文章目录
- 从内核出发
- 获取内核源码
- 使用Git
- 安装内核源码
- 使用补丁
- 阅读Linux内核源码
- Source Insight简介
- 阅读源码
- 内核开发的特点
- 无libc库抑或无标准头文件
- GNU C
- 没有内存保护机制
- 不要轻易在内核中使用浮点数
- 容积小而固定的栈
- 同步和并发
- 可移植性的重要性
- Linux源码分析
- Linux源码结构分析
- arch目录
- drivers目录
- fs目录
- 其他目录
- 内核配置选项
- 配置编译过程
- 常规配置
- 模块配置
- 块设备层配置
- CPU类型和特性配置
- 电源管理配置
- 总线配置
- 网络配置
- 设备驱动配置
- 通用驱动配置
- 字符设备配置
- 多媒体设备驱动配置
- USB设备驱动配置
- 文件系统配置
- 嵌入式文件系统基础知识
- 嵌入式文件系统
- 嵌入式系统的存储介质
- JFFS文件系统
- YAFFS文件系统
- 构建根文件系统
- 根文件系统概述
- Linux根文件系统目录
- BusyBox构建根文件系统
- BusyBox概述
- 解压BusyBox
从内核出发
获取内核源码
登录Linux内核官方网站,可以随时获取当前版本的Linux源代码。可以是完整的压缩形式(使用tar命令创建一个压缩文件),也可以是增量补丁形式。
除特殊情况下需要Linux源码的旧版本外,一般都希望拥有最新的代码。kernel.org是源码的库存之外,那些领导潮流的内核开发者所发布的增量补丁也放在这里。
使用Git
一直以来,Linus和他领导的内核开发者们开始使用一个新版本的控制系统来管理Linux内核源代码。Linus创造的这个系统称为Git。与CSV这样的传统的版本控制系统不同,Git是分布式的,它的用法和工作流程对许多开发者来说都很陌生,但是还是强烈建议使用Git来下载和管理Linux内核源代码。
你可以使用Git来获取最新提交到Linus版本树的一个副本:(为了保持对书籍的同步,所以这里也下载2.6版本,自己也会下载较新的版本进行后面的驱动实验)
git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git
还是比较慢的!!!
当下载代码后,你可以更新你的分支到Linus的最新分支:
git pull
有了这两个命令,就可以获取并随时保持与内核官方的代码树一致。要提交和管理自己的修改后面会介绍。关于Git学习推荐Git学习网站
安装内核源码
由于官网下载比较慢,所以推荐源码下载地址
内核压缩以GNU zip(gzip)和bzip两种形式发布。bzip2是默认和首选形式,因为它在压缩上比gzip更有优势。以bip2形式发布的Linux内核叫做linux-x.y.z.tar.bz2,这里的x.y.z是内核源码的具体版本。下载了源代码之后,就可以轻而易举地对其进行解压。如果压缩是bzip2,则运行
tar xvjf linux-x.y.z.tar.bz2
如果压缩形式是GNU的zip,则运行:
tar xvzf linux-x.y.x.tar.gz
何处安装并触及源码?
内核源码一般安装在/usr/src/linux目录下。但请注意,不要把这个源码树用于开发,因为编译你的C库所用的内核版本就链接到这颗树。此外,不要以root身份对内核进行修改,而应当建立自己的主目录,仅以root身份安装新内核。即使在安装新内核时,/usr/src/linux目录都应当原封不动。
使用补丁
在Linux内核社区中,补丁是通用语。你可以以补丁的形式发布对代码的修改,也可以以补丁的形式接收其他人所做的修改。增量补丁可以作为版本转移的桥梁。你不再需要下载庞大的内核源码的全部压缩,而只需给旧版本打上一个增量补丁,让其旧貌换新颜。这不仅节约了带宽,还省了时间。要应用增量补丁,从你的内核源码树开始,只需要运行:
patch -p1 < ../patch-x.y.z
一般来说,一个给定版本的内核补丁总是打在前一个版本上。
阅读Linux内核源码
如下我们已经下载好了Linux Kernel的源码,为了方便阅读源码,我们可以借助工具来完成。

