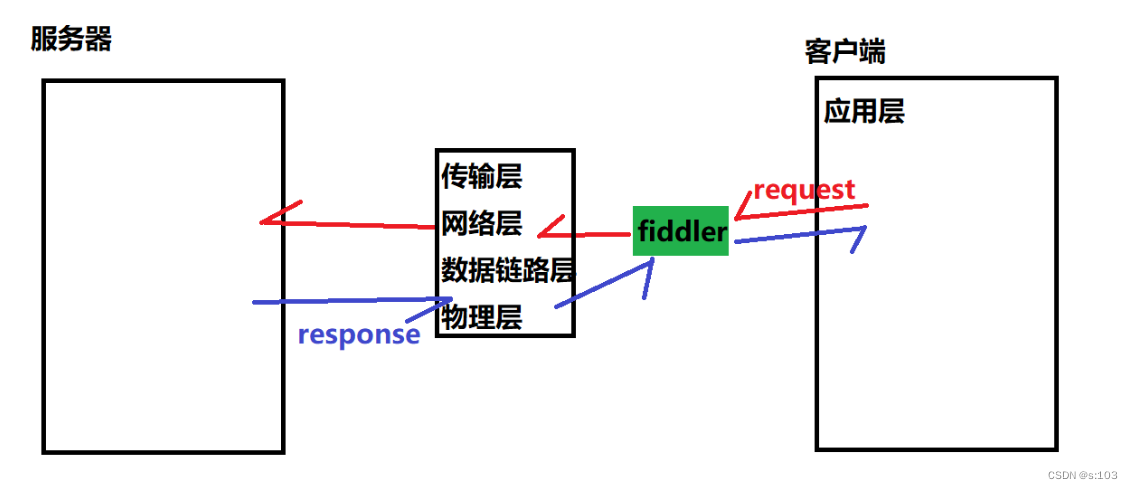
我们需要用到一些外部的工具,来把http协议显示出来,即抓包工具
- 抓包工具,本质上相当于一个“代理”,借助这个代理,就可以看到网络上传输的具体数据了~
- **启动这个抓包工具之后,它就会代理我们的网络请求,也就是说,我们的网络请求或者收到的网络响应,都必须经过它的手,才能发出去或者拿到手。**这样,这个“代理”,就能清楚网络上传输的数据了,即获取http数据报
当然,浏览器也能抓包,但是我更推荐fiddler
下载传送门:Download Fiddler Web Debugging Tool for Free by Telerik
- 我用的是免费版的
- 首次使用,需要开启https,因为现在网络上主要的协议是https,很少直接用http
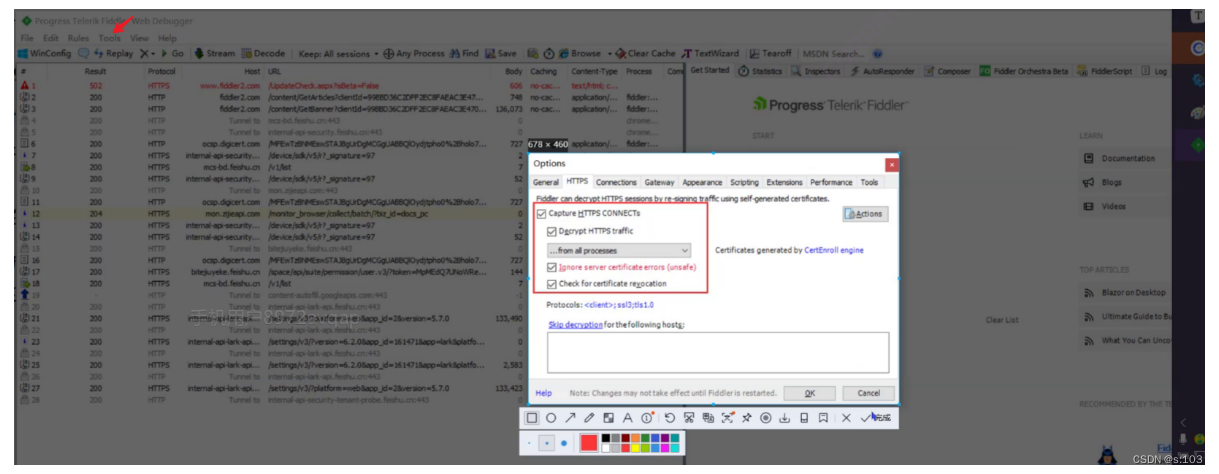
- 是否按照根证书:选择是!
1.1 fiddler介绍
左侧:抓到的包的内容,由于我们无时无刻都才发送请求和响应,这个列表是一直在滚动的
找到想要的包:
- 黑色包响应普通数据
- 蓝色包响应的是html
