一)优雅的key结构:
redis中的key虽然可以自定义,但是最好遵循下面的几个最佳实践约定:
1)遵循基本格式:业务名称:数据名字:ID;
2)长度不要超过44字节,key所占的字节数越小,占用空间越小,越短越好;
3)不要包含特殊字符;
例如当设计登录业务的时候,保存用户信息,其实可以这样:login:user:10
优点:
1)可读性强
2)避免key的冲突:没有直接使用用户的ID,防止不同的业务之间都使用用户的ID造成key冲突,加上业务名字可以避免业务冲突;
3)方便Key的管理,使用冒号分离,在redis中形成层级结构;
4)更节省内存:key是String类型,底层编码包括int,embstr和raw三种,embstr在小于44字节的时候进行使用,采用连续的内存空间,所占用的内存更小;
查看底层编码:object encoding+key的名字;
int编码:当key是数值的时候进行存储,占用内存空间是非常小的
embstr:是一段连续空间,编码会更加紧凑,占用空间比较小,想要使用ambstr的编码格式,key就需要小于44字节
raw:空间不是连续的,访问性能下降,内存占用会更高,还会产生内存碎片
二)BigKey
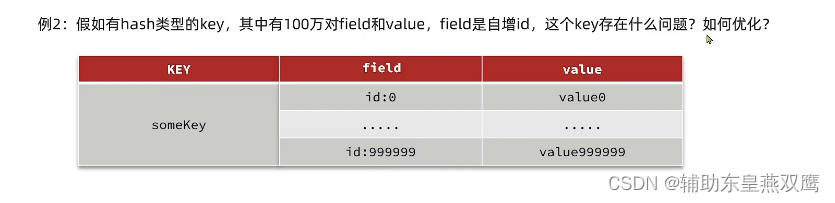
在Redis中,一个字符串最大是512MB,一个二级数据结构比如说哈希,list,set,zset可以存储大约40亿个元素,但是实际上如果出现以下几种情况,就被认为是bigKey
1)字符串类型:它的big体现在单个value置很大,一般认为超过10KB就是BigKey
2)非字符串类型:哈希,列表,集合它们的bigKey取决于元素个数太多
memory usage+Key的名字,查看key的大小,但是消耗的CPU资源比较多
针对于String类型来说:strlen key查看key的长度
针对于list集合来说:llen key,查看list集合的长度
三)BigKey的危害:
1)网络阻塞:针对于BigKey进行网络请求的时候,假设每秒钟对这个bigKey的请求达到了20个,少量的并发就很有可能导致带宽被占满,导致Redis实例乃至所在的物理机变慢,假设这太物理机除了部署redis以外还部署了一些其他的应用,那么会导致其他网络请求被阻塞
2)数据倾斜:BigKey所在的Redis实例内存利用率(数据量)远远超过其他实例,导致无法使数据分片的内存资源达到均衡;
3)Redis阻塞:针对元素比较多的哈希,list,zset等做运算的时候会耗时较久,redis还是单线程的,是主线程被阻塞
4)CPU压力过高:针对BigKey的数据做序列化和反序列化会导致CPU的使用率飙升,影响Redis和本机其他实例的使用
四)排查BigKey:
1)redis-cli --bigKeys,利用redis-cli提供的bigKeys参数,可以遍历分析所有的key,并返回Key的整体统计信息和每一种数据的Top1的big key;
2)scan扫描,利用scan扫描Redis中的所有key,利用strlen或者是hlen等命令来判断key的长度,此处不建议使用memory usage或者是keys *;
2.1)第1个参数是游标,也就是你从第几个位置开始进行扫描,最终redis会返回一个游标,下一次会继续从这个位置进行扫描;
2.2)第二个参数你扫描哪一种类型,第三个参数是你要扫描几个
@Controller public class UserController { @Autowired private Jedis jedis; private final int StringMax=10*1024; private final int HashMax=500; @RequestMapping("/Java100") @ResponseBody public void scan(){ System.out.println("1"); long MaxLen=0; long KeyLen=0; String cur="0"; do{ ScanResult<String> result= jedis.scan(cur); //1.记录游标 cur=result.getCursor(); //2.获取到扫描的key List<String> list=result.getResult(); if(list==null||list.isEmpty()){ break; } for(String key:list){ System.out.println(key); switch(jedis.type(key)){ case "string": KeyLen=jedis.strlen(key); MaxLen=StringMax; break; case "hash": KeyLen= jedis.hlen(key); MaxLen=HashMax; break; case "list": KeyLen= jedis.llen(key); MaxLen=HashMax; break; case "set": KeyLen= jedis.scard(key); MaxLen=HashMax; break; case "zset": KeyLen= jedis.zcard(key); MaxLen=HashMax; break; } if(KeyLen>=MaxLen){ System.out.println("当前key是一个bigKey"); } } } while(!cur.equals("0")); } }
五)如何删除BigKey
因为BigKey所占用的内存比较多,那么即便即使删除这样的Key也是很消耗时间的,这样还会导致Redis的主线程阻塞,从而引发一系列问题
1)redis3.0以下版本,比如说hash类型,先借用hdel来删除一个一个的子元素,最后删除key,如果是集合类型,那么先遍历BigKey的子元素,先逐个删除子元素,最后在删除BigKey,还是不能使用keys *,还是使用scan,还是指定key返回一个游标;
2)redis4.0以后提供了异步删除的命令,就是unlink命令



