🧑💻作者: @情话0.0
📝专栏:《C++从入门到放弃》
👦个人简介:一名双非编程菜鸟,在这里分享自己的编程学习笔记,欢迎大家的指正与点赞,谢谢!

vector
- 前言
- 一、vector的使用
- 1.1 vector的构造函数声明
- 1.2 vector 的迭代器的使用(遍历方式)
- 1.3 vector 空间增长问题
- 1.4 vector 的增删改查
- 二、vector的模拟实现
- 1. vector 的成员变量
- 2. 迭代器
- 3. 容量(reserve、resize)
- 4. 插入删除
- 4.1 任意位置插入
- 4.2 任意位置删除
- 4.3 尾插
- 4.4 尾删
- 5. 元素访问
- 6. 析构函数
- 7. 交换函数
- 8. 构造
- 8.1无参构造
- 8.2 实参构造
- 8.3 迭代器构造
- 8.4 实参构造的特例化
- 8.5 拷贝构造
- 8.6 赋值运算符重载
- 三、迭代器失效问题
- 四、memcpy拷贝问题
- 总结
前言
-
vector 是表示可变大小数组的序列容器。
-
就像数组一样,vector也采用的连续存储空间来存储元素。也就是意味着可以采用下标对vector的元素进行访问,和数组一样高效。但是又不像数组,它的大小是可以动态改变的,而且它的大小会被容器自动处理。
-
本质讲,vector使用动态分配数组来存储它的元素。当新元素插入时候,这个数组需要被重新分配大小为了增加存储空间。其做法是,分配一个新的数组,然后将全部元素移到这个数组。就时间而言,这是一个相对代价高的任务,因为每当一个新的元素加入到容器的时候,vector并不会每次都重新分配大小。
-
vector分配空间策略:vector会分配一些额外的空间以适应可能的增长,因为存储空间比实际需要的存储空间更大。不同的库采用不同的策略权衡空间的使用和重新分配。但是无论如何,重新分配都应该是对数增长的间隔大小,以至于在末尾插入一个元素的时候是在常数时间的复杂度完成的。
-
因此,vector占用了更多的存储空间,为了获得管理存储空间的能力,并且以一种有效的方式动态增长。
-
与其它动态序列容器相比(deque, list and forward_list), vector在访问元素的时候更加高效,在末尾添加和删除元素相对高效。对于其它不在末尾的删除和插入操作,效率更低。比起list和forward_list统一的迭代器和引用更好。
一、vector的使用
1.1 vector的构造函数声明
| (constructor)构造函数声明 | 接口说明 |
|---|---|
| vector(); | 无参构造 |
| vector (size_type n, const value_type& val = value_type()); | 构造并初始化n个val |
| vector (const vector& x); | 拷贝构造 |
| vector (InputIterator first, InputIterator last); | 使用迭代器进行初始化构造 |
void TestVector1()
{
vector<int> v1; //无参构造,参数类型为 int
vector<int> v2(5, 10); //构造v2,存放5个10
vector<int> v3(v2); //通过v2拷贝构造v3
vector<int> v4(v2.begin(),v2.end()); //使用迭代器构造
}
1.2 vector 的迭代器的使用(遍历方式)
| iterator的使用 | 接口说明 |
|---|---|
| begin + end | 获取第一个数据位置的iterator/const_iterator, 获取最后一个数据的下一个位置的iterator/const_iterator |
| rbegin + rend | 获取最后一个数据位置的reverse_iterator,获取第一个数据前一个位置的reverse_iterator |
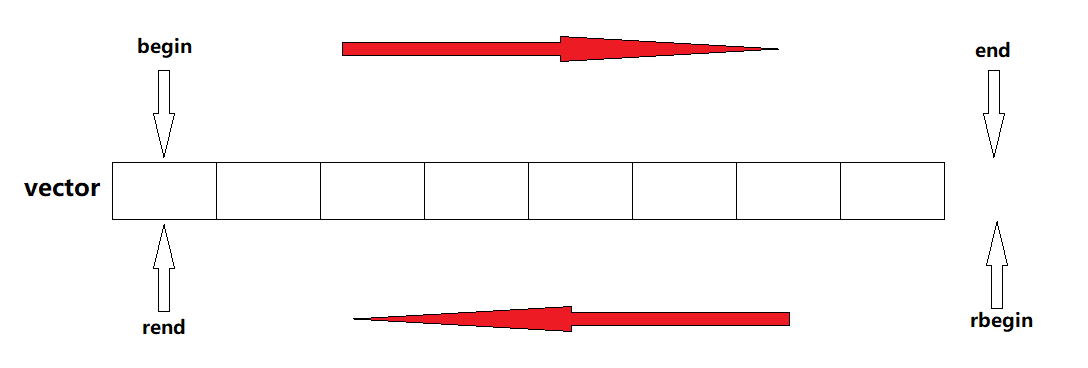
对于迭代器的使用,主要是对 vector 的遍历,除外还有其他两种方式:一种是按照数组下标的方式,另外一种是通过范围 for 的方式(底层也是迭代器)。
迭代器区间是左闭右开。
void TestVector2()
{
vector<int> v(5,10);
for (size_t i = 0; i < v.size(); ++i)
{
cout << v[i] << " ";
}
cout << endl;
vector<int>::iterator it = v.begin();
while (it != v.end())
{
cout << *it << " ";
it++;
}
cout << endl;
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}
1.3 vector 空间增长问题
| 容量空间 | 接口说明 |
|---|---|
| size | 获取数据个数 |
| capacity | 获取容量大小 |
| empty | 判断是否为空 |
| resize | 改变vector的size |
| reserve | 改变vector的capacity |
// resize()
void TestVector3()
{
vector<int> v;
for (int i = 0; i < 10; i++)
v.push_back(i);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
cout << v.size() << endl;
cout << v.capacity() << endl << endl;
v.resize(15);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
cout << v.size() << endl;
cout << v.capacity() << endl << endl;
v.resize(5);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
cout << v.size() << endl;
cout << v.capacity() << endl << endl;
v.resize(8, 100);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}

//reserve
void TestVector4()
{
vector<int> v;
for (int i = 0; i < 10; i++)
v.push_back(i);
cout << v.size() << endl;
cout << v.capacity() << endl << endl;
v.reserve(15);
cout << v.size() << endl;
cout << v.capacity() << endl << endl;
v.reserve(5);
cout << v.size() << endl;
cout << v.capacity() << endl << endl;
}

vector 的默认扩容机制:
capacity的代码在vs和g++下分别运行会发现,vs下capacity是按1.5倍增长的,g++是按2倍增长的。
void TestVectorExpand()
{
size_t sz;
vector<int> v;
sz = v.capacity();
cout << "making v grow:\n";
for (int i = 0; i < 100; ++i)
{
v.push_back(i);
if (sz != v.capacity())
{
sz = v.capacity();
cout << "capacity changed: " << sz << '\n';
}
}
}

如果已经确定vector中要存储元素大概个数,可以提前将空间设置足够就可以避免边插入边扩容导致效率低下的问题,有时间的可以自己测试一下提前将空间设置好的扩容时间差与没设置的时间差之间的差距。
1.4 vector 的增删改查
| vector增删查改 | 接口说明 |
|---|---|
| push_back | 尾插 |
| pop_back | 尾删 |
| find | 查找。(注意这个是算法模块实现,不是vector的成员接口) |
| insert | 在position之前插入val |
| erase | 删除position位置的数据 |
| swap | 交换两个vector的数据空间 |
| operator[] | 像数组一样访问 |
尾插和尾删:push_back/pop_back
void TestVector5()
{
vector<int> v;
for (size_t i = 0; i < 10; i++)
{
v.push_back(i);
}
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
v.pop_back();
v.pop_back();
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}
任意位置插入:insert和erase,以及查找find
void TestVector6()
{
// 使用列表方式初始化,C++11新语法
vector<int> v{ 1, 2, 3, 4 };
// 在指定位置前插入值为val的元素,比如:3之前插入30,如果没有则不插入
// 1. 先使用find查找3所在位置
// 注意:vector没有提供find方法,如果要查找只能使用STL提供的全局find
auto pos = find(v.begin(), v.end(), 3);
if (pos != v.end())
{
// 2. 在pos位置之前插入30
v.insert(pos, 30);
}
vector<int>::iterator it = v.begin();
while (it != v.end())
{
cout << *it << " ";
++it;
}
cout << endl;
pos = find(v.begin(), v.end(), 30);
// 删除pos位置的数据
v.erase(pos);
it = v.begin();
while (it != v.end()) {
cout << *it << " ";
++it;
}
cout << endl;
}
operator[]+index 和 C++11中vector的新式for+auto的遍历
void TestVector7()
{
vector<int> v{ 1, 2, 3, 4 };
// 通过[]读写第0个位置。
v[0] = 10;
cout << v[0] << endl;
// 1. 使用for+[]小标方式遍历
for (size_t i = 0; i < v.size(); ++i)
cout << v[i] << " ";
cout << endl;
vector<int> v1;
v1.swap(v);
cout << "v data:";
for (size_t i = 0; i < v.size(); ++i)
cout << v[i] << " ";
cout << endl;
// 2. 使用迭代器遍历
cout << "v1 data:";
auto it = v1.begin();
while (it != v1.end())
{
cout << *it << " ";
++it;
}
// 3. 使用范围for遍历
for (auto x : v)
cout << x << " ";
cout << endl;
}
二、vector的模拟实现
1. vector 的成员变量
iterator _start;
iterator _finish;
iterator _end_of_storage;
对于 vector 的整个模拟实现,主要是通过这三个迭代器来进行操作,_start 表示这段空间的第一个元素的位置,_finish 表示这段空间有效元素的下一个空间位置,而 _end_of_storage则表示整段空间的下一个位置。

2. 迭代器
// Vector的迭代器是一个原生指针
typedef T* iterator;
typedef const T* const_iterator;
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator begin()const
{
return _start;
}
const_iterator end()const
{
return _finish;
}
3. 容量(reserve、resize)
size_t capacity()const
{
return _end_of_storage - _start;
}
size_t size()const
{
return _finish - _start;
}
bool empty() const
{
return _start == _finish;
}
void reserve(size_t num)
{
if (num > capacity())
{
size_t oldsize = size();
//开辟新空间
T* tmp = new T[num];
if (_start)
{
for (size_t i = 0; i < oldsize; ++i)
{
tmp[i] = _start[i];
}
//释放原有空间
delete[] _start;
}
_start = tmp;
//_finish = _start + size();
_finish = _start + oldsize;
_end_of_storage = _start + num;
}
}
上面的注释掉的代码运行是会出错的,其实第一看感觉没什么问题,就是该段空间的起始位置+元素的个数就是_finish的位置,但是问题就出在这,因为 size() 的函数实现是 _finish - _start ,_start 确实是指向新空间的起始位置,但是_finish并没有指向新空间,依然指向的是原有空间,这必然导致算出的有效元素的个数是错误的,那么可以在拷贝之前先计算以下有效元素的个数。
void resize(size_t num, T val = T())
{
//如果n小于当前的size,则数据个数缩小到n
if (num < size())
{
_finish = _start + num;
}
else
{
//先扩容
if (num>capacity())
{
reserve(num);
}
//再将size扩大到n
while (_finish != _start + num)
{
*_finish = val;
++_finish;
}
}
}
4. 插入删除
4.1 任意位置插入
iterator insert(iterator pos, const T& val)
{
assert(pos >= _start);
assert(pos <= _finish)
if (_finish == _end_of_storage)
{
size_t len = pos - _start;
reserve(capacity() == 0 ? 4 : capacity() * 2);
//扩容之后得更新pos位置
pos = _start + len;
}
iterator it = _finish - 1;
while (it >= pos)
{
*(it + 1) = *it;
--it;
}
*pos = val;
++_finish;
return pos;
}
对于插入来说,解决迭代器失效问题并不只在插入的过程中,再插入完成之后同样也有可能会造成迭代器失效问题,为什么呢?比如说要给pos位置插入一个新元素,在插入完成之后,pos并不会指向原来所指向的元素,而是指向了新插入的元素,如果在插入函数外面进行操作((*pos)++),那么就会对新插入的元素加一,这也是一个迭代器时效问题。
为了解决这个问题,我们是否可以用引用传参的形式来解决呢?虽然对这个问题是可以解决的,但是v.insert(v.begin(),0)这行代码是错误的,为什么呢?因为调用begin函数返回的是一个临时对象,它不能通过引用传参,那么对于这个问题的解决办法就是通过返回值的方式,可以将新插入的元素的位置返回。
4.2 任意位置删除
iterator erase(iterator pos)
{
assert(pos >= _start);
assert(pos <= _finish)
// 挪动数据进行删除
iterator begin = pos + 1;
while (begin != _finish)
{
*(begin - 1) = *begin;
++begin;
}
--_finish;
return pos;
}
4.3 尾插
void push_back(const T& x)
{
insert(end(), x);
}
4.4 尾删
void pop_back()
{
erase(end() - 1);
}
5. 元素访问
T& operator[](size_t pos)
{
assert(pos < size());
return _start[pos];
}
const T& operator[](size_t pos)const
{
assert(pos < size());
return _start[pos];
}
T& front()
{
return *_start;
}
const T& front()const
{
return *_start;
}
T& back()
{
return *(_finish - 1);
}
const T& back()const
{
return *(_finish - 1);
}
6. 析构函数
~vector()
{
if (_start)
{
delete[] _start;
_start = _finish = _endOfStorage = nullptr;
}
}
7. 交换函数
void swap(vector<T>& v)
{
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_endOfStorage, v._endOfStorage);
}
8. 构造
8.1无参构造
vector()
: _start(nullptr)
, _finish(nullptr)
, _endOfStorage(nullptr)
{}
8.2 实参构造
//第二个参数通过匿名构造来创建参数对象
vector(size_t n, const T& value = T())
: _start(nullptr)
, _finish(nullptr)
, _endOfStorage(nullptr)
{
reserve(n);
while (n--)
{
push_back(value);
}
}
8.3 迭代器构造
template<class InputIterator>
vector(InputIterator first, InputIterator last)
{
while (first != last)
{
push_back(*first);
++first;
}
}
8.4 实参构造的特例化
为什么会有实参构造的特例化呢?原因就在于出现这种场景:vector<int> v(10, 5);
编译器在编译时,认为T已经被实例化为int,而10和5编译器会默认其为int类型,就不会走vector(size_t n, const T& value = T())这个构造方法,因为这个构造·方法相对与迭代器构造方法来说只是一个备选,而编译器认为最好的选择应该是迭代器构造方法,最终选择的是:vector(InputIterator first, InputIterator last),因为编译器觉得区间构造两个参数类型一致,因此编译器就会将InputIterator实例化为int,但是10和5根本不是一个区间,编译时就报错了。
如果说没有实现迭代器构造方法,那么这种情况就不会发生,但是针对于迭代器构造方法的出现,所以就对重新再写一个针对性的构造方法来解决这个问题。
还有一种解决办法就是:vector<int> v(10u, 5);,将第一个参数直接变为无符号型,那么就不会调用迭代器构造方法。
//在这个构造方法内,针对于那种场景两个参数都为int类型,这样就可以更好的解决刚才的问题
vector(int n, const T& value = T())
: _start(new T[n])
, _finish(_start+n)
, _endOfStorage(_finish)
{
for (int i = 0; i < n; ++i)
{
_start[i] = value;
}
}
8.5 拷贝构造
vector(const vector<T>& v)
: _start(nullptr)
, _finish(nullptr)
, _endOfStorage(nullptr)
{
reserve(v.capacity());
iterator it = begin();
const_iterator vit = v.cbegin();
while (vit != v.cend())
{
*it++ = *vit++;
}
_finish = it;
}
8.6 赋值运算符重载
vector<T>& operator=(vector<T> v)
{
swap(v);
return *this;
}
三、迭代器失效问题
迭代器的主要作用就是让算法能够不用关心底层数据结构,其底层实际就是一个指针,或者是对指针进行了封装,比如:vector的迭代器就是原生态指针T* 。因此迭代器失效,实际就是迭代器底层对应指针所指向的空间被销毁了,而使用一块已经被释放的空间,造成的后果是程序崩溃(即如果继续使用已经失效的迭代器,程序可能会崩溃)。
对于vector可能会导致其迭代器失效的操作有:
1. 引起 vector 底层空间改变的操作,都有可能是迭代器失效,比如:resize、reserve、insert、assign、push_back等。
void TestVector8()
{
vector<int> v{ 1, 2, 3, 4, 5, 6 };
auto it = v.begin();
// 将有效元素个数增加到100个,多出的位置使用8填充,操作期间底层会扩容
// v.resize(100, 8);
// reserve的作用就是改变扩容大小但不改变有效元素个数,操作期间可能会引起底层容量改变
// v.reserve(100);
// 插入元素期间,可能会引起扩容,而导致原空间被释放
// v.insert(v.begin(), 0);
// v.push_back(8);
// 给vector重新赋值,可能会引起底层容量改变
v.assign(100, 8);
}
根据上面的代码来看,都有可能引起迭代器的失效,为什么呢?原因就在于上述操作都有可能会导致vector扩容,也并不是说扩容就一定会迭代器失效,而是如果当前vector的底层空间不满足新空间的需要,那么就得内存其他地方重新开辟一段更大的空间,那么旧空间被释放掉,而在打印时,it还使用的是释放之间的旧空间,在对it迭代器操作时,实际操作的是一块已经被释放的空间,而引起代码运行时崩溃。
2. 指定位置元素的删除操作–erase
void TestVector9()
{
int a[] = { 1, 2, 3, 4 };
vector<int> v(a, a + sizeof(a) / sizeof(int));
// 使用find查找3所在位置的iterator
vector<int>::iterator pos = find(v.begin(), v.end(), 3);
// 删除pos位置的数据,导致pos迭代器失效。
v.erase(pos);
cout << *pos << endl; // 此处会导致非法访问
}
erase删除pos位置元素后,pos位置之后的元素会往前搬移,这里其实没有导致底层空间的改变,理论上讲迭代器不应该会失效,但是:如果pos刚好是最后一个元素,删完之后pos刚好是end的位置,而end位置是没有元素的,那么pos就失效了。因此删除vector中任意位置上元素时,vs就认为该位置迭代器失效了。
下面代码的功能是删除vector中所有的偶数,请问代码是否正确,为什么?如果不正确,该怎么改正?
void TestVector10()
{
vector<int> v{ 1, 2, 3, 4, 5, 6 };
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
v.erase(it);
++it;
}
it = v.begin();
while (it != v.end())
{
cout << *it << " ";
it++;
}
cout << endl;
}
在 VS 下,使用了 erase 函数之后,再对其解引用,无论是否合乎常理,编译器都认为迭代器是失效的。它的结果是未定义的。
改正后的代码:
void TestVector10()
{
vector<int> v{ 1, 2, 3, 4, 5, 6 };
auto it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
//对迭代器重新赋值
it = v.erase(it);
else
++it;
}
it = v.begin();
while (it != v.end())
{
cout << *it << " ";
it++;
}
cout << endl;
}
四、memcpy拷贝问题
看上面的拷贝构造函数,我们使用的是遍历赋值的方式完成的。那么是否可以用memcpy的方式同样完成呢?
vector(const vector<T>& v)
: _start(nullptr)
, _finish(nullptr)
, _endOfStorage(nullptr)
{
reserve(v.capacity());
memcpy(_start,v._start,sizeof(T)*v.size());
_finish = _start+v.size();
_end_of_storage = _start + v.capacity();
}
void TestVector()
{
vector<int> v1{1, 2, 3, 4, 5, 6};
vector<int> v2(v1);
auto it = v2.begin();
while (it != v2.end())
{
cout << *it << " ";
it++;
}
cout << endl;
}
其实通过运行发现似乎这样的方式可以完成 vector 的拷贝,但是对于这样的情况就不行了。
void TestVector()
{
vector<std::string> v1{5,"abcd"};
vector<std::string> v2(v1);
}
首先我们要明白的是:
- memcpy是内存的二进制格式拷贝,将一段内存空间中内容原封不动的拷贝到另外一段内存空间中
- 如果拷贝的是自定义类型的元素,memcpy既高效又不会出错,但如果拷贝的是自定义类型元素,并且自定义类型元素中涉及到资源管理时,就会出错,因为memcpy的拷贝实际是浅拷贝。
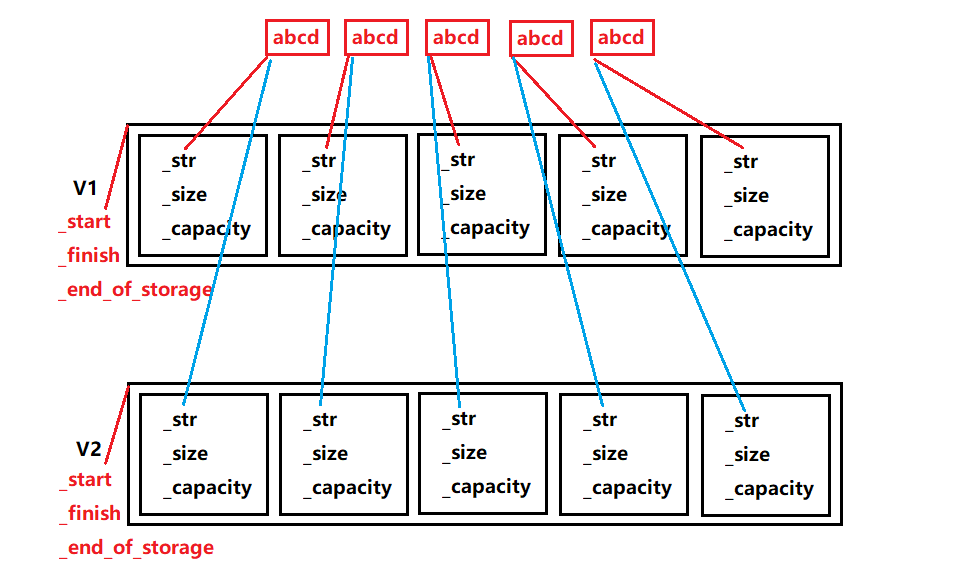
从这幅图我们可以看到,memcpy拷贝是将vector里的数据依次进行拷贝,但是每个数据优又是一个个的string类型的对象,也是通过一个个指针分别指向对应的字符串,那么当 v2 在析构时,就会先将一个个字符串从内存中删除掉,当 v1 再析构时就会发生错误(同一份空间析构两次)。所以说:如果对象中涉及到资源管理时,千万不能使用memcpy进行对象之间的拷贝,因为memcpy是浅拷贝,否则可能会引起内存泄漏甚至程序崩溃。同样在扩容的时候也不能使用 memcpy 方法。
总结
以上就是对vector的学习总结,总体来说还是挺容易的,但是有两点需要特别注意:一个就是迭代器失效问题,在扩容时就很有可能引起迭代器失效,删除操作同样也会引起迭代器失效问题,不管是否合乎常理;另外一个问题就是关于深浅拷贝问题,一个就是要注意关于自定义类型的数据在拷贝构造以及扩容的时候不要使用 memcpy 的拷贝方法,这样会引起浅拷贝,造成同一份资源被释放多次;还有就是二维数组的拷贝构造的时候也要注意这个问题。

![[Nacos] Nacos Server处理注销请求 (七)](https://img-blog.csdnimg.cn/3720b380053b4e2fb6d83b0acbf8803b.png)