一、集合类体系结构
二、部分Collection类型对象
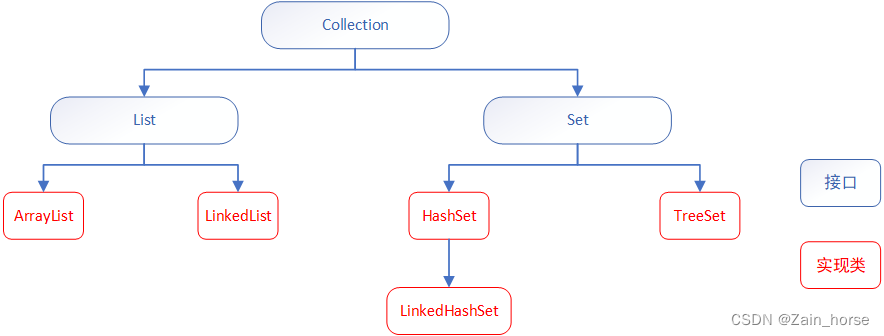
Collection集合特点
-
List系列集合是有序、可重复、有索引。
- ArrayList:有序、可重复、有索引
- LinkedList:有序、可重复、有索引
-
Set系列集合是无序、不重复、无索引。
- HashSet:无序、不重复、无索引
- LinkedHashSet:有序、不重复、无索引
- TreeSet:按照大小默认升序、不重复、无索引
约束存储数据
- 泛型约束: 集合是支持任意类型进行存储的。
- 引用类型约束: 集合不支持基本类型,但支持引用数据类型。
三、Collection常用API
| 方法 | 说明 |
|---|---|
| boolean add(E e) | 添加指定数据并返回添加结果 |
| void clear() | 清空数据 |
| boolean isEmpty() | 判断数据为空 |
| int size() | 获取集合大小 |
| boolean contains(Object o) | 判断集合是否包含某个元素 |
| boolean remove(E e) | 删除集合中某个元素默认删除第一个 |
| Object[] toArray() | 集合转对象数组 |
拓展API
| 方法 | 说明 |
|---|---|
| Collection addAll(Collection c) | 合并 |
四、Collection遍历方式
1、迭代器(Iterator)
获取迭代器
| 方法 | 说明 |
|---|---|
| Iterator iterator() | 返回迭代器对象,默认指向0索引 |
Iterator中常用方法
| 方法 | 说明 |
|---|---|
| boolean hasNext() | 询问当前位置是否有元素 |
| E next() | 获取当前元素,并向下移动,注意越界(NoSuchElementException) |
示例
/*1、创建集合对象*/
Collection<String> collection = new ArrayList<>();
collection.add("我");
collection.add("爱");
collection.add("中");
collection.add("国");
collection.add("!");
/*2、获取迭代器*/
Iterator<String> integer = collection.iterator();
/*循环遍历迭代器*/
while(integer.hasNext()){ //判断有没有值
System.out.print(integer.next()); //获取值并下移
}
/*打印结果*/
我爱中国!
2、foreach
foreach实际上是重写了迭代器进行遍历。
格式:
for(数据类型 element : 数组/集合){
循环体
}
示例
/*1、创建集合对象*/
Collection<String> collection = new ArrayList<>();
collection.add("我");
collection.add("爱");
collection.add("中");
collection.add("国");
collection.add("!");
/*2、foreach遍历*/
for (String str : collection) {
System.out.print(str);
}
/*打印结果*/
我爱中国!
3、lambda
Collection类提供了一个叫做 forEach() 的方法进行遍历,该方法采用的是匿名类进行重写。
/*1、创建集合对象*/
Collection<String> collection = new ArrayList<>();
collection.add("我");
collection.add("爱");
collection.add("中");
collection.add("国");
collection.add("!");
/*2、forEach()遍历*/
//System.out::print 是将当前元素进行引用打印
collection.forEach(System.out::print);
/*打印结果*/
我爱中国!