Source Insight简介
关于Source Insight的介绍和使用大家可以参考这篇博客。或者直接在网上找资料进行学习
参考博客
阅读源码
以下内容仅是我个人喜好,大家学会后可自行搭建属于自己风格的方式
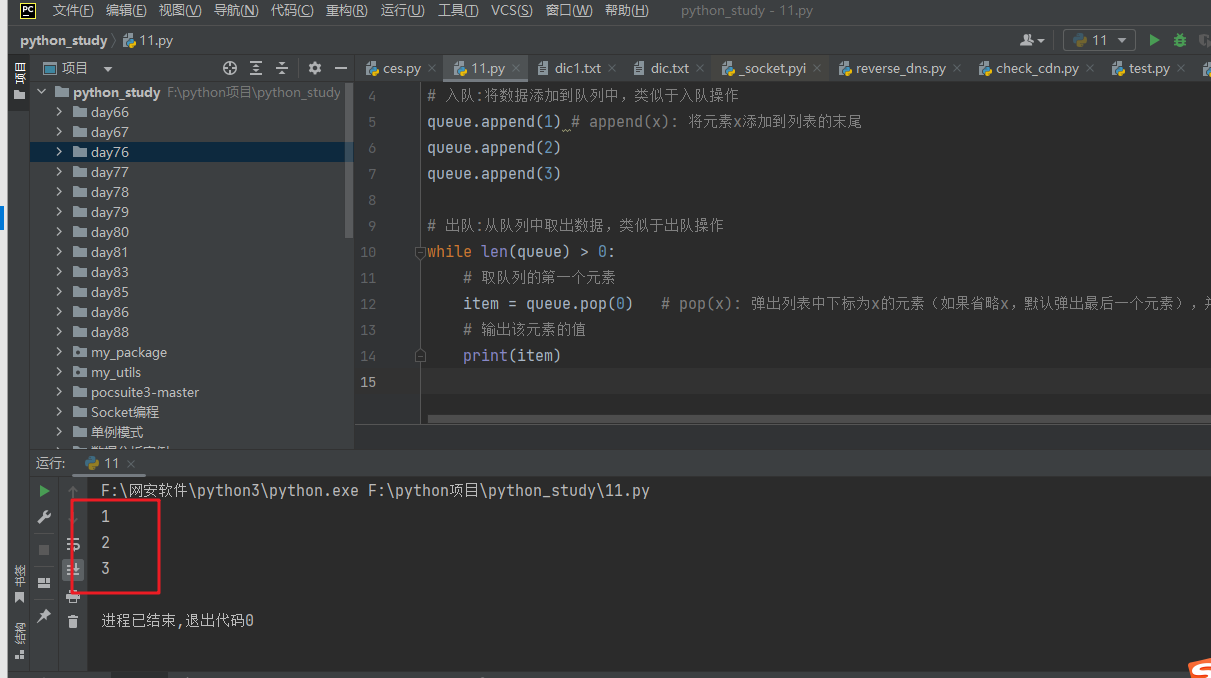
1、在Winows上查看Linux server上的代码——将Linux server映射到Windows本地
使用sftp工具将Linux server映射到本地。(网上搜索下载该工具即可)

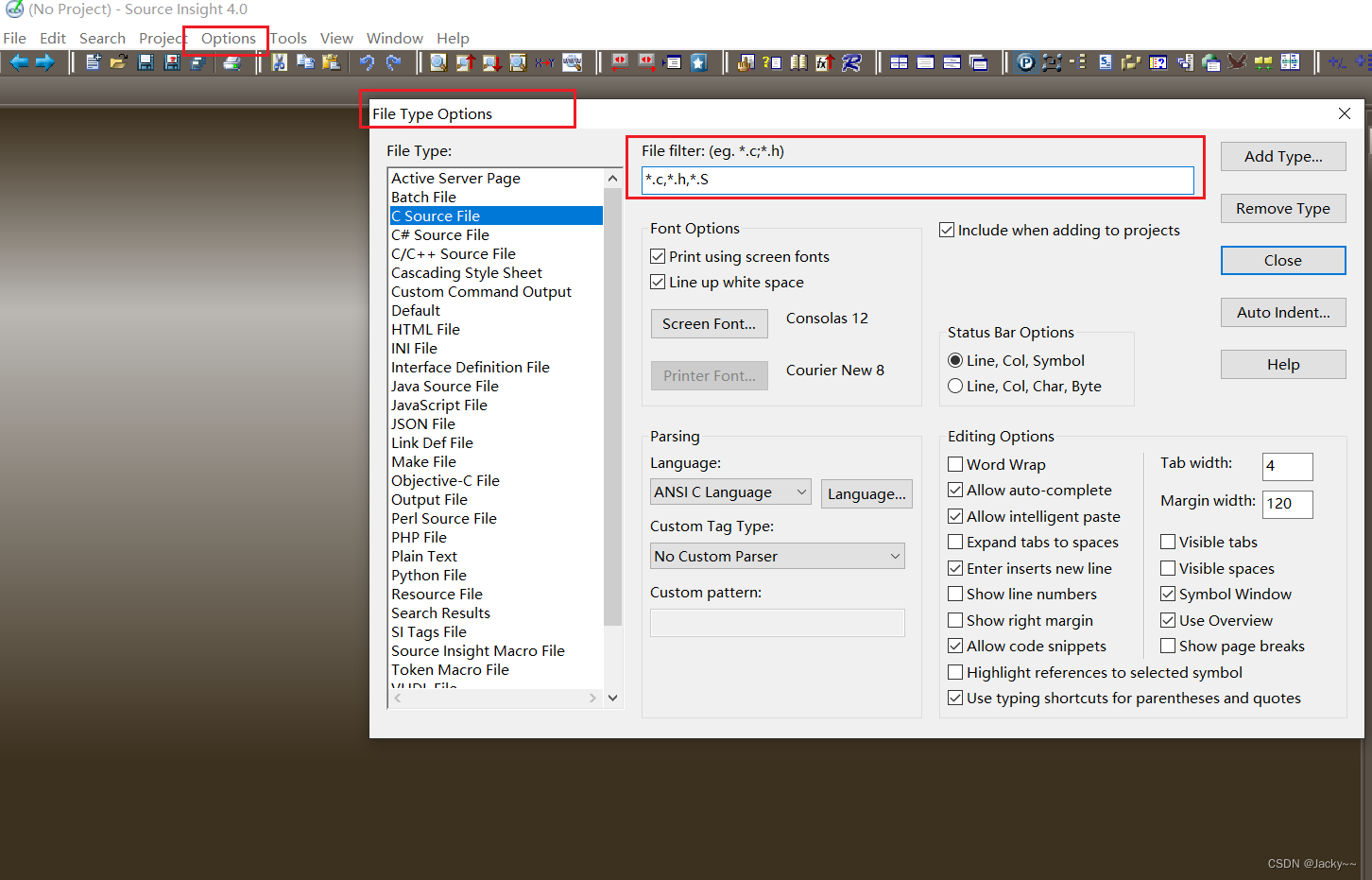
2、打开Source Insight建立工程
Source Insight默认情况下,只支持*.c和*.h文件,而Linux源代码中有大部分以*.S结尾的汇编语言文件,所以需要设置一下Source Insight软件,使其支持“.S”文件。
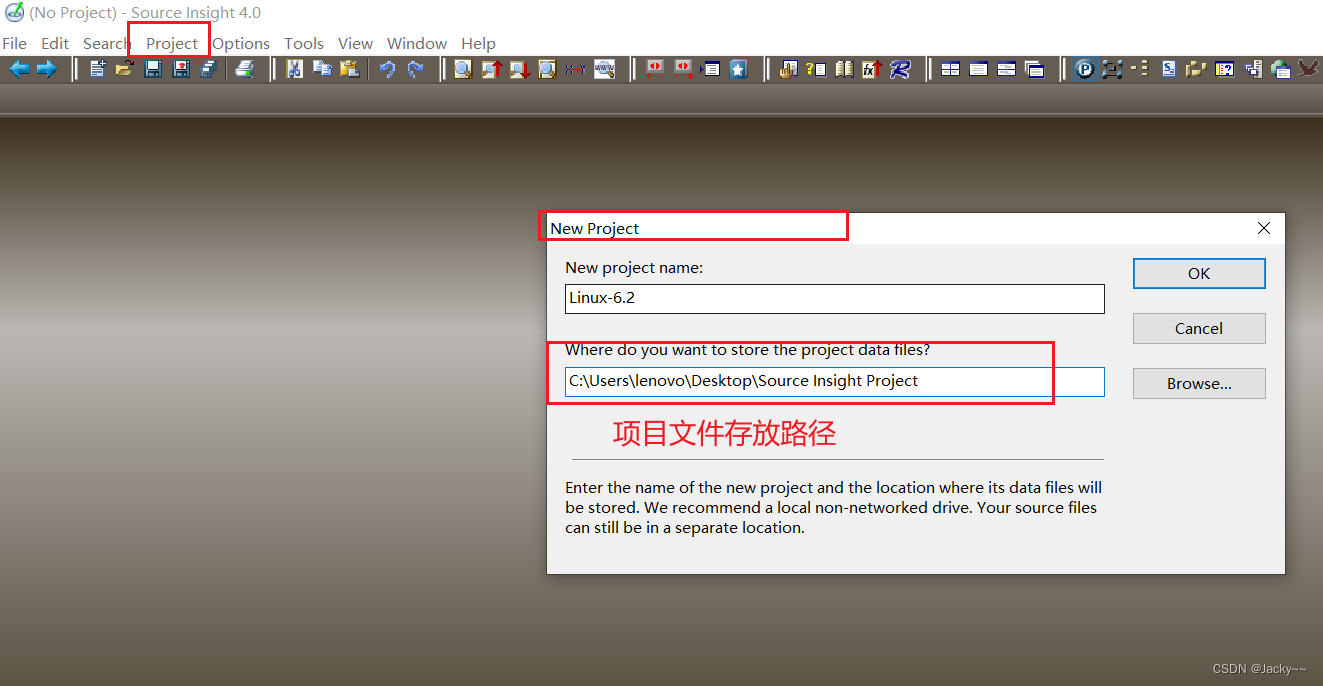
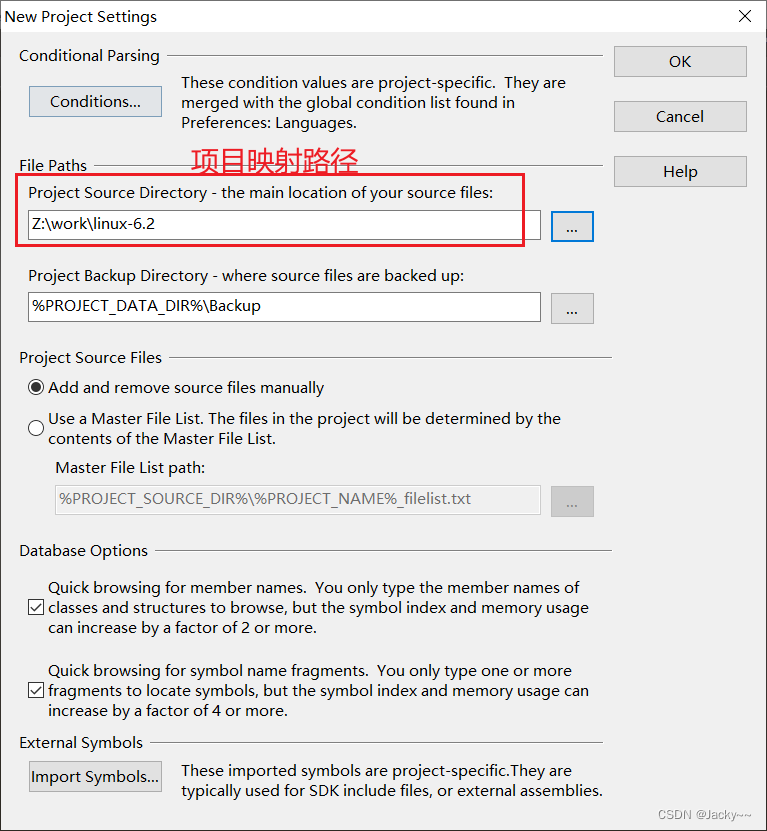
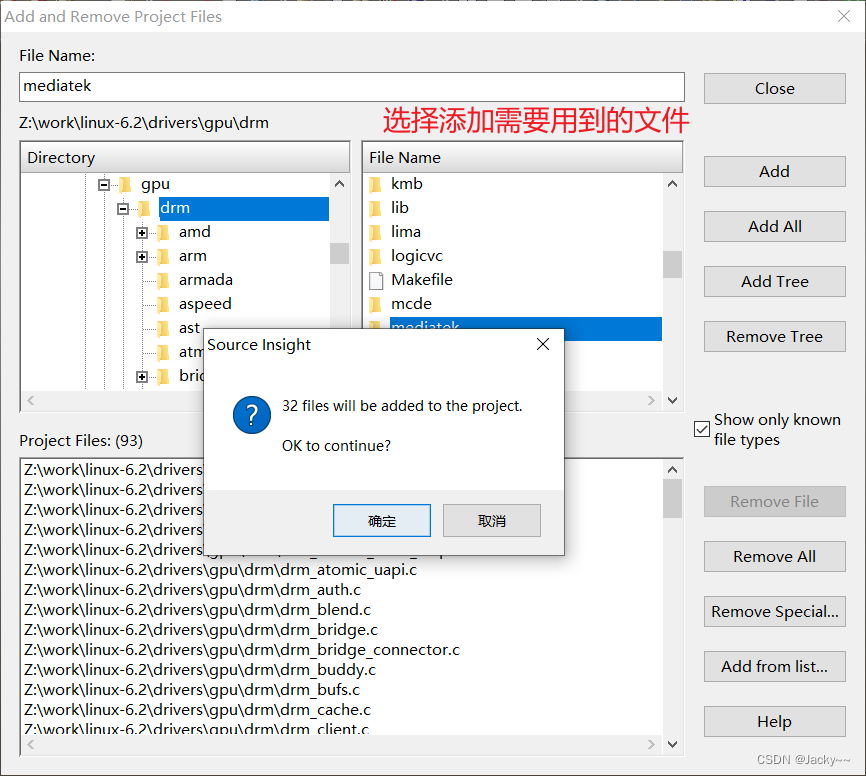
添加头文件路径
另建一个项目,添加Linux头文件路径include,还是选择自己需要的头文件进行添加。重新打开之前建立的文件,添加头文件路径
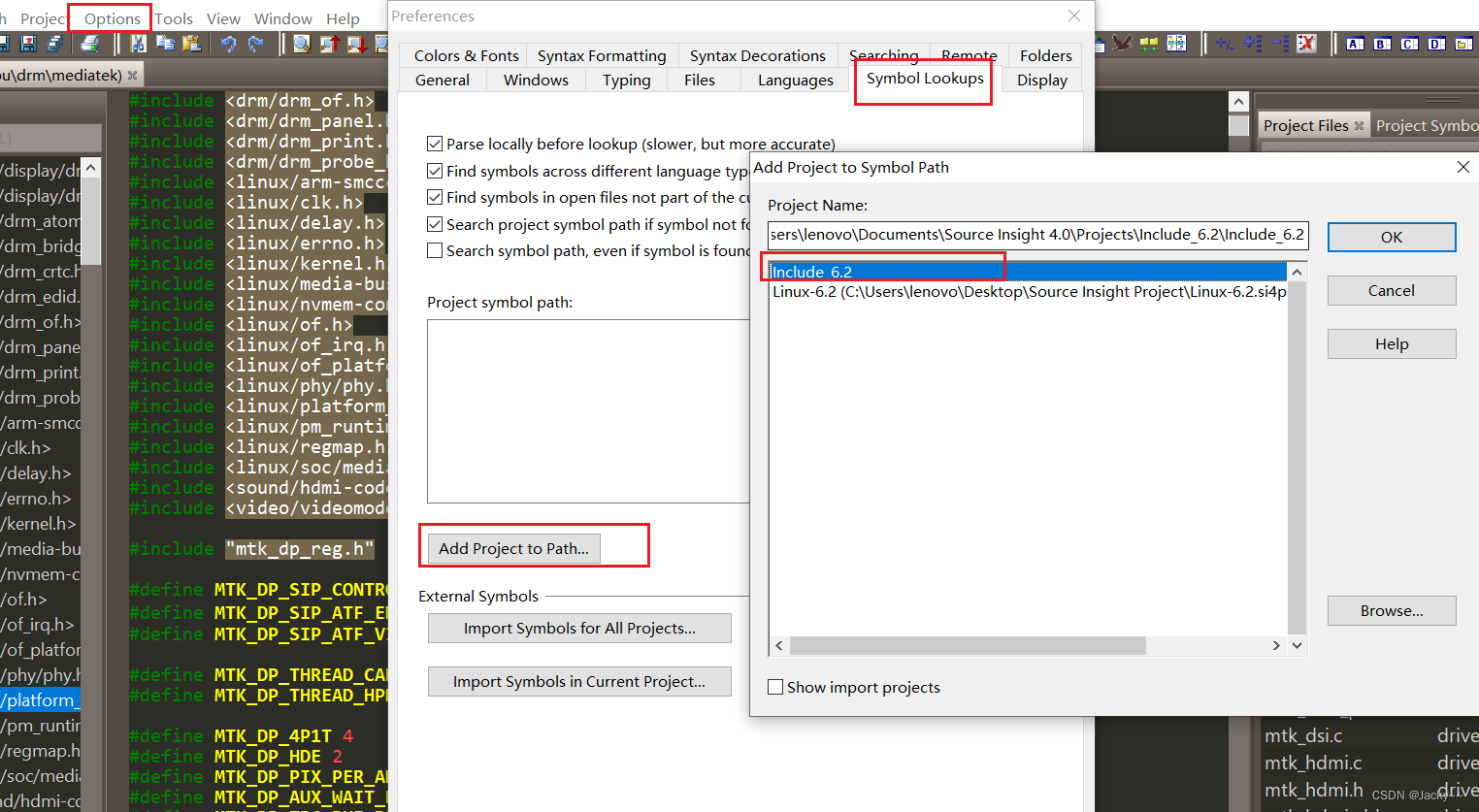
这样即可实现头文件的自由跳转。
安装内核
在内核编译好之后,你还需要安装它。怎么安装就和体系结构以及启动引导工具(Bootloader)息息相关了——查阅启动引导工具的说明,按照它的指导将内核映象拷贝到合适的位置,并且按照启动要求安装它。一定要保证随时有一个或者两个可以启动的内核,以防新编译的内核出现问题。
例如,在使用grub的x86系统上,可能需要把arch/i386/boot/bzImage拷贝到/boot目录下,像vmlinuxz-version这样命名它,并且编辑/etc/grub/grub.conf文件,为新内核建立一个新的启动项。使用LILO启动的系统应当编辑/etc/lilo.conf,然后运行lilo。
所幸,模块的安装是自动的,也是独立于体系结构的。以root身份,只要运行:
% make modules_install
就可以把所有已编译的模块正确安装到主目录/lib/modules下。
编译时也会在内核代码树的根目录下创建一个System.map文件。这是一份符号对照表,用以将内核符号和它们的起始地址对应起来。调试的时候,如果需要把内存地址翻译成容易理解的函数名以及变量名,这就会很有用。
内核开发的特点
相对于用户空间内应用程序的开发,内核开发有一些独特之处。尽管这些差异并不会使开发内核代码的难度超过用开发用户代码,但是它们依然有很大不同。
这些特点使内核成了一只性格迥异的猛兽。一些常用的准则被颠覆了,而又必须建立许多全新的准则。尽管有许多差异一目了然,但还是有一些差异晦暗不明,最重要的差异包含以下几种:
- 内核编程时既不能访问C库也不能访问标准的C头文件
- 内核编程时必须使用GNU C。
- 内核编程时缺乏像用户空间那样的内存保护机制。
- 内恶化编程时难以执行浮点运算。
- 内核给每个进程只有很小的定长堆栈。
- 由于内核支持异步中断、抢占和SMP,因此必须时刻注意同步和并发。
- 要考虑可移植性的重要性。
无libc库抑或无标准头文件
主要原因,对于内核来说完整的C库——哪怕是它的一个子集,都太大且太低效了。
对于内核基本的头文件位于内核源码顶层目录include目录中;体系结构相关的头文件集位于内核源码树的arch/<architecture>/include/asm目录下。内核代码通常以asm/为前缀的方式包含这些头文件。例如<asm/ioctl.h>
内核函数printk()与libc函数printf()之间一个显著的区别在于,printk()允许你通过一个标志来设置优先级。syslog会根据这个优先级标志来决定在什么地方显示这条系统消息。下面是一个使用优先级标志的例子:
printk(KERN_ERR "this is an error!\n");
注意:在KERN_ERR和要打印的消息之间没有逗号,这样写是别有用意的。优先级标志是预处理程序定义的一个描述性字符串,在编译时优先级标志就与要打印的消息绑定在一起处理。
GNU C
1、内联(inline)函数
C99和GNU C均支持内联函数。inline这个名称可以反映它的工作方式,函数会在它所调用的位置上展开。这么做可以消除函数调用和返回所带来的开销(寄存器存储和恢复)。而且,由于编译器会把调用函数的代码和函数本身放在一起进行优化,所以也有进一步优化代码的可能。不过,这么做是有代价的,代码会变长,这也就意味着占用更多的内存空间或占用更多的指令缓存。内核开发者通常要把那些时间要求比较高,而本身长度又比较短的函数定义成内联函数。如果一个函数较大,会被反复调用,且没有特别的时间上的限制,我们并不赞成把它做成内联函数。
定义一个内联函数的时候,需要使用static作为关键字,并且用inline限定它。比如:
static inline void wolf(unsigned long tail_size)
内联函数必须在使用之前就定义好,否则编译器就没法把这个函数展开。实践中一般在头文件中定义内联函数。由于使用了static作为关键字进行限制,所以编译时不会为内联函数单独建立一个函数体。如果一个内联函数仅仅在某个源文件中使用,那么也可以把它定义在该文件开始的地方。
在内核中,为了类型安全和易读性,优先使用内联函数而不是复杂的宏
2、内联汇编
gcc编译器支持C函数中嵌入汇编指令。当然,在内核编程的时候,只有知道对应得体系结构,才能使用这个功能。
我们通常使用asm()指令寄存器嵌入汇编代码。例如,下面这条内联汇编指令用于执行x86处理器的rdtsc指令,返回时间戳(tsc)寄存器的值。
unsigned int low, high;
asm volatile("rdtsc": "=a" (low), "=d" (high));
/*low和high分别包含64位时间戳的低32位和高32位*/
Linux内核混合使用了C语言和汇编语言。在偏近体系结构的底层或对执行时间要求严格的地方,一般使用的是汇编语言。在内核其他部分的大部分代码是使用C语言编写的。
3、分支声明
对于条件选择语句,gcc内建了一条指令用于优化,在一个条件经常出现,或者该条件很少出现的时候,编译器可以很具这条指令对条件分支选择进行优化。内核把这条指令封装成了宏,比如likely()和unlikely()。这样使用起来比较方便。
例如,下面是一个条件选择语句:
if(error){
/*...*/
}
//如果想要把这恶鬼选择标记成绝少发生的分支;
/*我们会认为error绝大多数时间会为0*/
if(unlikely(error)){
/**.../
}
//相反,如果我们想把一个分支标记为通常为真的选择:
/**我们认为success通常不会为0/
if(likely(success)){
/*....*/
}
在你想要对某个条件选择语句进行优化之前,一定要搞清楚其中是不是存在这么一个条件,在绝大多数情况下都会成立。这点十分重要:如果你的判断正确,确实是这个条件压倒性的地位,那么性能会得到提高;如果你搞错了,性能反而会下降。正如上面的例子所示,通常在对一些错误条件进行判断的时候会用到likey()和unlikely()。你可以猜到,unlikey()在内核中会得到更广泛的使用,因为if语句往往判断一种特殊情况。
没有内存保护机制
如果一个用户陈旭试图进行一次非法的内存访问,内核就会发现这个错误,发送SIGSEGV信号,并结束整个进程。然而,如果是内核自己非法访问了内存,那后果就很难控制了。(毕竟,有谁能照顾内核呢?)内核中发生的内存错误会导致oops,这是内核中出现的最常见的一类错误。在内核中,不应该去访问非法的内存地址,引用空指针之类的事情,否则它可能会死掉,却根本不告诉你一声——在内核里,风险常常会比外面大一些。
此外,内核中的内存都不分页。也就是说,你每用掉一个字节,物理内存就减少一个字节,所以你想往内核中加入什么新功能,要记住这一点。
