原文标题:MOLE-BERT: RETHINKING PRE-TRAINING GRAPH NEURAL NETWORKS FOR MOLECULES
原文链接:Mole-BERT: Rethinking Pre-training Graph Neural Networks for Molecules | OpenReview
https://github.com/junxia97/Mole-BERT
一、Introduction
AttrMask已经成为一个基本的预训练任务,但是只使用AttrMask(节点级预训练任务)进行预训练有时会产生负迁移问题(即预训练的模型落后于没有预训练的模型),他们认为这种现象可以归因于缺乏图级预训练任务,因此引入监督图级预训练策略,这是不切实际的,因为标签通常是昂贵的或不可用的。此外,一些与下游感兴趣任务无关的监督预训练任务甚至会降低下游性能

在图a中,AttrMask会迅速收敛,因为该任务就118类(原子词汇量小)。相比Bert中MLM准确率仅能到70%,并且对于大量文本词汇(~30K个token)几乎无法收敛。
不同原子之间的频率差异显著(图b),这使得模型更加偏向于优势原子,并迅速收敛。
先前的work揭示过简单的预训练任务将捕获较少的可转移知识,并损害对新任务的泛化或适应
在语言模型中,第一步训练Tokenizer,第二步训练模型。在GNN训练中,一般采用原子类型作为token,这导致原子词汇量规模小、不平衡。
论文中提出具有不同上下文的原子应该被tokenizer为不同的离散值,即使是同一类原子。比如aldehyde carbons 、ester carbons中C原子表现出不同性质,因此引入一个上下文感知器的tokenizer,将原子编码为有意义的离散值,具体来说是VQVAE的latent code