五、常见数据结构
概念: 数据结构是计算机底层存储、组织数据的方式,合适的数据结构能提高运行效率和存储效率。
常见结构
1、栈
特点: 后进先出,先进后出。
2、队列
特点: 先进先出,后进后出
三种队列: 单进单出队列,双进单出队列,双进双出队列
3、数组
存储特点: 一块内存连续的空间。
操作特点:
- 查询速度快: 通过地址值和索引定位。
- 删除速率低: 需要移动大量元素。
- 添加速率低: 需要移动大量元素。
4、链表
存储特点: 内存中不连续,每个节点包含数据和下一个元素地址。
操作特点:
- 查询速度慢: 因为内存不连续,所以需要遍历每一个元素。
- 删除速率高: 通过指针指向更变即可完成删除。
- 添加相对速率高: 因为查询慢,所以速率较低,高效添加是通过指针指向更变即可完成删除。
两种链表: 单向链表(数据+下一地址),双向链表(上一地址+数据+下一地址)
5、二叉树
存储特点: 内存不连续,每个节点包含父节点地址,左右节点地址,数据值。
结构特点:
- 只能有一个根节点,每个节点最多支持2个直接子节点。
- 节点的度: 节点拥有的子树个数,二叉树的度不大于2。
- 叶子结点: 度为0的节点,也称为终端节点。
- 高度: 叶子结点高度为1,叶子结点的父节点高度为2,…,根节点高度最高。
- 层: 根节点在第1层,以此类推。
- 兄弟节点: 拥有共同父节点的节点互称兄弟节点。
特殊的二叉树: 二叉排序树。
6、平衡二叉树
原则: 任意节点的左右两个子树高度差不超过1,任意节点的左右两个子树都是平衡二叉树。
7、红黑树
概念: 一种自平衡的二叉排序树,1972年被称为平衡二叉B树,1978年更名为**“红黑树”**。
特点: 每一个节点可以是红或者黑,通过 “红黑规则” 进行平衡。
红黑规则
- 每个节点是红色或黑色,根节点必须是黑色。
- 如果节点没有子节点或父节点,则节点对应指针属性为Nil,这些Nil视为叶节点,叶节点是黑色。
- 如果一个节点是红色,则子节点必须是黑色。
- 每个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点。
六、List集合
特有方法:
| 方法 | 说明 |
|---|---|
| void add(int index,E element | 指定位置插入元素 |
| E remove(int index | 指定位置的元素,并返回删除元素 |
| E set(int index,E element | 修改指定位置的元素,并返回修改元素 |
| E get(int index | 获取指定位置的元素 |
List实现类的底层原理
1、ArrayList底层原理:
- 底层基于数组实现,根据索引定位元素,增删需要做大量元素的移位操作。
- 第一次创建集合并添加元素时,默认创建长度为10的数组。
- 当数组满元素时,自动扩容二分之一。
2、LinkedList底层原理
- 基于双链表实现,查询速度慢,增删首尾元素快(最适合实现栈与队列结构)。
- 独有方法
| 方法 | 说明 |
|---|---|
| void addFirst(E e) | 首位插入指定元素 |
| void addLast(E e) | 末位插入指定元素 |
| E getFirst() | 获取首位元素 |
| E getLast() | 获取末位元素 |
| E removeFirst() | 删除首位元素 |
| E removeLast() | 删除末位元素 |
| E push() | 压栈/入栈 |
| E pop() | 弹栈/出栈 |
| E offerLast() | 入队 |
| E offerFrist() | 出队 |
补充知识
1、集合的并发修改异常
问题的出现: 当我们从集合中查找某个元素并删除时,可能会出现并发修改异常。
问题出现的原因: 当我们在循环遍历时,因为索引改变而产生跳跃查询的情况。
解决方案:
- 使用迭代器遍历,删除方法使用迭代器删除方法 iterator.remove(); 删除当前元素并不下移。(推荐使用)
- 使用倒着for循环。
2、深入泛型
(1)泛型定义的位置
- 类的后面。【class ArrayList】
- 方法声明。【public void get(T t)】
- 接口声明。【interface Collection】
(2)自定义泛型类
- 格式: 【修饰符 class 类名<泛型变量> { … }】
public class MyArrayList<T>{ }
- 泛型变量标识
常见标识:T、E、T、K、V
-
作用: 编译阶段指定数据类型。
-
原理: 出现泛型变量的地方全部替换成传输的真实数据类型。
-
示例
class Main{
public static void main(String[] args) {
MyArrayList<String> mal = new MyArrayList<>();
mal.add("String");
}
}
public class MyArrayList<E> {
public void add(E element){
}
public void remove(E element){
}
}
(3)自定义泛型方法
- 概念: 定义方法时同时定义泛型的方法。
- 格式:
修饰符 <泛型变量> 返回值 方法名称(参数列表){ ... }
- 作用: 方法中可以使用泛型接收一切实际类型的参数,方法更具备通用性。
- 示例:
class Main{
public static void main(String[] args) {
String[] names = {"x1","x2","x3"};
printArray(names);
System.out.println("——————————");
Integer[] ages = {10,11,12};
printArray(ages);
}
public static <T> void printArray(T[] arr){
StringBuilder builder = new StringBuilder("[");
Iterator<T> iterator = Arrays.stream(arr).iterator();
while(iterator.hasNext()){
builder.append(iterator.next());
builder.append(iterator.hasNext()?", ":"");
}
builder.append("]");
System.out.println(builder.toString());
}
}
/*输出结果*/
[x1, x2, x3]
——————————
[10, 11, 12]
(4)自定义泛型接口
- 概念: 使用泛型定义的接口。
- 格式:
修饰符 interface 接口名称<泛型变量>{ }
- 作用: 泛型接口让实现类选择当前功能需要操作的数据类型。
- 示例:
interface Info<E>{
void add(E element);
void removeByID(int id);
E queryByID(int id);
void update(int id,E element);
}
class Student implements Info<Student>{
@Override
public void add(Student element) {
}
@Override
public void removeByID(int id) {
}
@Override
public Student queryByID(int id) {
return null;
}
@Override
public void update(int id, Student element) {
}
}
(5)通配符:?
- 概念: ?可以在“使用泛型”时代表一切类型,而E,T,K,V在定义泛型时使用。
- 泛型的上下限:
【? extends Car】?必须是Car或者其子类,表示泛型上限
【? super Car】?必须是Car或者其父类,表示泛型下限 - 示例
/**
*使用场景:当我们需要传入多类型的引用集合时使用
*/
/*? extends Car使用*/
/*1、创建Car类以及子类*/
class Car{}
class BMW extends Car{}
class BENZ extends Car{}
/*2、运行方法,这里的<? extends Car>表示引用类型是Car或是其子类*/
public static void go(ArrayList<? extends Car> cars){}
/*3、使用方法*/
public static void main(String[] args){
ArrayList<BMW> bmw = new ArrayList<>();
bmw.add(new BMW());
bmw.add(new BMW());
bmw.add(new BMW());
ArrayList<BENZ> benzs= new ArrayList<>();
benzs.add(new BENZ());
benzs.add(new BENZ());
benzs.add(new BENZ());
go(bmw);
go(benzs);
}
七、Set集合体系
体系特点
- 无序: 存取顺序不一致
- 不重复: 可以去重
- 无索引: 没有带索引的方法
实现类特点
- HashSet: 无序、不重复、无索引
- LinkedHashSet: 有序、不重复、无索引
- TreeSet: 排序、不重复、无索引
实现类详情
1、HashSet
(1)元素无序的底层原理:哈希表
hash表的概念: 是一种对于增删改查数据性能较好的结构。
hash表的组成: JDK8之前使用数组+链表组成;JDK8之后使用数组+链表+红黑树
JDK7版本的HashSet的底层原理解析:数组+链表+Hash算法
- 1、优先创建一个默认长度为16,默认加载扩容因子为0.75的数组的数组,数组名table。
- 2、根据hash值跟数组长度求余计算存入位置(Hash算法)。
- 3、当发生冲突时调用equals()比较。若已知则不存;若不一致则存储数组。
- JDK7新元素占据老元素的位置,再将老元素挂载到新元素节点上。
- JDK8新元素直接挂载到老元素节点上。
- 4、当数组存满到16*0.75=12时,就自动扩容,每次扩容原先的两倍。
JDK8版本的HashSet原理解析:数组+链表+红黑树
两者区别在于由于当挂载链表长度超过8时,自动转换成红黑树。
(2)要理解hash表,必须先理解hash值。
hash值的概念: 是JDK根据对象的地址,按照某种自定义或预设规则计算的int类型数值。
获取hash值的方法: Object类API【int hashCode();】-> 返回对象的hash值
对象hash值特点
- 同一个对象多次调用hashCode()返回相同的hash值。
- 默认情况下,不同对象的hash值不同。
示例
/*1、创建对象获取hash值*/
String str = "石头人";
System.out.println(str.hashCode());
String integerV = "李雷";
System.out.println(integerV.hashCode());
/*打印结果*/
30237497
858473
(3)HashSet去重底层原理: Hash算法一致节点挂载。
注意: 当我们需要去重对象集合时,需要在对象中重写hashCode()以及equals()
重写的hashCode()和equals
@Override
public boolean equals(Object o){
if(this == o) return true; //判断是否为当前对象
if(o == null || getClass() != o.getClass()) return true; //判断空值以及对象类型是否相同。
类型 变量名 = (类型)o;
return 属性比较 && Objects.equals(xx,o.xx)。
}
@Override
public int hashCode(){
return Objects.hash(你比较的参数列表);
}
2、LinkedHashSet
(1)特点:有序、不重复、无索引
(2)有序特性:保证存储和取出的元素顺序一致。
(3)存储结构:Hash表
(4)有序原理:数据依次进入,每一个数据都会与前一个数据建立双向链表机制记录顺序。
3、TreeSet集合
(1)特点:可排序、不重复、无索引
(2)可排序特性:按照元素大小默认升序排列。
(3)存储结构:红黑树
(4)默认排序规则:
- 数值类型: Integer,Double,官方默认按照大小升序排序。
- 字符串类型: 默认按照首字符的ASCII码升序排序。
- 自定义类型: 采用自定义排序规则。
(5)示例
/*数值类型排序*/
Set<Integer> integerSet = new TreeSet<>();
integerSet.add(3);
integerSet.add(1);
integerSet.add(6);
integerSet.add(8);
integerSet.add(0);
integerSet.add(2);
System.out.println(integerSet);
/*字符串类型排序*/
Set<String> stringSet = new TreeSet<>();
stringSet.add("Java");
stringSet.add("MySQL");
stringSet.add("PHP");
stringSet.add("C++");
stringSet.add("Golang");
stringSet.add("JavaScript");
System.out.println(stringSet);
