前言
代码上的优化达到一定程度,再想提高系统的性能就很难了,这时候,优秀的程序猿往往会从JVM入手来进行系统的优化。但话说回来,JVM方面的优化也是比较危险的,如果单单从测试服务器来优化JVM是没有太大的意义的,不同的服务器即使环境相同,访问流量方面也是不一样的,所以,一般的JVM调优都是真生产环境,就要承担不可预测的风险,所以JVM调优也不是说谁都能做的,往往都需要前期各部门配合进行大讨论,之后才会开始实践,同时做好各种风险的评估和补救措施,下面,博主就从几个维度跟大家讲讲JVM调优的那些事。
JVM
JVM优化的原因
如上面所言,JVM调优一定是在系统性能无法通过代码提升的情况下发生的,否则,大多数开发者是绝对不会闲着没事去作这种吃力不讨好的死,当系统达到一定的瓶颈,会出现系统卡住,日志不输出,负载升高异常之类的问题,各种分析之后也无法从代码上得到有效的解决,有经验的程序猿就知道,一定是JVM一些参数的设置有问题,但参数的设置也不是说每一家公司都用一摸一样的参数,需要根据自己的系统的一些情况进行分析,得到一个相对合适的值。
这就很难了,可能大部分人开发多年,还不太清楚JVM参数具体有哪些,博主和大家一样,抛开这部分博客内容,谁去看那些带有默认值的系统参数呢?但是今天,我们必须去了解这些参数,只是因为当我们不得不去做的时候,给大家一个可能有用的教程,让大家尽可能的去优化自己的JVM。
JVM的运行参数有哪些
说起来JVM的参数,那可是太多了,简直有些烦了,但你要知道,并不是所有的参数都适合我们自己去调优的,知道了这些,你就耐着性子继续看下去吧。
JVM参数大致分为三种:
- 标准参数
- -X参数(非标准参数)
- -XX参数(也算是非标准的参数,此类参数使用较为频繁)
标准参数
查看标准参数很简单,我们在一个java工程中打开命令行工具:

输入:
java -help
Codeliu@bogon cache % java -help
用法: java [-options] class [args...]
(执行类)
或 java [-options] -jar jarfile [args...]
(执行 jar 文件)
其中选项包括:
-d32 使用 32 位数据模型 (如果可用)
-d64 使用 64 位数据模型 (如果可用)
-server 选择 "server" VM
默认 VM 是 server,
因为您是在服务器类计算机上运行。
-cp <目录和 zip/jar 文件的类搜索路径>
-classpath <目录和 zip/jar 文件的类搜索路径>
用 : 分隔的目录, JAR 档案
和 ZIP 档案列表, 用于搜索类文件。
-D<名称>=<值>
设置系统属性
-verbose:[class|gc|jni]
启用详细输出
-version 输出产品版本并退出
-version:<值>
警告: 此功能已过时, 将在
未来发行版中删除。
需要指定的版本才能运行
-showversion 输出产品版本并继续
-jre-restrict-search | -no-jre-restrict-search
警告: 此功能已过时, 将在
未来发行版中删除。
在版本搜索中包括/排除用户专用 JRE
-? -help 输出此帮助消息
-X 输出非标准选项的帮助
-ea[:<packagename>...|:<classname>]
-enableassertions[:<packagename>...|:<classname>]
按指定的粒度启用断言
-da[:<packagename>...|:<classname>]
-disableassertions[:<packagename>...|:<classname>]
禁用具有指定粒度的断言
-esa | -enablesystemassertions
启用系统断言
-dsa | -disablesystemassertions
禁用系统断言
-agentlib:<libname>[=<选项>]
加载本机代理库 <libname>, 例如 -agentlib:hprof
另请参阅 -agentlib:jdwp=help 和 -agentlib:hprof=help
-agentpath:<pathname>[=<选项>]
按完整路径名加载本机代理库
-javaagent:<jarpath>[=<选项>]
加载 Java 编程语言代理, 请参阅 java.lang.instrument
-splash:<imagepath>
使用指定的图像显示启动屏幕
有关详细信息, 请参阅 http://www.oracle.com/technetwork/java/javase/documentation/index.html。
咔咔咔一顿输出,我们现在来试试输出的这些命令,比如:
java -version输出:

我们甚至还可以通过-D设置系统属性参数,虽然博主觉得似乎实际中用处不是很大,不过还是给大家提一嘴。
首先我们新建一个简单的类:
package com.codingfire.cache;
import java.util.Arrays;
public class JVMTest {
public static void main(String[] args) {
String str = System.getProperty("str");
if (str == null) {
System.out.println("CodingFire");
} else {
System.out.println(str);
}
}
}
我们来操作下:

编译:
javac JVMTest.java 执行:
java com.codingfire.cache.JVMTest修改参数:
java -Dstr=libai com.codingfire.cache.JVMTest这里要注意几点,windows我不知道,但是mac下要编译java文件,需要进入到文件所在目录,运行主类文件的时候,需要在java目录下,运行路径要包括包名,图中已经圈出,给大家避坑。
这就是JVM标准参数的一些小用法,根据博主的经验,用处不大,大概知道就行,真用到了去查也来得及。
哦,对了,最后有两个稍微重要的参数还需要提一下:-server和-client
server VM初始堆空间大,默认使用并行垃圾收集器,启动慢,运行快
client VM初始堆空间小,默认使用穿行垃圾收集器,启动快,运行慢
但是,64位系统下,只有server VM可以选,不支持client VM,所以32位系统下博主就不说了,没意义,现在哪还有32位的?所以,没得选,提一嘴知道怎么回事就行。
-X参数
Codeliu@bogon java % java -X
-Xmixed 混合模式执行 (默认)
-Xint 仅解释模式执行
-Xbootclasspath:<用 : 分隔的目录和 zip/jar 文件>
设置搜索路径以引导类和资源
-Xbootclasspath/a:<用 : 分隔的目录和 zip/jar 文件>
附加在引导类路径末尾
-Xbootclasspath/p:<用 : 分隔的目录和 zip/jar 文件>
置于引导类路径之前
-Xdiag 显示附加诊断消息
-Xnoclassgc 禁用类垃圾收集
-Xincgc 启用增量垃圾收集
-Xloggc:<file> 将 GC 状态记录在文件中 (带时间戳)
-Xbatch 禁用后台编译
-Xms<size> 设置初始 Java 堆大小
-Xmx<size> 设置最大 Java 堆大小
