文章目录
- 概述
- 图解

概述
Kafka 的高性能主要依赖于以下几个关键因素:
- 分布式架构:Kafka 采用分布式集群架构,可以水平扩展到上万个节点,支持每秒处理百万级消息。
- 持久化存储:Kafka 使用文件系统持久化存储消息,避免了数据库成为性能瓶颈,大大提高了吞吐量。
- 顺序读写:Kafka 的消息和文件都是顺序读写的,不需要频繁的随机寻址,这种顺序写入的方式非常高效。
- 零拷贝:Kafka 使用 SendFile 技术,可以直接将文件映射到内核空间和网络空间,避免用户空间和内核空间之间的拷贝,提高网络吞吐量。
- 批量处理:Kafka 会将多个消息批量写入,避免了频繁的网络传输和磁盘寻址,提高了整体吞吐量。
- 页高速缓存:Kafka 利用页高速缓存来加速读写,最近访问的页会留在高速缓存,不需要每次都读磁盘。
- 消息压缩:Kafka 支持消息压缩,可以减少网络流量和磁盘空间占用,提高系统吞吐量。
- 高效订阅:Kafka 的消费组通过订阅 topic 实现负载均衡,简化了消费端设计,也提高了总体吞吐量。
以上这些技术设计使 Kafka 既可以作为高吞吐的消息队列,也可以作为低延迟的发布-订阅系统,性能非常优异。
图解
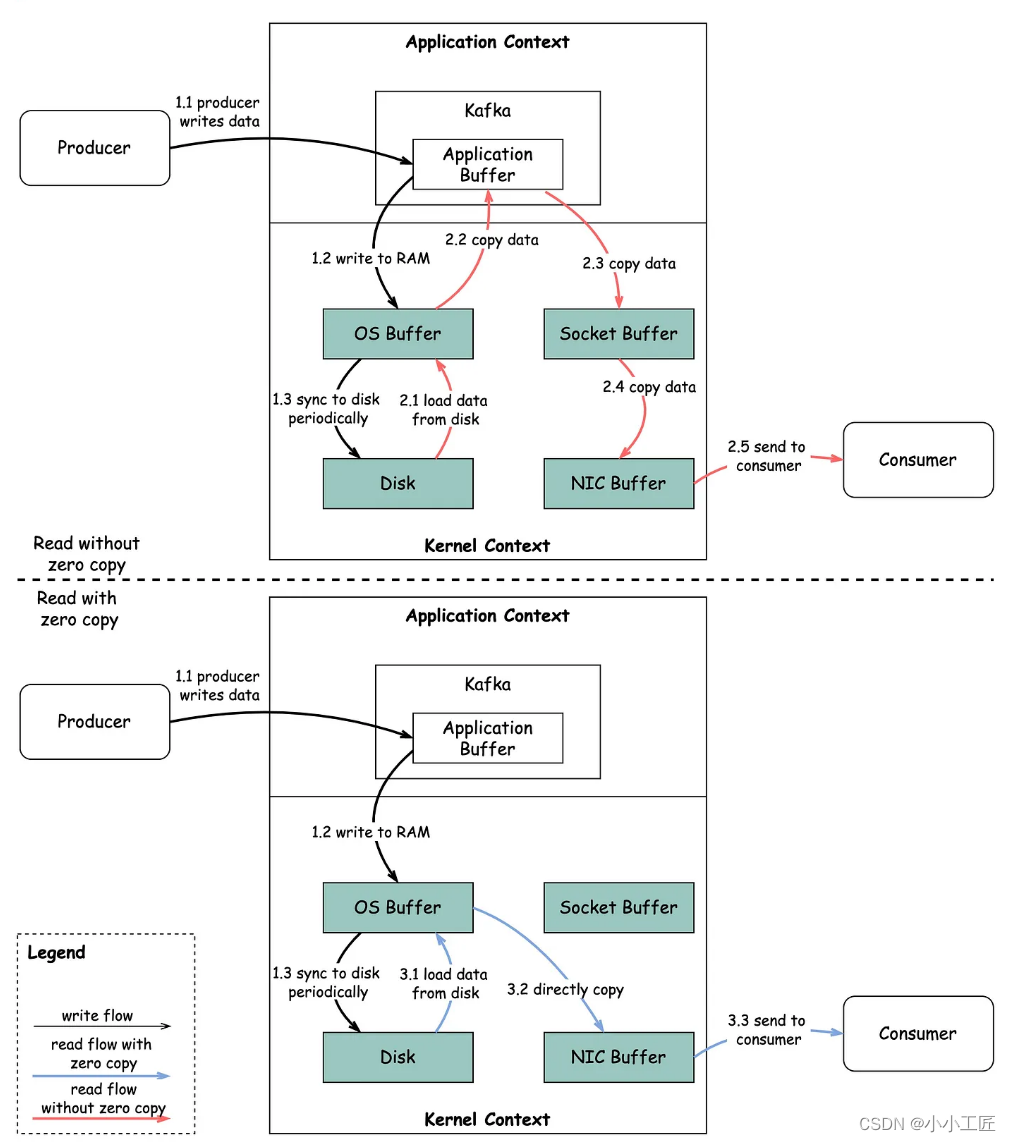
🔹步骤 1.1 - 1.3:生产者将数据写入磁盘
🔹步骤 2:消费者无零拷贝读取数据
2.1:数据从磁盘加载到操作系统缓存
2.2:数据从操作系统缓存复制到 Kafka 应用程序
2.3:Kafka 应用程序将数据复制到套接字缓冲区
2.4:数据从套接字缓冲区复制到网络卡
2.5:网络卡将数据发送给消费者
🔹步骤 3:消费者使用零拷贝读取数据
3.1:数据从磁盘加载到操作系统缓存
3.2:操作系统缓存通过 sendfile() 命令直接将数据复制到网络卡
3.3:网络卡将数据发送给消费者
零拷贝是一种节省应用程序上下文和内核上下文之间多次数据复制的方法。这种方法将时间降低了约 65%。