恰当的数据类型1:
第一种字符串对象存储方式,修改对应的字段值很不方便,新增字段值也很不方便
第二种转化成更大的key进行存储
1)占用空间比较大,有几个字段,key都是user:1:name,存储了很多相同的key,浪费空间
2)想要获取用户的所有信息比较麻烦
第三种的value又是一个键值对,但是Hash结构的Entry不要超过1000
恰当的数据类型2:
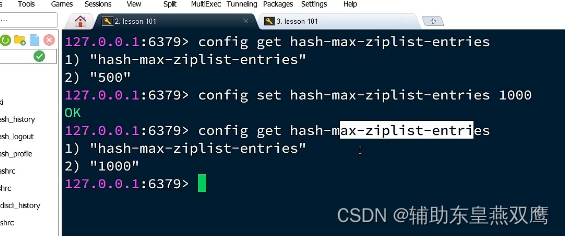
1)当hash的entry数量超过500的时候,会使用哈希表而不是使用ZipList,这样会使内存占用比较多
2)可以通过修改hash-max-ziplist-entries配置entry上限,但是如果entry过多就会导致bigKey问题,但是还是可以通过config set hash-max-ziplist-entries 1000来进行修改
解决方案:
1)转化成String类型进行存储:解决了BigKey的问题
1.1)String类型底层结构没有太多优化,内存占用比较多
1.2)想要批量获取这些数据比较麻烦
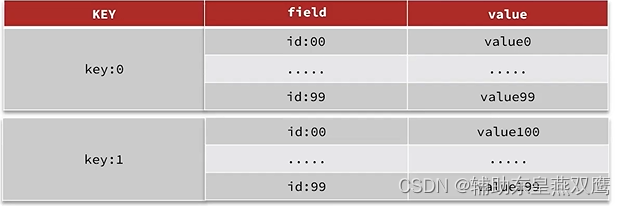
2)拆分成小的hash,将id/100作为key,将id%100作为field,这样每100个元素为一个hash,解决了BigKey的问题;