不要轻易在内核中使用浮点数
在用户空间的进程内进行浮点数的时候,内核会完成从整数操作到浮点数操作的模式转换。在执行浮点指令时到底会做些什么,因体系结构不同,内核的选择也不同,但是,通常内核捕获陷阱并着手于整数到浮点方式的转变。
与用户空间进程不同,内核并不能完美地支持浮点操作,因为它本身不能陷入。在内核中使用浮点数时,除了要人工保存和恢复浮点寄存器,还要其他一些琐碎的事情要做。如果要直接了当地回答,那就是:别这么做了,除了极少地情况,不要再内核中使用浮点操作。
容积小而固定的栈
内核栈的准确大小随体系结构而变。在x86上,栈的大小在编译时配置,可以是4KB也可以是8KB。从历史上说,内核栈的大小是两页,这就意味着,32位的机的内核栈是8KB,而64位机是16KB,这是固定不变的。每个处理器都有自己的栈。
同步和并发
内核很容易产生竞争条件。和单线程的用户程序不同,内核的许多特性都要求能够并发地访问共享数据,这就要求有同步机制以保证不出现竞争条件,特别是:
- Linux是抢占多任务操作系统。内核的进程调度程序即兴对进程进行调度和重新调度。内核必须和这些任务同步。
- Linux内核支持对称多处理系统(SMP)。所以,如果没有适当的保护,同时在两个或两个以上的处理器上执行的内核代码很可能会同时访问共享的同一资源。
- 中断是异步到来的,完全不顾及当前正在执行的代码。也就说,如果不加以适当的保护,中断完全有可能在代码访问资源的时候到来,这样,中断处理程序就有可能访问同一资源。
- Linux内核可以抢占。所以,如果不加以适当的保护,内核中一段正在执行的代码可能会被另一段代码抢占,从而有可能导致几段代码同时访问相关的资源。
常用的解决竞争的办法是自旋锁和信号量。后面介绍。
可移植性的重要性
尽管用户空间的应用程序不太注意移植问题,然后Linux却是一个可移植的操作系统,并且要一直保持这种特点。也就是说,大部分C代码应该与体系结构无关,在许多不同体系结构的计算机上都能够编译和执行,因此,必须把与体系结构相关的代码从内核代码树的特定目录中适当分离出来。
诸如保持字节顺序、64位对其、不假定字长和页面长度等一系列准则都有助于移植性。
Linux源码分析
Linux源码结构分析
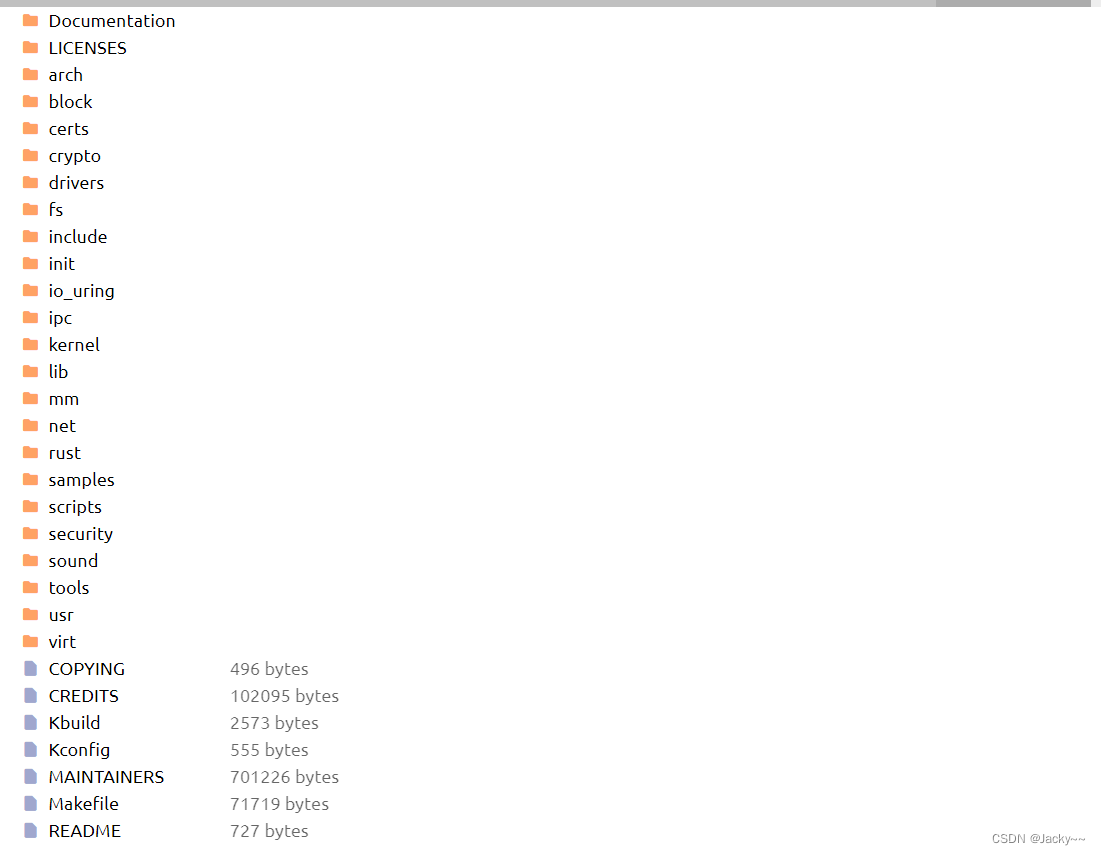
Linux Source Code
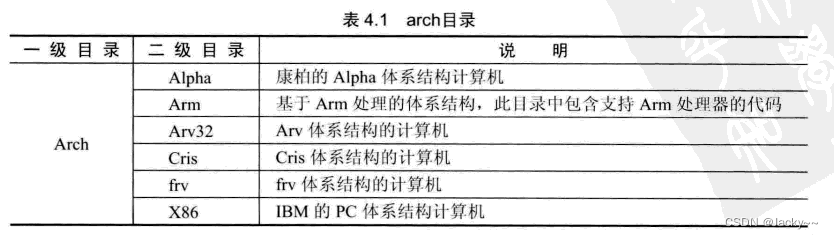
arch目录
包含与体系结构相关的代码,每种平台都有一种相应的目录,常见目录如下表:
drivers目录
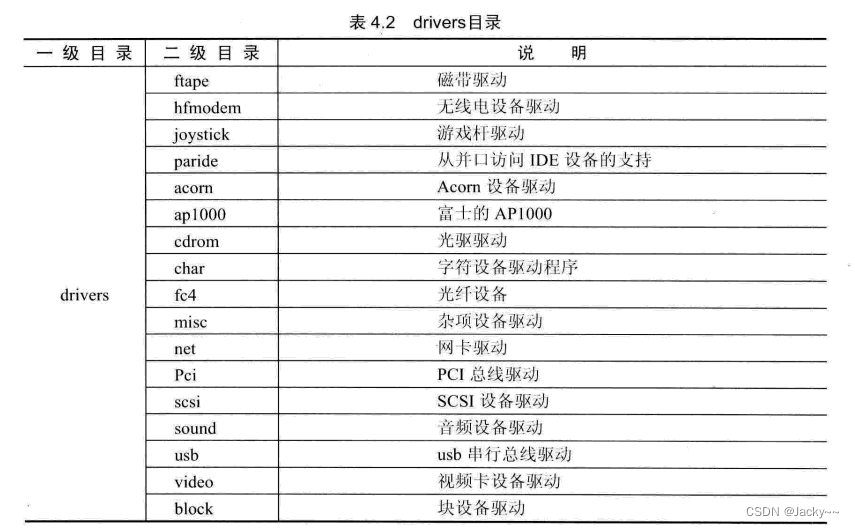
包含Linux内核支持的大部分驱动程序。每种驱动程序都占用一个子目录。目录中包含了驱动的大部分代码,这些代码和目录功能如下表所示:
注:这本书比较老了,是基于的Linux 2.6.30版本。具体的大家参考上面的Linux源码网页进行参考学习。
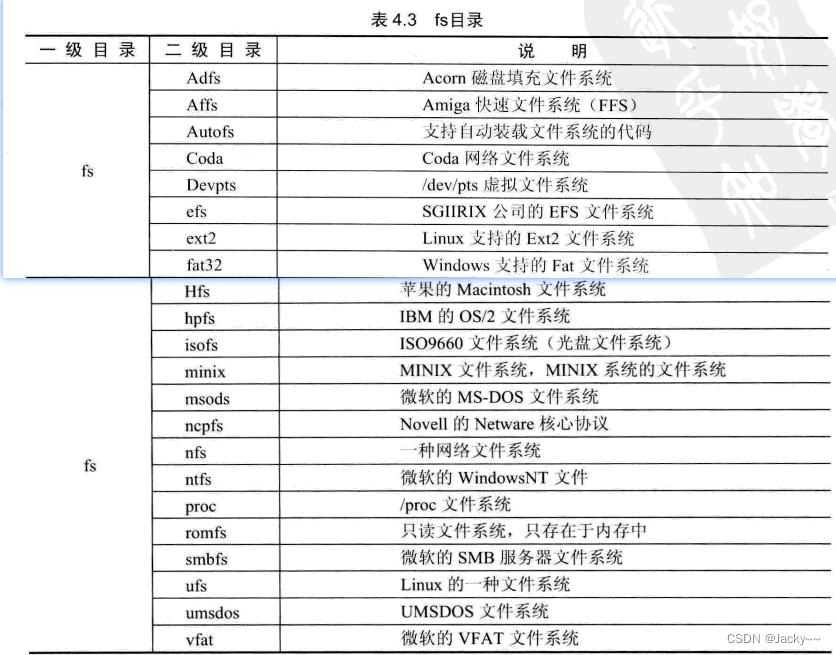
fs目录
fs目录中包含了Linux所支持的所有文件系统相关的代码。每个子目录中包含一种文件系统,例如msods和ext3。Linux几乎支持目前所有的文件系统,如果发现一种没有支持的新文件系统,那么可以很方便地在fs目录中添加一个新的文件系统目录,并实现一种文件系统。fs目录详细内容如下表:
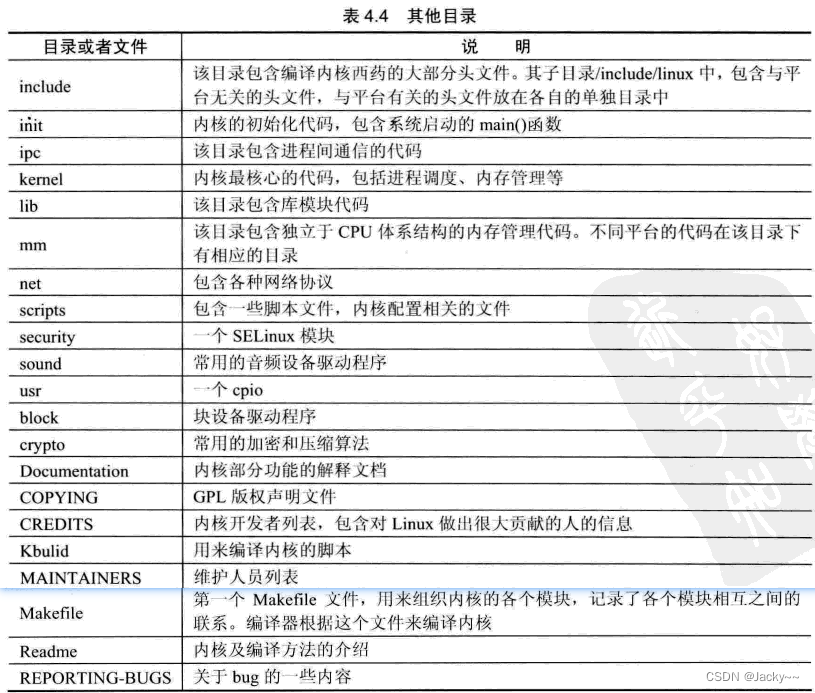
其他目录
除了上面介绍的目录外,内核中还有其他一些重要的目录和文件。每一个目录和文件都有自己特殊的功能,下面对这些目录和文件进行简单介绍:
内核配置选项
自己构建嵌入式Linux操作系统,首先需要对内核源码进行相应的配置。这些配置决定了嵌入式Linux系统所支持的功能,为了理解编译程序是怎样通过配置文件配置系统的,我们需要理解配置编译过程。
配置编译过程
面对日益庞大的Linux内核源码,要手动地编译内核是十分困难的。幸好Linux提供了一套优秀的机制,简化了内核源代码的编译。这套机制由以下几方面组成。