-Xss<size> 设置 Java 线程堆栈大小
-Xprof 输出 cpu 配置文件数据
-Xfuture 启用最严格的检查, 预期将来的默认值
-Xrs 减少 Java/VM 对操作系统信号的使用 (请参阅文档)
-Xcheck:jni 对 JNI 函数执行其他检查
-Xshare:off 不尝试使用共享类数据
-Xshare:auto 在可能的情况下使用共享类数据 (默认)
-Xshare:on 要求使用共享类数据, 否则将失败。
-XshowSettings 显示所有设置并继续
-XshowSettings:all
显示所有设置并继续
-XshowSettings:vm 显示所有与 vm 相关的设置并继续
-XshowSettings:properties
显示所有属性设置并继续
-XshowSettings:locale
显示所有与区域设置相关的设置并继续
-X 选项是非标准选项, 如有更改, 恕不另行通知。
以下选项为 Mac OS X 特定的选项:
-XstartOnFirstThread
在第一个 (AppKit) 线程上运行 main() 方法
-Xdock:name=<应用程序名称>"
覆盖停靠栏中显示的默认应用程序名称
-Xdock:icon=<图标文件的路径>
覆盖停靠栏中显示的默认图标
java -X以下就出来了,但是不同的jvm,参数路有差异。
比较重要的参数有俩:
-Xms和-Xmx,分别是设置jvm堆内存的初始内存和最大内存,比如-Xms512m活着-Xmx2048m。
也可以通过-X来给运行的程序设置参数:
Codeliu@bogon java % java -Xms512m -Xmx2048m com.codingfire.cache.JVMTest CodingFire
适当调整,可以很好的利用系统资源,提高效率。
-XX参数
-XX是非标准参数,用于JVM调优和debug操作,有两种使用方式,一种是boolean类型,一种是非boolean类型:
- boolean类型
- 格式:-XX:[+-]<name> 表示启用或禁用<name>属性
- 如:-XX:+DisableExplicitGC 表示禁用手动调用gc操作,也就是说调用System.gc()无效
- 非boolean类型
- 格式:-XX:<name>=<value> 表示<name>属性的值为<value>
- 如:-XX:NewRatio=1 表示新生代和老年代的比值
举个例子:

要查看-XX参数,需要运行java命令时打印参数,并添加-XX:+PrintFlagsFinal参数,参数比较多,电脑都开始卡了,删了一大半,大家看看就行,主要是知道里面基本上都是boolean类型和数字类型:
Codeliu@bogon java % java -XX:+PrintFlagsFinal -version
[Global flags]
intx ActiveProcessorCount = -1 {product}
uintx AdaptiveSizeDecrementScaleFactor = 4 {product}
uintx AdaptiveSizeMajorGCDecayTimeScale = 10 {product}
uintx AdaptiveSizePausePolicy = 0 {product}
uintx AdaptiveSizePolicyCollectionCostMargin = 50 {product}
uintx AdaptiveSizePolicyInitializingSteps = 20 {product}
uintx AdaptiveSizePolicyOutputInterval = 0 {product}
uintx AdaptiveSizePolicyWeight = 10 {product}
uintx AdaptiveSizeThroughPutPolicy = 0 {product}
uintx AdaptiveTimeWeight = 25 {product}
bool AdjustConcurrency = false {product}
bool AggressiveHeap = false {product}
bool AggressiveOpts = false {product}
intx AliasLevel = 3 {C2 product}
bool AlignVector = false {C2 product}
intx AllocateInstancePrefetchLines = 1 {product}
intx AllocatePrefetchDistance = 192 {product}
intx AllocatePrefetchInstr = 0 {product}
intx AllocatePrefetchLines = 4 {product}
intx AllocatePrefetchStepSize = 64 {product}
intx AllocatePrefetchStyle = 1 {product}
bool AllowJNIEnvProxy = false {product}
bool AllowNonVirtualCalls = false {product}
bool AllowParallelDefineClass = false {product}
bool AllowUserSignalHandlers = false {product}
bool AlwaysActAsServerClassMachine = false {product}
bool AlwaysCompileLoopMethods = false {product}
bool AlwaysLockClassLoader = false {product}
bool AlwaysPreTouch = false {product}
bool AlwaysRestoreFPU = false {product}
bool AlwaysTenure = false {product}
bool AssertOnSuspendWaitFailure = false {product}
bool AssumeMP = false {product}
bool UseSSE42Intrinsics = true {product}
bool UseSerialGC = false {product}
bool UseSharedSpaces = false {product}
bool UseSignalChaining = true {product}
bool UseSquareToLenIntrinsic = true {C2 product}
bool UseStoreImmI16 = false {ARCH product}
bool UseStringDeduplication = false {product}
bool UseSuperWord = true {C2 product}
bool UseTLAB = true {pd product}
bool UseThreadPriorities = true {pd product}
bool UseTypeProfile = true {product}
bool UseTypeSpeculation = true {C2 product}
bool UseUnalignedLoadStores = true {ARCH product}
bool UseVMInterruptibleIO = false {product}
bool UseXMMForArrayCopy = true {product}
bool UseXmmI2D = false {ARCH product}
bool UseXmmI2F = false {ARCH product}
bool UseXmmLoadAndClearUpper = true {ARCH product}
bool UseXmmRegToRegMoveAll = true {ARCH product}
bool VMThreadHintNoPreempt = false {product}
intx VMThreadPriority = -1 {product}
intx VMThreadStackSize = 1024 {pd product}
intx ValueMapInitialSize = 11 {C1 product}
intx ValueMapMaxLoopSize = 8 {C1 product}
intx ValueSearchLimit = 1000 {C2 product}
bool VerifyMergedCPBytecodes = true {product}
bool VerifySharedSpaces = false {product}
intx WorkAroundNPTLTimedWaitHang = 1 {product}
uintx YoungGenerationSizeIncrement = 20 {product}
uintx YoungGenerationSizeSupplement = 80 {product}
uintx YoungGenerationSizeSupplementDecay = 8 {product}
uintx YoungPLABSize = 4096 {product}
bool ZeroTLAB = false {product}
intx hashCode = 5 {product}
java version "1.8.0_201"
Java(TM) SE Runtime Environment (build 1.8.0_201-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)
还有,=代表默认值,:=代表修改后的值,这里没有修改过,所以没有,但大家要知道。
要想查看运行中的JVM参数,首先要运行起来一个工程,接着在命令行工具内:
#通过jps 或者 jps -l 查看java进程
Codeliu@bogon java % jps
53700 RemoteMavenServer36
62645 Jps
51542
62634 WorkStealingPoolDemo
Codeliu@bogon java % jinfo -flags 62634
Attaching to process ID 62634, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.101-b13
Non-default VM flags: -XX:CICompilerCount=3 -XX:InitialHeapSize=134217728 -XX:MaxHeapSize=2147483648 -XX:MaxNewSize=715653120 -XX:MinHeapDeltaBytes=524288 -XX:NewSize=44564480 -XX:OldSize=89653248 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseFastUnorderedTimeStamps -XX:+UseParallelGC
Command line: -Dfile.encoding=UTF-8
#查看某一参数的值,用法:jinfo -flag <参数名> <进程id>
Codeliu@bogon java % jinfo -flag MaxHeapSize 62634
-XX:MaxHeapSize=2147483648
此处我们查看的正是刚刚跑起来的工程的进程id:
这一块内容博主没有办法跟你说具体要改多少数值,要根据自己的系统来考虑,博主主要是带着大家了解这些参数和如何操作。
JVM内存模型
JVM的内存模型,我们针对JDK7和JDK8做个说明。
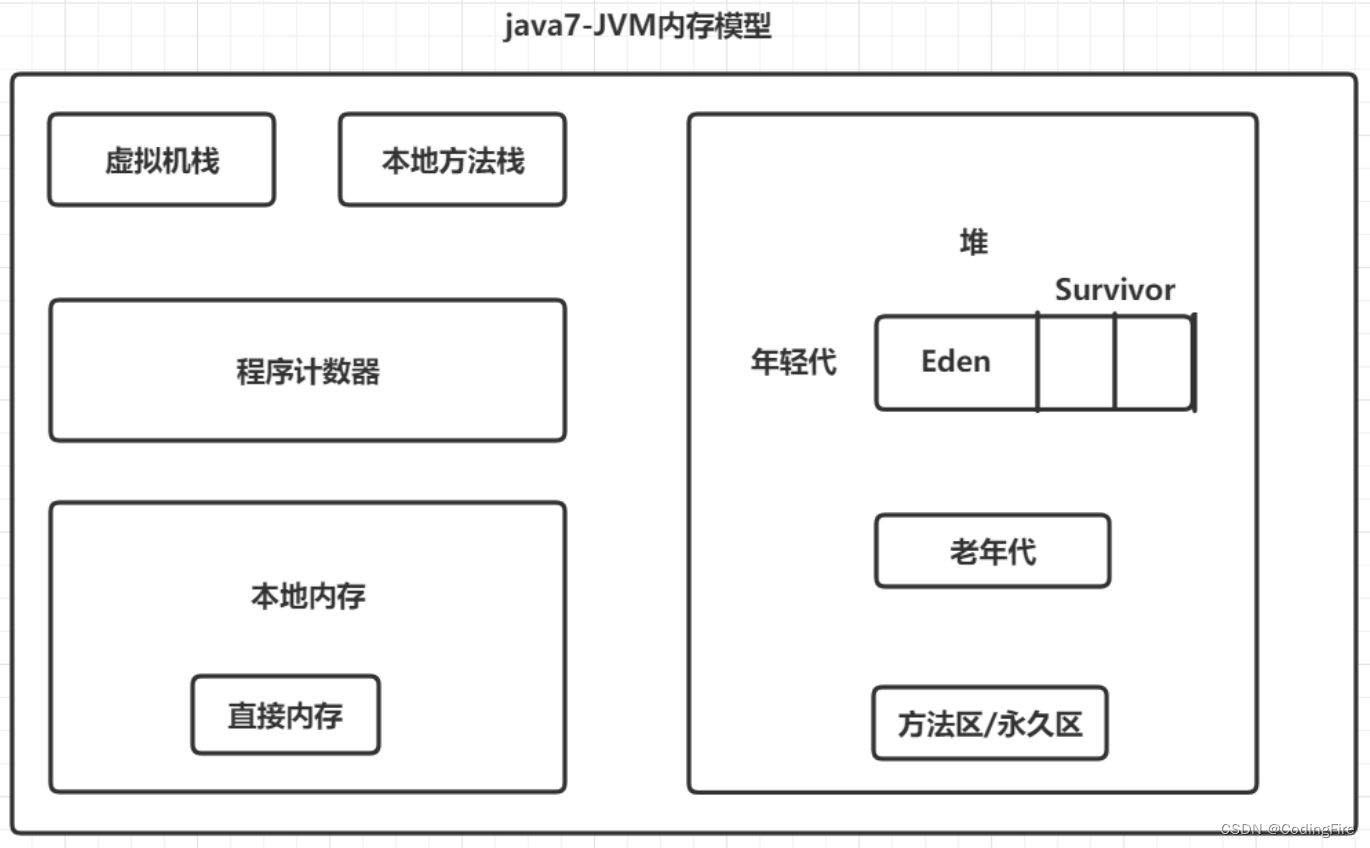
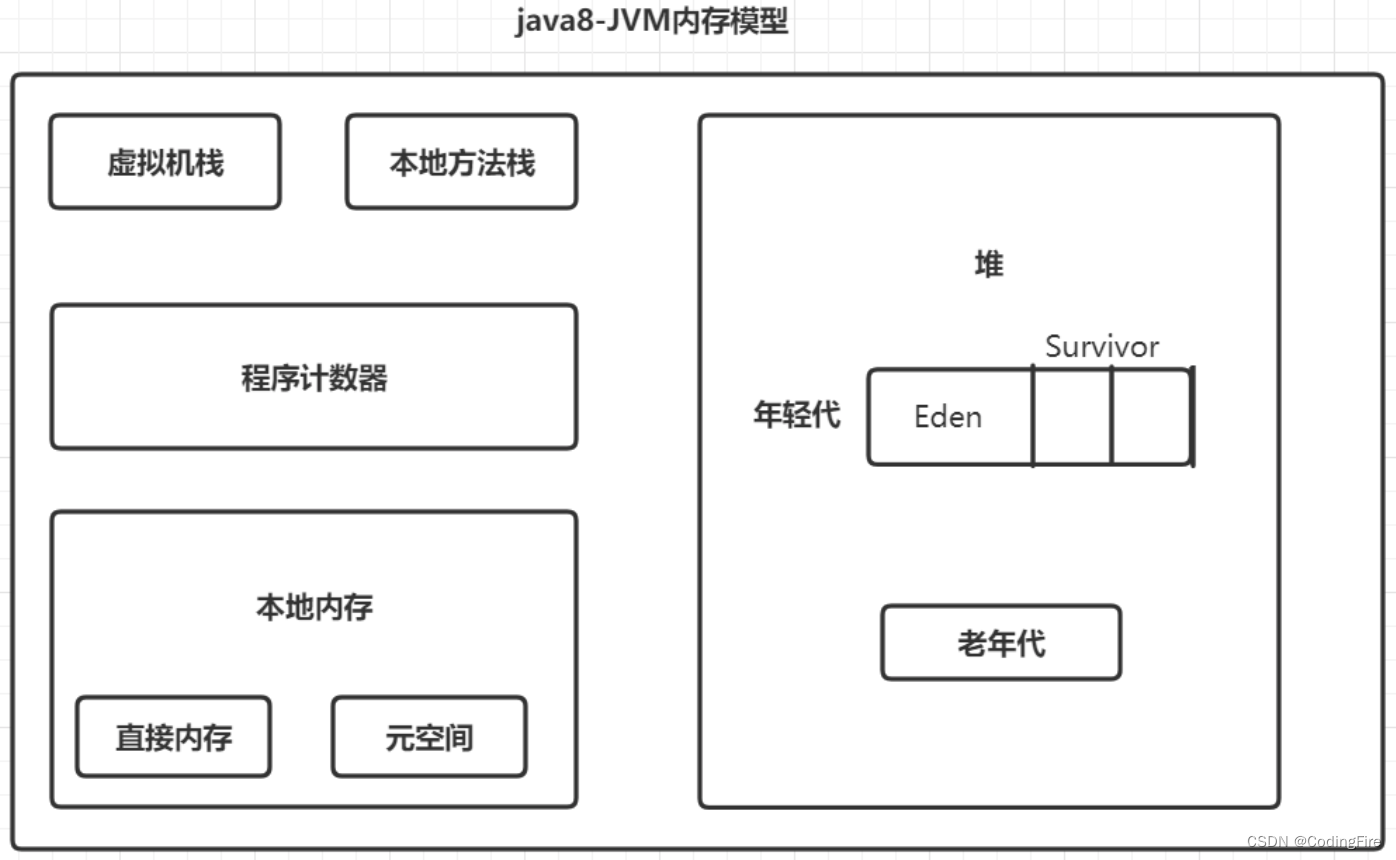
懒得自己画了,借了俩图,基本上大家画的都是这样的结构,知识对于内部的说明略微有些出入。
虚拟机栈:这是线程私有的,生命周期与线程相同的,保存执行方法时的局部变量、动态连接信息(其实就是调用其他方法)、方法返回信息等等。方法开始执行的时候会进栈,方法执行完会出栈,不需要进行GC。
本地方法栈:本地方法栈(Native Method Stacks)与虚拟机栈所发挥的作用是非常相似的,其区别只是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则是为虚拟机使用到的本地(Native)方法服务。
程序计数器:这是线程私有的,内部保存的字节码的行号,如果线程挂起,随后继续执行,这就是找到执行位置的有利手段。
本地内存/直接内存:本地内存又叫做堆外内存,是线程共享的区域,不受JVM的控制,所以也不会发生GC,它是一块物理内存,专门用于JVM和IO设备打交道,Java底层使用C语言的API调用操作系统与IO设备进行交互。因此对于整个java的执行效率的提升非常大。
堆:线程共享的区域,主要用来保存对象实例,数组等,如果堆中没有内存空间可分配给实例,也无法再扩展时,会抛出OOM异常。
年轻代:它被划分为三部分,Eden区和两个大小相同的Survivor区,在同一时间,只有其中一个被使用,另外一个留做垃圾收集时复制对象用,这就是复制算法。当Eden区满的时候, GC就会将存活的对象移到空的Survivor区中,当第二次满时,会把Eden和Survivor中存活的对象转移到另一个Survivor区中,然后清空第一次的Survivor区,如此往复循环,每一次进入一个Uurvivor区时,对象的年龄就+1,当15岁时,进入老年代。如果对象创建时非常大,则直接进入老年代。
老年代:主要保存生命周期长的对象,一般是一些老的对象和一些年轻代升上来的对象。
永久带: 用于保存类信息、静态变量、常量、编译后的代码,在java7中堆上方法区会受到GC的管理的,它有大小的限制,如果大量的动态生成类,就会放入到永久代,但很容易造成OOM。所以在Java8中,这块区域被放在了本地内存中,叫做元空间,元空间的内存很大,所以可以避免OOM。
最后说说为什么废除永久带:
This is part of the JRockit and Hotspot convergence effort. JRockit customers do not need to configure the permanent generation (since JRockit does not have a permanent generation) and are accustomed to not configuring the permanent generation.