由于其Encoder是GNN-based model,因此其tokenizer是上下文感知的,就可以根据原子上下文将优势原子分为几个亚型,这将扩大原子词汇量,减轻优势原子和稀有原子的数量差异,图c表明了t-SNE可视化,可以看到C原子是基于官能团聚类的,表明tokenizer可以将原址聚类为有意义的值。利用新的tokenizer,提出node-level(Masked Atoms Modeling,MAM),随机mask离散值后预测。graph-level,使用图对比学习,然而,对比学习将不同的分子平等地推开,而不管它们真正的相似程度,因此提出TMCL任务(使用不同masked ratio模拟不同程度的分子相似性)
二、Method
图G=(V,E),节点v∈ V,边e ∈ E,形式上,第l层得到更新(l-1)的更新:
![]()
AGGREGATE(·)为邻域信息的聚合函数(如均值)。COMBINE(·)将相邻节点和节点v的信息进行组合(例如,连接运算符)。经过L次消息传递迭代后,最后一次迭代的隐藏状态h (L) 是v的嵌入,最后采用READOUT(·)操作(如平均、求和或图池化)得到整个图G的表示hG
![]()
1、MASKED ATOMS MODELING (MAM)
分子图G的原子V = {v1, v2,···,vn}被标记为z = {z1, z2,···,zn}∈An,其中原子词汇a包含| a | (| a | = 512)个离散码,VQ-VAE中GNN编码器将原子编码为原子embedding; 接下来,矢量量化器(VQ)在码本中查找每个embedding原子的最近邻居。设{e1, e2,···,e|A|}表示码本embedding。第i个原子:
![]()
在将原子量化为离散标记后,输入相应的码本embedding:{ez1, ez2, · · · , ezn } , 给解码器重建输入的分子图。请注意,矢量量化过程是不可微的。为了训练编码器,梯度近似于straight-through estimator ,并从解码器复制到编码器。在输入属性vi和重构属性vi的情况下,训练损失为:

第一项:余弦误差(γ≥1)的重建损失,
第二项是旨在更新码本的VQ损失,
第三项是承诺损失,使得编码器的输出保持接近所选的码本embedding。