Makefile文件:他的作用是根据配置的情况,构造出需要编译的源文件列表,然后分别编译,并把目标代码链接到一起,最终形成Linux内核二进制文件。由于Linux内核源代码是按照树形结构组织的,所以Makefile也被分布在目录树中。Kconfig文件:作用是为用户提供一个层次化的配置选项集。make menuconfig命令通过分布在各个子目录中的Kconfig文件构成用户配置界面。配置文件(.config):当用户配置完后,将配置信息保存在.config文件中。配置工具:包括配置命令解释器(对配置脚本中使用的配置命令进行解释)和配置用户界面(提供基于字符、基于Ncurses图形界面以及基于Xwindows图形界面的用户配置界面,各自对应于Make config、Make menuconfig和make xconfig)。
这套机制在目录中的位置如下图:
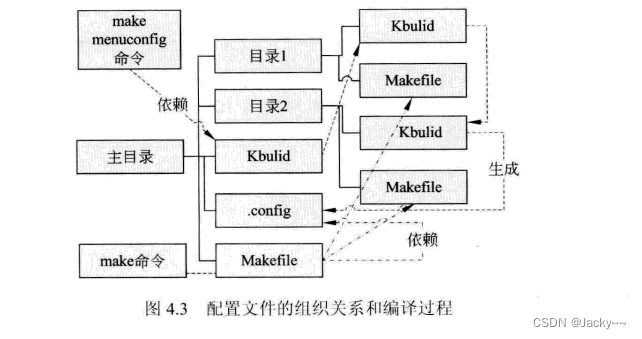
从图中可知,主目录中包含很多子目录,同时包含Kbuild和Makefile文件。各子目录中也包含其他子目录和Kbuild和Makefile文件。当执行make menuconfig命令时,配置程序会依次从目录由浅入深查找每个Kbuild我呢见,按照这个我呢见中的数据生成一个配置菜单。从这个意义上来说,Kbuild像是一个分布在各个目录中的配置数据库,通过这个数据库可以生成配置菜单。在配置菜单中根据需要配置完成后会在主目录下生成一个.config文件,此文件中保存了配置信息。
然后执行make命令时,会依赖生成的.config文件,以确定那些功能将编译入内核中,那些功能不编译进内核中。然后递归地进入每一个目录,寻找Makefile文件,编译相应的代码。
常规配置
常规配置包含关于内核的大量配置,这些配置包含代码成熟度、版本信息、模块配置等。
常规配置选项包含了一些通过配置,主要与进程相关,例如进程的通信、进程的统计等。这些配置的详细信息如下:
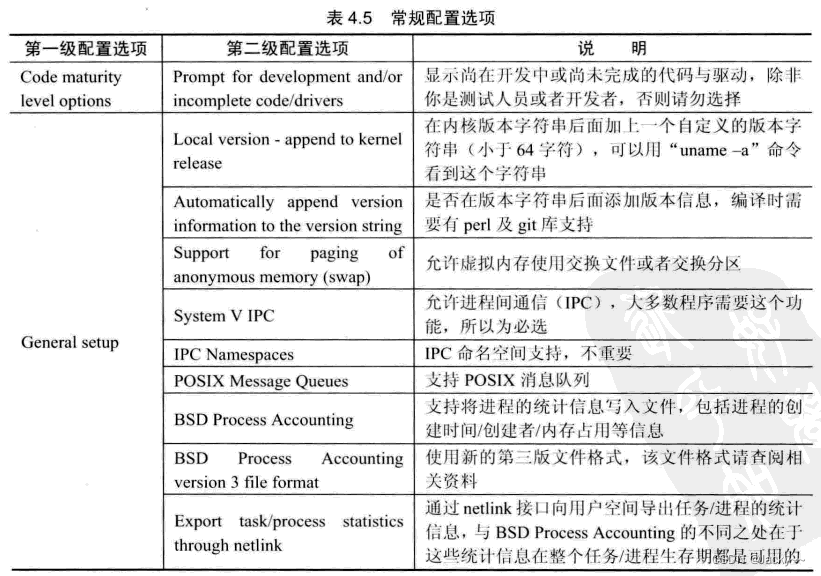
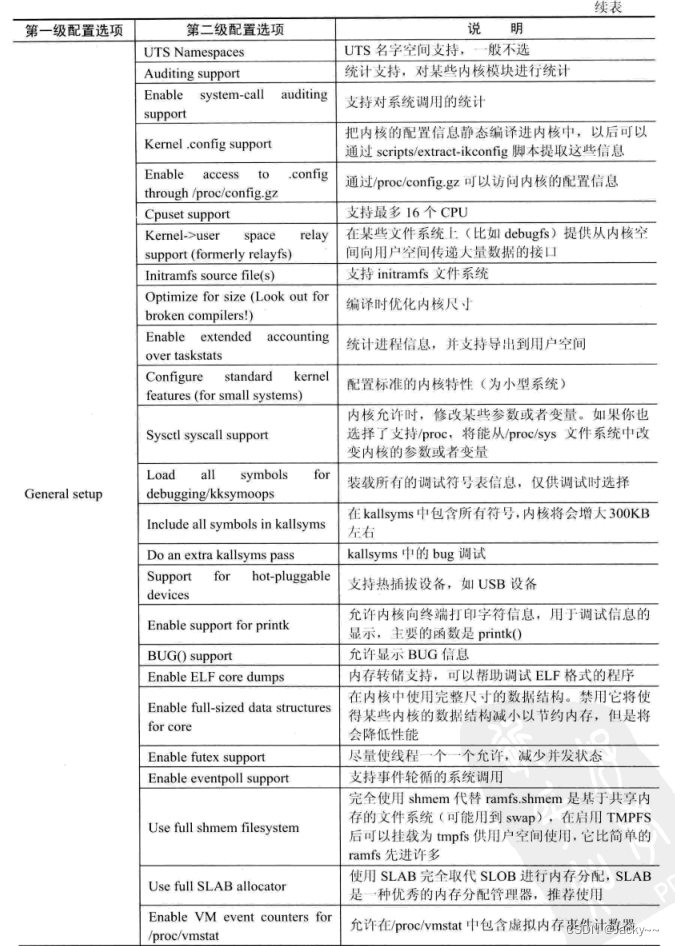
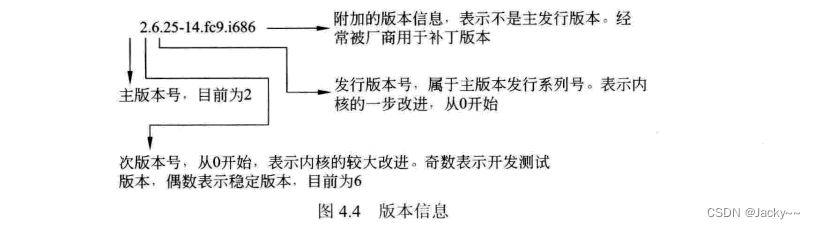
版本信息
上述Local version-append to kernel release选项用来配置版本信息,Linux的版本信息格式如下:
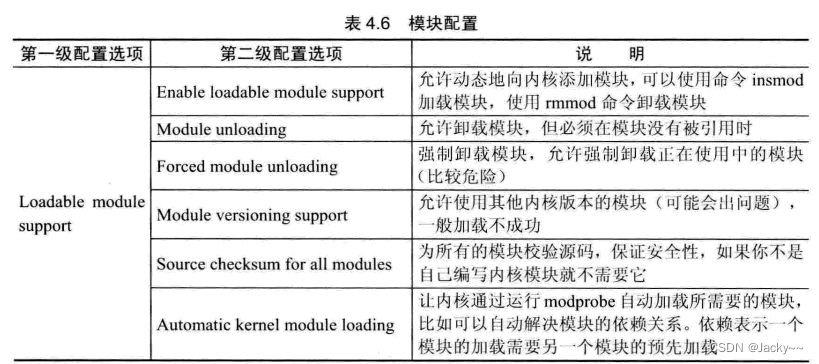
模块配置
模块时非常重要的Linux组件,有很多参数和功能可以配置,其配置的含义如下表
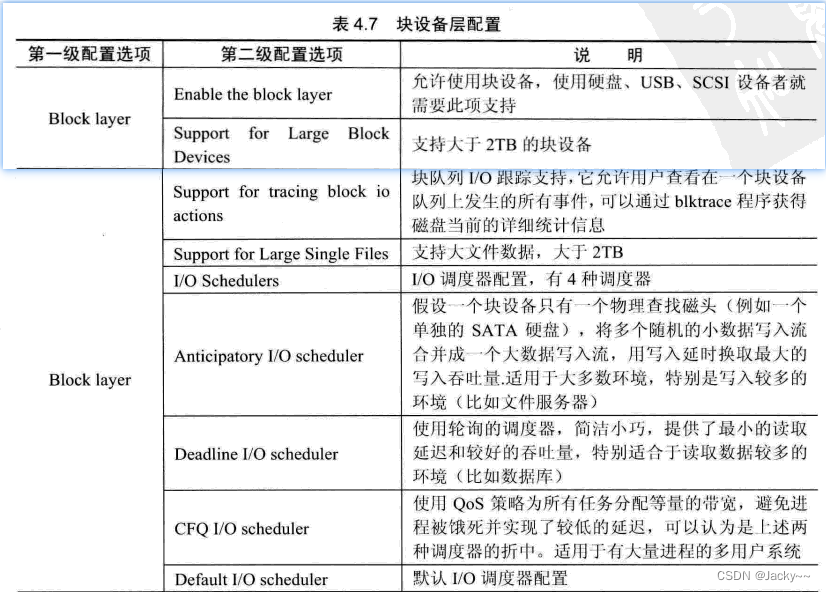
块设备层配置
块设备层包含对系统使用的块设备的配置,主要包含调度器的配置,硬盘设备的配置。详细的配置信息如下:
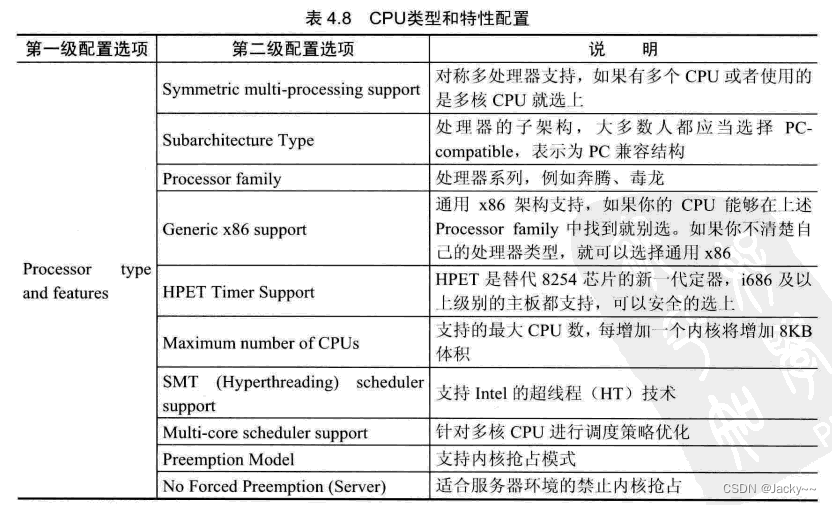
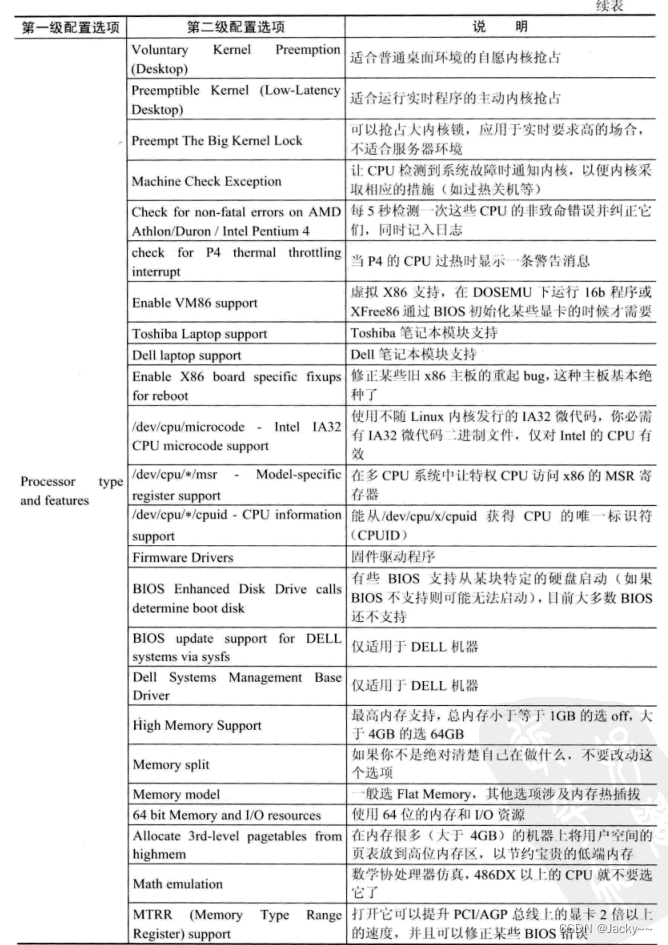
CPU类型和特性配置
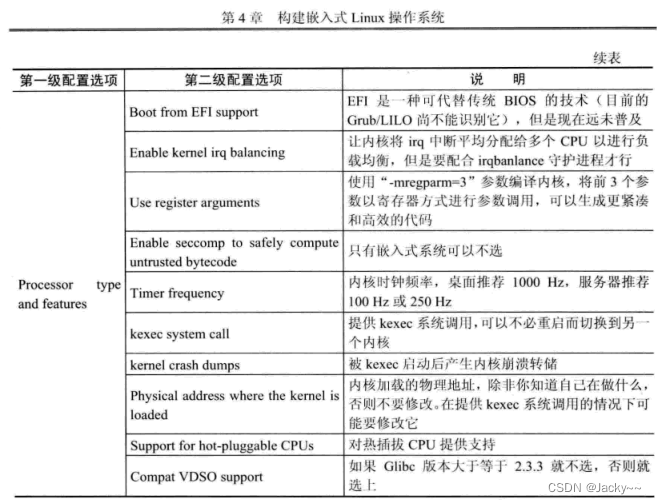
Linux内核几乎支持所有体系结构上的CPU。内核不能自动识别相应的CPU类型和一些相关的1特性,需要在配置内核时根据实际情况进行相应的配置。常用配置如下:
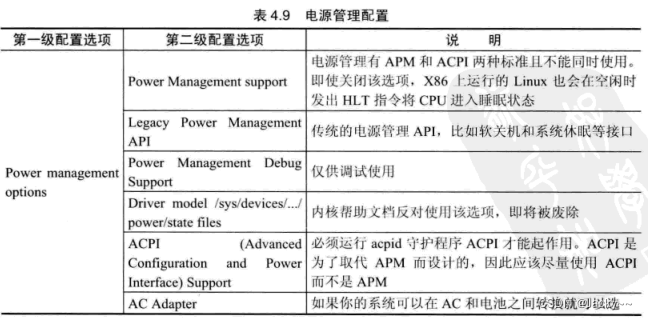
电源管理配置
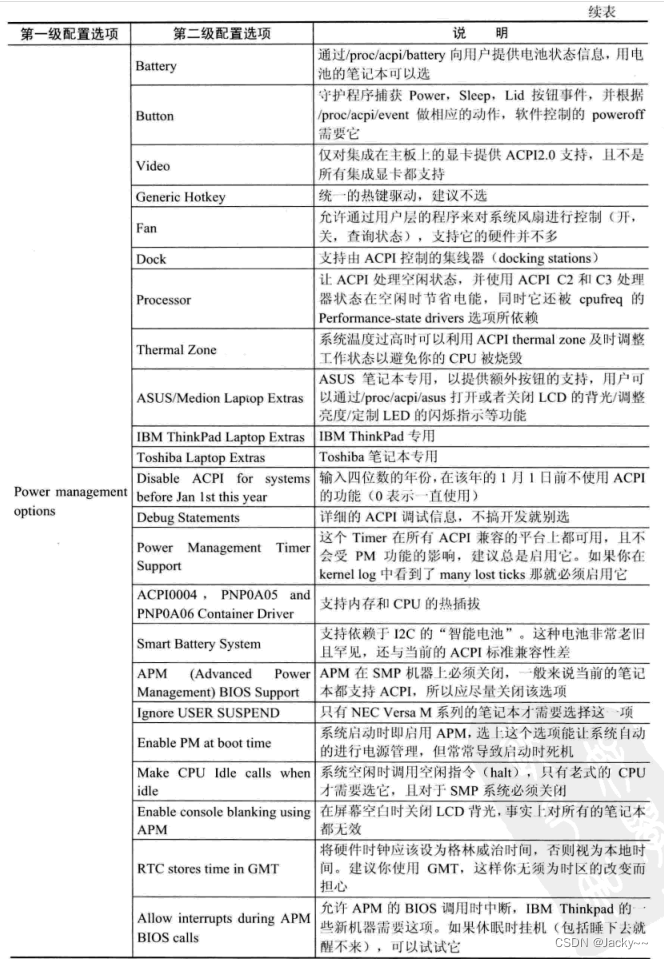
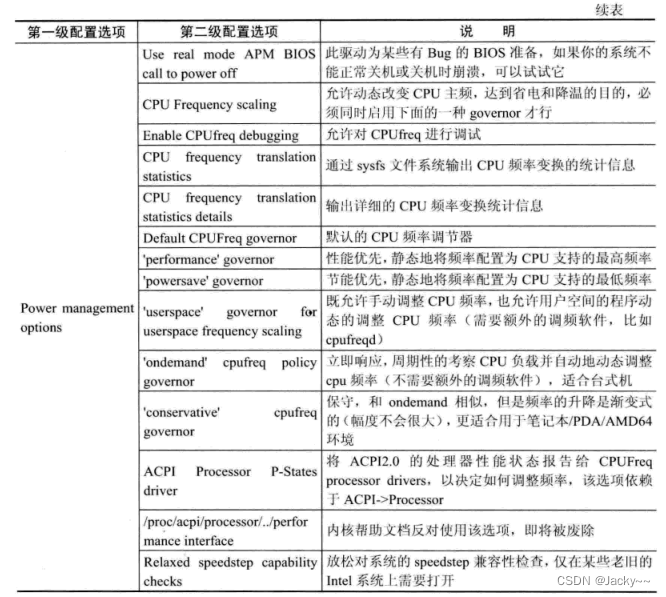
电源管理是操作系统中一个非常重要的模块,随着硬件设备省电节能能力的增强,该模块越来越重要。在嵌入式系统中,由于一般以电池供电,有低功耗的要求,所以在为嵌入式系统配置内核时,需要对相应的硬件配置电源管理模块,常用的电源管理配置选项如下表:
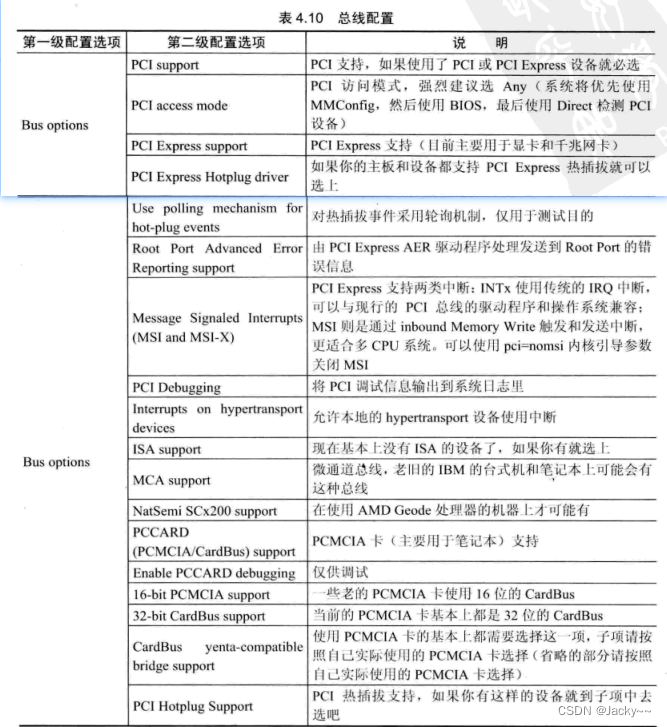
总线配置
嵌入式系统中可能包含很多总线,常见的总线有PCI总线、ISA总线、MCA总线等。不同的嵌入式系统包含不同的总线,需要对其支持的总线进行设置。参考下表:
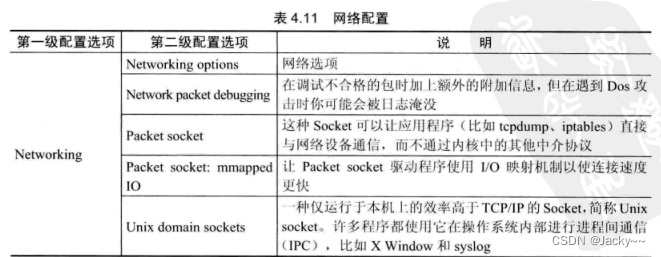
网络配置
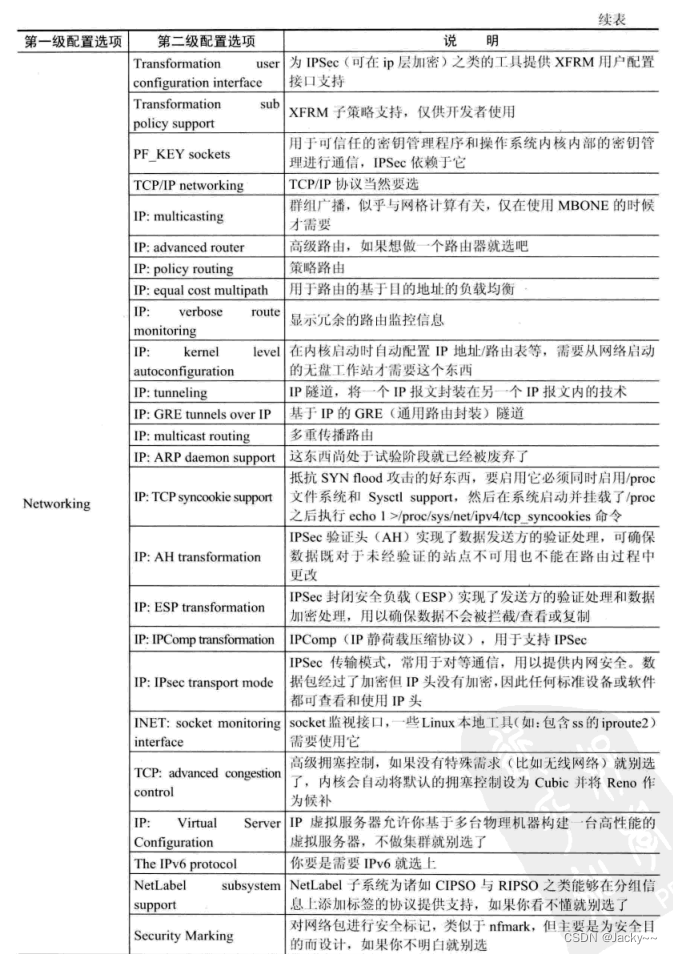
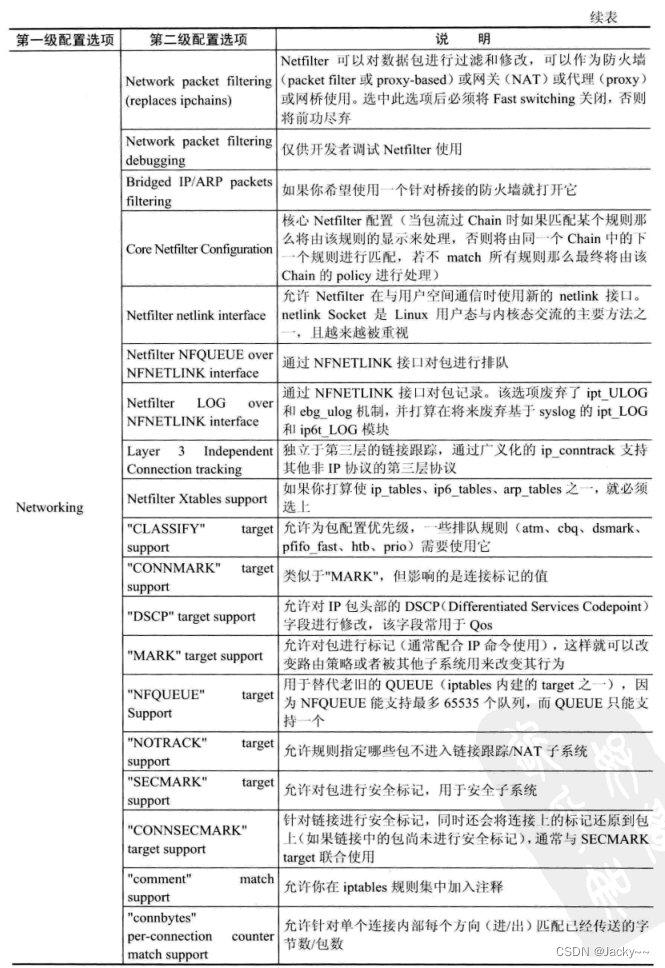
网络是嵌入式系统与外部通信的主要方式。目前,许多嵌入式设备都具备网络功能,为了使内核支持网路功能,需要对其做一些特殊的配置。常用的配置选项参考下图:
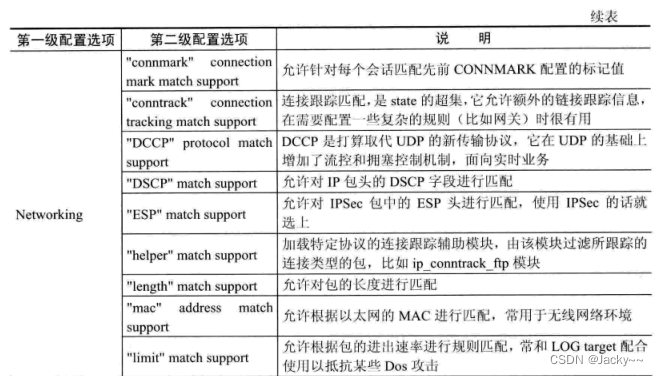
设备驱动配置
Linux内核实现了一些常用的驱动程序,如鼠标、键盘、常见的U盘驱动等。这些驱动非常繁多,许多驱动对于嵌入式系统来说,并不需要。在实际应用中,为了使配置的内核高效和小巧,只需要配置主要的一些驱动程序,这些驱动程序的配置选项如下:
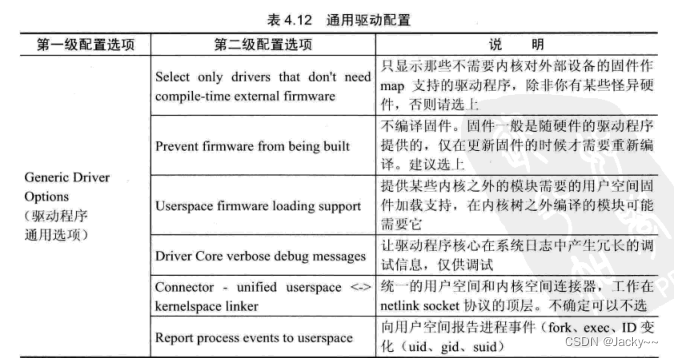
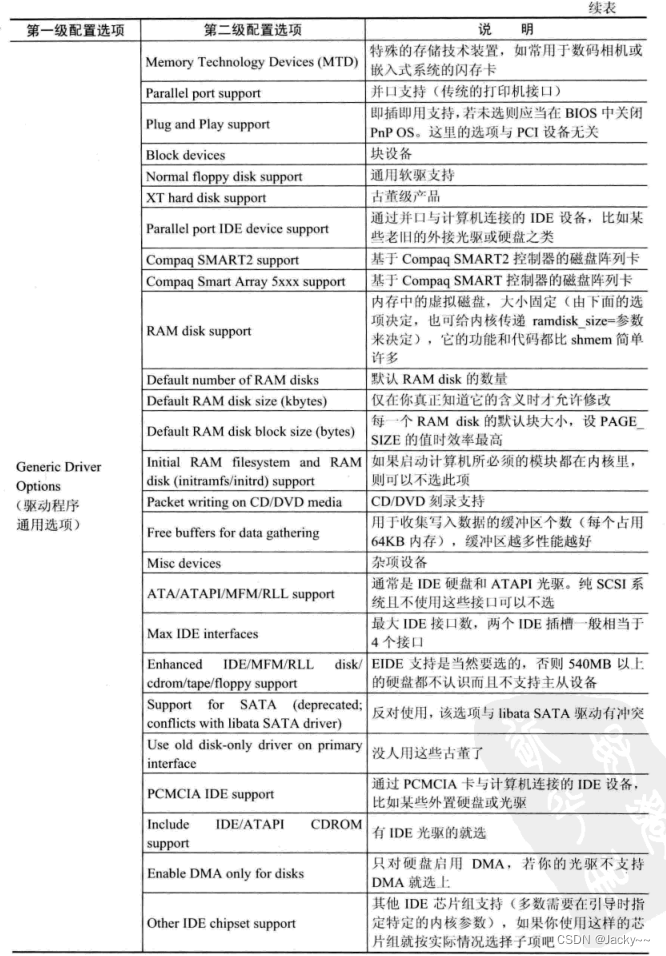
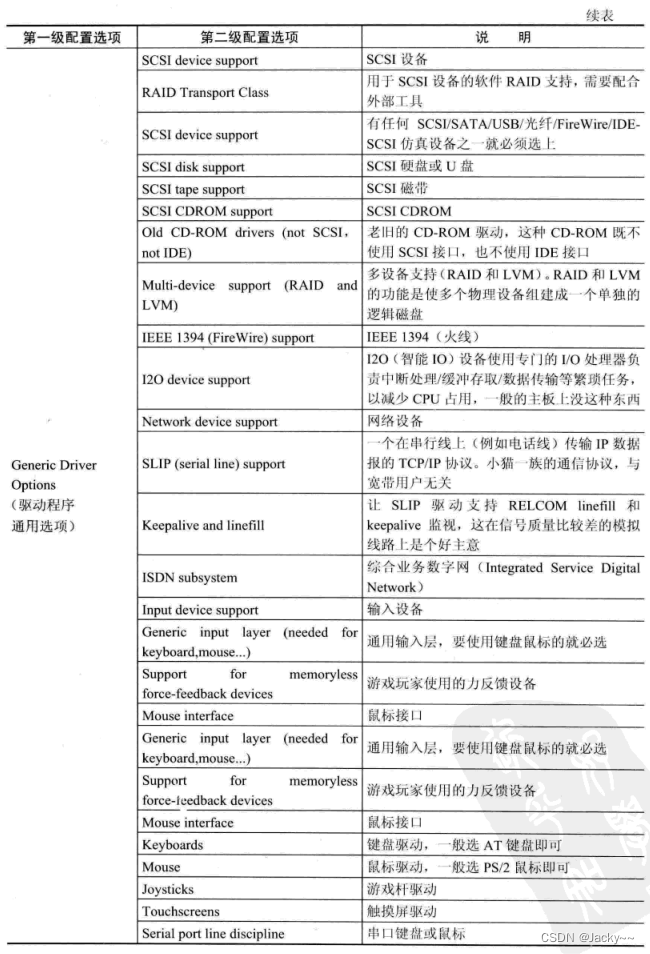
通用驱动配置
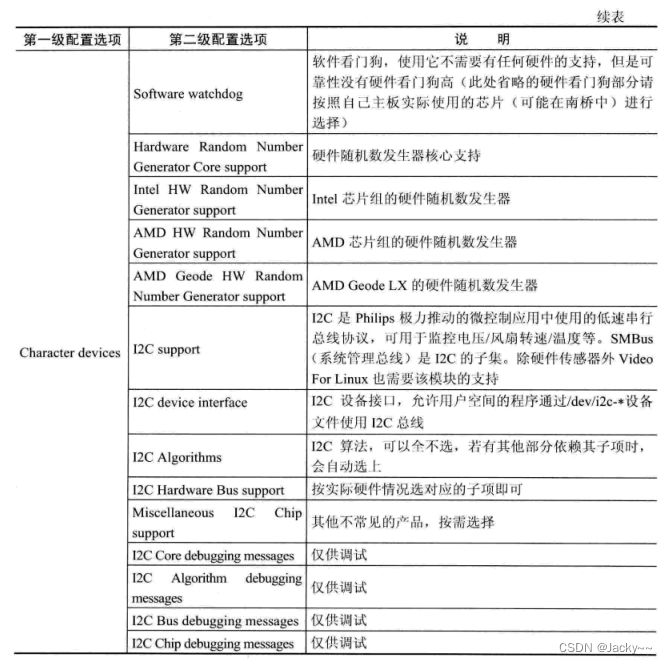
字符设备配置
字符设备驱动程序是一种常见的驱动程序,为了对这种驱动程序进行支持,内核提供了一些配置选项来设置,参考下图

多媒体设备驱动配置
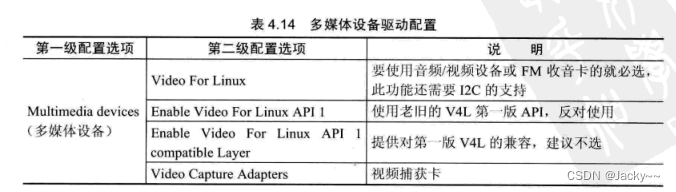
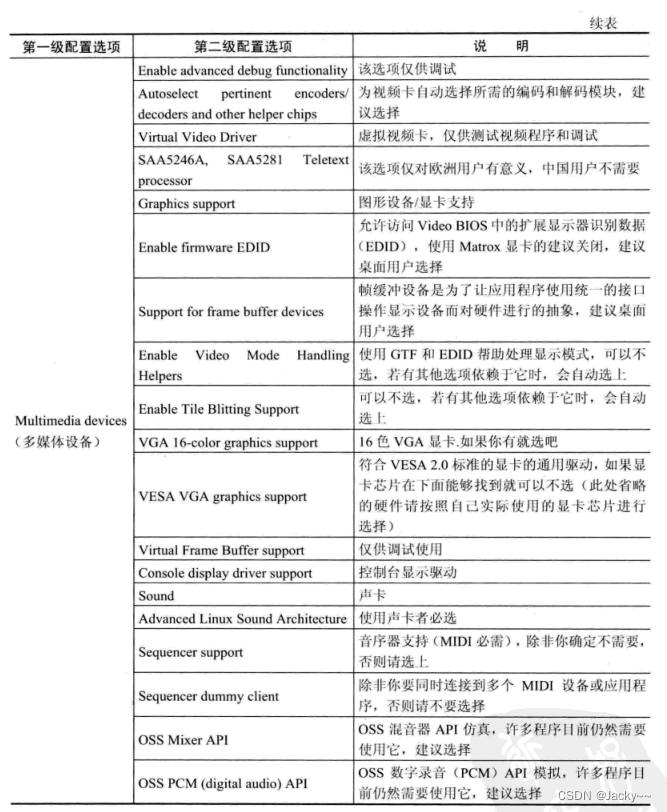
如果嵌入式系统需要多媒体功能,例如音乐、视频等功能,就需要配置多媒体驱动,常用的配置如下表:
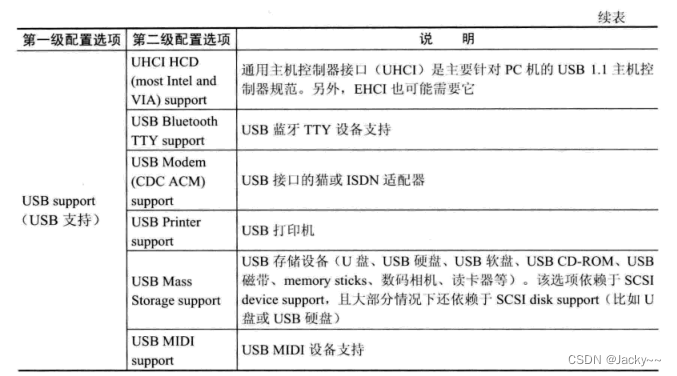
USB设备驱动配置
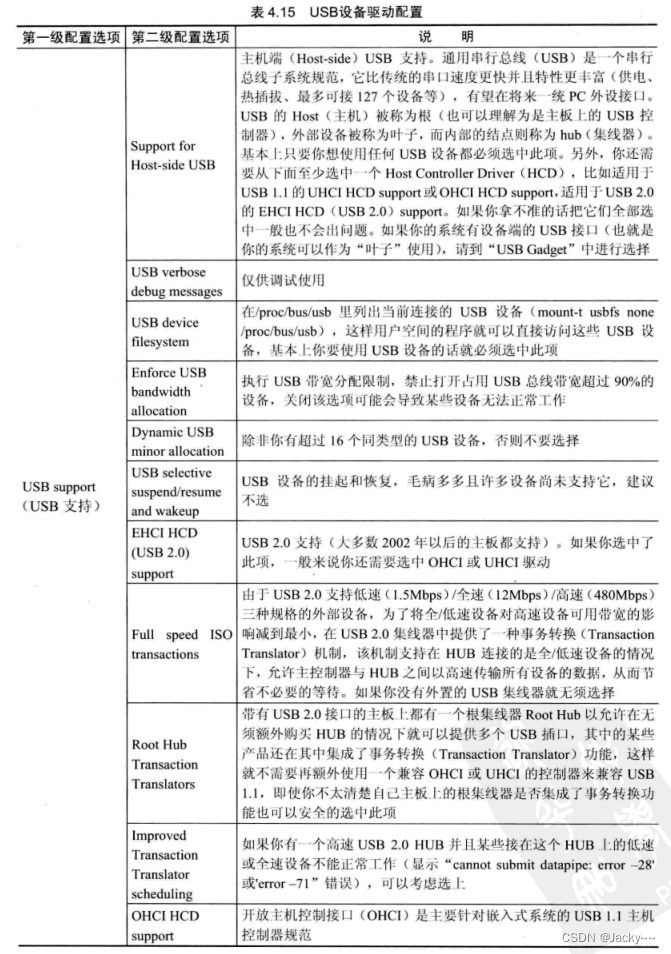
在嵌入式系统中,有些设备是通过USB总线来连接的,这时候,就需要USB设备驱动程序。Linux内核实现了USB驱动的一个框架,驱动开发人员利用这个框架可以容易地写出USB驱动程序来。对于是否支持USB设备驱动,内核也可以进行配置,常用的配置选项如下:
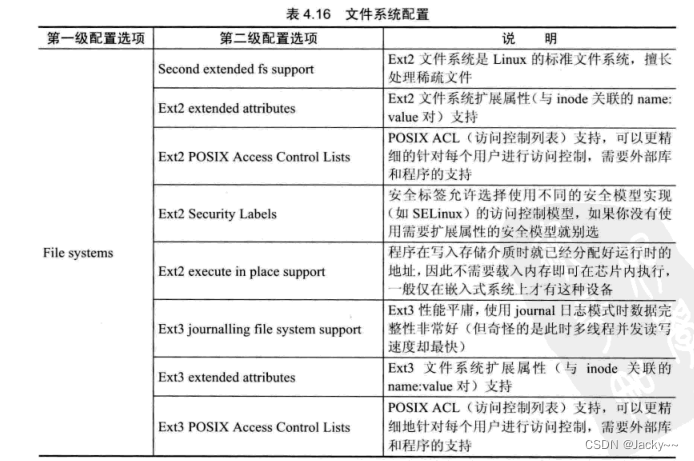
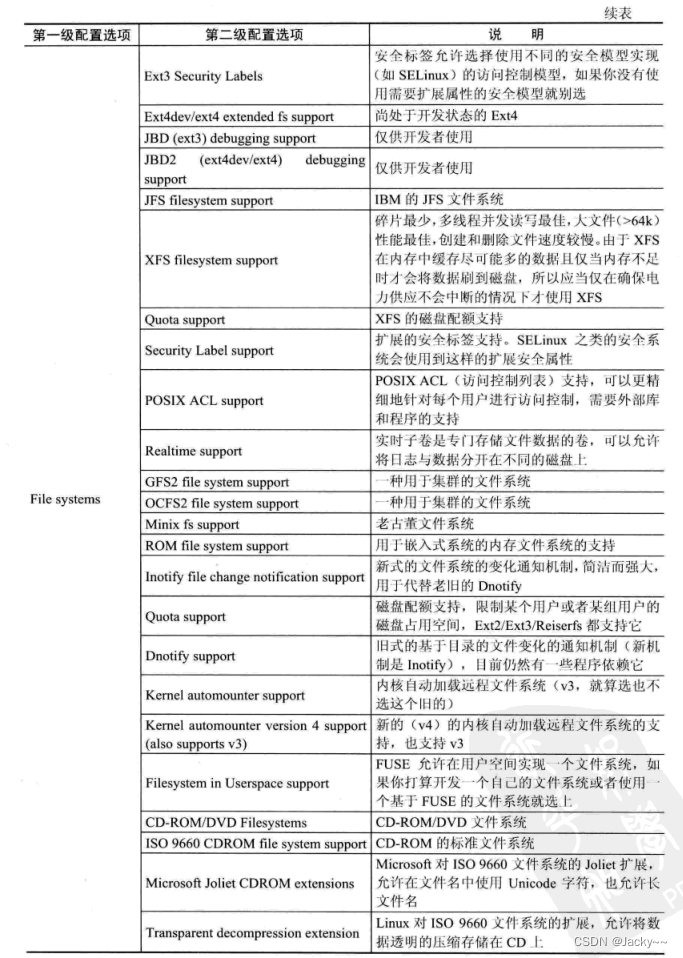
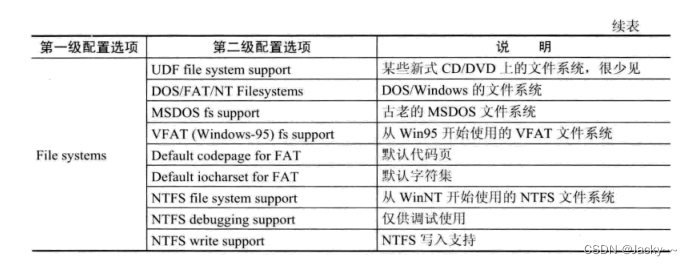
文件系统配置
文件系统是操作系统的主要组成部分。Linux支持很多文件系统,为了内核的高效和小巧性,支持那些文件系统都是可以配置的,常用的配置选项如下:
嵌入式文件系统基础知识
对于嵌入式系统来说,除了一个嵌入式操操作系统之外,还需要一个嵌入式文件系统来管理和存储数据和程序。目前,嵌入式Linux操作系统支持很多种文件系统,具体使用那种文件系统需要根据存储介质、访问速度、存储容量等来选择。
嵌入式文件系统
Linux支持多种文件系统,包括ext2、ext3、ext4、vfat、ntfs、iso9600、jffs、roomfs、cramfs和nfs等。为了对各类文件系统进行统一管理,Linux引入了虚拟文件系统VFS(Virtual File System),为各类文件系统提供一个统一的操作界面和应用编程接口。Linux文件系统的结构如下所示:
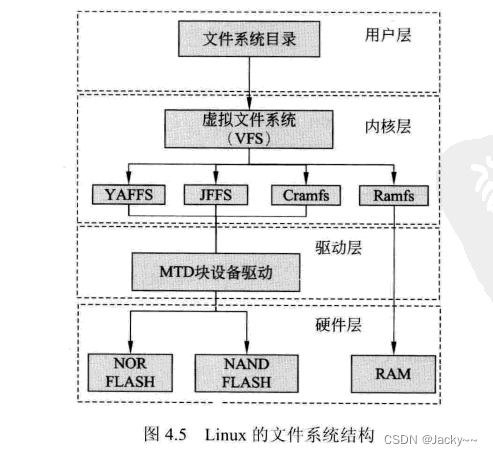
Linux文件系统结构由4层组成,分别是用户层、内核层、驱动层和硬件层。用户层为用户提供一个操作接口,内核层实现了各种文件系统,驱动层是块设备的驱动程序,硬件层是嵌入式系统使用的几种存储器。
在Linux文件系统结构种,内核层的文件系统实现是必须的。Linux启动时,第一个必须挂载的是根文件系统;若系统不能从指定设备上挂载根文件系统,则系统会出错而退出启动。当根文件系统挂载成功后,才可以全自动或手动挂载其他的文件系统。因此,一个系统种可以同时存在不同的文件系统。