/*打印结果*/
[0, 1, 2, 3, 6, 8]
[C++, Golang, Java, JavaScript, MySQL, PHP]
/*自定义类型排序*/
//方法一:Comparable接口重写compareTo()
public class AppleTemp {
public static void main(String[] args) {
Set<Apple> set = new TreeSet<>();
set.add(new Apple("绿苹果",82.2,50));
set.add(new Apple("黄苹果",54.1,20));
set.add(new Apple("金苹果",10.2,11));
set.add(new Apple("青苹果",100.0,1));
System.out.println(set);
}
}
class Apple implements Comparable<Apple>{
private String name;
private double weight;
private int count;
public Apple() {
}
public Apple(String name, double weight, int count) {
this.name = name;
this.weight = weight;
this.count = count;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getWeight() {
return weight;
}
public void setWeight(double weight) {
this.weight = weight;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
@Override
public int compareTo(Apple o) {
return this.getName().compareTo(o.getName());
}
@Override
public String toString() {
return "Apple{" +
"name='" + name + '\'' +
", weight=" + weight +
", count=" + count +
'}';
}
}
//方法二:TreeSet集合有参构造器,设置Comparator接口对应的比较器对象。(优先使用)
public class AppleTemp {
public static void main(String[] args) {
Set<Apple> set = new TreeSet<>(Comparator.comparing(Apple::getName));
set.add(new Apple("绿苹果",82.2,50));
set.add(new Apple("黄苹果",54.1,20));
set.add(new Apple("金苹果",10.2,11));
set.add(new Apple("青苹果",100.0,1));
System.out.println(set);
}
}
class Apple{
private String name;
private double weight;
private int count;
public Apple() {
}
public Apple(String name, double weight, int count) {
this.name = name;
this.weight = weight;
this.count = count;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getWeight() {
return weight;
}
public void setWeight(double weight) {
this.weight = weight;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
@Override
public String toString() {
return "Apple{" +
"name='" + name + '\'' +
", weight=" + weight +
", count=" + count +
'}';
}
}
/*打印结果*/
[Apple{name='绿苹果', weight=82.2, count=50}, Apple{name='金苹果', weight=10.2, count=11}, Apple{name='青苹果', weight=100.0, count=1}, Apple{name='黄苹果', weight=54.1, count=20}]
补充知识
1、可变参数
概念: 可变参数用在形参中接收多个数据。
格式:
/*数据类型... 参数名称*/
public static void sum(int... num);
作用:
- 1、传输参数灵活方便。可以不传参,也可以传输1个或者多个,也可以传输一个数组。
- 2、可变参数在方法内部按照数组进行使用。
注意事项
- 1、 一个形参列表中可变参数只能有一个。
- 2、可变参数必须放在形参列表的最后。
2、Collections操作类
概念: java.utils.Collections是集合工具类
常用API
| 方法 | 说明 |
|---|---|
| static boolean addAll(Collection<? super T> c,T… elements) | 批量添加元素 |
| static void shuffle(List<?> list) | 打乱集合顺序 |
| static void sort(List<?> list) | 集合排序 |
| static void sort(List list,Comparator<? super T> c) | 按指定规则排序 |