Sg[·]表示停止梯度,β是设置为0.25。
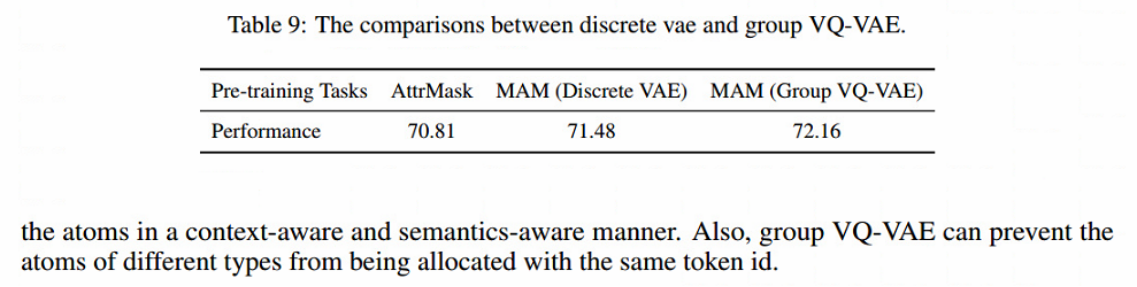
tokenizer以上下文感知的方式将原子token为离散的code,观察到不同类型的原子可能会被分配到与vanilla VQ-VAE相同的令牌id。因此,引入group VQ-VAE来解决这个问题。具体来说,将码本embedding分为几组,每组对应于特定的原子类型。例如,碳、氮、氧的code分别被限制为[1,128]、[129,256]和[257,384]。剩下的稀有原子被限制在[385,512],因为它们不太可能相互冲突。
给定分子图G,随机mask其15%的原子token,并预训练GNN来预测它们。将masked原子code集合命名为M,将masked分子图命名为GM。对于每个masked原子i∈M,采用softmax分类器预测词汇表a上的离散值。MAM损失:
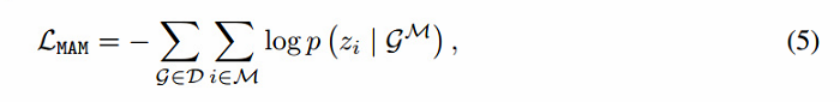
D表示数据集,zi是原子vi的标记。
2、GRAPH-LEVEL TASK: TRIPLET MASKED CONTRASTIVE LEARNING (TMCL)
虽然MAM可以减轻负转移问题,但观察到无法捕获图级语义。具体来说,首先计算了两个分子的扩展连接指纹(ECFP) 的谷本系数作为它们的化学相似性。然后选择前15%相似度的分子对作为“相似”分子对,而数据集中剩下的85%分子对是“随机”分子对。
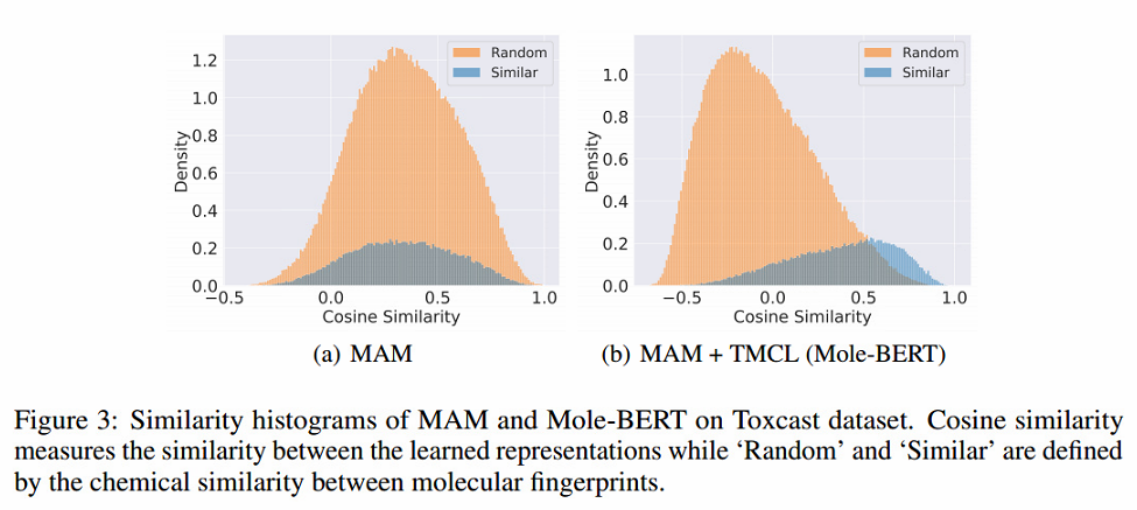
图3(a)显示了学习表征(MAM)和ECFP之间的显著不一致,这将损害使用MAM的分子检索,因为两个随机分子可能具有高相似性得分(缺乏一致性),而密切相关的分子可能具有更多不同的表征(缺乏一致性)。对比学习是最大化配对分子图增强(正对)之间的一致性,并将batch的其他分子作为负对(不同的分子)推开。然而,认为这个框架不能反映锚和其他分子之间的异质相似性。例如,acid(阴性)和acetic acid(锚)之间的相似性应该比ethanol(负)和acetic acid(锚)之间的关系更显著。因此,引入了三重掩蔽对比学习,称为TMCL,以减轻这一关键缺陷。
对于分子图G,首先生成其增强版本GM1,其中包含masked原子索引M1和较小的屏蔽比(例如,15%)。然后扩大掩蔽比(例如30%),得到另一个增强版本GM2。现在,我们构成了一个三联体(G, GM1, GM2),它们之间存在潜在关系,即GM1与G的相似度大于GM2与G的相似度。考虑到hG, hM1, hM2分别是G, GM1和GM2的图级表示,可以将这种潜在关系与三重态损失建模:
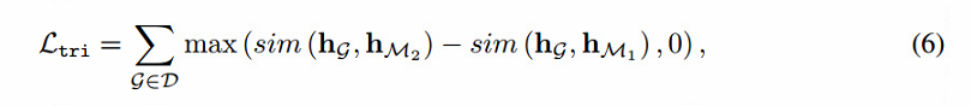
其中sim(·,·)为余弦相似度。三元组损失Ltri和常用的对比损失Lcon结合起来作为图级预训练目标LTMCL:
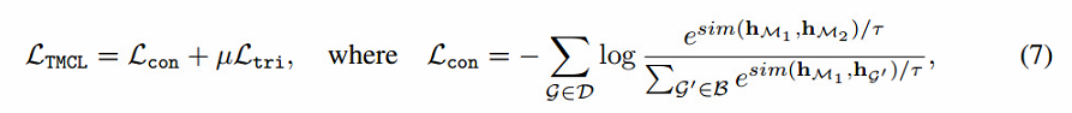
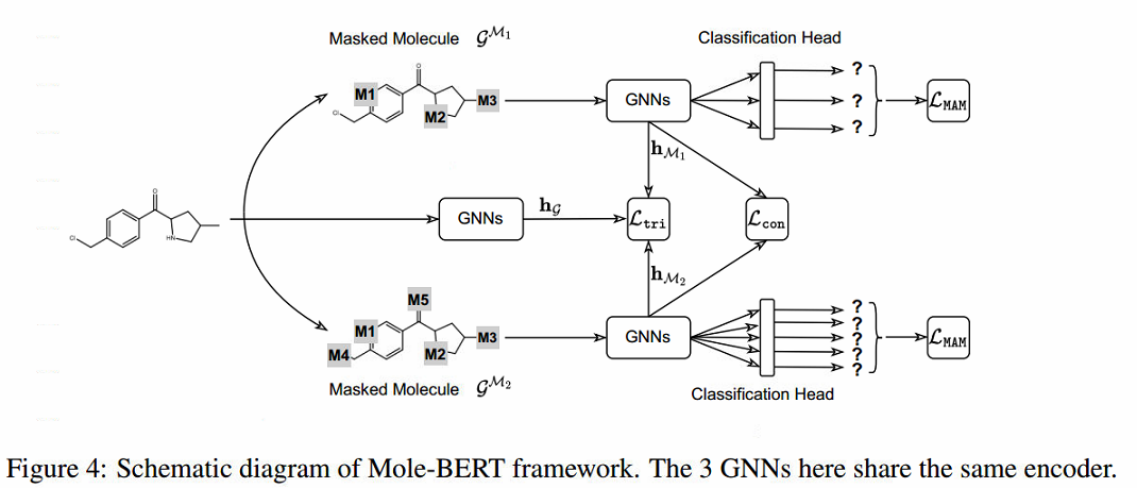
其中B为包含G的sample batch,µ为权衡超参数,τ为温度超参数。最后,MAM和TMCL构成了一个统一的预训练框架Mole-BERT(见图4),其混合损失为:
![]()
3、Mole-BERT
三、EXPERIMENTS
DATASETS
2M (ZINC15)、MoleculeNet(scaffold splitting)、
EXPERIMENTS CONFIGURATION
使用隐藏维数为300的5层图同构网络(GINs)作为主干架构。采用均值池化作为readout函数。在预训练阶段,gnn预训练100次,批大小为256,学习率为0.001。在微调阶段,我们训练了100个epoch, batch size为32,并报告了交叉验证性能最好的测试分数。
训练/验证/测试集的分割是80%:10%:10%。使用验证集从{0.1,0.3,0.5}中选取超参数µ。
使用10个随机种子(0-9)和支架分裂对各自公开可用的预训练模型进行微调。使用批量大小为32,dropout为0.5。在每个数据集上训练模型100个epoch,并在达到最佳验证性能时报告测试性能
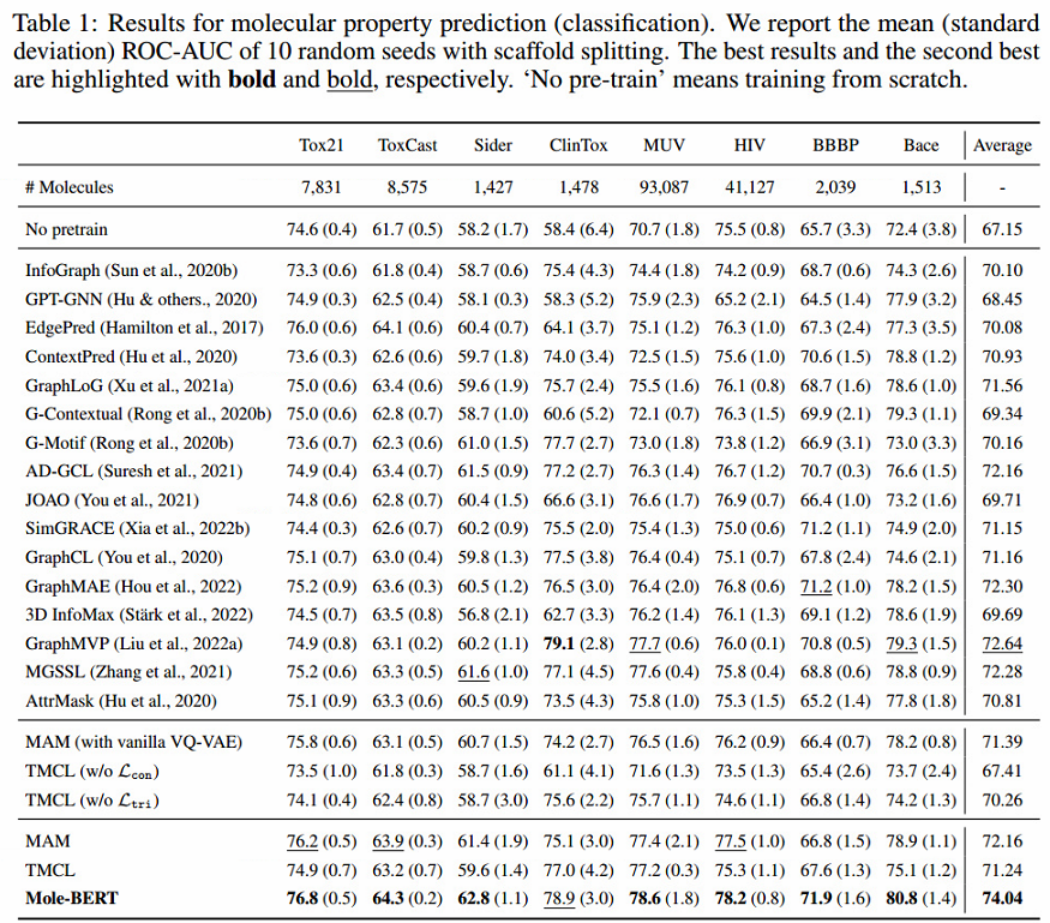
RESULTS AND ANALYSIS
- AttrMask的预训练任务在某些数据集(HIV和BBBP)上产生负迁移问题。相比之下,MAM在AttrMask和“No pretrain”上取得了一致且显著的改进,尽管MAM仅使用节点级任务预训练gnn。这一观察结果验证了只有节点级别的预训练任务也可以减轻负迁移,这推翻了之前认为单个节点级别的预训练gnn可能会带来有限改进的观点。AttrMask失败的原因在于极其小且不平衡的原子词汇表。
- 在相同的实验协议下,Mole-BERT可以获得与之前的预训练策略相当或更好的性能。更具体地说,Mole-BERT比“无预训练”模型高出6.89%,比目前最先进的方法GraphMVP高出近1.40%,尽管GraphMVP在另一个具有3D几何形状的分子数据集上预训练gnn。
- 如表2所示,MAM可以像AttrMask一样作为基本的预训练子任务。此外,当MAM作为多任务gnn预训练的子任务时,MAM比AttrMask具有显著的优势。
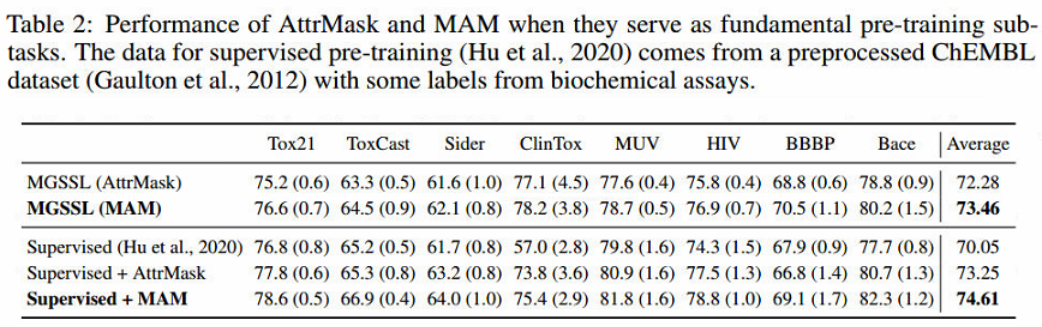
- 观察IV(消融研究): 从表1中可以看出,group VQ-VAE优于MAM中的普通VQ-VAE,因为可以防止不同类型的原子被分配相同的令牌id。此外,在TMCL中去除三重态损耗Ltri或对比损耗Lcon时,性能有明显下降,这表明它们都是必要和有效的。
Influence of GNNs Backbone.
通过尝试GIN 、GCN、 R-GCN 、GraphSAGE 四种流行的GNN模型来验证Mole-BERT对GNN架构的不可知性。与使用各种gnn从头开始训练相比,Mole-BERT实现了一致且显著的改进。此外,使用GIN进行预训练可以获得最显著的收益:

Broader Range of Downstream Tasks.