- 看域名
- 再看响应的数据长度,一般找长度长的
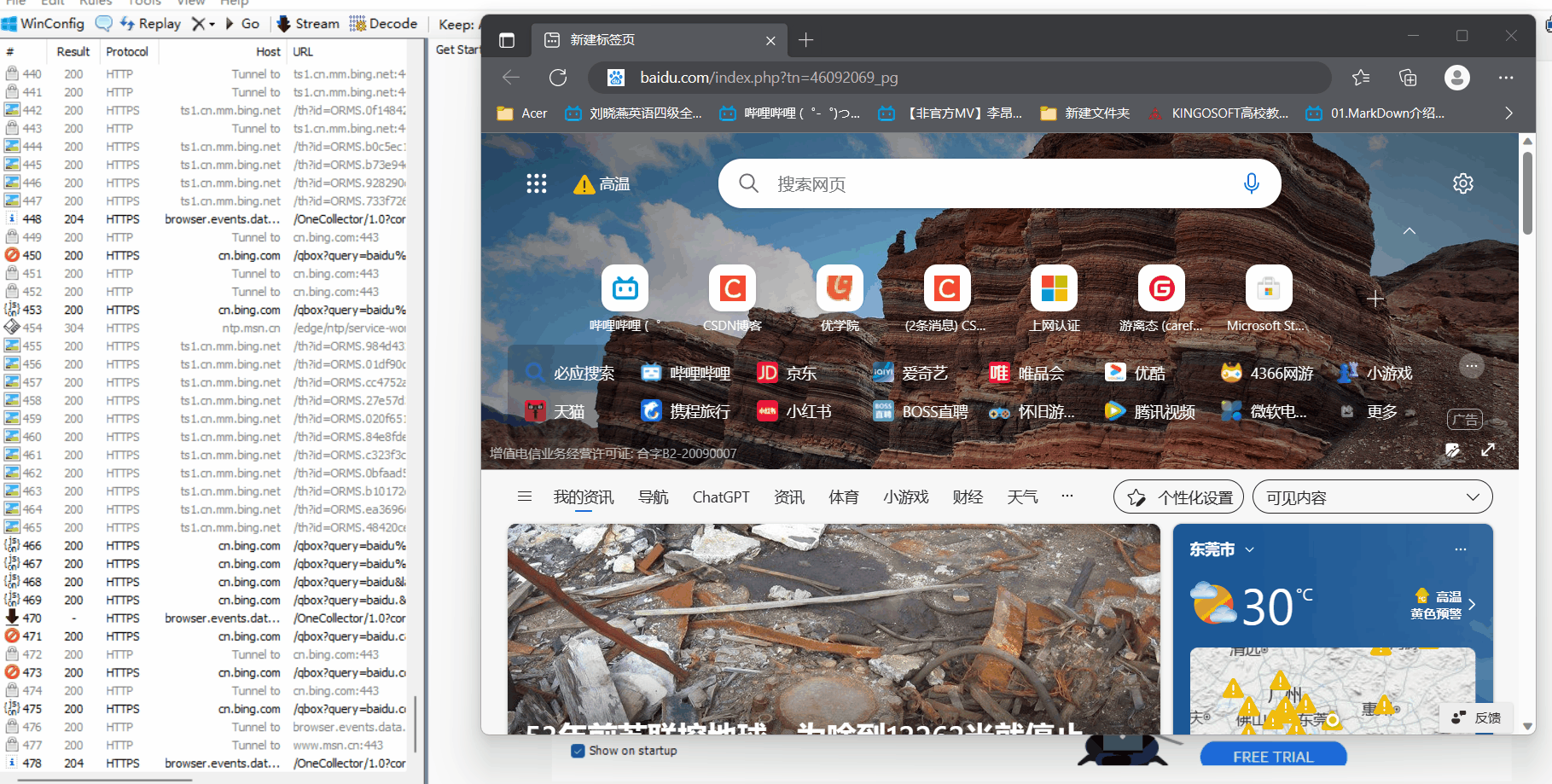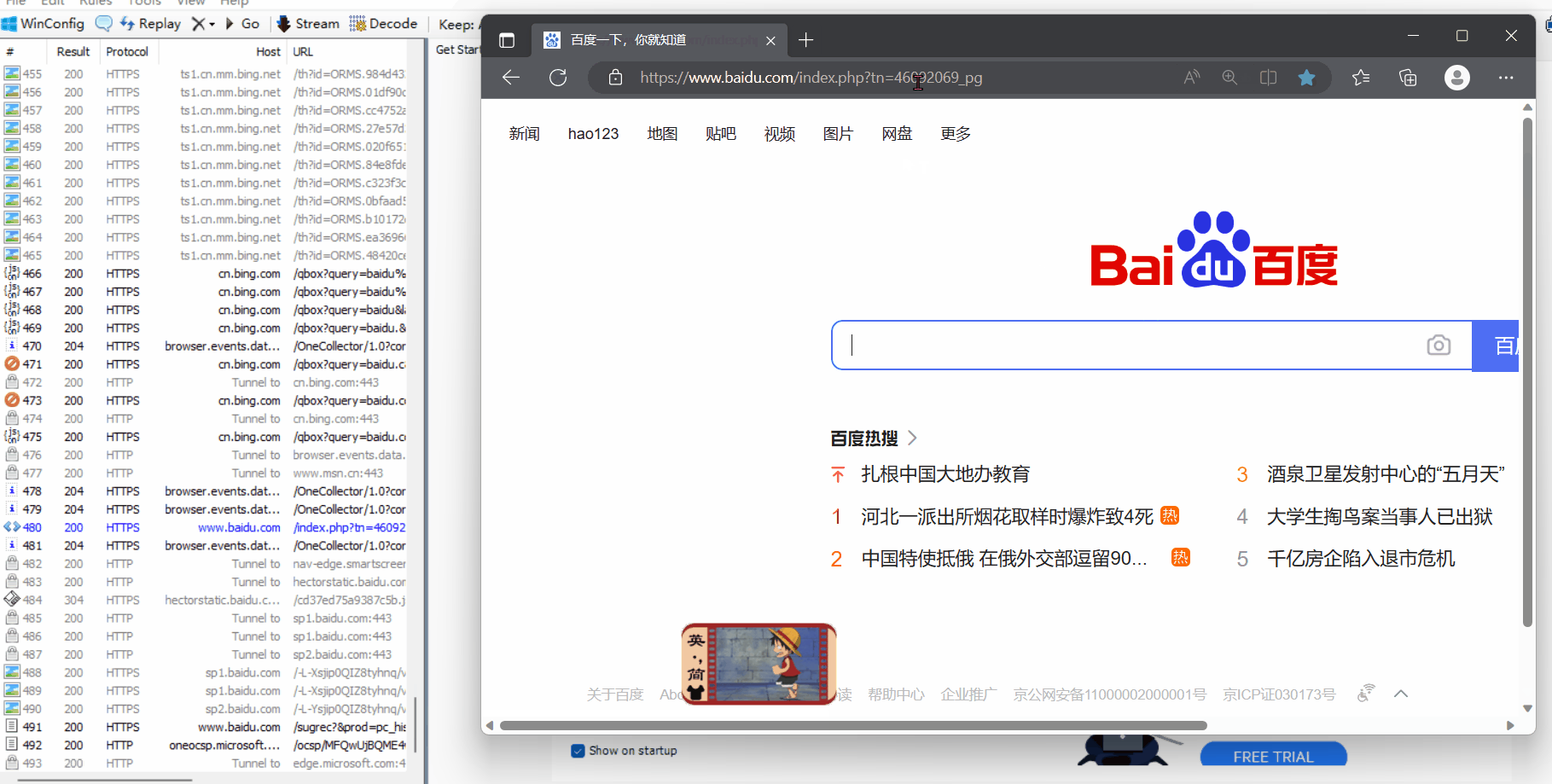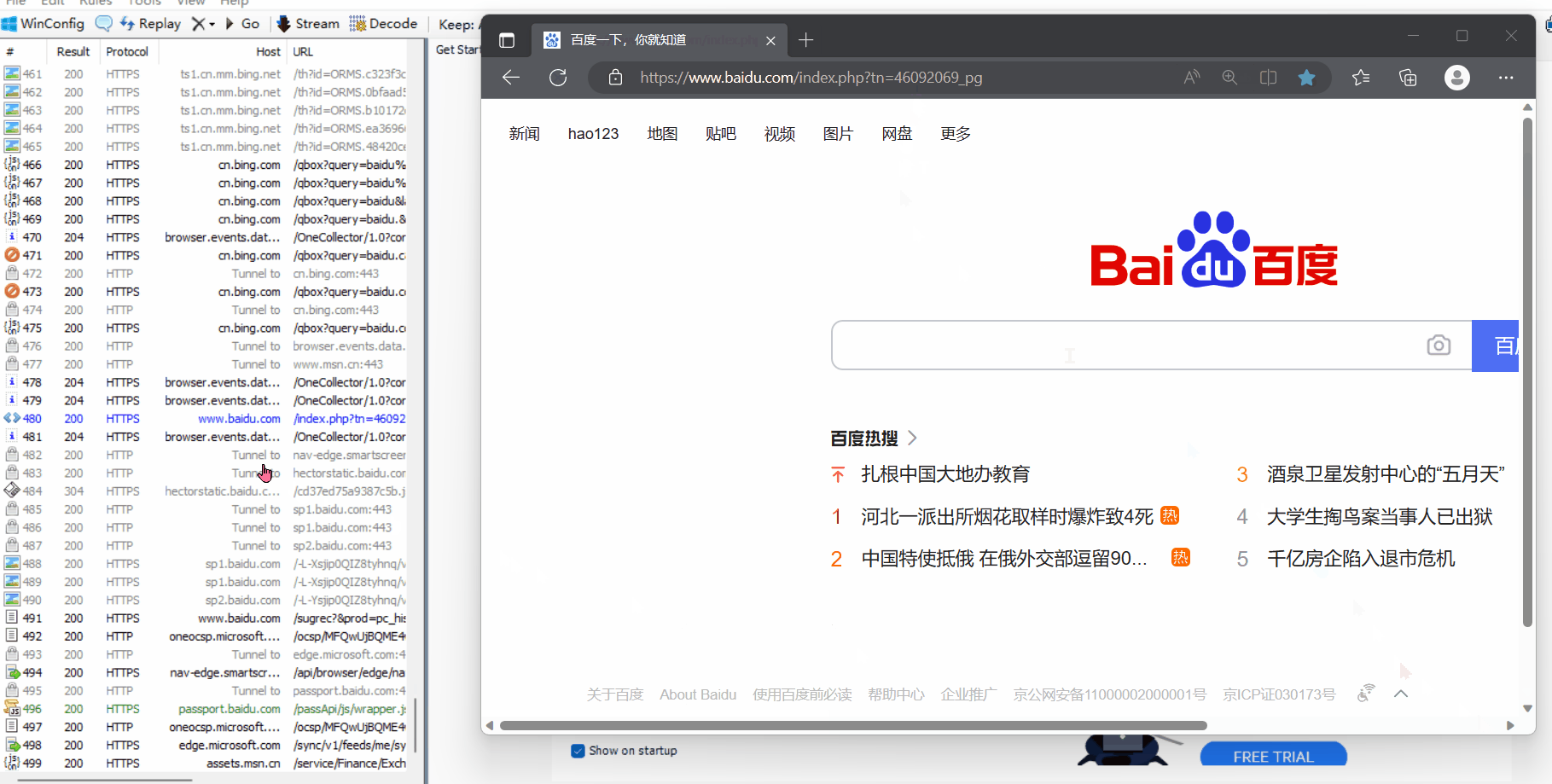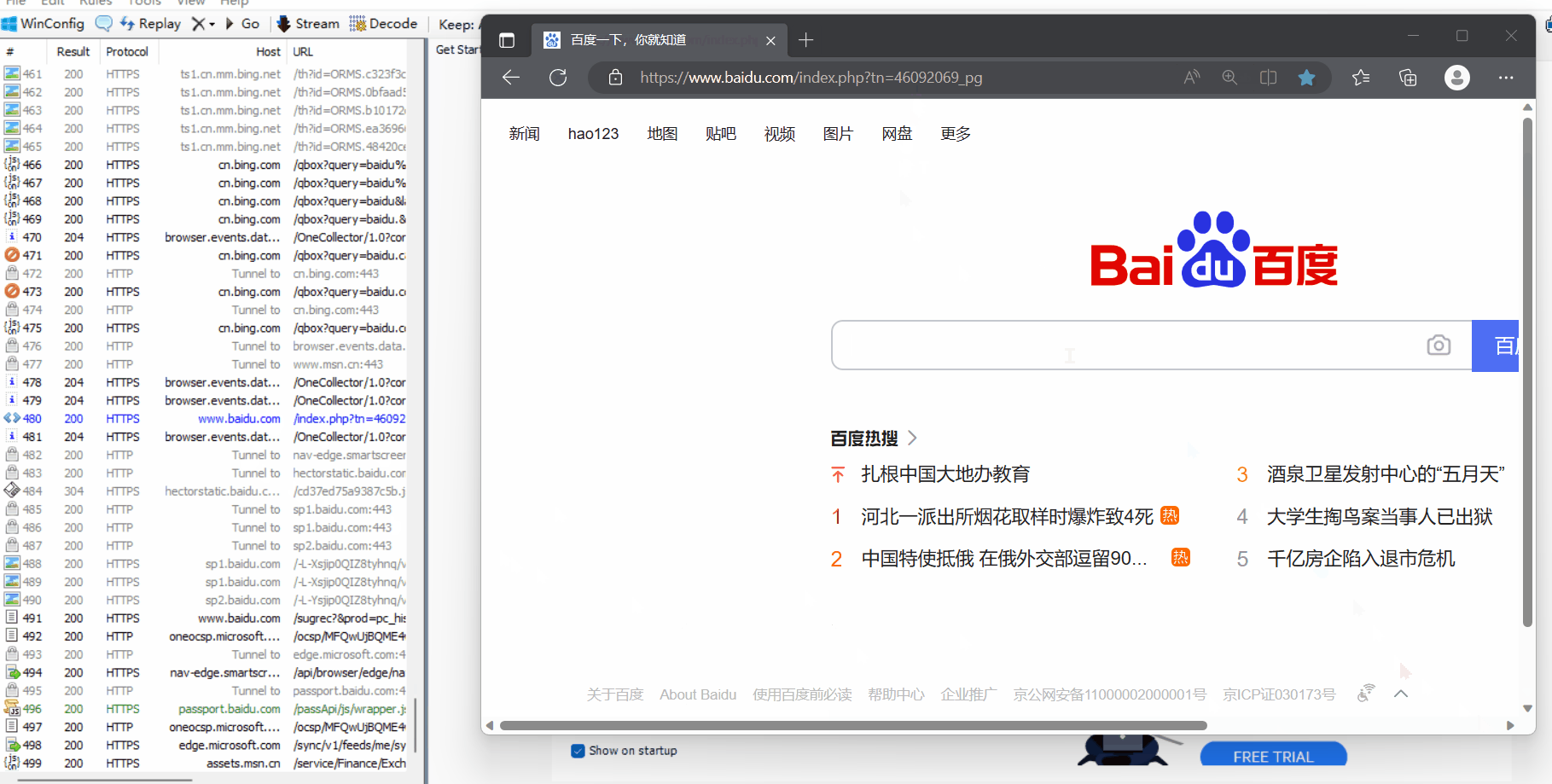
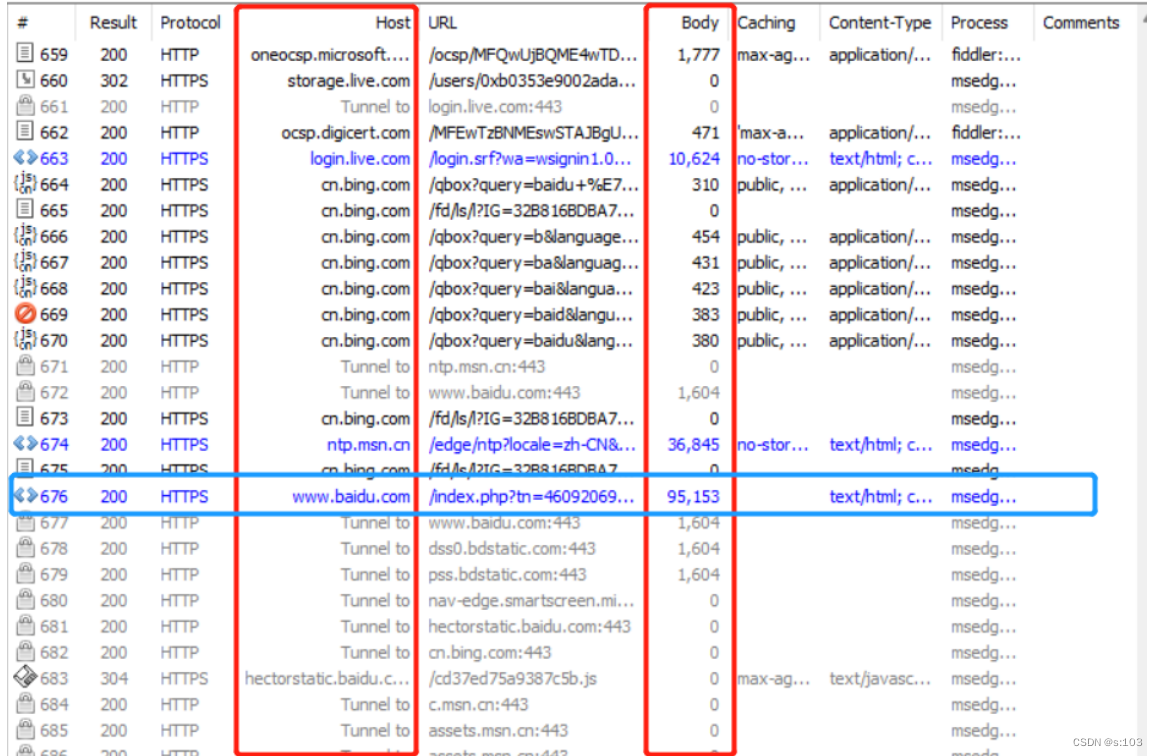
- 但是,经常抓包,就很容易看到,不用考虑这么多
右侧:就是我们的请求和响应了
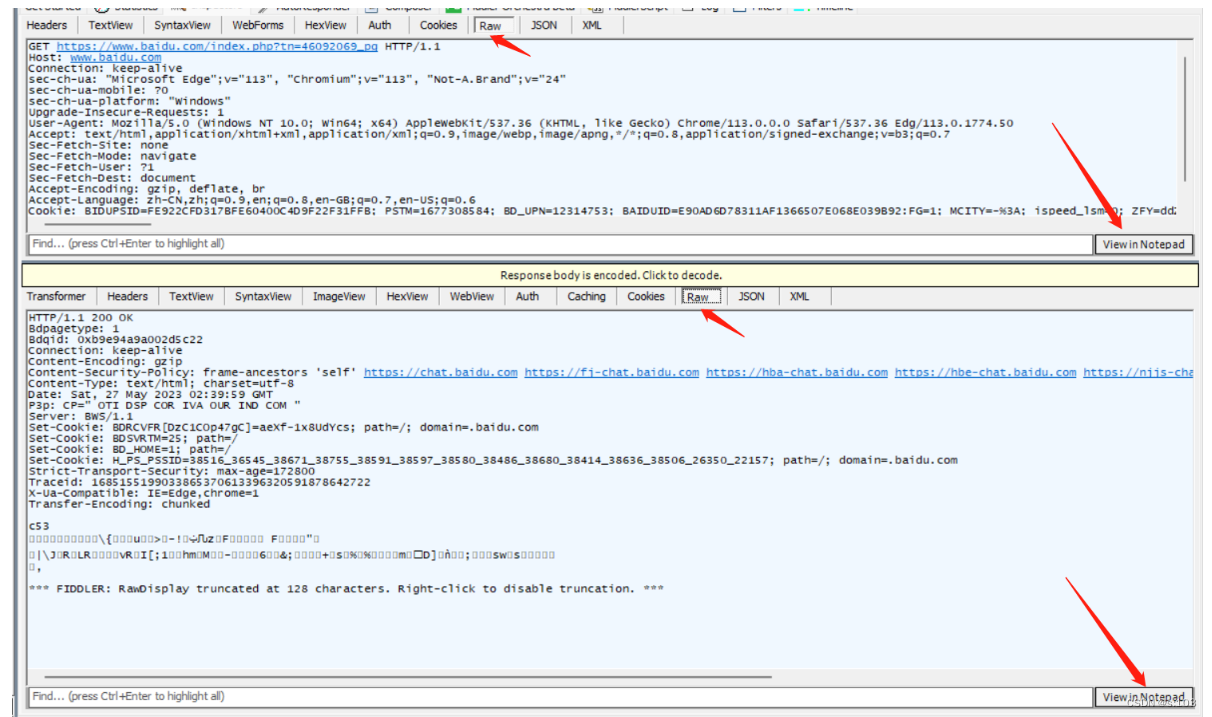
- raw有让数据报皮开肉绽,展露http数据报原始的样子
- view in notepad,在记事本中打开~
HTTP请求:
HTTP响应:
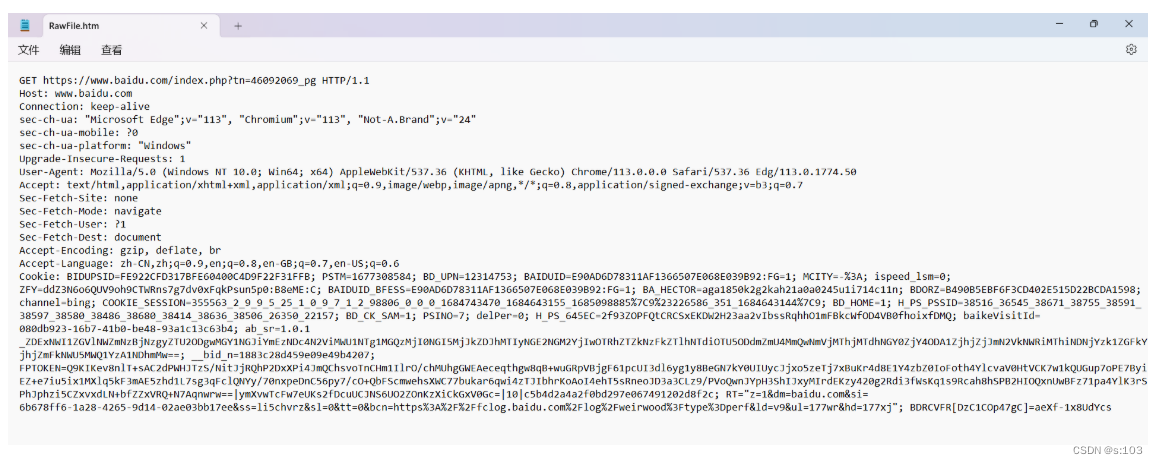

1.2 HTTP请求
说到底,我们发送的HTTP请求,就是通过代码,构造出一个符合HTTP格式要求的字符串,往TCP的socket中一写就行了~
- 看的出来,这是文本格式,而不是二进制格式
而一个http请求数据包,包含四个部分:
- 首行
- header
- 空行
- header的结束标记
- 正文,body
- 空行后面的内容,有时可以没有
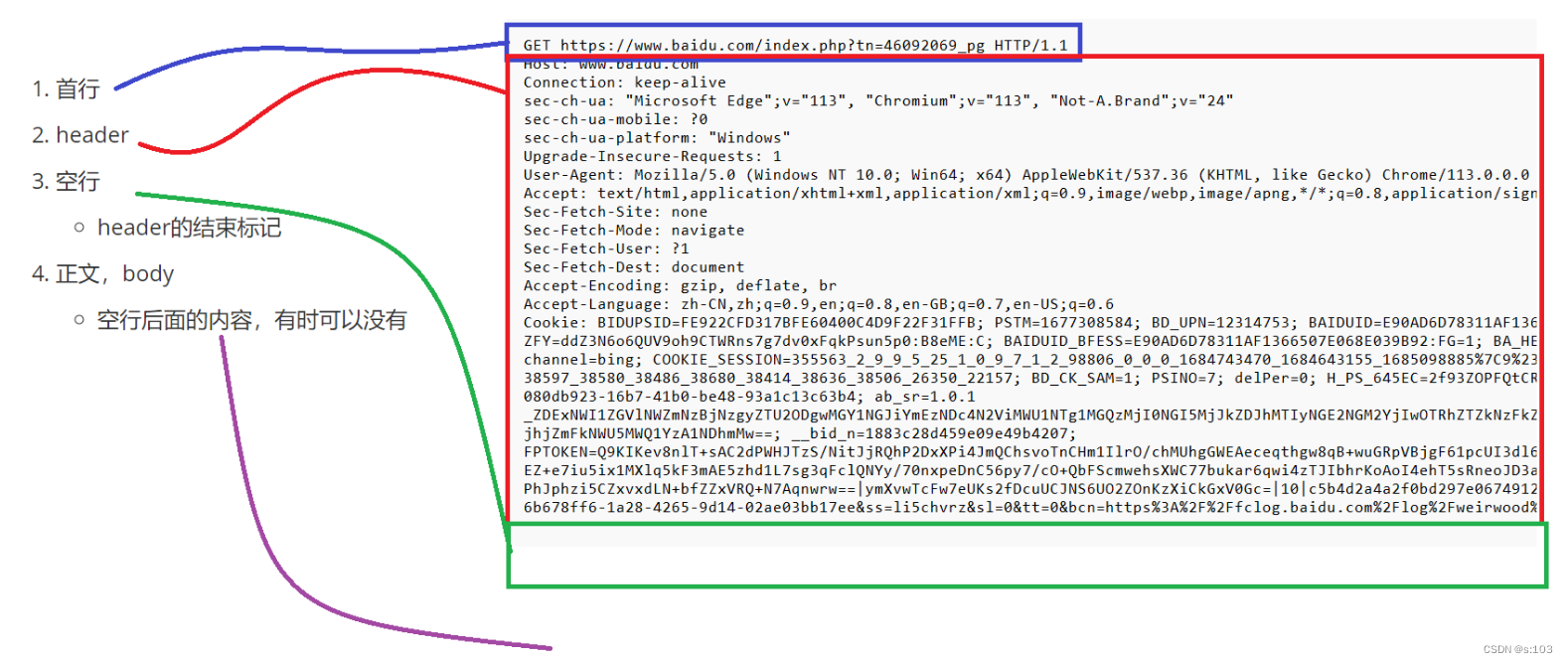
1.3 HTTP响应
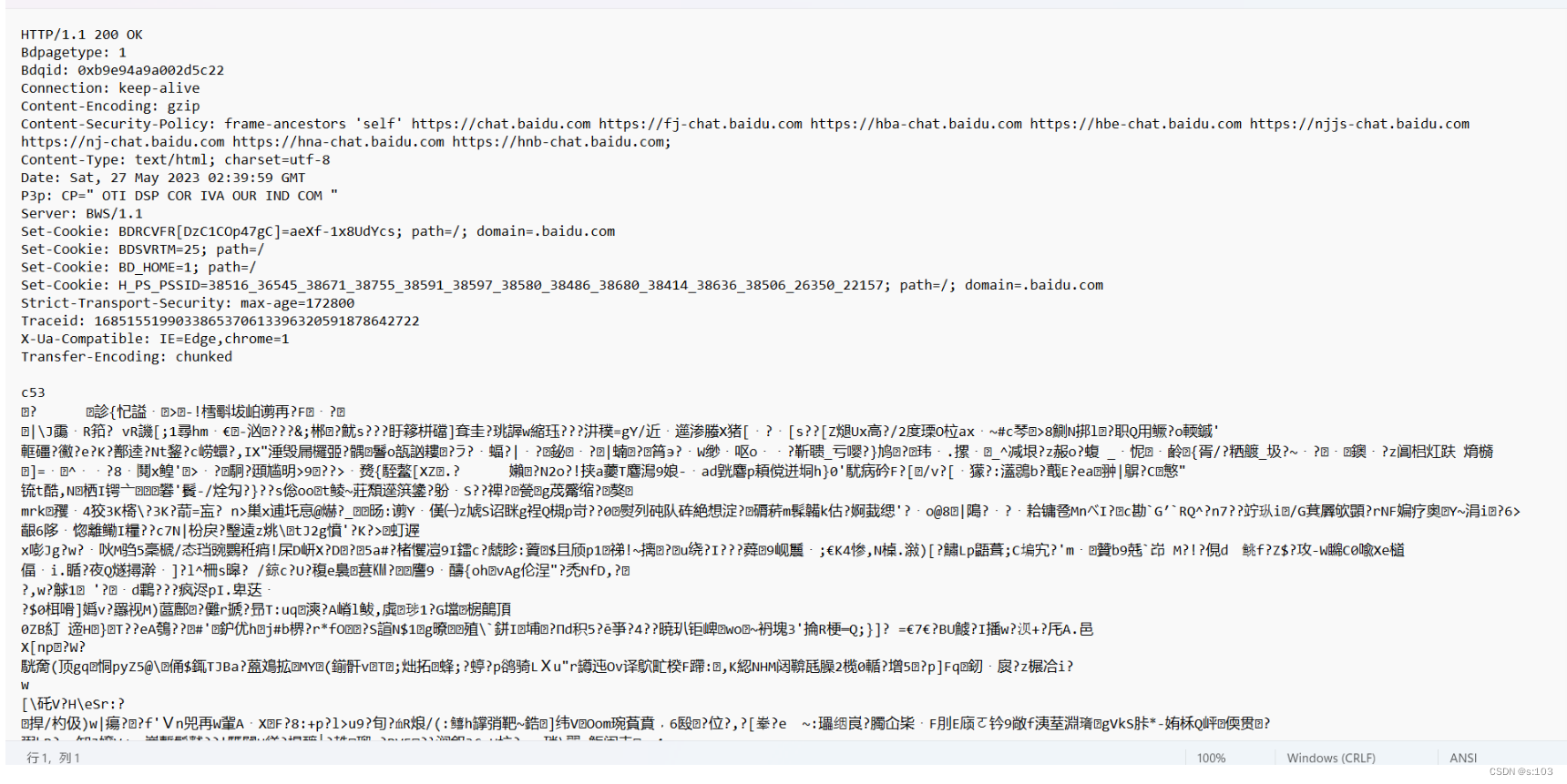
- http本身是文本格式的,为啥下面有乱码,这是因为要节约成本(节省带宽),压缩了文本,所以成了二进制~
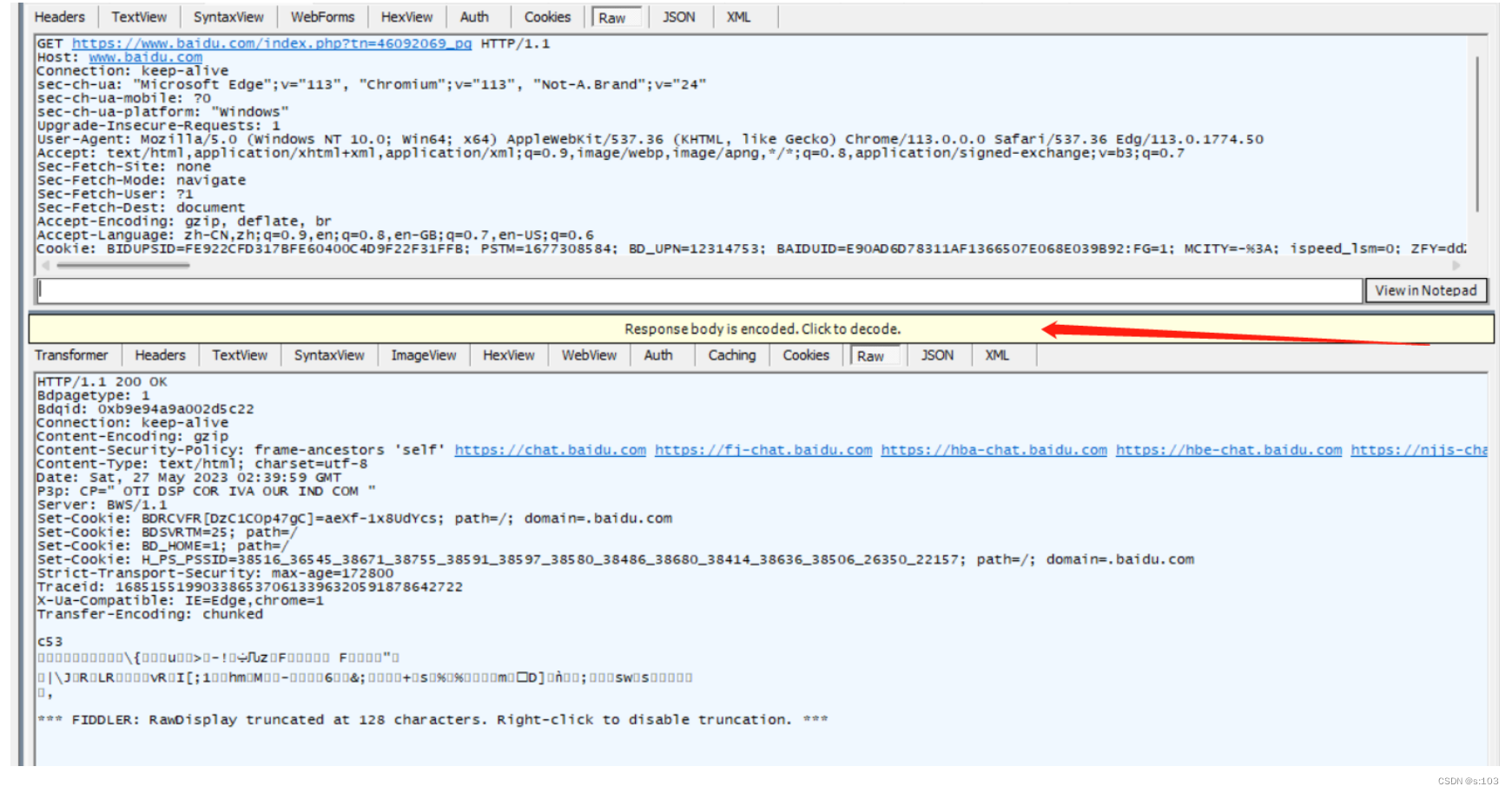
- 这里就有提醒,正文被压缩了,点了可以解压缩~
- 是不是很眼熟,没错,返回的正文就是html代码~
- 浏览器访问的页面内容,就是返回的响应中的html
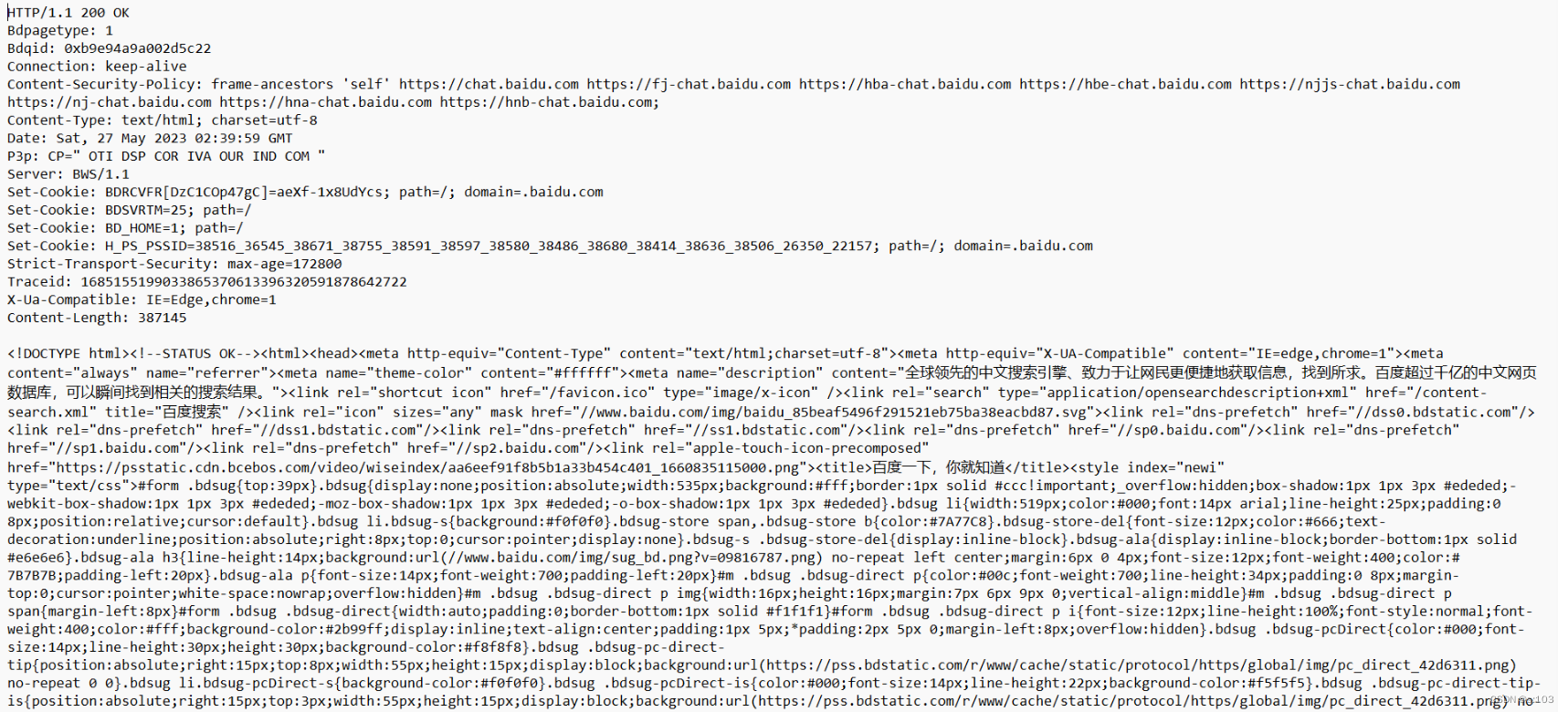
也包含四个部分:
- 首行
- 响应报头(header)
- 空行
- 正文body
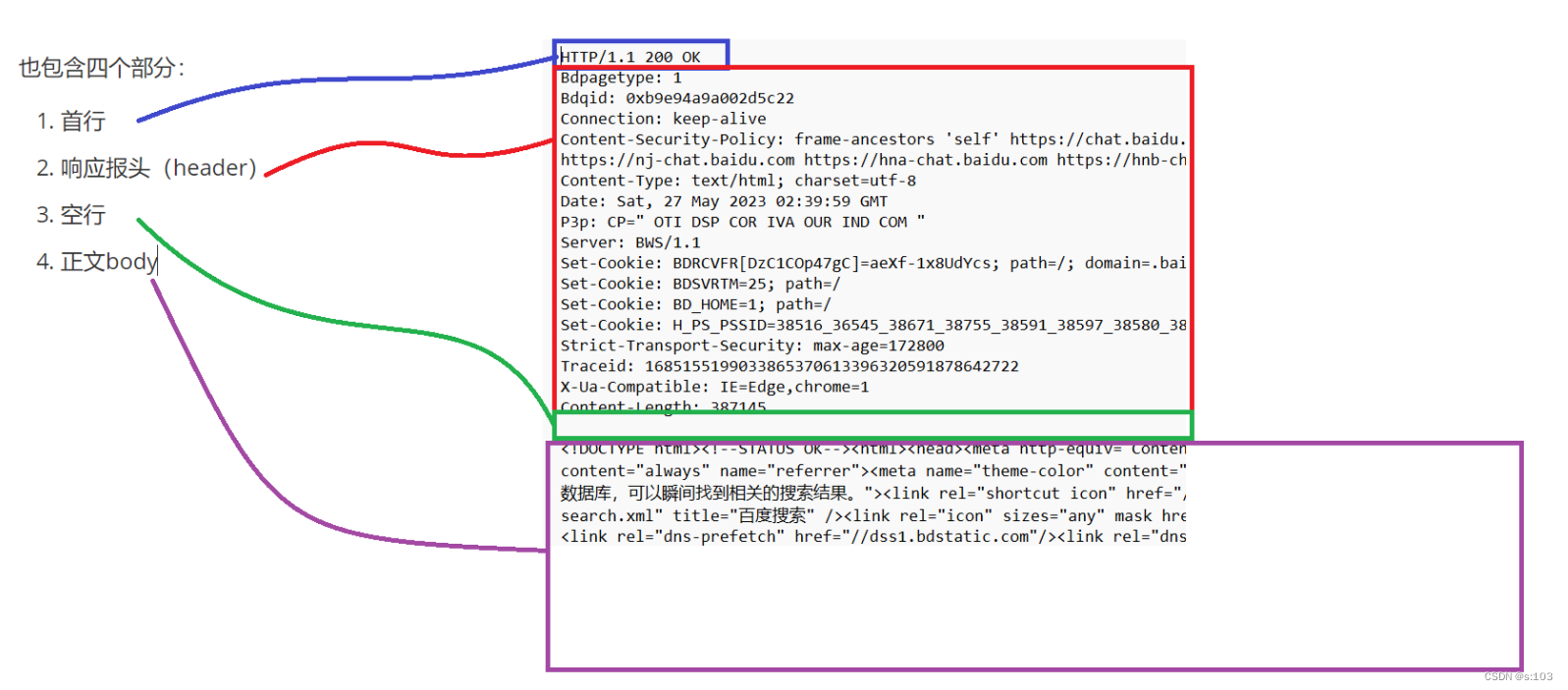
这就是HTTP请求和响应数据包的大概内容,接下来是细节的讲解