批处理优化:
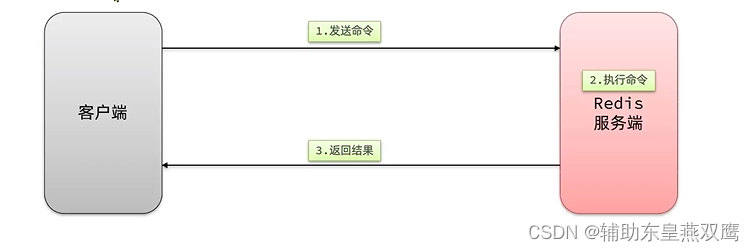
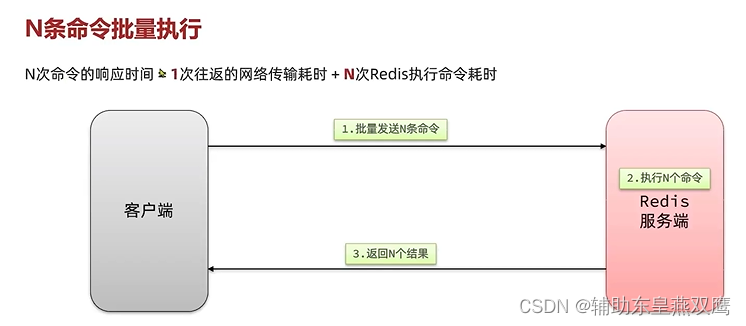
一次命令的执行时间:1次往返的网络传输耗时+1次redis的执行命令的耗时,网络传输是非常耗时的,但是也不需要在一次批处理中传输太多命令,否则单次命令占用网络带宽过多导致网络阻塞
mset虽然可以进行批处理,但是却只能操作部分数据类型,如果对有复杂数据类型的批处理需要,需要使用管道来进行处理
1)m操作是redis原生提供的操作,这个操作的执行是原子性的,一次性会直接全部执行完成,中间过程中不会有其他命令来进行插队
2)但是管道是直接讲这些命令发送到管道里面,但是不会一起执行,因为管道里面命令的传输是有先后顺序的,在命令传输的过程中也是可以有其他客户端来给redis传输命令的,管道的命令会进入到redis队列中排队,redis的线程会依次取出这些命令进行执行,如果有其他命令来插队,那么实际执行时长可能会比与其执行时长要长



集群下的批处理:
批处理是在一次连接中把所有的请求全部干掉,如mset或者是Pipeline这样的批处理需要在一次请求中携带多条命令,而如果此时Redis是一个集群,那么批处理得key必须落到同一个插槽中,否则就会执行失败;
mset、mget只支持在同一个槽内的key,因为不在一个槽内的key可能存在于不同节点上

服务器端的优化:
1)用来做缓存的redis尽量不要使用持久化功能;
2)建议关闭RDB持久化功能,使用AOF持久化功能;
3)利用脚本定期在slave节点做RDB,来实现数据备份;
4)设置合理的rewrite阈值,避免频繁的重写
5)配置no-appendfsyc-on-rewrite:yes,禁止在AOF重写的过程中做AOF持久化,避免因为AOF引起的阻塞
不建议redis和做大量CPU密集型计算的应用和高磁盘负载的应用部署到同一台服务器上

慢查询:

下面的例子就是假设执行了keys *命令,接下来就可以通过showlog get 1来查询对应的命令

bind表示可以访问所有可以访问redis的服务器

这个配置是把config命令替换成后面的命令


redis内存配置:
当redis内存不足的时候,可能会导致key频繁被删除,响应时间变长等问题,当redis的内存使用频率超过90%以上就需要我们警惕,并应该快速定位到内存占用的原因
1)数据内存,这是redis最主要的部分,用来存储redis的键值信息,主要的问题是BigKey问题,内存碎片的问题,是在内存分配的过程中产生的,当向redis中存储一部分的数据的时候,假设存储10个字节,就会分配16个字节,多分配给的6个字节就是内存碎片,要想解决内存碎片问题,就可以解决内存碎片的问题;
2)进程内存:Redis主进程本身运行肯定需要占用内存,比如说代码和常量池等等,这部分内存大约几兆,在大多数生产环境中和Redis数据占用的内存相比可以忽略
3)缓冲区内存: