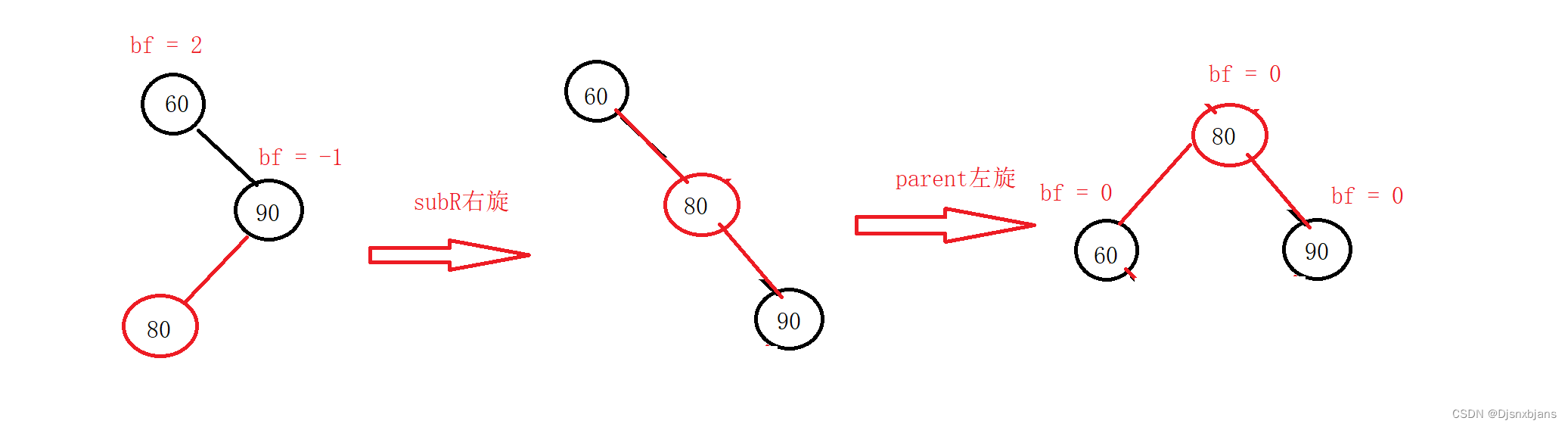
Auto-GPT 的出现,意味着 AI 已经能够在没有人工干扰的情况下独立地完成目标任务。这个在 GitHub 中不断创造历史的项目,正以惊人的速度发展着、变化着。
这样前沿又带有科幻色彩的技术项目,引起了各方关注,开发者、投资人、媒体人,难掩对 Auto-GPT 的热情。作为相关领域的技术开发者,我们自然也不例外。
今天,我们将带着对它连月以来的探索和实践,和大家探讨 Auto-GPT 的背后原理、局限性及其背后的解决方案。
Auto-GPT 究竟是什么?
Auto-GPT 是一个开源的自动化人工智能的实验项目,利用 LLM 来拆分任务与计划任务,并配合附属的额外可执行指令来达成用户提供的目标。
通俗点来理解,Auto-GPT 使用以 GPT 为代表的大语言模型(LLM)和人类反馈来分析和分解大型任务,并将特定的命令分配给这些已被分解的小任务且自动执行,同时命令执行结果又会作为下一轮认知处理的输入。上述程序会重复进行,直到 Auto-GPT 完成任务。
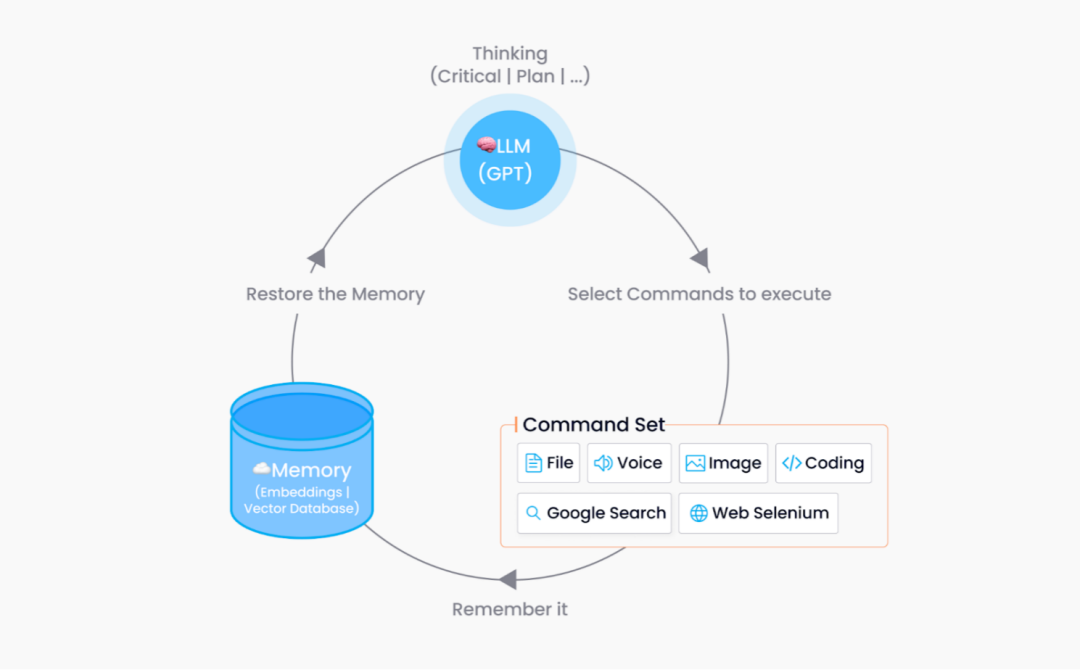
由此,我们便可以认识到,Auto-GPT 整体有两个核心部分:LLM 和命令集。一方面, LLM(如 GPT),负责认知处理。另一方面,Auto-GPT 内置了非常多命令组件,比如文件读写、代码分析、搜索能力、网页分析等等。加之 Auto-GPT 目前支持第三方的插件式开发,命令集得以大大拓展。据悉,目前它已经可以支持向必应、百度等进行搜索。有趣的是,这些插件和命令很多也是依赖于大语言模型得以实现,例如网页和代码分析能力等。
可以说,LLM 就是 Auto-GPT的“大脑”,叠加各种插件 buff 加成的命令集就像是 Auto-GPT的“手”和“感官”,它们相互配合,使得一切井然有序。
向量数据库——当下最为流行的 Memory 增强神器
虽然 Auto-GPT 可以自动执行任务,但它在理解信息和存储上下文方面仍有一定的局限性。
在自主 AI 程序中,为了完成用户设定的目标,必然会产生多个步骤。然而,这些步骤并不能单独发给 GPT 模型,否则将丢失上下文。如果没有上下文,自主程序无法判断当前执行动作是否正确,也就很难向靠近最终的目标。这里的上下文类似于训练模型中的 loss;然而,如果每个步骤都把所有历史消息发送给 GPT 模型,用户设定目标的复杂程度将受到极大的限制。过于复杂的任务必然需要被拆解成更多小步骤进行处理。这会导致自然历史对话变得长,其 token 数量也会增加,使得 token 数量超出 LLM 可处理的范围。
为此,开发者们在 Auto-GPT 中也尝试过两种方案来增强其信息存储和对上下文的理解能力。
其一,使用 LLM 对 Memory 进行 Summary。这是当前 Auto-GPT 正在尝试的一种方案,便于控制 Memory 的规模。其优势不言而喻,即在小规模的情况下可以收获不错的效果,每次传导给大模型的 prompt 概括度会更高。不过,该方案依然会受制于 token 数量,除了成本高昂以外,Auto-GPT 完成的任务复杂度也不会太高。
其二,利用向量数据库来保存 Memory。除了保存记忆,向量数据库也能承担起检索相关 Memory 的角色,流程大致如下:
-
在每个步骤运行完成时,将 command 信息和执行结果数据进行 embedding 操作,插入向量数据库中;
-
在进行下一次任务生成、构建 context 时,获取历史窗口中的消息;
-
将上述历史消息全部作为向量数据库搜索的输入,然后获取
topk的历史消息。这些topk的历史消息相对于之前固定窗口的上下文信息跨度将增加。同时,根据这些相似信息,自主程序将得知之前与当前动作类似的执行结果,这样就可判断之前行为对于完成任务是否有益,从而更加准确地生成下一个 command 的信息。
尽管方案二也存在一定的局限性,不过它仍是当前最为通用的一种方案。
如何将【记忆神器】集成到 Auto-GPT 中?
在最近更新的 Auto-GPT 版本中,Auto-GPT 暂时只支持第一种方案来理解上下文,想要体验向量数据库的小伙伴可以使用一个历史版本进行体验,链接为:【https://github.com/SimFG/Auto-GPT】。
在完成上述准备后,大家就可以使用 Milvus 试水了。
作为全球最受欢迎的开源向量数据库的代表,Milvus 能够处理数百万、数十亿向量的大型数据集。因此,有需求的小伙伴可以按照下述方式将 Milvus 与 Auto-GPT 进行集成。
-
拉取 Milvus 的 Docker 镜像并使用 Docker Compose 安装;
https://github.com/milvus-io/milvus/releases/download/v2.2.8/milvus-standalone-docker-compose.yml
docker compose up -d
-
在 python 环境中安装 pymilvus客户端;
pip install pymilvus==2.2.8
-
更新 .env文件。
MEMORY_BACKEND=milvus
当然,如果觉得部署和维护 Milvus 比较麻烦,推荐大家使用 Zilliz Cloud,可以提供开箱即用的向量数据库服务,轻松帮你管理 Auto-GPT 的内存。
Zilliz Cloud 在全球范围内拥有广泛的用户基础,是 OpenAI 指定的 ChatGPT Retrieval 插件提供者。目前已覆盖 AWS、GCP,今年 6 月底即将登陆阿里云,国内其他几朵云也在准备中。
以下是在 Auto-GPT 中使用 Zilliz Cloud 的方法:
-
登陆或注册 Zilliz Cloud 的账号(https://cloud.zilliz.com/signup),现在注册即可获赠价值 400 的 credits;
-
创建一个数据库并获取公共云端点;
-
安装
pymilvus运行pip install pymilvus==2.2.8,用下述命令更新.env文件:
MEMORY_BACKEND=milvus
MILVUS_ADDR=your-public-cloud-endpoint
MILVUS_USERNAME=your-db-username
MILVUS_PASSWORD=your-db-password
写在最后
不可置否,向量数据库为 Auto-GPT 的结合对于增强 Auto-GPT 的能力至关重要。不过,正如前文所言,这背后存在一定的局限性。例如:
-
从向量数据库中获取
top-k消息时没有进行过滤,相似度极低的信息可能会对 GPT 模型产生误导,从而减缓完成预设目标的速度; -
上下文数据只能进行添加和查询,加入清理功能会更好;
-
无法自定义 embedding 模型,目前只能使用 OpenAI 提供的 embedding 接口。
当然,向量数据库和自动化 AI 的结合远不止如此,仍有诸多可能性:
首先,可以想象到的是未来自动化 AI 可能具备自动纠错的能力,在其发现错误后,自动纠错可以通过快照的方式恢复进入错误路线前的记忆。此时,使用向量数据库来为快照恢复以及错误路线提供标记就是一个不错的方案。
其次,当前自动化 AI 的 Memory 结构仍然偏线性,但是现实世界中的复杂业务不太可能被线性地完成,Memory 可能是树状甚至是图状的结构。此时,我们需要整理及存储复杂的 Memory,向量数据库就是一个很好的选择。
再者,存储总是比计算便宜,未来自动化 AI 会产出大量的重复性数据(可能是同一个AI Agent的,也可能是非常多 AI Agent 的重复行为),使用向量数据库作为缓存可以大幅降低成本与提高响应速度。目前,已经有针对响应的解决方案出现,例如 GPTCache(点击了解更多)。
点击获取 Auto-GPT 相关 PPT 和视频讲解。
(本文作者系 Zilliz 软件工程师付邦、叶祯)
-
如果在使用 Milvus 或 Zilliz 产品有任何问题,可添加小助手微信 “zilliz-tech” 加入交流群。
-
欢迎关注微信公众号“Zilliz”,了解最新资讯。

本文由 mdnice 多平台发布