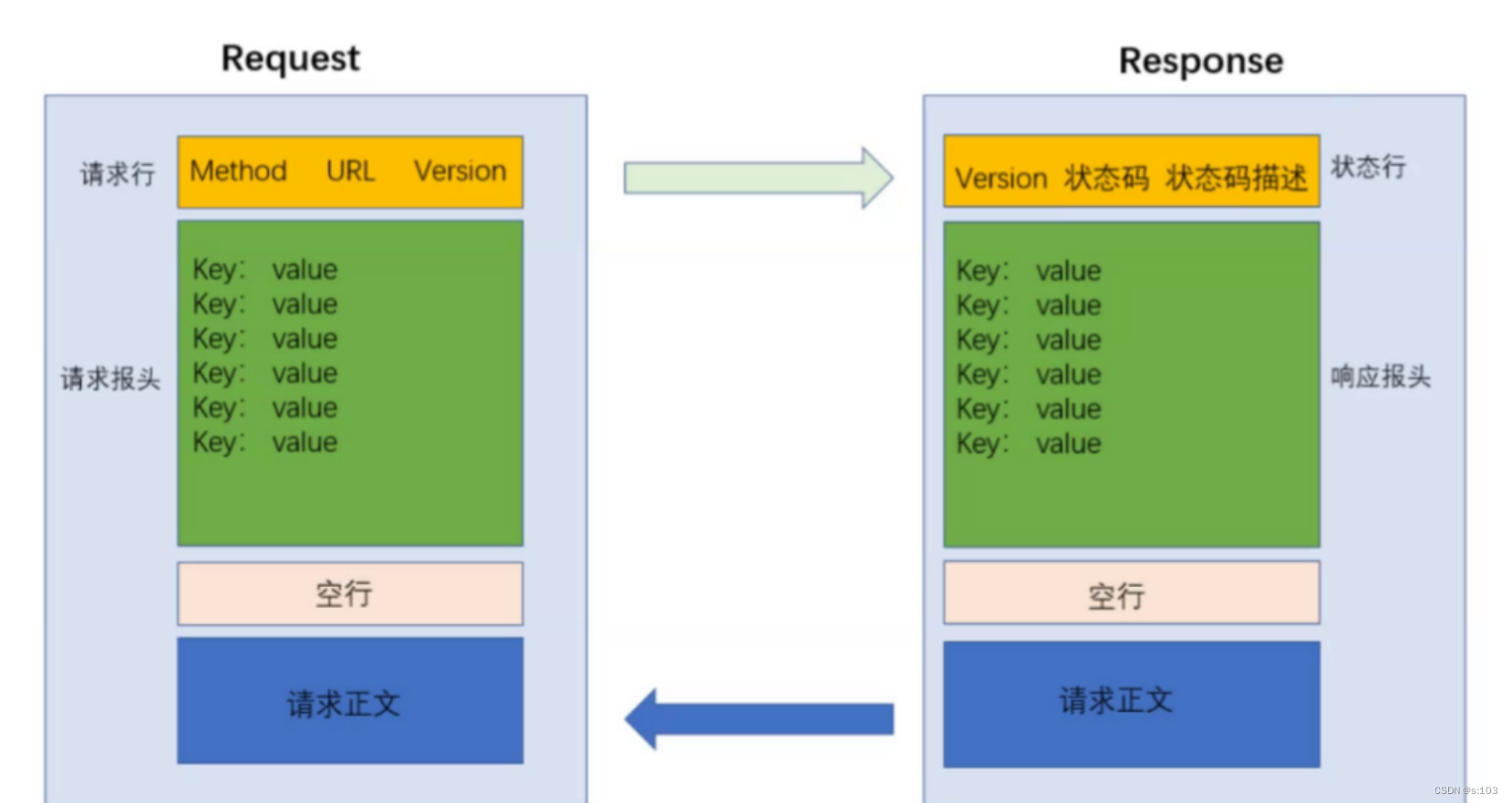
2. HTTP请求与响应
2.1 首行
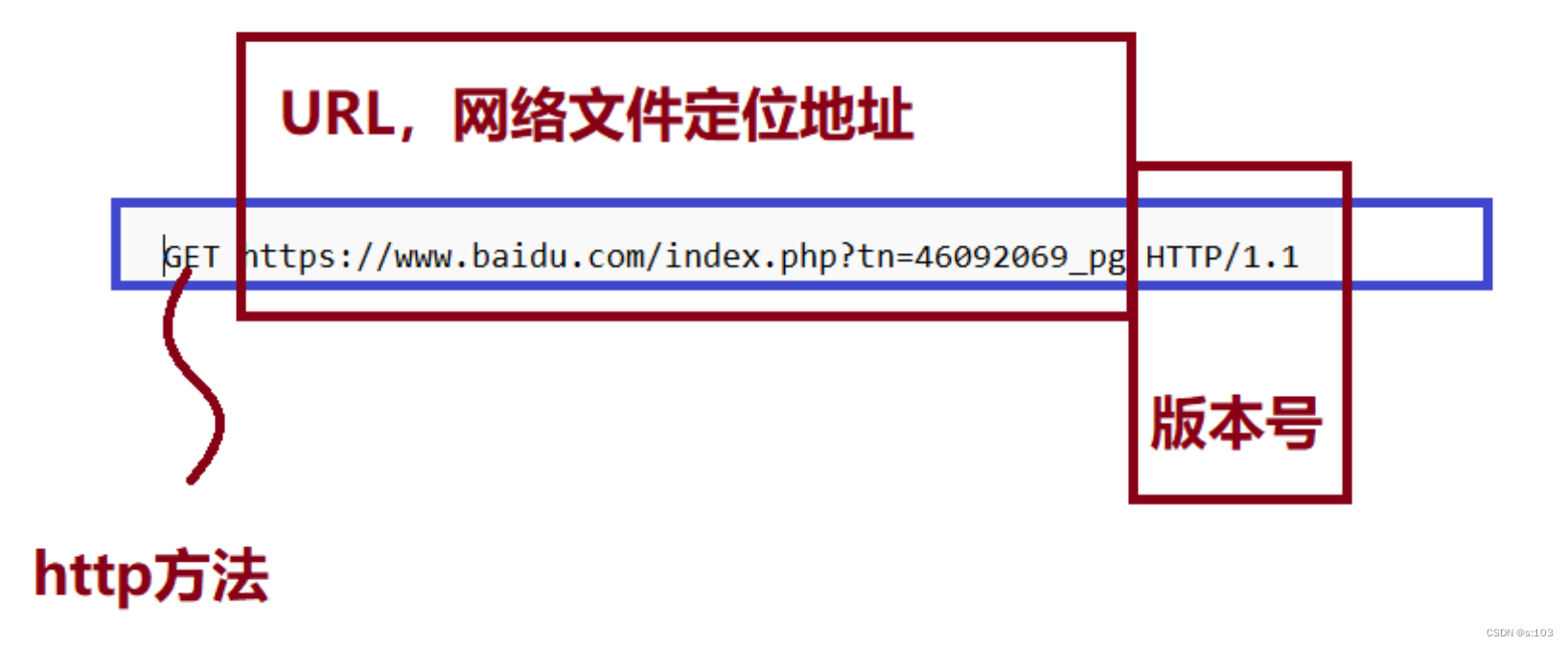
2.1.1 http方法

一般post请求也挺少的,一般是在
- 登录的时候
- 上传文件的时候
我随便抓一个登录时的http包作为例子:
- ctrl X 可以情况左侧列表
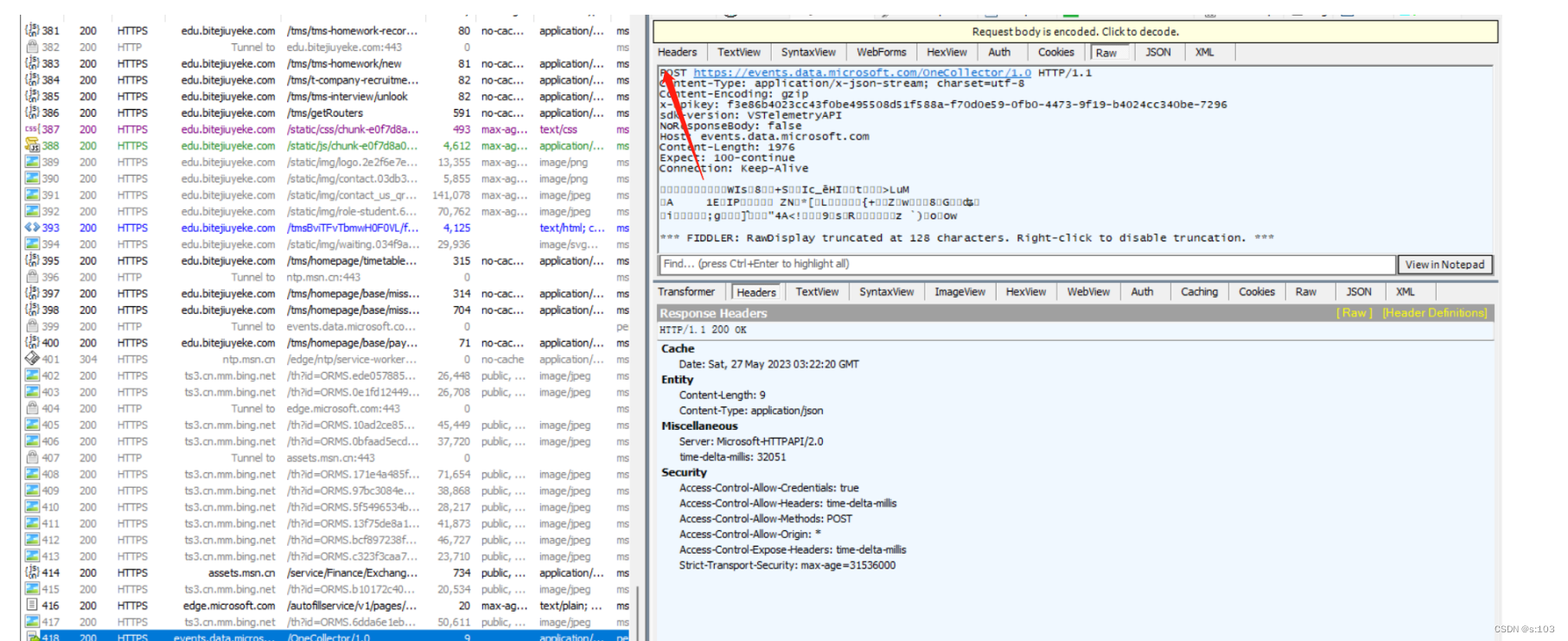
- 可以发现,post请求一般是有正文的
POST请求body一般不为空,GET请求body一般为空
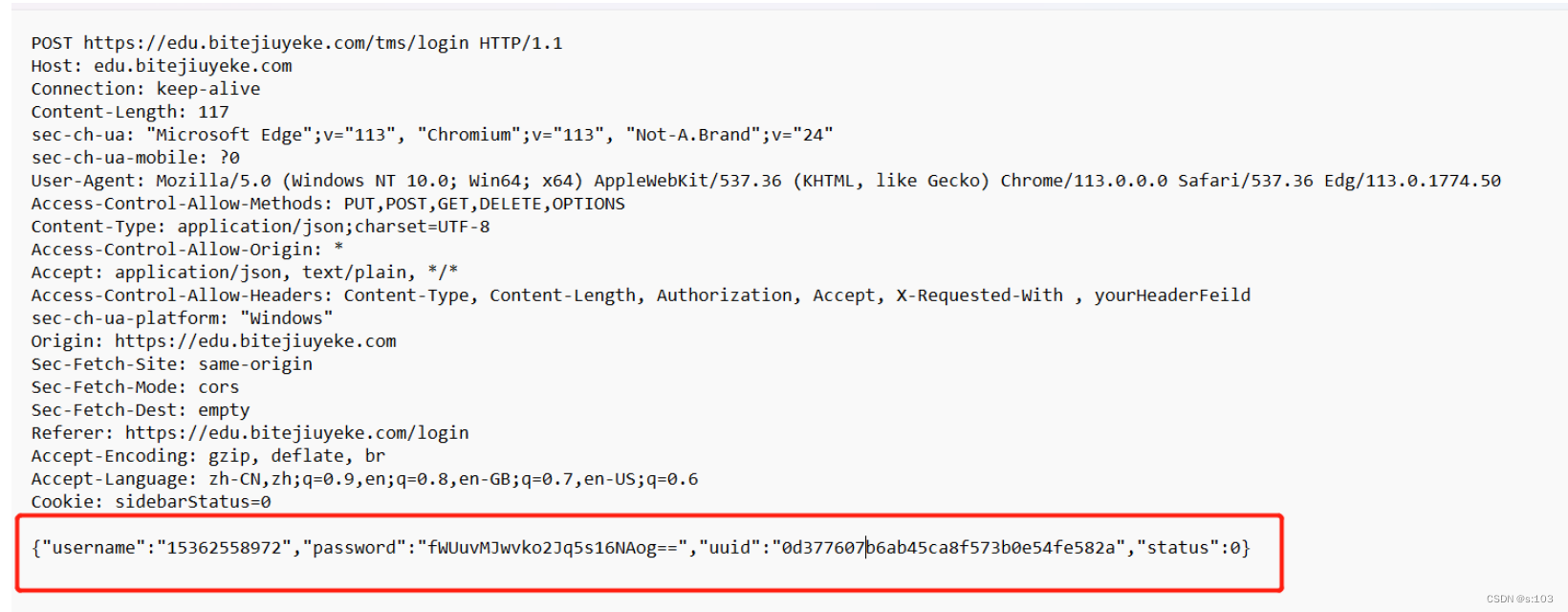
- 请求的正文里的数据,就是登录所必须的材料,当然,一般是加密的,当然也有些网站不加密,所以你要多备几个密码,不然一抓包就获得你的密码,一锅端了~
实际上,不需要严格遵守
- http方法的语义,只是一种建议,程序员并不一定要遵守
- get可以有正文,post也可以没有正文,看程序员咋写咯,只不过这个情况少见
如果说GET和POST有啥区别?
答:没有本质区别,GET对应的场景,POST一般也可以,POST对应的场景,GET一般也可以~
- 是习惯和初心上的区别~
- GET习惯上去获取,POST习惯上去提交
- GET一般没body,需要携带数据则放到URL中(随后说),而POST一般有body
- GET请求通常会设计成幂等的,POST则无要求~
幂等:
如果输入是一定的,得到的输出也是一定的
- 就是同样的请求不会因为时机不同而获得不同的响应,而是获取同样的响应
- 而数据满足这种稳定的幂等,才能被缓存~
- GET是可缓存的(前提是幂等的),POST则不能
缓存:
将已有的请求应该有的响应记录下来,下次就无需等待或者计算,可以直接获取或者返回响应,提高响应速度
- 浏览器也会有缓存的功能,所以有时候出现错误,也可能是因为缓存的原因,所以可以试试,ctrl+f5,强制刷新一下
- 而如果不是幂等的信息被缓存了,就很可能会出错~
- GET请求可以被浏览器收藏夹直接收藏,POST不能
RFC 2616: Hypertext Transfer Protocol – HTTP/1.1 (rfc-editor.org)
官方文档,可以去看看
- GET有长度限制,POST没有,扯淡!
- GET和POST是没有长度限制的
- POST比GET更安全,扯淡!
- 取决于你正文是否加密,没加密,都不安全
2.1.2 URL
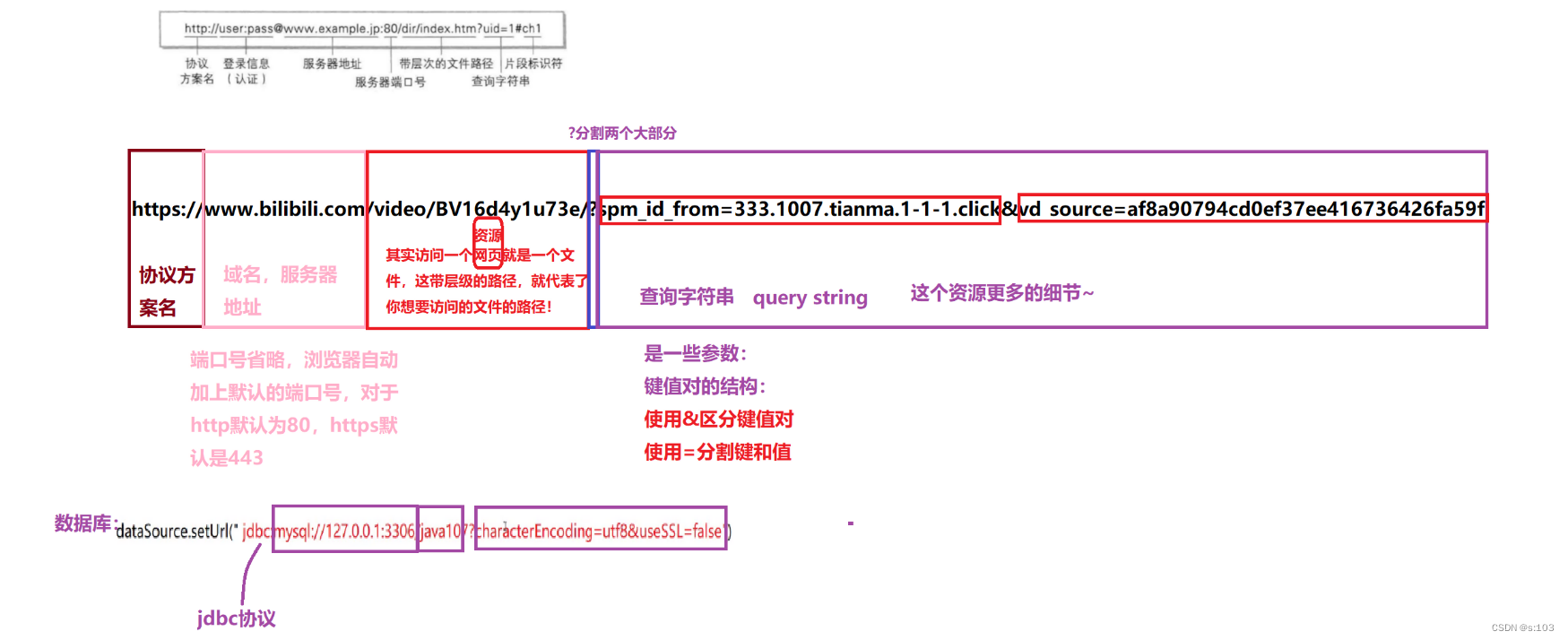
-
唯一资源定位符,描述了网络上唯一的一个资源
-
这个概念严格的说,并不是HTTP的概念,很多协议都会用到URL
-
例如,mysql的jdbc的时候当时就用过URL
- 不要背,但是要记住结构!
-
dataSource.setUrl("......");

-
URL的结构:
2.1.3 版本号
最常见的是HTTP/1.1
已经有很多版本了:
- HTTP/1.0
- HTTP/1.1
- 最主流的版本
- HTTP/2
- HTTP/3
2.2 header与空行

- 而这里有许多键值对,有很多行
- 会用空行作为结束标记~~
header中的键值对,大部分是HTTP协议规定的,当然也可以夹带私货,可以添加自定义的键值对
2.2.1 Host
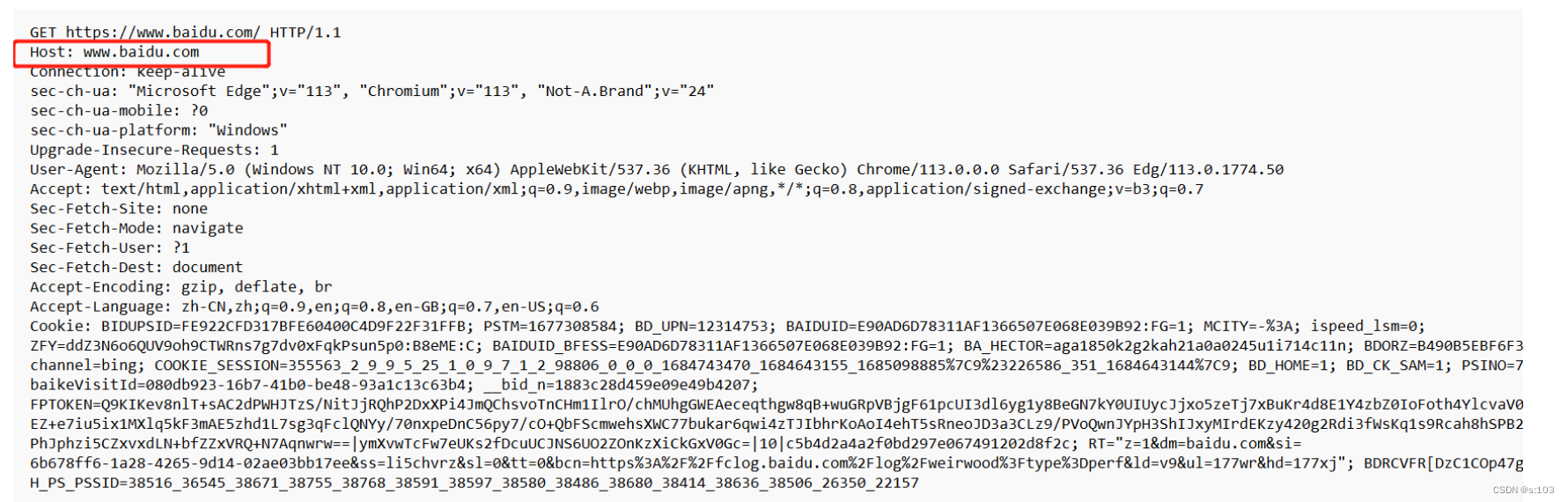
这个属性,描述了浏览器这个请求要访问的服务器,是谁~~
- 这里不仅仅可以写地址,也可以写端口号
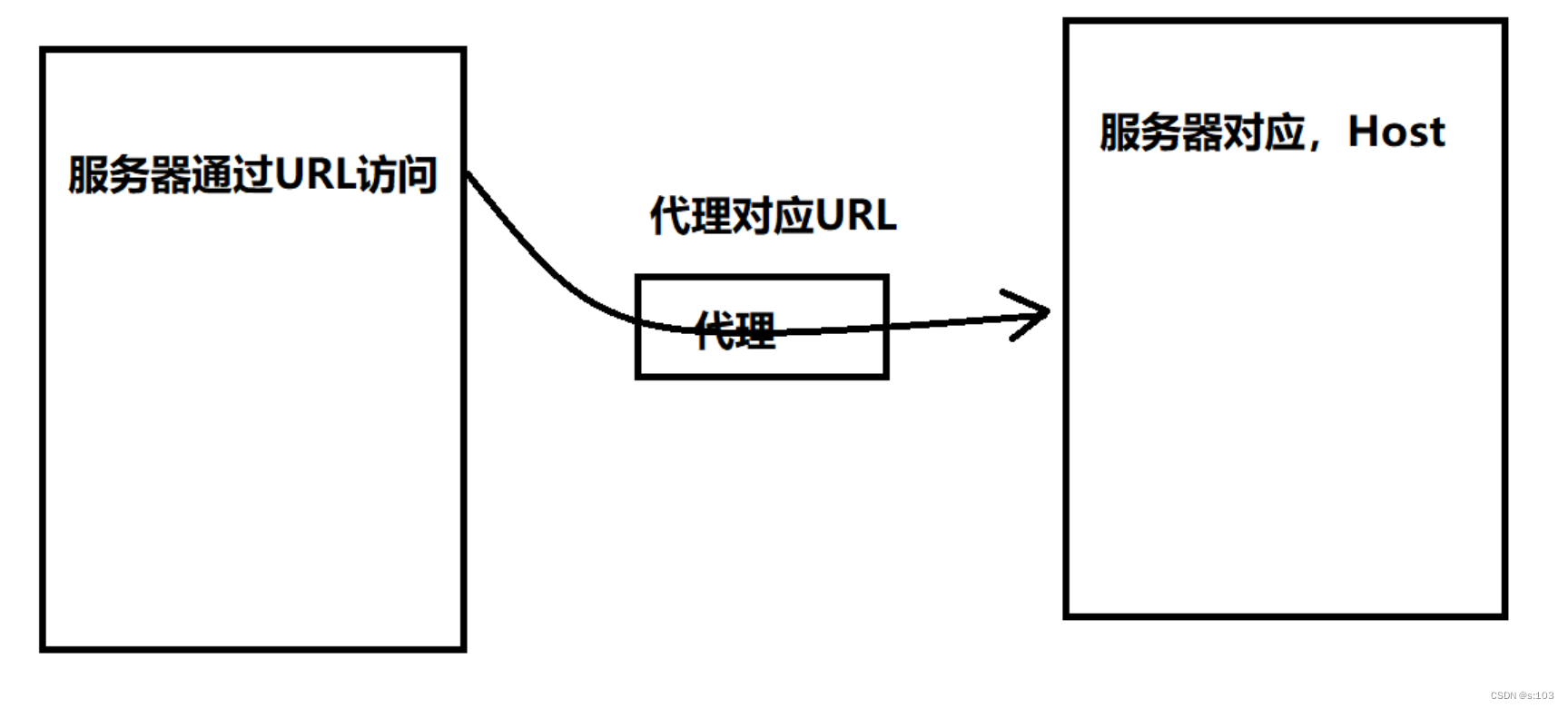
大部分情况下,Host和URL里的域名是一致的,但是如果当前的访问的服务器,不是直接访问的,而是通过“代理”访问的(不是fiddler,而是其他代理),就可能不一致了!
Host是最终的目标,URL是当前目标
2.2.2 Content-Type 与 Content-Length
- GET包里确实找不到,这也很正常,没有body,自然就没有这两个属性
那我们就找一个post请求
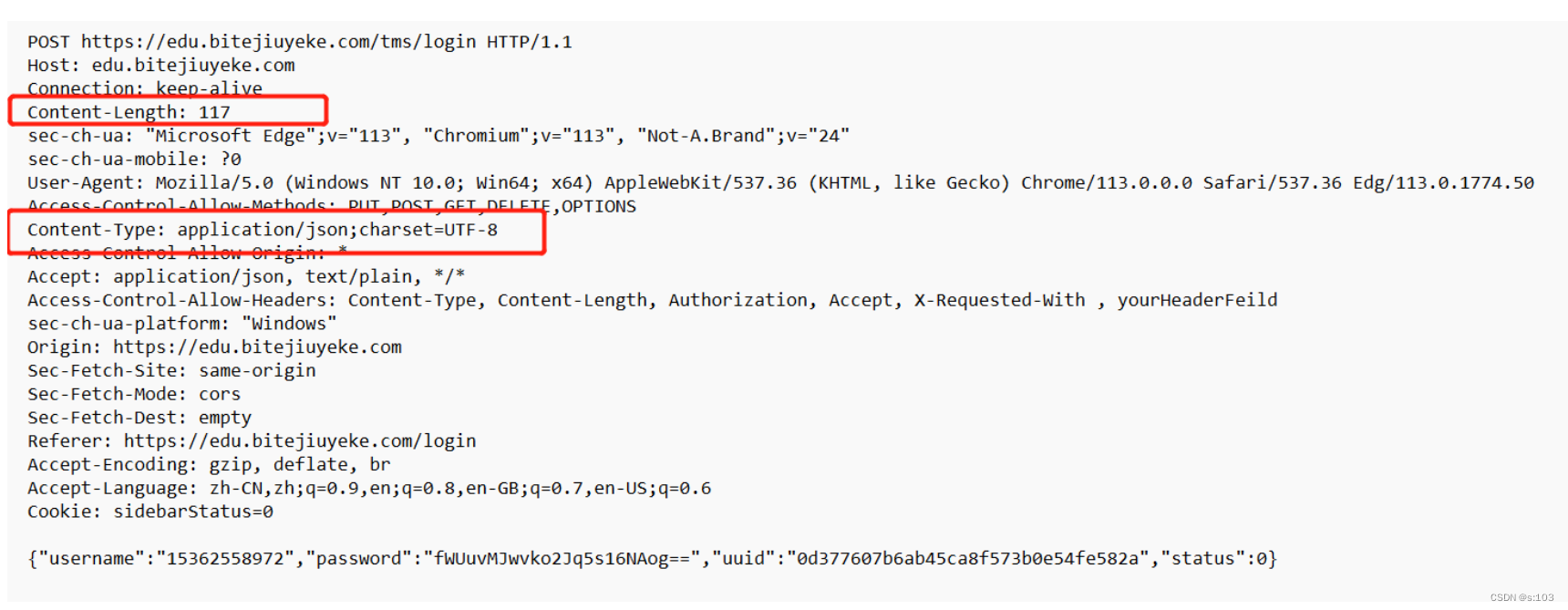
Content-Length:body的长度
Content-Type:body的类型
-
application/json(数据格式)
- 描述了我们的数据是按照json格式来组织的~
- 我们拿一个json组织的文件看一看:
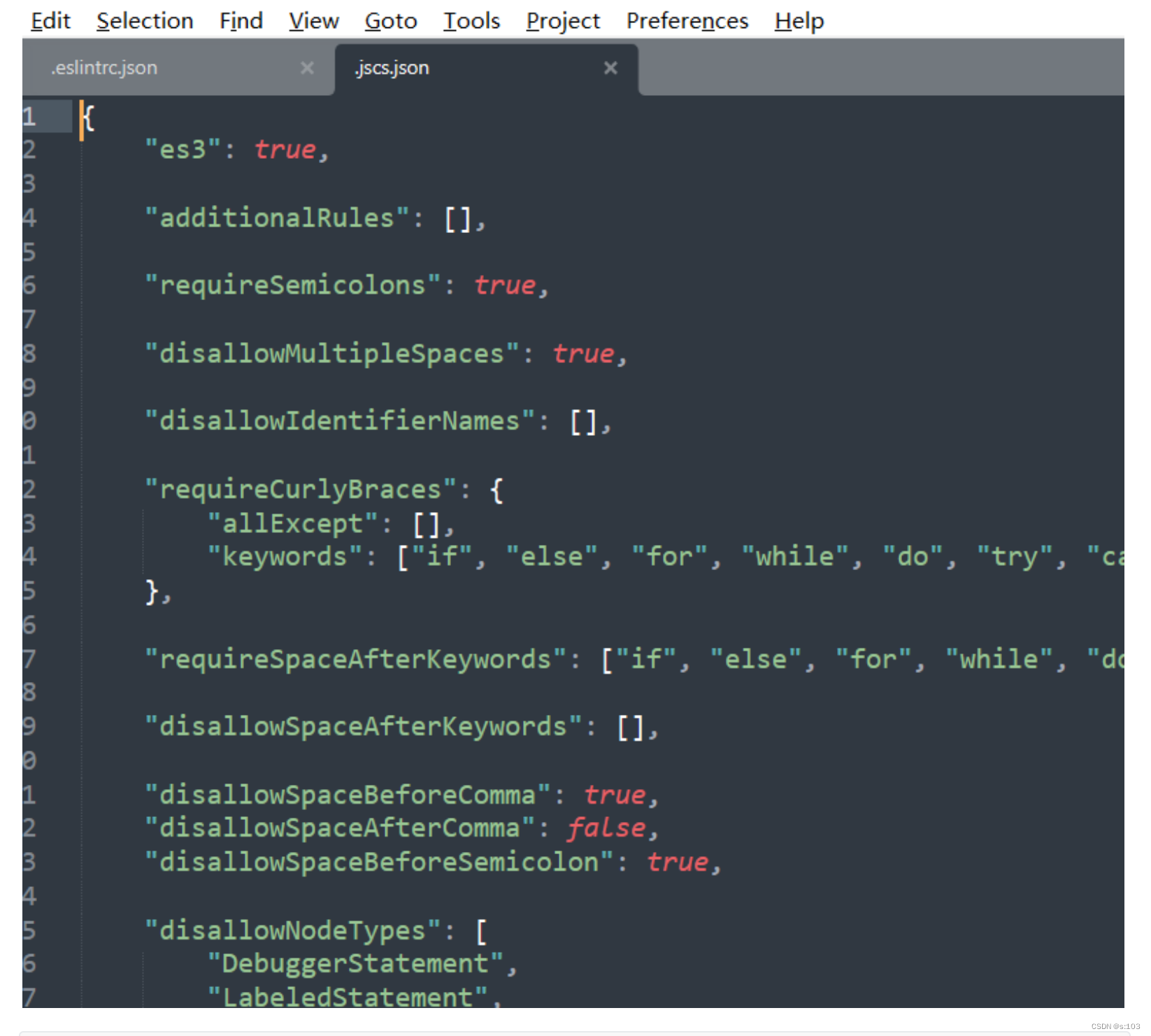
{ "username":"xxx", "password":"xxxxxx", "id":"xxxx", "status":0 }这个json格式,用{}表示,里面包含多个键值对,键值对之间用逗号,键与值之间,用冒号分割
var student = { name: '小马', height: 198, weight: 170, sayHello: function() { console.log("hello"); } };与JavaScript的对象定义挺像的,而json的这种格式,是js发展出来的
-
charset=utf8,字符集是utf-8
Content-Type还会有一些其他的写法
-
application/x-www-form-unlencoded
- form表单提交数据,就会生成这种格式的body
- 此时的body的格式,就是跟query string是一样的

作为请求,这两种写法最多
作为响应,Content-Type还有几种写法:
- text/html
- text/css
- application/javascript
- application/json
- image/jpg
- image/png
- …
按Ctrl+F5就可以获取大量的包
- 强制刷新,被缓存的响应/请求都重新加载
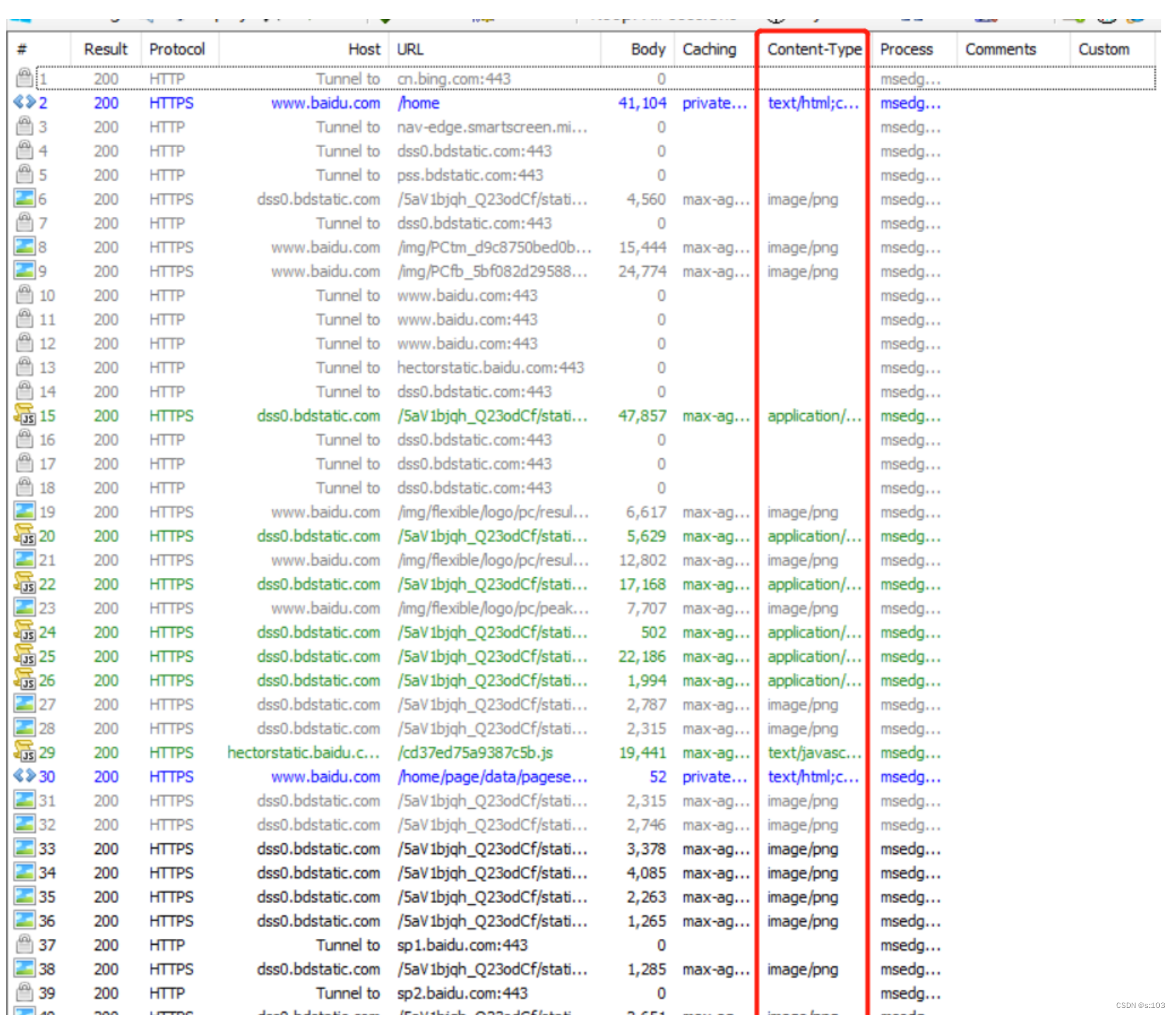
随便找一个:
- png本身就二进制格式,并不是body被压缩了

有了上述格式的描述,浏览器或者http服务器才能够正确认识当前的body里的数据,从而进行解析~
2.2.3 User-Agent(简称UA)
- 用户使用的客户端是啥样的
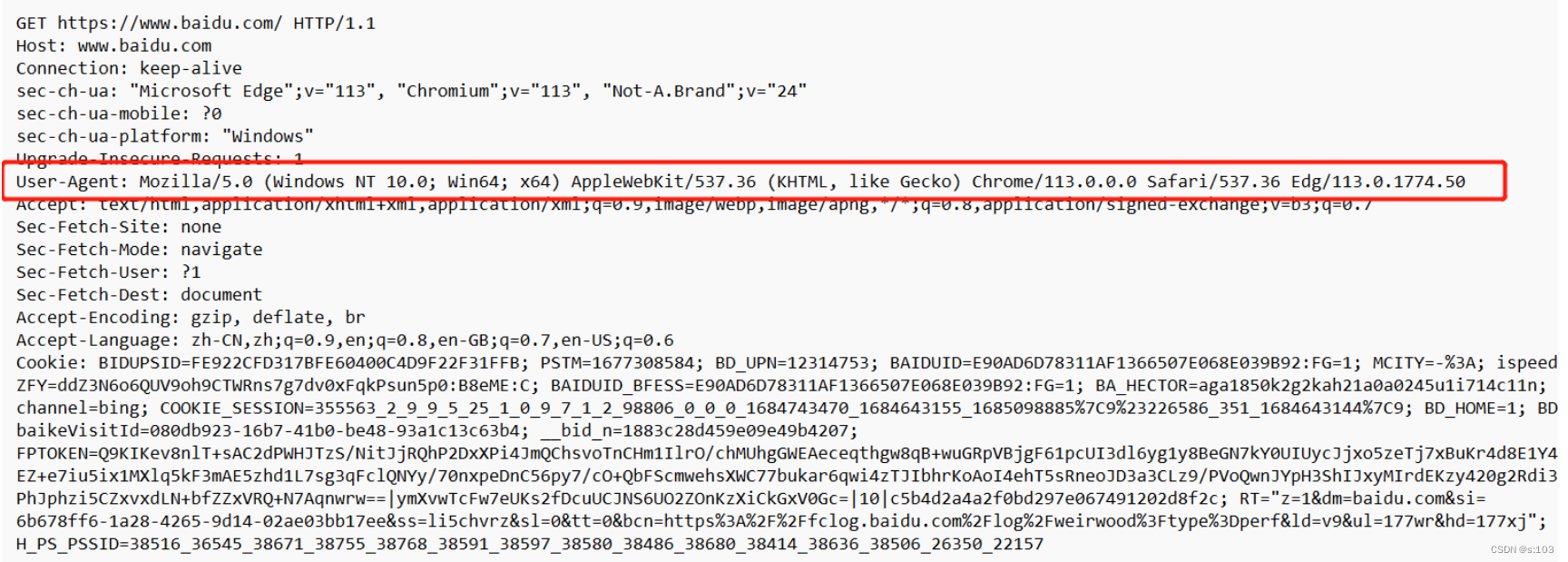
- 即操作系统的版本、浏览器的版本…
之前浏览器的功能参差不齐,所以有很多兼容性的问题,而后来浏览器发展的很快,到现在,浏览器功能基本一致,它们也都得遵循一些标准,兼容性问题也几乎没有了
- 而这个UA属性,就是为了解决兼容性问题来的,知道了客户端是啥样的,就可以对症下药~
而现在,UA的主要作用,是区分PC端还是移动端,因为电脑上看和手机上看,页面是不一样的,所以返回的响应也要不同~
- 打开F12开发者工具,返回的是一个pc端页面
- 按模拟手机端的选项返回手机端页面
- 可以看到,UA那边显示的是安卓系统…
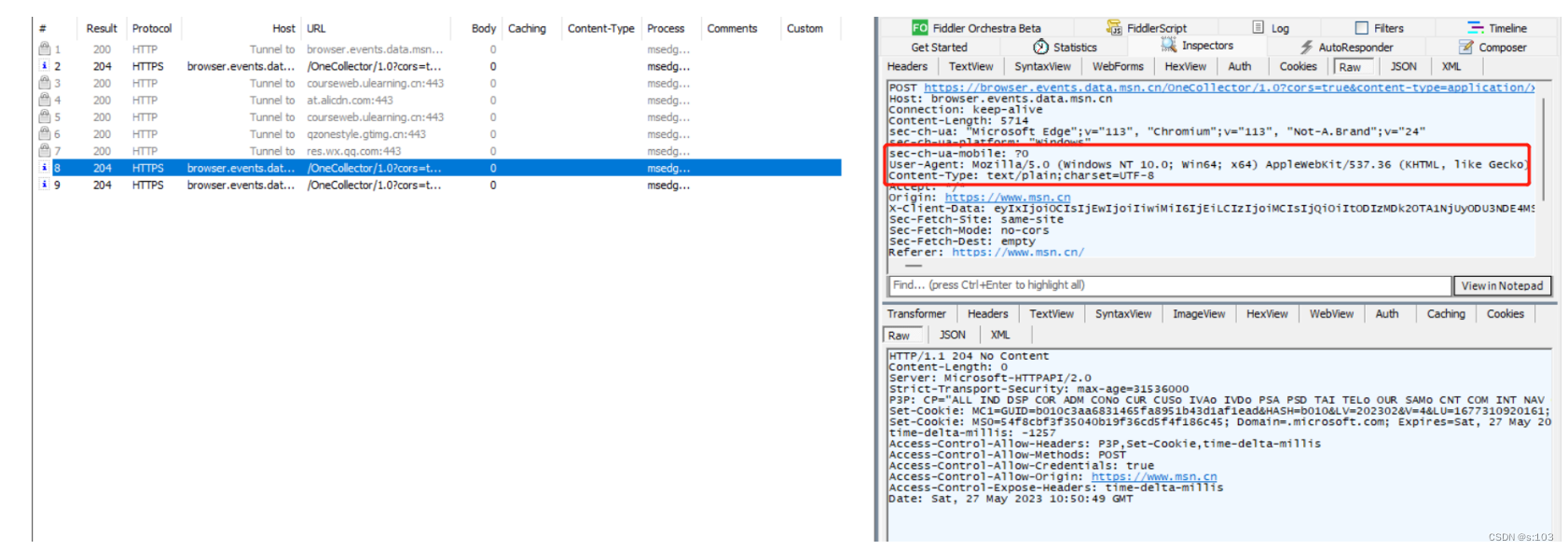
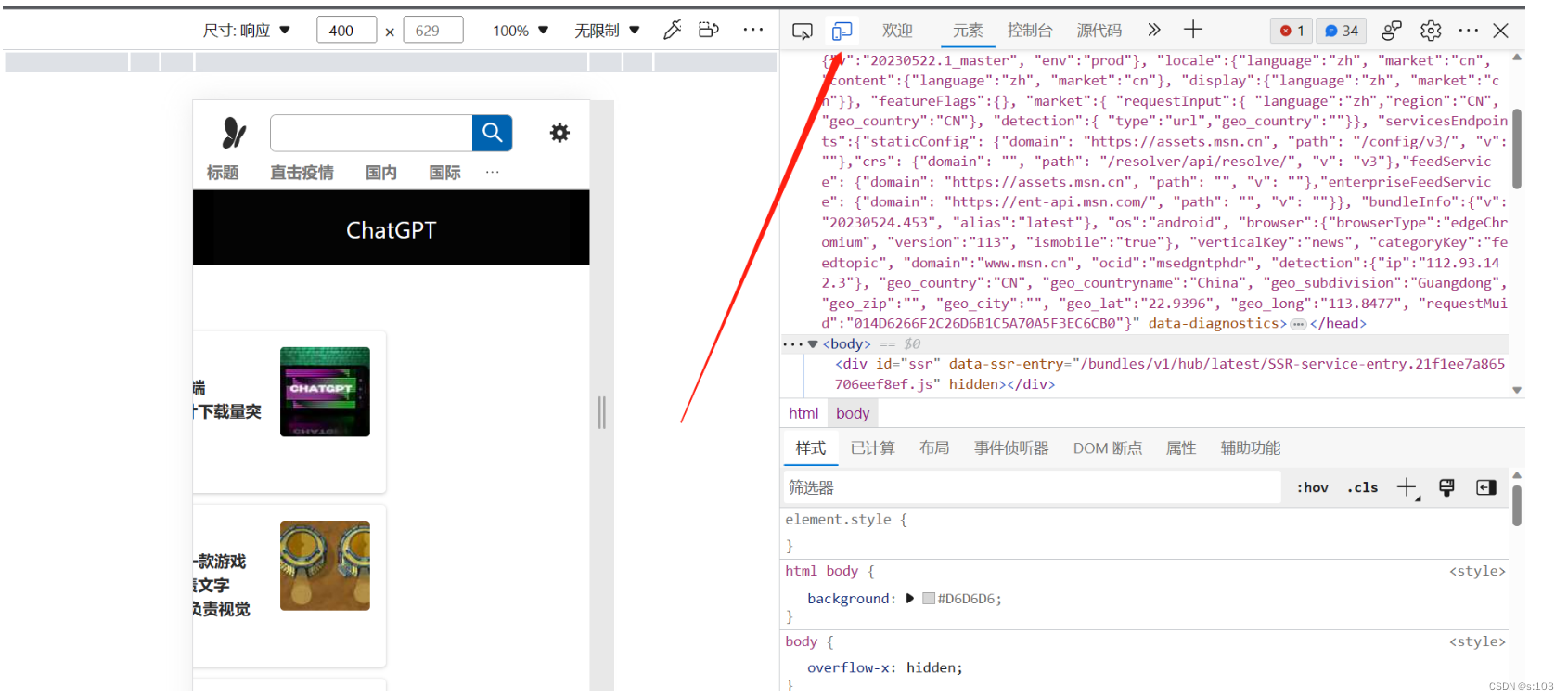

而我们有一个更好的方法去解决这个问题
- CSS3里提高了“媒体查询”的功能,可以根据浏览器出口的大小,来设置不同的样式,这种开发方式,称为“响应式布局”
2.2.4 Referer
- 顾名思义,就是“来路”(refer - er)

- 没错,不是每个请求都有Referer,如果你是直接通过地址栏输入url或者点击收藏夹的,就没有Referer
- 而如果是通过某个页面跳转的,就会有Referer,表示是从哪个页面跳转过来的
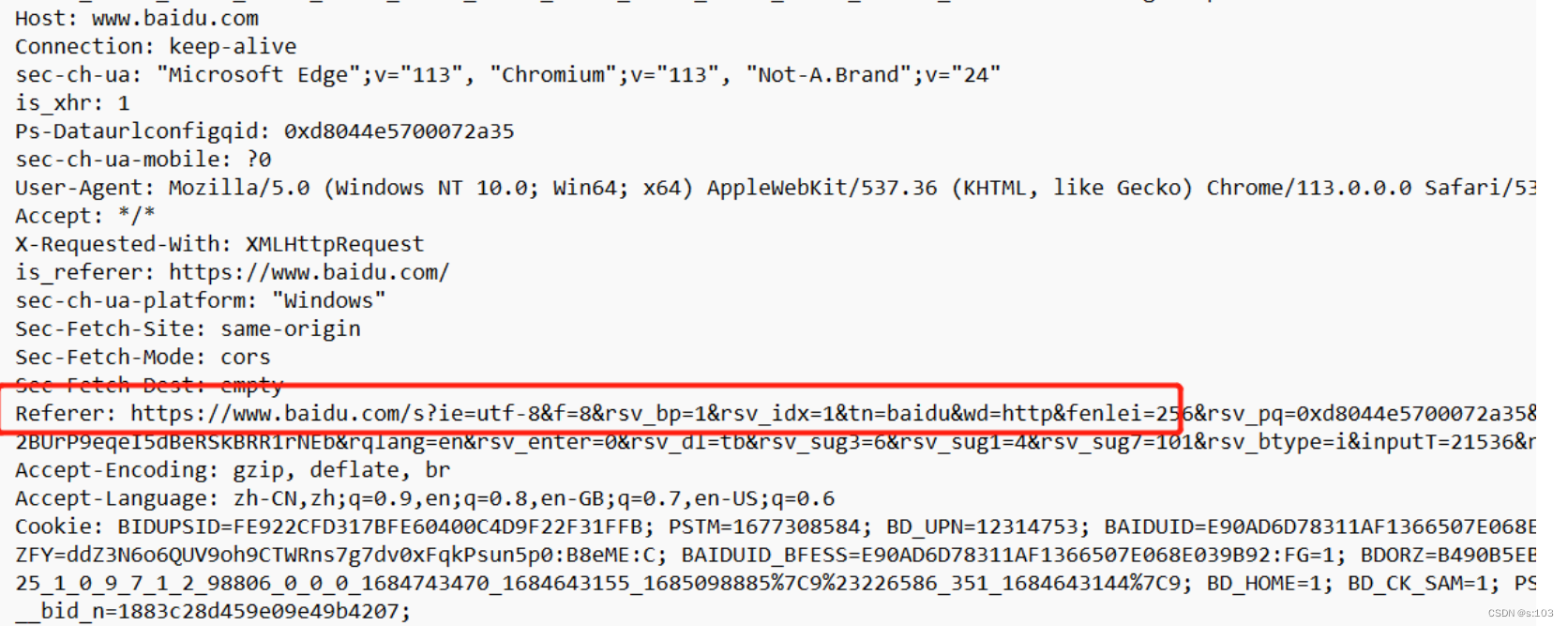
- 搜索一个东西,抓对应的那个请求包:
- 表示,“从baidu.com跳转过来的”
2.2.5 Cookie
- 小饼干,这是一个形象的说法,其实跟饼干没啥关系
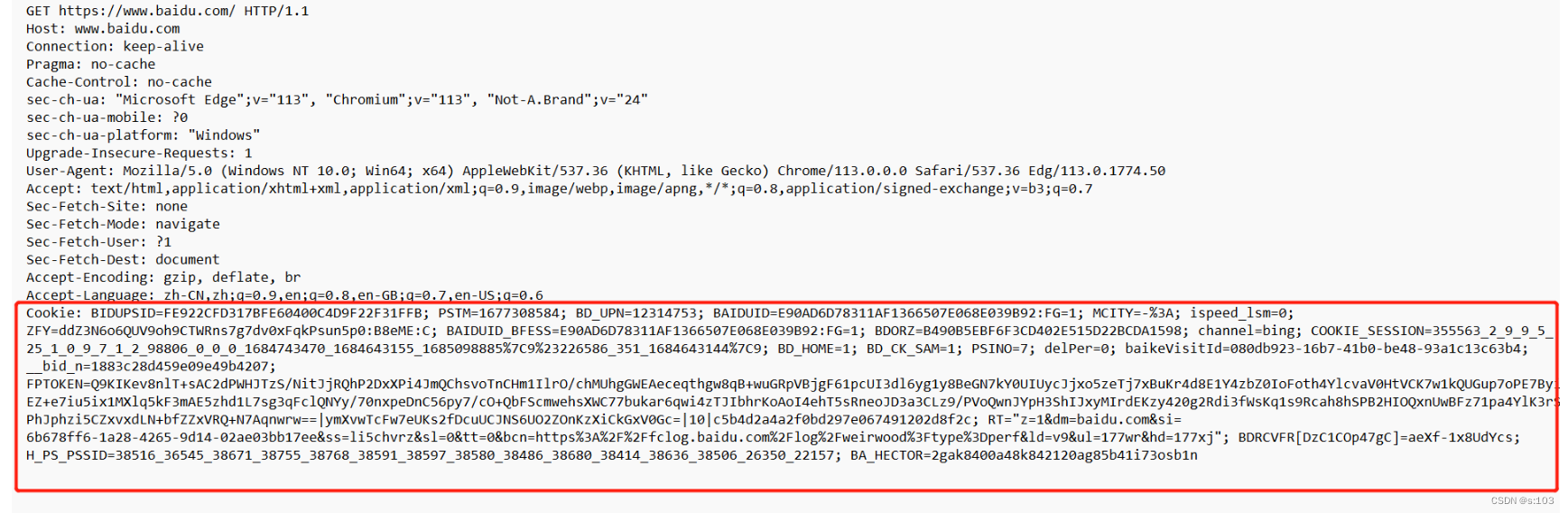
Cookie的值,也是键值对
- 键值对之间用分号分割
- 键与值之前用等号分割
这些数据,是程序员自定义的数据,键值对是什么意思,只有开发者知道~
- 不同的网站就有不同的键值对,拥有不同的涵义用途
小回顾:
HTTP中遇到的键值对
- url,query string
- header,每一行是一个键值对
- body,如果Content-Type为x-www-form-urlencoded或者json,body的内容也是键值对
- Cookie里面,存储的数据也是键值对
这些键值对,都是允许用户自定义的
- 这些自定义的键值对,都是HTTP留给程序员进行扩展的地方,可创新发展,这样就可以满足各种不同的场景,这也就是HTTP能这么火的一个重要原因
Cookie的本质,就是浏览器在本地存储用户自定义数据的一种关键机制!
- 直接存储在硬盘是肯定不合理的,如果是一些奇怪的网站,它有权限去访问你的硬盘,那就糟糕了!
Cookie机制,允许我也往浏览器这边存储一些自定义的键值对,这些数据通过浏览器的api,把这个特定的数据写入特定的文件中~
- 一般,我们用到的各种数据,都是从服务器获取的
- 而浏览器(客户端)也需要存储数据(用户自定义数据),例如,用户的身份信息
- 比如登录了u学院,那么访问u学院里面的其他页面,就不需要重新登录了,就是因为浏览器存储了这个信息,你跳转的时候,通过Cookie就能获取这些自定义信息了,也就不需要重新登录了
- 就像自己烘烤的小饼干,跳转的时候客户端自己提前吃了就是了
- 同一个网站(百度搜索,百度图片…)共享一份cookie,不同网站(百度和搜狗)则用的是各自的cookie
Cookie的几个问题:
- Cookie从哪来?
- Cookie到哪去?
- Cookie有啥用?
Cookie从哪里来?
- 从服务器来的,当我们的浏览器访问服务器的时候,服务器就会在HTTP响应中,通过Set-Cookie字段,把Cookie键值对,返回给浏览器
- 不是发出请求的时候,而是第一次得到该响应的时候设置的cookie
- 浏览器收到这个数据,就会在本地存储
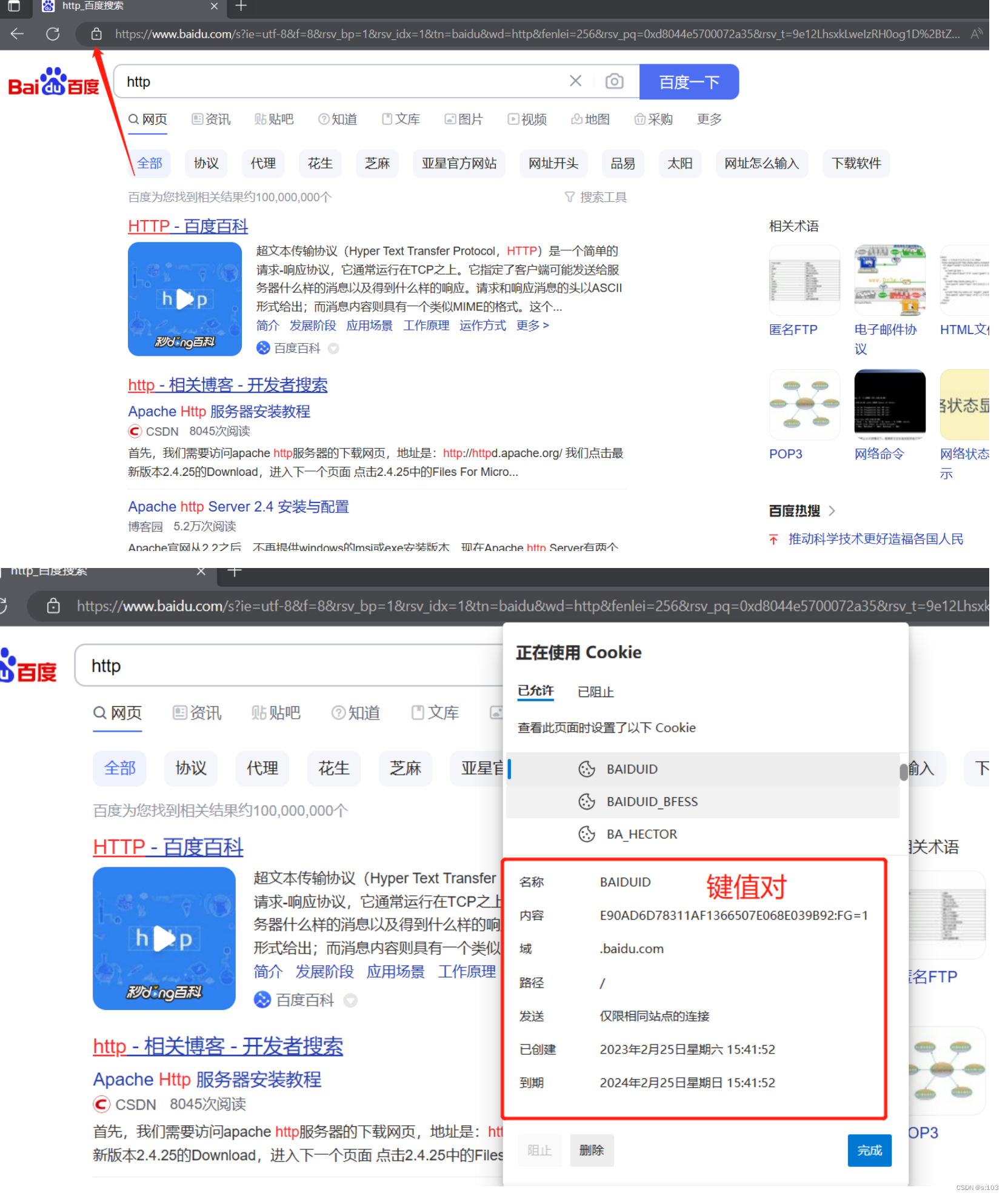
在edge浏览器中:
- 点击这个小锁头
- 在里面就可以找到Cookie对应的文件了
也可以删掉~
- 选中,按delete
这样在去抓包去观察SetCookie:
请求:
响应:
这些都服务器返回给浏览器的cookie数据,这样cookie文件里又有东西了:
下次也就可以通过一些api在这里获取了~
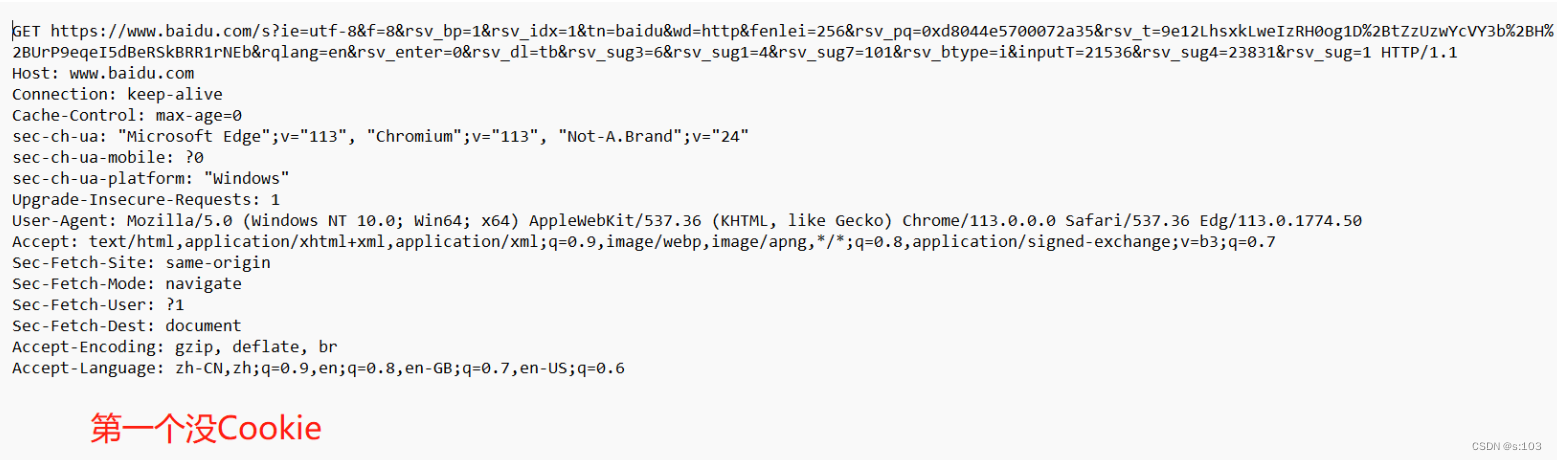
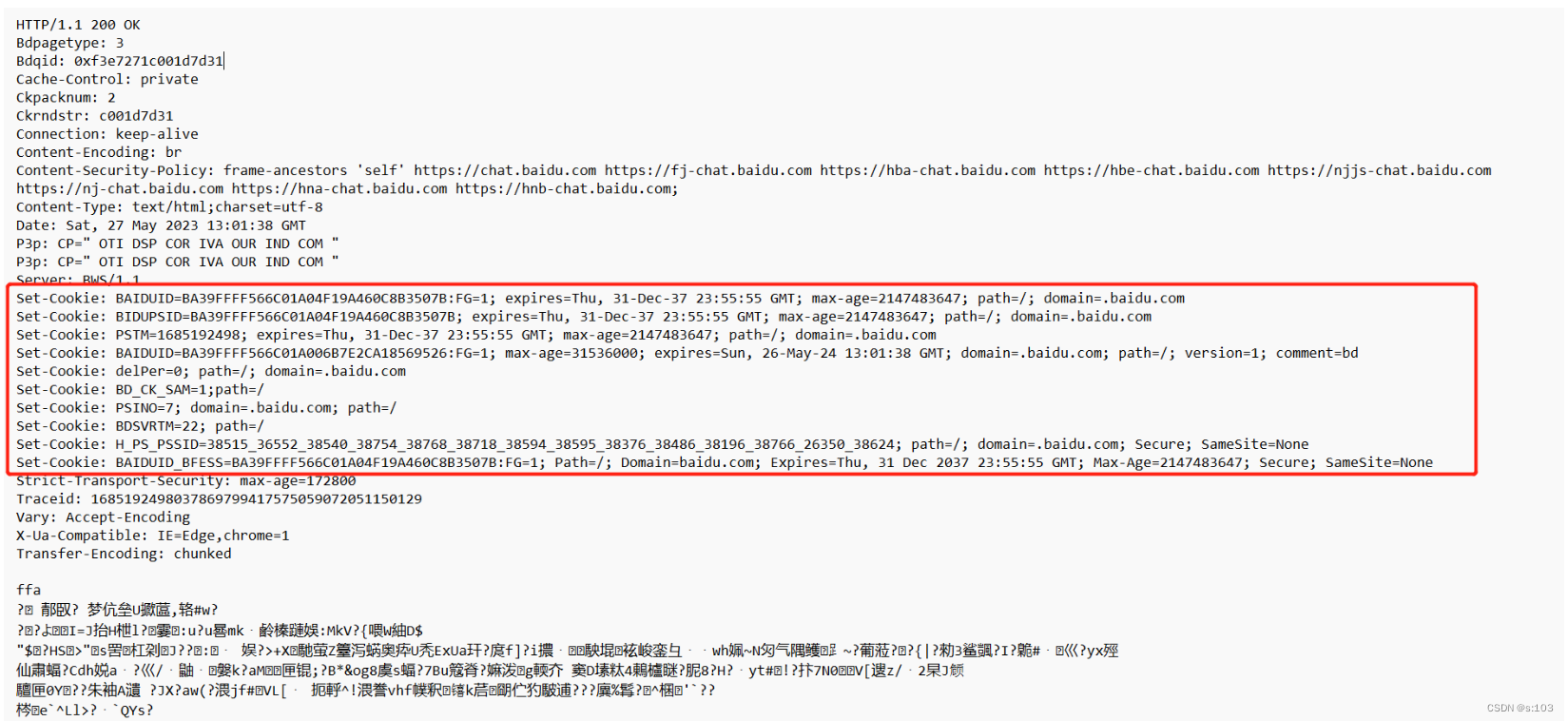
Cookie从哪去?
会在下场请求的时候把cookie发给服务器,而这时比第一次要快,因为不需要重新准备Cookie里的数据
- Cookie只是暂存于浏览器,真正的数据发挥作用,还得是服务器作用!
- 这也是Cookie与缓存不一样的一个点
Cookie有啥用?
- 是浏览器本地存储数据的机制
就比如学校的教务系统,服务器提供给老师和学生的服务是不一样的,服务器就可以通过Cookie去区分
- 比如,客户端在登录的时候,服务器就识别号客户端的角色,把角色set进Cookie里,后面的请求,服务器就根据Cookie就知道身份了
- 身份况且,常识是登录后跳转是不需要身份验证的
- 客户端也就不需要每次都构造这个信息数据
- 服务器也就不需要每次都判断身份
例子:
- 而这个就诊卡就是cookie!
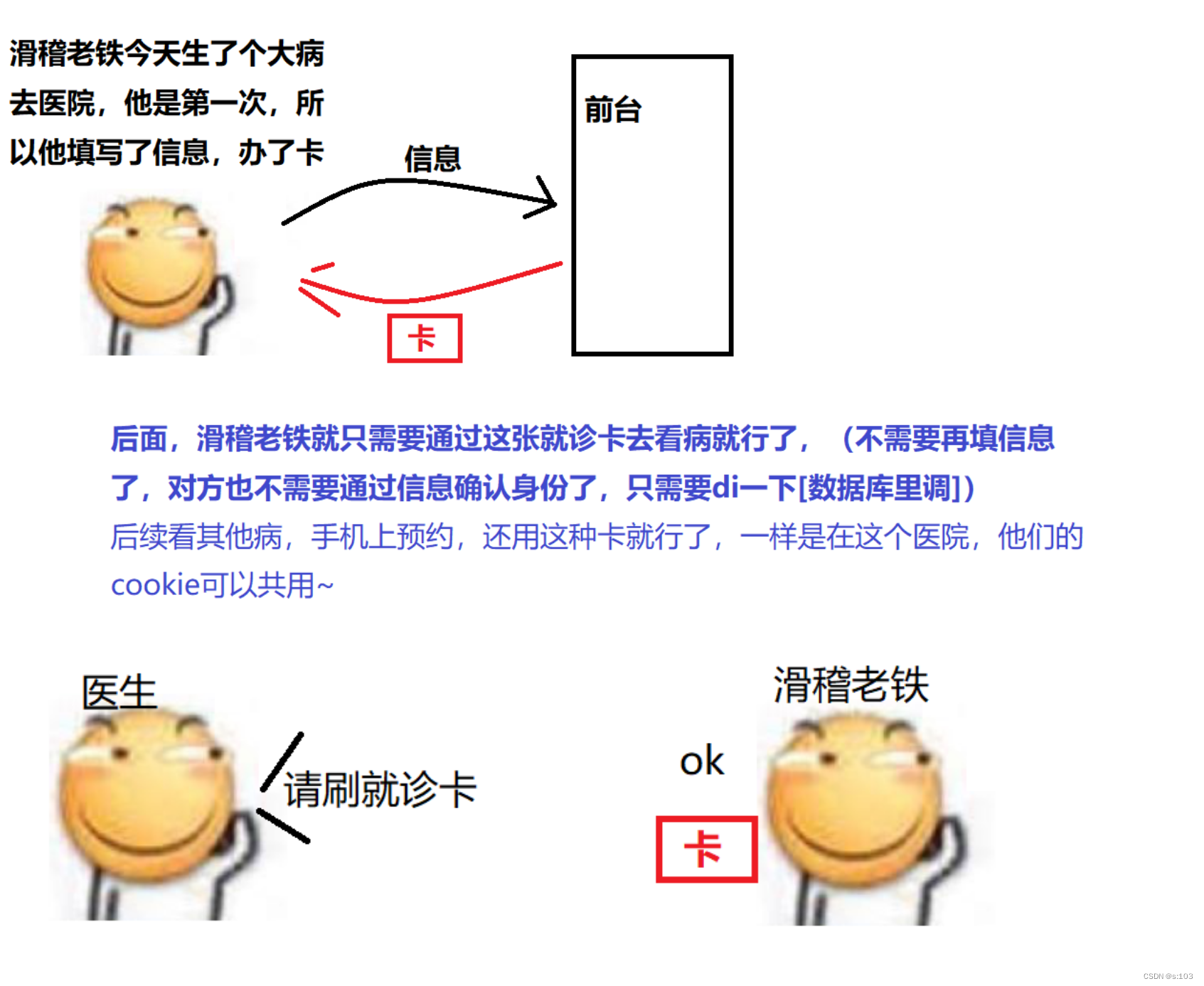
cookie的扩展性很强,需要重点掌握,后续涉及代码会重点讲解~
文章到此结束!谢谢观看
可以叫我 小马,我可能写的不好或者有错误,但是一起加油鸭🦆!后续会讲解HTTP状态码,构造HTTP请求,HTTPS加密机制等等…
敬请期待吧~