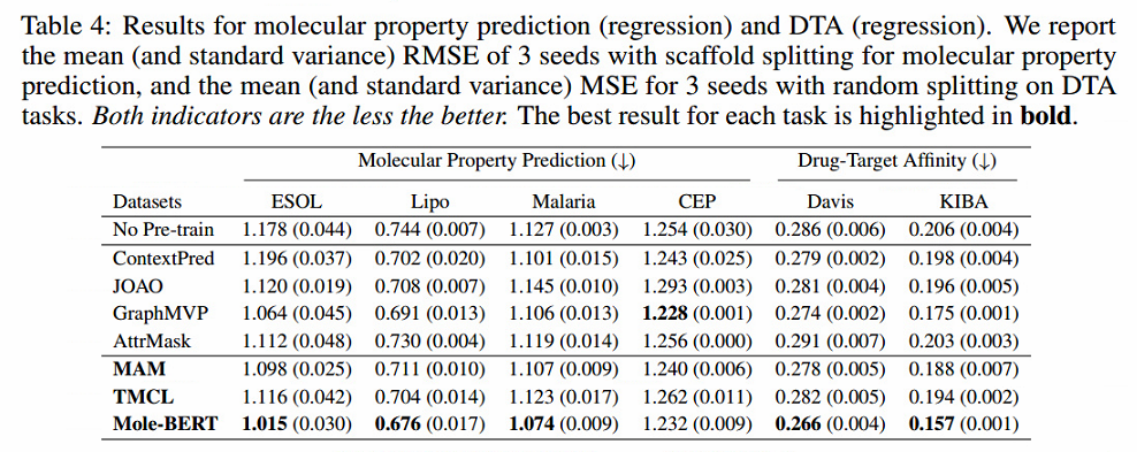
回归属性预测和药物靶标亲和力(DTA)任务的表现。DTA是药物发现中的一项重要任务,其目的是预测分子药物与蛋白质靶点之间的亲和力评分。用预训练的GNN代替他们方法中的GNN。优异的性能表明Mole-BERT可以在更广泛的下游任务中工作。
Influence of the Vocabulary Size.

当词汇量大小在128 ~ 2048之间时,可以观察到:(1)即使将词汇量大小设置为128,在AttrMask的119附近,MAM也可以优于AttrMask,这表明VQ-VAE派生的标记具有上下文感知能力,优于纯原子的标识;(2)词汇量的大小也会影响MAM的表现。
虽然1024的词汇量优于512,但优势并不显著。因此,考虑到计算预算,我们将512设置为默认词汇表大小。
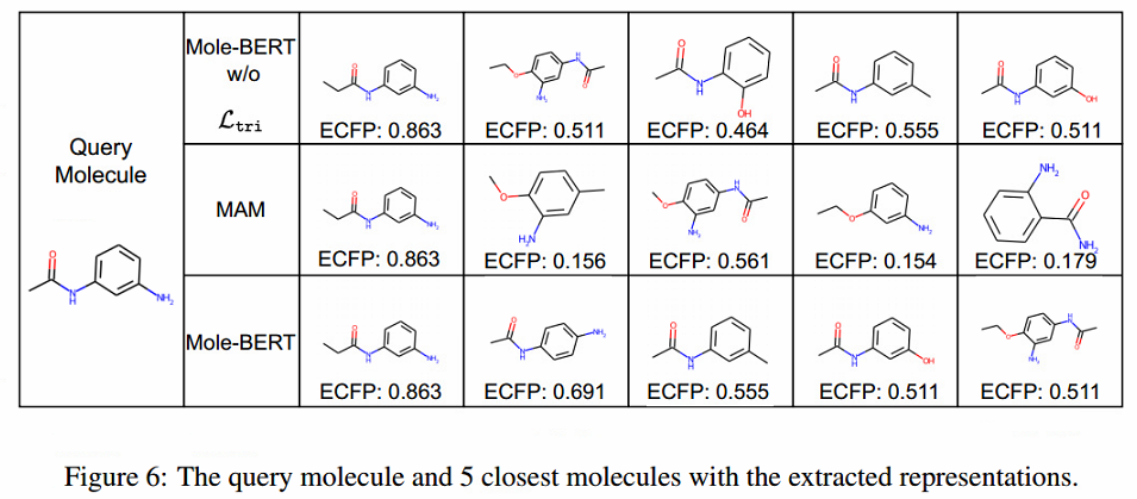