不同的文件系统类型有着不同的特点,因而根据存储设备的硬件特性、系统需求等有不同的应用场合。在嵌入式Linux应用种,主要的存储设备为RAM(DRAM,SDRAM)和ROM(常采用FLASH存储器),常用的基于FLASH存储设备的文件系统类型包括jffs2、yaffs、cramfs、roomfs、ramdisk和ramfs/tmpfs等。
嵌入式系统的存储介质
Linux操作系统支持大量的文件系统,在嵌入式领域,使用那种文件系统需要根据存储的芯片的类型来决定。目前市场上,嵌入式系统主流的两种存储介质是NOR和NAND Flash.Intel公司于1988年首先开发了NOR Flash存储器。NOR Flash的特点是芯片内执行(XIP, eXecute In Place),这样应用程序可以直接在Flash闪存内运行,不必再把代码读到系统RAM中。NOR的传输速率很高,在1MB~4MB的小容量时具有很高的成本效益,但是很低的写入和擦除速度大大影响到它的性能。
1989年,东芝公司开发了NAND Flash存储器。NAND Flash与NOR Flash相比,NAND Flash能提供极高的单元密度,可以达到高存储密度,并且写入和擦除的速度也很快。两者比较如下:
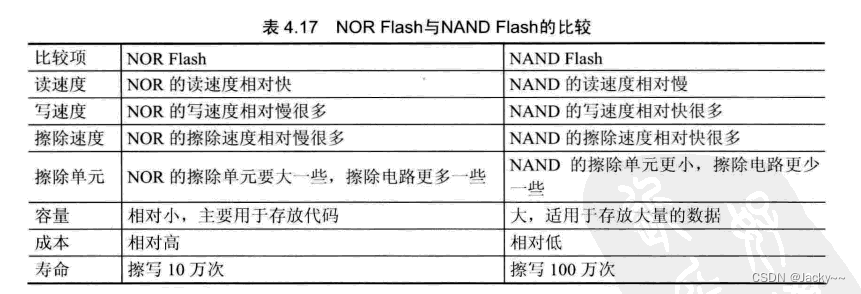
总的来说,NOR FLash比较适合存储代码,其容量小,而且价格较高。NAND Flash容量比较大,价格也相对便宜,比较适合存放数据。
JFFS文件系统
瑞典的Axis Communications公司基于Linux 2.0的内核,为嵌入式操作系统开发的JFFS文件系统。其升级版JFFS2是RedHat公司基于JFFS开发的内核闪存文件系统,最初是针对RedHat公司的嵌入式产品eCos开发的嵌入式文件系统,所以JFFS2也可以用于在Linux、uCLinux等操作系统中。JFFS的全称是日志闪存文件系统。
JFFS文件系统主要用于NOR型Flash存储器,其基于MTD驱动层。这种文件系统的特点是:可读可写的、支持数据压缩的、基于哈希表的日志型文件系统,并提供了崩溃/掉电安全保护,提供“写平衡”支持等等。缺点主要是当文件系统已满或接近满时,因为垃圾收集的关系jffs2的运行速度大大放慢。
目前JFFS3正在开发中。关于JFFS系列文件系统的使用详细文档,可参考MTD补丁包中mtd-jffs-HOWTO.txt。
JFFS文件系统不适合用于NAND型Flash存储器。主要是因为NAND闪存容量一般较大,这样导致JFFS为维护日志节点所占用的空间内存迅速增大。另外,JFFS文件系统挂载时需要扫描整个Flash的内容,以找出所有的日志节点,建立文件结构,对于大容量的NAND闪存会耗费大量时间。
YAFFS文件系统
YAFFS是第一个专门为NAND Flash存储器设计的嵌入式文件系统,适用于大容量的存储设备;并且是在GPL(General Public License)协议下发布的,可在其网站免费获得源代码。YAFFS文件系统有4个优点,分别是速度快、占用内存少,不支持压缩和只支持NAND Flash存储器。
YAFFS文件系统中,文件是以固定大小的数据块进行存储的。块的大小可以是512B、1024B或者2048B。每个文件(包括目录)都由一个数据块头和数据组成。数据块头中保存了ECC校验码和文件系统的组织信息,用于错误检测和坏块处理。YAFFS文件系统充分考虑了NAND Flash的特点,把每个文件的数据块头存储在NAND Flash的16B备用空间中。
当文件系统被挂载时,只须扫描存储器的备用空间就能将文件系统信息存入内存,并且驻留在内存中,不仅加快了文件系统的加载速度,也提高了文件的访问速度,但是增加了内存的消耗。
选择哪一种文件系统需要根据Flah存储器的类型来确定。Flash存储器类型主要有NOR和NAND Flash。根据存储器类型,NOR Flash存储器比较适用于JFFS。NAND Flash存储器比较适用于YAFFS。
构建根文件系统
当内核启动后,第一件要做的事情就是到存储设备上找到根文件系统。根文件系统包含了使系统运行的主要程序和数据。
根文件系统概述
根文件系统是Linux操作系统运行需要的一个文件系统。根文件系统被存储在Flash存储器中,存储器被分为多个分区,例如分区1、分区2、分区3等,如下图所示:
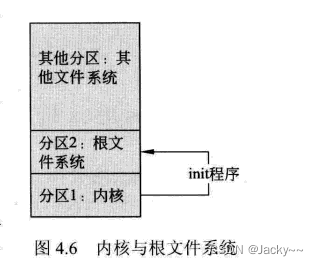
分区1一般存储Linux内核映象文件,在Linux操作系统中,内核映象文件一般存储在单独的分区中。分区2存放根文件系统,根文件系统中存放着系统启动必须的文件和程序。这些文件和程序包括:提供用户界面的Shell程序、应用程序依赖库、配置文件等。
其他分区上存放普通的文件系统,也就是一些数据文件。操作系统的运行并不依赖于这些普通文件。内核启动后运行的第一个程序是init,其将启动根文件系统中的shell程序,给用户提供一个友好的操作界面。这样系统就能够按照用户的需求正确地运行了。
Linux根文件系统目录
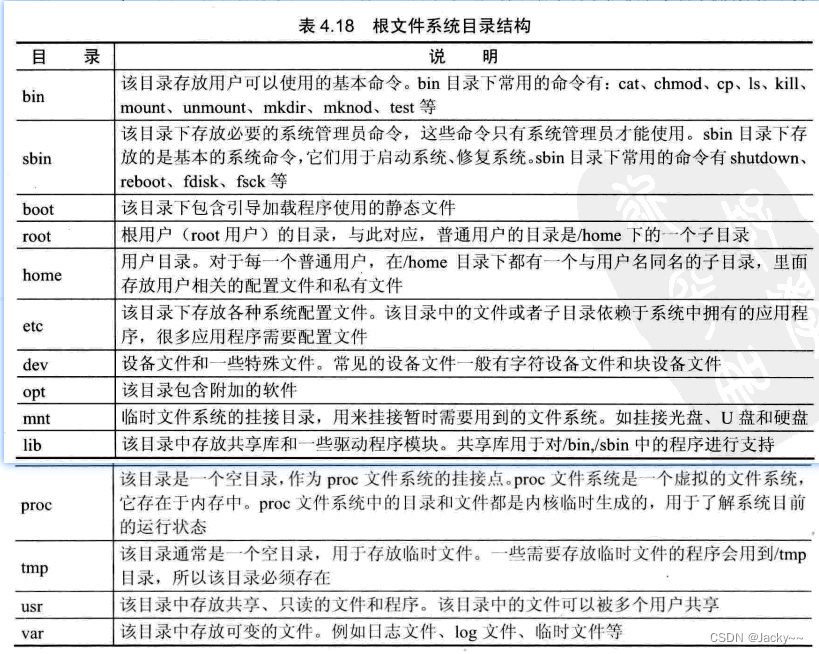
根文件系统以树形结构来组织目录和文件的结构。系统启动后,根文件系统被挂载到根目录"/"上,这时根目录下就包含了根文件系统过的各个目录和文件,例如/bin、/sbin、/mnt等。根文件系统应该包含的目录和文件遵循FHS标准(Filesystem Hierarchy Standard,文件系统层次标准)。这个标准包含了根文件系统中最少应该包含那些目录和文件,以及这些目录和文件的组织原则。参考下表。
BusyBox构建根文件系统
要使Linux操作系统能够正常的运行起来,至少需要一个内核和根文件系统。根文件系统除了应该以FHS标准的格式组织外,还应该包含一些必要的命令。这些命令提供给用户使用,以使用户能方便地操作系统。
一般来说构建文件系统地方法有两种。第一种方法是下载相应地命令源码,并移植到处理器架构平台上,除了一些必须地命令外,用户可以定制一些非必要地命令。第二种方法是使用一些开源地工具构建文件系统。例如BusyBox、TinyLogin和Embuilts。其中BusyBox是最常用的一个工具,下面对这个工具进行简要介绍。
BusyBox概述
BusyBox是一个用来构建根文件系统地工具。这个工具最初于1996年开始开发,当时嵌入式系统并没有开始流行。BusyBox最初的目的是自动构建一个能够在软盘上运行的命令系统。因为当时还没有可以移动的大容量可擦写存储介质,软盘是最常用的存储介质。BusyBox可以把常见的Linux命令打包编译称一个单一的可执行文件。通过建立链接,用户可以像使用传统的命令一样使用BusyBox。
在台式PC上,Linux操作系统中的每个命令都是一个单独的二进制文件。在嵌入式系统中,如果每个命令都是一个单独的文件,会增加整个根文件系统的大小,并且会使加载命令的速度变慢。这对于存储要求比较严格的嵌入式系统来说是不好的。BusyBox解决了这个问题,它能够以一个极小的应用程序来提供整个命令集的功能,而且需要那些命令不需要那些命令是可以配置的。
BusyBox的出现是基于Linux共享库。对于大多数Linux工具来说,不同的命令可以共享许多东西。如查找文件的命令grep和find,虽然功能不完全相同,但是两个程序都会用到文件系统搜索文件的功能,这部分代码可以是相同的。BusyBox的聪明之处在于把不同工具的代码,以及公用的代码都集成到一起,从而大大减小了可执行文件的体积。
BusyBox实现了许多命令,这些命令包括ar、cat、chgrp、chmod、chown、chroot、cpio、cp、date、df、dd、demesg、du、echo、env、expr、find、grep、gunzip、gzip、halt、id、ifconfig、init、insmod、kill、killall、ln、ls、lsmod、mkdir、mknod、modprobe、more、mount、mv、ping、ps、pwd、reboot、renice、rm、rmdir、rmmod、route、sed、sync、syslogd、tail、tar、telnet、tfp、touch、tracerout、umount、vi、wc、which和whoami等。