深度学习训练营之船类识别
- 原文链接
- 环境介绍
- 前言收获
- 前置工作
- 设置GPU
- 导入图片
- 数据预处理
- 数据可视化
- 配置数据集
- 数据显示
- 构建模型
- 模型训练
- 编译
- 训练模型
- 结果可视化(模型评估)
- 损失值可视化
- 混淆矩阵
- 各项指标评估
原文链接
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍦 参考文章:深度学习100例 | 第29天:船型识别
- 🍖 原作者:K同学啊|接辅导、项目定制
环境介绍
- 语言环境:Python3.9.12
- 编译器:jupyter notebook
- 深度学习环境:TensorFlow2
前言收获
这次主要是在结果可视化当中学习到了如何使用混淆矩阵来进行模型的评估,这次训练有点长,所以我之训练了十轮,所以结果不是很好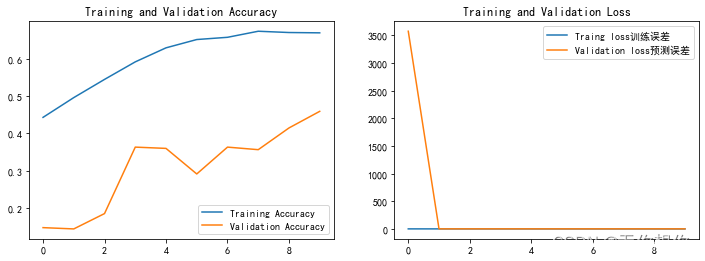
前置工作
设置GPU
import tensorflow as tf
gpus=tf.config.list_physical_devices("GPU")
if gpus:
gpu0=gpus[0];#选择第一个GPU
tf.config.experimental.set_memory_growth(gpu0,True)
tf.config.set_visible_devices([gpu0],"GPU")
import plotly.io as pio
pio.renderers.default="notebook_connected"
import matplotlib.pyplot as plt
import os,PIL,pathlib
import numpy as np
import pandas as pd
import warnings
from tensorflow import keras#开源人工神经网络库
warnings.filterwarnings("ignore")#忽视警告报错消息
plt.rcParams['font.sans-serif']=['SimHei']#显示中文标签
plt.rcParams['axes.unicode_minus']=False
注:这里有一部分是加了
import plotly.io as pio
pio.renderers.default=“notebook_connected”
这是因为在图片显示的时候我显示的结果是没有图片,是一段乱码的,我想可能是运行或者是文件名等问题,所以后面简单改了一下
导入图片
import pathlib
data_dir = "./29-data/"
data_dir = pathlib.Path(data_dir)
image_count = len(list(data_dir.glob('*/*')))
print("图片总数为:",image_count)
图片总数为: 1462
将图片大小设置为一样
batch_size = 16#批量大小
img_height = 224
img_width = 224
数据预处理
将数据分成训练集和测试集
##在导入数据的过程当中打乱数据位置
train_ds=tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=24,#随机数种子
image_size=(img_height,img_width),
batch_size=batch_size
)
Found 1462 files belonging to 9 classes.
Using 1170 files for training.
##在导入数据的过程当中打乱数据位置
val_ds=tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=24,#随机数种子
image_size=(img_height,img_width),
batch_size=batch_size
)
Found 1462 files belonging to 9 classes.
Using 292 files for validation.
这里我的随机数种子从12改成了24
切片大小改成了0.2
数据可视化
检查需要查看的类
class_names=train_ds.class_names
print("数据类型有:",class_names)
print("需要识别的船有%d类",len(class_names))
数据类型有: [‘buoy’, ‘cruise ship’, ‘ferry boat’, ‘freight boat’, ‘gondola’, ‘inflatable boat’, ‘kayak’, ‘paper boat’, ‘sailboat’]
需要识别的船有%d类 9
for image_batch,labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
这里检测了图片的大小是否统一,是否按照上述的image.size进行了调整
(16, 224, 224, 3)
(16,)
配置数据集
AUTOTUNE = tf.data.AUTOTUNE
def train_preprocessing(image,label):
return (image/255.0,label)
train_ds = (
train_ds.cache()
.map(train_preprocessing) # 这里可以设置预处理函数
.prefetch(buffer_size=AUTOTUNE)
)
val_ds = (
val_ds.cache()
.map(train_preprocessing) # 这里可以设置预处理函数
.prefetch(buffer_size=AUTOTUNE)
)
数据显示
plt.figure(figsize=(10, 8)) # 图形的宽为10高为5
plt.suptitle("数据展示")
for images, labels in train_ds.take(1):
for i in range(15):
plt.subplot(4, 5, i + 1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
# 显示图片
plt.imshow(images[i])
# 显示标签
plt.xlabel(class_names[labels[i]-1])
plt.show()

构建模型
from tensorflow.keras import layers, models, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout,BatchNormalization,Activation
# 加载预训练模型
base_model = keras.applications.ResNet50(weights='imagenet', include_top=False, input_shape=(img_width,img_height,3))
for layer in base_model.layers:
layer.trainable = True
# Add layers at the end
X = base_model.output
X = Flatten()(X)
X = Dense(512, kernel_initializer='he_uniform')(X)
X = Dropout(0.5)(X)
X = BatchNormalization()(X)
X = Activation('relu')(X)
X = Dense(16, kernel_initializer='he_uniform')(X)
X = Dropout(0.5)(X)
X = BatchNormalization()(X)
X = Activation('relu')(X)
output = Dense(len(class_names), activation='softmax')(X)
model = Model(inputs=base_model.input, outputs=output)
模型训练
编译
optimizer = tf.keras.optimizers.Adam(lr=1e-4)
model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
训练模型
from tensorflow.keras.callbacks import ModelCheckpoint, Callback, EarlyStopping, ReduceLROnPlateau, LearningRateScheduler
NO_EPOCHS = 10
PATIENCE = 5
VERBOSE = 1
# 设置动态学习率
# annealer = LearningRateScheduler(lambda x: 1e-3 * 0.99 ** (x+NO_EPOCHS))
# 设置早停
earlystopper = EarlyStopping(monitor='loss', patience=PATIENCE, verbose=VERBOSE)
#
checkpointer = ModelCheckpoint('best_model.h5',
monitor='val_accuracy',
verbose=VERBOSE,
save_best_only=True,
save_weights_only=True)
train_model = model.fit(train_ds,
epochs=NO_EPOCHS,
verbose=1,
validation_data=val_ds,
callbacks=[earlystopper, checkpointer])
结果可视化(模型评估)
本次模型评估学习到了如何使用混淆矩阵进行模型结果的评估
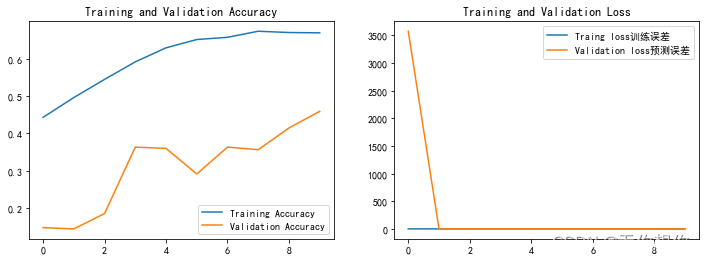
损失值可视化
acc=train_model.history['accracy']
val_acc=train_model.history['val_accuracy']
loss=train_model.history['loss']
val_loss=train_model.history['val_loss']
epochs_range=range(len(acc))
plt.figure(figsize=(12,4))
plt.subplot(1,2,1)
plt.plot(epochs_range,acc,label='Training Accuracy')
plt.plot(epochs_range,val_acc,label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1,2,2)
plt.plot(epochs_range,loss,label='Traing loss训练误差')
plt.plot(epochs_range,val_loss,label='Validation loss预测误差')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
混淆矩阵
from sklearn.metrics import confusion_matrix
import seaborn as sns
# import pandas as pd
def plot_cm(labels,predictions):
#生成混淆矩阵
conf_numpy=confusion_matrix(labels,predictions)
conf_df=pd.DataFrame(conf_numpy,index=class_names,columns=class_names)
plt.figure(figsize=(8,7))
sns.heatmap(conf_df,annot=True,fmt="d",cmap="BuPu")
plt.title('混淆矩阵',fontsize=15)
plt.ylabel('True_value真实值',fontsize=14)
plt.xlabel('val_value预测值',fontsize=14)
设置两个空数组,然后一个两侧循环将结果填入
val_pre=[]
val_label=[]
for images,labels in val_ds:
for image,label in zip(images,labels):
#图片增加一个维度
img_array=tf.expand_dims(image,0)
#使用模型预测图片当中的人物
prediction=model.predict(img_array)
val_pre.append(class_names[np.argmax(prediction)])
val_label.append(class_names[label])
plot_cm(val_label,val_pre)

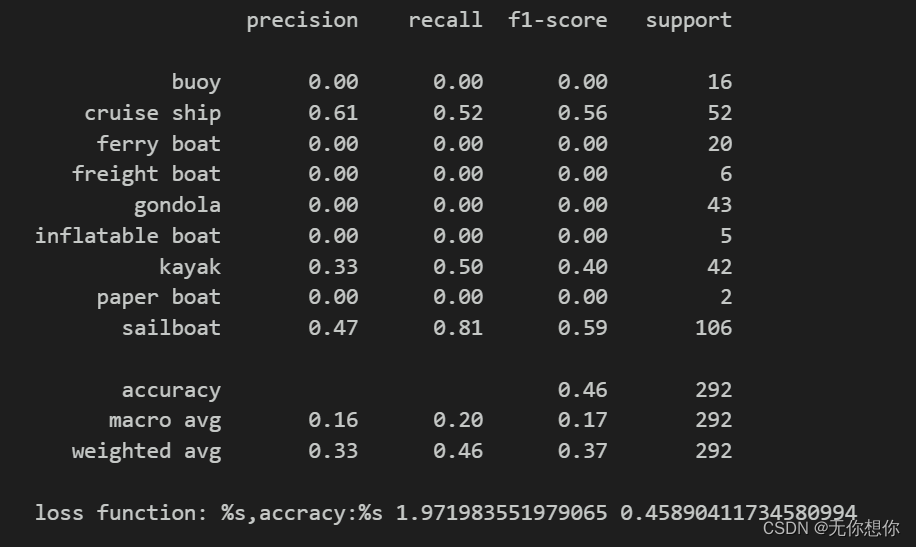
各项指标评估
from sklearn import metrics
def test_accuracy_report(model):
print(metrics.classification_report(val_label,val.pre,target_names=class_names))
score=model.evaluate(val.ds,verbose=0)
print('loss function: %s,accracy:%s',score[0],score[1])
test_accuracy_report(model)