移除永久代是为融合HotSpot JVM与 JRockit VM而做出的努力,因为JRockit没有永久代,不需要配置永久代。
一个是HotSpot JVM与 JRockit VM合二为一,另一个是堆上的内存还是有限制的,防止内存溢出。
JVM内存分析方式
查看类加载情况
Codeliu@bogon java % jps
51542
63079 Jps
62634 WorkStealingPoolDemo
Codeliu@bogon java % jstat -class 62634
Loaded Bytes Unloaded Bytes Time
548 1114.5 0 0.0 0.13
参数说明:
- Loaded:加载class的数量
- Bytes:所占用空间大小
- Unloaded:未加载数量
- Bytes:未加载占用空间
- Time:加载所用时间
查看编译情况
Codeliu@bogon java % jstat -compiler 62634
Compiled Failed Invalid Time FailedType FailedMethod
87 0 0 0.05 0 参数说明:
- Compiled:编译数量。
- Failed:失败数量
- Invalid:不可用数量
- Time:时间
- FailedType:失败类型
- FailedMethod:失败的方法
查看gc情况
Codeliu@bogon java % jstat -gc 62634
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
5120.0 5120.0 0.0 0.0 33280.0 6785.1 87552.0 0.0 4480.0 774.0 384.0 75.8 0 0.000 0 0.000 0.000
参数说明:
- S0C:第一个Survivor区的大小(KB)
- S1C:第二个Survivor区的大小(KB)
- S0U:第一个Survivor区的使用大小(KB)
- S1U:第二个Survivor区的使用大小(KB)
- EC:Eden区的大小(KB)
- EU:Eden区的使用大小(KB)
- OC:Old区大小(KB)
- OU:Old使用大小(KB)
- MC:方法区(元空间)大小(KB)
- MU:方法区使用大小(KB)
- CCSC:压缩类空间大小(KB)
- CCSU:压缩类空间使用大小(KB)
- YGC:年轻代垃圾回收次数
- YGCT:年轻代垃圾回收消耗时间
- FGC:老年代垃圾回收次数
- FGCT:老年代垃圾回收消耗时间
- GCT:垃圾回收消耗总时间
还可以指定打印间隔和打印次数:
#1s一次,共打印两次
Codeliu@bogon java % jstat -gc 62634 1000 2
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
5120.0 5120.0 0.0 0.0 33280.0 6785.1 87552.0 0.0 4480.0 774.0 384.0 75.8 0 0.000 0 0.000 0.000
5120.0 5120.0 0.0 0.0 33280.0 6785.1 87552.0 0.0 4480.0 774.0 384.0 75.8 0 0.000 0 0.000 0.000
查看内存使用情况
Codeliu@bogon java % jmap -heap 62634
Attaching to process ID 62634, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.101-b13
using thread-local object allocation.
Parallel GC with 4 thread(s)
#堆内存配置信息
Heap Configuration:
MinHeapFreeRatio = 0
MaxHeapFreeRatio = 100
MaxHeapSize = 2147483648 (2048.0MB)
NewSize = 44564480 (42.5MB)
MaxNewSize = 715653120 (682.5MB)
OldSize = 89653248 (85.5MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
PS Young Generation
Eden Space:
capacity = 34078720 (32.5MB)
used = 6947952 (6.6260833740234375MB)
free = 27130768 (25.873916625976562MB)
20.38794884314904% used
From Space:
capacity = 5242880 (5.0MB)
used = 0 (0.0MB)
free = 5242880 (5.0MB)
0.0% used
To Space:
capacity = 5242880 (5.0MB)
used = 0 (0.0MB)
free = 5242880 (5.0MB)
0.0% used
PS Old Generation
capacity = 89653248 (85.5MB)
used = 0 (0.0MB)
free = 89653248 (85.5MB)
0.0% used
2318 interned Strings occupying 163192 bytes.
查看对象数量和大小
#查看所有对象,包括活跃以及非活跃的
jmap -histo <pid> | more
#查看活跃对象
jmap -histo:live <pid> | more
Codeliu@bogon java % jmap -histo:live 62634 | more
num #instances #bytes class name
----------------------------------------------
1: 3576 312072 [C
2: 440 129528 [B
3: 3555 85320 java.lang.String
4: 629 71960 java.lang.Class
5: 595 36688 [Ljava.lang.Object;
6: 1 32784 [Ljava.util.concurrent.ForkJoinTask;
7: 180 11520 java.net.URL
8: 355 11360 java.util.HashMap$Node
9: 124 7160 [I
10: 124 6592 [Ljava.lang.String;
11: 127 5080 java.util.LinkedHashMap$Entry
12: 19 4976 [Ljava.util.HashMap$Node;
13: 106 4240 java.lang.ref.SoftReference
14: 256 4096 java.lang.Integer
15: 120 3840 java.util.Hashtable$Entry
16: 127 3048 java.io.ExpiringCache$Entry
17: 91 2912 java.util.concurrent.ConcurrentHashMap$Node
18: 7 2632 java.lang.Thread
19: 64 2560 java.lang.ref.Finalizer
:
对象说明:
- B byte
- C char
- D double
- F float
- I int
- J long
- Z boolean
- [ 数组,如[I表示int[]
- [L+类名 其他对象
把内存使用情况dump到文件里
Codeliu@bogon java % jmap -dump:format=b,file=/Users/Codeliu/Desktop/dump.dat 62634
Dumping heap to /Users/Codeliu/Desktop/dump.dat ...
Heap dump file created
查看桌面:

文件已经保存到指定路径了,下面我们来分析下这个文件。
通过jhat对dump文件进行分析
Codeliu@bogon java % jhat -port 10000 /Users/Codeliu/Desktop/dump.dat
Reading from /Users/Codeliu/Desktop/dump.dat...
Dump file created Fri May 26 19:31:04 CST 2023
Snapshot read, resolving...
Resolving 11498 objects...
Chasing references, expect 2 dots..
Eliminating duplicate references..
Snapshot resolved.
Started HTTP server on port 10000
Server is ready.
这时候,我们打开一个地址:localhost:10000
点击最后一个:
Execute Object Query Language (OQL) query
在输入框里输入:
#查询字符串长度大于1000的字符串
select s from java.lang.String s where s.value.length>1000
点击按钮Execute:
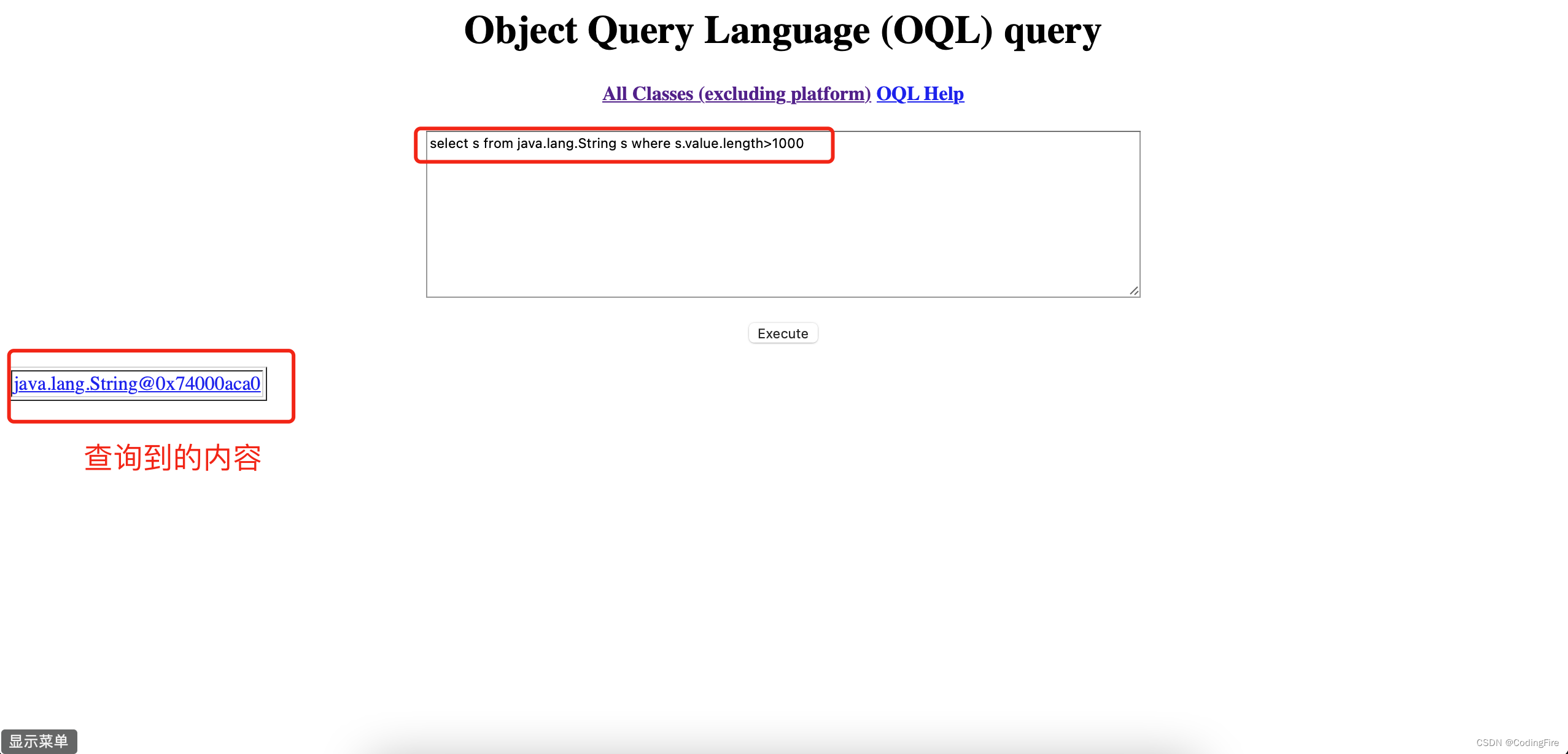
想找啥自己查吧。说白了就是一个可视化的界面,里面有我们上面查过的所有内容。
还有一个工具叫VisualVM,是jdk/bin下的一个软件,使用更简单,还能检查线程的死锁,就不介绍了,可视化界面一看就会。
垃圾回收
浅谈垃圾回收
如果一个或多个对象没有任何的引用指向它了,那么这个对象现在就是垃圾。是垃圾就要回收,这是一个常识问题。但问题是由谁回收?作为开发者,你想回收吗?我想100个开发者里应该没有一个想去管复杂的垃圾回收,那只能交给系统自己回收了。
这就是垃圾自动回收机制了,在Java中叫GC,除了Java,其他语言都有自己的垃圾回收机制,博主当年做移动端也有所接触,iOS的垃圾回收靠引用计数,Java以前也曾经使用过这种类似的方式,但由于一些原因改成了可达性分析算法,至于什么原因,咱们后面会讲到。
有了垃圾回收机制,开发者就可以专注于业务的开发,大大加快了开发的效率。但有时候,一些内存泄露的问题还是在所难免,这需要开发者日积月累的经验才能避免。下面,我们来了解下垃圾回收的相关内容和我们所能做的一些垃圾回收方面的配置。
垃圾回收的方式
引用计数
引用计数很好理解,当使用new或者对象被引用的时候,引用计数就+1,默认是0。
我们可以认为,对象就像是教室里的灯,没人时,不亮,第一个人进入,灯亮,引用计数+1,第二个人来的时候,灯依然是亮的,引用计数再+1,为2,走一个人,灯亮,引用计数-1,为1,再走一个人,引用计数-1,为0,此时没人,灯灭,代表对象被销毁,内存被回收。
之所以放弃引用计数是因为引用计数无法解决循环引用问题,所谓循环引用就是多个对象之间相互引用对方,导致内存无法回收。如下图:
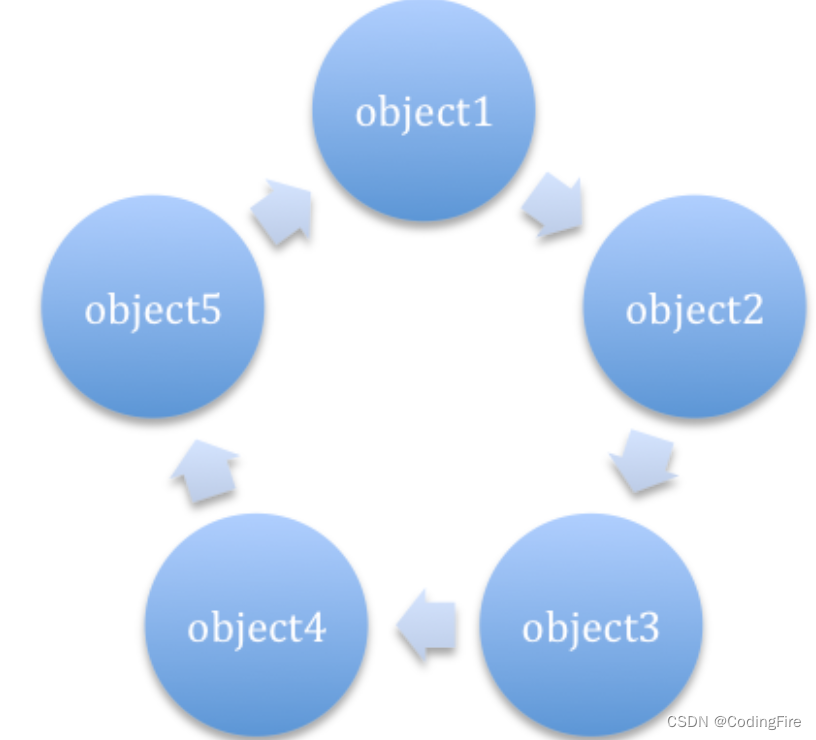
除此外,Java设计者们认为,对象被引用时,都需要去更新计数器,有时间开销 ,同时浪费CPU资源,因为即使内存够用,仍然在运行时进行计数器的统计。所以就弃用了引用计数的方式。
iOS到目前为止还在使用引用计数的方式,且业内公认,苹果的垃圾回收机制是最好的,不知道Java为什么会弃用,可能两种引用计数存在差别吧,博主没有深究过,不做过多评价。
可达性分析算法
首先来看此图:
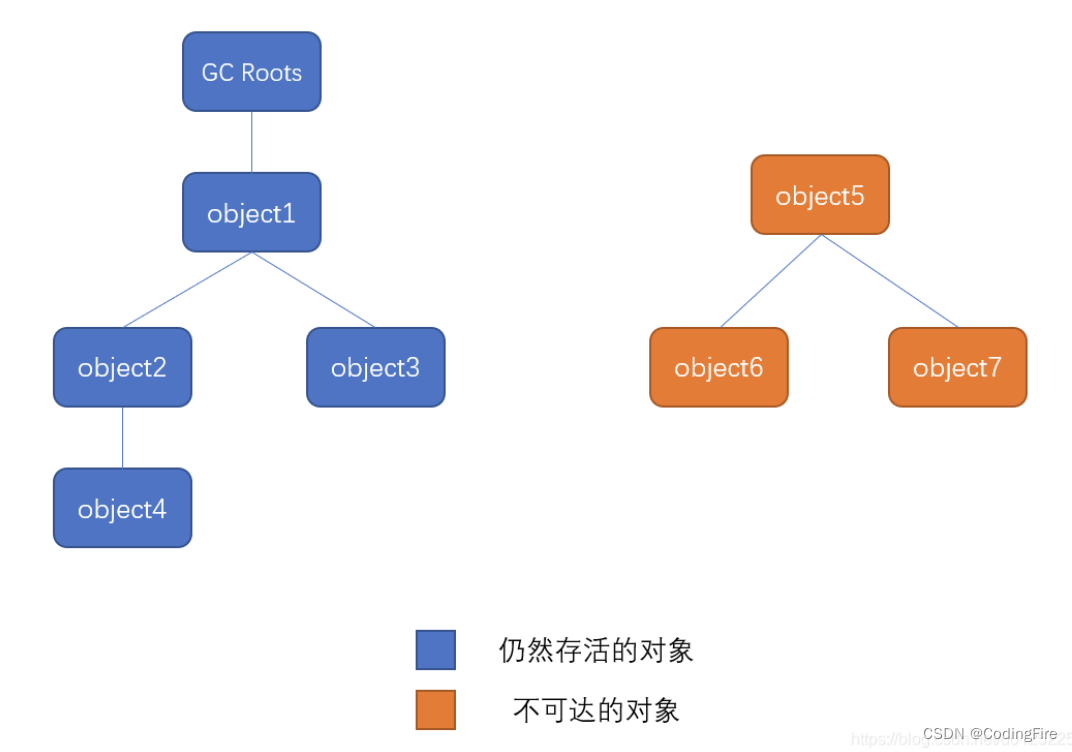
可达性分析算法会存在一个根节点【GC Roots】,它指向下一个节点,再以下一个节点节点开始找出它下面的节点,依次往下类推,直到所有的节点全部遍历完毕。 此时,不在跟节点这条链路下的对象就是不可达对象,就是需要被回收的对象了。
但并不是立即回收该对象,而是给他们一个机会,证明自己还是可达的,会执行对象的finalize方法,该方法仅可被执行一次,如果没有执行,就执行此方法,否则直接回收。
若是执行finalize方法后,能够证明该对象可达,并合根节点有了关联,就不回收,但第二次如果再被认定为不可达,就不会再执行finalize方法,将直接回收该对象。
垃圾回收的算法
标记清除算法
标记清除算法是将垃圾回收分为2个阶段,分别是标记和清除:
- 根据可达性分析算法对不可达的对象进行垃圾标记
- 对这些标记为不可达的对象进行垃圾回收


标记清楚算法在标记和清除的时候都需要遍历全部对象,且GC时,会STW(stop the world),即应用程序完全停止,这个后果大家可以自行脑补一下。另外,标记清楚算法之后的内存是不连续的,也就是碎片化的,这对内存的分配是很不利的。
复制算法
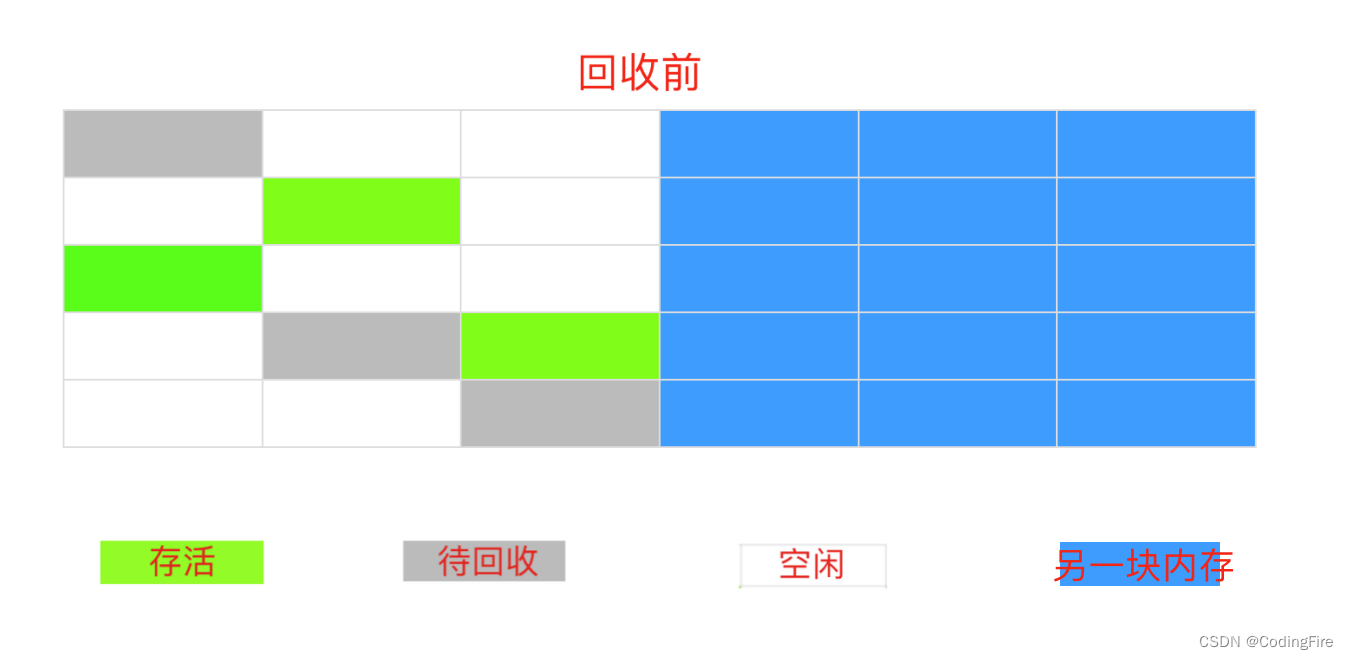
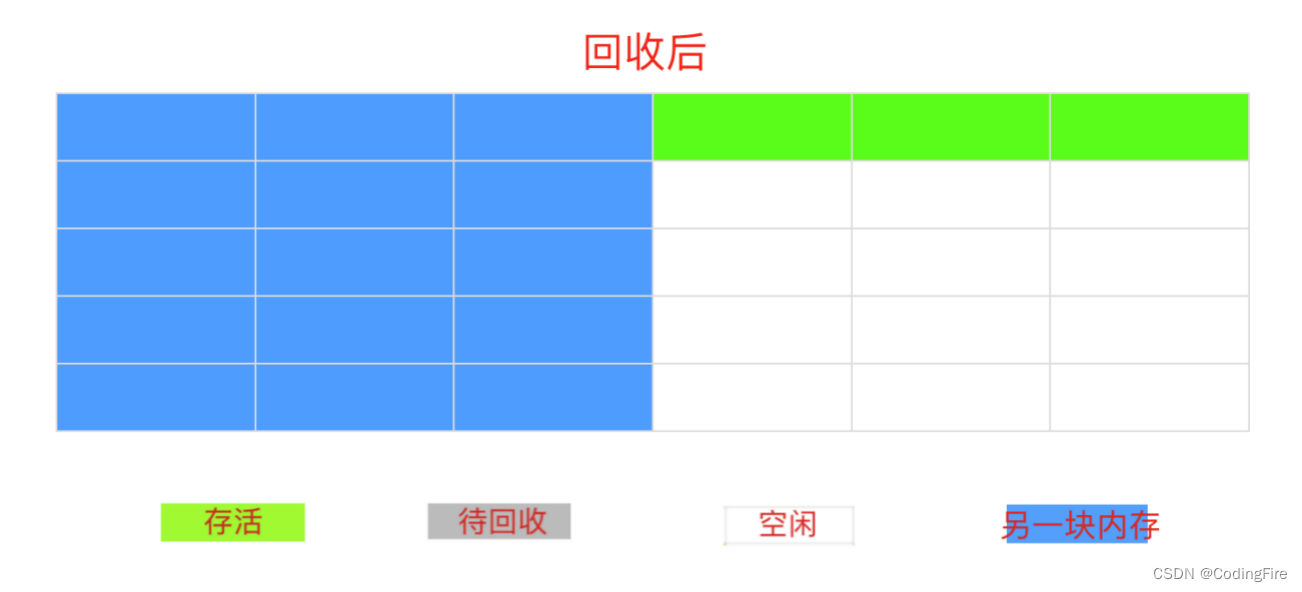 很明显,复制算法的缺点是每次只能使用一半的内存,这对内存的利用率不是很高,但并不代表它没用,年轻代用的就是这种算法。虽然每次只能使用一半内存,但是不存在碎片化,也算是一个优点。
很明显,复制算法的缺点是每次只能使用一半的内存,这对内存的利用率不是很高,但并不代表它没用,年轻代用的就是这种算法。虽然每次只能使用一半内存,但是不存在碎片化,也算是一个优点。
标记压缩算法

标记压缩算法是在标记清除算法的基础之上做了优化改进的算法。和标记清除算法一样,也是从根节点开始,对对象的引用进行标记,在清理阶段,并不是简单的直接清理可回收对象,而是将存活对象都向内存另一端移动,然后清理边界以外的垃圾,从而解决了碎片化的问题。但标记压缩算法多了一步移动内存位置的步骤,对效率也有一定的影响。
分代收集算法
分代收集算法其实说的就是年轻代+老年代,然后分E区和S0,S1区,我们在上面已经简单说过他们的工作方式,这里做下总结。
- 当创建一个对象的时候,这个对象会被分配在新生代的Eden区,当Eden区要满了时候,触发YoungGC
- YoungGC后,Eden区存活的对象被移动到S0区,并且当前对象的年龄会加1,清空Eden区
- 再一次触发YoungGC的时候,会把Eden区中存活下来的对象和S0中的对象,移动到S1区中,这些对象的年龄加1,清空Eden区和S0区
- 再再一次触发YoungGC的时候,会把Eden区中存活下来的对象和S1中的对象,移动到S0区中,这些对象的年龄加1,清空Eden区和S1区。
- 接着,周而复始
当对象的年龄达到了某一个限定的值(默认15岁,CMS默认6岁 ),这个对象就会进入到老年代,如果对象太大,也会直接进入老年代,有的地方说,如果在Survivor区中相同年龄的对象的所有大小之和超过Survivor空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代,这一点博主不是很确定正确性,会去求证。
当老年代满了之后,就触发FullGC,FullGC同时回收新生代和老年代,只有FullGC的一个线程执行,其他的线程全部被挂起。
另外,年轻代内部三个区域的大小比例为:Eden区,S0区,S1区【8:1:1】
年轻代和老年代的比例为:【1:2】
当对年轻代产生GC:MinorGC【young GC】
当对老年代产生GC:FullGC【OldGC】
以上,是在Java8之下。
吐槽
这些图真是太难搞了,全是博主用表格一个个标记出来的:

为了方便拖拽,还用上了ppt:
我太难了,用过几个画图软件,都不是很理想,小伙伴有好用的画图软件麻烦推荐下。
垃圾回收器有哪些
垃圾回收就需要拉机回收器,垃圾回收器是垃圾回收算法的载体,垃圾收集器共分为以下四大类:
- 串行垃圾收集器Serial
- 并行垃圾收集器Parallel
- CMS垃圾收集器
- G1垃圾收集器
接下来,博主就讲讲它们具体的作用。以下是新生代和老年代的搭配使用图:
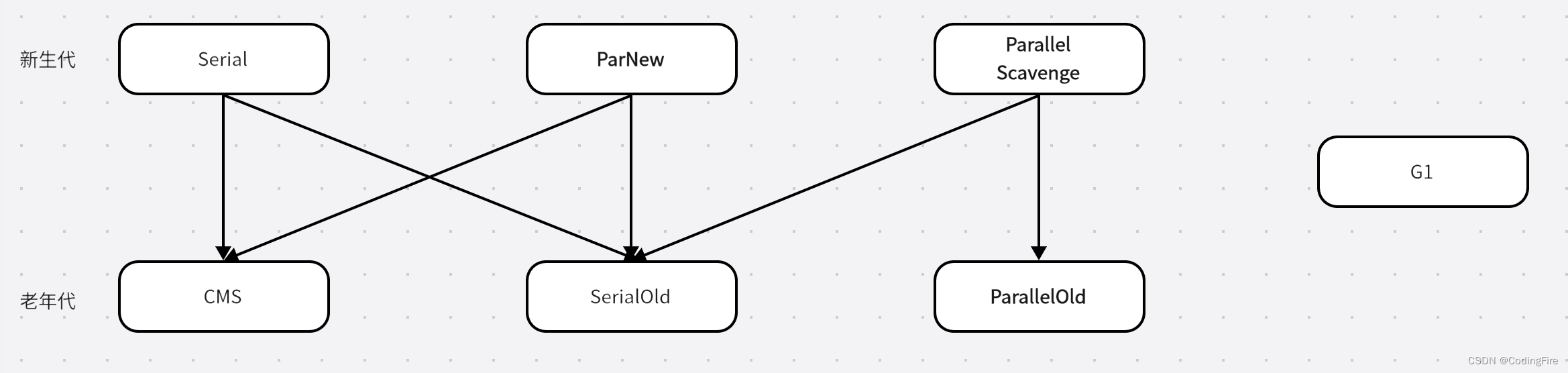
串行垃圾收集器Serial
串行垃圾收集器是用单线程进行垃圾回收的,垃圾回收时,只有一个线程在工作,此时java应用中的其他线程都要暂停,并等待垃圾回收的完成。这种现象称之为STW(Stop-The-World)前面有提到过。SerialNew应用在年轻代,SerialOld应用在老年代。
由于其单线程的性质,性能太差。所以此垃圾收集器在实战中是不太受欢迎的。
在程序运行参数中添加参数:
- -XX:+UseSerialGC
- 指定年轻代和老年代都使用串行垃圾收集器
- -XX:+PrintGCDetails
- 打印垃圾回收的详细信息
-XX:+UseSerialGC -XX:+PrintGCDetails设置是在这里:
并行垃圾收集器Parallel
并行垃圾收集器是在串行垃圾收集器的基础之上做了改进,将单线程改为了多线程进行垃圾回收,这缩短了垃圾回收的时间。
但并行垃圾收集器在收集的过程中仍会暂停应用程序,这个和串行垃圾回收器是一样的,只是并行执行的速度更快些,暂停的时间更短。
ParNew垃圾回收器作用在年轻代,其设置方式如下:
-XX:+UseParNewGC -XX:+PrintGCDetails设置后,年轻代使用ParNew回收器,老年代使用串行收集器。是否打印GC信息根据需要自行设置即可。
接着说Parallel垃圾收集器,不要把它和ParNew混为一谈。Java8默认使用此垃圾收集器。但在此基础之上新增了两个和系统吞吐量相关的参数,使得其使用起来更加的灵活和高效:
- -XX:+UseParallelGC
- 年轻代使用ParalleScavenge垃圾回收器,老年代使用串行回收器
- -XX:+UseParallelOldGC
- 年轻代使用ParallelScavenge垃圾回收器,老年代使用ParallelOldGC垃圾回收器,ParallelOldGC是ParallelScavenge收集器的老年代版本,为什么是这样大家要去上面看博主画的那个图的配合使用情况
- -XX:MaxGCPauseMillis(避免stm时间较长,会自动适当调小内存)
- 设置最大的垃圾收集时的停顿时间,单位为毫秒
- 需要注意的时,ParallelGC为了达到设置的停顿时间,可能会调整堆大小或其他的参数,如果堆的大小设置的较小,就会导致GC工作变得很频繁,反而可能会影响到性能,所以该参数使用需谨慎。
- -XX:UseAdaptiveSizePolicy
- 此为自适应GC,垃圾回收器将自动调整年轻代、老年代等参数以达到吞吐量、堆大小、停顿时间之间的平衡。用于手动调整参数比较困难的场景,让收集器自动进行调整。
设置如下:
-XX:+UseParallelGC -XX:+UseParallelOldGC -XX:MaxGCPauseMillis=100 -XX:+PrintGCDetails
CMS垃圾收集器
CMS全称 Concurrent Mark Sweep,是一款并发的、使用标记-清除算法的垃圾回收器,该回收器是针对老年代进行垃圾回收的,通过XX:+UseConcMarkSweepGC进行设置。
其最大的特点是在进行垃圾回收时,应用仍然能正常运行。主要,是回收时,其在垃圾标记过程中仍然存在STW的情况。其流程如下:
- 初始化标记(CMS-initial-mark) ,会导致stw;
- 并发标记(CMS-concurrent-mark),启动并发标记并开始标记;
- 预清理(CMS-concurrent-preclean),启动预处理并预处理;
- 重新标记(CMS-final-remark) ,最终标记,会导致stw;
- 并发清除(CMS-concurrent-sweep),启动并发清理并清理;
- 并发重置(CMS-concurrent-reset)重置CMS状态,等待下次CMS的触发;
这些可在日志中看到步骤,添加配置后,运行项目就可以输出。
-XX:+UseConcMarkSweepGC -XX:+PrintGCDetails前提是你得把堆的初始大小和最大内存设置的小一点,让他们能很快触发GC才行。
看到一篇讲的不错的CMS好文,推荐给大家:深入理解CMS GC - 简书
G1垃圾收集器
Java9之后默认使用G1垃圾收集器,它适合于堆内存较大的情况,也是适应于目前大内存的计算机,可以充分发挥大内存的优势。它可以设置最大停顿时间,目的是用来取代CMS,使用G1非常方便,只需要设置使用G1,设置最大堆内存和最大停顿时间,剩下的一切你都可以交给G1。
G1的内存模型比较特殊,年轻代和老年代依然存在,还增加了一个大内存区:
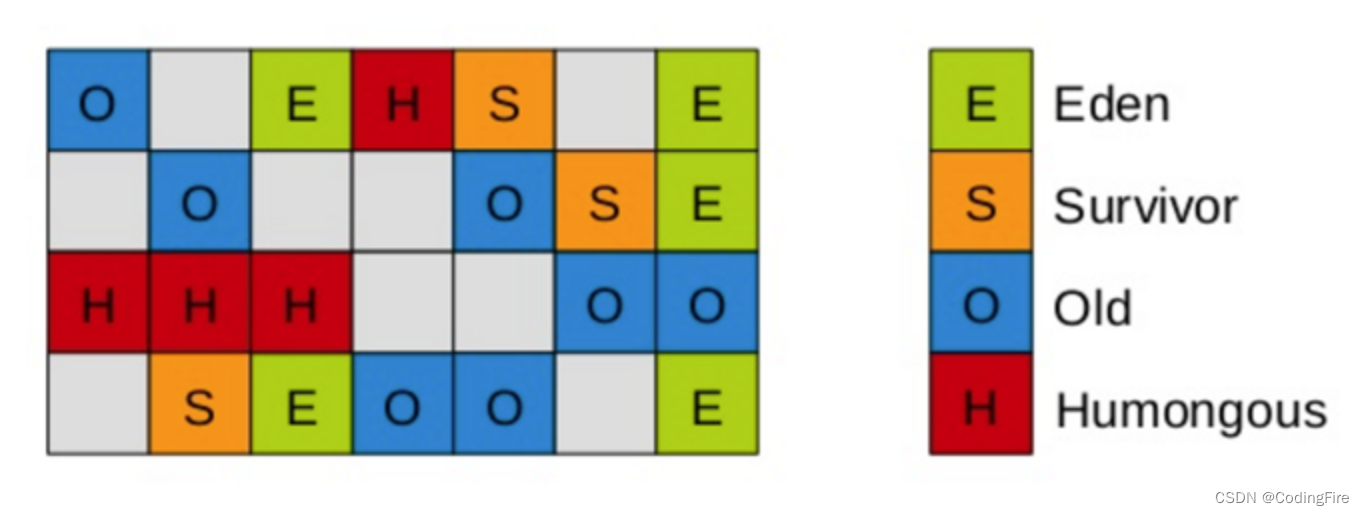
看来看去,还是这张图描述的更为贴切,这就是G1的内存模型,E,S,O,H都有多个存在,并形成连续的内存空间,我们猜猜它用什么清理算法?有没有复制算法那味儿?没错,这么多空间,不复制清除用啥?而且复制算法效率也高,内存碎片化也小,是不是有些小激动。
G1提供了三种垃圾回收方式:young GC、Mixed GC、Full GC。
young gc晋升到Mixed GC的方式和原来一样,如果有大对象,也会直接进入Old区。
当old区满了,会触发mixed gc,从名字来看就是混合gc,也就是说,除了回收整个young 区外,还会回收一部分的old区,是一部分老年代哦,不是全部。CMS中老年代触发GC的默认阈值是80%,G1中默认是45%,你可以手动设置:XX:InitiatingHeapOccupancyPercent。
其清理过程如下:
- initial mark: 初始标记,会STW,采用可达性分析算法
- concurrent marking: 并发标记,和应用线程一起执行,收集各个区的存活对象信息
- remark: 最终标记,会STW,标记并发标记中的遗漏对象
- clean up: 垃圾清除,把存活的对象复制到同区的空闲的区,然后清除原来的区
当对象分配的很快,Mixed GC忙不过来的时候,就触发full gc,这是个灾难,因为full gc是单线程执行的serial old gc,会导致长时间的STW,只能不断的调优以尽可能的避免full gc。
设置G1参数:
-XX:+UseG1GC -XX:MaxGCPauseMillis=100 -XX:+PrintGCDetails
业内关于G1垃圾收集器的调优公认有两个办法:
- 不要设置新生代和来年代大小,让系统自行调整
- 设置XX:MaxGCPauseMillis=xxxx来设置应用程序暂停的时间,G1在运行的时候会根据这个参数选择CSet来满足响应时间的设置,一般是100~200ms之间,根据自己系统,再不断调优精确
其他垃圾收集器
- Epsilon 收集器是在 Java11 中引入的,是一个 no-op(无操作)收集器。它不做任何实际的内存回收,只负责管理内存分配
- Shenandoah 收集器是在 JDK12 中引入的,是一种 CPU 密集型垃圾收集器。它会进行内存压缩,立即删除无用对象并释放操作系统的空间
- ZGC 收集器是为低延迟需要和大量堆空间使用而设计的,允许垃圾回收器运行时 Java 应用程序继续运行。在 JDK11 引入,在 JDK12 改进,并在JDK15和 Shenandoah一起被移出了实验阶段
常用GC分析工具
GC工具多种多样,大家都用什么呢?最后来做个统计调研吧,放在最后。
结语
到此,JVM相关的内容就给大家分享完毕了,每次一说到JVM我就想到了迪迦里面的基里艾洛的人,好顺嘴啊,哈哈哈!!!这一部分内容还是需要大家多探索的,优化没有上限,让我们一起努力吧。