1 简介
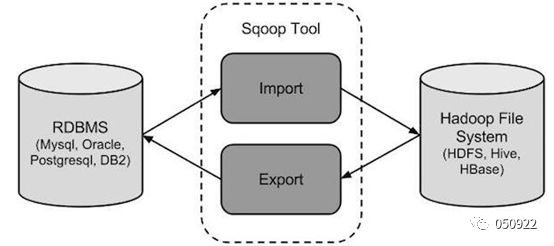
Sqoop是Apache下的一款数据传输工具,用于Hadoop和关系型数据库等结构化数据存储之间的数据传输。
最新的稳定版本是1.4.7,Sqoop2 的最新版本是 1.99.7。请注意,1.99.7 与 1.4.7不兼容,且没有特征不完整,也并不打算用于生产部署。
导入数据(import):RDBMS(mysql、Oracle)--->Hadoop(HDFS、Hive、HBase)
导出数据(export):Hadoop(HDFS、Hive)---->RDBMS
2 原理
Hive本质:执行mr程序,依赖hdfs存储数据,把sql转换成mr程序。
sqoop本质:数据迁移。
迁移方式:将导入或导出命令翻译成mapreduce 程序来实现。
在翻译出的mapreduce中主要是对inputformat和outputformat进行定制,可自定义多个format。

Hadoop中只用hdfs,去掉yarn和mapreduce框架,与spark结合使用,加速执行。
3 安装
软件:
sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
mysql-connector-java-5.1.46-bin.jar
解压:
[root@master src]# tar -xvfsqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /usr/local/
[root@master local]# mvsqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop-1.4.6
环境变量配置
vim /etc/profile(工作中使用单用户目录)
#####################sqoop
export SQOOP_HOME=/usr/local/sqoop-1.4.6
export PATH=$PATH:$SQOOP_HOME/bin
配置sqoop文件
[root@master conf]# cpsqoop-env-template.sh sqoop-env.sh
[root@master conf]# vim sqoop-env.sh
#Set path to where bin/hadoop is available
exportHADOOP_COMMON_HOME=/usr/local/hadoop-2.8.4
#Set path to where hadoop-*-core.jar isavailable
exportHADOOP_MAPRED_HOME=/usr/local/hadoop-2.8.4
#set the path to where bin/hbase isavailable
export HBASE_HOME=/usr/local/hbase-0.98.6
#Set the path to where bin/hive isavailable
export HIVE_HOME=/usr/local/hive-1.2.2
#Set the path for where zookeper config diris
export ZOOCFGDIR=/usr/local/zookeeper-3.4.5
配置bin目录下的configure-sqoop
注释135-147,就是hadoop,hbase等的日志干扰
拷贝jar包
[root@master lib]# cp -a/usr/local/src/mysql-connector-java-5.1.46/mysql-connector-java-5.1.46-bin.jar .
查看版本:sqoop version
查看命令:sqoop help
启动hadoop、zookeeper、mysql
连接数据库:
[root@master ~]#sqoop list-databases --connectjdbc:mysql://master:3306/ --username root --password 123456
4 RDBMS导入到Hive
(1) 查询导入数据:查询表中某些数据导入到hdfs中。
先进入数据库,并创建表
mysql> create database company;
mysql> create table company.staff(id int(4) primary key not nullauto_increment, name
varchar(255), sex varchar(255));
插入数据
mysql> insert into company.staff(name, sex)values('Thomas', 'Male');
mysql> insert into company.staff(name, sex) values('Catalina', 'FeMale');
全部导入
[root@master ~]#sqoop import \
--connect jdbc:mysql://linux01:3306/company \
--username root \
--password 123456 \
--table staff \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t"
Target-dir:hdfs目录
num-mappers:map个数,看数据量来定,一个map一个文件
误删:hadoop有个回收站,可以找回来
Mysql数据导入到hdfs,默认的列分隔是“,”,默认的行分隔符是“\n”
查看:
到hdfs中查看/user/company数据
(2) 查询导入数据:查询表中某些数据导入到hdfs中。
[root@master ~]# sqoop import \
--connect jdbc:mysql://linux01:3306/company \
--username root \
--password 123456 \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--query 'select name,sex from staff where id <=1 and $CONDITIONS;'
must contain'$CONDITIONS' in WHERE clause.
如果 query 后使用的是双引号,则$CONDITIONS 前必须加转移符,防止 shell识别为自己的变量。
--query 选项, 不能同时与--table 选项使用
在使用query的时候,后面必须加条件,在任务产生多个map的时候,用条件表示从哪个map开始读取数据
(3) 导入指定列
[root@master ~]# sqoop import \
--connect jdbc:mysql://linux01:3306/company \
--username root \
--password 123456 \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--columns id,sex \
--table staff
columns 中如果涉及到多列,用逗号分隔,分隔时不要添加空格
还可以导入数据的时候先对数据进行修改再导入
(4) 使用sqoop关键字筛选查询导入数据
[root@master ~]# sqoop import \
--connect jdbc:mysql://linux01:3306/company \
--username root \
--password 123456 \
--target-dir /user/company \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by "\t" \
--table staff \
--where "id=1"
在 Sqoop 中可以使用 sqoop import -D property.name=property.value 这样的方式加入执行任务的参数,多个参数用空格隔开。
5 RDBMS导入到Hive
[root@master ~]# sqoop import \
--connect jdbc:mysql://linux01:3306/company \
--username root \
--password 123456 \
--table staff \
--num-mappers 1 \
--hive-import \
--fields-terminated-by "\t" \
--hive-overwrite \
--hive-table staff_hive
该过程分为两步,第一步将数据导入到 HDFS,默认的临时目录是/user/admin/表名,第二步将导入到 HDFS的数据迁移到 Hive 仓库。
6 Hive/HBase到RDBMS
导出使用export 命令
[root@master ~]# sqoop export \
--connect jdbc:mysql://linux01:3306/company \
--username root \
--password 123456 \
--table staff \
--num-mappers 1 \
--export-dir /user/hive/warehouse/staff_hive \
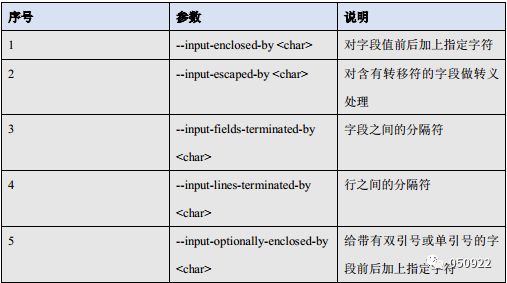
--input-fields-terminated-by "\t"
export-dir:数据存放的地址。
Mysql中如果表不存在,不会自动创建。
7 脚本打包
Hive中:hive -f xxx.sql
Sqoop也可以执行脚本文件的,使用 opt 格式的文件打包 sqoop命令,然后执行
[root@master sqoop]# cat hdfs_RDBMS.opt
export
--connect
jdbc:mysql://linux01:3306/company
--username
root
--password
123456
--table
staff
--num-mappers
1
--export-dir
/user/hive/warehouse/staff_hive
--input-fields-terminated-by
"\t"
[root@master sqoop]# sqoop --options-filehdfs_RDBMS.opt
再到数据库中查看
常用参数
数据库连接参数

Import参数


Export参数








![[机器学习]线性回归](https://img-blog.csdnimg.cn/af8e6fab43a546b8b2e6a76bf03efac0.png)