Molecule Retrieval
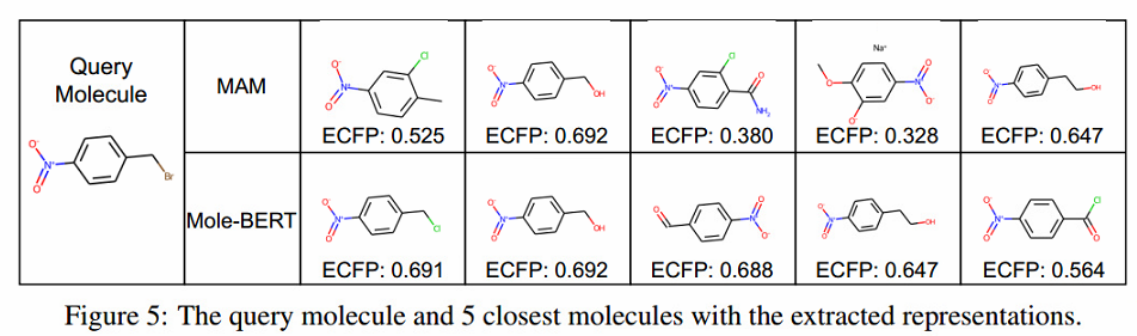
为了进行更全面的评估,首先提取查询分子的表示。然后,计算其与ToxCast数据集中所有参考分子的余弦相似度。用图5中的余弦相似度展示了与查询分子最相似的5个分子。可以观察到,Mole-BERT的表征相似度与指纹相似度近似一致,这表明Mole-BERT学习了化学上有意义的表征。此外,从MAM中提取的表征不能模拟分子之间不同程度的相似性。因此,像TMCL这样的图级任务对于分子检索是必要和有效的。
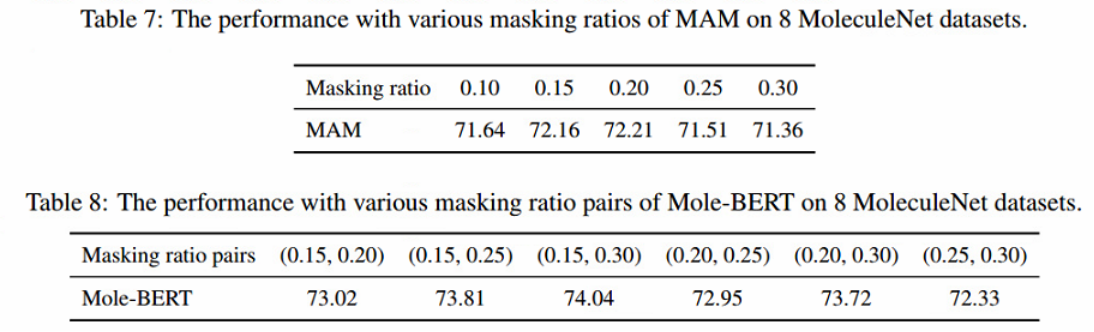
不同MASK ratio对MAM的区别
更多检索:
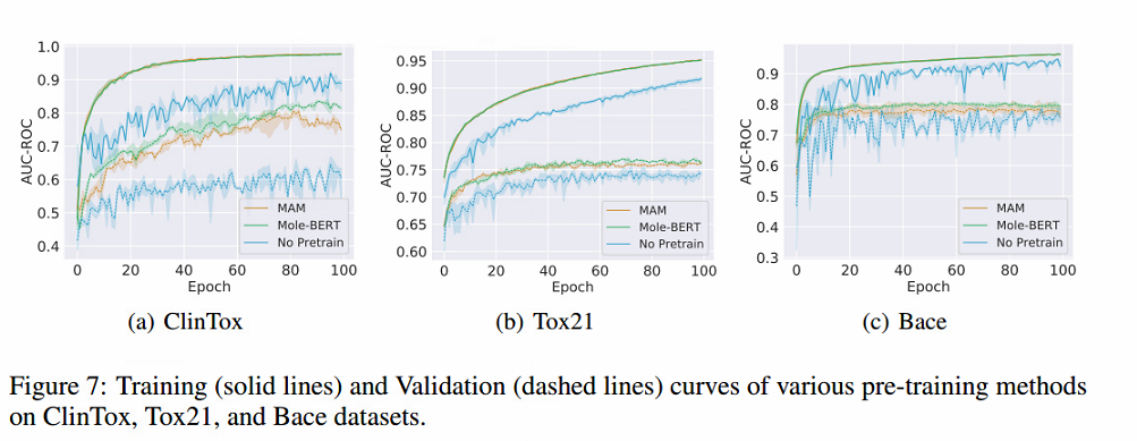
训练过程:
不同VAE的性能: